【干货收藏】Prompt工程VS模型训练:大模型能力的终极边界深度解析
本文从底层视角剖析了Prompt工程与模型训练的本质区别与边界。指出Prompt工程是通过设计巧妙context改变输出,属于输入重构;而模型训练是将外部知识编码进参数θ的三层结构(知识记忆、表示学习、元学习)。信息存储位置不同(参数vs上下文)且可压缩性差异大。Prompt工程虽能指定任务和触发推理,但无法弥补能力缺口、处理细粒度知识或保证安全一致性。未来格局是分层协作:底层预训练、中层微调对齐
本文从底层视角剖析了Prompt工程与模型训练的本质区别与边界。指出Prompt工程是通过设计巧妙context改变输出,属于输入重构;而模型训练是将外部知识编码进参数θ的三层结构(知识记忆、表示学习、元学习)。信息存储位置不同(参数vs上下文)且可压缩性差异大。Prompt工程虽能指定任务和触发推理,但无法弥补能力缺口、处理细粒度知识或保证安全一致性。未来格局是分层协作:底层预训练、中层微调对齐、上层Prompt工程与RAG等工具结合。
1 、LLM的本质
可以把一个大模型抽象成一个条件概率分布:
训练:在海量文本数据上,通过梯度下降,更新θ,让模型更好地拟合真实数据分布。
Prompt:在θ固定不变的前提下,修改context,从而改变输出。
2 、Prompt工程的本质
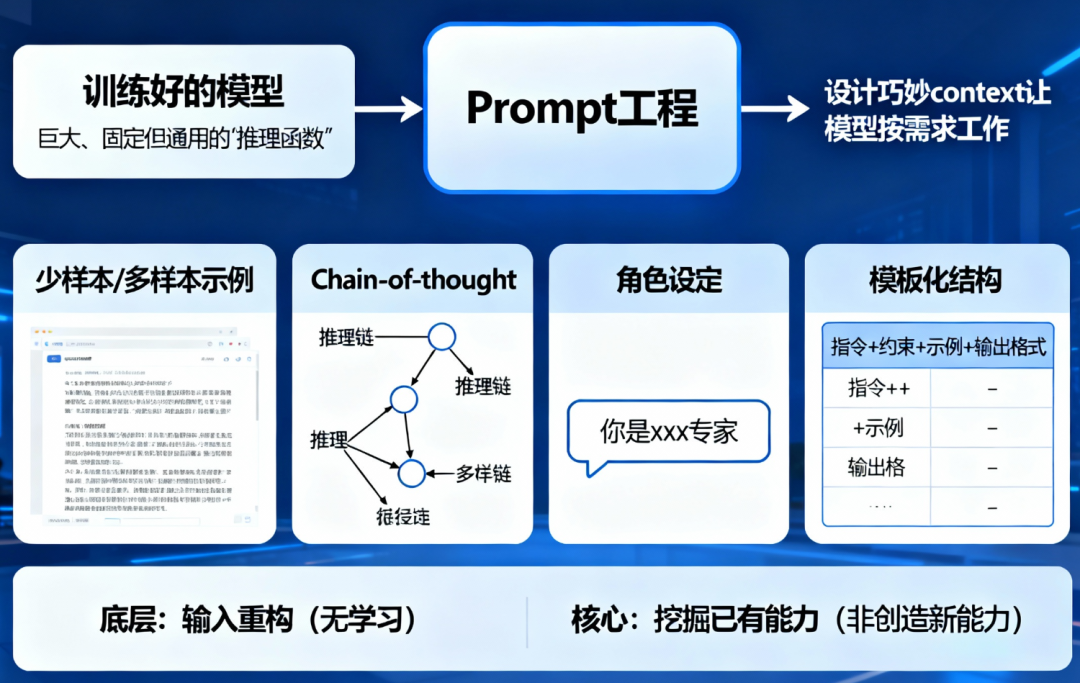
可以把已经训练好的模型看成一个巨大、固定但非常通用的推理函数。Prompt 工程做的事情其实只有一件:设计一个巧妙的context,让 fθ 以想要的方式工作。典型手段:
少样本 / 多样本示例(few-shot / many-shot);Chain-of-thought(显式推理链);角色设定(你是一个 xxx 专家);模板化结构(指令 + 约束 + 示例 + 输出格式)
这些都属于输入重构,底层并没有任何「学习」,模型只是调用它在预训练阶段已经学会的统计模式和内隐算法。
3 、大模型训练的本质
训练(包括预训练和微调)是干一件 Prompt 做不到的事:把外部数据里的模式、知识和算法,编码进参数 θ。分三层:
表层知识记忆:事实:谁是谁、公式、API、网络协议…
中层表示学习:把语义、语法、逻辑、代码结构等压缩成一个高维流形上的分布。
深层元学习能力:模型会在上下文内看几个示例 → 推测任务 → 模仿模式。
4、 信息论角度 Prompt vs 训练
4.1 信息存储位置不一样
训练:信息被写进模型参数θ(参数空间),是长期记忆。
Prompt:信息被塞进context(上下文窗口里),是短期记忆。
上下文窗口是有限的,比如 128K tokens。不可能靠 Prompt 把一个 10GB 的知识库长期写进模型,最多是临时塞一点进去。
4.2 可压缩性差异
训练的过程本质是做一个高效压缩:用 N 个参数,泛化地表达巨量数据中稳定的模式和规律。
而 Prompt 是在线重复描述:每次用的时候,都要把关键信息重新丢进 context 里,模型现场计算。
同一个任务,如果通过训练(微调),prompt可以短得多,性能也更稳定。只靠prompt,需要提供大量示例和解释,浪费上下文和token,推理成本高。
5、 Prompt工程的极限在哪?
5.1 可以做的事情
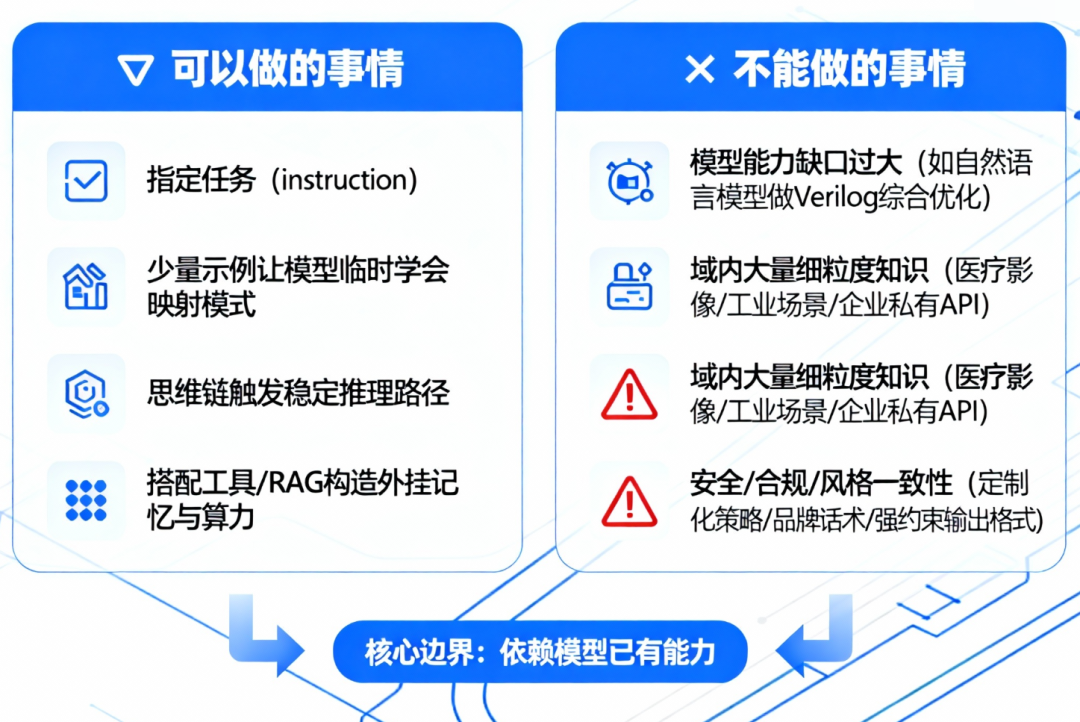
在已有通用能力上,指定任务(instruction)。
用少量示例,让模型临时学会某个映射模式。
通过思维链,触发模型更稳定的推理路径。
搭配工具 / 检索(RAG)构造「外挂记忆」与「外挂算力」。
5.2 不能做的事情
模型「能力缺口」过大时:拿一个只在自然语言上预训练的模型,让它做 Verilog 综合优化。模型里根本没有这方面的模式与表示,只能胡扯。想象你跟一个没学过微积分的人说:你是一个顶级微积分大师,从现在开始这样那样思考……。对方气势可以很足,但不会突然会算偏导。
域内大量、细粒度知识:医疗影像某个细分类别诊断标准;极细分工业场景的报警与策略映射;某企业内部业务流程、历史bug、私有 API。
安全、合规、风格一致性:企业定制化安全策略;品牌语气、话术统一要求;强约束输出格式(例如特定 schema 的JSON,错误要非常少)。
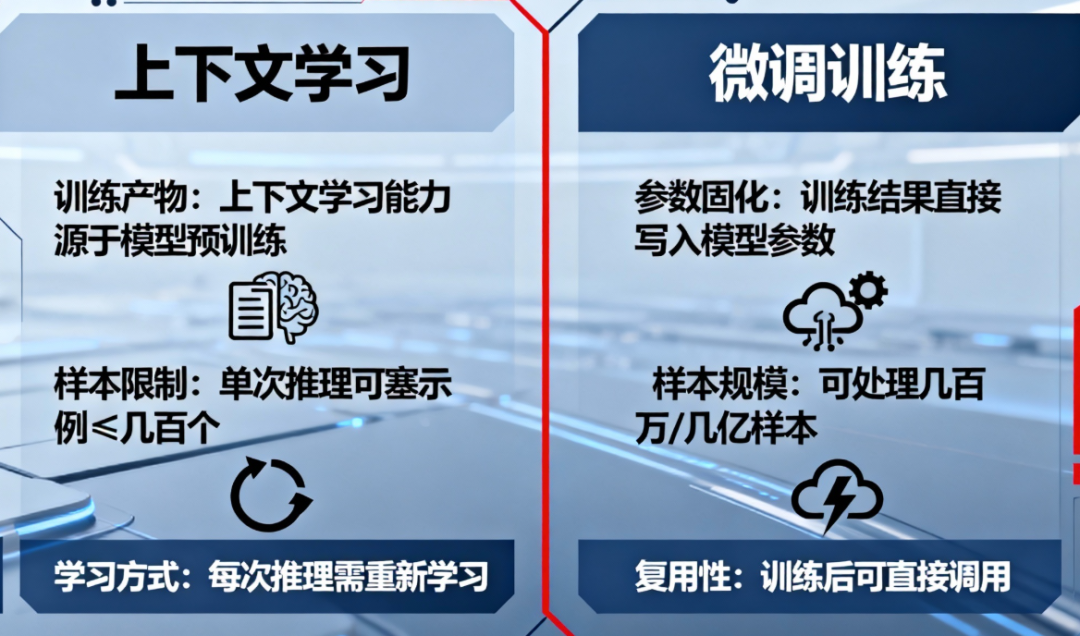
6 、上下文学习能否替代模型训练?
既然模型可以在上下文里「看几个示例 → 学会一个任务」,那我们是不是可以完全靠 prompt few-shot 来代替微调?
本身就是训练出来的能力:它不是替代训练,而是训练的产物。
批量样本受上下文长度限制:能塞的示例就那么多,几百个已经很夸张了。微调可以吃几百万、几亿样本。
每次推理都要重新学习一遍:微调是学完写进参数,之后可以直接用。
7、 RAG+Prompt能否替代模型训练?
现在流行RAG(检索增强生成),模型只管读懂资料和生成,真正的知识放在外部向量库里,那是不是以后都不用训练新模型了,只要RAG+prompt?
RAG解决的是知识时效性和外部大知识库接入,它避免了频繁重新训练模型来更新知识,确实很有价值。
但 RAG 依赖的关键能力是:模型要能理解检索结果,能把检索到的多段文档进行融合、推理、比较、归纳,这些高层能力,仍然是预训练 + 微调写进参数里的。
8 、未来的格局是分层协作
底层大规模预训练:学语言、代码、逻辑推理的通用能力;学上下文学习机制(看几例就会模仿任务)。
中层微调、对齐:对齐安全、价值观、企业规范;领域专精(医疗、法律、工业控制、金融)。
上层Prompt工程+RAG+工具调用+Agent框架:把一个通用、对齐、专精后的模型,通过 prompt 组装成各种应用形态,动态接入外部知识、数据库、API、程序。
限时免费!CSDN 大模型学习大礼包开放领取!
从入门到进阶,助你快速掌握核心技能!
资料目录
- AI大模型学习路线图
- 配套视频教程
- 大模型学习书籍
- AI大模型最新行业报告
- 大模型项目实战
- 面试题合集
👇👇扫码免费领取全部内容👇👇

📚 资源包核心内容一览:
1、 AI大模型学习路线图
- 成长路线图 & 学习规划: 科学系统的新手入门指南,避免走弯路,明确学习方向。

2、配套视频教程
- 根据学习路线配套的视频教程:涵盖核心知识板块,告别晦涩文字,快速理解重点难点。

课程精彩瞬间

3、大模型学习书籍

4、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

6、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献264条内容
已为社区贡献264条内容

所有评论(0)