南京大学 LLM 开发基础(七)RAG 检索增强生成
RAG(检索增强生成)通过结合外部知识检索与大模型生成能力,显著提升了专业问答的准确性和时效性。其核心流程包括:索引构建(数据清洗、向量化)、文本拆分(固定大小重叠切割)、向量检索(余弦相似度匹配),以及提示词增强生成。相比传统大模型,RAG有效缓解了幻觉问题、上下文长度限制和知识更新滞后等弊端,同时避免了昂贵且易过拟合的微调过程。实现时可通过Haystack或LangChain等框架,构建“检索
https://njudeepengine.github.io/llm-course-lecture/2025/lecture13.html
目录
传统大模型文本生成:基于训练数据中的模式和知识进行生成
存在的缺点:
- 幻觉问题:模型可能生成不准确或虚构的信息
- 上下文长度限制:模型能处理的输入长度有限,无法涵盖大量的背景信息
- 知识更新滞后:模型的知识截至训练时间,无法包含最新的信息(问之后的 模型就不知道或者瞎编)
预训练知识:唐诗三百首; 专业知识指令微调:如何作诗
微调的代价:成本高昂、不易维护、过拟合风险
搜索查询:搜索到相关的作诗作品当作作诗的参照,提升回答专业问题的能力
RAG(Retrieval-Augmented Generation):检索增强生成
先从外部知识库中检索相关信息,再结合这些信息进行生成。
1. 索引 + 拆分 + 向量数据库 + 检索
1. 准备阶段 索引构建:
1. 数据预处理(清洗、分句);2. 向量化表示;3. 建立高效的检索索引结构
数据覆盖:全面性,尽可能覆盖所有可能被问到的主题
避免知识孤岛:确保相关内容之间有关联。
2. 文本拆分(Chunking)策略:
大小适中:Chunk 太大,会包含过多无关信息,干扰检索和生成;
Chunk 太小,会失去上下文,导致信息碎片化。
固定大小重叠分割:设置一个固定长度(如 512 tokens),并让相邻 Chunk 有一定重叠(如 50 tokens),以保持上下文连贯。
split_by 的单位有 page、passage、sentence、line、word。
DocumentSplitter 比如下例:按词切,3个切割,1个重叠。
from haystack.components.preprocessors import DocumentSplitter
from haystack import Document
numbers = "0 1 2 3 4 5 6 7 8 9"
document = Document(content=numbers)
splitter = DocumentSplitter(split_by="word", split_length=3, split_overlap=1)
docs = splitter.run(documents=[document])["documents"]我想要按句子切,会按照句号分割,但是要区分人名中的点(特殊符号)。
NLTKDocumentSplitter
from haystack.components.preprocessors import NLTKDocumentSplitter, DocumentSplitter
from haystack import Document
text = """The dog was called Wellington. It belonged to Mrs. Shears who was our friend.
She lived on the opposite side of the road, two houses to the left."""
document = Document(content=text)
# 人名中的. 会被分为两个句子
simple_splitter = DocumentSplitter(split_by="sentence", split_length=1, split_overlap=0)
simple_docs = simple_splitter.run(documents=[document])["documents"]
# 人名的. 会合并人名
nltk_splitter = NLTKDocumentSplitter(split_by="sentence", split_length=1, split_overlap=0)
nltk_docs = nltk_splitter.run(documents=[document])["documents"]3. 向量数据库的考量
-
可扩展性:随着知识库增大,数据库能否支持高效的近似最近邻(ANN)搜索。
-
过滤能力:是否支持元数据过滤(例如,只搜索“2023年之后的”、“属于A产品的”文档)。
-
混合搜索:除了向量检索,是否支持关键词(如 BM25)检索,以便实现混合搜索,兼顾语义和精确关键词匹配。
4. 检索:计算问题和文档向量之间的相似度(如余弦相似度)
优化:1. 对查询进行改写或扩展同义词,以提高召回率。
2. 多路召回:同时使用向量检索和关键词检索,取各自的前 K 个结果,合并去重。
3. 重排序:多路召回的结果进行精排
4. 元数据过滤:预过滤,缩小检索范围,提升效率和准确性。
query -> 文档库 D。

from haystack import Document
from haystack.components.retrievers.in_memory import InMemoryBM25Retriever
from haystack.document_stores.in_memory import InMemoryDocumentStore
# 文档准备
document_store = InMemoryDocumentStore()
documents = [
Document(content="There are over 7,000 languages."),
Document(content="****."),
Document(content="++++.")
]
document_store.write_documents(documents=documents)
# 文档检索
retriever = InMemoryBM25Retriever(document_store=document_store)
docs = retriever.run(query="How many languages?")["documents"]
# 文档的内容和分数
for doc in docs:
print(f"content: {doc.content}")
print(f"score: {doc.score}")
简单速度快,但是依赖 query 质量。
2. Haystack 实现 RAG -- 维基百科南京大学
1. 初始化索引组件
from haystack.document_stores.in_memory import InMemoryDocumentStore # 内存文档存储
from haystack.components.fetchers import LinkContentFetcher # 网页内容获取
from haystack.components.converters import HTMLToDocument # HTML转文档
document_store = InMemoryDocumentStore() # 内存向量数据库
fetcher = LinkContentFetcher() # 获取网页内容
converter = HTMLToDocument() # HTML转Document对象
from haystack.components.preprocessors import DocumentSplitter # 文档分割
from haystack.components.writers import DocumentWriter # 文档写入存储
from haystack.components.embedders import (
SentenceTransformersTextEmbedder, # 文本嵌入(查询用)
SentenceTransformersDocumentEmbedder, # 文档嵌入(存储用)
)
splitter = DocumentSplitter(split_by="sentence", split_length=3, split_overlap=1) # 按句子分割
document_embedder = SentenceTransformersDocumentEmbedder(
model="sentence-transformers/all-MiniLM-L6-v2" # 文档嵌入模型
)
writer = DocumentWriter(document_store=document_store) # 写入文档存储2. 索引管道:数据流:URL → HTML → Document → 分割 → 向量化 → 存储
indexing_pipeline = Pipeline()
indexing_pipeline.add_component("fetcher", fetcher)
indexing_pipeline.add_component("converter", converter)
indexing_pipeline.add_component("splitter", splitter)
indexing_pipeline.add_component("document_embedder", document_embedder)
indexing_pipeline.add_component("writer", writer)
# 连接组件的数据流
indexing_pipeline.connect("fetcher.streams", "converter.sources") # URL→HTML
indexing_pipeline.connect("converter.documents", "splitter.documents") # HTML→文档
indexing_pipeline.connect("splitter.documents", "document_embedder.documents") # 分割→嵌入
indexing_pipeline.connect("document_embedder.documents", "writer.documents") # 嵌入→存储南京大学的维基百科页面 -> 处理并向量化后存入内存数据库
indexing_pipeline.run(data={"fetcher": {"urls": ["https://en.wikipedia.org/wiki/Nanjing_University"]}})3. 提示词模版
prompt_template = """
Given these documents, answer the question.
Documents:
{% for doc in documents %}
{{ doc.content }}
{% endfor %}
Question: {{question}}
Answer:
"""4. 查询组件
api_key = "***"
model = "***"
api_base_url = ***
query_embedder = SentenceTransformersTextEmbedder(model="sentence-transformers/all-MiniLM-L6-v2")
retriever = InMemoryEmbeddingRetriever(document_store=document_store)
prompt_builder = PromptBuilder(template=prompt_template)
llm = OpenAIGenerator(
api_key=Secret.from_token(api_key), # 安全封装API密钥
model=model,
api_base_url=api_base_url
)5. 查询管道:问题 → 向量化 → 检索 → 构建提示词 → LLM生成答案
rag_pipeline = Pipeline()
rag_pipeline.add_component("query_embedder", query_embedder)
rag_pipeline.add_component("retriever", retriever)
rag_pipeline.add_component("prompt_builder", prompt_builder)
rag_pipeline.add_component("llm", llm)
rag_pipeline.connect("query_embedder.embedding", "retriever.query_embedding") # 查询向量化→检索
rag_pipeline.connect("retriever.documents", "prompt_builder.documents") # 检索结果→提示词
rag_pipeline.connect("prompt_builder.prompt", "llm.prompt") # 提示词→LLM6. 交互式问答循环
while(True):
question = prompt("> ") # 获取用户输入
results = rag_pipeline.run(
{
"query_embedder": {"text": question}, # 输入查询文本
"prompt_builder": {"question": question}, # 传入问题
}
)
reply = results["llm"]["replies"][0] # 获取LLM回复
print(reply)3. 使用 LangChain 实现 RAG
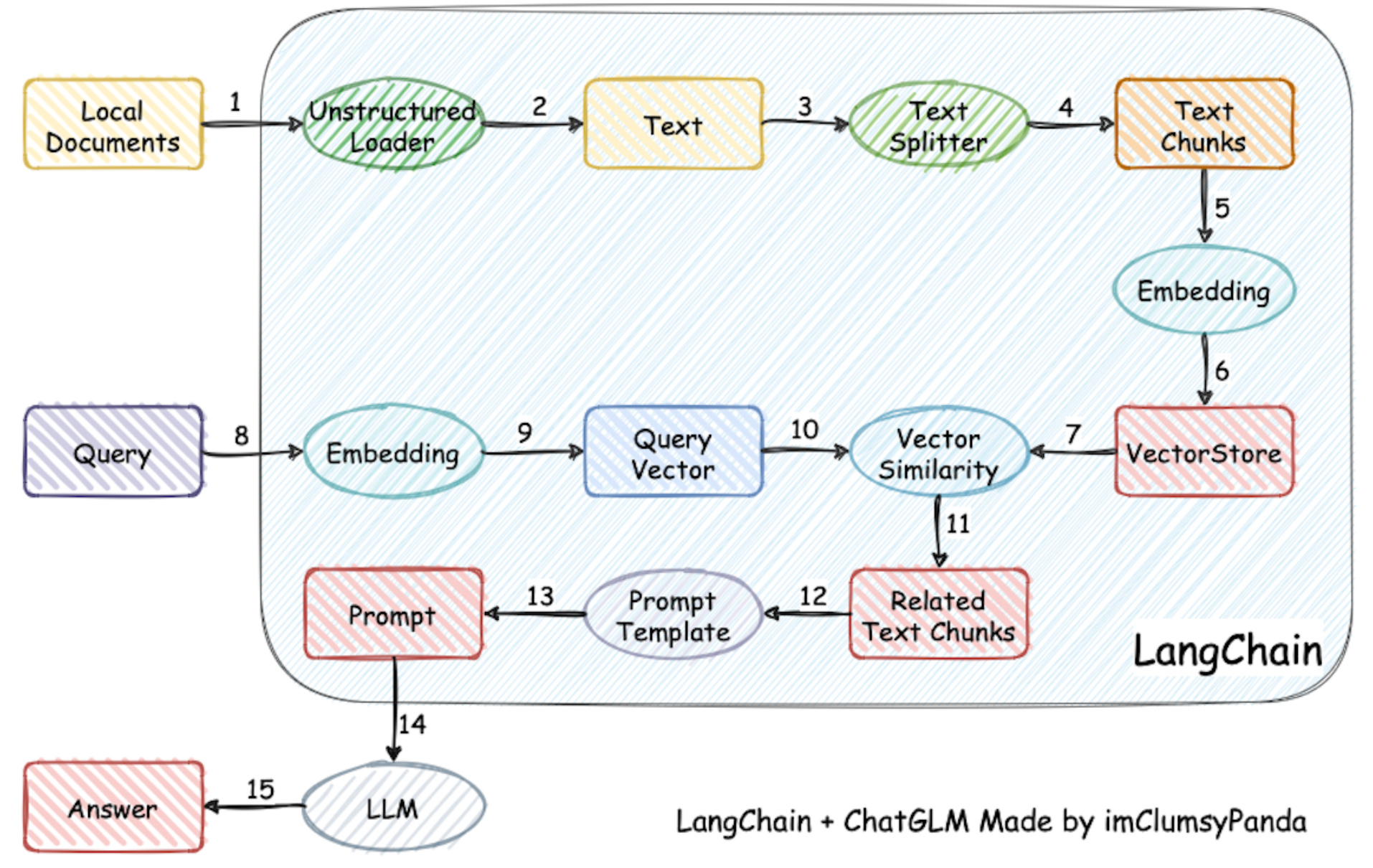
1. 创建 Embedding + LLM 模型实例
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
llm = ChatOpenAI(model="gpt-4o-mini")
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")2. 加载文档并拆分
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), # 网址
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header") # 只看正文、标题、开头
)
),
)
docs = loader.load()
# chunk 拆分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)3. 建立向量数据库
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
# Index chunks
_ = vector_store.add_documents(documents=all_splits)4. 状态类及检索、生成函数
# Define state for application
class State(TypedDict):
question: str
context: List[Document]
answer: str
# 检索
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}5. 创建工作流程并测试
from langgraph.graph import START, StateGraph
from typing_extensions import List, TypedDict
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()
response = graph.invoke({"question": "What is Task Decomposition?"})
print(response["answer"])
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 20
20 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)