AI 三大学习类型(监督/无监督/强化)的分类图
数据没有标签(没有 “标准答案”),模型是自己找数据里的规律(比如分组、找特征),但没人告诉它 “这么分组是对的 / 错的”。:因为数据是带标签的(相当于 “标准答案”),模型做完预测后,能直接和标签对比,立刻知道 “预测错了 / 对了”“错在哪里”。比如用 “猫的图片 +‘猫’标签” 训练模型:模型预测某张图是 “狗”,就能直接和标签 “猫” 对比,得到 “预测错误” 的反馈。这两个 “反馈”
·
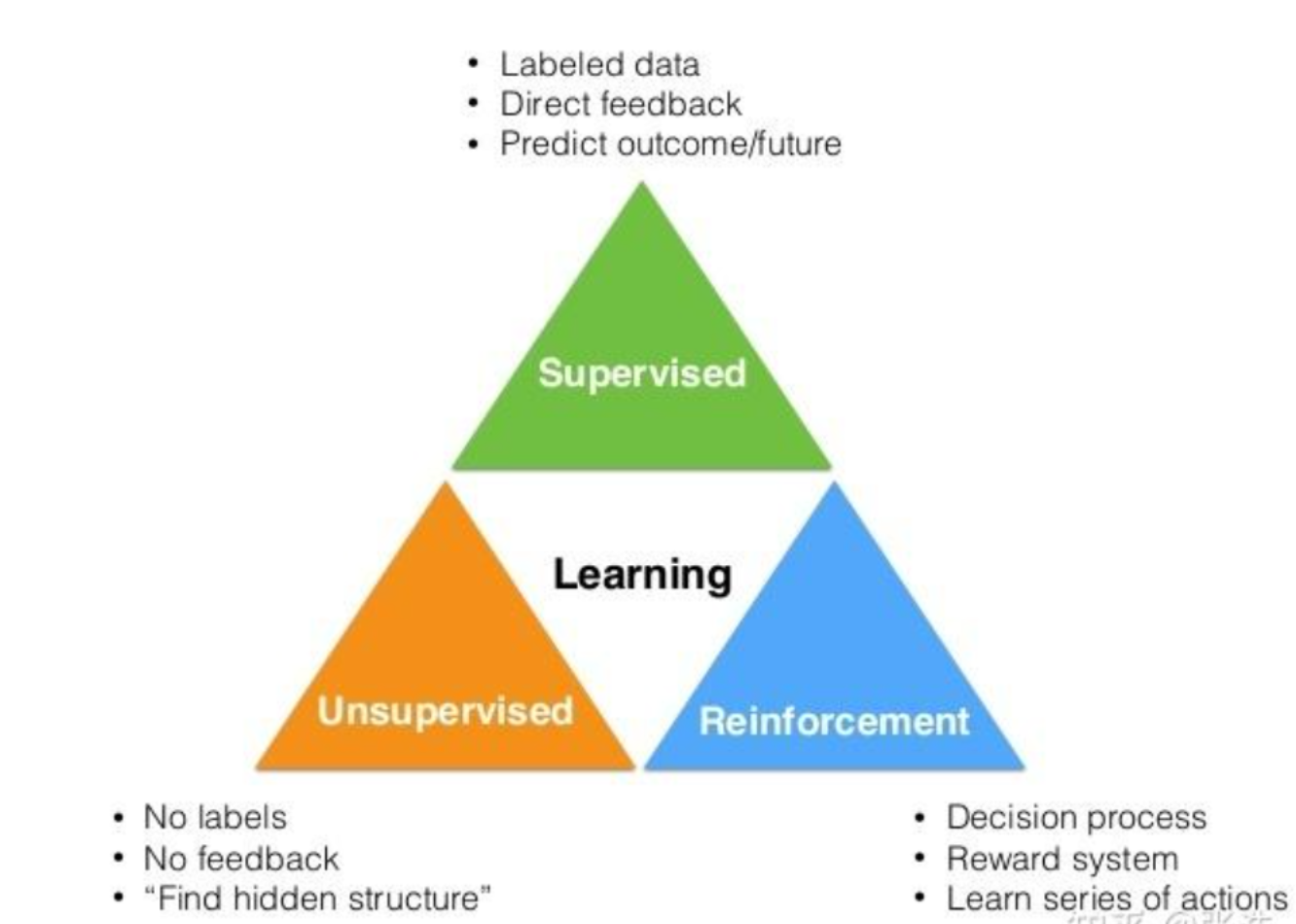
中间核心
Learning → 学习
绿色三角形:Supervised(监督学习)
对应特点:
- Labeled data → 带标签的数据
- Direct feedback → 直接反馈
- Predict outcome/future → 预测结果 / 未来
橙色三角形:Unsupervised(无监督学习)
对应特点:
- No labels → 无标签
- No feedback → 无反馈
- “Find hidden structure” → “发现隐藏结构”
蓝色三角形:Reinforcement(强化学习)
对应特点:
- Decision process → 决策过程
- Reward system → 奖励机制
- Learn series of actions → 学习一系列动作
对应特点中:直接反馈和无反馈啥意思?
这两个 “反馈” 其实是指模型训练时有没有 “标准答案” 来告诉它 “做得对不对”:
-
监督学习的 “直接反馈”:因为数据是带标签的(相当于 “标准答案”),模型做完预测后,能直接和标签对比,立刻知道 “预测错了 / 对了”“错在哪里”。比如用 “猫的图片 +‘猫’标签” 训练模型:模型预测某张图是 “狗”,就能直接和标签 “猫” 对比,得到 “预测错误” 的反馈。
-
无监督学习的 “无反馈”:数据没有标签(没有 “标准答案”),模型是自己找数据里的规律(比如分组、找特征),但没人告诉它 “这么分组是对的 / 错的”。比如把一堆混合的水果图片分组:模型可能按 “颜色” 分成两堆,但没有标签说 “这堆必须是苹果、那堆必须是橘子”,所以没有明确的对错反馈。
实际场景举例:
监督学习(有直接反馈)的例子:公司的人脸识别打卡
- 训练阶段:系统里存了带标签的数据—— 每个员工的人脸照片,都对应 “张三”“李四” 的姓名标签(相当于标准答案)。
- 打卡时:你站在打卡机前,模型识别你的脸,预测 “这是张三”,然后立刻和系统里的标签对比 —— 如果你的标签确实是 “张三”,反馈就是 “正确,打卡成功”;如果模型认错成 “李四”,反馈就是 “错误,打卡失败”。→ 这就是 “直接反馈”:有明确的 “对 / 错” 结果告诉你。
无监督学习(无反馈)的例子:电商平台给用户分群
- 平台有一堆用户的消费数据(比如 “买了零食”“常逛数码区”“每月花 200 元”),但没有标签(没人告诉系统 “这些用户该分成‘吃货组’‘数码党’”)。
- 模型自己分析数据,把消费习惯像的用户分成几组:比如组 1 是 “高频买零食的用户”,组 2 是 “只买过一次的新用户”。
- 但这个分组没有 “标准答案”—— 没人会说 “组 1 必须叫‘吃货组’才对”,平台只是用这个分组去推对应的商品,不会有 “分组错误” 的反馈。→ 这就是 “无反馈”:没有明确的对错评价,只看分组有没有实际用处。
强化学习的例子:王者荣耀 AI 英雄的对局
- 智能体:游戏里的 AI 英雄;环境:对局战场
- 过程:
- AI 处于当前对局状态(比如 “自己剩半血、敌方射手在前方”);
- AI 做决策动作(比如 “走位靠近敌方、释放技能”);
- 环境(游戏)给奖励:如果技能命中敌方→加正奖励;如果被敌方反打扣血→加负奖励;
- AI 不会立刻知道 “这个动作对不对”,但会通过 “累计奖励多少” 调整后续动作 —— 慢慢学会 “先躲技能再输出” 这类能拿更多正奖励的操作。
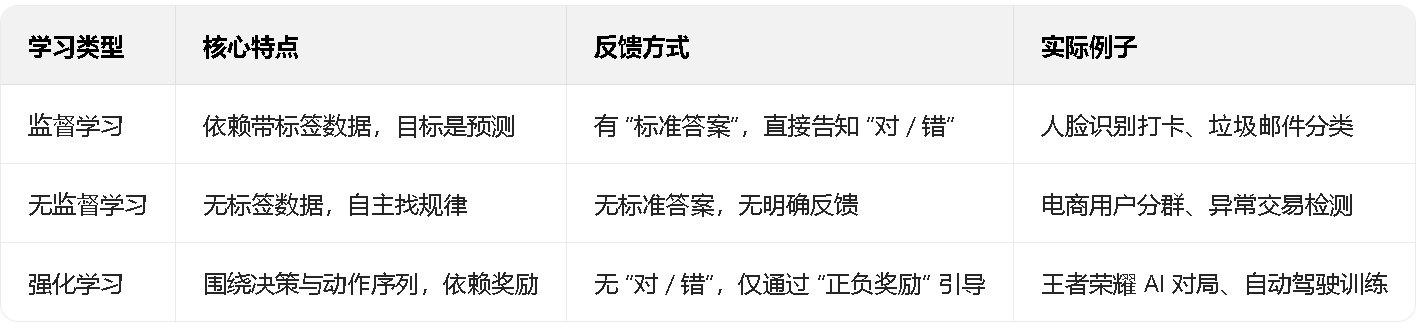
三种学习的反馈方式对比(更清晰):
- 监督学习:有 “标准答案”(标签),直接告诉你 “对 / 错”;
- 无监督学习:没标准答案,自己找规律,没明确反馈;
- 强化学习:没 “对 / 错”,只有 “奖励多少”,靠 “累计奖励” 调整动作。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)