随机森林:三分钟让你懂“三个臭皮匠,顶个诸葛亮”的AI版
本文介绍了随机森林算法及其应用。随机森林是一种集成学习方法,通过构建多棵决策树并综合投票结果进行分类或回归。其优点包括抗过拟合、抗噪能力强、适合高维数据处理等,但存在参数复杂、计算速度慢等缺点。文章详细阐述了随机森林的生成规则和影响因素,并以加州房价预测为例展示了代码实现过程,包括数据准备、模型训练、性能评估和特征重要性可视化。结果表明随机森林在回归任务中表现良好,同时可通过调参进一步优化。该算法
前言
机器学习可分为监督学习和无监督学习两大类,核心区别在于数据是否有“标签”(label/answer)。
监督学习就像有老师提供标准答案的学习,学习一个从输入到输出的映射函数。当给模型看到新的、从未见过的输入时,它能预测出正确的输出(标签)。
主要任务:
分类:预测一个离散的类别。
例如:垃圾邮件识别(是垃圾/不是垃圾)、图像识别(猫/狗/汽车)、疾病诊断(患病/健康)。
回归:预测一个连续的数值。
例如:预测房价、预测销售额、预测气温。
常见算法:线性回归、逻辑回归、支持向量机、决策树、随机森林、神经网络等。
一句话总结:从有答案的数据中学习规律,用于预测未来答案
无监督学习就像自学,没有标准答案,靠自己发现数据中的模式和结构。
- • 主要任务:
- 聚类:将数据自动分组,使得同一组内的数据彼此相似,不同组的数据差异较大。例如:客户细分、社交网络社群发现、市场划分。
- 降维:在保留主要信息的前提下,减少数据的特征数量,便于可视化或简化后续计算。例如:将高维数据压缩到2D/3D进行可视化(如PCA, t-SNE)。
- 关联规则学习:发现数据中属性之间的有趣联系。例如:购物篮分析(“买啤酒的人常常也买尿布”)
- 异常检测:识别与大多数数据显著不同的异常点。
- 例如:信用卡欺诈检测、工业品缺陷检测。
常见算法:K-Means聚类、层次聚类、主成分分析、自编码器等
机器学习中的监督学习主要有两种任务:回归和分类,而随机森林可以同时胜任这两种任务。
随机森林
什么是随机森林
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支--集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想-集成思想的体现。从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果,而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出。这就是一种最简单的 Bagging 思想。
随机森林的特点
优点:
🔵每棵树都选择部分样本及部分特征,一定程度避免过拟合;
🔵每棵树随机选择样本并随机选择特征,使得具有很好的抗噪能力,性能稳定
🔵能处理很高维度的数据,并且不用做特征选择(不需要降维处理);
🔵适合并行计算;
🔵实现比较简单。
缺点:
🔵参数较复杂;
🔵模型训练和预测都比较慢。
随机森林的生成
随机森林中有许多的分类树。我们要将一个输入样本进行分类,我们需要将输入样本输入到每棵树中进行分类。
打个形象的比喻:森林中召开会议,讨论某个动物到底是老鼠还是松鼠,每棵树都要独立地发表自。对这个问题的看法,也就是每棵树都要投票。该动物到底是老鼠还是松鼠,要依据投票情况来确定获得票数最多的类别就是森林的分类结果。
森林中的每棵树都是独立的, 99.9%不相关的树做出的预测结果涵盖所有的情况,这些预测结果将会彼此抵消。少数优秀的树的预测结果将会超脱于芸芸“噪音”,做出一个好的预测。将若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器,这就是随机森林bagging的思想。
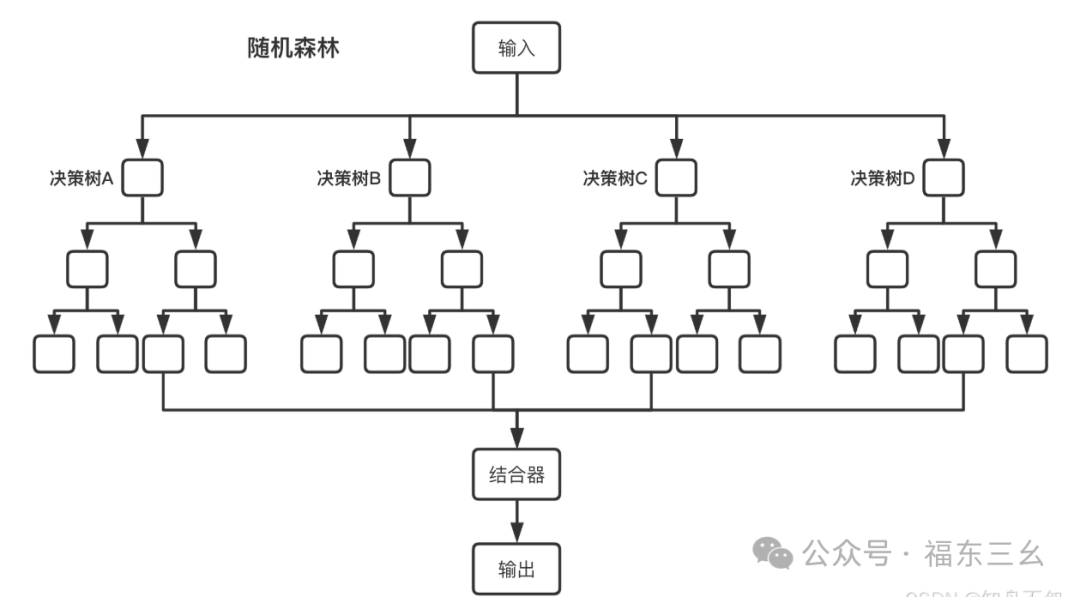
森林中树的生成规则为:
🔵如果训练集大小为N,对于每棵树而言,随机且有放回地从训练集中的抽取N个训练样本(这种采样方式称为bootstrapsample方法),作为该树的训练集;每棵树的训练集都是不同的,而且里面包含重复的训练样本。
🔵为什么要随机抽样训练集:如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的,这样的话完全没有bagging的必要;
🔵为什么要有放回地抽样:如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是"有偏的",都是绝对"片面的",也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决,这种表决应该是"求同",所以说使用完全不同的训练集来训练每棵树这样对最终分类结果是没有帮助的,这样无异于是"盲人摸象"。
🔵每棵树都尽最大程度的生长,并且没有剪枝过程。
随机森林分类效果(错误率)与两个因素有关:
🔵森林中任意两棵树的相关性:相关性越大,则错误率越大,
🔵森林中每棵树的分类能力:每棵树的分类能力越强,则整个森林的错误率就越低。
则随机森林有着:减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键是如何选择最优的m(或者是范围),这也是随机森林唯一的一个参数。
代码实现
以fetch_california_housing房价预测为例:
所谓预测,就是根据数据集来进行训练预测,这里直接用准备好的fetch_california_housing数据集实现。
# 导入所需库
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 加载加州房价数据集
california = fetch_california_housing()
X = california.data
y = california.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用随机森林进行回归
rf = RandomForestRegressor(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
RandomForestRegressor()的一些参数设置
创建随机森林分类器,使用文档中提到的参数
rf_classifier rf分类器= RandomForestClassifier 随机森林分类器(
n_estimators 决策树数量=100, # 森林中决策树的个数
criterion 准则='gini', # 分裂质量的度量方法,可以是'gini'或'entropy'
max_features 最大特征数='auto', # 寻求最佳分割时考虑的特征数量
max_depth 最大深度=None, # 树的最大深度,None表示不限制
min_samples_split 最小样本分割=2, # 分割内部节点所需的最小样本数量
min_samples_leaf 最小样本叶=1, # 叶子节点上包含的样本最小值
min_weight_fraction_leaf 叶节点最小权重分数=0.0, # 叶子节点权重和的最小加权分数
max_leaf_nodes 最大叶节点数=None, # 最大叶子节点数
min_impurity_decrease 最小不纯度减少量=0.0, # 分裂所需的最小不纯度减少量
bootstrap 自助法=True, # 是否采用有放回式的抽样方式
oob_score 袋外分数=False, # 是否使用袋外样本来估计模型准确率
n_jobs 工作数量=-1, # 并行作业数,-1表示使用所有处理器
random_state 随机状态=42, # 随机种子,确保结果可重复
class_weight 类别权重=None, # 类别权重
ccp_alpha =0.0 # 复杂度参数,用于最小代价复杂度剪枝
)
创建随机森林回归器,使用文档中提到的参数
rf_regressor = RandomForestRegressor (
n_estimators 决策树数量=100, # 森林中决策树的个数
criterion 准则='squared_error', # 回归时使用'squared_error', 'absolute_error'或'poisson'
max_features 最大特征数=1.0, # 寻求最佳分割时考虑的特征数量
max_depth 最大深度=None, # 树的最大深度
min_samples_split 最小样本分割=2, # 分割内部节点所需的最小样本数量
min_samples_leaf 最小样本叶=1, # 叶子节点上包含的样本最小值
min_weight_fraction_leaf 叶节点最小权重分数=0.0, # 叶子节点权重和的最小加权分数
max_leaf_nodes 最大叶节点数=None, # 最大叶子节点数
min_impurity_decrease 最小不纯度减少量=0.0, # 分裂所需的最小不纯度减少量
bootstrap 自助法=True, # 是否采用有放回式的抽样方式
oob_score 袋外分数=False, # 是否使用袋外样本来估计模型准确率
n_jobs 工作数量=-1, # 并行作业数
random_state 随机状态=42, # 随机种子
ccp_alpha =0.0 # 复杂度参数
)
将训练结果展示:
# 预测测试集
y_pred = rf.predict(X_test)误差展示:
# 输出性能指标
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse:.2f}")
print(f"Mean Absolute Error: {mae:.2f}")
print(f"R-squared Score: {r2:.2f}")
Mean Squared Error: 0.26
Mean Absolute Error: 0.33
R-squared Score: 0.80可以看出,误差还是比较大的,后续可以通过RandomForestRegresso()的参数设计进一步减小误差,本次就不讨论这些。
# 绘制预测值与实际值的散点图
plt.scatter(y_test, y_pred, alpha=0.5)
plt.xlabel("Actual Values")
plt.ylabel("Predicted Values")
plt.title("Actual vs Predicted Values (Random Forest Regression)")
plt.show()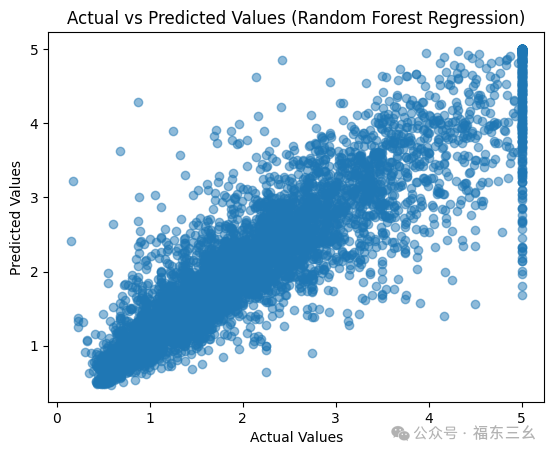
# 绘制特征重要性
feature_importances = rf.feature_importances_
features = california.feature_names
# 创建特征重要性条形图
plt.figure(figsize=(10, 6))
indices = np.argsort(feature_importances)[::-1]
plt.bar(range(len(feature_importances)), feature_importances[indices])
plt.xticks(range(len(feature_importances)), features[indices], rotation=45)
plt.xlabel("Features")
plt.ylabel("Importance")
plt.title("Feature Importance in Random Forest Regression")
plt.tight_layout()
plt.show()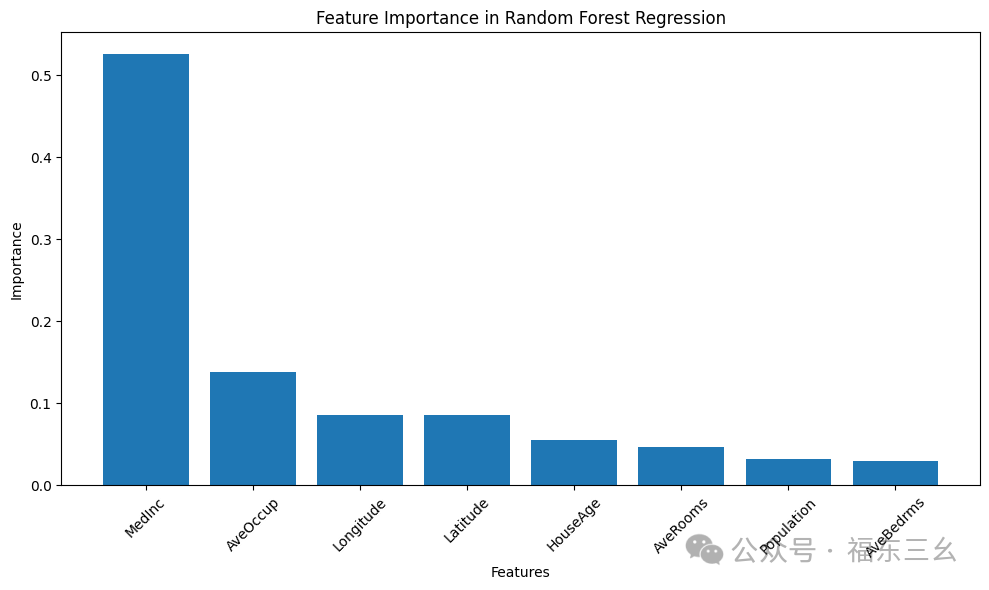
通过可视化得知:MedInc、AveOccup对房价的影响程度较大
后续:
🔵可以保存模型,用于新数据的预测;
🔵可以通过可结合GridSearchCV等工具自动调参,将训练的模型进一步优化。
总结
随机森林作为集成学习的代表算法,凭借其高准确率、强鲁棒性和广泛适用性,已成为机器学习和数据科学领域的主流方法。它不仅能有效提升模型性能,还能辅助特征工程和异常检测。理解随机森林的原理、调参方法和工程应用,有助于你在实际项目中高效落地和持续优化模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 35
35 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)