从Java到AI Agent:初级开发必备的核心技术宝典(含落地实战)
RAG(Retrieval Augmented Generation,检索增强生成)是**"外部知识库+大模型"的协同方案**——通过检索技术从本地/私有知识库中抓取相关信息,作为上下文补充给大模型,再生成回答。解决大模型"知识过期"问题:无需重新训练,更新知识库即可让模型掌握最新信息(如2025年行业政策、内部业务文档);提升回答准确性:基于真实数据源生成内容,大幅降低AI幻觉(尤其适用于医疗、
对于Java背景转型AI Agent开发的开发者而言,RAG、向量数据库、LangChain、Spring AI等核心技术是入门关键。本文将用"Java开发者易懂的语言"拆解核心概念,补充实战技巧与Java生态适配方案,帮你快速搭建Agent开发知识体系,避开常见坑点。
一、RAG核心:检索增强生成的底层逻辑与实战
1. 什么是RAG?核心价值在哪?
RAG(Retrieval Augmented Generation,检索增强生成)是**"外部知识库+大模型"的协同方案**——通过检索技术从本地/私有知识库中抓取相关信息,作为上下文补充给大模型,再生成回答。
核心价值体现在三点:
- 解决大模型"知识过期"问题:无需重新训练,更新知识库即可让模型掌握最新信息(如2025年行业政策、内部业务文档);
- 提升回答准确性:基于真实数据源生成内容,大幅降低AI幻觉(尤其适用于医疗、金融等严谨场景);
- 支持私有数据安全使用:内部文档无需上传至公网模型,兼顾数据隐私与AI能力。
2. 混合检索:解决"语义匹配+精准定位"的双重需求
纯向量检索擅长语义理解(如"手机续航强"与"电池使用时间长"的关联),但对专有名词(如"Spring AI 1.0")、缩写(如"RAG")的匹配精度不足;而关键词检索(如BM25算法)恰好相反,能精准命中特定术语,但缺乏语义关联能力。
混合检索就是将两者结合:先通过关键词检索快速筛选出候选文档,再用向量检索做语义精细化排序,既保证"不遗漏",又确保"找得准"。
流程图示例:
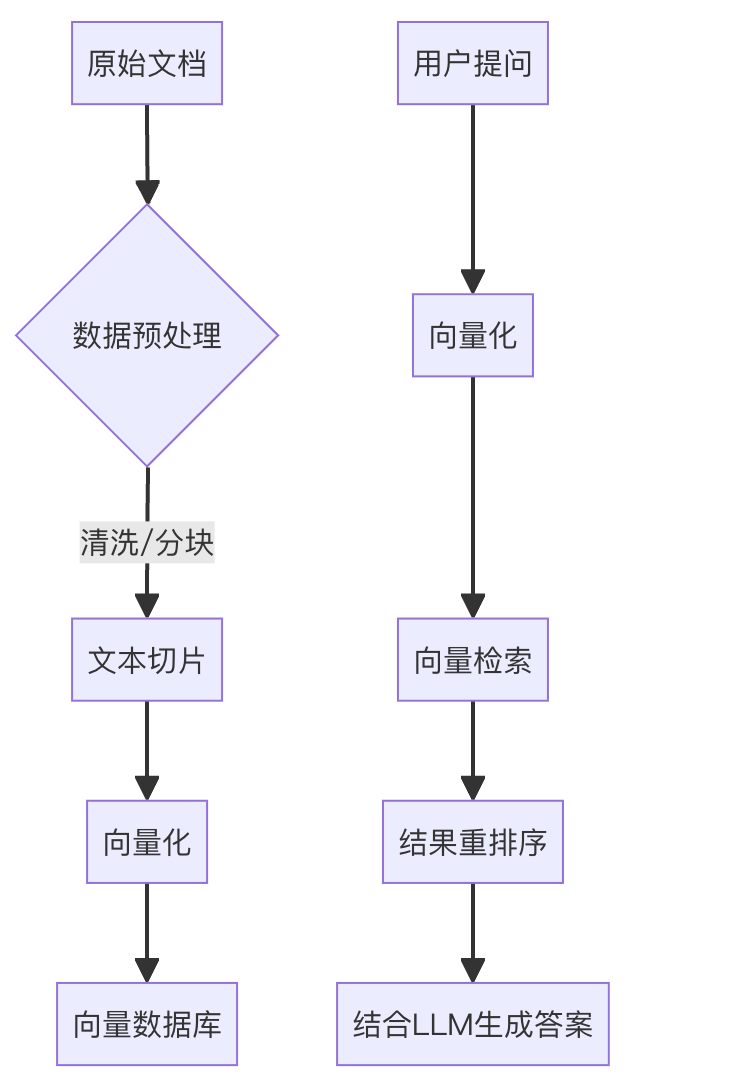
3. RAG完整流程:5个核心阶段(附Java技术栈适配)
RAG的执行流程可拆解为"数据准备→向量化→索引存储→检索增强→生成答案",对应Java开发者熟悉的"数据处理→存储→查询→应用"链路:
| 阶段 | 核心操作 | Java生态工具推荐 |
|---|---|---|
| 数据准备 | 文档解析(PDF/Word/HTML)、去重降噪、分块 | Apache Tika(文档解析)、Jsoup(HTML提取) |
| 向量化 | 文本转高维向量(保留语义) | Spring AI Embedding(封装OpenAI/BGE模型)、Hugging Face Java SDK |
| 索引存储 | 向量数据持久化,支持高效查询 | Milvus(Java SDK适配)、Elasticsearch(8.x+支持向量检索) |
| 检索增强 | 用户查询向量化,匹配相关文档 | Spring AI Retrieval(集成混合检索逻辑) |
| 生成答案 | 上下文+查询拼接,调用大模型 | Spring AI ChatClient(统一调用OpenAI/本地化模型) |
补充:从"开发视角"可简化为三阶段:
- 索引阶段:文档→分块→向量化→存入向量库(类似Java中"数据→DTO→数据库");
- 检索阶段:用户查询→向量化→混合检索→召回相关块(类似"查询条件→索引→数据库查询");
- 生成阶段:查询+相关块→Prompt工程→大模型生成(类似"请求参数→业务逻辑→响应结果")。
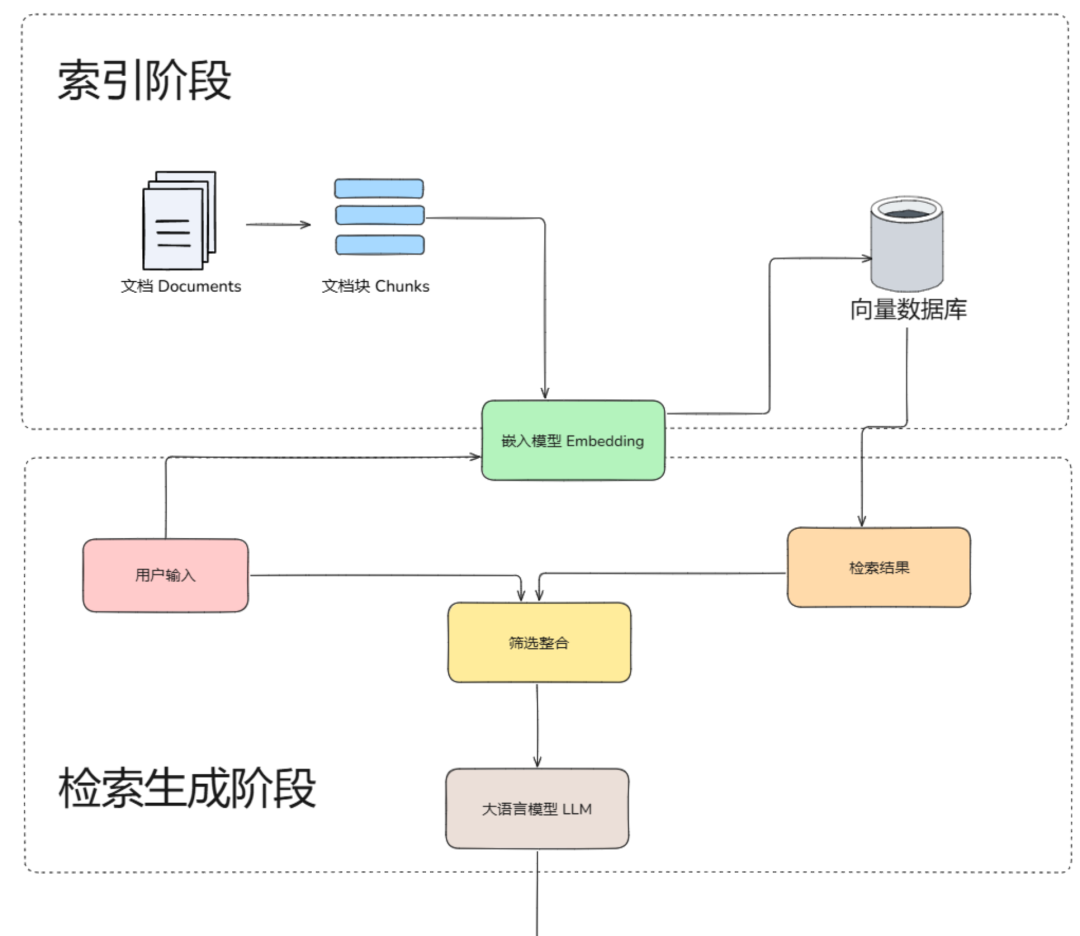
4. 数据清洗与预处理:RAG效果的"地基"(附实战技巧)
数据预处理直接影响检索精度,Java开发者可按以下步骤落地:
-
多源数据整合与格式统一
- 支持PDF/Word/CSV/API等多源数据,用Apache Tika提取纯文本,避免格式干扰;
- 统一编码为UTF-8,用正则表达式去除乱码(如
replaceAll("[^\\u0020-\\u007E\\u4E00-\\u9FA5]", " ")),统一大小写(避免"SpringAI"与"springai"被误判为不同词)。
-
清洗降噪与敏感信息处理
- 去除重复内容(如页眉页脚、会议记录中的重复发言),可用HashMap去重或SimHash算法检测相似文本;
- 过滤特殊字符、Markdown格式(如
###、**),保留核心语义; - 关键步骤:用正则或Spring AI的PII检测工具,删除手机号、邮箱、身份证号等敏感信息(如
replaceAll("1[3-9]\\d{9}", "***"))。
-
分块策略:平衡语义完整性与检索效率
- 核心原则:不切断上下文,适配大模型上下文窗口(如GPT-4 8k tokens可容纳10-15个500字块);
- 推荐方案:使用LlamaIndex的
RecursiveCharacterTextSplitter(优先按标题/段落切分,超长部分递归拆分),或Spring AI的TokenTextSplitter(按token数精准控制); - Java开发者注意:分块时可保留文档元数据(如文件名、章节、时间),用HashMap存储,后续检索时可作为过滤条件。
-
元数据标注:提升检索精准度
- 用规则或LLM提取结构化元数据(如文档发布时间、所属部门、关键词),例如给2025年的产品文档标注
{"year":"2025", "product":"AI助手", "tag":"技术文档"}; - 检索时可通过元数据过滤(如用户问"2025年的产品手册",直接筛选
year=2025的文档块),减少无效召回。
- 用规则或LLM提取结构化元数据(如文档发布时间、所属部门、关键词),例如给2025年的产品文档标注
5. 自查询(Self-Query):解决"隐含需求"的检索神器
当用户提问包含模糊条件(如"2025年鸭鸭的用户报告"),传统检索可能只匹配"用户报告",忽略"2025年"和"鸭鸭"这两个关键约束。
自查询的核心是:让LLM自动解析查询中的语义需求+元数据条件,生成结构化查询语句。例如上述查询会被拆解为:
- 语义匹配:用户报告
- 元数据过滤:author=鸭鸭、time=2025
Java落地技巧:使用Spring AI的SelfQueryRetriever,配置元数据字段(如year、author),让框架自动生成结构化查询,再调用向量数据库的过滤+检索接口,精准命中目标文档。
二、向量数据库:Agent的"长期记忆仓库"
1. 什么是向量数据库?为什么Agent离不开它?
向量数据库是专门存储和管理高维向量嵌入(文本/图像/音频的"数字指纹")的数据库,核心能力是高效相似性搜索——就像给Agent配备了一个"记忆大脑",能快速从海量数据中调取相关信息。
对于Java开发者,可类比为:传统关系型数据库(如MySQL)存储结构化数据(表、字段),而向量数据库存储"语义向量",支持按"语义相似度"查询(而非精确匹配)。
2. 核心解决的3个问题
- 高效相似性搜索:毫秒级匹配用户查询与知识库向量,支撑实时问答;
- 海量数据处理:轻松应对百万级、十亿级向量数据,远超传统数据库的检索能力;
- 动态更新支持:知识库新增/修改时,向量数据库可增量更新索引,无需全量重建(类似MySQL的增量备份)。
3. 核心原理:3步实现高效检索
- 向量化:用嵌入模型(如BGE、GPT-4 Embedding)将文本/图像转为高维向量(如768维数组),保留语义信息;
- 索引构建:通过HNSW(分层导航小世界)、PQ(产品量化)等算法构建索引,降低高维数据检索复杂度(类似MySQL的B+树索引);
- 近似搜索:采用ANN(近似最近邻)算法,在"速度"与"精度"间平衡,返回Top-K最相似结果(如前10个相关文档块)。
4. 常用相似性度量方法:怎么选?
| 方法 | 核心逻辑 | 适用场景 | Java代码示例(Spring AI) |
|---|---|---|---|
| 余弦相似度 | 衡量向量方向一致性(取值[-1,1]) | 文本语义匹配、推荐系统 | SimilarityMeasure.COSINE |
| 欧氏距离 | 计算向量空间直线距离(≥0) | 图像/视频特征匹配 | SimilarityMeasure.EUCLIDEAN |
| 曼哈顿距离 | 各维度差值绝对值之和(≥0) | 网格数据(如地图坐标) | SimilarityMeasure.MANHATTAN |
Java开发者选型建议:文本类Agent优先用余弦相似度(不关心文本长度,只看语义方向);如果是多模态Agent(如图文问答),可选用欧氏距离。
5. 主流向量数据库Java适配情况
| 向量数据库 | Java SDK支持 | 优势场景 |
|---|---|---|
| Milvus | 完善(官方SDK) | 大规模数据、高并发检索 |
| Elasticsearch | 原生支持(8.x+) | 已用ES的项目,无需额外部署 |
| Pinecone | 第三方SDK | 云原生、免运维 |
| Chroma | 轻量SDK | 本地开发、小规模测试 |
三、LangChain生态:Agent开发的"Spring框架"
对于Java开发者,LangChain就像AI领域的Spring——提供模块化组件和工具链,让你无需从零搭建Agent架构,专注业务逻辑开发。
1. 核心定位:连接大模型与外部能力
LangChain的核心价值是"解耦":将模型调用、提示词管理、工具集成、记忆存储等功能拆分为独立组件,通过"链(Chain)"和"智能体(Agent)“编排流程,类似Spring的"IoC容器+Bean装配”。
2. 核心组件:Java开发者需重点掌握
| 组件 | 作用 | 类比Java技术 |
|---|---|---|
| Models | 统一调用OpenAI/Anthropic/Llama等模型 | Spring Cloud的服务网关(统一接口) |
| Prompt Templates | 动态生成提示词(支持参数填充) | Thymeleaf模板引擎 |
| Memory | 存储对话上下文(短期/长期) | Redis缓存+数据库持久化 |
| Chains | 串联多步任务(如"检索→生成→总结") | Spring Batch(任务流转) |
| Agents | 动态决策工具调用(自主完成复杂任务) | 状态机+策略模式 |
| Tools | 外部能力扩展(API/数据库/搜索) | Spring Boot Starter(插件化集成) |
3. LangChain Agent:智能决策的"核心大脑"
LangChain Agent是基于LLM推理能力的"自主决策者"——无需预定义流程,能根据用户需求动态选择工具、拆分任务,类似Java中的"策略模式+工厂模式"组合。
工作流程示例(电商Agent"查询订单+退款申请"):
- 用户输入:“我昨天买的手机能退款吗?订单号12345”;
- Agent解析需求:需要先查询订单状态,再判断是否符合退款条件;
- 调用工具:调用"订单查询API",传入订单号12345;
- 接收结果:API返回"订单未发货,支持退款";
- 生成动作:调用"退款申请工具",自动填充订单信息;
- 返回结果:告知用户"退款已提交,预计1-3个工作日到账"。
4. LangGraph:复杂Agent的"流程编排引擎"
当Agent需要多角色协作(如"客服Agent+财务Agent+物流Agent")或状态管理时,LangGraph是最佳选择——它将流程建模为有向图(DAG),支持分支、循环、人工干预等复杂逻辑。
核心区别:
- LangChain:线性流程(如"检索→生成"),适合简单任务;
- LangGraph:图结构流程(支持循环、分支),适合复杂任务(如审批流程、多Agent协作)。
Java开发者落地建议:简单Agent用LangChain的SequentialChain;复杂Agent用LangGraph编排多节点流程,结合LangChain的工具组件。
四、Spring AI:Java开发者的AI Agent快速开发框架
对于Java技术栈团队,Spring AI是衔接Spring生态与AI能力的最佳桥梁——无需学习新的开发范式,用Spring Boot的方式快速搭建AI应用。
1. 核心特性:Java开发者的"福音"
- 统一API:对大模型、向量数据库、工具调用提供标准化接口,切换OpenAI和本地化模型无需修改代码;
- 自动配置:类似Spring Boot Starter,引入依赖即可快速集成(如
spring-ai-openai-starter); - 与Spring生态无缝兼容:支持Spring MVC、Spring Data、Spring Security等,可直接嵌入现有Java项目;
- 结构化输出:自动将大模型响应映射为POJO(如将"订单状态"响应转为
OrderStatusDTO),无需手动解析JSON。
2. 核心功能实战:工具调用与RAG集成
(1)工具调用(Tool Calling)实现步骤
Java开发者可通过注解快速定义工具,让Agent自动调用:
- 定义工具类(用
@Tool注解标记方法):
@Component
public class OrderTool {
// 订单查询工具
@Tool("查询订单状态,参数为订单号")
public OrderStatusDTO queryOrder(@ToolParam("orderNo") String orderNo) {
// 调用订单系统API查询逻辑
return orderService.getOrderStatus(orderNo);
}
}
- 配置ChatClient,注册工具:
@Configuration
public class SpringAiConfig {
@Bean
public ChatClient chatClient(ChatClient.Builder builder, OrderTool orderTool) {
return builder
.defaultTools(orderTool) // 注册工具
.build();
}
}
- 发起对话,Agent自动调用工具:
@RestController
public class AgentController {
@Autowired
private ChatClient chatClient;
@PostMapping("/chat")
public String chat(@RequestBody String userInput) {
return chatClient.prompt()
.user(userInput)
.call()
.content();
}
}
当用户输入"查询订单12345的状态",Agent会自动调用queryOrder方法,返回结果后生成自然语言回复。
(2)RAG集成:Spring AI + 向量数据库
Spring AI提供RetrievalAugmentationAdvisor,可快速实现RAG功能:
@Bean
public RetrievalAugmentationAdvisor retrievalAdvisor(EmbeddingClient embeddingClient, VectorStore vectorStore) {
// 配置检索器:从向量库中召回前5个相关文档
Retrieval retrieval = Retrieval.from(vectorStore, 5);
// 构建RAG增强器
return RetrievalAugmentationAdvisor.from(retrieval, embeddingClient);
}
// 配置ChatClient,启用RAG增强
@Bean
public ChatClient chatClient(ChatClient.Builder builder, RetrievalAugmentationAdvisor advisor) {
return builder
.advisor(advisor) // 注入RAG增强器
.build();
}
3. 长期记忆实现:Spring AI + 向量数据库
Spring AI结合向量数据库可轻松实现Agent的长期记忆:
- 短期记忆:利用
ConversationMemory存储当前会话上下文(默认基于内存); - 长期记忆:将历史对话向量化后存入向量数据库,新会话时通过RAG召回相关历史:
@Bean
public VectorStore vectorStore(EmbeddingClient embeddingClient) {
// 使用Elasticsearch作为向量存储(已部署ES 8.x)
return ElasticsearchVectorStore.builder()
.client(elasticsearchClient)
.embeddingClient(embeddingClient)
.indexName("agent_memory")
.build();
}
// 保存对话记忆
public void saveConversation(String userId, String userInput, String aiResponse) {
String content = String.format("用户:%s\nAI:%s", userInput, aiResponse);
Document document = Document.from(content)
.withMetadata("userId", userId);
vectorStore.add(List.of(document));
}
五、Agent开发关键问题:避坑指南与解决方案
1. RAG检索不准?3个优化方向
- 预处理优化:调整分块大小(复杂文档用300-500字,简单文档用800-1000字),增加元数据标注;
- 检索策略:启用混合检索(向量检索+BM25关键词检索),用Spring AI的
HybridRetriever; - 后处理优化:对召回结果进行重排序(如用Cross-Encoder模型),过滤低相似度文档(阈值建议≥0.7)。
2. 如何平衡AI幻觉与效率?
- 技术手段:RAG+知识图谱(确保数据源权威)、提示词约束(明确"仅基于提供的知识库回答")、输出校验(用正则或LLM自身校验关键信息);
- 工程方案:建立"人机协作机制"——AI生成的关键结果(如医疗诊断、财务决策)需人工审核后再输出。
3. 大模型输出重复/幻觉?微调与工程方案结合
- 微调优化:采用PEFT(参数高效微调),用高质量、无重复的领域数据训练,引入"重复惩罚因子";
- 工程手段:提示词中加入"禁止重复内容",使用RAG提供实时数据源,避免模型依赖过期知识。
4. 多知识库如何高效检索?
- 知识路由:用轻量LLM(如Llama 3 8B)作为路由模型,根据用户查询判断所属知识库(如"技术文档"→技术知识库,"财务政策"→财务知识库);
- 分阶段检索:先在各知识库内粗召回(Top20),再汇总到全局重排序(Top10),兼顾效率与准确性。
六、Java开发者转型Agent开发:学习路径建议
- 基础阶段:掌握RAG核心流程、向量数据库原理(重点关注Java SDK使用);
- 工具阶段:熟悉LangChain生态组件,用Spring AI快速搭建简单Agent(如文档问答、客服助手);
- 进阶阶段:学习LangGraph实现复杂流程编排,掌握Agent的记忆机制、工具调用优化;
- 实战阶段:落地多模态Agent(如图文问答)、多Agent协作系统(如电商售后Agent),结合Java生态实现规模化部署。
通过以上核心技术拆解与实战技巧,Java开发者可快速打通Agent开发的"任督二脉"。建议从简单的RAG文档问答系统入手,逐步引入LangChain/Spring AI框架,最终实现复杂场景的Agent落地。记住:Agent开发的核心是"模块化思维+工程化落地",这与Java开发的核心理念高度一致,你的Java技术积累将成为转型路上的重要优势!
如今技术圈降薪裁员频频爆发,传统岗位大批缩水,相反AI相关技术岗疯狂扩招,薪资逆势上涨150%,大厂老板们甚至开出70-100W年薪,挖掘AI大模型人才!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻
是不是也想抓住这次风口,但卡在 “入门无门”?
- 小白:想学大模型,却分不清 LLM、微调、部署,不知道从哪下手?
- 传统程序员:想转型,担心基础不够,找不到适配的学习路径?
- 求职党:备考大厂 AI 岗,资料零散杂乱,面试真题刷不完?
别再浪费时间踩坑!2025 年最新 AI 大模型全套学习资料已整理完毕,不管你是想入门的小白,还是想转型的传统程序员,这份资料都能帮你少走 90% 的弯路
👇👇扫码免费领取全部内容👇👇

部分资料展示
一、 AI大模型学习路线图,厘清要学哪些
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:大模型核心原理与Prompt
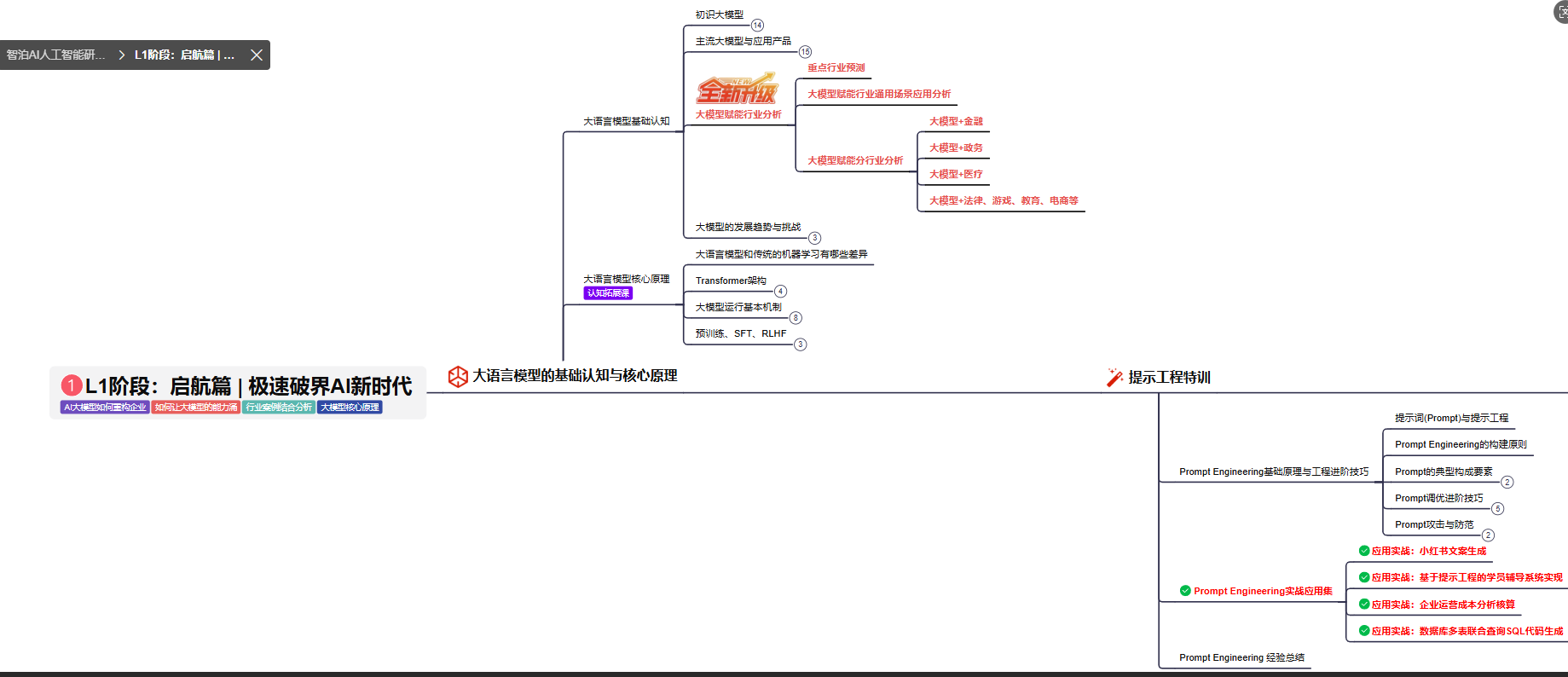
L1阶段: 将全面介绍大语言模型的基本概念、发展历程、核心原理及行业应用。从A11.0到A12.0的变迁,深入解析大模型与通用人工智能的关系。同时,详解OpenAl模型、国产大模型等,并探讨大模型的未来趋势与挑战。此外,还涵盖Pvthon基础、提示工程等内容。
目标与收益:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为AI应用开发打下坚实基础。
L2级别:RAG应用开发工程
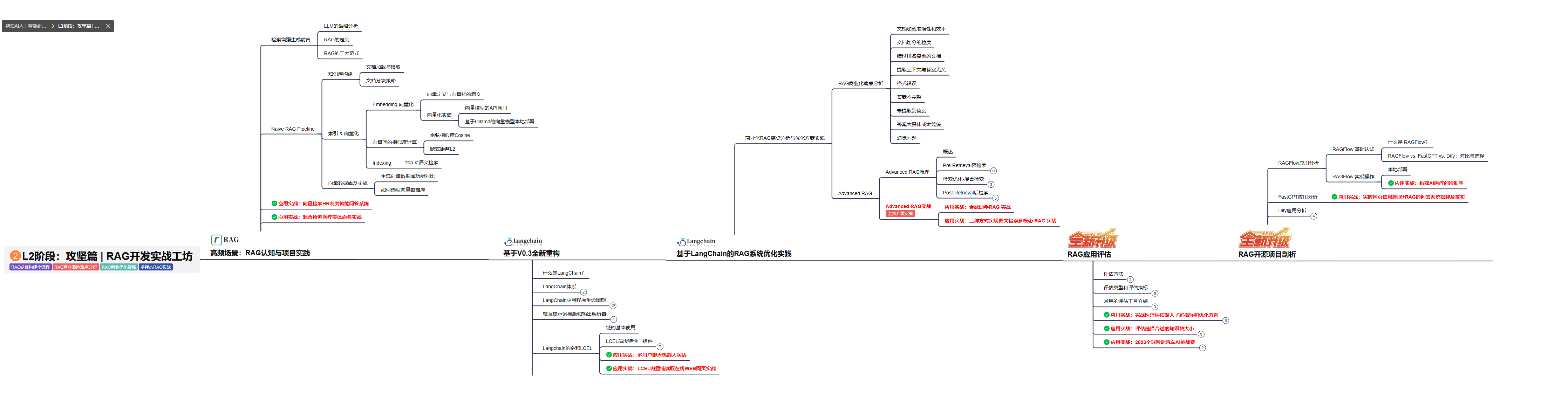
L2阶段: 将深入讲解AI大模型RAG应用开发工程,涵盖Naive RAGPipeline构建、AdvancedRAG前治技术解读、商业化分析与优化方案,以及项目评估与热门项目精讲。通过实战项目,提升RAG应用开发能力。
目标与收益: 掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
L3级别:Agent应用架构进阶实践
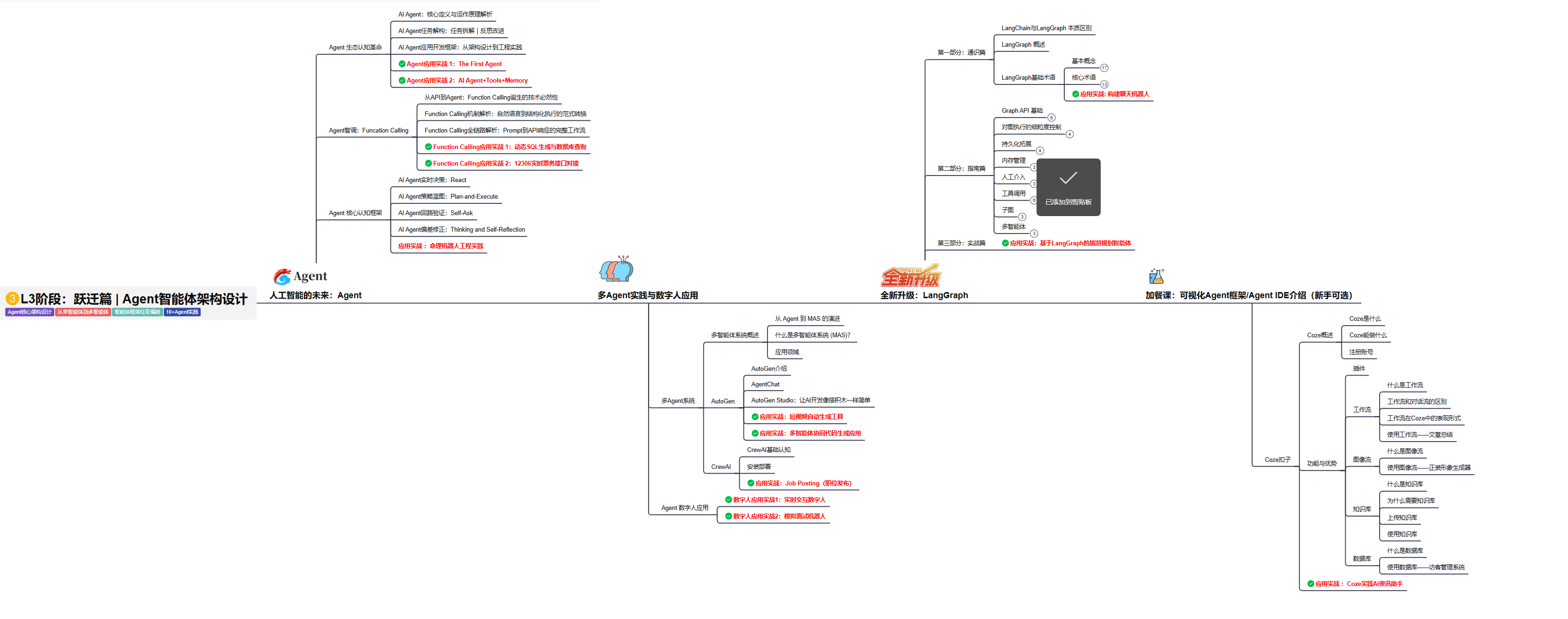
L3阶段: 将 深入探索大模型Agent技术的进阶实践,从Langchain框架的核心组件到Agents的关键技术分析,再到funcation calling与Agent认知框架的深入探讨。同时,通过多个实战项目,如企业知识库、命理Agent机器人、多智能体协同代码生成应用等,以及可视化开发框架与IDE的介绍,全面展示大模型Agent技术的应用与构建。
目标与收益:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
L4级别:模型微调与私有化大模型
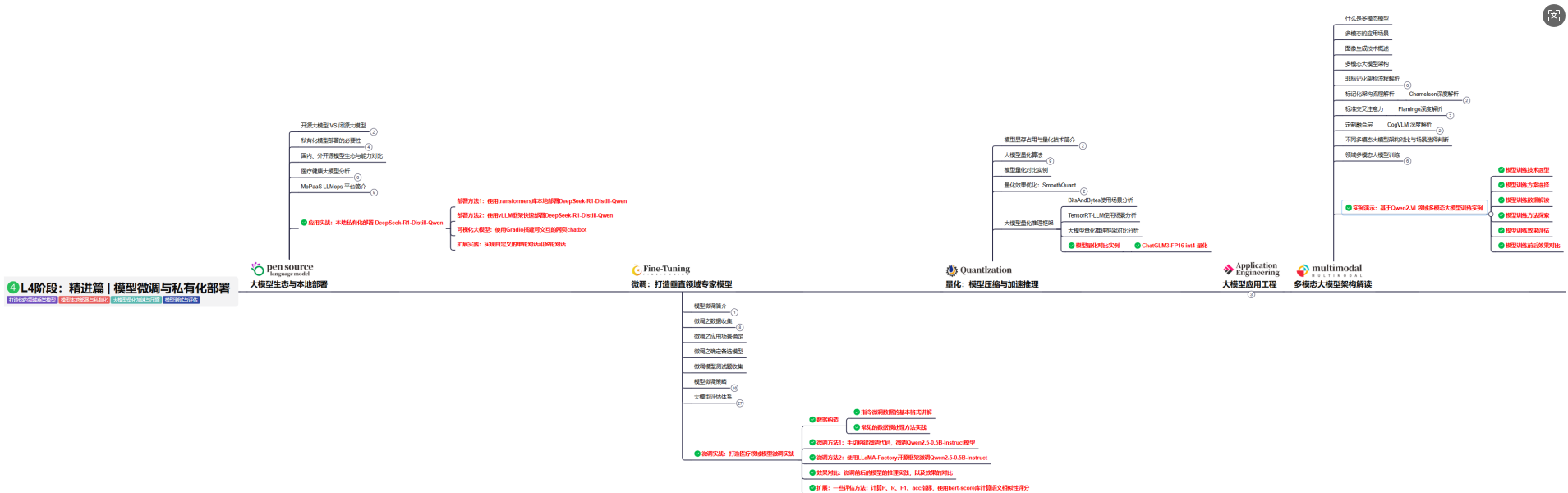
L4级别: 将聚焦大模型微调技术与私有化部署,涵盖开源模型评估、微调方法、PEFT主流技术、LORA及其扩展、模型量化技术、大模型应用引警以及多模态模型。通过chatGlM与Lama3的实战案例,深化理论与实践结合。
目标与收益:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。
二、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

三、 大模型学习书籍&文档
收录《从零做大模型》《动手做AI Agent》等经典著作,搭配阿里云、腾讯云官方技术白皮书,帮你夯实理论基础。

四、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

五、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

六、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

适用人群

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献264条内容
已为社区贡献264条内容

所有评论(0)