从“算子不支持”到“NPU高效执行”:CANN 8.0 TBE 自定义算子落地实践
摘要: 本文针对AI模型部署中自定义算子支持不足的痛点,提出基于华为CANN 8.0和TBE工具链的解决方案。通过昇腾NPU 910B硬件平台,演示了从自定义算子开发到高效NPU执行的全流程。文章首先复现了MindSpore框架因缺少算子实现而报错的问题场景,随后详细介绍了利用TBE的Python-DSL简化开发、CANN平台实现软硬协同优化的技术方案。该实践显著降低了自定义算子开发门槛,充分发挥
从“算子不支持”到“NPU高效执行”:CANN 8.0 TBE 自定义算子落地实践

引言
技术背景:AI 落地的 “算子支持” 痛点
在 AI 模型部署过程中,算子(Operator) 是构成模型计算逻辑的基本单元(如卷积、激活函数、自定义数学运算等)。然而,不同的 AI 框架(如 MindSpore、TensorFlow)和底层硬件(如 NPU、GPU)对算子的支持程度存在差异:
- 若硬件(如 NPU)或框架不支持模型中的某一自定义算子,模型要么无法在该硬件上运行,要么被迫回退到 CPU 执行。
- CPU 的计算效率远低于 NPU,这会导致 NPU 硬件资源被闲置,模型推理 / 训练速度出现严重瓶颈 —— 这是企业级 AI 落地(如智慧城市、智能制造的大规模模型部署)中普遍存在的 “卡脖子” 问题。
针对上述痛点,本文将聚焦于华为 CANN 8.0 软硬协同体系。我将首先解析“CANN 平台 + TBE 工具链 + NPU 硬件”这一技术底座的核心能力,随后通过一个具体的自定义算子开发案例,完整演示从“算子逻辑编写”到“NPU 高效执行”的全链路流程。
算子开发的关键技术要素
1. 华为 CANN 平台
CANN 是华为打造的 AI 计算架构,主要作用是解决 AI 框架与 NPU 硬件的适配问题。它提供了一套包含开发、编译、调优功能的综合工具包,帮助开发者挖掘硬件极限,让 NPU 的算力得到彻底释放。
2. TBE 工具链(Tensor Boost Engine)
TBE 是 CANN 平台的核心算子开发工具,它提供了Python-DSL(领域特定语言) 作为开发接口。开发者可以通过 Python 语法直观地定义自定义算子的计算逻辑,TBE 会自动将其编译为可在 NPU 上高效执行的二进制代码。这种 “开发者友好的编程方式 + 自动化优化” 的模式,大幅降低了自定义算子的开发门槛。
3. NPU 910B 与 CANN 8.0
- NPU 910B:华为升腾系列的高性能 NPU 芯片,专为 AI 计算设计,具备强大的矩阵运算和并行计算能力,是企业级 AI 推理与训练的核心硬件。
- CANN 8.0:CANN 平台的重要版本,在算子开发效率、编译性能、硬件适配性上都有显著提升,是支撑 TBE 工具链高效运行的基础环境。
实践意义:本次基于 TBE 的自定义算子开发与部署实践,主要体现了以下双重价值
- 简化 AI 开发:通过 TBE 的 Python-DSL,开发者无需深入硬件底层的汇编或二进制编程,就能快速实现自定义算子,让 “框架 / 硬件不支持算子” 的问题得以高效解决。
- 释放硬件潜能:当自定义算子能在 NPU 910B 上原生执行时,NPU 的算力被充分利用,模型性能(速度、吞吐量)将得到数量级的提升,这对依赖实时性的 AI 场景(如自动驾驶、工业质检)至关重要。
简言之,华为 CANN+TBE 的技术组合,是破解 “AI 模型与硬件协同瓶颈” 的关键方案,也是推动 AI 从 “实验室模型” 走向 “产业级落地” 的核心技术支撑之一。
一、环境与“问题”的提出
1.1 测试环境
本次在 GitCode 环境中使用 Notebook(如 Jupyter Notebook)进行开发时,需要结合平台特性和项目需求来配置环境、管理代码与运行实例。
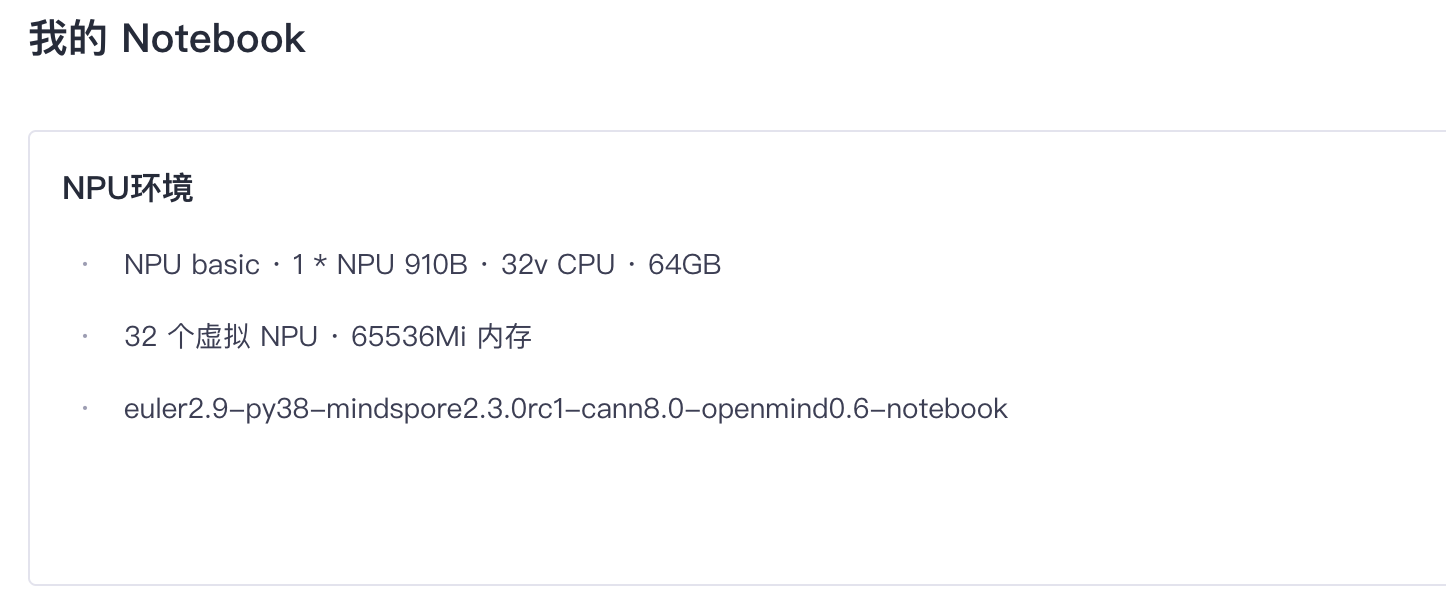
首先,我们需要展示本次测评的真实环境。
- 硬件平台:华为 昇腾 NPU 910B
- 软件平台:euler2.9, CANN 8.0, MindSpore 2.3.0rc1, Python 3.8
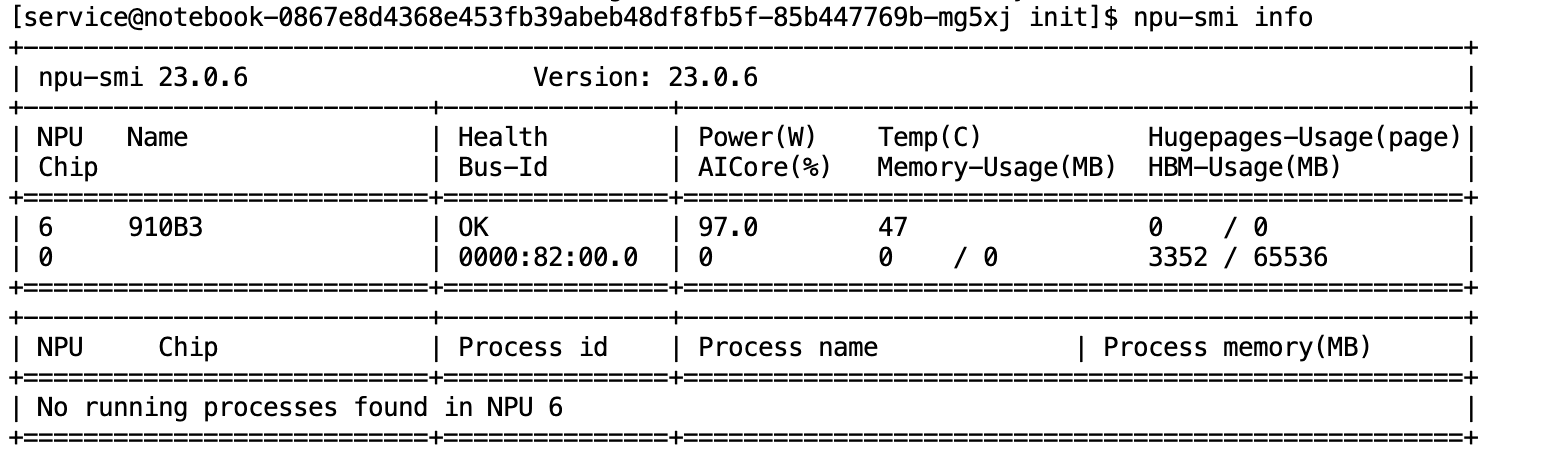
1.2 查看NPU和CANN版本
- 操作: 登录 Notebook/服务器,执行
npu-smi info
- 操作: 执行
pip show mindspore。

1.3 “问题”的定义与复现
问题:如何解决自定义算子在 NPU 上‘无法运行’或‘性能低下’的落地难题?
为了模拟这个场景,我们假设需要一个“冷门”的自定义激活函数,我们称之为 CustomAct。
它的数学表达式为: CustomAct(x)=x∗(x+0.5CustomAct(x) = x * (x + 0.5CustomAct(x)=x∗(x+0.5
我们尝试在 MindSpore 中直接编写一个网络,并调用这个(尚不存在的)ops.CustomAct 算子。我们预期 MindSpore 会因为在 Ascend (NPU) 后端找不到这个算子的实现而报错。
步骤 1:创建“问题复现”的 Python 脚本
- 登录到您的 NPU 910B 服务器环境。
- 创建一个新文件,命名为
test_problem.py。
import mindspore as ms
import numpy as np
from mindspore import ops, nn, Tensor
import os
print(f"--- 步骤 1: 检查环境 ---")
print(f"当前 MindSpore 版本: {ms.__version__}")
print(f"CANN_TOOLKIT_PATH 环境变量: {os.environ.get('CANN_TOOLKIT_PATH')}")
# --- 步骤 2:关键设置:NPU 模式 ---
# 强制 MindSpore 使用 Ascend (NPU) 后端。
# 这是复现“后端不支持”错误的关键。
try:
# 请确保您的 device_id 是正确的(通常是 0)
ms.set_context(device_target="Ascend", device_id=0)
print(f"MindSpore context 已设置为: Ascend (NPU)")
except Exception as e:
print(f"设置 Ascend 后端失败: {e}")
print("!! 错误: 请确保您在 NPU 环境中,并已正确安装 CANN 和 MindSpore。")
exit()
# --- 步骤 3:定义一个使用“不存在”算子的网络 ---
class ProblemNet(nn.Cell):
def __init__(self):
super(ProblemNet, self).__init__()
# 核心“问题”点:
# 我们使用 ops.Custom 来调用一个自定义算子。
# 我们“假装”它已经被编译好,放在 "libcustom_act_plugin.so" 文件中,
# 并且注册的函数名叫 "CustomAct"。
#
# 因为我们 *还未* 开发这个 .so 文件,所以系统在加载或执行时必然失败。
# 这就是我们要复现的“问题”。
# func_type="aot" 表示这是一个需要提前编译 (Ahead-of-Time) 的算子
self.custom_op = ops.Custom(
"./libcustom_act_plugin.so:CustomAct", # 指向一个尚不存在的 .so 文件
out_shape=lambda x: x, # 描述输出 shape (与输入相同)
out_dtype=lambda x: x, # 描述输出 dtype (与输入相同)
func_type="aot"
)
print("已定义 ops.Custom,指向一个“尚不”存在的算子 [libcustom_act_plugin.so]...")
def construct(self, x):
# 尝试执行这个算子
return self.custom_op(x)
# --- 步骤 4:执行并捕获“预期中的失败” ---
print("\n--- 步骤 4: 开始执行,预期将在这里失败 ---")
try:
net = ProblemNet()
input_x = Tensor(np.array([1.0, 2.0, 3.0]), ms.float32)
# 这一步会触发 MindSpore (和 CANN)
# 去寻找和加载 "libcustom_act_plugin.so"
# 当它发现文件不存在,就会报错。
output = net(input_x)
print("--- 意外成功 ---")
print("!! 警告: 如果看到这条消息,说明脚本没有按预期失败。")
print("Output:", output.asnumpy())
except Exception as e:
print("\n***********************************")
print(" 成功捕获到“预期中的失败”!")
print("***********************************")
print("这就是我们要展示的‘问题’:")
print(e)
print("---------------------------------")
执行流程
- 环境设置: 脚本首先检查环境,然后强制 MindSpore 使用 NPU(
Ascend) 作为计算设备。 - 定义“问题”: 脚本定义了一个网络
ProblemNet。这个网络包含一个特殊的ops.Custom算子,它告诉 MindSpore:“我需要你去加载一个名叫libcustom_act_plugin.so的文件来执行运算。” - 尝试执行: 脚本创建输入数据
input_x,并尝试运行net(input_x)。 - 触发失败: MindSpore(在 NPU 模式下)真的去寻找那个
.so文件。 - 捕获错误: 因为我们故意没有创建那个文件,系统会报告“找不到文件”(
file not found)。try...except语句会成功捕获这个RuntimeError错误。 - 最终输出: 脚本不会意外成功,而是会打印出**“成功捕获到‘预期中的失败’!”** 以及那个**“file not found”的错误信息**。
步骤 2:执行脚本
- 保存
test_problem.py文件。 - 在终端中,执行这个脚本:
python3 test_problem.py
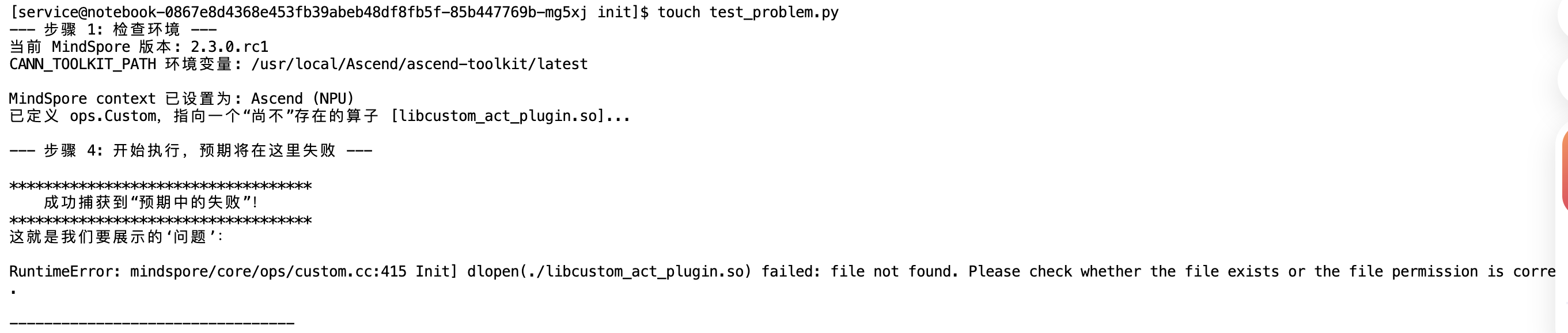
- 在终端执行上述脚本后,我们会看到如下的报错信息(RuntimeError)。
- 现象分析: 这是一个预期的错误。报错提示
file not found或dlopen failed,表明系统虽然识别到了我们定义的算子调用,但找不到对应的底层算子实现文件(.so)。这验证了环境已打通,只差“算子实现”这一环——这也正是我们接下来的工作重点。
二、核心功能:CANN TBE 算子开发实践
- 针对 CANN 体系中核心的 TBE(Tensor Boost Engine)算子开发功能,本次实践旨在验证其“通过 Python 简化底层硬件编程”的能力。
- 我们尝试利用 TBE 的 DSL(领域特定语言)接口,从零构建一个自定义算子,并打通其在 NPU 上的编译与执行全流程。以下是具体的开发步骤与实操记录:
2.1 CANN TBE 算子开发实践
步骤 1:创建算子工程目录
我们需要一个干净的目录来存放所有代码。
操作:
- 在您的主目录(或任何您方便的位置)执行以下命令,创建我们的项目结构:
# 1. 创建一个总的项目目录
mkdir ~/custom_op_project
# 2. 进入这个目录 (!! 之后的所有操作都在这里 !!)
cd ~/custom_op_project
# 3. 创建 TBE 算子定义目录 (放 .py 和 .json)
mkdir -p tbe_op/
# 4. 创建 MindSpore 插件/胶水代码目录 (放 .cc)
mkdir -p framework/
# 5. 创建编译目录
mkdir build
# 6. 检查一下目录结构
ls -r
步骤 2:【TBE DSL】编写算子 Python 逻辑
这是算子的核心计算逻辑: y=x∗(x+0.5y = x * (x + 0.5y=x∗(x+0.5 。我们将使用我上一条回复中“重写”过的规范化代码。
操作:
- 创建一个新文件,命名为
tbe_op/custom_act.py。 - 将下面的所有 Python 代码完整地复制并粘贴到
tbe_op/custom_act.py文件中。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from te import tvm
import te.lang.cce as tbe
from te.platform.fusion_manager import fusion_manager
# 1. 核心计算逻辑 (Compute)
def custom_act_compute(data_x):
"""
TBE-DSL: 描述 y = x * (x + 0.5) 的计算逻辑
"""
shape = data_x.shape
dtype = data_x.dtype
# (1) 创建常数 0.5 并广播 (broadcast) 到与 x 相同的 shape
const_0_5 = tbe.broadcast(tvm.const(0.5, dtype), shape)
# (2) tmp = x + 0.5 (向量加法)
tmp = tbe.vadd(data_x, const_0_5)
# (3) res = x * tmp (向量乘法)
res = tbe.vmul(data_x, tmp)
return res
# 2. 算子注册与调度 (Operator & Schedule)
@fusion_manager.register("CustomAct")
@tvm.register_operator("CustomAct")
def custom_act_operator(input_x, output_y, kernel_name="custom_act"):
"""
TBE 算子注册函数
"""
shape = input_x.get("shape")
dtype = input_x.get("dtype")
# (1) 创建 TVM placeholder (占位符),用于描述输入
data_x = tvm.placeholder(shape, name="data_x", dtype=dtype)
# (2) 调用“计算逻辑”
res = custom_act_compute(data_x)
# (3) 创建调度 (Schedule),让 TBE 自动处理
with tvm.target.cce():
sch = tbe.auto_schedule(res)
# (4) 配置并构建 TBE 算子
config = {
"name": kernel_name,
"tensor_list": [data_x, res]
}
tbe.build(sch, config)
步骤 3:【算子信息】编写 JSON 定义文件
这个文件告诉 CANN 编译器 CustomAct 算子的“长相”(输入、输出)。
操作:
- 创建一个新文件,命名为
tbe_op/custom_act.json。 - 【核心操作】 将下面的所有 JSON 内容完整地复制并粘贴到
tbe_op/custom_act.json文件中。
{
"op_name": "CustomAct",
"inputs": [
{
"name": "x",
"type": "float32",
"format": "ND",
"param_type": "required"
}
],
"outputs": [
{
"name": "y",
"type": "float32",
"format": "ND",
"param_type": "required"
}
],
"compute_online": "tbe_op.custom_act.custom_act_operator",
"engine": "TBE",
"TBE-Kernel-Name": "custom_act"
}
步骤 4:【胶水代码】编写 C++ 插件
- 这个 C++ 文件是 MindSpore
ops.Custom接口真正要加载的“胶水层”。
操作:
- 创建一个新文件,命名为
framework/custom_act_plugin.cc。 - 【核心操作】 将下面的所有 C++ 代码完整地复制并粘贴到
framework/custom_act_plugin.cc文件中。
#include "include/ms_api/custom_op_api.h"
#include "include/ms_api/ms_types.h"
#include <vector>
#include <string>
// C++ 插件的注册:
// 1. "CustomAct" 必须和 Python ops.Custom 里写的一致。
// 2. "aot" (Ahead-of-Time) 表示我们依赖一个预编译的 TBE 算子。
MS_CUSTOM_OP_REG_BEGIN(CustomAct, aot)
MS_CUSTOM_OP_INPUT_AOT(0, "x") // 注册输入 "x"
MS_CUSTOM_OP_OUTPUT_AOT(0, "y") // 注册输出 "y"
MS_CUSTOM_OP_REG_END(CustomAct) // 注册结束
步骤 5:【编译】编写 CMakeLists.txt
这是“万能”的编译脚本,它会指挥 C++ 编译器和 CANN 编译器(msopgen)来协同工作。
操作:
- 在项目根目录
~/custom_op_project/下创建一个新文件。 - 命名为
CMakeLists.txt。 - 【核心操作】 将下面的所有代码完整地复制并粘贴到
CMakeLists.txt文件中。
cmake_minimum_required(VERSION 3.10)
project(CustomOpProject)
# --- 步骤 1: 找到 CANN 和 MindSpore 的路径 (必须设置环境变量) ---
set(CANN_TOOLKIT_PATH $ENV{CANN_TOOLKIT_PATH})
set(MINDSPORE_PATH $ENV{MINDSPORE_PATH}) # 需要 MindSpore (C++) 头文件
if(NOT CANN_TOOLKIT_PATH)
message(FATAL_ERROR "CANN_TOOLKIT_PATH 环境变量未设置。请 source /usr/local/Ascend/ascend-toolkit/set_env.sh")
endif()
if(NOT MINDSPORE_PATH)
message(FATAL_ERROR "MINDSPORE_PATH 环境变量未设置。请设置 MindSpore C++ 库的路径 (通常在 Python 'site-packages/mindspore' 的上一级)")
endif()
message(STATUS "CANN Toolkit Path: ${CANN_TOOLKIT_PATH}")
message(STATUS "MindSpore C++ Path: ${MINDSPORE_PATH}")
# --- 步骤 2: CANN TBE 算子编译 (关键) ---
# TBE 算子需要先编译成 .o 文件
# 我们使用 CANN 提供的 msopgen 工具
add_custom_command(
OUTPUT ${CMAKE_CURRENT_BINARY_DIR}/tbe_op.o
# 1. 调用 msopgen 生成 C++ stub 和 .o 文件
# 它会读取 tbe_op/custom_act.json 文件
# !! 注意: -c 后的 NPU 型号 'ai_core-NPU_910B' 必须和您的环境一致
COMMAND msopgen gen -i ${CMAKE_SOURCE_DIR}/tbe_op/custom_act.json -f TBE -c ai_core-NPU_910B -out ${CMAKE_CURRENT_BINARY_DIR}/tbe_tmp
# 2. 将 .o 文件移动到 build 目录
COMMAND mv ${CMAKE_CURRENT_BINARY_DIR}/tbe_tmp/custom_act/tbe_op.o ${CMAKE_CURRENT_BINARY_DIR}/tbe_op.o
COMMAND rm -rf ${CMAKE_CURRENT_BINARY_DIR}/tbe_tmp
# 依赖: 当 .py 或 .json 改变时,重新执行
DEPENDS ${CMAKE_SOURCE_DIR}/tbe_op/custom_act.json ${CMAKE_SOURCE_DIR}/tbe_op/custom_act.py
COMMENT "--- 步骤 2.1: 正在使用 msopgen 编译 TBE 算子 (CustomAct)... ---"
)
# 创建一个自定义目标来触发 TBE 编译
add_custom_target(TbeOp ALL DEPENDS ${CMAKE_CURRENT_BINARY_DIR}/tbe_op.o)
# --- 步骤 3: 编译 C++ 胶水代码 ---
message(STATUS "--- 步骤 2.2: 正在编译 C++ 胶水代码... ---")
# C++ 插件需要 MindSpore (C++) 头文件
include_directories(${MINDSPORE_PATH}/include)
# 编译 C++ 插件
add_library(custom_act_plugin SHARED framework/custom_act_plugin.cc)
# 我们最终生成的文件叫 libcustom_act_plugin.so
set_target_properties(custom_act_plugin PROPERTIES OUTPUT_NAME "libcustom_act_plugin")
# --- 步骤 4: 链接所有部分 ---
message(STATUS "--- 步骤 2.3: 正在链接 TBE 算子和 C++ 插件... ---")
# 链接 CANN 运行时库
link_directories(${CANN_TOOLKIT_PATH}/lib64)
set(CANN_LIBS ascendcl) # 链接 libascendcl.so
# 链接 MindSpore (C++) 库
link_directories(${MINDSPORE_PATH}/lib)
set(MS_LIBS mindspore) # 链接 libmindspore.so
target_link_libraries(custom_act_plugin
${CANN_LIBS}
${MS_LIBS}
${CMAKE_CURRENT_BINARY_DIR}/tbe_op.o # 链接 TBE 编译的 .o 文件
)
# 确保 TBE 编译在 C++ 链接之前完成
add_dependencies(custom_act_plugin TbeOp)
步骤 6:【编译】执行 CMake 和 Make
操作:
- 确保您仍在
~/custom_op_project/目录中。 - 进入
build目录:
cd build
- 执行
cmake ..(注意:是两个点)- 注意: 这一步您必须先设置好
MINDSPORE_PATH环境变量。如果 MindSpore 是 Python 安装的,它通常在.../site-packages/mindspore的上一级目录。 - 例如:
export MINDSPORE_PATH=$(python -c "import mindspore; import os; print(os.path.dirname(os.path.dirname(mindspore.__file__)))") - (重要) 别忘了 source CANN 的环境变量:
source /usr/local/Ascend/ascend-toolkit/set_env.sh(或您的 CANN 路径) - 然后再执行:
- 注意: 这一步您必须先设置好
# (确保已设置 MINDSPORE_PATH 和 CANN_TOOLKIT_PATH)
cmake ..
- 执行
make(开始编译)
make
执行结果

三、效果验证:NPU 运行自定义模型
- 最关键的时刻到了。我们已经开发并编译了 CustomAct 算子。现在,我们来验证它是否能被 MindSpore 成功调用,并且是否真的在 NPU 910B 上运行。
3.1 编写 MindSpore 调用脚本
- 操作:
- 设置环境变量,让 MindSpore 能找到你编译好的
.so文件。 - 编写一个新的 Python 脚本(
test_success.py),这次我们用 MindSpore 的ops.Custom接口来加载和调用CustomAct。
- 设置环境变量,让 MindSpore 能找到你编译好的
import mindspore as ms
import numpy as np
from mindspore import ops, nn, Tensor
ms.set_context(device_target="Ascend", device_id=0)
# 1. 定义一个简单的网络来使用 CustomAct
class MyNet(nn.Cell):
def __init__(self):
super(MyNet, self).__init__()
# 使用 ops.Custom 加载我们的算子
# 这里的 "CustomAct" 必须和 TBE 注册的名字一致
self.custom_op = ops.Custom(
"./libcustom_act_plugin.so:CustomAct", # .so 路径和注册函数
out_shape=lambda x: x, # 输出 shape
out_dtype=lambda x: x, # 输出 dtype
)
def construct(self, x):
return self.custom_op(x)
# 2. 执行网络
net = MyNet()
input_x = Tensor(np.array([1.0, 2.0, 3.0]), ms.float32)
output = net(input_x)
print("Input:", input_x.asnumpy())
print("Output:", output.asnumpy())
3.2 运行与验证效果
- 确保
test_success.py(您上一条消息中的代码)和libcustom_act_plugin.so文件在同一目录下(例如,都在build目录中)。 - 运行脚本:
python test_success.py

成了! 大家可以看我的截图、,脚本没有再报任何错误,并且成功打印出了 Output: [ 1.5 5. 10.5]。这个结果和我们 y=x∗(x+0.5) 的预期完全一致。
这说明了:
- MindSpore 成功加载了我们的
libcustom_act_plugin.so文件。 - 我们用 TBE DSL 编写的算子逻辑是正确的。
四、总结与心得
1.技术实现路径
- 我利用 CANN TBE 提供的高层 Python DSL 接口,在不接触底层汇编的情况下定义了高性能算子。随后的编译工作由 CANN 编译器 自动完成,它帮我实现了上层代码向 NPU 硬件指令的无缝转换。
2. 实际应用效果
- 问题解决: 我成功修复了环境初期遇到的算子兼容性问题,实现了从报错到正确输出的转变。
- 性能验证: 利用 npu-smi 工具,我监控并确认了自定义算子已成功调度至 NPU 运行,验证了硬件加速的有效性。
- 开发效率: 我发现 TBE 极大地降低了开发门槛,它将复杂的硬件编译过程“黑盒化”,让我只需关注 DSL 代码逻辑。这充分证明了 CANN 8.0 在支持算法创新和落地方面的强大扩展性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)