多卡显存优化技术:DP/DDP/FSDP,Deepspeed ZeRO 1/2/3 (Offload),Gradient(Activation) checkpointing详解
视频地址:
最简单的单卡训练方式
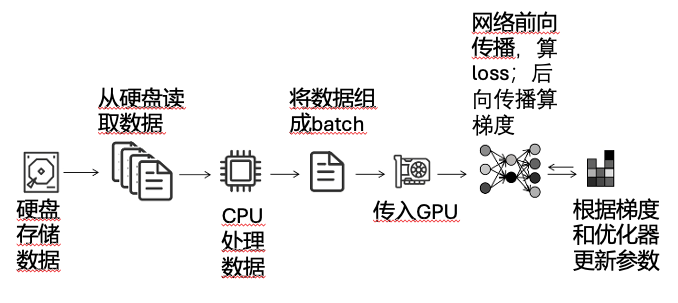
最简单的分布式训练方式:DP data parallel
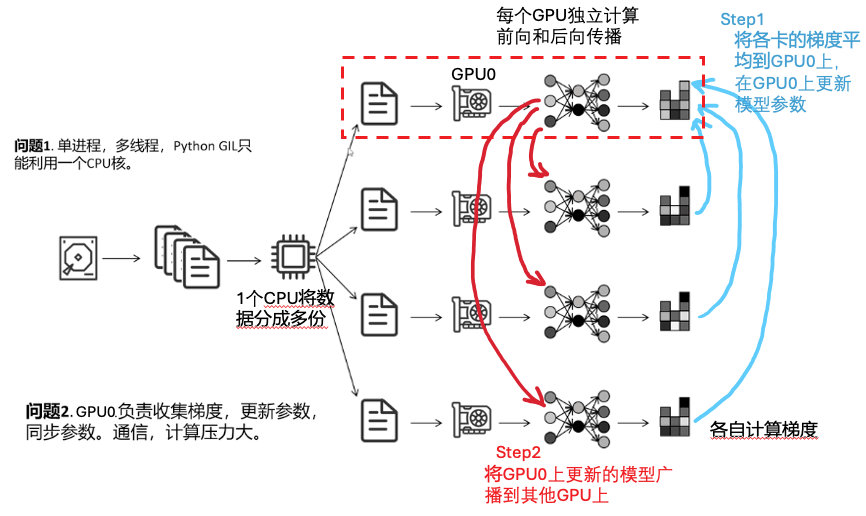
DDP ditributed data parallel
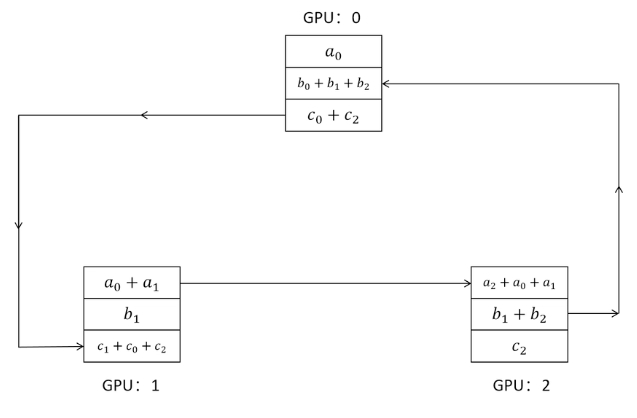
通过环的方式更新参数
1,阶段1scatter reduce:累加梯度和
2,互相发送梯度和
通过这种方式,每个GPU上的负载是一样的,并且同时进行发送和接收,效率大大提高
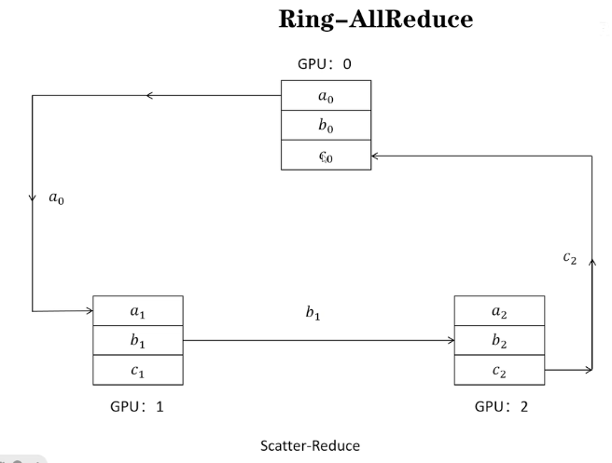
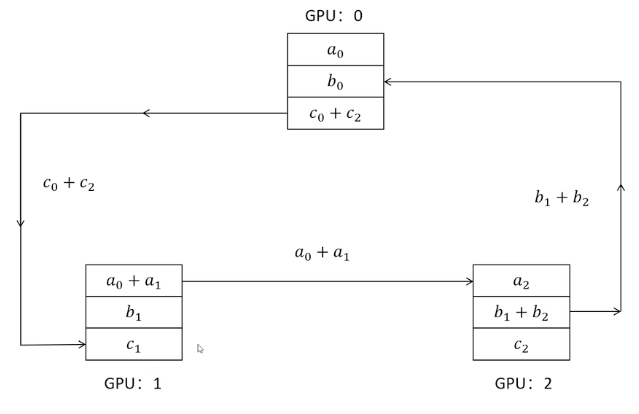
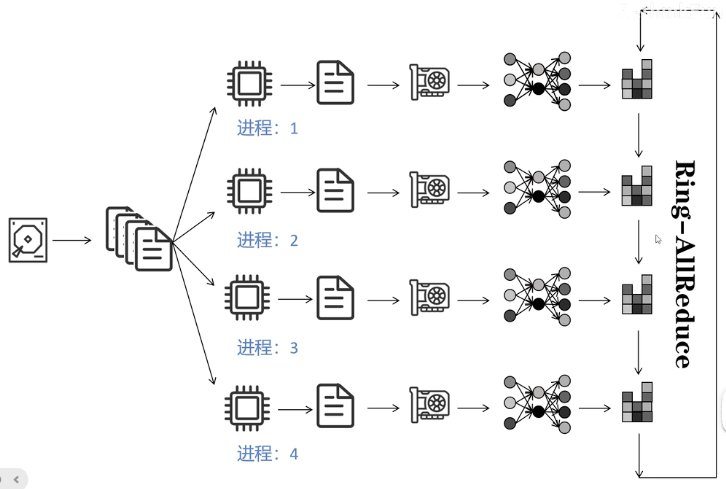
DDP是多进程的方法
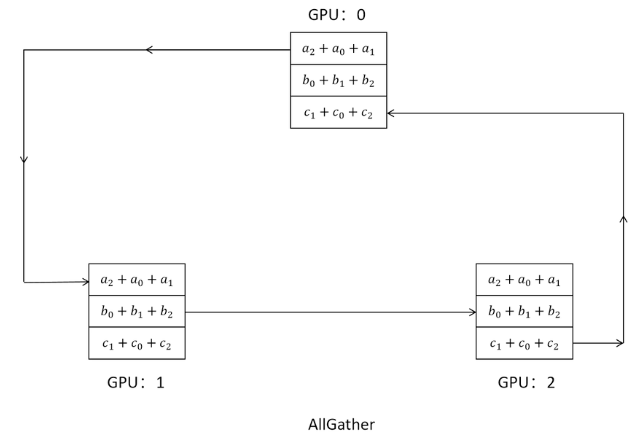
DDP通过ring all reduce的方式实现梯度和网络参数的同步
具体细节:同步梯度和网络参数
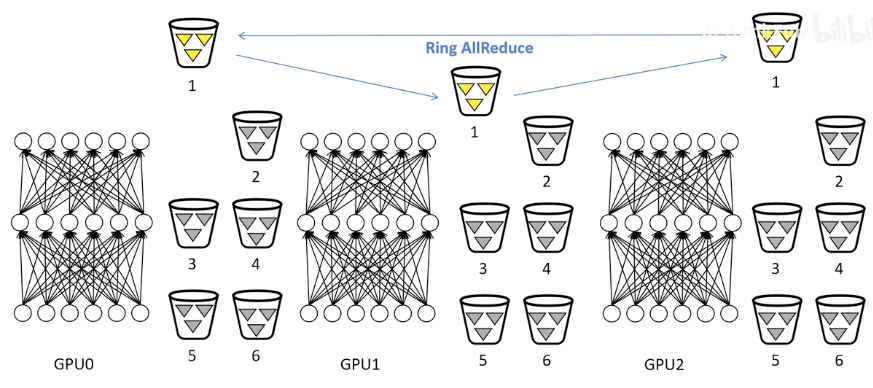
DP的通讯量分析:
GPU0的通讯量随着GPU数量的增加会不断增加
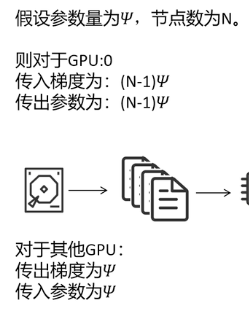

DDP的缺点:每个GPU都要存储完整的模型和优化器,显存消耗大
FSDP (Fully Sharded Data Parallel)
FSDP是什么:

FSDP不是什么:

张量并行:
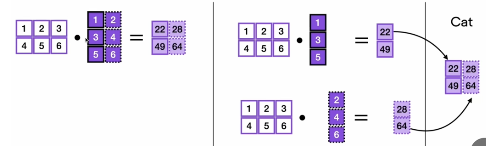
模型并行:当一张卡无法放下一整个模型时,使用多个卡,每张卡存模型的不同层,每张卡计算完后交给下一张卡,实际上一个片段内只有一张卡在跑,其他卡在等待
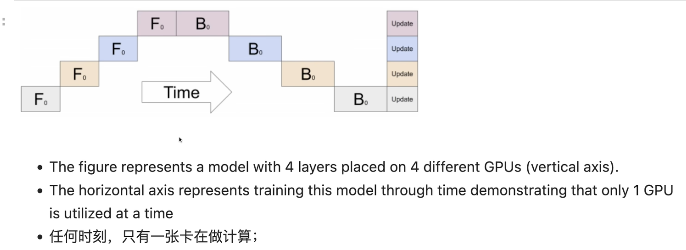
流水线并行:
通过划分不同的数据batch,batch之间不同步,可以让每张卡都同时计算
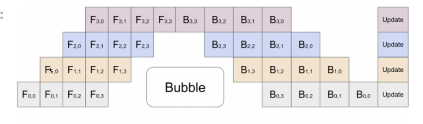
实现方式:可以看到模型不同的层被放到了不同的卡上面:
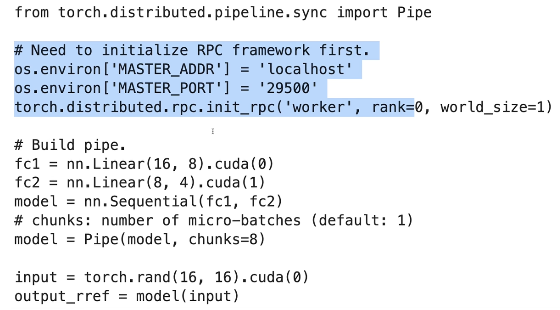
不同颜色代表不同的shards(分片到不同的GPU)
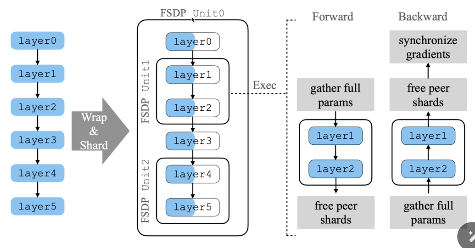


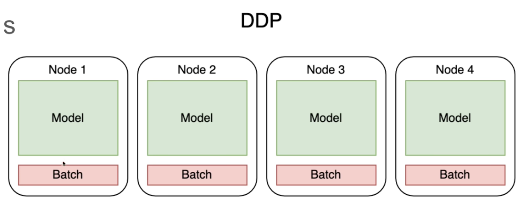
DDP和FSDP的区别:
DDP中每个卡上面的模型都是完整的模型
FSDP中,每个卡上的模型都是被切分的
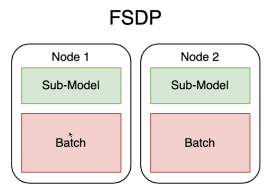
FSDP和deepspeed的区别:

Accelerate
Accelerate是一个封装库,里面集成了FSDP,deepspeed这些库
DeepSpeed ZeRO:zero redundancy optimizer
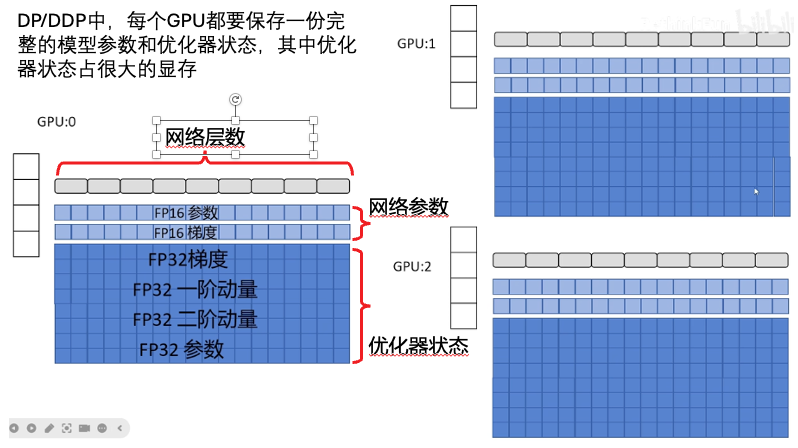
ZeRO1:对优化器的状态根据网络的不同层数在多个GPU上进行分片

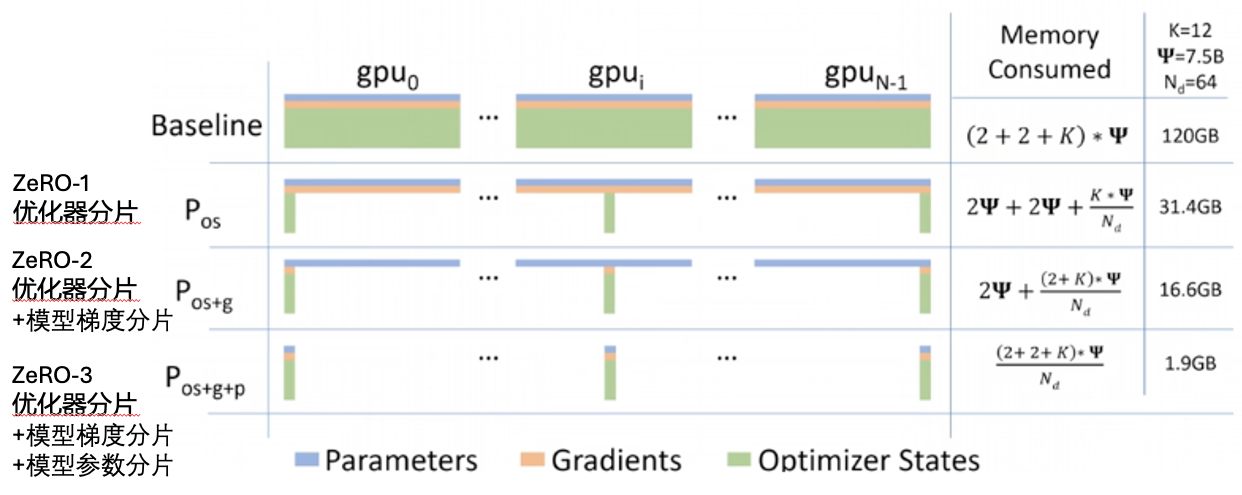
显存节省分析
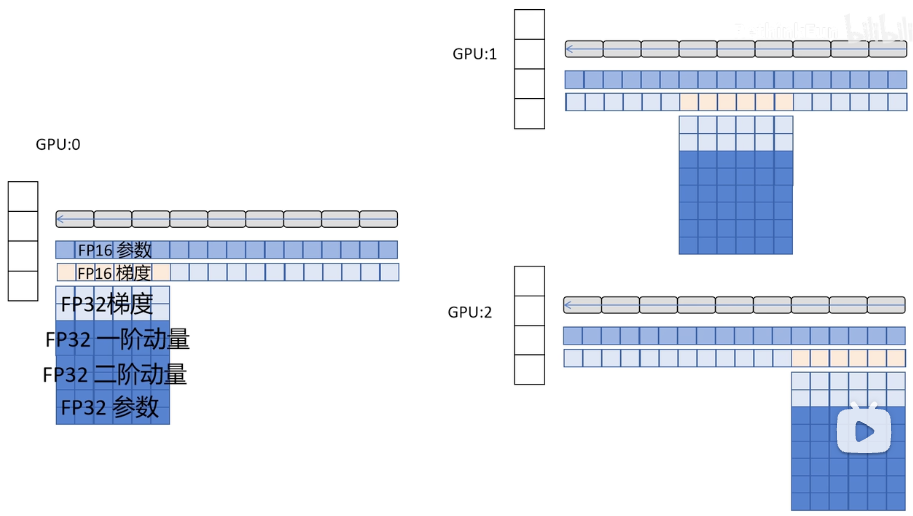
ZeRO2:对优化器的状态和模型的梯度部分根据网络的不同层数在多个GPU上进行分片
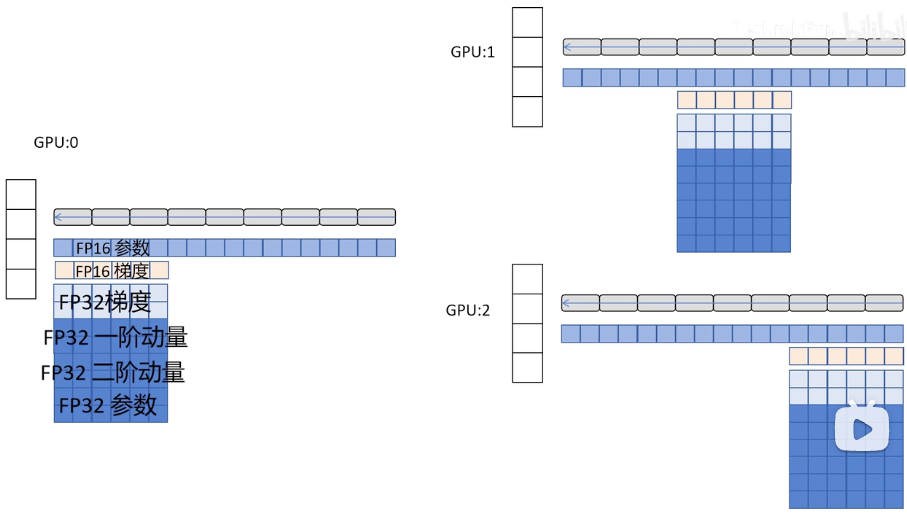

ZeRO3:对优化器的状态和模型的梯度部分和参数部分根据网络的不同层数在多个GPU上进行分片
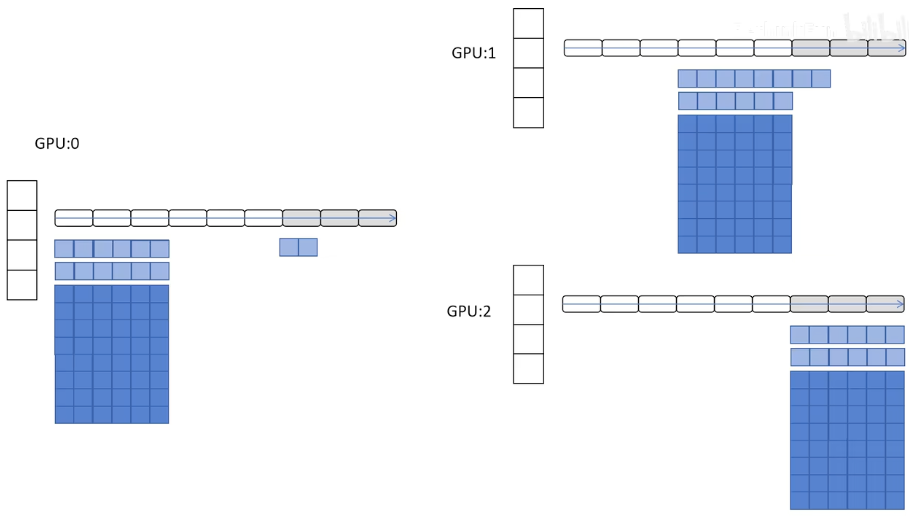

一般实际使用过程中采用的是ZeRO2,因为他没有增大通讯量,但是大大减小了显存占用
DeepSpeed ZeRO Offload技术
在之前的3个stage的基础上,还可以通过Offload到CPU的方式进一步减小对GPU的显存要求


zero代码和zero offload的代码对比:
源自Rex-omni仓库
zero 3代码
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"train_micro_batch_size_per_gpu": "auto",
"train_batch_size": "auto",
"gradient_accumulation_steps": "auto",
"zero_optimization": {
"stage": 3,
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
}
}zero 3 offload 代码:其实核心改动就两个,声明一下把参数状态和优化器状态offload到CPU上即可
"zero_optimization": {
"stage": 3,
# 将optimizer的状态offload到CPU上
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
# 将模型参数offload到CPU上
"offload_param": {
"device": "cpu",
"pin_memory": true
},完整代码:
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"train_micro_batch_size_per_gpu": "auto",
"train_batch_size": "auto",
"gradient_accumulation_steps": "auto",
"steps_per_print": 1e5,
"wall_clock_breakdown": false
"zero_optimization": {
"stage": 3,
# 将optimizer的状态offload到CPU上
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
# 将模型参数offload到CPU上
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"gather_16bit_weights_on_model_save": true
},
}Gradient Checkpointing技术(又叫activation Checkpointing)
Gradient Checkpointing
在前向传播时,丢到一部分的计算值
在反向传播时,重新再计算一次
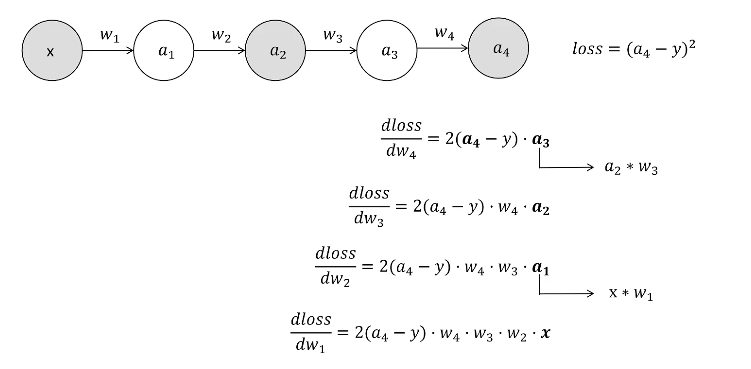
代码实现:
直接指定gradient checkpointing==True即可

Activation Checkpointing
在Deepspeed的代码中,把Gradient Checkpointing叫做activation Checkpointing,其实这两者是一回事。

Activation Checkpointing在deepspeed中的实现方式:
在.json文件中加入activation_checkpointing这个键即可:
代码:
"activation_checkpointing": {
"partition_activations": true,
"cpu_checkpointing": true,
"contiguous_memory_optimization": true,
"number_checkpoints": null,
"synchronize_checkpoint_boundary": true,
"profile": false
}完整的代码:
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"train_micro_batch_size_per_gpu": "auto",
"train_batch_size": "auto",
"gradient_accumulation_steps": "auto",
"zero_optimization": {
"stage": 2,
"overlap_comm": false,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": 5e7,
"allgather_bucket_size": 5e7,
"round_robin_gradients": true
},
# 设置 activation_checkpointing 进一步减小显存消耗
"activation_checkpointing": {
"partition_activations": true,
"cpu_checkpointing": true,
"contiguous_memory_optimization": true,
"number_checkpoints": null,
"synchronize_checkpoint_boundary": true,
"profile": false
}
}
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)