AI环境音频(场景音效)合成技术详解
在AI生成音频领域。主要涉及文本到语音(TTS)、语音克隆、音乐生成、环境音效合成等子任务。近年来,AI场景音频合成技术快速发展,当前主流方法涵盖基于音效库匹配、GAN、Diffusion和大语言模型(如AudioGen)等多种技术路线。最新进展包括Google V2A、Diff-Foley等视频到音频模型,以及索尼开源的MMAudio多模态模型,通过跨模态联合训练实现音画同步。这些技术在虚拟现实
为了更好的理解整个场景音频合成的技术,下面将介绍一些音频领域的基本知识。
AI音频生成的概念
AI音频合成(AI Audio Generation / Audio Synthesis)是指通过机器学习模型,自动生成具有特定内容、风格、结构的音频信号的过程。
常见的子任务
| 分类 | 简述 |
|---|---|
| 🎤 TTS(Text to Speech) | 输入文字 → 生成一个人说话的声音 |
| 🧑🎤 Voice Cloning / Conversion | 换个声音说同一句话 |
| 🎼 Music Generation | 创作音乐 |
| 🧘 Ambient Sound Synthesis | 模拟环境音效 |
| 🔧 Audio Editing / Inpainting | 修补缺失音频、去杂音、混响设计 |
| 🎮 Foley & SFX | 用AI生成音效 |
音频的表示方法
深度学习中的音频表示方法(附代码)(波形图、频谱图、梅尔谱图、梅尔倒谱)
TTS相关模型
由于TTS是音频合成中较为成熟的技术,开始时间也相对较早,环境音频合成技术很多都借鉴了TTS中相关的一些技术手段,因此这里我们会引入TTS中一些基础概念与模型。
文本转语音(TTS,Text-to-Speech)技术详解
AI场景音频合成
AI场景音频合成的概念
场景音频生成技术是指通过计算机算法自动或半自动地生成与特定环境或视觉场景相匹配的声音效果,包括环境声(ambient sound)、Foley音效(物体交互声音)以及空间音频(spatial audio)。这项技术的发展与多媒体制作、虚拟现实和游戏产业的蓬勃需求密不可分。
技术方向:
- 文本 → 音频(Prompt式生成)
- 图像/视频 → 音频(多模态推理)
- 音频补全 / 合成编辑(生成音景片段)
模型与方法
基于音效库匹配
- 音效库构建:提前录制或合成大量环境音(如雨声、脚步声、机械声),并标注其适用场景。
- 场景分析:通过计算机视觉或文本描述识别当前环境(如“森林”“城市街道”)。
- 音频检索与混合:从音效库中检索匹配的音频片段,并按需混合(如“雨声+雷声+远处车声”)。
优点:整体架构简单,易于实现
缺点:灵活性低,需要提前录制文本;存储成本高;适配度差
基于流(2018)
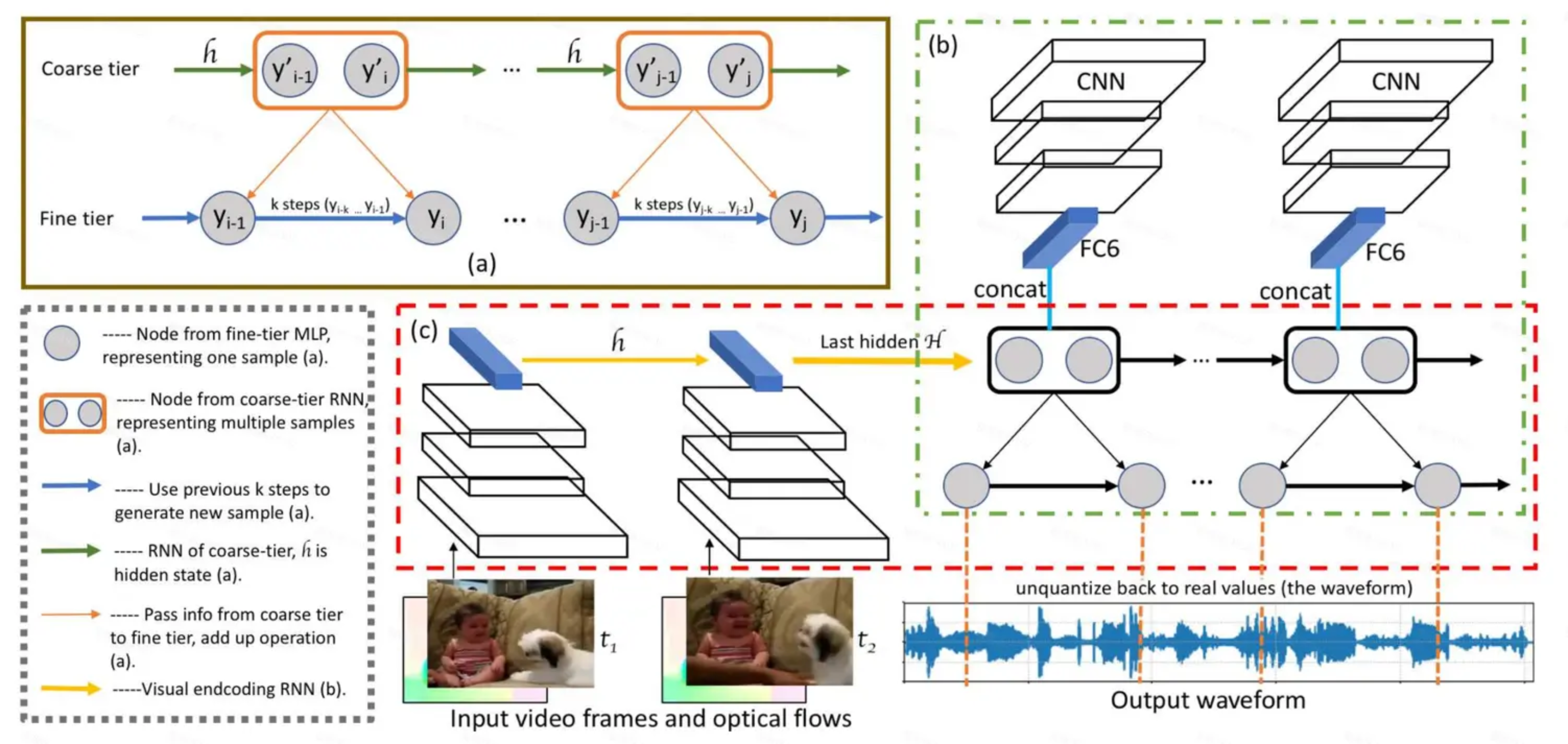
- 整体架构是:Encoder-Decoder + SampleRNN,在VEGAS 10类上训练
- 视觉编码器:使用预训练的VGG19,同时使用已有的光流算法,在原有的特征提取器上,得到每一帧的运动特征,和图像特征做拼接处理,然后送入解码器
- 音频解码器:3层结构的 SampleRNN(Coarse [8个点] -> Mid[2个点] -> Fine[1个点]),自回归生成,实测效果比Wavenet效果好
- Real or Fake:73.4% (Real: 91.6%)
基于GAN(2020)
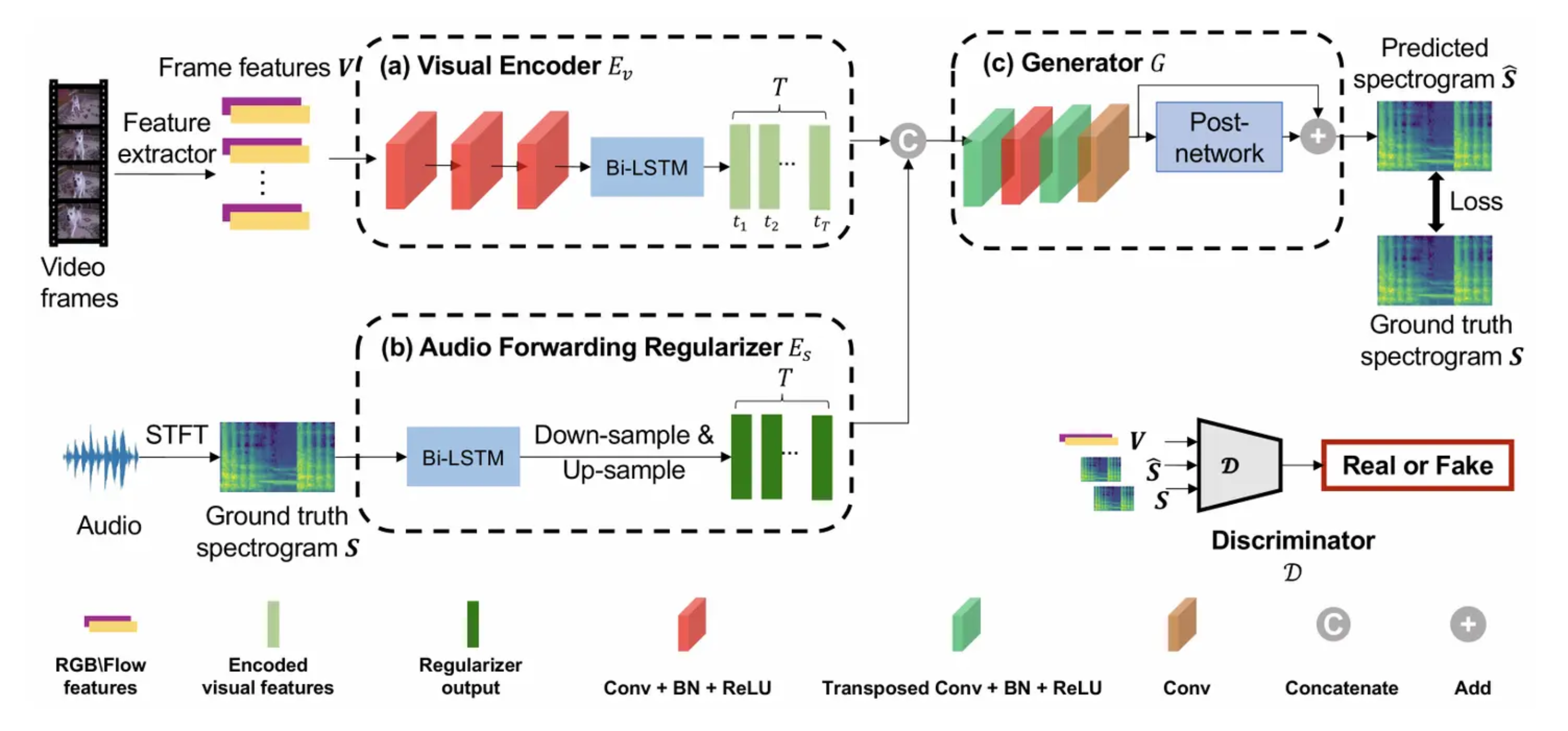
- 整体架构是:Encoder-Decoder + GAN在VEGAS 8类上训练
- 基本思想是:音效由画面相关音频和画面不相关音频组成
- 音频正则器:训练时使用频谱图输入,通过双向LSTM提取特征之后和视频特征做维度对齐,拼接,假定这两个一个是画面音频相关特征,一个是画面音频无关特征,这一步告诉模型哪些特征是画面相关的,哪些是画面无关的,在推理时会移除正则器
- Real or Fake:68.12% ,最好的类别(如烟花)能到 86%
📌Demo:示例视频
基于Diffusion(2023)
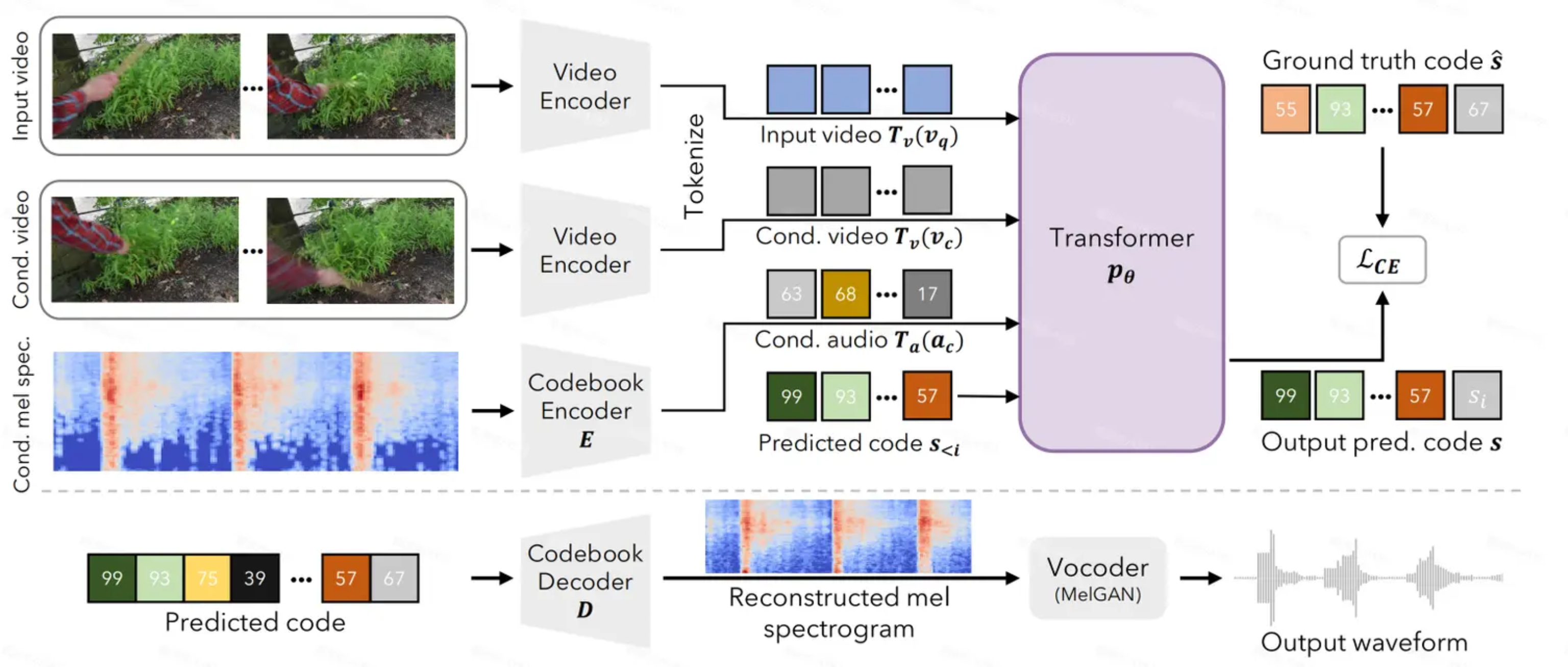
- 数据集:Greatest Hits + CountixAV 动作与声音数据集
- 用一个有声视频 clip 作为条件(Condition),再给一个无声的视频(Query),模型要合成一个声音,使它保留条件 clip 的音色(timbre),同时对齐输入视频的动作节奏(timing)。
- 自监督预训练任务:从同一个原视频中随机截两个片段(一个作为 query,无声;一个作为 condition,有图像+声音),模型要学会用 condition 的音色+query 的画面动作,合成新的声音。
- 模型结构:视频编码器(ResNet);条件音频编码(VQGAN),把音频转换为mel 频谱,再量化成 code,Transformer Decoder自回归地预测要生成的声音的 code sequence,Mel GAN讲Mel谱图转为音频
- 推理时可输入任意条件视频
📌Demo:示例视频
基于ALM的间接合成方法
文字-音频大模型
其他开源模型:Stable Audio Open
AudioGen
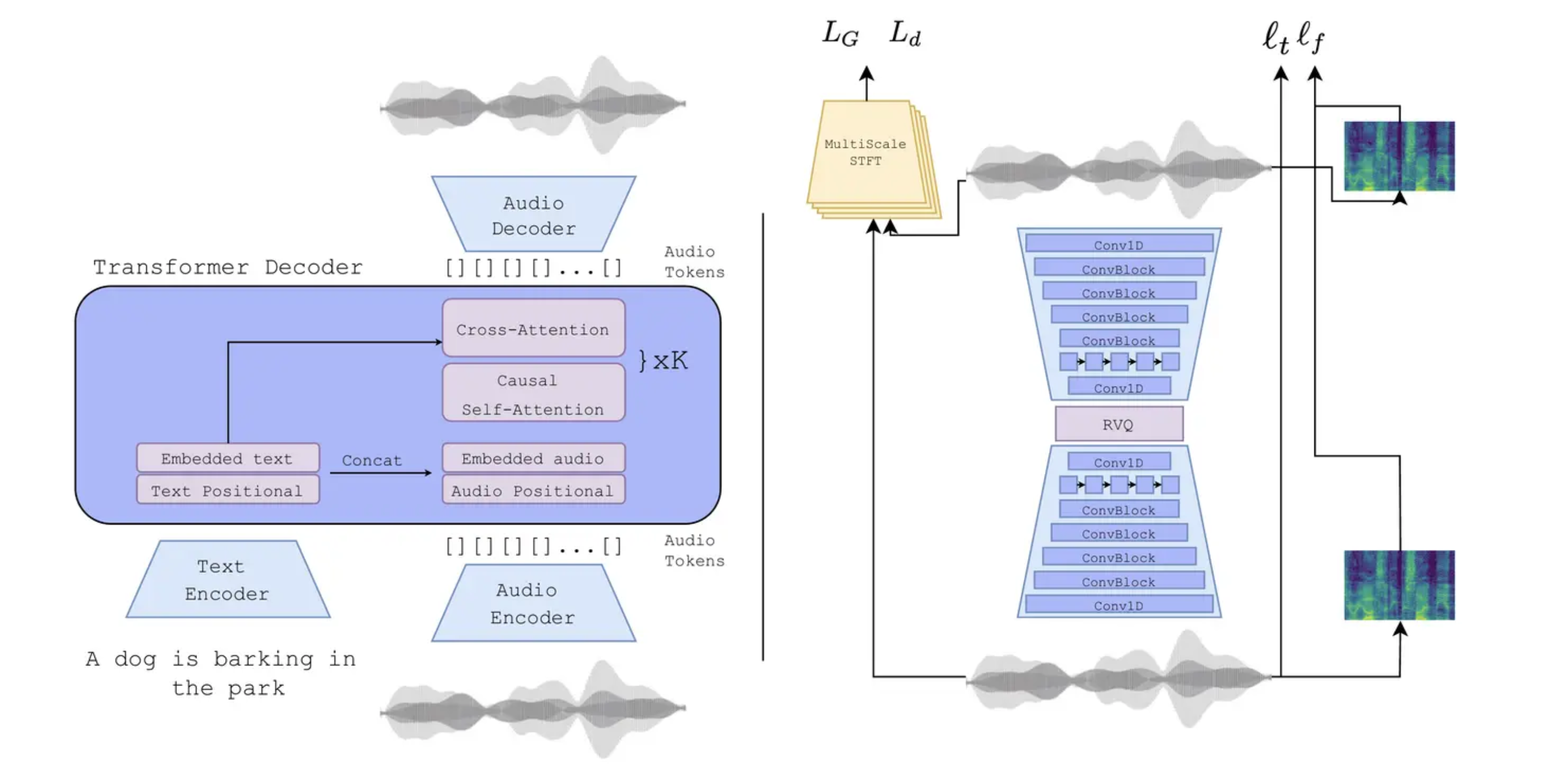
- VQ-VAE 编码器/解码器
- 使用 Residual Vector Quantization (RVQ),提高信息保留能力,一层一层残差地量化词典向量
- 架构类似Transformer,自回归 + Cross Attention
间接合成方法(2024)
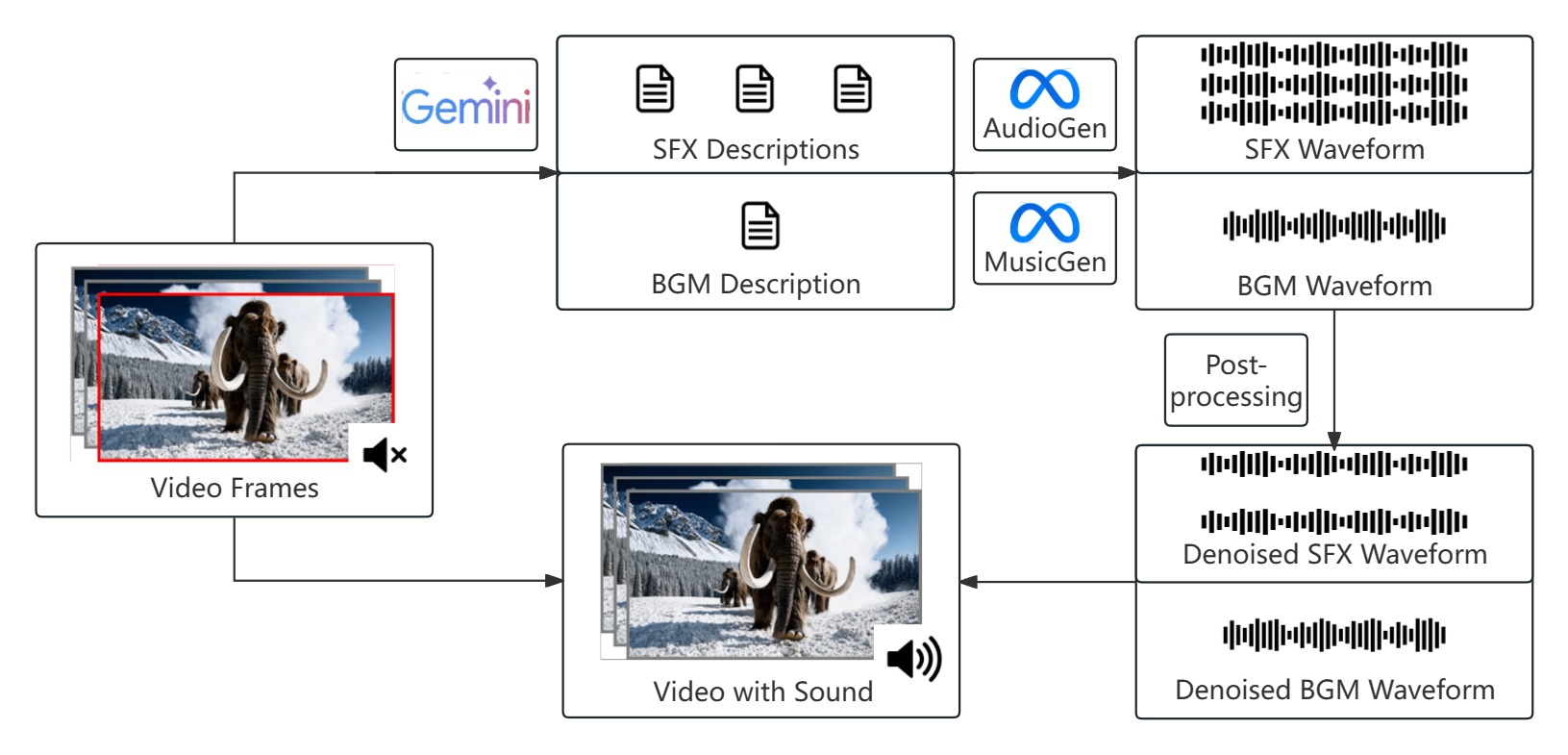
- 音效合成模块(SFX):通过Gemini模型生成音效文本描述,送入AudioGen大模型生成音频,通过一些后处理方法降噪得到音效。
- BGM合成模块(BGM):通过Gemini模型生成BGM文本描述,送入AudioGen大模型生成音频,通过一些后处理方法降噪得到BGM。
- 合并两个音频得到最终的从场景音效。
📌Demo:示例视频
视频到音频大模型
一些免费音效合成工具:Soundify,SoundEffect
Diff‑Foley(2023)
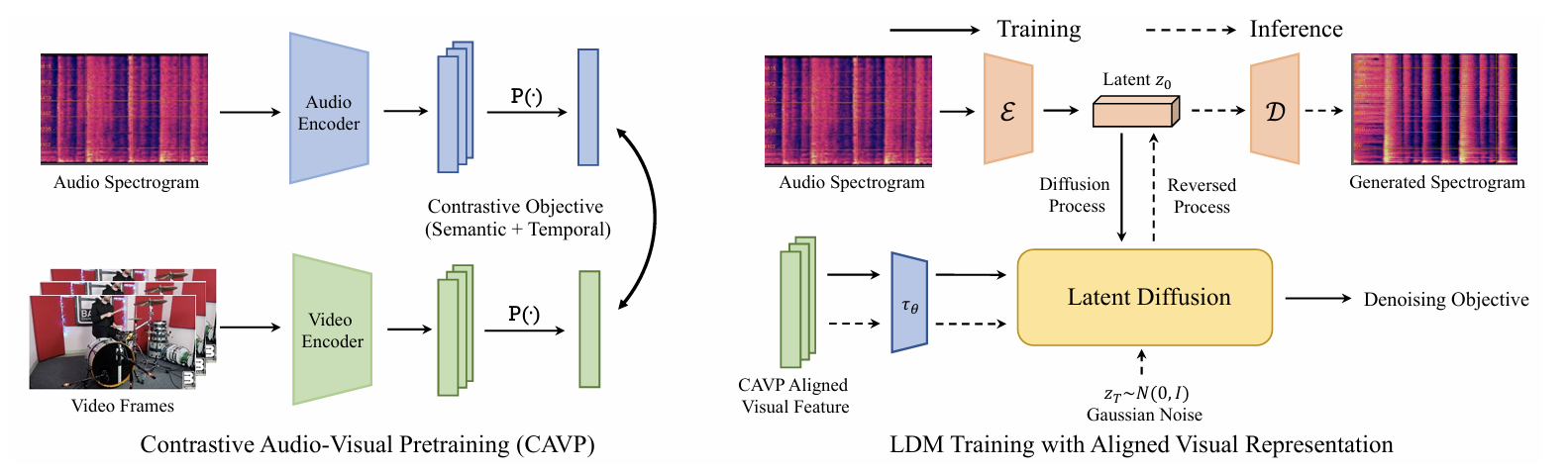
- 视觉-音频预训练特征(CAVP)
- 潜在扩散模型,在 spectrogram 的潜在编码空间里进行扩散采样
- Cross-Attention 融合,把 CAVP 对齐的视觉特征作为条件信息喂入 cross-attention 模块,让 LDM 在每个时间步都能理解画面内容和节奏变化
- 双重引导:Classifier-free guidance + CAVP discriminator gradient guidance
- 训练:用 CAVP 训练视觉和音频编码器,使它们共享 embedding 空间。→在潜在 spectrogram 空间训练 LDM,输入是视频特征,目标是重建对应音频
- 推理:用户输入静音视频 → 提取 CAVP 视觉特征 → 在 LDM 潜在空间中通过 cross-attn + double guidance 采样 → 最终解码回音频 → 得到同步音轨。
Google V2A(2024)
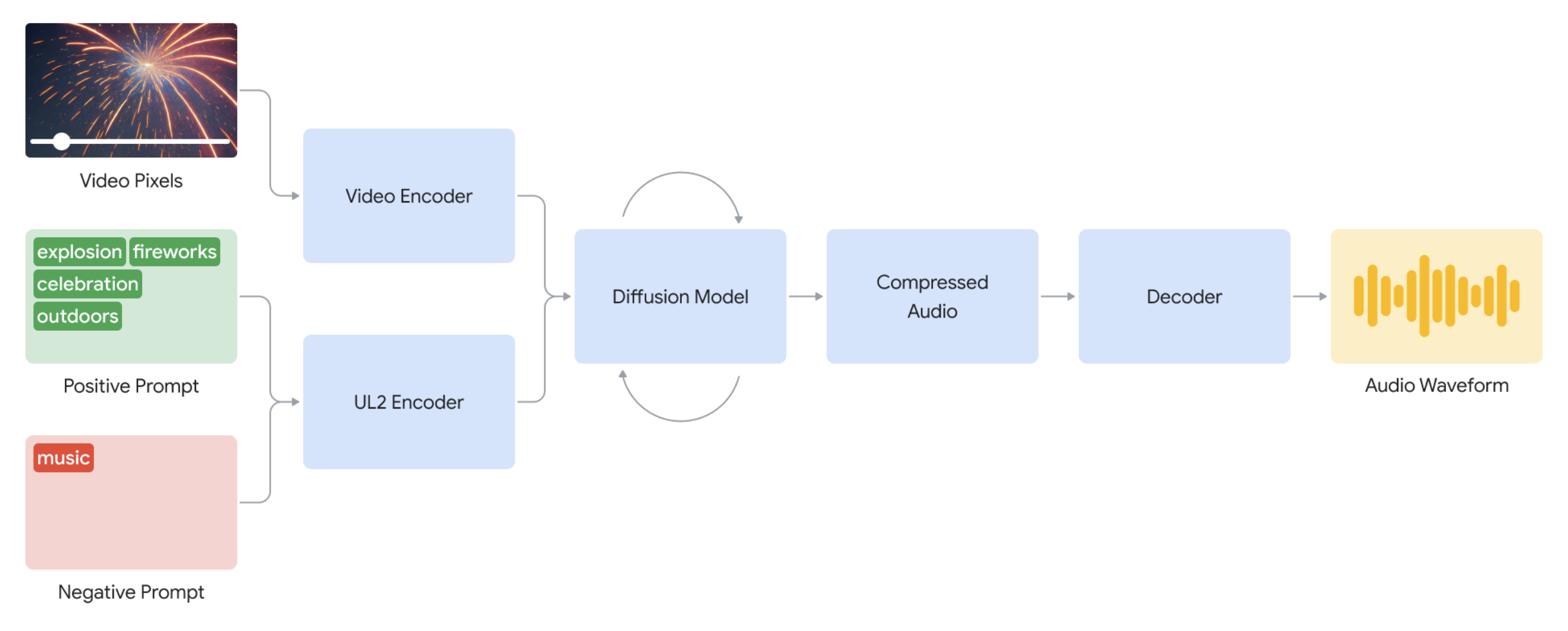
- 输入信号:把视频帧(原始像素)和一个可选的prompt,一起送进模型
- 编码器环节:视频帧和语言输入被压缩编码成中间表示,提取视觉与语义信息。
- 扩散模型:从随机噪声逐步生成压缩后的音频表示,这过程受到视频内容和提示的双重引导。
- 解码器:将压缩音频表示转成最终波形,合成连贯的声音并回拼到视频里。
MMAudio(2025)
| 模型 | CMOS↑ | CLAPScore↑ | SyncScore↑ | MAE↓ |
|---|---|---|---|---|
| MMAudio | +0.79 | 0.346 | 0.72 | 1.57 |
| TTA | +0.15 | 0.314 | 0.41 | 2.11 |
| AudioLDM2 | +0.08 | 0.294 | 0.38 | 2.33 |
| Diff-Foley | +0.39 | 0.302 | 0.59 | 1.95 |
| CLIPSynth | +0.17 | 0.311 | 0.51 | 1.89 |
- 索尼推出的开源音效合成大模型
- 跨模态联合训练:以前的视频→音频方法仅靠音频-视觉数据,数据量有限,MMAudio 把文本-音频大数据也拉进来,一起训练,把三模态融合到同一个 Transformer 框架里,能缺哪个就 mask 掉哪个
- 引入了一个对齐模块,在 frame level 对齐视频和音频 latent,这就确保声音和画面同步性。
- 数据集:LibriTTS-R 和 AudioCap,大约600小时
📌Demo:示例视频
AudioX(2025)
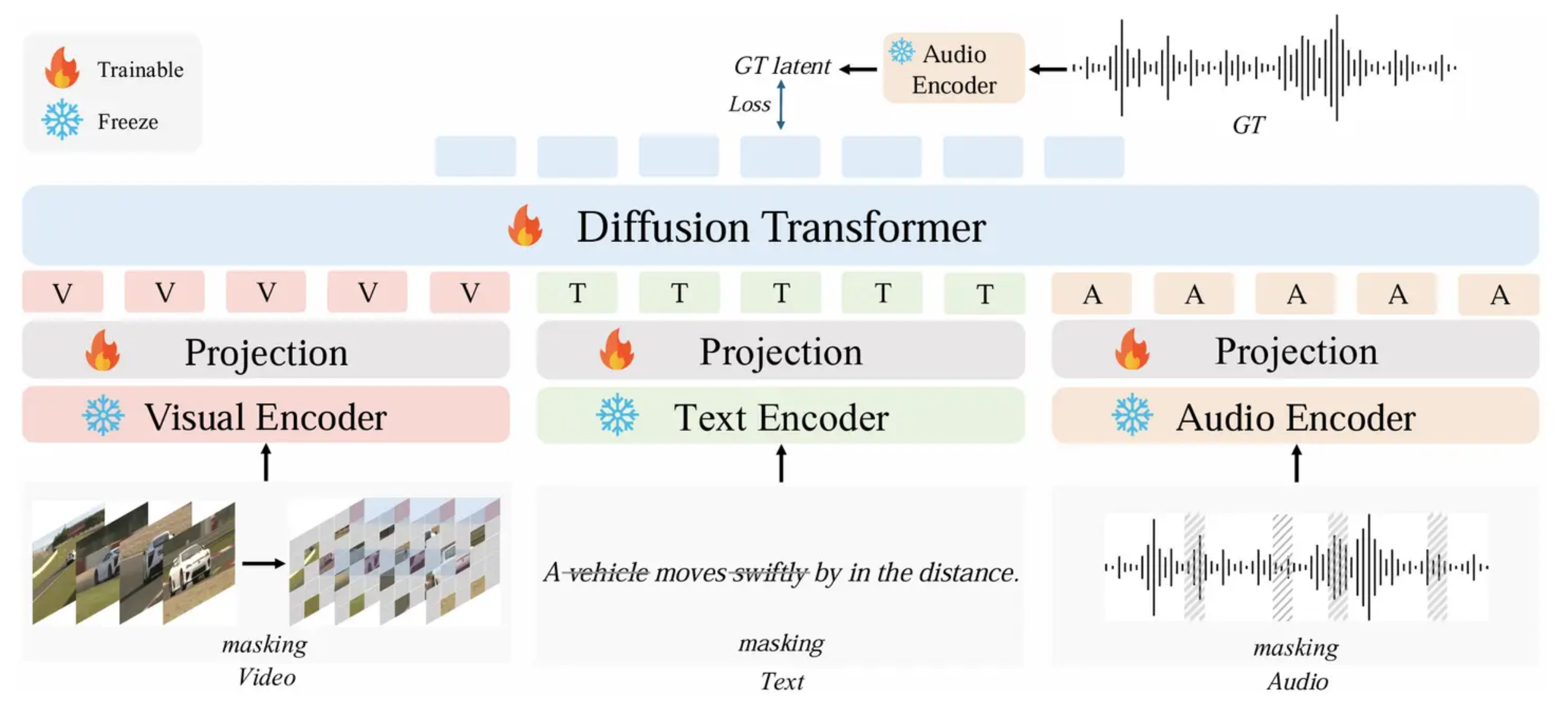
- 可以合成音效和音乐
- 数据集:AudioCaps, Wav Caps, VGGSound, AudioSet Strong, Greatest Hits, AVVP, V2M, MusicCaps
- Diffusion Transformer 架构,同时接受 多模态输入(文字、图像、视频、已有音频或音乐)作为输入
📌Demo:项目地址
参考资料
- 2010.05646
- GitHub - suno-ai/bark: 🔊 Text-Prompted Generative Audio Model
- FastSpeech2 Demo
- 1905.09263
- GitHub - ming024/FastSpeech2: An implementation of Microsoft’s “FastSpeech 2: Fast and High-Quality End-to-End Text to Speech”
- SoundStorm: Efficient Parallel Audio Generation
- GitHub - jaywalnut310/vits: VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
- Audio Samples from “Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech”
- SoundStorm: Efficient parallel audio generation
- AudioX: Diffusion Transformer for Anything-to-Audio Generation
- krantiparida/awesome-audio-visual: A curated list of different papers and datasets in various areas of audio-visual processing
- 2008.00820
- Conditional Generation of Audio From Video via Foley Analogies
- Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
- MMAudio:AI生成的视频终于有了声音! - 知乎
- MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
- https://github.com/facebookresearch/audiocraft/blob/main/docs/AUDIOGEN.md
- 2503.10522
- Generating audio for video - Google DeepMind

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)