NeurIPS 2025 | 让扩散模型“评价”自己:中科院与快手可灵团队提出隐式奖励建模新范式
用 AI 画图总遇到 “差口气” 的情况 —— 明明按指令描述了,生成的图却不符合审美,要么颜色奇怪,要么细节拉胯… 原来问题出在 “偏好优化” 上!中科院自动化所和快手可灵团队的新研究,用 LRM+LPO 直接解决了传统方法的坑,目前该论文已被NeurIPS 2025 录用。
在图像生成领域,偏好优化的目标是让模型更好地符合人类的审美标准。传统的偏好优化方法通常依赖视觉-语言模型(VLMs)作为像素级的奖励模型对生成图像进行打分,并通过强化学习或对比学习方式进行微调。然而,像素级奖励模型应用于步骤级(step-aware)的偏好优化时,其对高噪声图像不鲁邦,导致后续强化学习效果差。
为了解决这些问题,中科院自动化所与快手可灵团队联合提出了一种全新的偏好建模与优化范式——Latent Reward Model(LRM)与Latent Preference Optimization(LPO)。该方法首次系统性地将扩散模型自身作为奖励模型,在带噪隐空间中直接建模人类偏好,并实现了从数据筛选、奖励建模到模型优化的完整流程。相关研究成果已被NeurIPS 2025会议正式接收,相关代码已开源。

论文标题:Diffusion Model as a Noise-Aware Latent Reward Model for Step-Level Preference Optimization
论文链接:https://arxiv.org/abs/2502.01051
代码链接:https://github.com/Kwai-Kolors/LPO/tree/main
一、研究背景
随着 Stable Diffusion、SDXL 等模型的广泛应用,如何使其生成结果更符合人类审美与语义偏好,成为图像生成研究的关键方向。当前主流方法主要依赖像素级奖励模型(Pixel-level Reward Models, PRMs),如 CLIP、PickScore 等,通过打分机制引导模型优化。
然而,这类方法在步骤级偏好优化(step-level preference optimization)中存在以下问题:
1. 复杂推理链路:每一步都需还原图像,涉及扩散逆过程与 VAE 解码,计算开销大;
2. 高噪声不兼容:在大时间步(timestep)下,图像高度模糊,PRMs 难以准确评估;
3. 缺乏时间感知:PRMs 通常不感知 timestep,难以建模不同阶段的偏好差异。
二、核心思路
本文提出一个关键问题:是否存在一种模型,能直接在带噪隐空间中建模人类偏好,同时具备良好的时间感知与噪声鲁棒性?
答案是:扩散模型本身。扩散模型本身就具备建模偏好的潜力,可以使用扩散模型自己评价自己!
本文提出的核心洞见是:扩散模型本身就具备建模偏好的潜力。它们在预训练过程中已经学习到了丰富的文本-图像对齐能力,能够直接处理带噪隐变量,不需要进行VAE的解码。并且扩散模型对不同时间步的噪声强度具有天然敏感性。因此,作者提出将扩散模型“改造”为一个噪声感知的隐式奖励模型(LRM),在隐空间中预测图像对的偏好关系,从而规避传统像素级方法的种种限制。

三、方法框架
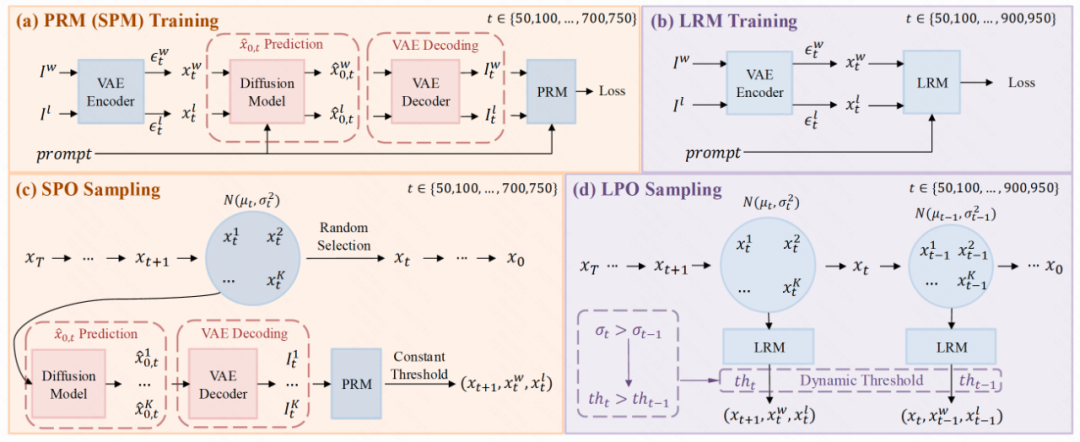
1. Latent Reward Model(LRM):隐式奖励建模
LRM 利用扩散模型的 U-Net 或 DiT 结构提取视觉特征,结合文本编码器的语义信息,构建图文联合表示。为了增强模型对文本-图像对齐的关注,作者还引入了视觉特征增强模块(VFE),通过无分类器引导机制强化文本相关特征的表达。最终,LRM 在带噪隐空间中直接输出偏好分数,实现对图像对的排序与评估。
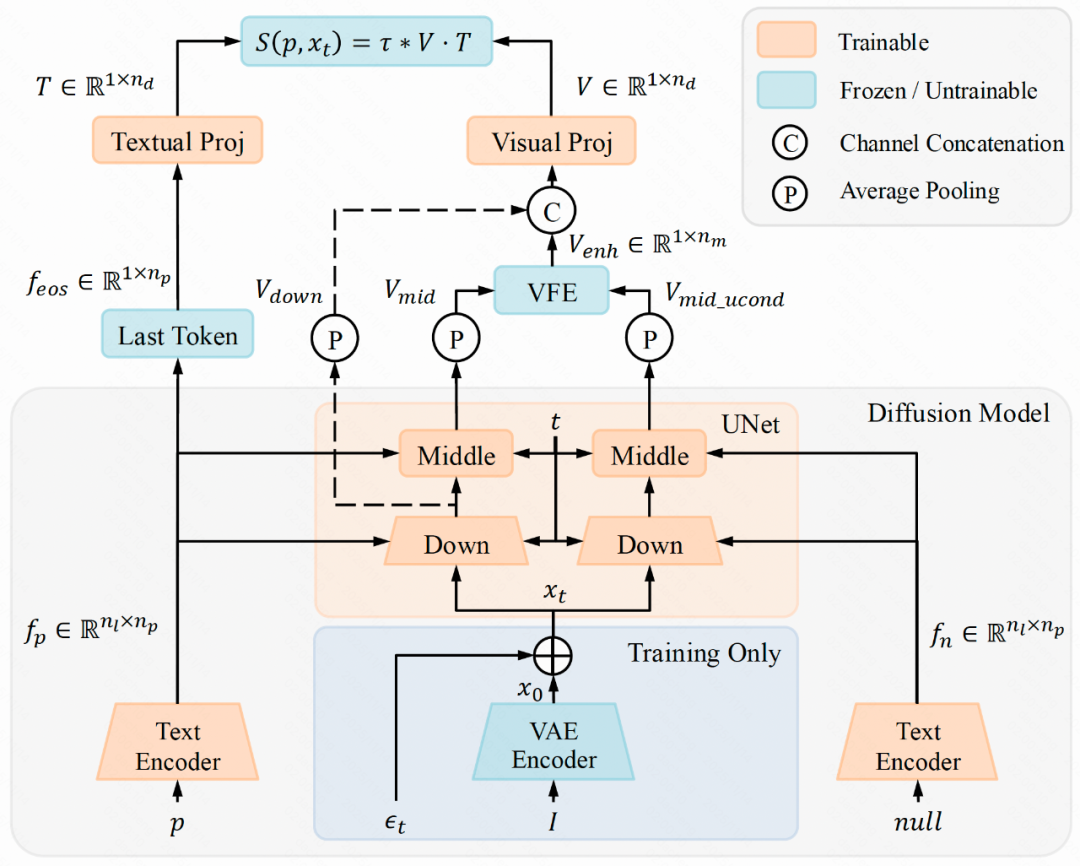
LRM计算文本特征和图像特征的点积作为最终奖励,使用Bradley-Terry (BT)损失进行训练 。
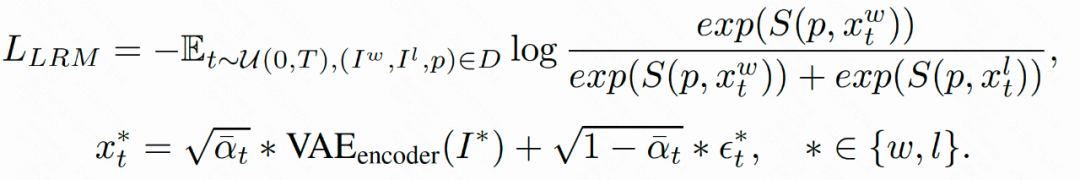
2. Multi-Preference Consistent Filtering(MPCF):高质量偏好数据筛选
为了训练出更稳健的奖励模型,本论文提出了一种多偏好一致性筛选策略(MPCF),用于从公开数据集中构建高质量的偏好对。以 Pick-a-Pic 数据集为例,原始数据中存在大量“胜出图像在某一方面优于败者,但在其他方面劣于败者”的情况,这种偏好不一致会严重影响模型训练效果。
MPCF 策略从美学评分、CLIP 分数、VQA 分数等多个维度对图像对进行筛选,确保胜出图像在多个关键指标上均优于败者图像。通过这种方式,LRM 能够在训练中获得更一致、更可靠的偏好信号,从而提升其对齐能力与泛化性能。
3. Latent Preference Optimization(LPO):步骤级偏好优化新方法
基于LRM,本论文提出隐空间的逐步偏好优化方法LPO(Latent Preference Optimization),其在扩散模型的隐空间进行在线采样,并利用LRM对样本进行打分和筛选,然后在隐空间对模型进行偏好优化。LPO 可以在整个去噪过程(t ∈ [0, 950])中进行优化,而传统方法如 SPO 仅能覆盖低中噪声段(t ∈ [0, 750]),这进一步体现了 LRM 在高噪声条件下的鲁棒性与适应性。
四、实验结果
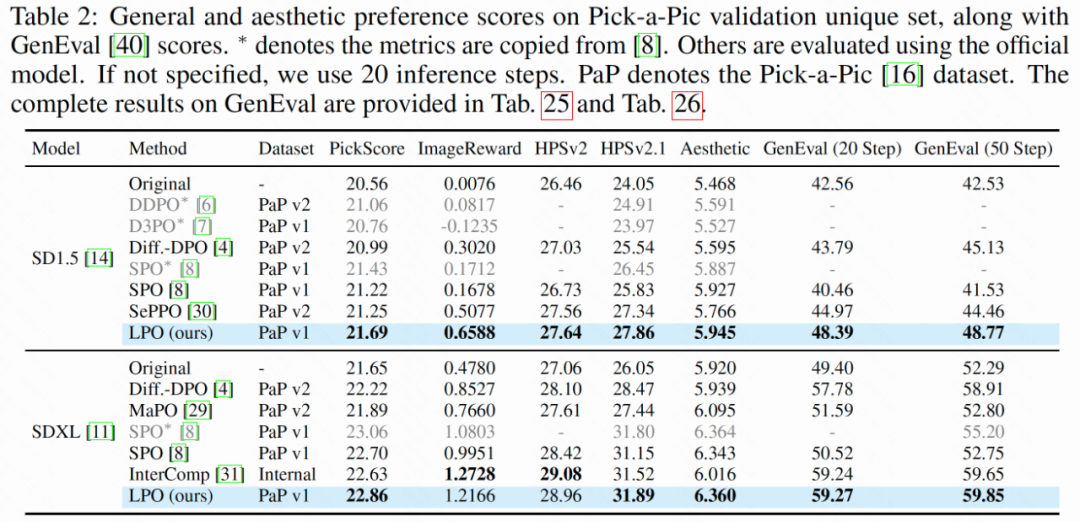
LPO方法在整体人类偏好得分、图文对齐能力、图像美学质量等多个维度均大幅提升模型性能,在 PickScore、ImageReward、HPSv2 和 Aesthetic Score 等指标上均显著优于现有方法。
在更具挑战性的 T2I-CompBench++ 基准上,LPO 在颜色、形状、纹理、空间关系等维度均取得领先成绩,尤其在颜色与纹理生成方面,提升超过 10%。

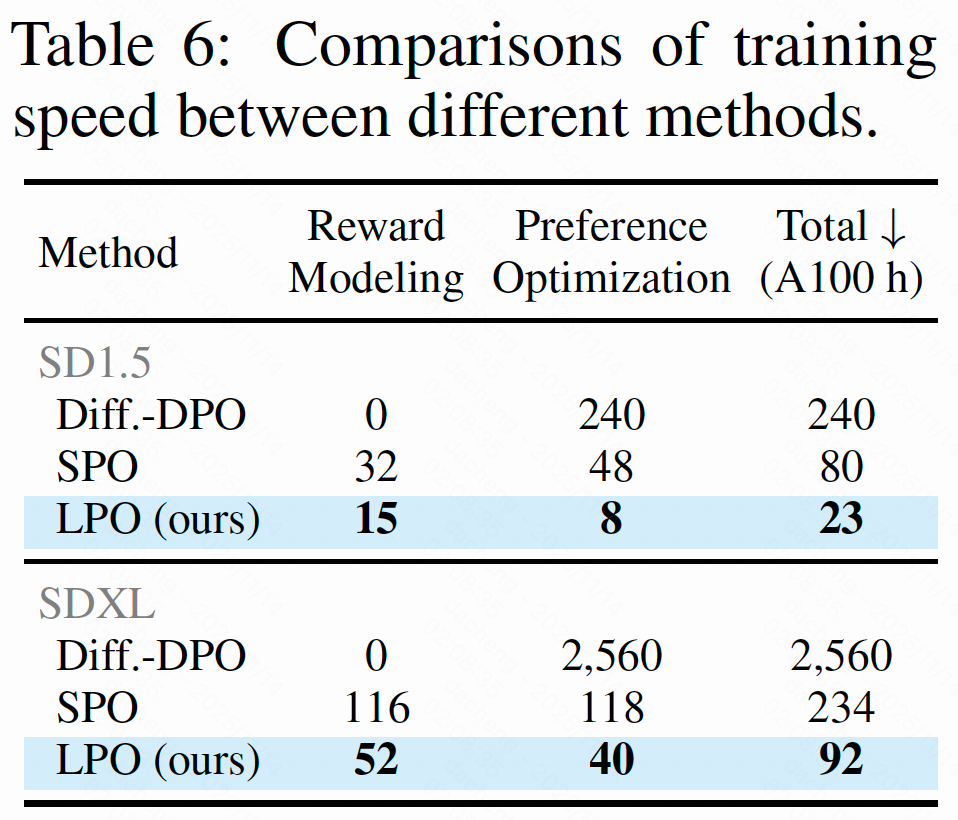
除了性能提升,LPO 在训练效率方面也实现了质的飞跃。以 SDXL 为例,LPO 的总训练时间仅为 92 小时,而传统的 Diffusion-DPO 方法需 2560 小时,SPO 也需 234 小时。LPO 的训练速度分别是两者的28 倍和2.5 倍,极大地降低了模型对齐的计算门槛。
五、总结与展望
本论文提出了LRM 与 LPO方法,首次系统性地将扩散模型自身转化为奖励模型,并在带噪隐空间中完成偏好优化,突破了传统像素级方法的瓶颈。同时,我们将LRM方法应用于不同的强化学习算法,如step-wise的GRPO,并且将LRM和LPO方法拓展至基于DiT架构和Flow matching策略的SD3模型上,均取得了不错的效果。未来,LRM 与 LPO 有望成为图像/视频生成模型对齐的基础工具,推动生成式 AI 迈向更高质量、更强一致性的新阶段。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)