AI时代底层技术链:GPU、云原生与大模型的协同进化全解析
在当今 AI 技术快速演进的背景下,GPU、云原生、大模型与人工智能之间的关系常被误解为孤立或替代,但它们实际上构成了一条从算力到智能的完整技术链。GPU 提供海量并行计算能力,是大模型训练与推理的物理基座;云原生通过容器化与智能调度,实现 GPU 集群的高效管理与弹性供给,使算力像水电一样便捷可用;大模型则基于 Transformer 架构,在海量数据与算力支撑下实现通用认知与智能涌现;而人工智
过去两年,你可能经常看到类似的信息洪流:
-
一台服务器卖 300 万?因为它装了 8 张 H100 GPU。
-
大模型训练一次要烧掉上亿人民币?
-
云计算巨头都在抢「算力调度业务」?
-
各国发布「AI 国家战略」?
看新闻仿佛置身一场术语大混战:
AI、大模型、GPU、云原生,到底在说啥?
是彼此替代?还是互为上下游?能不能一句话讲明白?
如果把当今 AI 技术体系比作一家 米其林三星餐厅:
| 角色 | 对应概念 | 职责类比 | 技术定位 |
|---|---|---|---|
| 最终端的精美菜品 | 人工智能(AI) | 呈现的价值成果 | 应用与愿景 |
| 顶级主厨 | 大模型(LLM) | 掌握核心配方 | 智能核心 |
| 厨房炉具与自动化设备 | GPU | 高效烹饪体系 | 算力底座 |
| 餐厅管理与食材供应系统 | 云原生(Cloud Native) | 流程调度 | 算力管理基础设施 |
一句话总纲:
GPU 提供算力 → 云原生调度算力 → 大模型实现智能 → 人工智能走向真实世界价值落地
它们不是替代,而是“垂直贯通”的技术链条。

下面我们逐层拆解。
01|GPU:深度学习时代的“暴力美学”
GPU = 并行算力的工业化生产线
CPU 像一位逻辑大师,可以思考复杂流程,但一次处理少量任务:
串行强、并行弱
GPU 像一个训练有素的万人方阵:
并行爆炸强 → 执行海量简单位运算(矩阵加乘)
大模型训练的底层本质就是:
矩阵乘法 × 海量数据 × 无限迭代优化
以 GPT 类模型为例:
-
模型参数可达 10,000,000,000,000(10万亿)级别
-
单次训练算力需求为 ExaFLOPS(百亿亿次)级
如果用 CPU:
训练 GPT-4 ≈ 等待几十年
如果用 GPU:
数千张 H100 服务器:几周完成
所以 GPU 被称为:
AI 时代的「石油」
谁掌握 GPU,谁就掌握智能计算的加速度
02|云原生:驯服算力巨兽的“缰绳”
拥有 GPU ≠ 拥有 AI 能力
更像拥有了一群极难管理的猛兽
问题包括:
-
10000 张 GPU 如何协同?
-
GPU 故障如何自动容错?
-
如何根据用户访问变化自动扩缩容?
-
如何让训练和推理像消费水电一样便捷?
这正是**云原生(Cloud Native)**登场的意义。
云原生典型技术组合:
| 能力 | 核心技术 | 解决的问题 |
|---|---|---|
| 资源抽象 | 容器(Docker) | 应用运行环境标准化 |
| 智能调度 | Kubernetes(K8s) | 哪块卡干活?什么时候扩?怎么补位? |
| 微服务架构 | Service Mesh | 复杂业务模块化、自治化 |
| 自动化 DevOps | CI/CD | 更新不宕机,快速迭代 |
一句话总结云原生:
把 GPU 集群变成“有调度、有弹性、有韧性”的超级算力工厂
它的目标就是:
≈「自来水模式算力」
随取随用、省钱省人省心,越大越稳定
03|大模型:从统计学习到“涌现智能”
模型为什么“大”才能“聪明”?
因为更多参数 = 更强表达能力
参数如同神经突触连接,规模跨过某个阈值后会出现:
智能涌现(Emergent Intelligence)
也就是:
你没教它,但它突然就会推理、写代码、写诗、讲笑话。
| 时代 | 技术范式 | 能力 | 瓶颈 |
|---|---|---|---|
| 传统 AI | 规则引擎 | 仅机械执行 | 人写规则,规模受限 |
| 机器学习 | 特征工程 | 特定领域表现强 | 人工特征设计困难 |
| 深度学习 | 神经网络 | 感知能力提升 | 通用理解能力不足 |
| 大模型(LLM) | Transformer | 泛化与生成跃迁 | 算力与数据成本巨大 |
大模型本质是一种:
跨模态知识引擎 + 泛化推理能力
当它接受人类意图后,就能生成:
-
文本、图像、音频、视频
-
软件代码、数学推导
-
商务战略建议
-
科研分析、法律条文草案…
它不仅回答问题,还能代替你完成任务。
04|人工智能:大目标与世界接口
AI 是 顶层愿景与最终价值出口
它不是技术,而是:
改变产业与社会的「智能基础设施」
AI 应用涵盖:
-
医疗诊断与药物发现
-
自动驾驶
-
金融风控
-
教育辅学
-
公检法应急指挥
-
工业检测与预测性运维
-
内容创作、虚拟助理、机器人…
AI 无处不在,它正在变成:
像电力一样的通用生产力(General Purpose Technology)
而大模型是当下最有效率的 AI 实现方式,但不是全部。
AI 仍包括:
-
强化学习
-
多智能体体系(Agents)
-
具身智能(Embodied AI)
-
知识推理与符号逻辑
未来 AI 不只是“会说话的模型”,而是能行动的智能体。
技术链路全景图
用一句最清晰的话总结:
想要 AI 改变世界 → 需要大模型
想要大模型跑起来 → 需要海量 GPU
想要 GPU 集群不崩溃且不烧钱 → 需要云原生
形成如下技术金字塔结构:
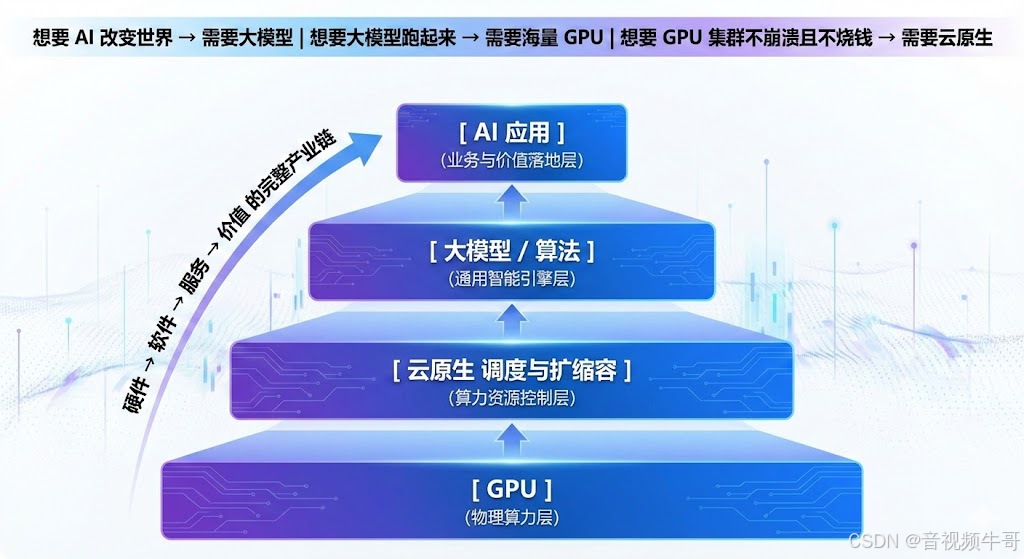
它们不是并列概念,而是:
从硬件 → 软件 → 服务 → 价值 的完整产业链
为什么这条链会成为国家与巨头竞争焦点?
因为每一层都体现国家竞争力与产业控制力:
| 层级 | 决定因素 | 产业战略价值 |
|---|---|---|
| GPU | 制造能力、供应链、安全可控 | 卡脖子最严重、最稀缺资源 |
| 云原生 | 算力调度能力、规模管理 | 算力是否可成为基础设施 |
| 大模型 | 算法积累与数据规模 | 通用智能竞争壁垒 |
| AI 应用 | 行业落地与生态 | 真实生产力转化 |
一句话:
谁掌握 GPU、云原生和大模型,谁就能定义 AI 的未来
结语:时代的底层规律
当我们仰望人工智能的璀璨时,别忘了它脚下的地基:
-
GPU 承担算力之力
-
云原生 赋予调度之序
-
大模型 凝聚知识之智
-
AI 应用 承载落地之业
它们共同构成了这个时代最重要的底层公式:
算力 → 模型 → 服务 → 价值
未来十年,最激烈的竞争,不是某个应用火爆与否,而是谁能更快、更稳、更经济地把这条链条跑通。
当智能成为新的基础设施
当算力像水电一样随取随用
当模型能力像操作系统一样普世
那将不是工具升级
而是生产方式的跃迁。
技术的演进从来不是炫技
而是推动世界向前的力量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)