黄仁勋预测AI生成知识将占主导:未来90%的新内容或由人工智能合成
【摘要】AI正从辅助工具演变为知识生产的主导者。未来焦点将从内容来源转向其可验证性,自然语言成为新的编程接口,人类的核心价值则重塑为问题设计与质量把关。
【摘要】AI正从辅助工具演变为知识生产的主导者。未来焦点将从内容来源转向其可验证性,自然语言成为新的编程接口,人类的核心价值则重塑为问题设计与质量把关。

引言
英伟达CEO黄仁勋近期提出的一个论断,正在技术圈内引发一场深刻的思考。他预测,在未来两到三年内,全球约90%的新知识将由人工智能(AI)合成。这个数字并非危言耸听,而是对当前技术演进速度的冷静评估。它标志着一个根本性的范式转移,即知识生产的重心正从人类创作者,不可逆转地滑向人机协同,甚至AI主导的新模式。
这篇文章不讨论这一趋势的好坏,而是将其作为一个即将到来的技术现实进行拆解。我们将从工程视角分析“90%”背后的含义,探讨信任体系如何从“来源权威”转向“过程可验证”,并深入剖析自然语言作为新一代编程接口的技术实现。最终,我们将重新审视人类在这一新生态中的定位与核心价值。
💡 一、范式转移:解构“90%新知识由AI合成”的工程内涵

黄仁勋的预测并非凭空而来,它建立在对算力增长、模型迭代和数据爆炸的深刻理解之上。这一预测的核心,是知识生产工作流的彻底重构。
1.1 时间尺度与技术基础
“两到三年”的时间窗口,是基于当前大语言模型(LLM)能力迭代的指数级速度。从GPT-3到GPT-4,模型在逻辑推理、代码生成、多模态理解等方面的能力实现了非线性跃迁。这种进步的背后是三大支柱的支撑。
-
算力(Compute):以NVIDIA的GPU为例,硬件性能的持续迭代为更大规模、更高复杂度的模型训练提供了物理基础。
-
算法(Algorithm):Transformer架构及其变体的优化,使得模型能够更高效地处理和理解长序列数据,捕捉深层语义。
-
数据(Data):互联网海量的高质量文本和代码数据,为模型提供了前所未有的学习素材。
这三者构成的正反馈循环,使得AI的能力边界以前所未有的速度向外扩张。因此,“90%”的预测,在技术层面具备其合理性。
1.2 “新知识”的范畴界定
这里的“新知识”是一个广义概念,它不局限于传统意义上的学术论文或发明专利。从一个软件工程师的日常工作流来看,它涵盖了以下多个层面。
|
知识类别 |
传统生产方式 |
AI合成生产方式 |
|---|---|---|
|
代码实现 |
工程师手动编写、调试、重构 |
工程师描述需求,AI生成代码片段、单元测试、甚至完整模块 |
|
技术文档 |
查阅官方文档,手动撰写API说明 |
AI根据代码自动生成注释、README、API文档 |
|
解决方案 |
搜索技术论坛、博客,结合经验设计 |
提出复杂问题,AI提供多种架构方案、技术选型对比 |
|
数据分析 |
编写SQL/Python脚本,手动可视化 |
用自然语言提问,AI自动生成查询、分析报告和图表 |
|
市场洞察 |
阅读行业报告,人工整理分析 |
AI整合海量新闻、财报、社交媒体数据,生成趋势摘要 |
|
创意内容 |
营销人员头脑风暴,撰写文案 |
AI根据产品特点和目标人群,生成多种风格的营销文案和图片 |
AI的角色正从一个被动的查询工具,转变为知识初稿的主动生产者。人类的工作起点,不再是一张白纸,而是一个由AI提供的、完成度相当高的草案。
1.3 生产模式重塑:从辅助到主导
传统的知识生产流程是线性的,而AI介入后,它变成了一个高效的迭代循环。我们可以用流程图来清晰地展示这一变化。
传统知识生产流程

AI合成知识生产流程
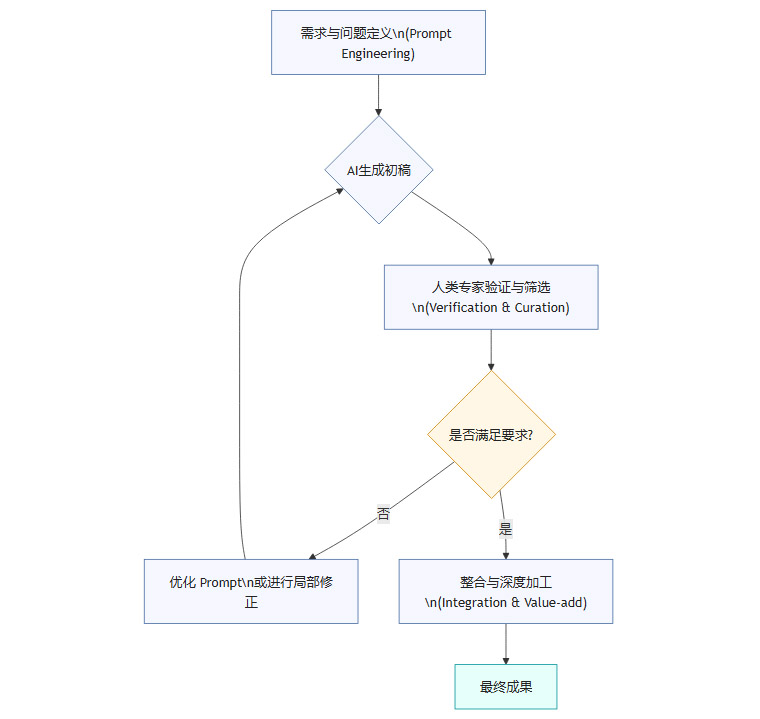
在这个新流程中,人类的价值点从“从零到一”的创造,转移到了“从一到N”的优化和“从N到一”的决策。即,提出高质量的问题、验证AI输出的可靠性、并最终对结果负责。
💡 二、信任重构:从“来源权威”到“可验证性”的转变
当知识的主要生产者变为AI时,我们传统的信任体系受到了巨大冲击。过去,我们信任某个信息,往往是因为它来自权威机构或知名专家。但在AI时代,这个逻辑正在失效。
2.1 历史类比:教科书与陌生人作者
黄仁勋用了一个非常贴切的比喻,AI生成的内容就像一本“陌生人写的教科书”。我们之所以接受教科书里的知识,不是因为我们认识作者,而是因为这些知识本身是可验证的、符合基本原理的、并经过了同行评议。
这个类比的核心在于,它将信任的锚点从**“作者身份”(Who)转移到了“内容质量”(What & How)**。无论信息由谁生成,我们都必须用同样的标准去审视它。
-
原理一致性:它是否与已知的科学原理或逻辑公理相符?
-
事实可追溯:它引用的数据和事实,能否追溯到可信的原始来源?
-
逻辑可复现:它的推导过程是否清晰,能否被独立复现?
这种思维转变,要求我们从“身份迷信”中解放出来,回归到证据和原理导向的批判性思维。
2.2 技术挑战:生成式AI的“幻觉”问题
当前生成式AI最大的技术瓶颈之一是“幻觉”(Hallucination)。这指的是模型在无法找到确切答案时,会“编造”出看似合理但实际上完全错误的信息。
“幻觉”的根本原因在于LLM的底层工作原理。它本质上是一个概率分布模型,其任务是根据上文预测下一个词(Token)出现的概率。它并不具备真正意义上的“理解”或“事实核查”能力。当训练数据中存在矛盾、过时或稀疏的信息时,模型就容易生成虚构内容。
例如,你问一个LLM关于某个冷门开源库的特定API用法,如果训练数据中没有相关信息,它很可能会“创造”一个不存在的函数名和参数,但其格式和命名风格却非常逼真,极具迷惑性。
2.3 新的信任锚点:建立在技术之上的可验证性
既然不能无条件信任AI,我们就必须建立一套新的、基于技术手段的验证机制。这套机制将成为未来知识消费的“安全带”。信任不再是盲目的,而是有条件的、基于验证过程的。未来的信息消费者,需要像代码审查员一样,对AI生成的内容进行严格的“Review”。
💡 三、技术基石:构建AI生成内容的可信验证体系

应对AI“幻觉”的挑战,不能仅靠用户提高警惕,更需要从技术架构层面构建一套完整的可信验证体系。这套体系将成为未来AI应用不可或缺的基础设施。
3.1 核心技术栈:RAG与知识图谱
目前,业界正在积极探索多种技术来增强AI生成内容的事实准确性,其中最主流的技术之一是检索增强生成(Retrieval-Augmented Generation, RAG)。
RAG的核心思想是,在AI生成答案之前,先从一个可信的、最新的知识库中检索相关信息,然后将这些信息作为上下文(Context)一并提供给LLM。这样,LLM的回答就被“锚定”在了这些可靠的资料上,而不是任其自由发挥。
RAG的工作流程可以简化为以下步骤:
-
用户提问(Query):用户输入一个问题。
-
信息检索(Retrieve):系统将问题向量化,在向量数据库(如Pinecone, Weaviate)中搜索最相关的文档片段。这个数据库中的内容是预先加载的可信数据源(如公司内部文档、最新的技术手册等)。
-
上下文增强(Augment):将检索到的文档片段与用户的原始问题拼接成一个新的、更丰富的Prompt。
-
答案生成(Generate):将这个增强后的Prompt发送给LLM,生成最终答案。
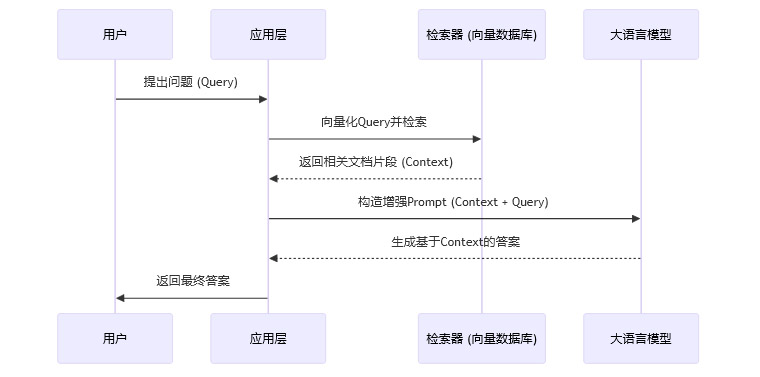
除了RAG,**知识图谱(Knowledge Graph)**也扮演着重要角色。知识图谱以结构化的方式(实体-关系-实体)存储事实信息,可以作为AI进行事实交叉验证的“真值表”。当AI生成一个陈述时,可以查询知识图谱,验证其中的实体和关系是否真实存在。
3.2 工作流再造:人机协同的验证闭环
技术无法解决所有问题,最终的判断仍需人类专家介入。未来的知识工作流将是一个紧密的人机协同闭环。
-
AI生成(Generation):AI快速生成内容的初稿。
-
自动化校验(Automated Verification):系统利用RAG、知识图谱、多源数据比对等技术,对内容进行初步的事实核查,并标记出可疑或无法验证的部分。
-
人类专家审查(Human-in-the-Loop):人类专家重点审查被标记的部分,并对内容的逻辑、价值和适用性进行高阶判断。
-
反馈与迭代(Feedback Loop):专家的修正和反馈被系统记录,用于优化未来的AI生成和验证模型。
这个闭环确保了效率与质量的平衡,让AI负责广度(80%的常规工作),让人类负责深度(20%的关键决策)。
3.3 未来基础设施:可追溯与引用系统
为了实现彻底的可验证性,我们需要为AI生成的内容建立一套类似“Git”的版本控制和溯源系统。
-
内容溯源:每一条AI生成的信息,都应能追溯到其所依据的原始数据源。这要求在生成过程中保留详细的引用链。
-
内容标识:通过数字水印等技术,明确标识出内容是由AI生成的,帮助用户建立合理的期望值。
-
可信知识库:企业和社区需要维护自己的可信知识库,作为RAG等技术的数据基础,确保AI的“思考”素材是高质量的。
💡 四、交互革命:自然语言成为新的通用编程接口
黄仁勋的另一个重要观点是,AI将彻底改变人机交互的方式,使得自然语言成为新的“编程语言”。这不仅是用户体验的提升,更是对软件开发和技术使用门槛的颠覆。
4.1 “自我教学”的工具范式
以ChatGPT为代表的AI工具,展现了一种前所未有的特性,工具本身可以用自然语言教会你如何使用它。
在传统软件时代,学习一个新工具的路径是:阅读静态文档 -> 观看视频教程 -> 论坛提问 -> 反复试错
这是一个漫长且低效的过程。而现在,你可以直接问ChatGPT:“我是一个Python初学者,请教我如何用Pandas库分析一个CSV文件,并找出销售额最高的前三个产品。请给出完整的代码和每一步的解释。”
AI将根据你的背景和需求,生成一个动态的、个性化的、可交互的教程。使用说明从“静态文档”变成了“动态对话式指南”,这极大地降低了新技术的学习曲线。
4.2 自然语言编程(Natural Language Programming)
“自然语言成为编程语言”的背后,是一个复杂的技术栈在支撑。其核心是将非结构化的人类语言,精确地翻译为结构化的、机器可执行的指令。
|
层次 |
技术实现 |
作用 |
|---|---|---|
|
意图理解 |
LLM的语义分析能力 |
准确捕捉用户用自然语言表达的真实需求,即使描述模糊或不完整。 |
|
任务拆解 |
CoT (Chain-of-Thought), ReAct |
将一个复杂任务分解为一系列可执行的子步骤。 |
|
代码/API生成 |
Code LLMs (如Codex) |
将每个子步骤翻译成具体的Python代码、SQL查询或API调用。 |
|
执行与反馈 |
Code Interpreter, API集成 |
执行生成的代码或调用,并将结果返回给用户或用于下一步决策。 |
这种模式下,用户的角色从**“代码实现者”转变为“需求描述者”。编程的核心能力,从掌握语法细节,变成了清晰、准确地定义问题和期望结果**。
4.3 打破边界:开发与使用的融合
这一变革最深远的影响是,它彻底打破了软件开发者和软件使用者之间的壁垒。一个懂业务但不懂代码的市场分析师,现在可以通过自然语言直接驱动数据分析工具,完成过去需要数据工程师协助才能完成的工作。
“公民开发者”(Citizen Developer)的概念将不再局限于低代码平台,而是扩展到所有能够用语言清晰表达逻辑的个体。这无疑会释放巨大的生产力,让创新不再是少数技术专家的特权。
💡 五、生态重塑:技术鸿沟弥合与人类价值再定位

当知识生产和技术使用的门槛被大幅降低后,整个社会的技术生态和人才评价体系都将随之重塑。
5.1 语言与技能的双重普惠
技术鸿沟的形成,主要源于两个门槛。
-
语言门槛:绝大多数高质量的技术文档和社区都是以英语为主。
-
技能门槛:掌握编程语言、算法等专业技能需要长期的学习投入。
AI正在同时瓦解这两个壁垒。ChatGPT等工具的多语言能力,让非英语用户也能无障碍地获取全球最新的技术知识。而自然语言编程,则绕过了复杂的编程语法,让用户可以专注于业务逻辑本身。
这种普惠效应,将使得更多来自不同文化和教育背景的人,能够参与到技术创新活动中,极大地丰富整个技术生态的多样性。
5.2 人类角色的演进路径
在AI主导知识生产的时代,人类并非无事可做,而是需要向价值链的更高层级移动。我们的角色将发生以下转变。
|
传统角色 |
演进后的新角色 |
核心价值 |
|---|---|---|
|
内容创作者 |
问题设计者 & 成果审核人 |
提出有价值的问题,定义清晰的目标,对AI的输出进行事实和价值判断。 |
|
初级程序员 |
AI协同开发者 & 系统集成者 |
善用AI生成代码,专注于系统架构、模块集成和复杂调试。 |
|
数据分析师 |
业务洞察师 & 决策顾问 |
利用AI处理海量数据,专注于从结果中提炼商业洞察,为决策提供支持。 |
|
信息检索者 |
批判性思考者 & 信息验证者 |
面对AI提供的海量信息,核心能力是辨别真伪、评估质量、整合观点。 |
人类的价值,正从“执行”转向“规划、设计、与决策”。那些重复性的、有固定模式的脑力劳动,将被AI接管。而那些需要跨领域思考、深刻理解商业场景、进行价值判断和伦理考量的工作,将变得愈发重要。
5.3 新的核心能力栈
未来的职场,对人才的要求将不再是记忆和复述知识,而是应用和验证知识的能力。以下几项能力将成为新的“硬技能”。
-
精准提问(Prompt Engineering):用清晰、无歧义的语言向AI描述复杂需求的能力。
-
批判性思维(Critical Thinking):对AI生成的内容保持审慎,不盲从、不轻信。
-
验证与核查(Verification & Fact-Checking):熟练使用工具和方法,对信息的可靠性进行交叉验证。
-
系统性思考(Systems Thinking):将AI作为系统的一个组件,理解其能力边界,并将其有效地整合到完整的工作流中。
教育体系和个人职业发展规划,都需要围绕这些新的核心能力进行调整。
💡 六、双刃剑效应:AI主导知识生产的风险与治理
任何颠覆性技术都具有两面性。AI主导知识生产在带来巨大机遇的同时,也伴随着不容忽视的风险。
6.1 机遇:生产力跃迁与创新加速
-
效率提升:知识生产和软件开发的效率将实现数量级的提升,极大地缩短创新周期。
-
成本降低:许多过去需要专业团队才能完成的工作,现在个人借助AI即可完成,降低了创新创业的门槛。
-
个性化增强:AI可以为每个人提供量身定制的学习材料、解决方案和内容,实现真正的个性化服务。
6.2 风险:信息污染与认知操纵
-
错误信息规模化传播:如果不对AI生成的内容进行有效监管,错误的、带有偏见的信息可能会以前所未有的速度和规模传播,造成“信息污染”。
-
权威感滥用:AI生成的内容往往语言流畅、结构完整,容易给人一种“权威”的错觉,可能被用于认知操纵或诈骗。
-
认知负担加重:信息过载将达到新的顶峰,用户需要在海量AI生成的内容中进行筛选和验证,认知负担不降反升。
-
思维能力退化:过度依赖AI可能导致人类自身的批判性思维和独立解决问题能力的退化。
6.3 治理框架:技术、法规与教育并行
应对这些风险,需要一个多层次的治理框架。
-
技术层面:大力发展上文提到的内容溯源、数字水印、RAG等技术,从源头上增强AI内容的可控性和透明度。
-
法规层面:建立明确的法律法规,界定AI生成内容的责任主体。对于利用AI进行恶意造谣、诈骗等行为,必须予以严厉打击。
-
教育层面:将AI素养(AI Literacy)纳入国民基础教育体系,培养公众的信息辨别能力和批判性思维,这是应对信息泛滥的最终防线。
结论
黄仁勋“90%新知识由AI合成”的预测,为我们描绘了一个既令人兴奋又充满挑战的未来。这并非终结的预言,而是一个新时代的开端。在这个时代,知识的获取和创造变得前所未有的民主化,但对真实性和可靠性的要求也达到了前所未有的高度。
我们正处在一个关键的转折点。人类的核心竞争力不再是拥有信息,而是驾驭信息的能力。从“亲手完成一切”到“提出高质量问题并审核AI输出”,这一转变要求我们重塑自己的技能树和思维模式。
最终,决定未来的不是AI本身,而是我们如何使用它。学会与AI共舞,将其作为增强我们智慧的强大杠杆,同时建立起坚固的验证和治理体系,这才是我们应对这场技术变革的最佳路径。那些能够主动拥抱变化,并迅速掌握“提问、验证、整合”这一新能力组合的个人和组织,将在即将到来的智能时代中占据先机。
📢💻 【省心锐评】
AI合成知识的浪潮已至,对抗无益。核心挑战从创造内容转向了验证内容。未来,精准提问和批判性验证将是比编码更重要的元技能,是新的数字时代生存指南。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献420条内容
已为社区贡献420条内容

所有评论(0)