Langchain-Chatchat[四、知识库管理]
文章目录
前言
Langchain-Chatchat基于知识库管理 代码解析。
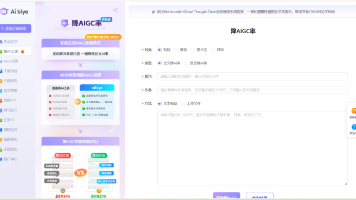
知识库管理如图:
新创建知识库【智慧城市 (pg @ text-embedding-v1)】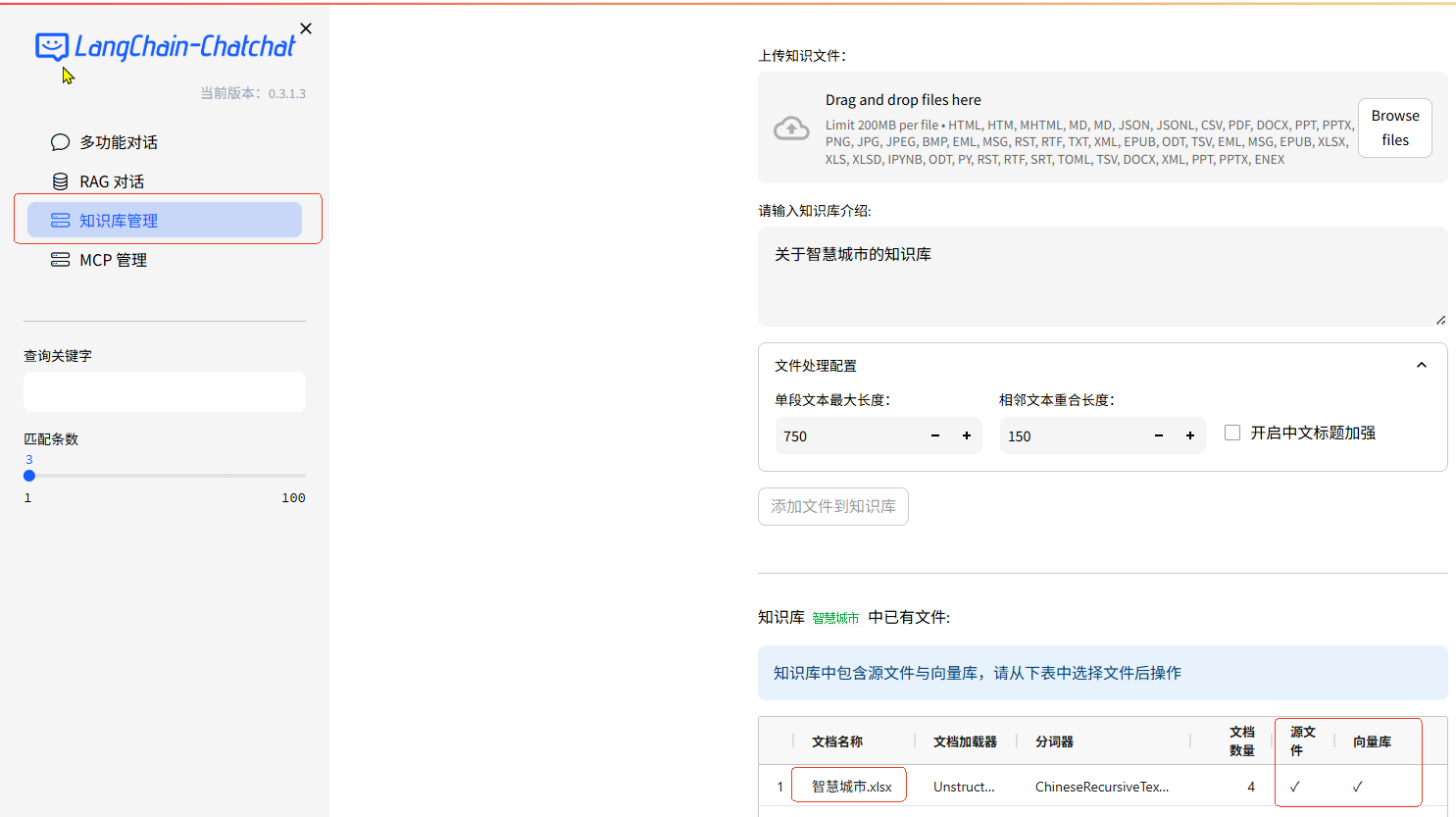
前提
Langchain-Chatchat[一、本地开发环境部署]
PyCharm 配置debug调试参数:start -a
一、知识库管理流程图
图一:
图二: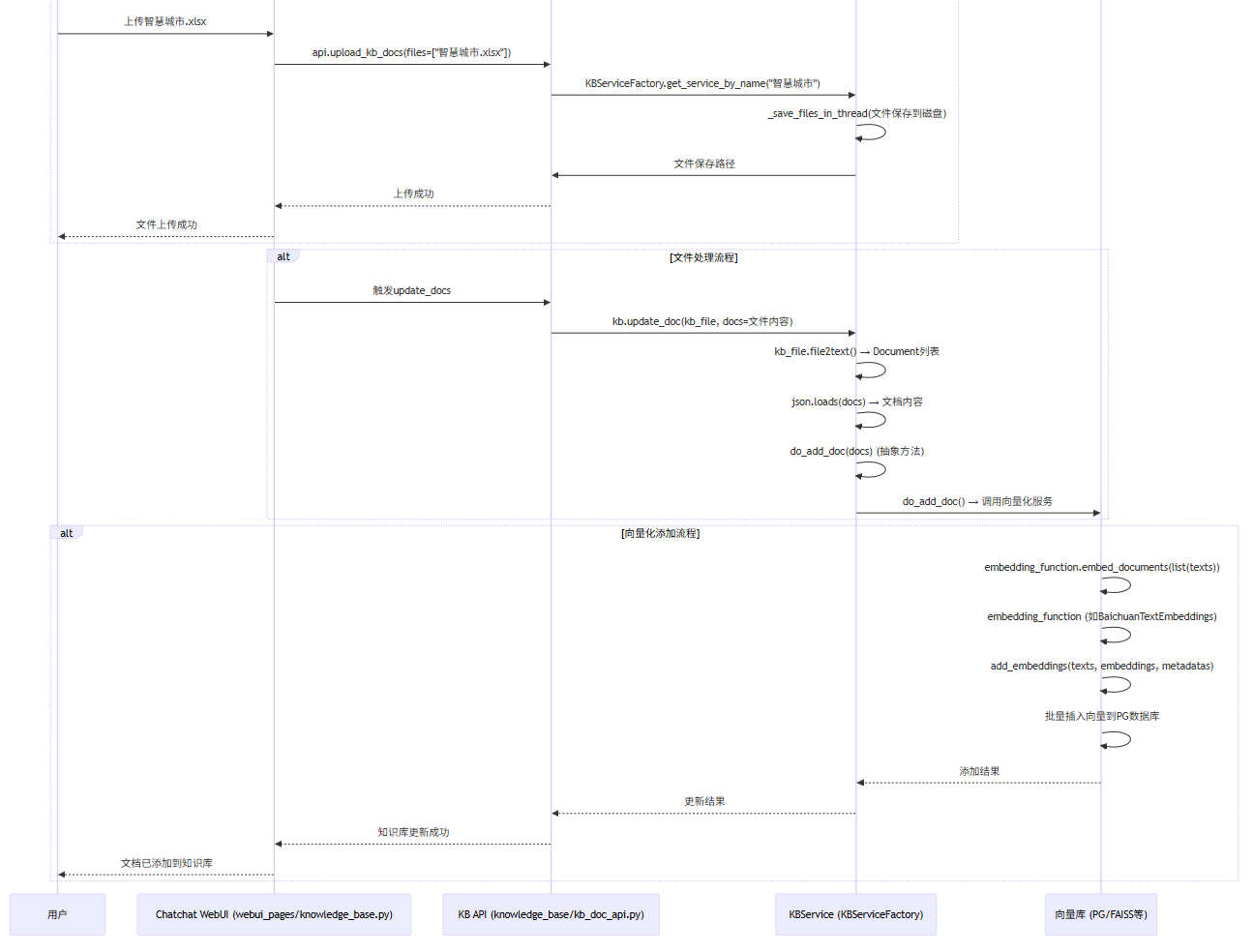
二、流程核心部分说明
文本和元数据embeddings后,添加到向量库
vectorstores.py#def add_texts
代码如下(片断):
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
说明:抽象方法,将文本和元数据embeddings后,添加到向量库,由遵循此标准的类(如 FAISS向量库类、Milvus向量库类、PG向量库类等)实现
实现类:PG向量库类
pgvector.py#def add_texts
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
**kwargs: Any,
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
metadatas: Optional list of metadatas associated with the texts.
kwargs: vectorstore specific parameters
Returns:
List of ids from adding the texts into the vectorstore.
"""
embeddings = self.embedding_function.embed_documents(list(texts))
return self.add_embeddings(
texts=texts, embeddings=embeddings, metadatas=metadatas, ids=ids, **kwargs
)
说明:PG向量库类将文本和元数据embeddings后添加到向量库
1.1 文本加强
embedding_function.embed_documents(list(texts))
说明:文本加强,由大模型加强模型embedding models实现,如BaichuanTextEmbeddings、ZhipuAIEmbeddings,返回embeddings对象
1.2 批量插入embeddings对象到数据库
def add_embeddings(
self,
texts: Iterable[str],
embeddings: List[List[float]],
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
**kwargs: Any,
) -> List[str]:
"""Add embeddings to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
embeddings: List of list of embedding vectors.
metadatas: List of metadatas associated with the texts.
kwargs: vectorstore specific parameters
"""
if ids is None:
ids = [str(uuid.uuid4()) for _ in texts]
if not metadatas:
metadatas = [{} for _ in texts]
with Session(self._bind) as session: # type: ignore[arg-type]
collection = self.get_collection(session) # 获取当前操作的集合对象
if not collection:
raise ValueError("Collection not found")
documents = []
for text, metadata, embedding, id in zip(texts, metadatas, embeddings, ids):
# 每个文档创建ORM 模型实例
embedding_store = self.EmbeddingStore(
embedding=embedding,
document=text,
cmetadata=metadata,
custom_id=id,
collection_id=collection.uuid,
)
documents.append(embedding_store)
#批量插入到数据库
session.bulk_save_objects(documents)
session.commit()
return ids
三、核心类说明
1.base.py 管理知识库基础类
位置:knowledge_base/kb_service/base.py,KBService 类定义系列方法用于管理知识库,包括创建知识库 、
删除知识库、向知识库添加文档、从知识库删除文档、更新知识库信息、文档搜索等。它是一个抽象基类(ABC)
, 通过继承它的子类来实现具体的功能。允许不同类型的知识库服务(如Faiss、Milvus、Elasticsearch等)实现
相同的接口,从而提供一致的操作方式。
KBService 类在项目中被多个子类继承,每个子类代表一种特定类型的知识库服务,例如`FaissKBService`、
`MilvusKBService`等。这些子类实现了KBService类中定义的抽象方法.
此外,KBService 类还与KBServiceFactory类相关联,KBServiceFactory类提供了get_service和get_service_by_name方法,用于根据知识库名称和向量存储类型动态创建相应的知识库服务实例。
1.1 class KBService(ABC):
class KBService(ABC):
# 初始化KBService类的实例
def __init__(
self,
knowledge_base_name: str,
kb_info: str = None,
embed_model: str = get_default_embedding(),
):
self.kb_name = knowledge_base_name
self.kb_info = kb_info or Settings.kb_settings.KB_INFO.get(
knowledge_base_name, f"关于{knowledge_base_name}的知识库"
)
self.embed_model = embed_model #嵌入模型
self.kb_path = get_kb_path(self.kb_name)
self.doc_path = get_doc_path(self.kb_name)
self.do_init()
......
Function Def save_vector_store(self)
save_vector_store: 此函数的功能是保存向量库。 参数: 此函数没有参数。
代码描述:将向量库的数据持久化保存。根据不同的向量库类型(如FAISS、Milvus等)采取不同的保存策略。例如Milvus类型的向量库,数据则会被保存到数据库中。
在项目中,save_vector_store函数被多个地方调用,以确保在进行文档的上传、删除、更新或向量库重建等操作后,向量库的状态能够被正确地保存。这些调用场景包括:
- 文档上传(
upload_docs):在上传文档并进行向量化处理后,根据not_refresh_vs_cache参数的值决定是否立即保存向量库。 - 文档删除(
delete_docs):在删除指定的文档后,根据not_refresh_vs_cache参数的值决定是否立即保存向量库。 - 文档更新(
update_docs):在更新文档内容并进行向量化处理后,根据not_refresh_vs_cache参数的值决定是否立即保存向量库。 - 向量库重建(
recreate_vector_store的output方法):在重建向量库的过程中,完成所有文档的向量化处理后,根据not_refresh_vs_cache参数的值决定是否立即保存向量库。 - 数据库文档清理(
prune_db_docs):在从数据库中删除不存在于本地文件夹中的文档后,保存向量库以确保向量库与数据库的一致性。
Function Def create_kb(self)
create_kb: 此函数的功能是创建知识库。 参数: 此函数没有参数。
代码描述: 负责知识库的创建流程。该方法首先检查指定的文档路径是否存在,如果不存在,则创建该路径。接着,调用 do_create_kb 方法,这是一个预留给开发者的扩展点,允许在知识库创建的基础流程中插入自定义逻辑。之后,该方法会调用 add_kb_to_db 函数,将知识库的名称、简介、向量库类型和嵌入模型等信息添加到数据库中。add_kb_to_db 函数的执行结果(状态)会被返回,表示知识库创建操作的成功与否。
注意:
do_create_kb方法默认不执行任何操作,需要在继承KBService类的子类中根据具体需求重写此方法。
输出示例: 返回一个布尔值,表示知识库创建操作的成功与否。
Function Def add_doc(self, kb_file, docs)
add_doc: 此函数用于向知识库添加文件。
参数:
kb_file:KnowledgeFile类型的对象,表示要添加到知识库的文件。docs:Document类型的列表,默认为空列表。这些是要添加到知识库的文档。**kwargs: 接收额外的关键字参数,这些参数将传递给内部方法。
代码描述:
调用kb_file的file2text方法将文件内容转换为文档列表。
调用delete_doc方法删除知识库中与kb_file相对应的旧文档。
调用do_add_doc方法将文档添加到知识库中,该方法需要在子类中具体实现,返回(doc_infos)。
调用add_file_to_db函数,将文件信息(doc_infos)添加到数据库中
最后,函数根据操作结果返回一个状态值,如果文档列表为空,则直接返回False。
输出示例:返回值主要用于指示操作是否成功。
1.2 class KBServiceFactory:
提供一个静态方法工厂,用于根据不同的参数创建并返回不同类型的知识库服务实例。
属性:该类没有定义属性,所有功能都通过静态方法实现。
代码描述:提供三个静态方法,分别用于根据不同的条件获取知识库服务实例。
-
get_service方法接受知识库名称(kb_name)、向量存储类型(vector_store_type)、嵌入模型名称(embed_model)作为参数。该方法首先会检查向量存储类型是否为字符串,如果是,则将其转换为SupportedVSType枚举类型。根据向量存储类型的不同,方法会动态导入并返回对应的知识库服务实例,如 FaissKBService、PGKBService、MilvusKBService 等,这些服务实例都继承自 KBService 基类。 -
get_service_by_name方法接受知识库名称(kb_name)作为参数,通过调用数据库加载函数load_kb_from_db来获取知识库的向量存储类型和嵌入模型名称,然后调用get_service方法来获取对应的知识库服务实例。 -
get_default方法不接受任何参数,直接返回一个默认向量存储类型为SupportedVSType.DEFAULT的知识库服务实例。
在项目中KBServiceFactory 被多个模块调用,用于创建、删除、更新、搜索知识库中的文档,以及上传和下载文档等操作。例如,在 knowledge_base_chat.py 中,通过 KBServiceFactory 获取知识库服务实例来搜索知识库中的文档;在 kb_api.py 中,通过 KBServiceFactory 创建新的知识库或删除现有知识库。
输出示例:
返回的知识库服务实例根据不同的向量存储类型,将具有不同的方法和属性,用于执行知识库的相关操作。
2. class PGKBService(KBService):
KBService子类,通过 PostgreSQL 实现父类KBService知识库服务的具体方法。
位置:knowledge_base/kb_service/pg_kb_service.py
**属性**:
- `engine`: 通过 SQLAlchemy 创建的连接引擎,用于与 PostgreSQL 数据库进行交互。
- `pg_vector`: 用于存储和检索嵌入向量的 PGVector 实例。
**代码描述**:
PGKBService 类继承自 KBService 类,提供了与 PostgreSQL 数据库交互的具体实现。
它使用 SQLAlchemy 作为 ORM 工具,通过 `engine` 属性与数据库建立连接。
此类主要负责初始化向量存储、文档的增删查改、知识库的创建和删除等操作。
`_load_pg_vector` 方法用于加载 PGVector 实例,该实例负责嵌入向量的存储和检索。
- `get_doc_by_ids` 方法通过文档 ID 获取文档内容和元数据。
- `del_doc_by_ids` 方法删除指定 ID 的文档,实际调用基类的同名方法。
- `do_init` 方法在类初始化时被调用,用于加载 PGVector 实例。
- `do_create_kb` 方法是创建知识库的具体实现,当前为空实现。
- `vs_type` 方法返回支持的向量存储类型,即 PostgreSQL。
- `do_drop_kb` 方法删除知识库,包括数据库中的相关记录和文件系统上的知识库路径。
- `do_search` 方法实现了基于查询的文档搜索功能,返回与查询最相关的文档列表。
- `do_add_doc` 方法向知识库添加文档,并返回添加的文档信息。
- `do_delete_doc` 方法从知识库删除指定的文档。
- `do_clear_vs` 方法清空向量存储中的所有内容,并重新创建集合。
**注意**:
- 使用 PGKBService 类前确保 PostgreSQL 数据库已经正确配置,位置: kb_settings.yaml文件
- `kbs_config` 中 `pg` 配置。
- 在调用 `do_add_doc` 和 `do_delete_doc` 等方法修改数据库内容时,需要确保传入的参数符合预期格式,
- 以避免执行错误或数据损坏。
**输出示例**:
```python
# 假设调用 get_doc_by_ids 方法查询 ID 为 ['doc1', 'doc2'] 的文档
docs = pgkb_service.get_doc_by_ids(['doc1', 'doc2'])
# 可能的返回值为
[
Document(page_content="文档1的内容", metadata={"author": "作者1"}),
Document(page_content="文档2的内容", metadata={"author": "作者2"})
]
此示例展示了通过文档 ID 获取文档内容和元数据的过程及其可能的返回值。
Function Def _load_pg_vector(self)
_load_pg_vector: 此函数的功能是加载PostgreSQL向量空间搜索引擎。
参数: 此函数没有显式参数,但它依赖于类实例的多个属性。
代码描述: _load_pg_vector函数负责初始化一个PGVector实例,该实例用于在PostgreSQL数据库中进行向量空间搜索。这个过程包括以下几个关键步骤:
-
使用
EmbeddingsFunAdapter类创建一个嵌入函数适配器。这个适配器基于类实例的embed_model属性,用于将文本转换为向量表示。EmbeddingsFunAdapter支持同步和异步两种文本嵌入方式,适用于不同的应用场景。 -
指定向量空间搜索的集合名称,这里使用类实例的
kb_name属性作为集合名称。 -
设置距离策略为欧氏距离(
DistanceStrategy.EUCLIDEAN),用于计算向量之间的距离。 -
使用
PGKBService.engine作为数据库连接。这是一个类属性,表示与PostgreSQL数据库的连接引擎。 -
通过
kbs_config.get("pg").get("connection_uri")获取数据库连接字符串,这个字符串包含了数据库的地址、端口、用户名、密码等信息,用于建立数据库连接。
通过这些步骤,_load_pg_vector函数配置了一个用于向量空间搜索的PGVector实例,并将其保存在类实例的pg_vector属性中。这使得类的其他方法可以利用这个PGVector实例来执行向量空间搜索操作,例如查找与给定文本向量最相似的文档。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)