torch Tensor常见操作
1. torch.cat()https://cloud.baidu.com/article/29954792.
Tensor含义
Tensor(张量)可以看作是一个多维数组,它是标量、向量和矩阵向更高维度的扩展。
|
张量维度 |
数学等价物 |
实例说明(PyTorch创建示例) |
|---|---|---|
|
0维 |
标量 (Scalar) |
单个数值,如损失值: |
|
1维 |
向量 (Vector) |
一维数组,如特征向量: |
|
2维 |
矩阵 (Matrix) |
二维数组,如全连接层权重: |
|
3维及以上 |
高阶张量 |
如RGB图像(3, 224, 224)、图像批次(16, 3, 224, 224) |
Tensor的关键属性
- 数据类型(dtype):指定张量中常见的数据类型,如torch.float32、torch.float64、torch.int64、torch.bool等
- 设备(device):表明张量当前存储在何处,是cpu还是cuda:0(GPU)等
- 形状(shape):一个元组,表示张量在每个维度上的大小。
- 是否需要梯度(requires_grad):一个布尔值,指示是否需要为张量计算梯度。
Tensor常见操作
创建Tensor
1. numpy转tensor
import numpy as np
import torch
numpy_array = np.array([1, 1, 1])
tensor = torch.from_numpy(numpy_array)
print(tensor)
"""
tensor([1, 1, 1])
"""2. 列表转tensor
import torch
torch.tensor([[1, 2, 3], [4, 5, 6]])3. 利用大写接受以shape创建
import torch
torch.Tensor(3, 2)
tensor([[2.1439e-34, 0.0000e+00],
[2.7678e-04, 4.5817e-41],
[4.4842e-44, 0.0000e+00]])
torch.empty(3, 2)
tensor([[3.8401e-34, 0.0000e+00],
[3.8398e-34, 0.0000e+00],
[1.1210e-43, 0.0000e+00]])
4. 随机创建tensor
import torch
torch.rand(2, 3)
tensor([[0.3263, 0.2546, 0.9332],
[0.3767, 0.1792, 0.3704]])
tensor的切片(start:end:step)
如果要存一张RGB的minist(28*28)图片
image = torch.rand(4, 3, 28, 28)
image[1] # 获取第2张图片
image[0, 0].shape # 获取第1张图片第0个通道的图片形状
image[0, 0, 2, 4] # 返回像素灰度值的标量
# ...tensor的索引查找(index_select/masked_select/take)
x1 = np.array([[1,0,0,1],[1,1,0,1],[0,1,1,0],[0,1,1,1],[1,1,0,0]])
x2 = np.array([[1,0,1],[1,1,1]])
x1= torch.from_numpy(x1).long()
x2= torch.from_numpy(x2).long()
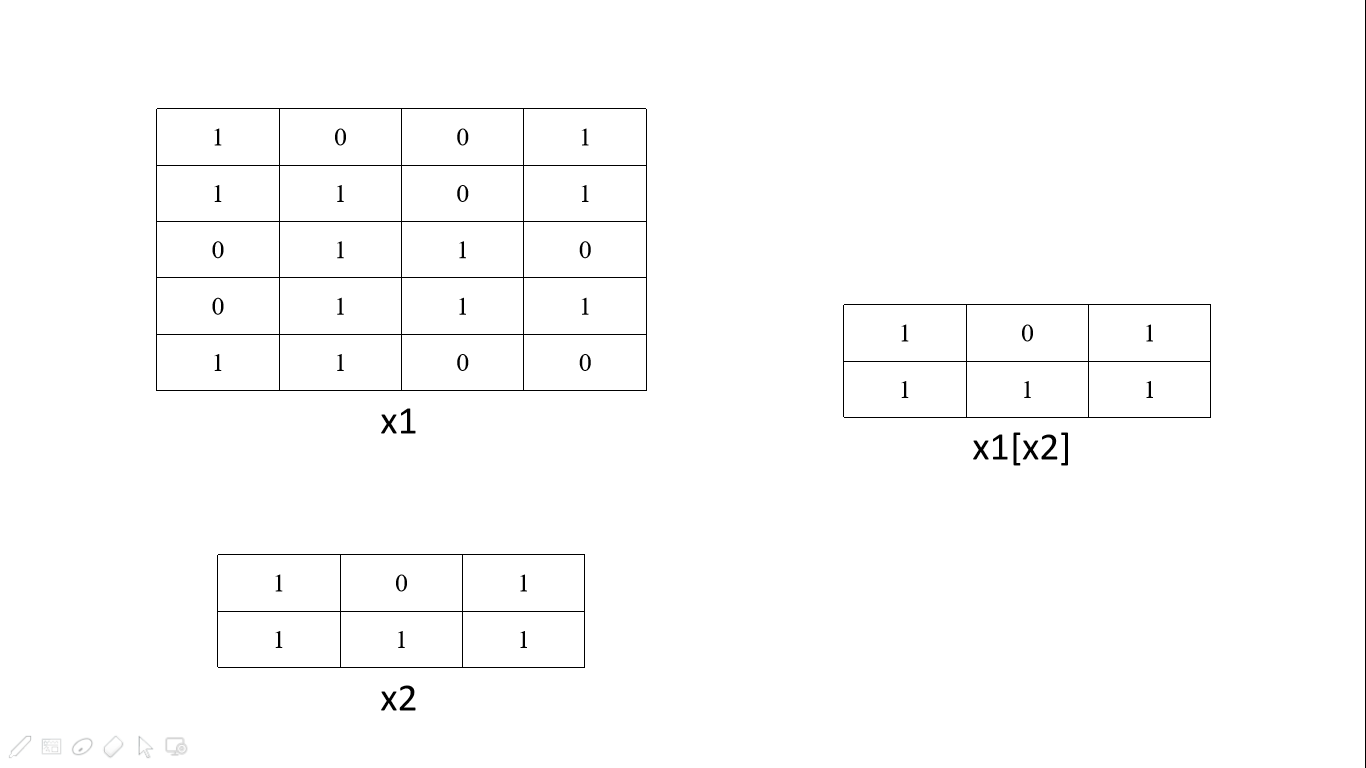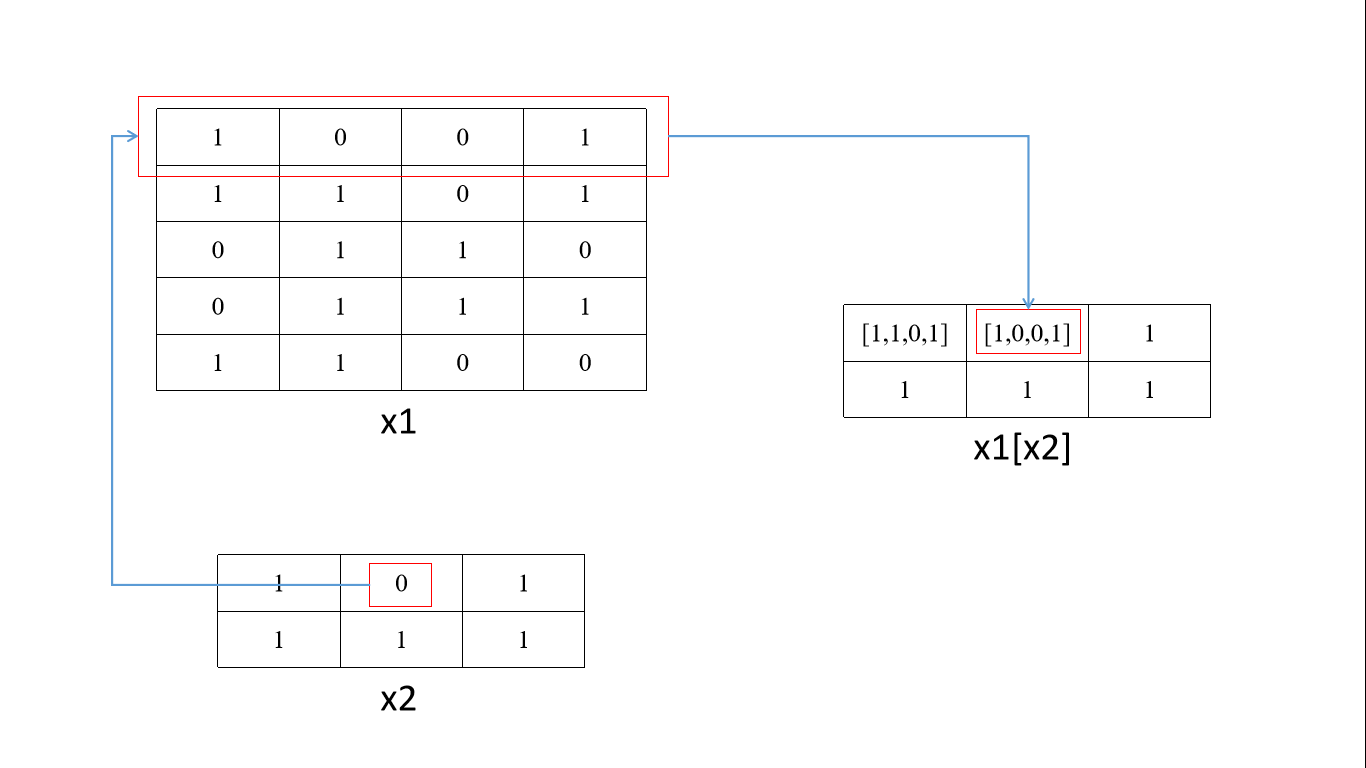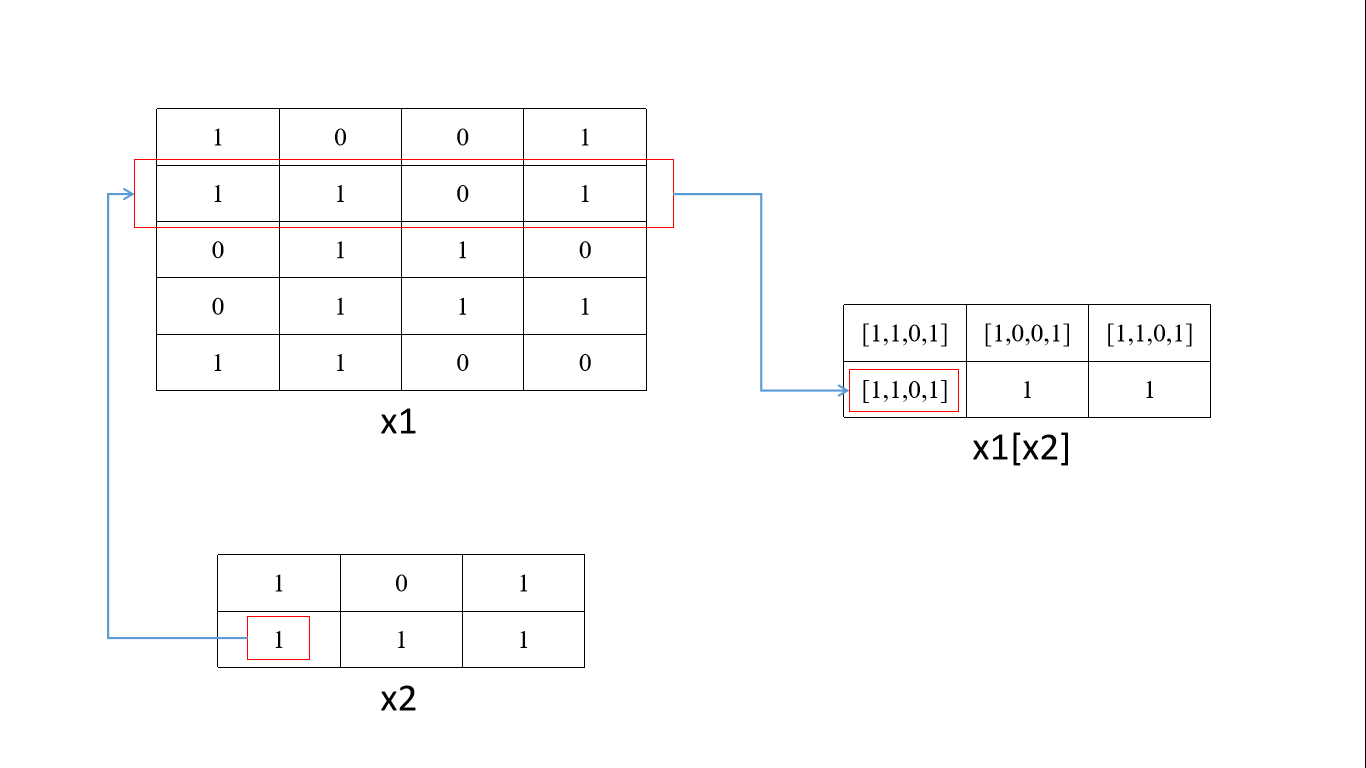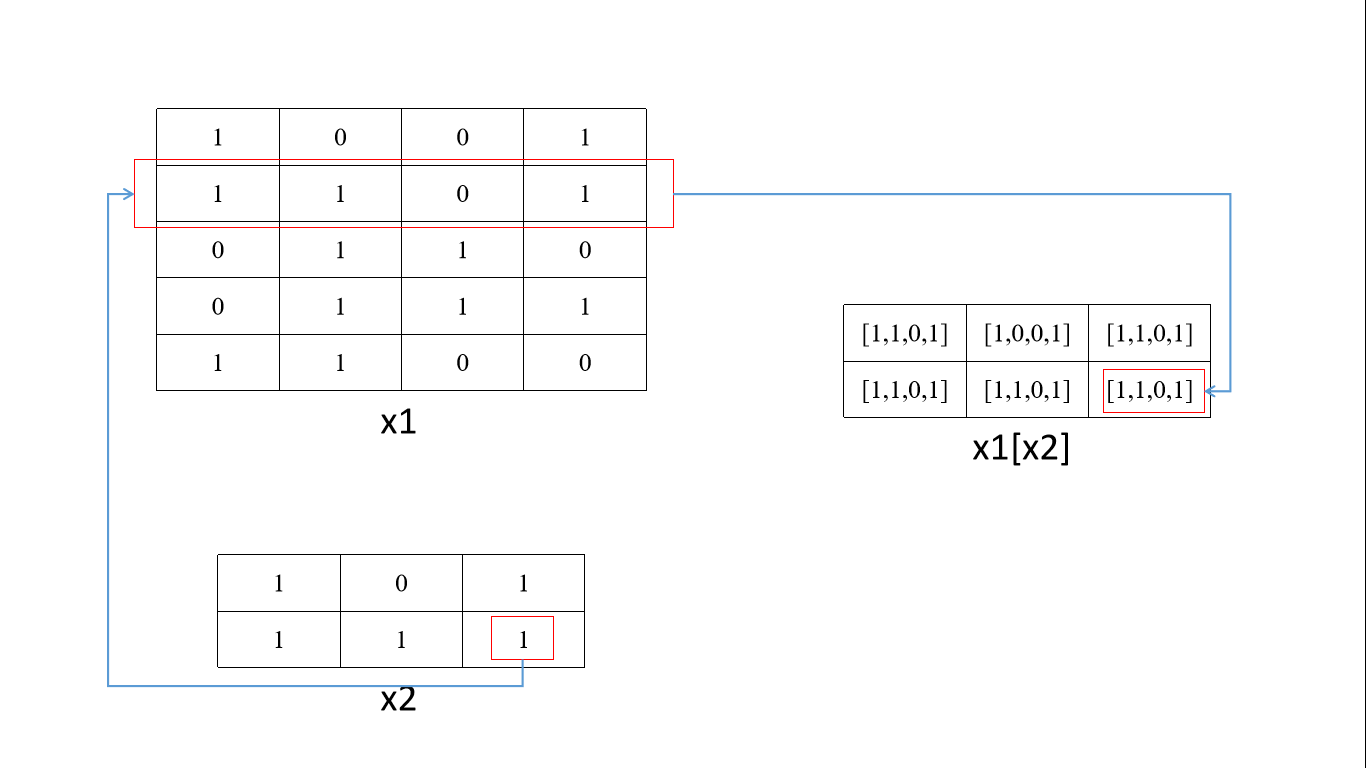
tensor的拼接与拆分
拼接
cat拼接
torch.cat(torsors, dim)
import torch
a = torch.rand(4, 3, 18, 18)
b = torch.rand(5, 3, 18, 18)
c = torch.rand(4, 2, 18, 18)
torch.cat([a, b], dim=0) # 拼接得到(9, 3, 18, 18)的数据
torch.cat([a, c], dim=1) # 拼接得到(4, 5, 18, 18)的数据
stack拼接
>>> import torch
>>> a = torch.rand(4, 3, 18, 18)
>>> b = torch.rand(4, 3, 18, 18)
>>> torch.stack([a, b], dim=0).shape
torch.Size([2, 4, 3, 18, 18])
>>> 拆分
split拆分 (按尺寸拆分)
torch.split()
>>> a = torch.rand(4, 4)
>>> b = a.split(1, dim=0) # 对第0维按照1个一份进行拆分,拆分得到4个形状为(1, 4)的张量
>>> a
tensor([[0.3690, 0.0144, 0.2122, 0.7564],
[0.1500, 0.1695, 0.3577, 0.3648],
[0.7477, 0.8034, 0.0912, 0.0237],
[0.2286, 0.0323, 0.5477, 0.3168]])
>>> b
(tensor([[0.3690, 0.0144, 0.2122, 0.7564]]), tensor([[0.1500, 0.1695, 0.3577, 0.3648]]), tensor([[0.7477, 0.8034, 0.0912, 0.0237]]), tensor([[0.2286, 0.0323, 0.5477, 0.3168]]))
>>>
>>> c = a.split(2, dim=0)
>>> a
tensor([[0.8824, 0.4966, 0.5721, 0.3487],
[0.3847, 0.2010, 0.5711, 0.4622],
[0.7004, 0.3376, 0.7784, 0.9710],
[0.9798, 0.1327, 0.9444, 0.1308]])
>>> c
(tensor([[0.8824, 0.4966, 0.5721, 0.3487],
[0.3847, 0.2010, 0.5711, 0.4622]]), tensor([[0.7004, 0.3376, 0.7784, 0.9710],
[0.9798, 0.1327, 0.9444, 0.1308]]))
# 不同长度进行拆分,(4, 4) 拆成 (1, 4)和 (3, 4)
>>> d, f = a.split([1, 3], dim=0)
>>> a
tensor([[0.8824, 0.4966, 0.5721, 0.3487],
[0.3847, 0.2010, 0.5711, 0.4622],
[0.7004, 0.3376, 0.7784, 0.9710],
[0.9798, 0.1327, 0.9444, 0.1308]])
>>> d
tensor([[0.8824, 0.4966, 0.5721, 0.3487]])
>>> f
tensor([[0.3847, 0.2010, 0.5711, 0.4622],
[0.7004, 0.3376, 0.7784, 0.9710],
[0.9798, 0.1327, 0.9444, 0.1308]])chunk拆分(按块数拆分)
>>> a = torch.rand(4, 4)
>>> a.chunk(4, dim=0) # 将张量依第0维拆分成4个(1, 3, 18, 18)的张量,等效于a.split(1, dim=0)
(tensor([[0.7528, 0.9029, 0.5109, 0.1446]]), tensor([[0.7029, 0.9443, 0.9600, 0.4517]]), tensor([[0.2038, 0.8926, 0.0444, 0.0144]]), tensor([[0.5201, 0.1761, 0.5112, 0.8281]]))
>>> a
tensor([[0.7528, 0.9029, 0.5109, 0.1446],
[0.7029, 0.9443, 0.9600, 0.4517],
[0.2038, 0.8926, 0.0444, 0.0144],
[0.5201, 0.1761, 0.5112, 0.8281]])
那么chunk和split有啥区别?
在torch中,chunk和split都用于拆分张量,他们的核心区别在于指定的拆分方式不同:chunk指定的是想要得到的块数,而split指定的是每块的尺寸
|
特性 |
|
|
|---|---|---|
|
核心逻辑 |
按块数拆分:指定希望将张量在某个维度上分成几块。 |
按尺寸拆分:指定拆分后每块在该维度上的大小。 |
|
关键参数 |
|
|
|
尺寸计算 |
每块尺寸 = 总尺寸 / 块数 (尽可能平均)。 |
尺寸由用户直接指定。 |
|
整除问题 |
若不能整除,前几块尺寸会稍大,最后一块包含余下部分。实际块数可能小于指定值。 |
若按整数拆分且不能整除,最后一块尺寸会较小。实际块数由总尺寸和指定尺寸决定。 |
|
灵活性 |
相对固定,目标是均分。 |
更灵活,可通过整数列表精确控制每一块的大小。 |
|
典型场景 |
需要将张量等分成N份,例如数据并行、分批处理。 |
1. 需要每块具有固定尺寸。 |
重塑
view
在 PyTorch 中,torch.Tensor.view() 方法用于重塑张量(Tensor)的形状,它返回一个与原张量数据共享内存的新张量(即修改新张量会影响原张量)。其核心作用是在不改变数据的情况下,调整张量的维度和大小。
基本用法
view(*shape) -> Tensor
- 参数:
shape是一个整数序列,表示新张量的形状。可以包含-1,表示该维度的大小由其他维度自动计算。 - 返回值:重塑后的新张量,与原张量共享数据。
>>> x = torch.rand(6)
>>> x
tensor([0.9957, 0.2430, 0.0249, 0.4692, 0.8152, 0.2445])
>>> x.shape
torch.Size([6])
>>> x.view(2, 3)
tensor([[0.9957, 0.2430, 0.0249],
[0.4692, 0.8152, 0.2445]])
>>> x
tensor([0.9957, 0.2430, 0.0249, 0.4692, 0.8152, 0.2445])
>>> y = x.view(2, -1)
>>> y
tensor([[0.9957, 0.2430, 0.0249],
[0.4692, 0.8152, 0.2445]])
>>> x
tensor([0.9957, 0.2430, 0.0249, 0.4692, 0.8152, 0.2445])
>>> y[0] += 1
>>> y
tensor([[1.9957, 1.2430, 1.0249],
[0.4692, 0.8152, 0.2445]])
>>> x
tensor([1.9957, 1.2430, 1.0249, 0.4692, 0.8152, 0.2445])
>>>
在 PyTorch 中,view() 和 reshape() 都是用于重塑张量形状的核心方法,但二者在内存连续性要求、数据内存共享策略、适用场景上有显著区别。下面从核心差异、使用场景、底层实现三个维度详细拆解。
一、核心区别对比
| 特性 | view() |
reshape() |
|---|---|---|
| 内存连续性要求 | 要求原张量是连续的(内存中按顺序存储,无间隔),否则直接调用会报错。 | 无连续性要求,自动处理非连续张量(内部会判断是否需要转换为连续张量)。 |
| 内存共享策略 | 始终与原张量共享内存(修改新张量会影响原张量)。 | 可能共享内存,也可能创建数据副本:1. 若原张量连续,行为与 view() 一致(共享内存);2. 若原张量非连续,会创建新的连续张量副本(不共享内存)。 |
| 功能灵活性 | 相对受限,仅适用于连续张量。 | 更灵活,是 view() 的超集,兼容所有重塑场景。 |
| 底层实现 | 直接修改张量的维度元信息(stride/shape),无数据拷贝,效率极高。 | 内部逻辑:1. 若张量连续 → 调用 view();2. 若张量非连续 → 调用 contiguous() + view()(会拷贝数据)。 |
二、具体使用场景与示例
1. 当张量是连续的时:二者行为一致
此时 reshape() 等价于 view(),均共享内存,无数据拷贝。
python
运行
import torch
# 创建连续张量(默认创建的张量都是连续的)
x = torch.tensor([[1, 2, 3], [4, 5, 6]]) # shape: (2, 3),is_contiguous() → True
# view() 重塑
y_view = x.view(3, 2)
# reshape() 重塑
y_reshape = x.reshape(3, 2)
# 修改新张量,原张量也会被改变(共享内存)
y_view[0, 0] = 100
print(x) # 输出: tensor([[100, 2, 3], [ 4, 5, 6]])
y_reshape[1, 1] = 200
print(x) # 输出: tensor([[100, 2, 3], [ 4, 5, 200]])
2. 当张量是非连续的时:二者行为不同
张量经过 transpose()/permute() 等操作后,会变成非连续(内存存储顺序与维度顺序不一致),此时 view() 会报错,而 reshape() 能正常工作。
python
运行
# 转置张量(转置后张量变为非连续)
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
x_trans = x.transpose(0, 1) # shape: (3, 2),is_contiguous() → False
# 直接调用 view() 会报错
try:
x_trans.view(6)
except RuntimeError as e:
print("view() 报错:", e) # 输出:view size is not compatible with input tensor's size and stride
# reshape() 可正常工作(内部创建了数据副本)
x_reshape = x_trans.reshape(6)
x_reshape[0] = 100
print(x) # 输出: tensor([[1, 2, 3], [4, 5, 6]])(原张量未被修改,因为是副本)
# 若要让 view() 工作,需先调用 contiguous() 转换为连续张量
x_trans_cont = x_trans.contiguous()
x_view = x_trans_cont.view(6)
x_view[0] = 100
print(x) # 输出: tensor([[100, 2, 3], [4, 5, 6]])(共享内存,原张量被修改)
三、如何选择?
-
优先用
reshape():- 如果你不确定张量是否连续(比如经过转置、维度交换后),
reshape()更安全,无需手动处理连续性。 - 对代码简洁性要求高,不想关注内存细节时。
- 如果你不确定张量是否连续(比如经过转置、维度交换后),
-
用
view()的场景:- 你明确知道张量是连续的(比如刚创建的张量、经过
contiguous()后的张量),且需要极致的效率(无数据拷贝)。 - 需强制共享内存(修改新张量必须影响原张量)时。
- 你明确知道张量是连续的(比如刚创建的张量、经过
四、补充:reshape() 与 clone() 的配合
如果希望重塑后的张量与原张量完全独立(不共享内存),可在 reshape() 后调用 clone():
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
x_reshape = x.reshape(6).clone()
x_reshape[0] = 100
print(x) # 输出: tensor([[1, 2, 3], [4, 5, 6]])(原张量无变化)
总结
view():轻量级重塑,仅适用于连续张量,始终共享内存,效率高但有使用限制。reshape():通用型重塑,兼容所有张量,灵活安全,是日常开发的首选。
简单记:reshape() 是 view() 的 “增强版”,解决了 view() 对非连续张量的限制,代价是在非连续场景下会产生数据副本。
tensor的运算
乘法
#tensor直接相*,其结果为element wise,矩阵乘法为torch.matmul或者@ #高维tensor矩阵相乘实际上是对多个二维矩阵进行并行运算 a=torch.rand(4,3,28,64) b=torch.rand(4,3,64,32) a@b#结果得到的形状为(4,3,28,32)
>>> a = torch.rand(2, 2)
>>> b = torch.rand(2, 3)
>>> a
tensor([[0.9662, 0.4762],
[0.6365, 0.2129]])
>>> b
tensor([[0.6583, 0.9811, 0.2332],
[0.5010, 0.9111, 0.3308]])
>>> a @ b
tensor([[0.8746, 1.3818, 0.3828],
[0.5257, 0.8185, 0.2189]])
>>>
>>> a = torch.rand(4, 16, 28, 28)
>>> b = torch.rand(4, 16, 28, 32)
>>> (a @ b).shape
torch.Size([4, 16, 28, 32])平方/开方
>>> a = torch.full([2, 2], 2) # 创建一个(2, 2)的全2矩阵
>>> a
tensor([[2, 2],
[2, 2]])
>>> a.pow(2) # a的每个元素都平方,等价于 a ** 2
tensor([[4, 4],
[4, 4]])
>>> a ** 2
tensor([[4, 4],
[4, 4]])
>>>
#开方
a.sqrt()#平方根
a**0.5#等价于上一句
#exp,log
a.torch.exp(torch.ones(2,2))
torch.log(a)
#近似
#floor()向下取整,ceil()向上取整,round()四舍五入。
#取整取小数
#trunc()取整,frac()取小数
#clamp取范围
a=torch.tensor([[3,5],[6,8]])
a.clamp(6)#得到[[6,6],[6,8]],小于6的都变为6
a.clamp(5,6)#得到[[5,5],[6,6]],小于下限变为下限,大于上限变为上限。爱因斯坦标示库
代码操作概览
|
操作类别 |
代码示例 |
功能描述 |
关键参数说明 |
|---|---|---|---|
|
1. 转置 |
|
交换维度c(通道)和h(高度)的顺序。 |
模式字符串直观表示维度重排。 |
|
2. 变形 |
|
将批次和通道维度合并,改变张量形状而不改变数据顺序。 |
括号 |
|
3. 图像分块 |
|
将图像分割成不重叠的小块(例如2x2的patch)。 |
|
|
4. 池化/规约 |
|
对高度和宽度维度进行最大化操作,实现全局最大池化。 |
模式定义输出形状, |
|
5. 堆叠张量列表 |
|
将张量列表堆叠成一个新的张量,增加一个批次维度。 |
对张量列表进行操作。 |
|
6. 扩维与复制 |
|
在张量末尾增加一个大小为1的维度。 |
类似 |
|
|
在新增的维度上将数据复制2次。 |
类似 |
|
|
|
在空间维度上进行上采样,将图像尺寸放大2倍。 |
|
import torch
from einops import rearrange, reduce, repeat
x = torch.randn(2,3,4,4) # 4D Tensor: bs*c*h*w
## 1. 转置
out1 = x.transpose(1,2)
out2 = rearrange(x, 'b c h w -> b h c w')
## 2. 变形
out1 = x.reshape(6,4,4)
out2 = rearrange(x, 'b c h w -> (b c) h w')
out3 = rearrange(out2, '(b c) h w -> b c h w', b=2)
## 3. image2patch
out1 = rearrange(x, 'b c (h1 p1) (w1 p2) -> b c (h1 w1) (p1 p2)', p1=2, p2=2) # p1,p2是patch的高度和宽度
out2 = rearrange(out1, 'b c n a -> b n (a c)') # shape:[batchsize, num_patch, patch_depth]
## 4. 求平均池化
out1 = reduce(x, 'b c h w -> b c h', 'mean') # mean, min, max, sum, prod
out2 = reduce(x, 'b c h w -> b c h 1', 'sum') # keep dimension
out3 = reduce(x, 'b c h w -> b c', 'max')
## 5. 堆叠张量
tensor_list = [x, x, x]
out1 = rearrange(tensor_list, 'n b c h w -> n b c h w')
## 6. 扩维与复制
out1 = rearrange(x, 'b c h w -> b c h w 1') # 类似 torch.unsqueeze
out2 = repeat(out1, 'b c h w 1 -> b c h w 2') # 类似 torch.tile
out3 = repeat(x, 'b c h w -> b c (2 h) (2 w)') 为什么使用 einops?
从您提供的代码对比和上面的讲解可以看出,einops的核心优势在于代码的可读性和意图的清晰表达。
-
声明式语法:你只需要描述“你想让张量变成什么样子”(如
-> b c (2 h) (2 w)),而不需要一步步指挥程序“如何去做”(比如先unsqueeze再tile)。 -
统一的API:无论是转置、重塑、切片、重复还是规约操作,都可以通过
rearrange、repeat、reduce这几个函数和统一的模式字符串来完成,大大降低了记忆负担。 -
内置维度检查:
einops会自动验证变换模式的合理性,有效减少因维度计算错误导致的Bug
参考资料:
https://cloud.tencent.com/developer/article/2345313

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)