从CLIP到BGE-M3:多模态嵌入的演进与实践
多模态嵌入技术:打破AI的模态壁垒 多模态嵌入技术通过将文本、图像等不同模态数据映射到同一向量空间,实现了跨模态语义理解。OpenAI的CLIP模型采用双编码器架构和对比学习策略,开创性地实现了图文语义对齐。北京智源研究院的BGE-M3在此基础上进一步发展,通过网格嵌入和多语言支持,提升了复杂场景的处理能力。这些技术突破使AI系统能够理解"一只奔跑的狗"的文字描述与对应图片的语
“在AI的世界里,图像与文本不应是两个独立的宇宙,而是同一个语义宇宙的两个侧面。”
一、为什么我们需要多模态嵌入?
在AI的早期发展中,文本和图像被视为两个完全独立的领域。文本可以被嵌入为向量,图像也能被编码为特征,但它们处于相互隔离的向量空间中,如同隔着一堵"模态墙"。
传统方法的局限:
- 文本嵌入模型无法理解"那张有黑色汽车的图片"
- 图像特征向量无法与"黑色汽车"的文本描述进行语义匹配
- 无法实现跨模态的语义检索与理解
**多模态嵌入(Multimodal Embedding)的出现,正是为了解决这一核心挑战。其目标是将不同模态的数据(文本、图像、音频、视频)**映射到同一个共享的向量空间中,使"一只奔跑的狗"的文本描述与真实图片的向量在空间中彼此靠近。
关键突破:通过对比学习、Transformer架构和注意力机制,模型学会了在共享空间中对齐不同模态的语义。
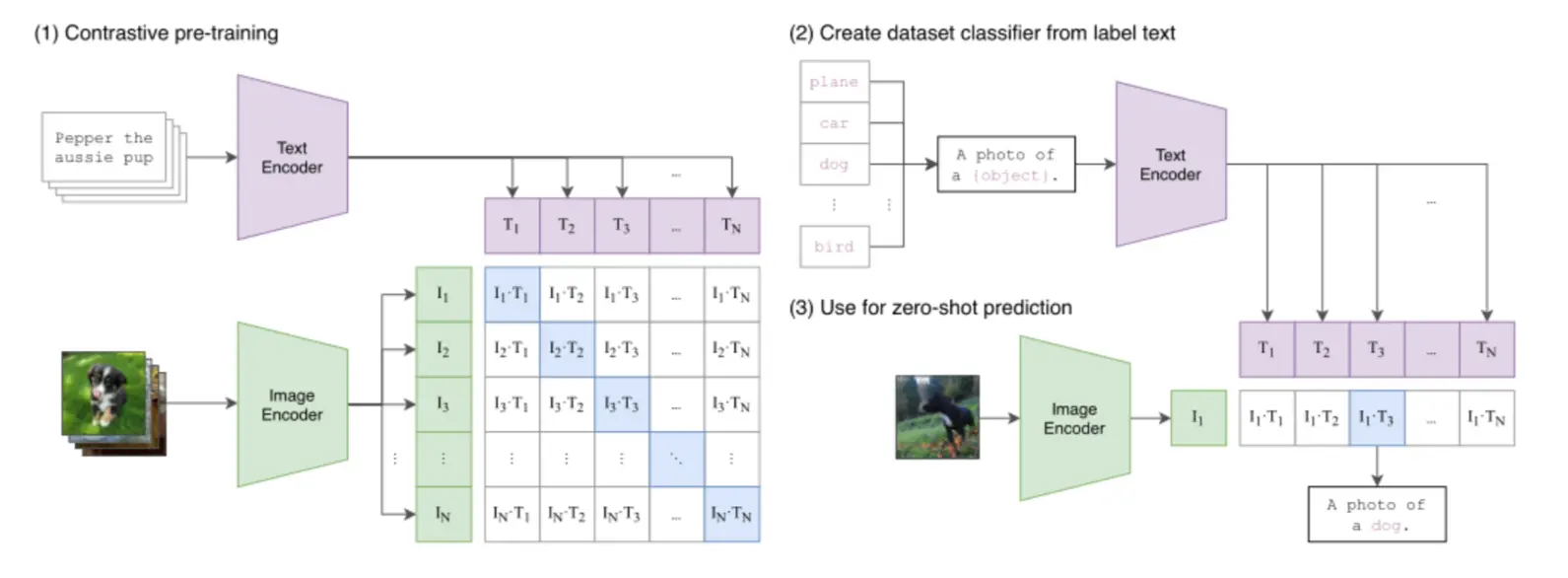
二、CLIP:多模态嵌入的里程碑
OpenAI的CLIP (Contrastive Language-Image Pre-training) 为多模态嵌入定义了一个有效范式,其核心创新在于:
2.1 双编码器架构
CLIP采用双编码器架构,包含:
- 图像编码器:将图像转换为向量
- 文本编码器:将文本转换为向量
两者共享同一个向量空间,通过对比学习训练,使语义相关的图文对在空间中距离更近。
2.2 对比学习策略
在训练过程中,CLIP的优化目标是:
- 最大化正确图文对的相似度
- 最小化错误图文对的相似度
这种"拉近正例,推远负例"的策略,让模型从海量数据中学习到了跨模态的语义关联。
2.3 零样本能力
CLIP的对比学习赋予了它强大的零样本(Zero-shot)识别能力。例如:
- 判断图片是否为猫:只需计算图片向量与"photo of a cat"文本向量的相似度
- 无需针对猫的分类任务进行微调,即可实现对视觉概念的泛化理解
CLIP的影响力:它证明了大规模对比学习在跨模态对齐中的有效性,为后续多模态模型奠定了基础。
三、BGE-M3:现代多模态嵌入的集大成者
在CLIP的基础上,多模态嵌入领域迅速发展,涌现出众多针对不同场景优化的模型。其中,BGE-M3(由北京智源人工智能研究院BAAI开发)代表了当前技术向"更统一、更全面"发展的趋势。
3.1 BGE-M3的"M3"特性
BGE-M3的名称源自其三大核心优势:
| 特性 | 说明 | 优势 |
|---|---|---|
| 多语言性 (Multi-Linguality) | 原生支持100+种语言 | 跨语言图文检索无缝支持 |
| 多功能性 (Multi-Functionality) | 同时支持密集检索、多向量检索和稀疏检索 | 适应不同场景的灵活检索策略 |
| 多粒度性 (Multi-Granularity) | 有效处理从短句到8192 token的长文档 | 覆盖广泛的应用需求 |
3.2 技术架构创新
BGE-M3在技术架构上实现了突破性改进:
- 基于XLM-RoBERTa优化的联合编码器:继承了BGE强大的文本表示能力
- 网格嵌入(Grid-Based Embeddings):不同于CLIP对整张图编码,将图像分割为网格单元独立编码
- 优势:显著提升对图像局部细节的捕捉能力
- 应用场景:多物体重叠、复杂场景的图像理解
技术对比:
- CLIP:整图编码,适合简单场景
- BGE-M3:网格编码,适合复杂场景,对局部细节更敏感
四、BGE-M3实战:代码示例与解读
4.1 环境准备
# 安装所需依赖
pip install -q torch transformers pillow requests
# 安装visual_bge模块
pip install -q git+https://github.com/BAAI/VisualBGE.git
4.2 模型下载
import os
import requests
from pathlib import Path
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
def download_visualized_bge_model():
"""
下载 Visual BGE 模型权重文件
如果模型文件不存在,则从 Hugging Face 下载
"""
# 定义模型路径和下载URL
model_dir = Path("./models/bge")
model_file = model_dir / "Visualized_base_en_v1.5.pth"
# download_url = "https://huggingface.co/BAAI/bge-visualized/resolve/main/Visualized_base_en_v1.5.pth?download=true"
download_url = "https://hf-mirror.com/BAAI/bge-visualized/resolve/main/Visualized_base_en_v1.5.pth?download=true"
# 检查模型文件是否已存在
if model_file.exists():
print(f"模型文件已存在: {model_file}")
print(f"文件大小: {model_file.stat().st_size / (1024*1024):.1f} MB")
return str(model_file)
# 创建目录
model_dir.mkdir(parents=True, exist_ok=True)
print(f"创建模型目录: {model_dir}")
# 下载模型
print(f"开始下载模型...")
print(f"下载地址: {download_url}")
try:
response = requests.get(download_url, stream=True)
response.raise_for_status()
# 获取文件大小
total_size = int(response.headers.get('content-length', 0))
downloaded_size = 0
with open(model_file, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
downloaded_size += len(chunk)
# 显示下载进度
if total_size > 0:
progress = (downloaded_size / total_size) * 100
print(f"\r下载进度: {progress:.1f}% ({downloaded_size/(1024*1024):.1f}/{total_size/(1024*1024):.1f} MB)", end='')
print(f"\n模型下载完成: {model_file}")
print(f"文件大小: {model_file.stat().st_size / (1024*1024):.1f} MB")
return str(model_file)
except requests.exceptions.RequestException as e:
print(f"下载失败: {e}")
# 如果下载失败,删除不完整的文件
if model_file.exists():
model_file.unlink()
return None
except Exception as e:
print(f"发生错误: {e}")
if model_file.exists():
model_file.unlink()
return None
if __name__ == "__main__":
model_path = download_visualized_bge_model()
if model_path:
print(f"✅ 模型准备就绪: {model_path}")
else:
print("❌ 模型下载失败")
脚本会自动检查./models/bge/目录,若模型文件不存在则从Hugging Face镜像站下载。
4.3 代码示例与解读
import os
import requests
from PIL import Image
from io import BytesIO
import torch
from visual_bge.visual_bge.modeling import Visualized_BGE
# 设置环境变量
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
# 初始化模型
model = Visualized_BGE(
model_name_bge="BAAI/bge-base-en-v1.5",
model_weight="./models/bge/Visualized_base_en_v1.5.pth"
)
model.eval()
# 下载示例图片
def download_image(url):
response = requests.get(url)
img = Image.open(BytesIO(response.content))
return img
# 获取通用图片URL
cat_image_url = "https://pic1.imgdb.cn/item/68c22d1e58cb8da5c89a0dad.png"
dog_image_url = "https://pic1.imgdb.cn/item/68c22d4b58cb8da5c89a0dc5.png"
car_image_url = "https://pic1.imgdb.cn/item/68c22d6a58cb8da5c89a0dcd.png"
# 下载图片
cat_img = download_image(cat_image_url)
dog_img = download_image(dog_image_url)
car_img = download_image(car_image_url)
# 保存下载的图像到本地
cat_img.save("cat.png")
dog_img.save("dog.png")
car_img.save("car.png")
# 编码示例
with torch.no_grad():
# 文本嵌入
text_cat = model.encode(text="a cat")
text_dog = model.encode(text="a dog")
text_car = model.encode(text="a red car")
# 图像嵌入
img_cat = model.encode(image="cat.png")
img_dog = model.encode(image="dog.png")
img_car = model.encode(image="car.png")
# 图文联合嵌入
img_text_cat = model.encode(image="cat.png", text="a cat")
img_text_dog = model.encode(image="dog.png", text="a dog")
img_text_car = model.encode(image="car.png", text="a car")
# 相似度计算
cat_dog_sim = img_cat @ img_dog.T
cat_car_sim = img_cat @ img_car.T
cat_text_cat_sim = img_cat @ text_cat.T
img_text_cat_sim = img_text_cat @ img_cat.T
print("=== 相似度计算结果 ===")
print(f"猫图片 vs 狗图片: {cat_dog_sim.item():.4f}")
print(f"猫图片 vs 汽车图片: {cat_car_sim.item():.4f}")
print(f"猫图片 vs 猫文本: {cat_text_cat_sim.item():.4f}")
print(f"猫图片 vs 猫图文: {img_text_cat_sim.item():.4f}")
4.4 代码关键点解析
- 模型架构:
Visualized_BGE是基于BGE文本嵌入框架构建的多模态模型- 集成了图像token嵌入到BGE框架中,实现多模态处理
- 多模态编码能力:
- 纯文本编码:保持BGE的文本嵌入能力
- 纯图像编码:使用EVA-CLIP视觉编码器
- 图文联合编码:融合图像和文本特征到统一空间
- 相似度计算:
- 使用矩阵乘法计算余弦相似度
- 所有嵌入向量已标准化到单位长度,确保相似度值合理
4.5 运行结果
=== 相似度计算结果 ===
猫图片 vs 狗图片: 0.6061
猫图片 vs 汽车图片: 0.4382
猫图片 vs 猫文本: 0.6123
猫图片 vs 猫图文: 0.9438
纯文本与图文结合的相似度(0.6123)低于图文结合之间(0.9438)的相似度,表明文本信息与图像信息的融合效果
五、多模态嵌入的未来展望
5.1 超越图文:多模态的扩展
- 视频理解:将时间维度纳入嵌入空间,实现视频内容的语义表示
- 音频-文本对齐:构建音频与文本的统一嵌入空间
- 3D场景理解:将空间信息纳入多模态嵌入
5.2 轻量化与边缘部署
- 模型压缩:通过知识蒸馏、量化等技术,使多模态模型能在移动端部署
- 高效推理:优化计算流程,减少推理延迟
5.3 语义与知识的深度融合
- 结合知识图谱:将多模态嵌入与知识图谱结合,增强语义理解能力
- 因果推理:从简单的相关性到因果关系的多模态推理
六、结语
多模态嵌入技术的发展,从CLIP的对比学习到BGE-M3的"M3"特性,标志着AI系统正在从单一模态理解迈向全面的跨模态认知。它打破了"模态墙",让AI真正能够像人类一样,同时理解文本、图像、音频等多源信息。
“未来的AI系统,将不是能理解文字或图像的系统,而是能理解文字、图像、声音、视频的统一系统。”
参考资料:
- CLIP: Contrastive Language-Image Pre-training
- [BGE-M3: A Modern Multimodal Embedding Model](

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)