【强化学习】第三章:马尔可夫决策过程(MDP)、贝尔曼期望方程(Bellman Expectation Equation)、贝尔曼最优方程(Bellman Optimality Equation)
【强化学习】第三章:马尔可夫决策过程(MDP)、贝尔曼期望方程(Bellman Expectation Equation)、贝尔曼最优方程(Bellman Optimality Equation)
一、本章学习内容介绍
学习强化学习,我们一般是从有模型过渡到无模型这么一个过程。因为有模型的强化学习比较简单。所以本篇学的是有模型的强化学习,从简到繁嘛。
有模型指的是不需要和环境进行交互,就自动有state-action-reward的序列过程,比如生活中的打简单的小游戏、下象棋等都可以用有模型的强化学习来解决。我们具体的解决流程是:
(1)先把生活中问题抽象成一个数学问题,具体这里就是抽象成一个MDP问题,也就是用MDP来对生活问题进行数学描述。
(2)那解决MDP问题就变成了数学上的最优化问题,我们再用数学中的一些优化算法,比如动态规划(Dynamic Programming)、迭代学习(如Q-learning),来求解这个最优化问题,这样求解出来的数学答案,就是解决我们生活中实际问题的最优答案 。
本篇只讲抽象成的数学问题:马尔可夫决策过程(MDP问题) ,下一篇章讲MDP问题的解:动态规划。下图是本篇章在鲁鹏老师课件中的位置,通过下图也可以对强化学习的全部内容有一个大致了解: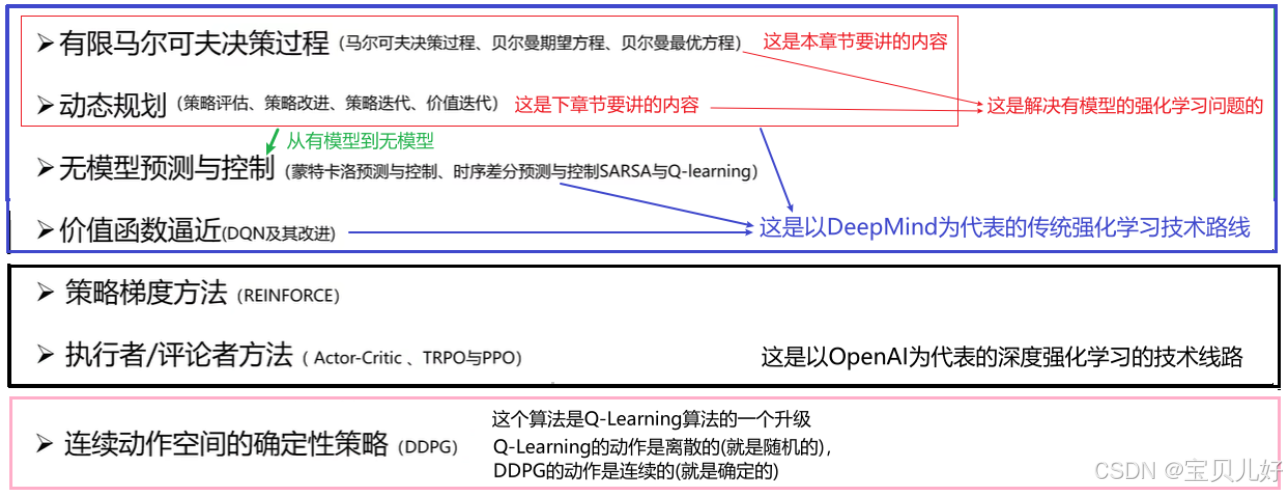
对于不需要和环境进行交互、或者说环境是完全可观测的强化学习问题,我们一般都给它定义成MDP问题,MDP是这类问题的理想化数学表示形式。这种能定义成MDP问题的强化学习我们叫有模型的强化学习。对于无法获取马尔可夫决策过程的问题,我们就得用无模型的强化学习算法来解决,比如蒙特卡罗估计(Monte-Carlo Estimation)、时间差分(Temporal Difference)等,这些就是后续章节来介绍了。
二、从生活中的小例子-->MDP问题-->MDP框架
我们是把生活中的问题转化成MDP问题,所以这里我先展示一个生活中的小例子,通过这个例子引出什么是MDP。
下图是sliver课件中的例子,我也以这个例子为例进行类比讲解。因为后面还会牵扯到很多计算和数学公式,使用这个例子我们就可以和Sliver的课件对答案,以防讲解有误。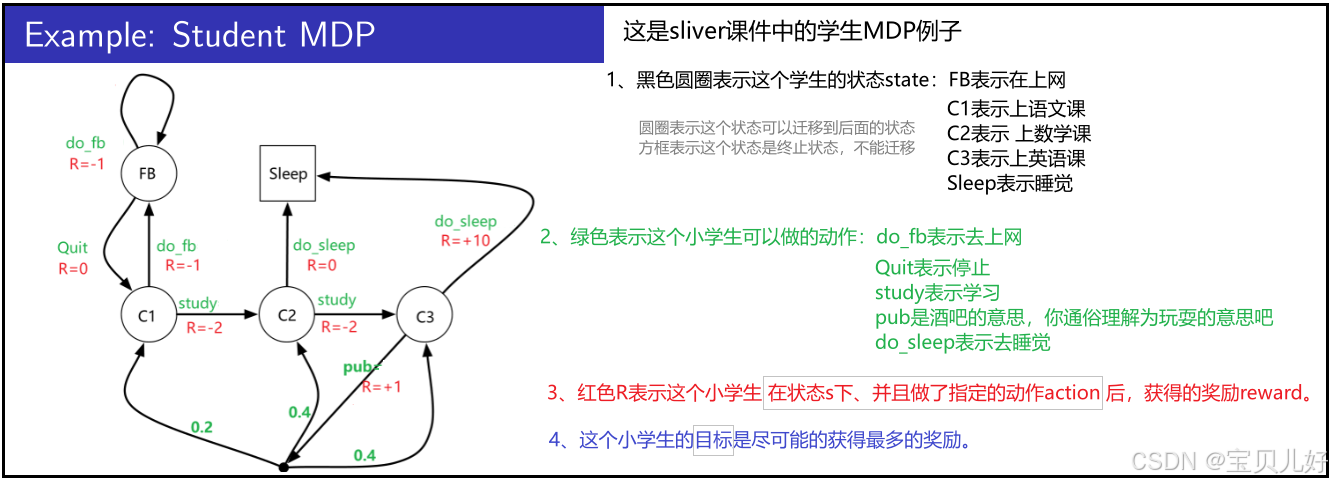
这个学生例子,你完全可以迁移到打简单的小游戏、棋牌等例子中。
1、初步解读学生例子,引出agent、马尔科夫决策链、幕、分幕等概念
(1)你可以把这个小学生看成一个Agent,一个智能体,那上图1就是一个系统。所以有时我们也给学生MDP叫系统。
(2)上图2是直观的展示,这个系统的状态(state)、动作(action)、奖励(reward)三个因素是如何发生的。
(3)上图3是从这个系统中的一个随机采样。
假如我们自己就是这个小学生,我们在上左图随机走一圈,也就是随机采样,就会生成一条具体的马尔可夫决策链,如上图右下角的链条。这样的链条我们叫马尔可夫决策链。这个采样过程叫马尔可夫决策过程, Markov Decision Processes, 简称MDP。当我们多次采样,就会生成多条马尔可夫决策链,此时每条链我们叫它幕,多次采样叫分幕。
通俗的理解就是:一条马尔科夫决策链就是这个小学生过了一天。分幕就是这个小学生过了多天。你类比到游戏里就是打一局游戏和打多局游戏的意思。
2、从学生例子中,抽取MDP和策略Policy的数学定义
上面我把这个小学生看成一个智能体agent,那么MDP中的行动action,就是由这个智能体做出的,所以我们还得引入策略(Policy)这个概念。就是这个agent要按照某个策略来做出行动。下面用数学语言进一步描述MDP和Policy:
3、状态(state)和行动(action)都是有限的。
本例中只有5种状态:fb,c1,c2,c3,sleep,你可通俗理解为:上网,上语文,上数学,上英语,睡觉这5种状态。
行动恰巧也只有5种行动:do_fb,quit, study, do_sp, pub,你可以通俗理解为:去上网,离开,去学习,去睡觉,去酒吧。
一个状态可以对应多个动作,一个动作也可属于多个状态。
4、策略Policy:智能体是如何做出行动的?
智能体在某个状态下做出某个动作,是由智能体的策略来决定的。智能体只需要基于当前状态即可决定其行动,因为状态具有马尔可夫性,马尔科夫性就是当前状态就已经充分反映了过去的所有,过去即当下、未来只与当前有关。所以智能体只需要根据当前的状态就可以做出行动。
智能体在当前状态下的动作是由智能体的策略函数(Policy)来决定的。策略函数的输入是智能体的当前状态s_t,输出是当前动作a_t的概率。因为是概率,所以策略可以分确定性策略和随机策略:
也所以,智能体的策略函数可以写成表格的形式。根据表格,只需要查询当前状态,就可以知道所有动作的概率值。如果概率值是0和1就是确定性策略,0-1之间就是随机策略: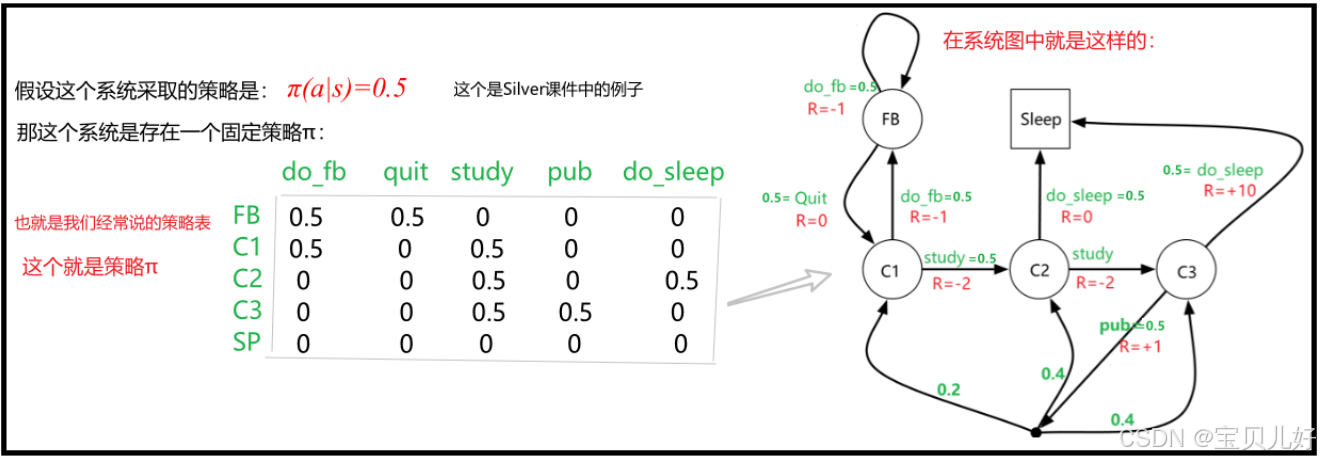
说明:
(1)上图是策略Π=0.5的策略函数。不同agent可以有不同的策略函数。一个agent只能有一个策略函数。
通俗理解就是不同人会有不同的策略函数,比如小白的策略Π就比较low,只能得到很少的奖励;高手的策略Π非常厉害,可以得到很高的奖励。所以小白和高手的策略函数是不同的。就是小白和高手拥有的是不同的Π。
同一个人在一局游戏中只会有一个策略Π。比如小白第一次玩这个游戏,没经验,他使用的策略Π很low,得了很低的奖励。当这个小白打了无数次游戏后,他有经验了,他在下一轮游戏中就会采取很厉害的策略Π,这个小白就变成了高手。所以小白变高手的过程也是不断更新自己的策略的过程。
(2)以后我们要寻找最优策略时,找的就是确定性策略。这个后面学了状态价值后再继续展开讲。
5、状态迁移:状态是如何迁移的?
在MDP中,Agent是在某个状态下、做出某个动作后,才发生状态迁移的。在MDP中,状态转移是不需要过去的信息。就是此前系统处于什么状态、执行了什么动作都不重要。因为马尔可夫链有马尔可夫性。未来St+1的状态只与St有关。就是未来只与当下有关。也所以我们会经常把生活中的很多事情抽象成马尔科夫链,抽象成这个数学工具后,复杂的事情就变得简单了。t+1时刻的状态只与t时刻的状态有关,与其他状态无关。
(1)从系统图中我们可以看到状态迁移也是分确定性状态迁移和随机性状态迁移: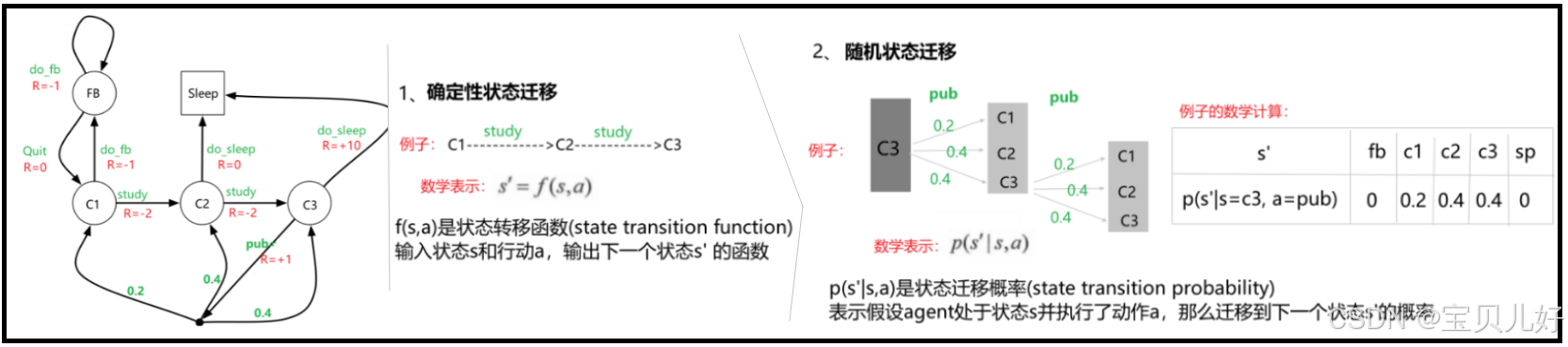
确定性状态迁移,得到的st+1就是一个确定的状态。如上图1中的例子,在C1状态下,只要agent做了study动作,那agent的状态就一定会迁移到C2状态。
随机性状态迁移,st+1就是一个概率值,就是一个随机状态。如上图2中的例子,在C3状态下,只要agent做了pub动作,那agent的状态会被系统以0.2\0.4\0.4的概率随机迁移到C1\C2\C3状态。这个概率分布你可以认为是系统提前预设的。
(2)状态迁移函数
不管是确定性状态迁移还是随机性状态迁移,我们都可以把它统一到状态迁移函数中,状态迁移函数的输入是当前状态s_t和当前动作a_t,输出是下一个状态s_t+1的发生概率。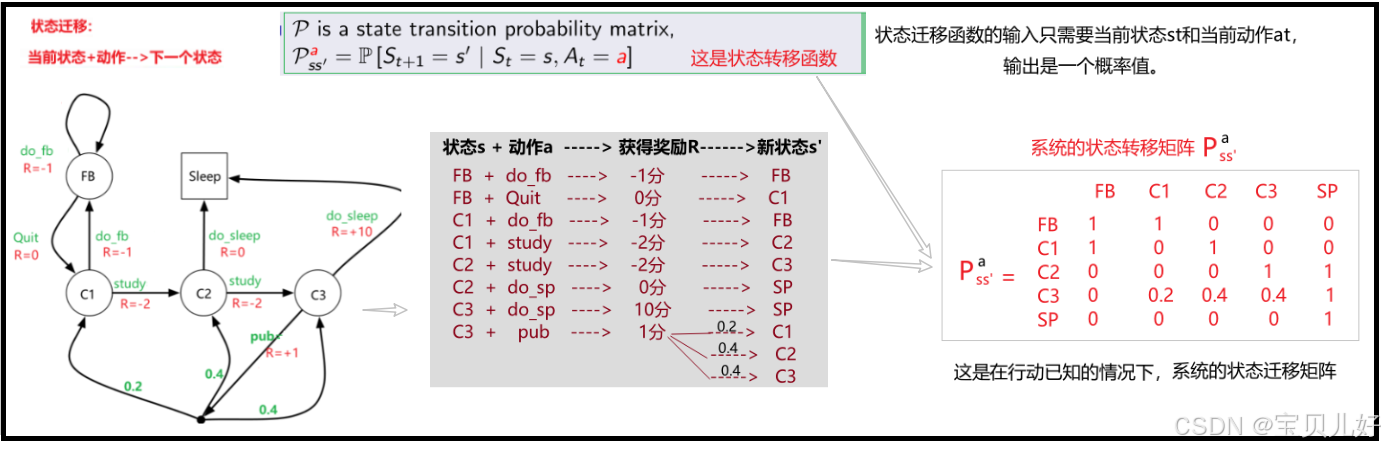
确定状态迁移就是指Pa矩阵中,状态与状态之间的转化概率是1的那些情况(当然喽,概率为1嘛)。随机状态迁移是指哪些在0-1之间的情况,就是状态与状态之间的转化是一个概率值。上图中概率值你可以认为是系统提前预设的。
(3)继续深入分析:
从上面的分析我们可以知道,Pa是在状态和动作都已经发生的条件下,下一个状态s'的迁移概率。
现在假设我只知道t时刻的状态s,我不知道t时刻的s状态下,agent做了什么action,那我能不能求出t->t+1时刻,状态s是如何迁移到s'的?当然可以,此时我们假设策略Π是固定的-->策略固定了,动作就固定了-->动作固定了,下一时刻状态也就固定了: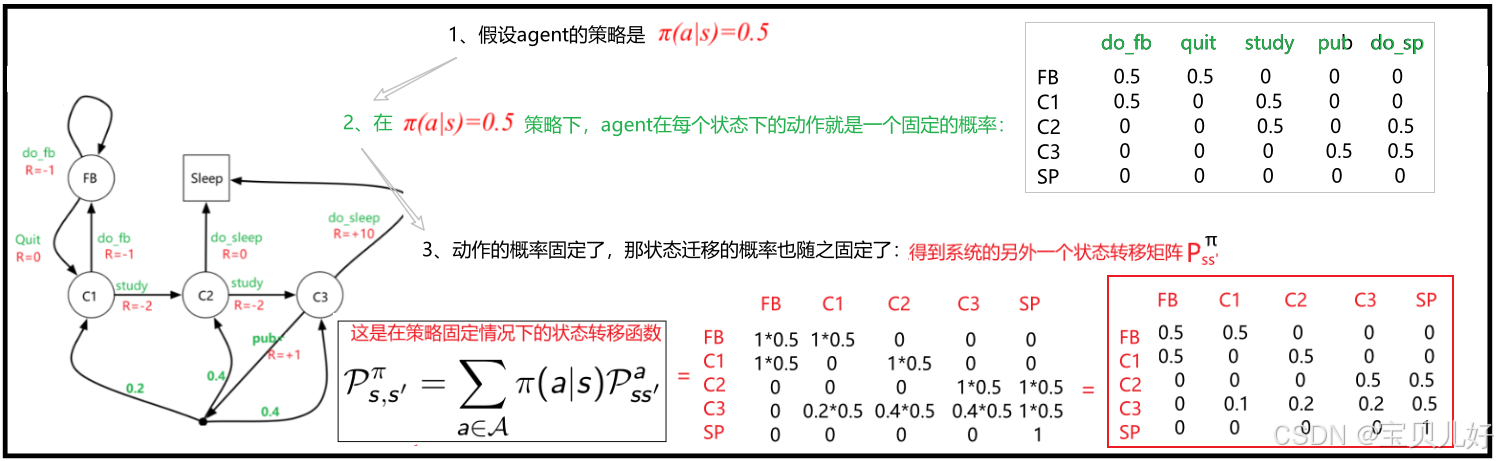
Pπ矩阵是指在系统策略固定的情况下,系统状态从t时刻到t+1时刻的状态迁移矩阵。因为策略是一个随机性策略,也就是动作是随机的,那动作随机就导致状态迁移也是随机的。所以Pπ矩阵中的状态迁移都是随机迁移的。
(4)一定要注意区分Pa矩阵和Pπ矩阵,尤其是后面数学推导部分,经常有这两个符号出现。
6、奖励Reward:系统是如何给与奖励的?
奖励是强化学习中的灵魂,就类似监督学习中的损失函数一样,它是序列决策中的牵引力量,所以系统的奖励设计和分配是和模型效果强相关的!
(1)在强化学习中,我们一般假设奖励的发放是确定性的,所以奖励发生的时间我们一般是定义在t+1时刻得到t时刻的奖励。所以,下图的定义1,silver课件中的定义,这个奖励函数的输出是一个t+1时刻的期望奖励。因为是期望奖励,所以silver的奖励函数的输入只需要当前状态st和当前动作at。但有的资料用的是定义2,奖励函数的输入是st、at、st+1,输出是t时刻的奖励:
对于确定性的状态迁移,只要agent处于状态s,并执行了动作a,那状态就一定转移到s',到s'就是t+1时刻,那自然也得到了t时刻的奖励。此时的奖励分数只于s和a有关。定义1中的期望E里面就是一个实数,E(实数)=这个实数。定义2中的s'就可有可无,因为一定会走到s'的嘛。
对于系统设置的随机状态迁移,Rt+1不仅与s、a有关还和系统迁移有关,所以定义1是一个求期望的过程。如上图A处所示,系统给的R+=1是指只要在C3状态并且执行了了pub动作,就会得到1分的奖励。所以此时你用定义1计算时就不用求期望了,这个奖励值就已经是一个期望值了。但是如果你要用定义2,由于状态转移是系统自动执行的,所以此时输不输入s'都无所谓,在状态C3下执行pub就是奖励1分。如果你要计算t+1时刻的奖励,此时你才需要分开计算奖励。
可见两个定义在本质上其实是不冲突的,就是使用场合不一样。
(2)MDP中的奖励也是分Ra和Rπ的:
你可以类比状态转移的Pa和Pπ。Ra表示agent处于状态s,并执行了动作a后可以获得的系统奖励的期望。Rπ则表示策略固定的情况下的奖励,下图是两种奖励的计算过程: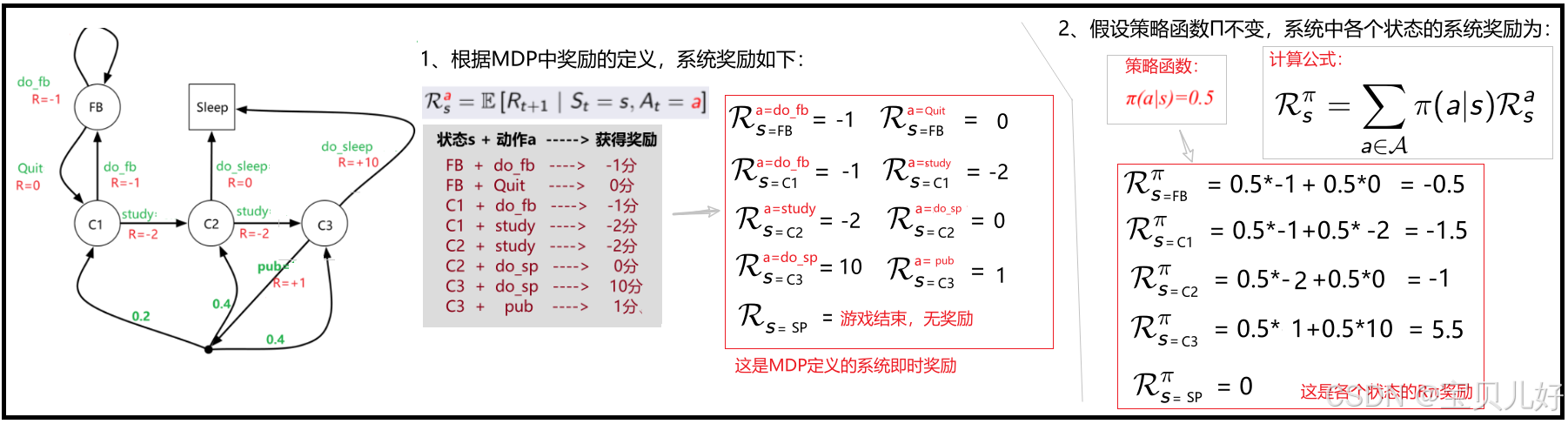
Ra是MDP定义的系统即时奖励。Rπ是在π策略下的系统奖励。 一定要注意区分,后面计算要用到。
7、小结:MDP框架
至此,我已经用数学语言描述智能体在环境中的行动。(你可以把状态s和奖励r看成环境Environment):
一是把silver课件中的MDP定义中出现的数学符号都一一详细解释了一遍,这些符号是后面推导价值函数的基础,一定要搞清楚。(除了γ,这个放后面讲状态收益时讲)
二是重点拆解了:
(1)策略是如何决定行动的?
(2)状态是如何迁移的?
(3)奖励是如何发放的?
至此我们总结马尔可夫决策过程就是:智能体根据策略π(a|s)采取行动(行动可以是确定的行动也可以是有概率分布的随机行动)-->系统根据当前状态和行动进行状态转移Pa(这个转移也可以是确定性转移,也可以是系统内部制造的随机转移,形成概率分布)-->系统根据新的状态s'给agent发奖励。如此反复的过程,就是马尔可夫决策过程: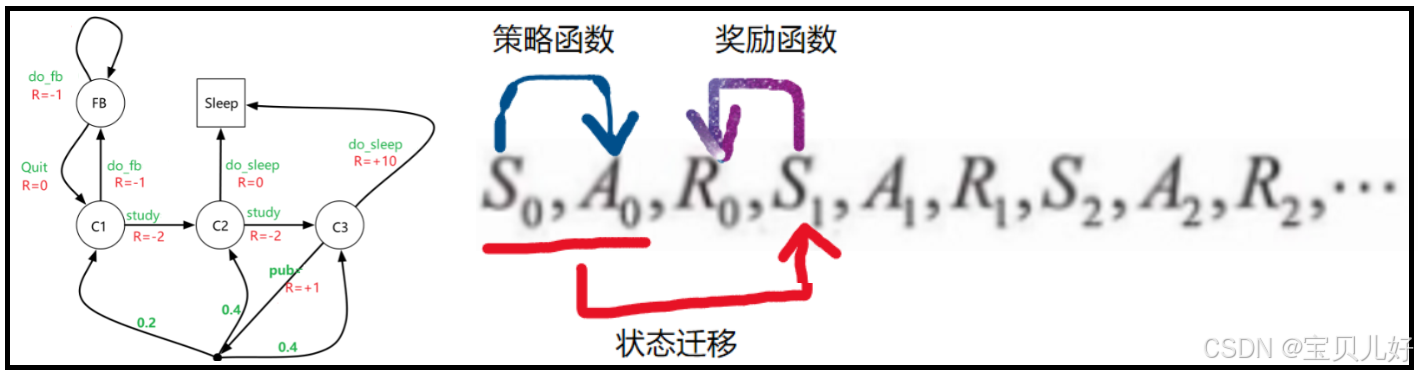
这就是MDP框架,所有的MDP链都是在这个框架中随机采样得到的。
由此,我们把生活中的问题抽象成了一个MDP问题,并从中抽取MDP框架中各个环节的计算公式。
三、从MDP目标-->状态收益-->状态价值函数-->状态价值函数的贝尔曼期望方程-->状态价值函数的贝尔曼方程
MDP的目标是奖励reward最大化。类比这个小学生就是如何让自己的一天得到更多的奖励。
这个小学生想得到最多的奖励,就要找到最优策略(optimal policy)。通过这个最优策略,这个学生就会做出最优的动作-->最优的动作会走出一条最优的状态序列-->最优的状态序列就是获得奖励最多的序列。
假设我们自己就是这个小学生,假设我们现在在C2状态:
可见,每个状态的奖励不仅仅是达到这个状态能获得的系统奖励,还包括这个状态之后的其他状态可能获取的奖励。那我们把这些所有可能获取的奖励都算上,那就是这个状态的收益了。所以这里我们要引出了一个新概念:状态收益。有了状态收益,我们的行动action就不会只参考下一个状态s'的系统奖励了,而是可以跟着下一个状态的收益值走,就是选择收益高的状态,而非系统奖励高的状态。这样就能做到为获取未来更多的奖励,可以暂时牺牲当前奖励,从而使最终奖励达到最多!
1、状态收益(return)
(1)如何度量状态收益?
状态收益的公式和计算现金的当前价值一模一样,所以γ也叫折现率。
(1)折扣因子γ的取值要在0-1之间。
一是,γ的存在是为了防止连续性任务的收益变得无穷大。在连续性任务中,如果γ=1,那收益就会发散到无穷大。所以γ是为了防止收益发散的。γ在0-1之间可以迅速弱化后面收益的比重,如上图r=0.5,在第5步的奖励就几乎可以被忽略了。
二是,γ一定程度上也可以表示这个智能体是走一步考虑后面的几步? 当γ=0表示智能体只往后看一步。就是这个智能体只考虑迁移到下一个状况可以得到多少系统奖励。下一个状态的系统奖励是Rt+1嘛。此时这个智能体追求的只是眼前奖励的最大化。当γ=1表示智能体一直看到了游戏的结束。此时这个智能体追求的就是全局游戏的奖励最大化。
(2)折扣因子γ的取值也不能过大!
假如你让γ=1,就是计算了状态s后面的所有可能状态的系统奖励。但是后面的t+1,t+2,t+3,t+4....等状态不是确定状态啊,因为策略是随机的、系统状态转移也是随机的,所以后面时刻的状态早已不是t时刻预设的链路了,那按预设的链路计算出来的状态收益就是一个不太靠谱的参考数字,按照这个不靠谱的度量来指导策略的指定,肯定也是瞎指挥的。
所以,强化学习本质上就是一个序列决策问题,是一个reward的设计和分配问题,所以γ的取值要和reward匹配,否则效果欠佳!
(3)状态收益和智能体的策略函数、状态迁移函数有关
只有智能体的随机策略固定下来+系统的随机状态迁移也固定下来,这样生成的一条具体的状态序列中,我们才能计算出每个状态的收益值。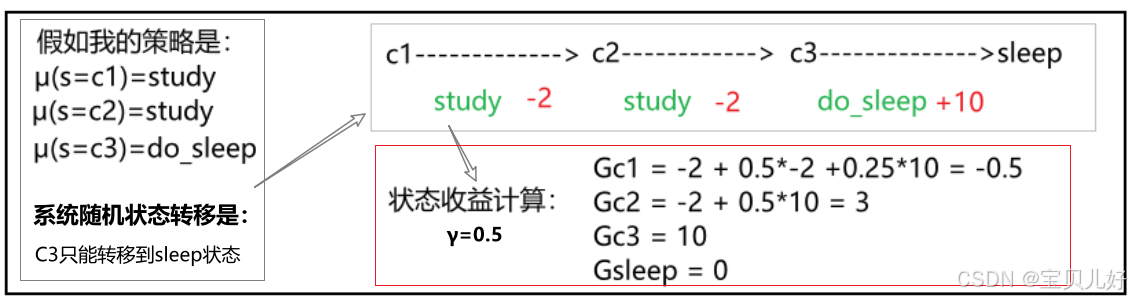
所以,每个状态的收益是要从一条条具体的马尔可夫决策链中算得的。而由于策略的随机性和状态迁移的随机性,状态收益也会呈现出随机性的特点!
那是不是无法度量系统中各个状态的收益了?!不是的,因为策略函数是一个概率分布、系统迁移也是一个概率分布,这些因素虽然都是随机性的,但我们是知道其概率分布的。知道概率分布不就可以用期望来度量了!所以此处我们再引入一个新概念:状态价值函数。
2、状态价值函数
状态价值函数是收益(return)的期望值,其数学定义如下: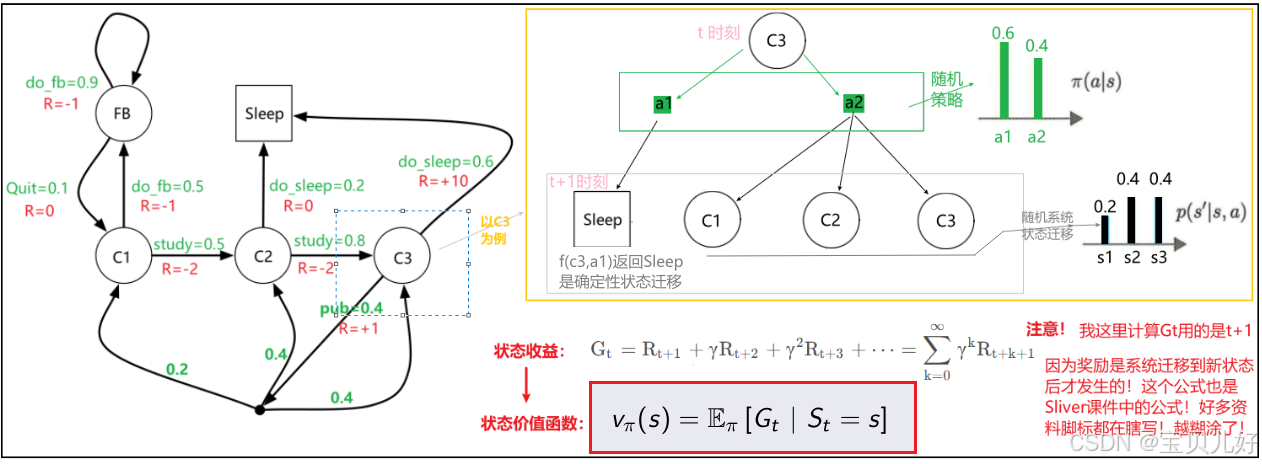
上图红框中的公式就是状态价值函数。
上图举了C3状态的例子:在St=C3时,C3的收益的期望就是就是C3的状态价值。可见,在策略函数随机、系统状态迁移随机的双随机下,我们是可以通过求收益的期望来计算状态的长期价值的。
3、状态价值函数的贝尔曼期望方程
前面我们写出了状态价值函数的数学表达公式,这个公式是个期望,但是我们又不知道概率分布,所以是没法计算的。除非我们随机生成足够多条幕,然后逐幕计算链条上的各个状态的收益,然后求一个平均当作期望。但是这种操作很多情况下是不可行的。所以急需另外的求解方法。于是状态价值函数的贝尔曼期望方程诞生了:
上图就是状态价值函数的贝尔曼期望方程的推导过程,其中最难的部分就是如何将概率条件从st=s变成st+1=s'的形式。换句话说,就是要进入下一个时刻了,该下一时刻的状态的价值函数出场了: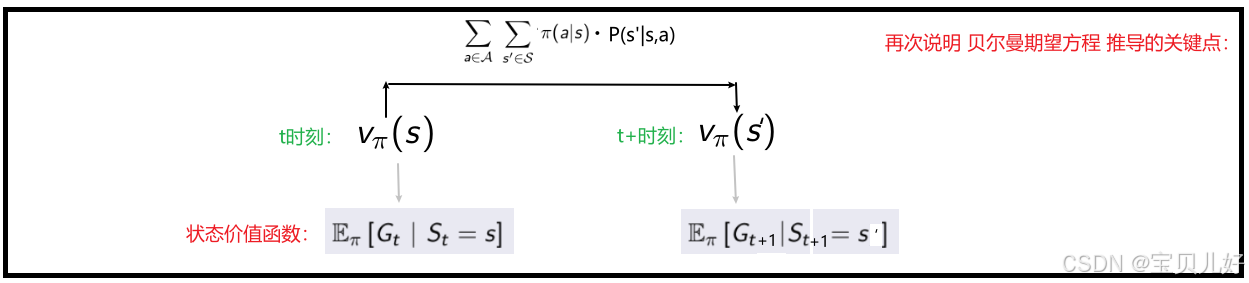
可见,贝尔曼期望方程是对状态价值函数的进一步推导得到的,利用贝尔曼期望方程就可以让状态价值函数变得可以求解。因为贝尔曼期望方程把状态s的价值函数和下一时刻所有可能的状态s'的价值函数之间的关系建立起来了。本来是无限计算的状态收益,我们通过贝尔曼期望方程,将其转化为两步就可以列出状态价值之间的关系。下面针对小学生的例子,用贝尔曼期望方程手动列出所有状态之间的关系: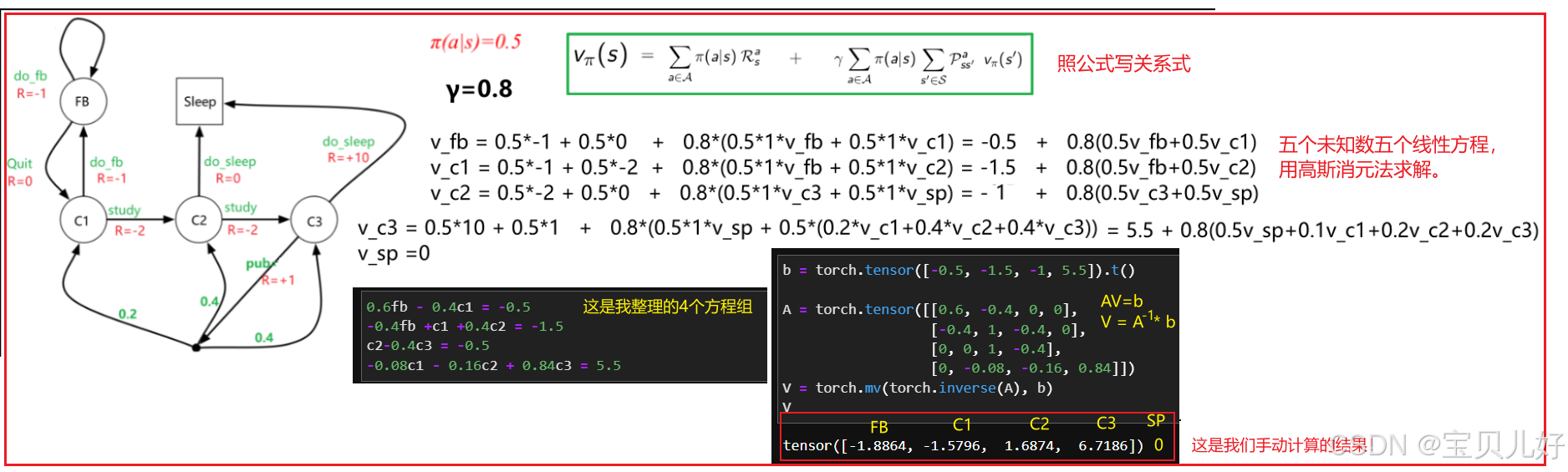
五个方程五个未知数,是一个一次线性方程组,用高斯消元法解即可。上图我用了矩阵求逆解。
所以贝尔曼期望方程能够将无限的计算转换为有限的联立方程。尽管问题中存在随机性行动、随机性状态迁移,我们还是通过有限的联立方程组求出了状态价值。
4、状态价值函数的贝尔曼方程
贝尔曼期望方程是对所有状态s和所有策略Π都成立的等式。当我们把策略的随机性打掉后,贝尔曼期望方程就会坍塌成贝尔曼方程。贝尔曼方程可以用矩阵形式来表示,这样就可以推导出状态价值的解析解了,这样计算就更方便了。所以下面我们继续推导贝尔曼期望方程: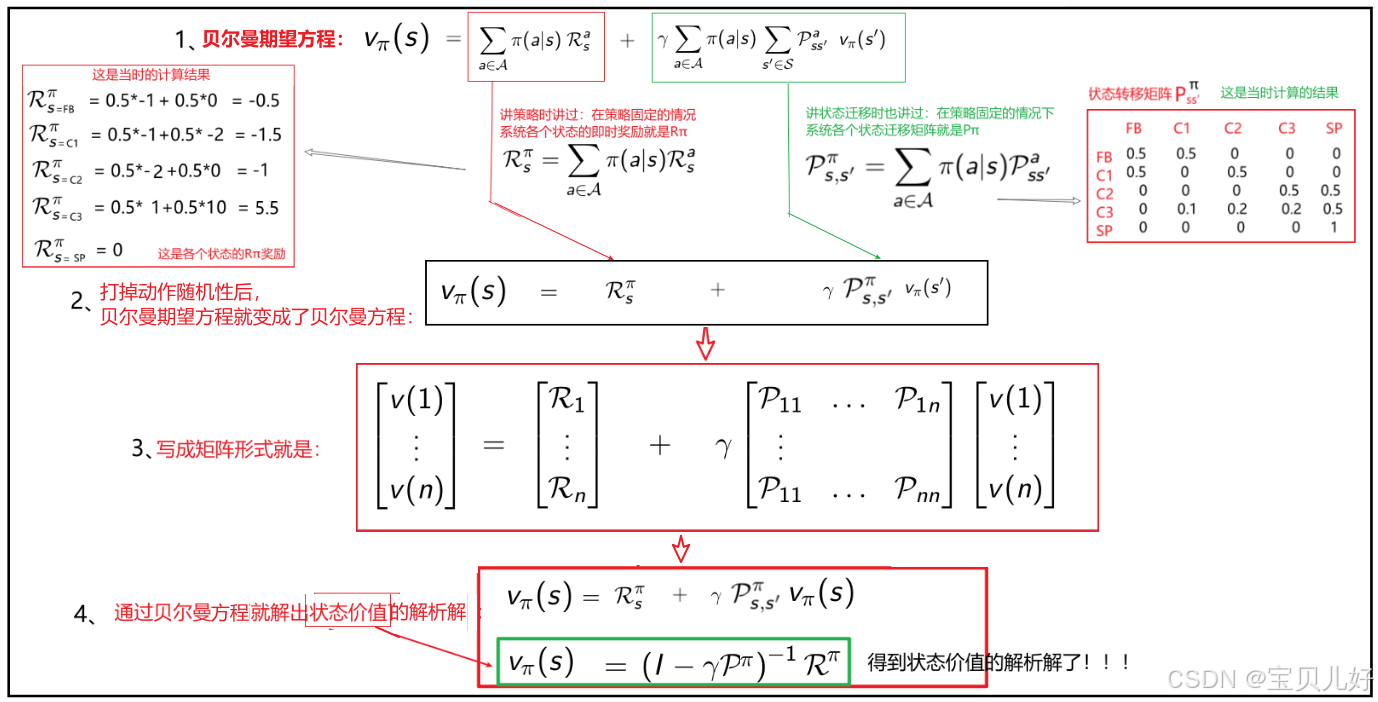
那现在我们直接用上面绿框中解析解来计算系统各个状态的价值,看看和Silver的课件上计算结果一样不一样: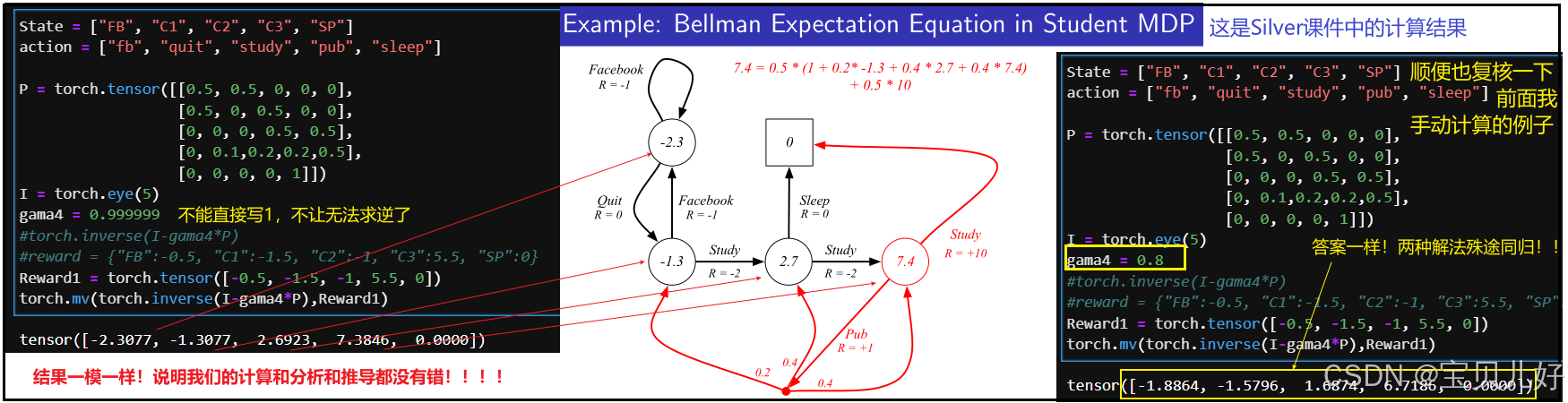
至此,我们通过贝尔曼方程,就求出了在策略Π下的状态价值。
四、行动价值函数、行动价值函数的贝尔曼期望方程
1、行动价值函数(action-value function)
只要我们能深刻理解上面讲的状态价值函数以及状态价值函数的贝尔曼期望方程,这个行动价值函数就非常好理解,下面我再给大家串联一下上面的内容,引出行动价值函数的定义:
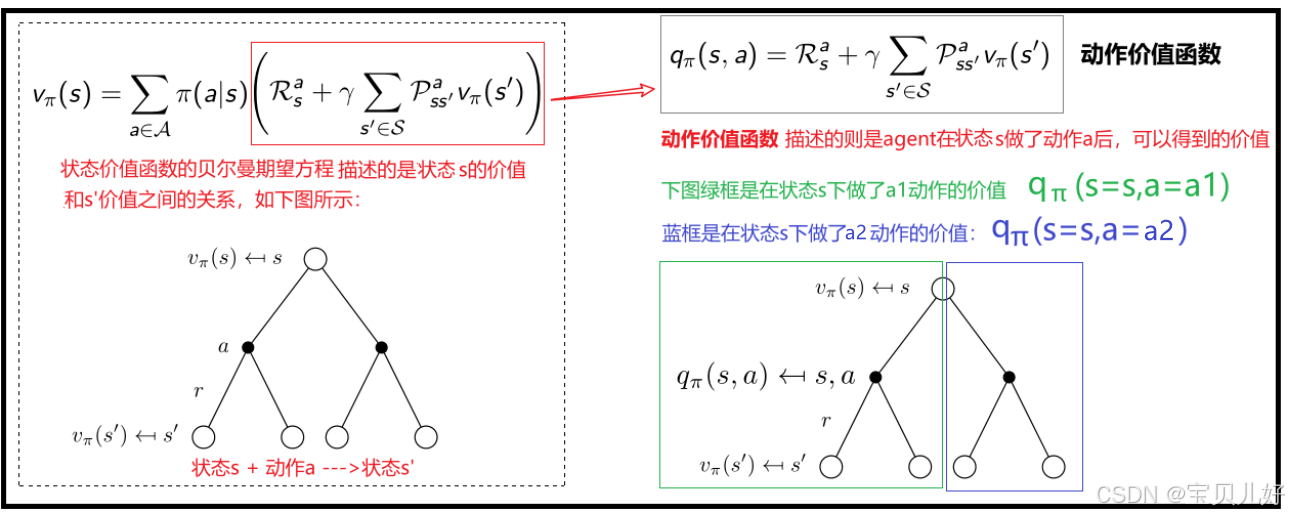
动作价值函数和状态价值函数之间的关系:
2、行动价值函数的贝尔曼期望方程
(1)和状态价值函数的贝尔曼期望方程的推导一样:
3、状态价值函数和动作价值函数之间的相互关系:
4、手动算一下小学生例子中的动作价值: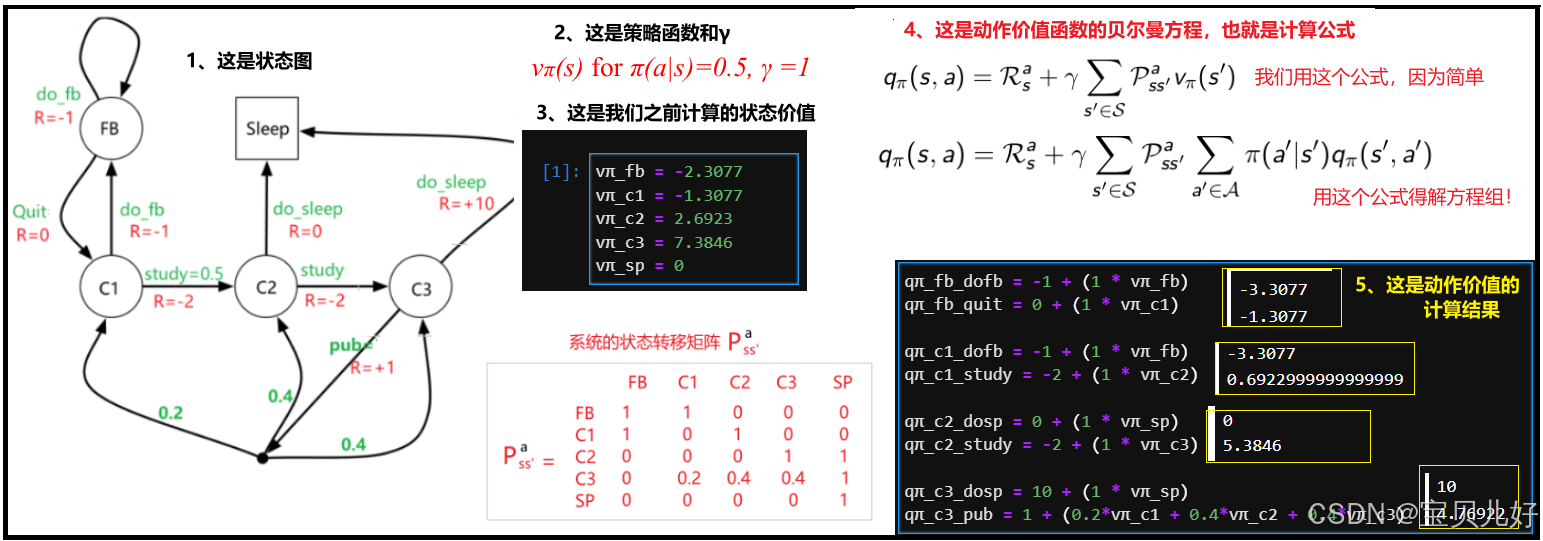
计算的对不对呢?我们验证一下:
至此,我们定义了什么是动作价值函数,推导了动作价值函数的贝尔曼期望方程,梳理了状态价值函数和动作价值函数之间的关系。用学生的例子计算了这个学生的动作价值,并进了的验证。可以理解为前期的准备工作做完了,暂告一段落!下面我对上面的内容做一个总结: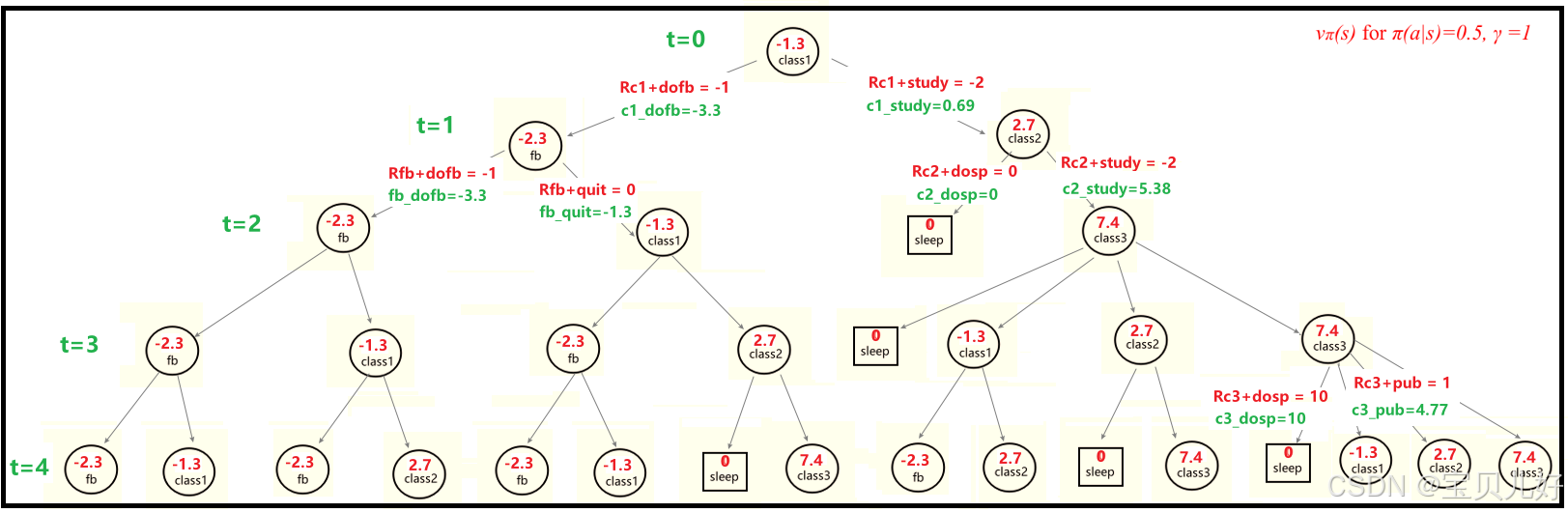

五、最优策略和最优价值函数->贝尔曼最优方程-> 贝尔曼最优方程的求解->最优动作->最优策略
1、最优策略和最优价值函数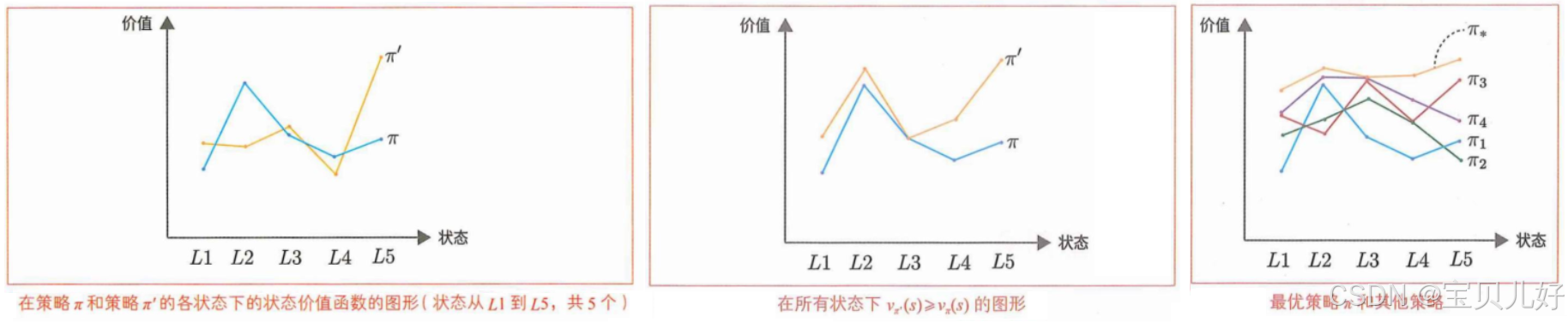
(1)上图中的牌π、π'、π1、π2、π3、π* 指的都是不同的策略。图中的曲线是在不同策略下计算出来的系统所有状态的价值。
(2)上左图中,在某个状态下Vπ'(s)>Vπ(s),在另外一些状态下Vπ'(s)<Vπ(s)。比如状态L1在策略π'下的价值大于π策略下的价值,但是状态L2却是π策略下的价值大于π'下的价值。此时策略π和策略π'是没有优劣之分。就是两个策略都一样,没有好坏。
(3)上中图,系统中的所有状态在π'策略下的价值都大于π策略下的价值,即Vπ'(s)>Vπ(s)。此时我们可以说策略π'优于策略π,就是策略π'比策略π更好。这是因为无论从哪个状态开始,使用策略π'获得的奖励之和的期望值都比使用策略π获得的大(或相等)。
(4)上右图,当所有状态下的某个策略的状态价值函数的值都大于其他任何策略时,这个策略就是最优策略,我们一般用π*表示。最优策略下的状态价值函数叫最优状态价值函数optimal state-value function。我们一般用v*来表示最优状态价值函数。
在MDP中,至少存在一个最优策略。而且最优策略是确定性策略。在确定性策略下,每个状态下的行动是唯一确定的。据说可以用数学公式来证明在MDP中至少有一个最优的确定性策略。感兴趣的同学可自行查找资料,这里我省略了。
“在MDP中至少存在一个最优策略,而且最优策略是确定性策略”,这句话的言外之意就是,一个系统可能会存在多个确定性的最优策略,比如Vπ'(s)=Vπ"(s)这种情况,此时我们可以说策略π'和策略π"是同样好的最优策略。此时π'和π"虽不同,但二者对应的状态价值都是一样的!就是二者的价值函数的值是相同的!就好比两个高手玩同一款游戏,两个高手的策略虽然不同,但二人都能打到同一个高分,那这两个人的策略就都是最优策略,二人的价值函数的值都是相同的。
2、贝尔曼最优方程
一是,我们要获得最多奖励-->就要找到最优的策略-->而最优策略是使所有状态下的状态价值函数最大化的策略-->所以问题转化为求最优状态价值函数的问题。
二是,动作价值函数是状态价值函数的一个组成部分,最优状态价值知道了-->最优动作价值自然就知道了-->知道了最优动作,我们就立刻能得到最优策略-->也就获取了最多的奖励。
这也是为什么我们前面花极重的笔墨一直在算状态价值、动作价值的原因。
由于我们前面推导的状态价值函数Vπ(s)的贝尔曼方程和动作价值函数qπ(s,a)的贝尔曼方程是对所有的策略(确定/随机)都成立的方程,那对最优策略π*自然也成立。但是最优策略π*是一个确定性策略,所以状态价值函数Vπ(s)的贝尔曼方程和动作价值函数qπ(s,a)的贝尔曼方程会坍塌成一个更加简单的形式: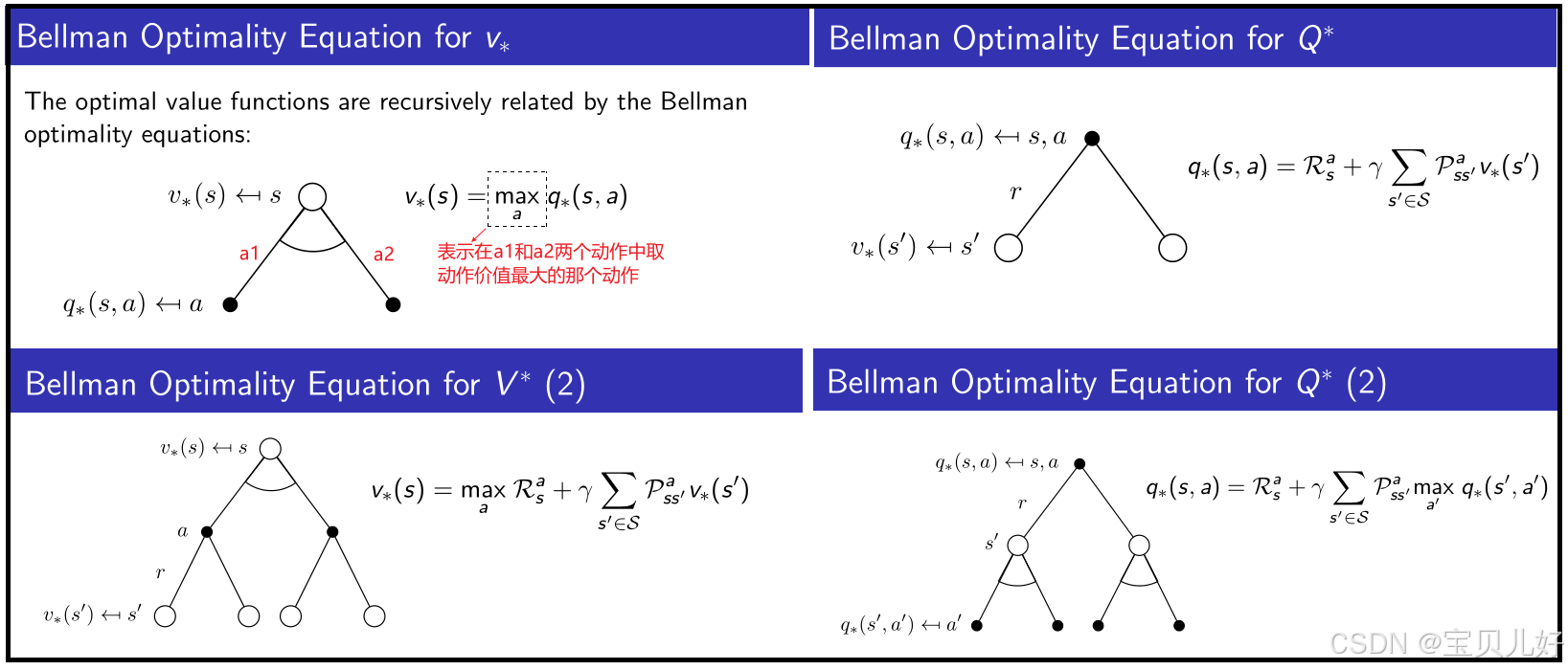
上面4个公式就是贝尔曼最优方程。前面理解的透彻后,这里就会秒懂。下面我用学生的例子,根据最优状态价值函数的贝尔曼最优方程,列出最优策略下的状态价值函数之间的关系:
3、贝尔曼最优方程的求解
上图中的max表示要分别计算后,再进行对比,取二者中的最大值,所以max函数是非线性的,所以上面的方程组是非线性方程组。那这样的方程组如何求解呢?最原始的方法就是手动配对,2x2x2x2=16组方程组,然后分别计算,取最大的那组解。手动配对虽然容易理解,但实在低效,实际中,我们一般都是用值迭代(Value Iteration),通过反复更新逼近最优解,直到收敛: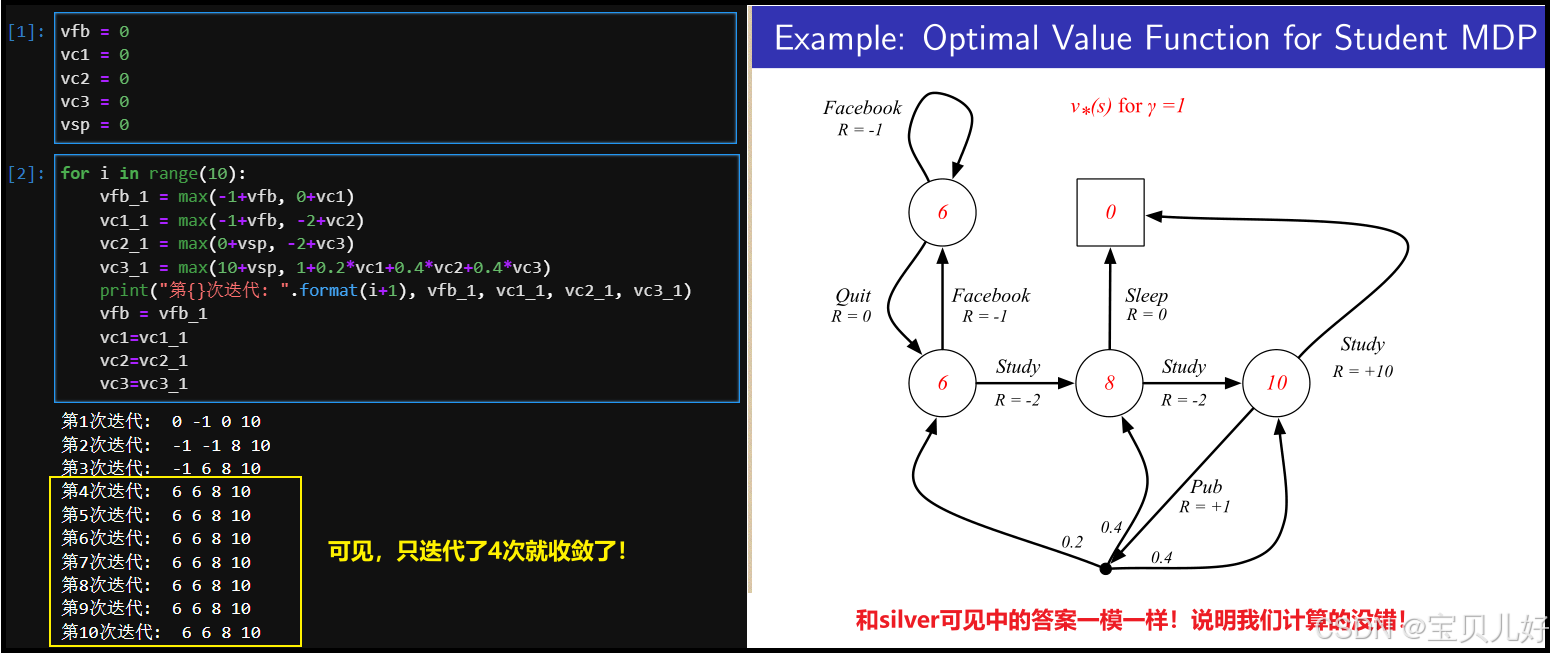
4、最优动作
求出了最优状态价值,就等于求出了最优动作价值:
上图A处:这是silver的课件,是2015年DeepMind发布的公开课课件,十年了,有多少人看,居然没有一个人发现里面这个小小的错误!他忘记加1分的系统奖励了!
5、最优策略
知道了最优动作价值,就是知道了最优策略: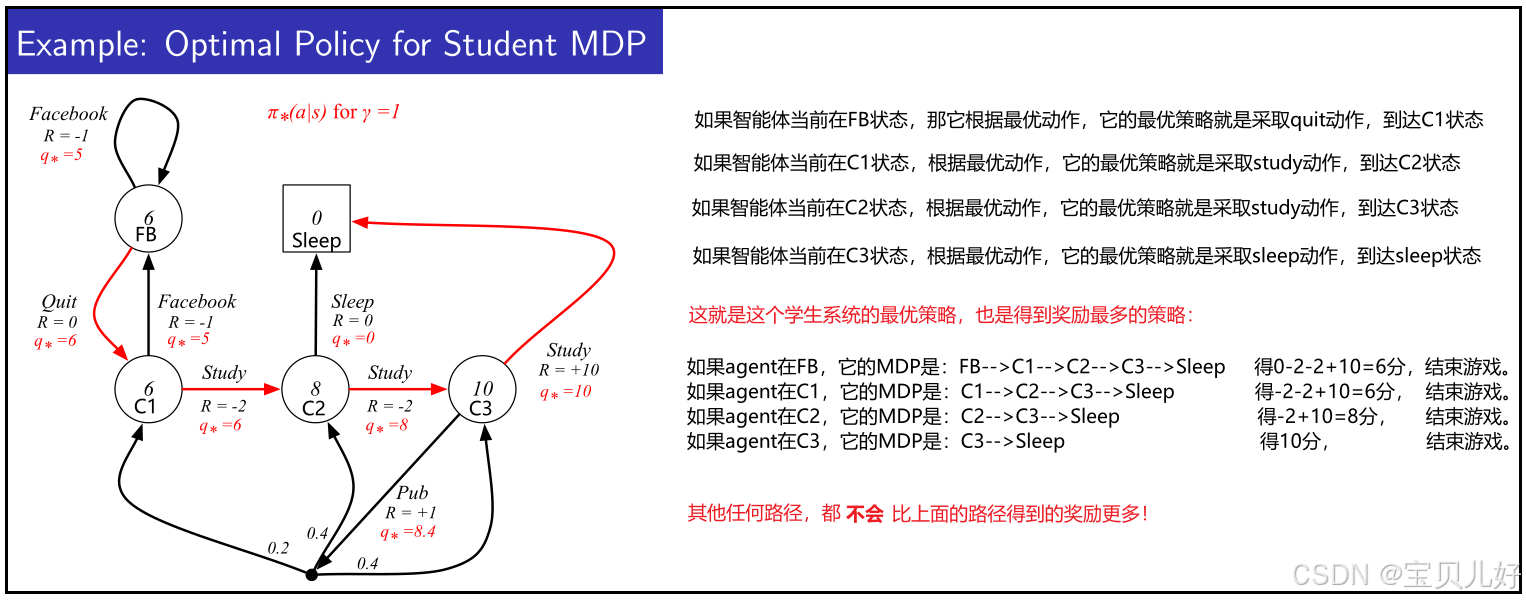
最优策略对应的就是最多的系统奖励。也就是我们的智能体从小白变成了高手。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)