构建下一代AI算力平台:聚合模型API的技术架构解析
摘要:本文探讨聚合模型API算力平台的技术架构设计,分为三个核心层次:接入层通过统一API网关、安全认证和标准化接口降低使用门槛;调度层采用智能资源分配算法实现负载均衡、优先级管理和弹性伸缩;模型层则专注于版本控制、灰度发布和热加载机制。这三个层次的协同设计共同构成了平台的技术底座,能够有效整合分散的算力资源,为企业提供高效稳定的AI模型服务,推动AI技术的广泛应用。
随着大模型技术的快速发展,企业对高效、稳定且易用的模型API算力平台需求日益迫切。一个现代化的聚合模型API算力平台,其核心价值在于将分散的算力资源、多样的模型能力和复杂的调用流程,通过标准化的技术架构整合为统一、可靠的服务。本文将深入解析此类平台的关键技术架构,涵盖接入层、调度层与模型层的核心设计。
一、接入层:标准化接口设计
接入层是平台与外部开发者交互的第一道门户,其设计的核心目标是降低使用门槛与保障通信安全。
1. 统一API网关
平台通过一个统一的API网关对外提供服务,所有请求首先经过此网关。网关负责协议转换、请求路由、身份认证与限流。典型的做法是采用RESTful API作为标准接口,部分对延迟敏感的场景可辅以gRPC或WebSocket。接口设计遵循OpenAPI规范,确保文档与实现的一致性,并自动生成多语言SDK,极大简化开发者的集成工作。
2. 认证与安全机制
安全是接入层的基石。平台普遍采用基于Token(如JWT)或API Key的认证方式。每次请求需携带密钥,网关会验证其有效性、权限及配额。此外,通过HTTPS加密传输、请求签名防篡改、IP白名单等手段,构建多层次的安全防护体系。
3. 请求与响应标准化
为兼容不同的下游模型,接入层需要对请求和响应进行标准化封装。例如,将用户输入的文本、图像等统一封装为特定的消息格式(如类似OpenAI的ChatCompletion格式)。同时,响应也被标准化,包含统一的状态码、业务数据及结构化错误信息,确保开发者获得一致的体验。
二、调度层:智能资源分配算法
调度层是平台的“智能中枢”,其核心任务是在多租户、多模型、异构算力的复杂环境下,实现资源的高效、公平分配,并保障服务的稳定性与低延迟。
1. 资源感知与负载均衡
调度器实时监控所有计算节点(如GPU服务器)的资源状态,包括显存使用率、GPU利用率、网络IO等。基于这些指标,结合加权最小连接数或一致性哈希等算法,将新到达的推理请求动态分配到最合适的节点上,避免单点过载,实现集群负载的整体均衡。
2. 优先级队列与配额管理
平台需要服务不同优先级的用户(如付费用户与试用用户)。调度层通常实现多级优先级队列。高优先级请求可被优先处理,同时通过令牌桶或漏桶算法对每个用户或应用进行严格的QPS(每秒查询率)和并发数限制,确保资源分配的公平性,防止个别用户过度消耗资源影响整体服务。
3. 弹性伸缩与容错
为应对流量波峰波谷,调度层与云原生基础设施深度集成,支持基于预设规则(如CPU/GPU平均利用率)或自定义指标的自动伸缩。当某个计算节点或模型实例发生故障时,调度器能快速检测并将其标记为不可用,将后续请求路由至健康节点,并结合重试机制,实现服务的高可用性。
三、模型层:精细化版本管理机制
模型层直接负责AI模型的加载、推理与维护。模型版本管理是确保服务平滑演进、支持A/B测试和快速回滚的关键。
1. 模型仓库与版本化
所有模型文件(如权重、配置文件、词汇表)均存储在统一的模型仓库中,并使用语义化版本号进行管理。每次模型更新都对应一个唯一版本,仓库记录完整的版本变更历史。这类似于代码的Git管理,为模型的追溯和复用提供了基础。
2. 多版本并行与灰度发布
平台支持同一模型的多个版本同时在线服务。这使得灰度发布成为可能:可以将小部分流量导向新版本模型,在验证其效果和稳定性后,再逐步扩大流量比例。同时,这也方便进行A/B测试,以数据驱动的方式评估不同版本模型的性能差异。
3. 热加载与无缝切换
优秀的模型管理机制支持热加载,即在不重启服务的情况下,将新版本模型加载至内存。结合调度层的路由能力,可以实现用户无感知的模型切换。当新版本出现严重问题时,可以立即将流量全部切回至稳定的旧版本,实现秒级回滚,极大降低了运维风险。
4. 模型缓存与优化
为提升推理效率,平台会对已加载的模型实例进行缓存管理。高频使用的模型会常驻在GPU显存中,以减少重复加载带来的开销。同时,集成模型编译优化工具,在模型加载阶段进行图优化、算子融合等操作,进一步提升推理速度。
总结
构建一个成熟的聚合模型API算力平台,是一项涉及多领域技术的系统工程。通过接入层的标准化设计降低使用门槛,通过调度层的智能算法实现资源最优利用,再通过模型层的精细化管理保障服务稳定与持续迭代,三者协同构成了平台坚实的技术底座。随着AI技术的不断普及,此类平台将成为连接AI能力与行业应用不可或缺的基础设施,推动智能化变革深入各行各业。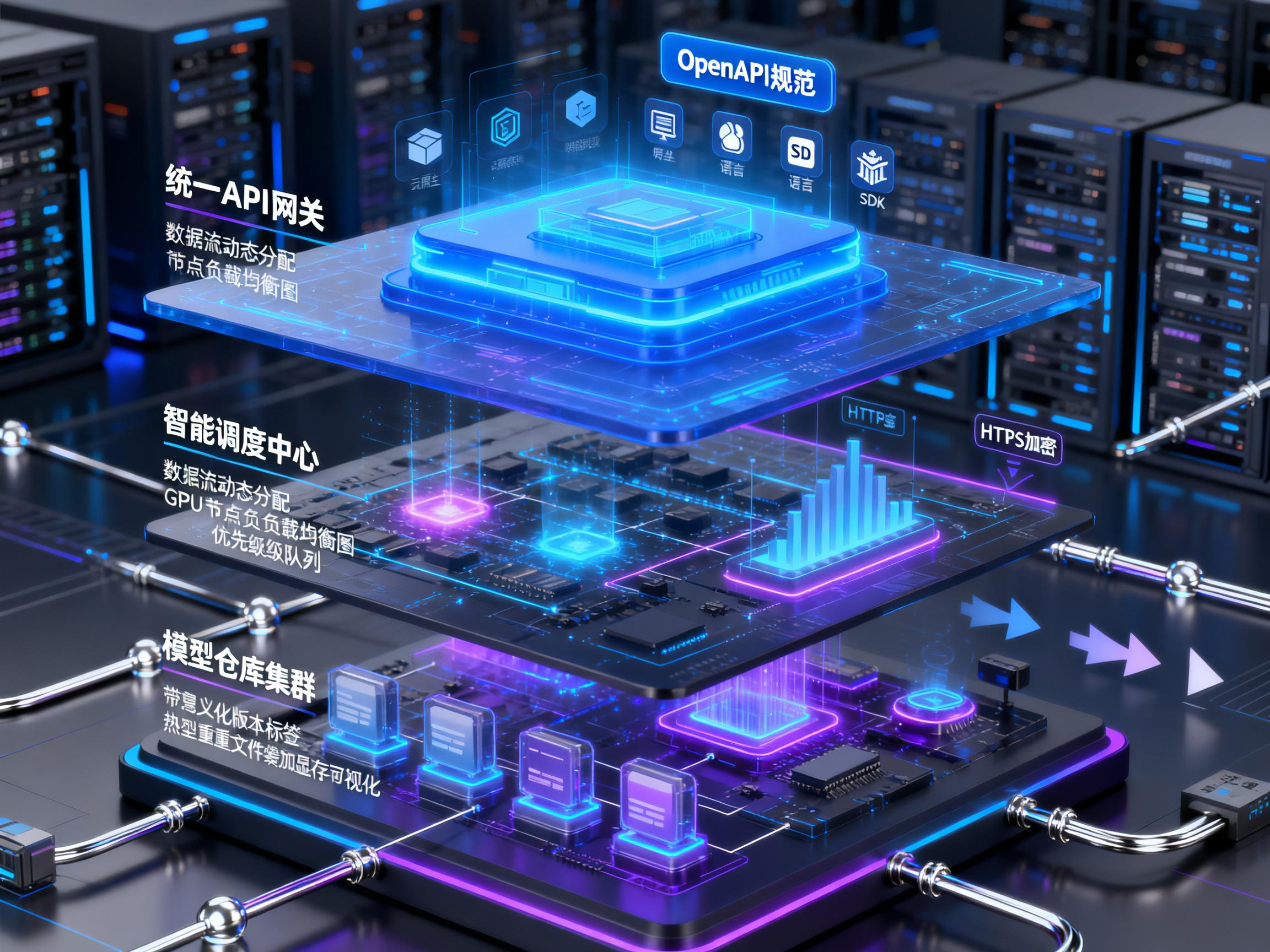

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)