Spring AI:文生视频 - wanx2.1-i2v-plus
Spring AI:文生视频 - wanx2.1-i2v-plus
历史文章
Spring AI:对接DeepSeek实战
Spring AI:对接官方 DeepSeek-R1 模型 —— 实现推理效果
Spring AI:ChatClient实现对话效果
Spring AI:使用 Advisor 组件 - 打印请求大模型出入参日志
Spring AI:ChatMemory 实现聊天记忆功能
Spring AI:本地安装 Ollama 并运行 Qwen3 模型
Spring AI:提示词工程
Spring AI:提示词工程 - Prompt 角色分类(系统角色与用户角色)
Spring AI:基于 “助手角色” 消息实现聊天记忆功能
Spring AI:结构化输出 - 大模型响应内容
Spring AI:Docker 安装 Cassandra 5.x(限制内存占用)&& CQL
Spring AI:整合 Cassandra - 实现聊天消息持久化
Spring AI:多模态 AI 大模型
Spring AI:文生图:调用通义万相 AI 大模型
Spring AI:文生音频 - cosyvoice-V2
本文中,我们感受一下 “文生视频” 的魅力 —— 只需一张静态图片,加一段提示词。
介绍
文生视频(Text-to-Video)是指利用人工智能技术,根据用户输入的文本描述(Prompt),自动生成一段符合描述的视频内容的技术。它代表了生成式人工智能(Generative AI)在视频创作领域的重大突破。
其应用场景如下:
- 营销与广告: 快速制作吸睛的社交媒体短视频、产品广告、个性化营销内容、动态广告素材。
- 内容创作: 为自媒体、短视频平台生成创意短片、故事片段、个性化表达内容。
- 影视与创意产业:
前期制作: 生成概念图、动态故事板、特效预演。
素材补充: 创建难以实拍的背景、场景或特效镜头(尤其对低成本制作)。 - 教育科普: 将抽象概念、历史事件、科学原理可视化为生动视频,制作个性化学习资料和科普短片。
- 游戏与虚拟世界: 生成游戏过场动画、动态场景、NPC行为动画,加速元宇宙内容构建。
- 电商展示: 自动生成多角度、多场景的产品展示视频和虚拟试用体验视频。
- 新闻媒体: 快速将复杂信息或突发新闻转化为动态信息图/短视频(必要时用于模拟场景还原)。
- 设计与艺术: 作为创意探索工具,快速生成视觉风格、动态效果,为设计提供动态素材。
挑选大模型
进入到阿里百炼的模型广场 ,筛选出 “视频生成” 下的 AI 大模型,这里我们选择的是 “通义万相2.1-图生视频-Plus” 模型,它可以让图片变为动态视频,支持大幅度复杂运动、物理规律遵循、丰富艺术风格和影视级画面质感,指令遵循能力进一步提升,视频质量相对更高。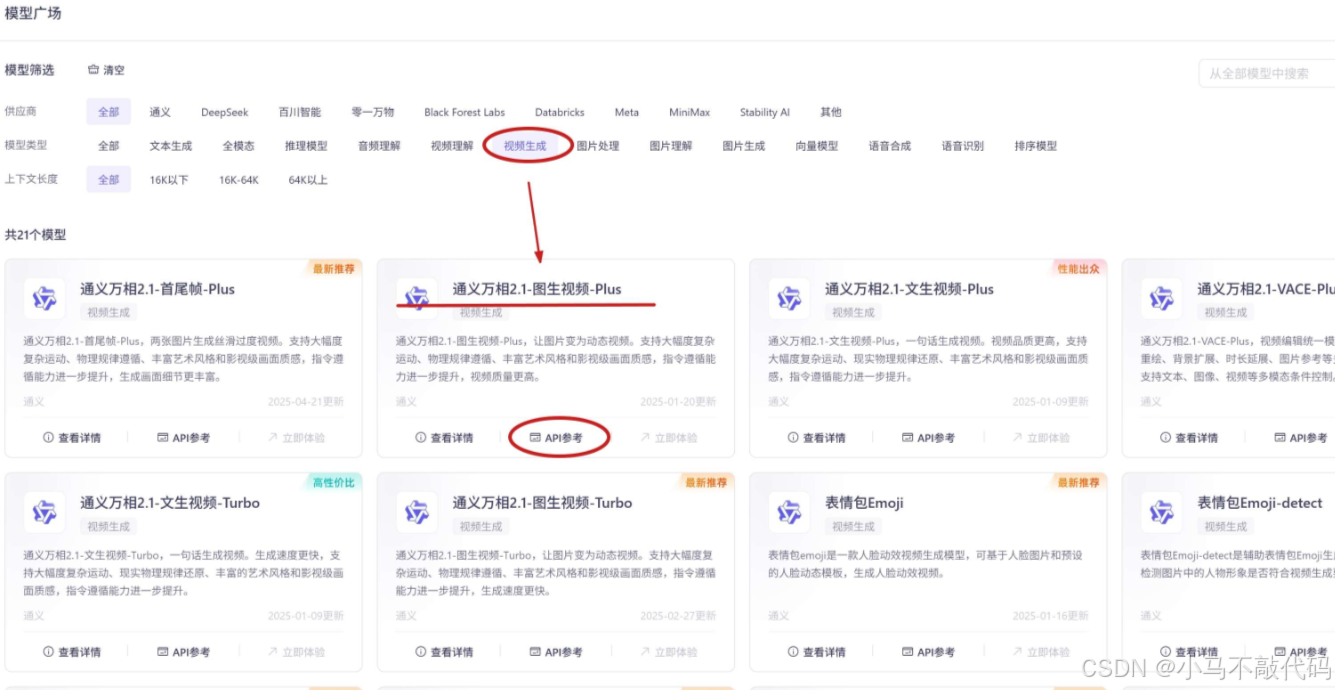
点击 “API参考” , 可查看模型的详细文档,一共包含 2 种类型的模型,以及其计费方式:
- wanx2.1-i2v-turbo: 生成速度更快,耗时仅为plus模型的三分之一,性价比更高。计费价格为 0.24元/秒。
- wanx2.1-i2v-plus: 生成细节更丰富,画面更具质感。计费价格为 0.70元/秒。
以上两款模型,各自都拥有 200s 的免费生成额度。
准备一张静态图片
让我们准备一张小姐姐图片,放到某个路径下,我这里是放到了 D:/ 盘下,等会基于它来转换为视频:

新增 Controller 控制器
在 /controller 包,新建一个 Text2VideoController 控制器,并声明 /v12/ai/text2video 文生视频接口,代码如下:
spring.ai.openai.api-key的值获取你自己的阿里百练平台上的key,可以看上篇文章
Spring AI:多模态 AI 大模型
@RestController
@RequestMapping("/v12/ai")
@Slf4j
public class Text2VideoController {
@Value("${spring.ai.openai.api-key}")
private String apiKey;
/**
* 调用阿里百炼图生视频大模型
* @param prompt
* @return
*/
@GetMapping("/text2video")
public String text2video(@RequestParam(value = "prompt") String prompt) {
// 设置视频处理参数,如指定输出视频的分辨率、视频时长等。
Map<String, Object> parameters = new HashMap<>();
// 是否开启 prompt 智能改写。开启后使用大模型对输入 prompt 进行智能改写。对于较短的 prompt 生成效果提升明显,但会增加耗时。
parameters.put("prompt_extend", true);
// 静态图片路径,将它转换为动态视频
String imgUrl = "file:///" + "D:/xiaojiejie.png"; // Windows 系统
// 构建调用大模型所需参数
VideoSynthesisParam param =
VideoSynthesisParam.builder()
.apiKey(apiKey) // API Key
.model("wanx2.1-i2v-plus") // 模型名称
.prompt(prompt) // 提示词
.imgUrl(imgUrl) // 静态图片路径
.parameters(parameters) // 视频处理参数
.build();
log.info("## 正在生成中, 请稍等...");
// 调用 AI 大模型生成视频
VideoSynthesis vs = new VideoSynthesis();
VideoSynthesisResult result = null;
try {
result = vs.call(param);
} catch (Exception e) {
log.error("", e);
}
// 返参
return JsonUtils.toJson(result);
}
}
测试
重启后端项目,浏览器访问地址如下,提示词为 “一个小姐姐在跳舞”:
http://localhost:8080/v12/ai/text2video?prompt=一个小姐姐在跳舞
注意,生成视频较为耗时,估计需要 10 分钟左右,请耐心等待,拿到返参后,结构如下,其中包括视频的 url 下载链接:

浏览器访问视频的下载链接,即可完成下载,通过视频播放器,打开看看效果咋样吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)