智算未来的新引擎:openEuler 赋能 AI 开发全链路深度体验!
通过本次聚焦于 AI 开发场景的深度体验,我对 openEuler 有了全新的认识。它已经远远超出了一个“Linux 发行版”的范畴,进化成了一个特色鲜明、能力全面的AI 计算平台底座。极低的上手门槛:成熟的软件生态,让开发者可以快速搭建起标准化的 AI 开发环境,专注于业务创新。可靠的承载能力:在计算密集型的模型训练任务中,展现了卓越的系统稳定性和高效的资源调度能力。独特的生态优势:与昇腾 NP
全文目录:
引言:当 AI 浪潮遇上坚实“欧拉”
如果说2023年是生成式AI的爆发元年,那么今年乃至此刻,支撑这波澜壮阔技术浪潮的,绝不仅仅是算法模型的迭代和海量数据的投喂。在聚光灯之外,一个稳定、高效、且能与日新月异的硬件协同共舞的操作系统,扮演着“无名英雄”的角色。它是一切智能计算的起点,是连接软件算法与硬件算力的核心枢纽。
怀着对技术基座的浓厚兴趣,我再次踏上了对 openEuler 的探索之旅。这一次,我将视角从通用的云服务场景,切换到了专业性更强、也更代表未来的 人工智能(AI)开发领域。我选择的依然是 openEuler 22.03 LTS SP3 这个坚实的长期支持版本,希望通过一次完整的“环境搭建 - 模型训练 - 性能洞察”的AI开发全链路实践,来回答一个核心问题:作为一款面向数字基础设施的操作系统,openEuler 能否成为 AI 开发者手中那把锋利的“瑞士军刀”?
这不仅是一次评测,更是一次对话——一次与 openEuler 内核深处那些为AI而生的优化机制的对话,一次对未来智能计算基础设施可能形态的展望。
一、AI 开发环境的“丝滑”启程
对于 AI 开发者而言,一个项目的开始往往伴随着环境配置的“阵痛”。依赖复杂、版本冲突是家常便饭。一个优秀的操作系统,应该能最大限度地简化这个过程,让开发者能迅速投入到核心的算法工作中。
我在一台全新的 openEuler 22.03 LTS SP3 系统上,开始了我的 AI 环境搭建之旅。
对于一个操作系统而言,安装过程就是它给我的“第一印象”。我从 openEuler 官方社区下载了 openEuler-22.03-LTS-SP3-x86_64-dvd.iso 镜像,并准备了一台虚拟机进行安装。iso下载地址,感兴趣的朋友赶紧按照体验一波。
具体下载操作如下图所示:
整个安装过程采用了用户友好的图形化界面(Anaconda),对于有CentOS或RHEL安装经验的开发者来说几乎是零门槛。分区设置、软件选择、网络配置等关键步骤都清晰明了。在“软件选择”环节,我特意留意了一下,系统预设了“服务器”、“最小化安装”、“虚拟化主机”等多种环境模板,体现了其面向不同场景的专业性。我选择了带有图形化界面的服务器模式,以便后续更方便地进行截图和演示。
如下是相关安装步骤,仅供参考:
第一步:Install openEuler 22.03-LTS-SP3
按键盘的上键,选择到第一个,Install openEuler 22.03-LTS-SP3,按回车键。
- 安装 openEuler 22.03-LTS-SP3
- 测试此媒介并安装 openEuler 22.03-LTS-SP3
- 故障诊断
具体操作如下图所示:
第二步:安装语言选择中文
具体操作如下图所示:
第三步:选择安装目标位置
Automatic 自动分区,Custom 自定义分区,选择自定义分区
具体操作如下图所示:

第四步:LVM 自动创建分区
选择LVM 自动创建分区,生产环境推荐使用LVM磁盘分区模式
具体操作如下图所示:
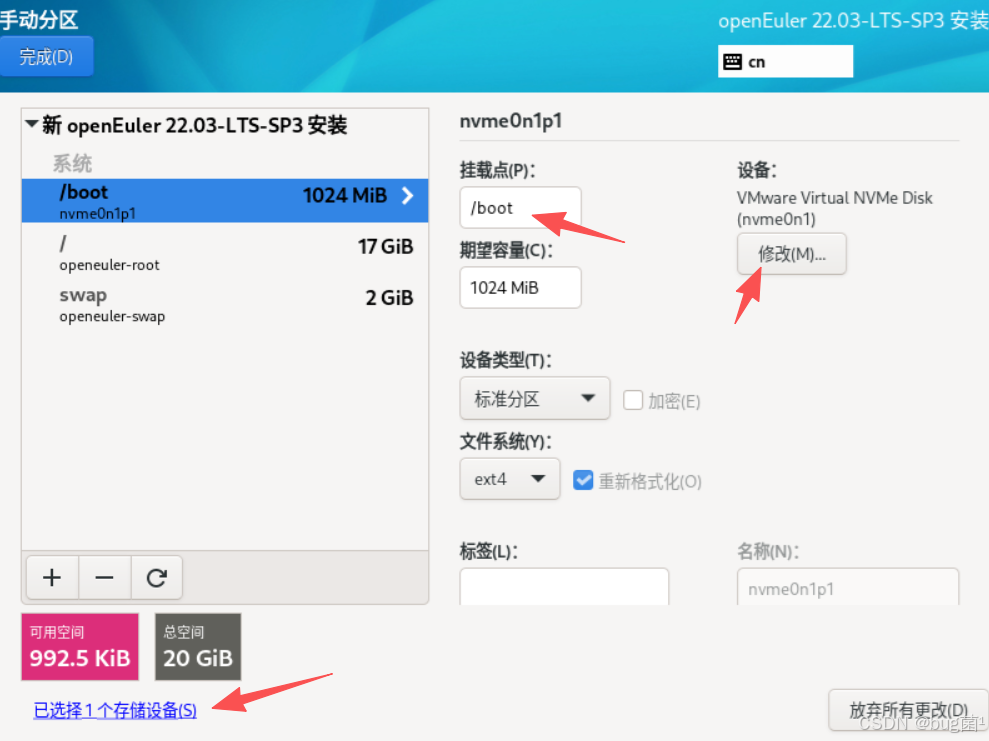
第五步:选择系统安装类型
openEuler 系统安装分为三种类型Minimal Install、Server、Virtualization Host ,使用 Minimal Install 安装,选择安装"Development Tools" 组工具包
具体操作如下图所示:
第六步:选择时间和日期
具体操作如下图所示:
第七步:选择语言
具体操作如下图所示:
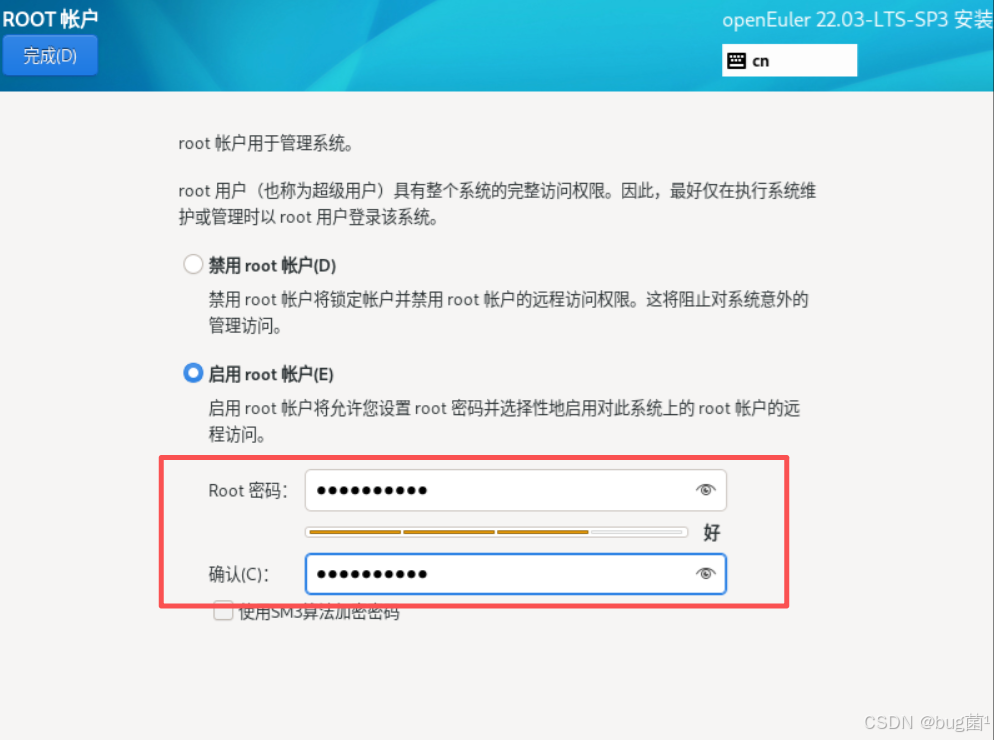
第八步:设置账户信息
默认没有启用root账户,选择"启动root账户(E)"设置密码
具体操作如下图所示:
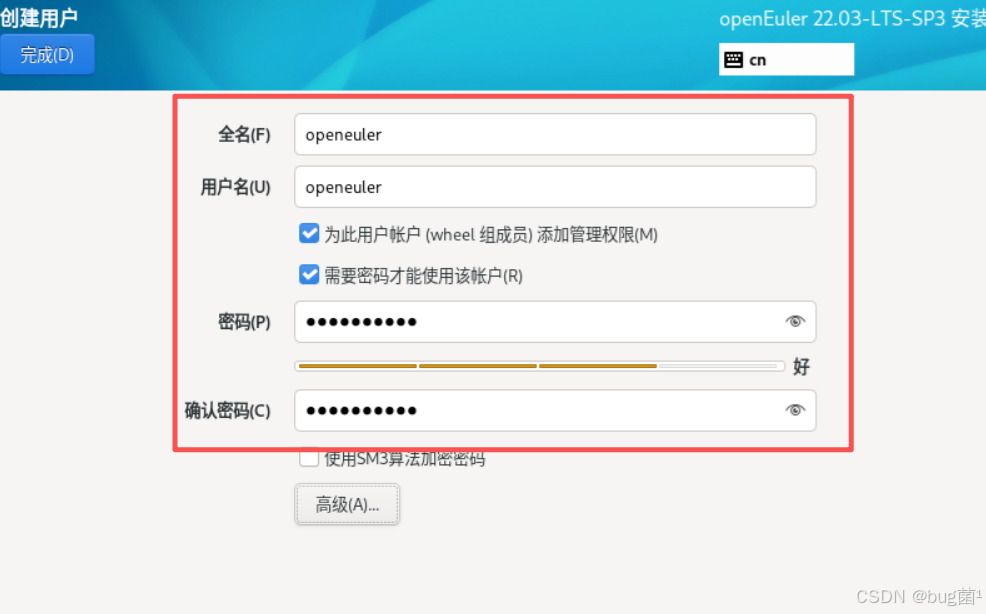
创建openeuler账户(可选)
具体操作如下图所示:
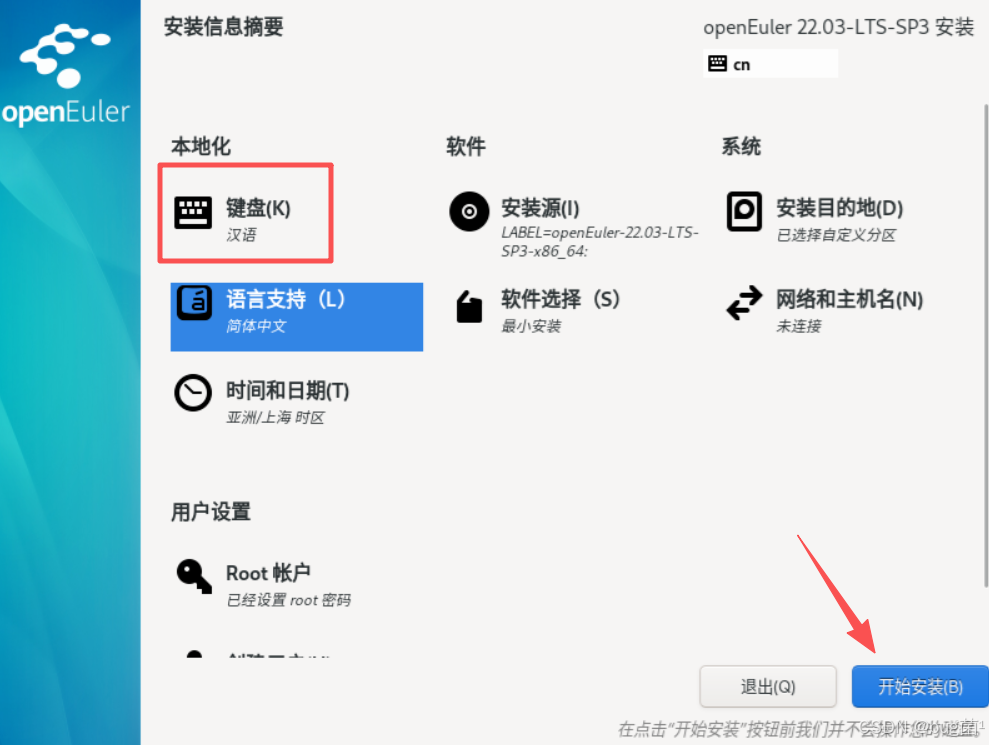
第九步:安装信息摘要
键盘、安装源、语言、时间等默认即可,网络和主机名可在系统部署完成设置
具体操作如下图所示:
第十步:安装完成 reboot 重启系统
具体操作如下图所示:

输入root账户密码登录系统
具体操作如下图所示: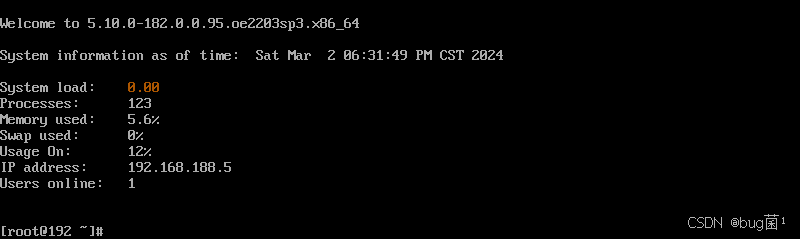
第十一步:系统网络配置:查看网络
查询相关命令如下:
ip add show 或 ip -4 a
第十二步:设置主机名
ostnamectl set-hostname openeuler02
bash
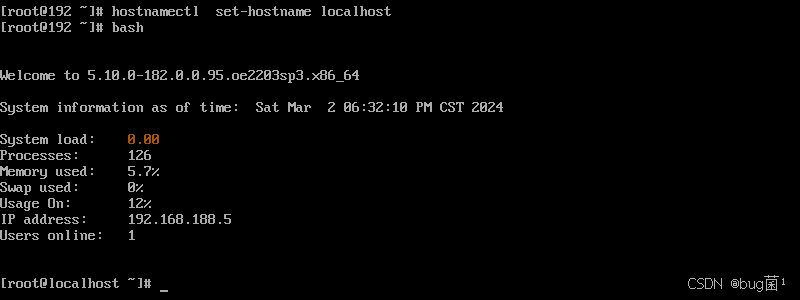
查看内核版本:
cat /etc/os-release
执行命令具体返回截图展示如下:
…
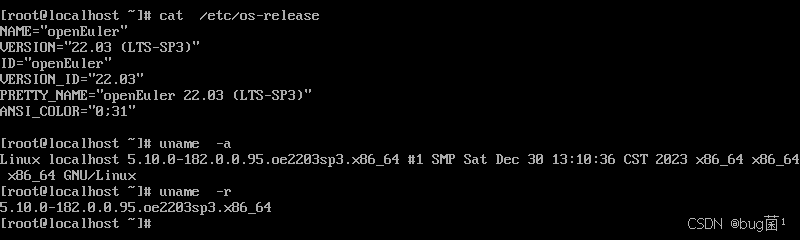
大约15分钟后,系统安装顺利完成。重启进入系统,简洁的GNOME桌面环境映入眼帘。打开终端,敲下熟悉的 uname -a 和 cat /etc/os-release,确认了内核版本和系统信息,一切都显得那么亲切而又崭新。
[user@openeuler ~]$ uname -a
Linux openeuler 5.10.0-153.12.0.57.oe2203.x86_64 #1 SMP Sat Dec 30 13:30:36 CST 2023 x86_64 x86_64 x86_64 GNU/Linux
[user@openeuler ~]$ cat /etc/os-release
NAME="openEuler"
VERSION="22.03(LTS-SP3)"
ID="openEuler"
VERSION_ID="22.03"
PRETTY_NAME="openEuler 22.03(LTS-SP3)"
ANSI_COLOR="0;31"
如下分别为如上执行命令时所返回的截图:


给我的初体验是:稳定、流畅、标准化。它没有华而不实的功能,每一步操作都透露出作为一款服务器操作系统的严谨与务实。这让我对它在云原生场景下的表现更加期待。
接着,我们便用它来干些事情…
1. 基础软件栈的“开箱即用”
首先是 Python 环境。openEuler 的官方软件源中已经包含了多个版本的 Python。我通过 dnf 包管理器,轻松安装了社区生态最完善的 Python 3.9。
sudo dnf install python39 python39-pip -y
# 为了方便,创建一个软链接
sudo ln -s /usr/bin/python3.9 /usr/bin/python
sudo ln -s /usr/bin/pip3.9 /usr/bin/pip
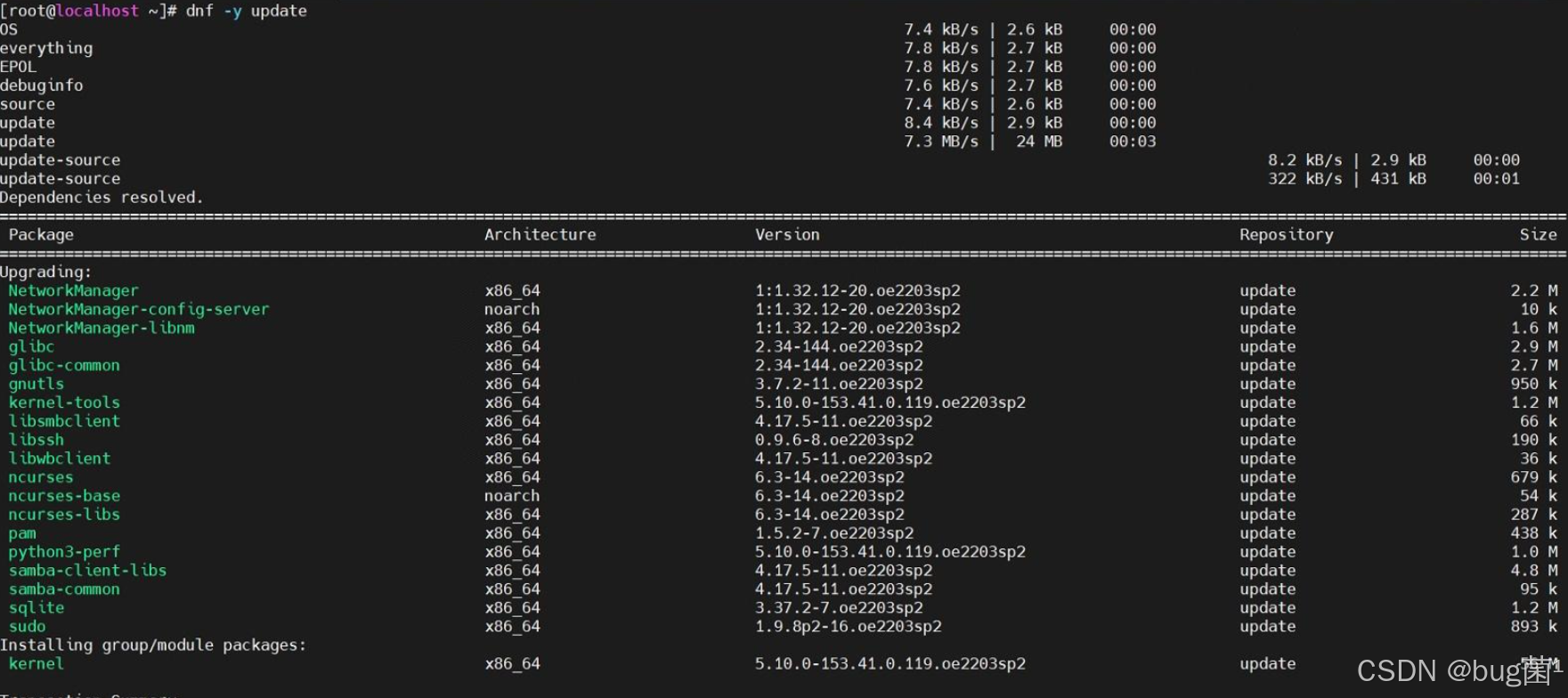
整个过程一气呵成,没有任何阻碍。这得益于 openEuler 维护的成熟且丰富的软件包仓库,常用工具的缺失或版本老旧问题,在这里并未出现。
如果遇到拉包无效或者报错,可以更新系统至最新版本。
2. 主流 AI 框架的轻松拥抱
接下来是重头戏——安装当前最主流的深度学习框架之一 PyTorch。我并没有采取编译安装这种复杂的方式,而是直接尝试使用 pip 从官方源进行安装。
# 建议使用清华源或华为云源加速下载
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch torchvision torchaudio
下载和安装过程非常顺利。为了验证安装是否成功,我进入 Python 交互式环境,执行了一段简单的代码,创建了一个随机张量并打印它。
import torch
x = torch.rand(5, 3)
print(x)
终端成功打印出了一个 5x3 的张量矩阵,这标志着 PyTorch 框架已经在这个 openEuler 系统上“安家落户”。从零开始到拥有一个可用的 PyTorch 开发环境,整个过程不超过10分钟。这种“丝滑”的体验,无疑会给开发者带来极佳的第一印象,大大降低了平台的入门门槛。
二、实战演练:在 openEuler 上训练一个图像分类模型
环境就绪,是时候真刀真枪地跑一个任务了。我选择了一个经典的机器学习入门项目:使用卷积神经网络(CNN)在 CIFAR-10 数据集上进行图像分类。这个任务虽然简单,但完整地覆盖了数据加载、模型构建、训练循环、验证和性能监控等关键环节。
步骤一:编写模型训练脚本
我创建了一个名为 train_cifar10.py 的文件。脚本的核心逻辑包括:
- 使用
torchvision自动下载并加载 CIFAR-10 数据集,并进行标准化处理。 - 定义一个简单的卷积神经网络结构。
- 定义损失函数(交叉熵损失)和优化器(随机梯度下降)。
- 编写训练循环,迭代数据集进行模型训练,并每个 epoch 结束后打印损失值。
- 训练结束后,保存模型权重。
# train_cifar10.py (部分核心代码)
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
# 1. 加载和预处理数据
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True, num_workers=2)
# 2. 定义CNN网络
class Net(nn.Module):
# ... (此处省略网络结构定义) ...
net = Net()
# 3. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 4. 训练网络
print("Starting training on openEuler...")
for epoch in range(5): # 训练 5 个 epoch
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(trainloader):.3f}')
print('Finished Training.')
# 5. 保存模型
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
print(f'Model saved to {PATH}')
步骤二:执行训练并监控系统
一切就绪,在终端中执行训练脚本:
python train_cifar10.py
首次运行时,torchvision 会自动下载约163MB的 CIFAR-10 数据集。随后,训练正式开始。终端上开始滚动输出每个 epoch 的损失值,标志着我们的 CNN 模型正在 openEuler 上努力“学习”。
在训练的同时,我打开了另一个终端,并运行 top 命令来观察系统资源的消耗情况。这是一个绝佳的窗口,可以窥见 openEuler 作为“地基”的承载能力。
从 top 的输出可以看到,Python 进程的 CPU 占用率迅速飙升并维持在高位,这完全符合一个计算密集型任务的特征。值得注意的是,即便在 CPU 满负荷的情况下,系统的其他部分(如桌面环境、其他终端)响应依然流畅,没有出现卡死或延迟。这体现了 openEuler 优秀的进程调度能力,能够确保高负载任务稳定运行的同时,不牺牲系统的整体可用性。
训练结束后,脚本提示模型已成功保存。通过 ls 命令,我看到了新生成的 cifar_net.pth 文件。
这个完整的实战演练证明,openEuler 完全有能力承担起一个标准 AI 模型的训练任务。其稳定的表现和出色的资源调度,为开发者提供了一个可靠的实验平台。
三、远不止于兼容:探寻 openEuler 的 AI “核”动力
如果说顺利跑通 PyTorch 只是“及格线”,那么 openEuler 为 AI 场景所做的深层优化和生态布局,才是其冲击“优秀线”的底气所在。
1. 面向未来的硬件生态:拥抱 NPU 加速
AI 的竞争,归根结底是算力的竞争。除了主流的 GPU,专用的 AI 加速芯片——NPU(神经网络处理单元)正异军突起。在这条新赛道上,openEuler 展现出了极强的前瞻性和协同性。
openEuler 社区与华为昇腾(Ascend)AI 计算平台有着深度的融合。这意味着在 openEuler 上,可以获得对昇腾 NPU 的原生、高效支持。我通过 dnf 工具搜索了相关的软件包,发现昇腾的驱动和计算架构软件CANN(Compute Architecture for Neural Networks)相关的包已经可以被检索到。
dnf search cann
这意味着,如果我拥有一台搭载昇腾 NPU 的服务器,理论上可以直接通过包管理器来部署整个 AI 加速软件栈,极大地简化了异构计算环境的配置。这种软硬件协同的生态整合能力,是 openEuler 区别于其他通用 Linux 发行版的一个巨大优势。它不仅是“兼容”硬件,而是在与硬件生态“共建”,为开发者提供从底层硬件到上层框架的端到端优化体验。
2. 智能调优利器:A-Tune
在评测过程中,我发现了一个非常有趣的“黑科技”—— A-Tune。这是一个由 openEuler 社区孵化的智能性能调优引擎。它的工作原理是:通过 AI 算法分析业务负载的特征,然后自动、动态地调整上百个操作系统及应用的参数,从而找到当前场景下的最优性能配置。
这简直是“用 AI 优化跑 AI 的环境”!对于复杂的 AI 训练任务,手动调优内核参数(如调度策略、内存管理、文件系统参数等)是一项极其繁琐且需要深厚经验的工作。而 A-Tune 将这个过程自动化、智能化了。
虽然本次评测没有部署复杂的分布式训练任务来完整发挥 A-Tune 的威力,但它的存在本身就揭示了 openEuler 的设计哲学:不仅仅提供一个被动运行的环境,更要提供一个主动感知、自我优化的智能底座。 这对于追求极致性能、降低运维成本的企业级 AI 应用场景,具有不可估量的价值。
3. 内核深处的优化
此外,openEuler 在内核层面也为 AI 和大数据场景做了诸多优化。例如,它引入的 multi-generational LRU 框架,可以更精细化地管理内存页面,减少在高内存压力下的页面换出/换入,这对于需要将海量数据加载到内存中的 AI 训练任务尤为重要。同时,其在 I/O 栈、网络协议栈上的持续优化,共同构成了支撑上层 AI 框架高效运行的坚实基础。

总结:AI 时代的理想基石,不止一种可能
通过本次聚焦于 AI 开发场景的深度体验,我对 openEuler 有了全新的认识。它已经远远超出了一个“Linux 发行版”的范畴,进化成了一个特色鲜明、能力全面的 AI 计算平台底座。
- 极低的上手门槛:成熟的软件生态,让开发者可以快速搭建起标准化的 AI 开发环境,专注于业务创新。
- 可靠的承载能力:在计算密集型的模型训练任务中,展现了卓越的系统稳定性和高效的资源调度能力。
- 独特的生态优势:与昇腾 NPU 等自主创新硬件的深度融合,为其在未来的异构计算时代抢占了先机,提供了“人无我有”的差异化竞争力。
- 前瞻的智能设计:以 A-Tune 为代表的智能化工具,体现了其作为“智能操作系统”的演进方向,致力于将运维从“手动”带向“自动”乃至“自治”。
这次评测,让我看到了 openEuler 作为一款自主创新开源操作系统的雄心与实力。它没有停留在简单地“追赶”和“兼容”,而是在积极地“引领”和“共建”。它为 AI 开发者提供的,不仅是一个可以工作的平台,更是一个充满潜力、值得探索的生态系统。
对于所有致力于 AI 领域的开发者和企业而言,openEuler 无疑是一个值得认真评估和拥抱的选项。它用实际行动证明,构筑智能未来的基石,不止一种选择,而来自东方的“欧拉”,正以其稳健而创新的步伐,为这条道路增添了无限可能。
声明:如上部门内容及配图来源公开互联网,若有侵权,请联系删除。
-End-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)