通义千问qwen_3_4b-fp8.safetensors模型的使用教程及下载地址分享 搭配z-image-turbo快速生图教程
为了搞清它到底是不是真的这么猛,我花了一个晚上把模型拉下来,并塞进自己的 ComfyUI 流程里,顺便搭上最近火得不行的。身为一个常年折腾本地 AI 模型的前端工程师,我一直都在寻找一种既轻量又能跑得飞快的模型方案。下面我就把整个体验、配置方式、模型信息,还有下载方式全部整理出来,方便你们也能轻松复现。的性能,说这玩意解码速度快得离谱,还特别适合做本地生成式工作流。特别是放进绘图管线里的时候,速度
通义千问qwen_3_4b-fp8.safetensors模型的使用教程及下载地址分享
标签:通义千问、本地大模型、Qwen3、ComfyUI生图、AI绘图、z-image-turbo、FP8模型、模型分享、AI加速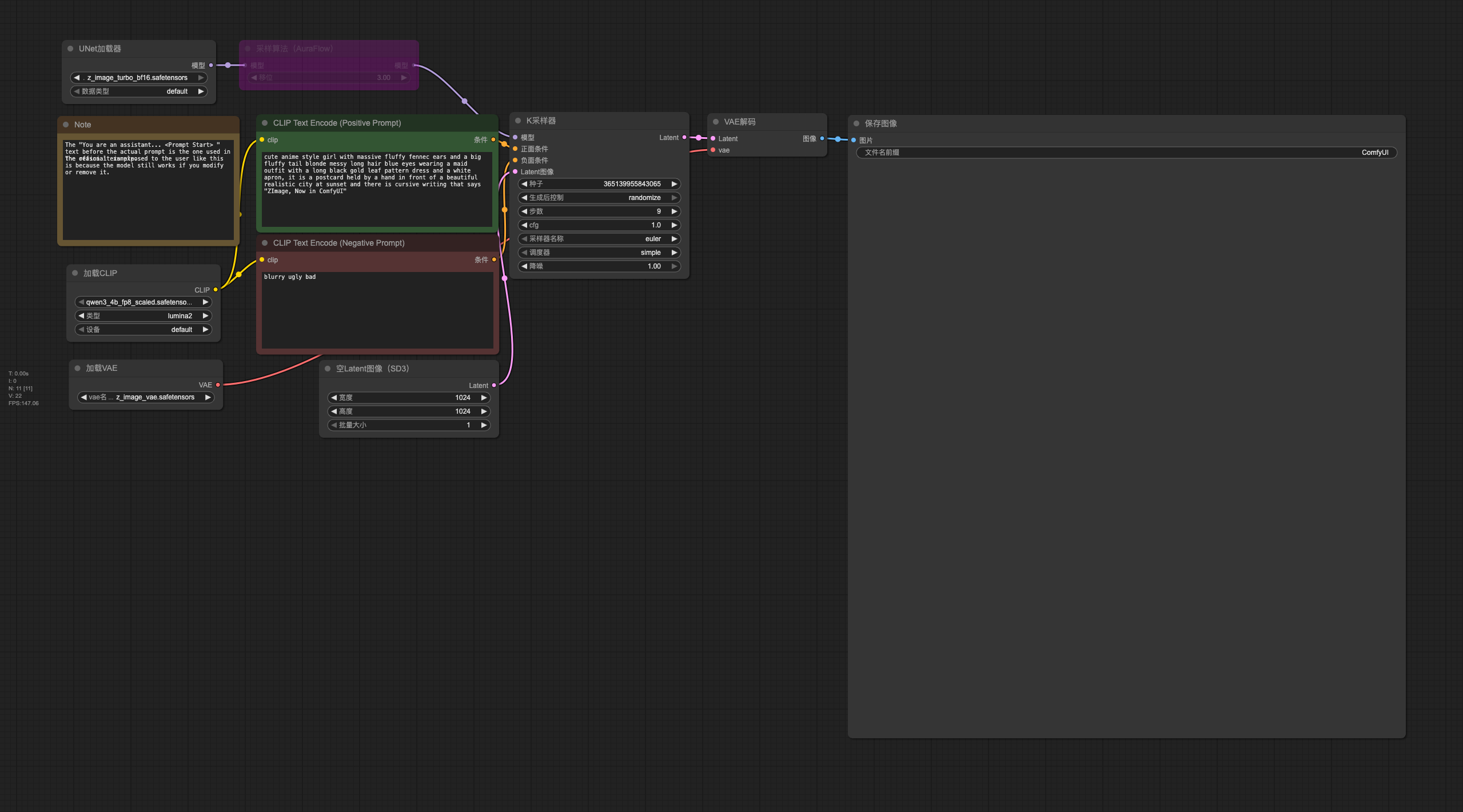
身为一个常年折腾本地 AI 模型的前端工程师,我一直都在寻找一种既轻量又能跑得飞快的模型方案。前段时间刷到不少人在讨论 qwen_3_4b-fp8 的性能,说这玩意解码速度快得离谱,还特别适合做本地生成式工作流。
为了搞清它到底是不是真的这么猛,我花了一个晚上把模型拉下来,并塞进自己的 ComfyUI 流程里,顺便搭上最近火得不行的 z-image-turbo,结果实际跑下来比我预期还要爽。
下面我就把整个体验、配置方式、模型信息,还有下载方式全部整理出来,方便你们也能轻松复现。
- 先放qwen_3_4b-fp8.safetensors下载地址:
https://pan.quark.cn/s/dbf9a4a9f32c - z-image-turbo-fp8模型下载地址:
https://pan.quark.cn/s/731f89698ff9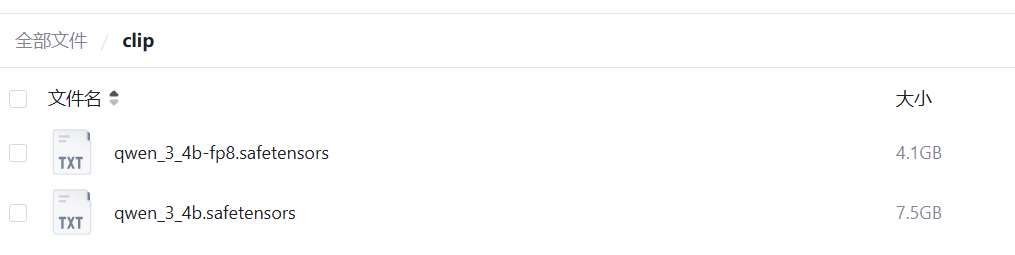
一、为什么选 Qwen3-4B-FP8?(4B 竟然这么快)
如果你电脑显存不算大,但又想玩本地大模型推理,那么 4B 体量的 FP8 版本真的很香:
🌟 亮点总结(但不是最终结论)
- 体积极小:FP8 比 FP16、BF16 轻多了
- 解码速度极快:本地实时感强
- 能力在同尺寸模型里非常能打
- 配合 ComfyUI + z-image-turbo,能实现“快速文生图”流程
特别是放进绘图管线里的时候,速度快到基本没有任何等待焦虑。
二、模型文件信息(含 safetensors 版本)
本次分享的模型文件:
qwen_3_4b-fp8.safetensors
格式为 safetensors,加载更安全,也更适合放到本地推理流程里。
三、如何在 ComfyUI 中使用?(含 z-image-turbo 搭配方法)
我这次的流程主要围绕:
ComfyUI + z-image-turbo + Qwen3-4B-FP8
大致结构如下:
- 加载 Qwen3 模型(fp8)
使用 Custom Nodes 中的文本模型加载节点 - z-image-turbo 负责图像生成核心加速
- Qwen3 负责 prompt 组织、场景理解或需求扩写
- 最终进入绘图节点生成结果
整个过程并不复杂,真正的关键点只有两个:
关键点 1:模型路径要绝对正确
将 qwen_3_4b-fp8.safetensors 放到:
ComfyUI\models\text_encoders
或你的自定义目录(只要在节点里能正确引用即可)。
关键点 2:建议搭配 Turbo 流程
如果你使用:
- z-image-turbo(极快)
- SD Turbo 系模型
- FastFlux / LCM / Hyper-SD
都可以让整条链路速度进一步提升。
实际体验下来:
4B FP8 + z-image-turbo 的 prompt 解读速度
真的比 13B、33B 那些巨型模型跑图更爽。
四、实际速度体验(我本机数据)
我的配置:
- RTX 4060 单卡
- 8G 显存
- Windows + ComfyUI
Qwen3-4B-FP8 加载速度:约 1 秒
ComfyUI 中 prompt 解读:完全不卡顿
z-image-turbo 出图速度:约 1.5~2 秒一张
整个体验非常顺畅。
五、模型下载地址
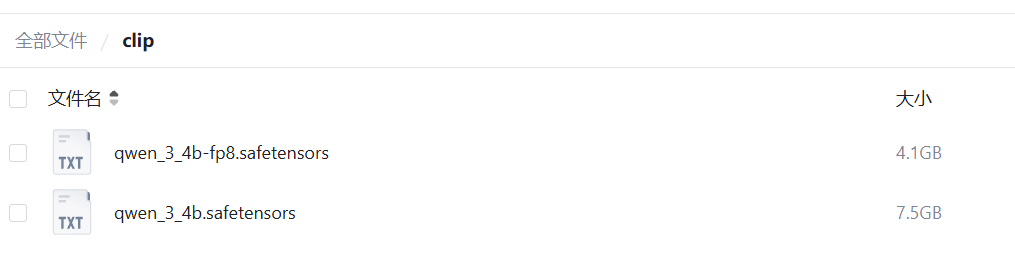
链接:https://pan.quark.cn/s/dbf9a4a9f32c
https://pan.quark.cn/s/dbf9a4a9f32c
你只需要下载 qwen_3_4b-fp8.safetensors 放到 ComfyUI 的模型目录就能直接使用。
六、结语:这小模型太能打了
这波实测结束,我得说一句:
4B + FP8 + safetensors + Turbo 工作流 = 本地推理性价比天花板
如果你正在找一个轻量又够强的模型来做
- Prompt 生成
- 场景扩写
- 本地文生图辅助
- 超高速工作流

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)