Lustre 高性能并行文件系统全景解析
Lustre 的核心竞争力源于 “分离式架构 + 并行化设计 + 分布式扩展” 的深度协同,其 “PB 级容量 + TB/s 吞吐 + 微秒级延迟” 的性能组合,使其成为高性能计算、AI 训练等极端场景的首选存储方案。在企业级私有云建设中,Lustre 适合作为 “高性能存储池”,支撑核心业务的性能瓶颈突破。对于国内企业,建议优先选择青云 EPFS 等商用化改造版本,可降低部署运维复杂度,同时满足
引言
Lustre(Linux Cluster File System)作为全球应用最广泛的分布式并行文件系统之一,专为大规模集群环境设计,核心优势集中于高吞吐、低延迟、线性扩展三大特性。其架构设计深度契合高性能计算(HPC)、AI 训练、大数据分析等极端性能需求场景,已成为 PB 级数据存储与并行 I/O 处理的行业标杆。本文将从核心架构、技术原理、适用场景、部署实践、局限性与替代方案等维度,全面解析 Lustre 的技术体系与应用价值。
一、核心架构:分离式分布式架构设计
Lustre 的高性能根源在于其 “元数据与数据分离、全分布式部署、高速网络互联” 的架构逻辑,整体采用 “四层组件模型”,所有组件支持分布式扩展,无单点故障,性能随节点数量线性提升。
1. 四层组件架构与职责分工
| 架构层级 | 核心组件 | 英文全称 | 核心职责 | 性能定位 |
|---|---|---|---|---|
| 客户端层 | Lustre Client | Lustre Client | 1. 提供 POSIX 兼容接口(无缝对接 Linux 应用);2. 缓存元数据减少 MDS 查询;3. 并行与多个 OST 通信执行 I/O 操作 | 应用与存储的 “桥梁”,负责 I/O 分发 |
| 网络通信层 | LNET(Lustre Network) | Lustre Network | 1. 专用数据传输协议;2. 支持 IB/RDMA/TCP 协议;3. 优化节点间通信路由、流量控制 | 低延迟、高带宽的 “传输通道” |
| 服务端层(核心) | 元数据服务器(MDS) | Metadata Server | 1. 管理文件系统命名空间(目录、文件名、权限);2. 维护文件元数据(大小、创建时间、条带信息);3. 协调多客户端并发访问 | 元数据 “大脑”,无数据存储压力 |
| 元数据目标(MDT) | Metadata Target | 1. 实际存储 MDS 管理的元数据;2. 支持多 MDT 分片扩展(分散元数据压力) | 元数据 “存储载体” | |
| 对象存储目标(OST) | Object Storage Target | 1. 存储实际文件数据块;2. 执行数据条带化分布;3. 响应客户端并行 I/O 请求 | 数据 I/O “核心算力” | |
| 存储介质层 | 对象存储设备(OSD) | Object Storage Device | 1. OST 对应的物理存储介质(SSD/HDD);2. 通过 RAID / 多副本保证数据可靠性 | 数据 “最终存储载体” |
2. 关键组件关系说明
-
MDS 与 MDT:MDS 为 “管理进程”,MDT 为 “存储设备”(通常部署在 MDS 节点本地的 NVMe SSD),单 MDS 可关联 1 个或多个 MDT,多 MDT 通过目录分片分散元数据压力。
-
OST 与 OSD:1 台 OST 节点可部署多个 OST 进程(如 4 个),每个 OST 绑定一组 OSD(如 8 块 NVMe SSD 组成 RAID 6),OST 负责数据块逻辑管理,OSD 负责物理存储。
-
客户端部署:Lustre Client 需安装在计算节点(HPC 节点、云主机节点),通过内核模块集成到 Linux 系统,应用可通过本地目录(如
/mnt/lustre)直接访问。
3. 核心交互流程:并行 I/O 的实现逻辑
以 “多客户端并发读取大文件” 为例,Lustre 的读写流程通过 “元数据查询与数据读写并行” 实现高性能:
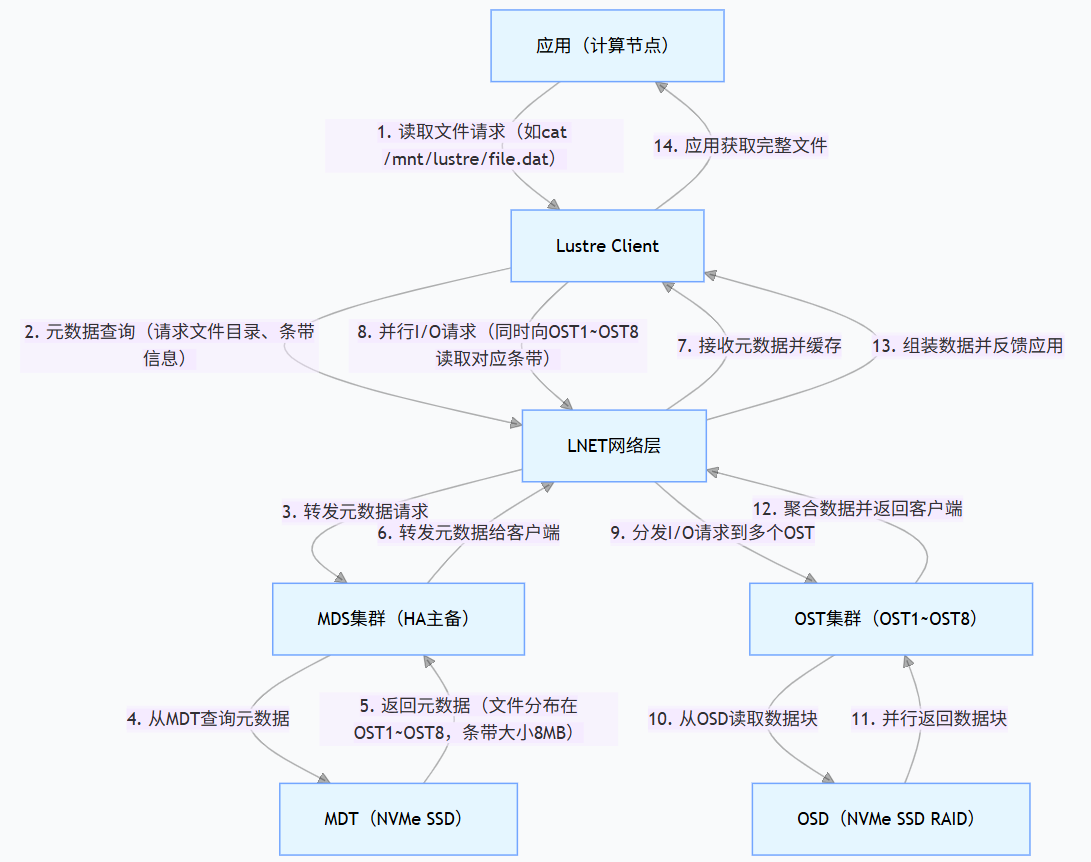
流程核心亮点:
-
元数据与数据分离:MDS 不参与数据传输,仅负责元数据调度,避免瓶颈;
-
并行化最大化:客户端根据条带信息并发访问多个 OST,吞吐能力 = 单个 OST 吞吐 × 条带宽度;
-
缓存优化:客户端缓存元数据,减少重复查询开销。
4. 架构设计三大核心原则
(1)元数据与数据分离
-
解决传统存储痛点:避免 NAS 等存储 “元数据 + 数据” 同节点处理导致的并发瓶颈;
-
分工优化:MDS 专注元数据管理,OST 专注数据读写,且均支持分布式扩展。
(2)数据条带化
-
定义:将文件分割为固定大小条带(64KB~1GB 可配置),按条带宽度分散存储在多个 OST;
-
关键参数:
-
条带大小:小条带(≤4MB)适合随机读写,大条带(≥16MB)适合顺序读写;
-
条带宽度:文件分布的 OST 数量(最大 1024),宽度越大并行度越高。
-
(3)全分布式无单点故障
-
高可用设计:
-
MDS:双节点主备(Pacemaker+Corosync),故障切换 RTO<30 秒;
-
OST:多节点部署,支持副本 / RAID 冗余,单节点故障不影响整体;
-
网络:双 IB 网卡绑定,多路径冗余。
-
-
线性扩展:
-
容量扩展:新增 OST 节点即可扩容(无需停机),支持 EB 级容量;
-
性能扩展:OST 节点数量与吞吐 / IOPS 线性正相关,万节点集群吞吐达 TB/s 级。
-
二、高性能核心技术原理
Lustre 的性能优势源于架构设计与底层技术的深度协同,关键技术包括以下四大方向:
1. 并行 I/O 优化
-
多客户端并发:支持数千计算节点同时访问,通过分布式锁保证数据一致性;
-
单文件并行:客户端可同时从多个 OST 读写同一文件的不同条带,实现带宽聚合。
2. 网络与存储介质优化
-
网络层面:支持 InfiniBand(IB)RDMA 协议,延迟低至亚微秒级,带宽达 100Gbps~400Gbps;LNET 协议优化传输开销,支持流量控制。
-
存储介质:全闪存部署(NVMe SSD)使单 OST 随机 IOPS 达 10 万 +,延迟≤100 微秒;支持混合存储(热数据 SSD + 冷数据 HDD)。
3. 数据一致性与可靠性机制
-
一致性保障:POSIX 兼容文件锁,支持多客户端并发读写一致性;
-
冗余策略:
-
OST 多副本(默认 2 副本):容忍节点故障;
-
OSD RAID:HDD 场景 RAID 6(容忍 2 块盘故障),SSD 场景 RAID 10;
-
自动重建:故障后从副本 / 校验块重建数据,不中断业务。
-
4. 元数据优化
-
多 MDT 分片:不同目录元数据分配至多个 MDT,分散查询压力;
-
客户端缓存:缓存常用元数据(目录结构、文件属性),减少 MDS 交互。
三、核心优势与适用场景
1. 跨存储方案性能对比
| 特性 | Lustre 并行文件系统 | 传统 NAS(NFS/SMB) | 分布式对象存储(S3) |
|---|---|---|---|
| 峰值吞吐 | 单集群 TB/s 级(万节点) | 百 GB/s 级(单节点瓶颈) | 百 GB/s 级(高并发小文件) |
| 随机 IOPS | 百万级(全闪存) | 万~十万级 | 千万级(单文件延迟高) |
| 延迟 | 微秒级(IB/RDMA) | 毫秒级 | 毫秒~秒级(小文件) |
| 扩展性 | 线性扩展(节点数→性能 / 容量) | 垂直扩展(单节点升级) | 线性扩展(并行 I/O 弱) |
| 接口兼容性 | POSIX 兼容(无缝替代本地文件系统) | POSIX 兼容(并发差) | RESTful API(非 POSIX) |
| 适用文件大小 | 大文件(GB~TB 级)、海量文件 | 中小文件(KB~GB 级) | 海量小文件(KB 级)、备份数据 |
2. 典型应用场景
-
高性能计算(HPC):气象预报、石油勘探、量子计算等 TB 级大文件并行处理;
-
AI / 深度学习训练:大规模数据集(医疗影像、ImageNet)的多 GPU 并行读取;
-
大数据分析:Spark、Hadoop 集群 PB 级日志数据高吞吐处理;
-
媒体处理:4K/8K 视频渲染、动画制作,多工作站并发读写超大文件;
-
私有云高性能存储池:为 OpenStack、K8s 集群提供高性能存储后端,支撑核心业务(数据库、实时计算)。
四、企业级部署实践(私有云场景)
1. 部署架构设计(100 节点 HPC 私有云示例)
| 组件类型 | 节点数量 | 硬件配置建议 |
|---|---|---|
| MDS 节点 | 2(HA) | 2U 机架式,CPU:2×Intel Xeon 8470C(24 核),内存:256GB DDR5,存储:4×4TB NVMe SSD(MDT),网卡:2×100G IB/RDMA |
| OST 节点 | 16 | 2U 机架式,CPU:2×Intel Xeon 8375C(32 核),内存:128GB DDR5,存储:12×8TB NVMe SSD(OSD,RAID 6),网卡:2×100G IB/RDMA |
| 计算节点(客户端) | 100 | 2U 刀片服务器,CPU:2×Intel Xeon 8358(32 核),内存:512GB DDR5,GPU:4×A100,网卡:1×100G IB/RDMA |
| 管理节点 | 2(HA) | 2U 机架式,CPU:2×Intel Xeon 6348(24 核),内存:128GB DDR5,存储:4×2TB SATA SSD |
2. 关键配置优化建议
(1)条带化配置
-
HPC 大文件场景:条带大小 = 16MB~64MB,条带宽度 = 8~16;
-
AI 训练场景:条带大小 = 4MB~8MB,条带宽度 = 4~8(平衡并行度与元数据开销)。
(2)网络规划
-
存储网络与业务网络分离,单独部署 100G IB RDMA 网络(如 Mellanox HDR IB 交换机);
-
配置 LNET 路由,优化客户端与 OST 网络拓扑,减少跨交换机转发。
(3)高可用与容灾
-
MDS 双节点 HA 部署,配置自动故障切换;
-
关键数据 2 副本,非关键数据 1 副本 + RAID 6;
-
跨机房容灾:通过 Lustre Replication 实现异地同步(RPO<1 小时)。
(4)监控与运维
-
基础监控:Lustre 自带工具(lctl、lustre-monitor)监控负载、延迟、带宽;
-
可视化监控:集成 Prometheus+Grafana,设置告警阈值(如 IO 延迟 > 500 微秒告警)。
3. 与 OpenStack 私有云集成
-
Manila 服务集成:通过 OpenStack Manila 提供文件共享服务,云主机通过 NFS/CIFS 挂载 Lustre;
-
直接挂载客户端:计算节点(Nova)安装 Lustre 客户端,通过 Cloud-Init 自动挂载(性能最优);
-
存储池划分:创建多文件系统(如 “hpc-pool”“ai-pool”),通过租户隔离按需分配资源。
五、局限性与替代方案对比
1. 主要局限性
-
部署复杂度高:需专业团队配置网络、条带化、HA,运维成本高;
-
小文件性能一般:文件 < 4KB 时,元数据开销占比高,性能不及对象存储;
-
跨平台兼容性差:仅支持 Linux 系统,Windows/macOS 需通过 NFS 网关(性能损耗 30%+);
-
商业支持依赖:开源版本无官方支持,企业级部署需第三方商业版本。
2. 主流替代方案对比
| 替代方案 | 核心优势 | 适用场景 |
|---|---|---|
| GPFS(IBM Spectrum Scale) | 兼容性强(Windows/Linux)、管理便捷 | 企业级混合负载(HPC + 中小文件) |
| BeeGFS | 开源免费、部署简单、小文件性能优 | 中小型 HPC 集群、实验室环境 |
| Ceph FS | 统一存储(块 + 对象 + 文件)、与 OpenStack 深度集成 | 私有云混合存储场景(无需单独部署多种存储) |
| 青云 EPFS | 基于 Lustre 优化、支持信创环境、国产化适配 | 国内企业私有云、信创项目 |
六、总结
Lustre 的核心竞争力源于 “分离式架构 + 并行化设计 + 分布式扩展” 的深度协同,其 “PB 级容量 + TB/s 吞吐 + 微秒级延迟” 的性能组合,使其成为高性能计算、AI 训练等极端场景的首选存储方案。在企业级私有云建设中,Lustre 适合作为 “高性能存储池”,支撑核心业务的性能瓶颈突破。
对于国内企业,建议优先选择青云 EPFS 等商用化改造版本,可降低部署运维复杂度,同时满足信创合规要求;若需兼顾混合负载(HPC + 中小文件存储),可采用 “Lustre+Ceph” 混合架构,

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)