【模型推理篇】vLLM核心思想 - ③ Kernel内核优化(attn backend、cuBLAS、CUTLASS)
最近身体抱恙断更了,北京这温度不穿秋裤确实不行…长期作为AI修仙界的散修(偶像韩立),也形成了自己一套学习新招式的套路,就比如像下面这种 “官方简历”,就至少需要全部掌握;所以继续看看vLLM的其他核心能力,今天就盘盘它偏底层的内核优化;
最近身体抱恙断更了,北京这温度不穿秋裤确实不行…
今天继续 vLLM 推理框架核心思想的第三篇,前两篇文章分别介绍了:
长期作为AI修仙界的散修(偶像韩立),也形成了自己一套学习新招式的套路,就比如像下面这种 “官方简历”,就至少需要全部掌握;
所以继续看看vLLM的其他核心能力,今天就盘盘它偏底层的内核优化;

Attention backend
官方这句原话的后半句,指的是 vLLM 提供了多种 attn 后端 backend,这里可以直接看源码 vllm\attention\selector.py
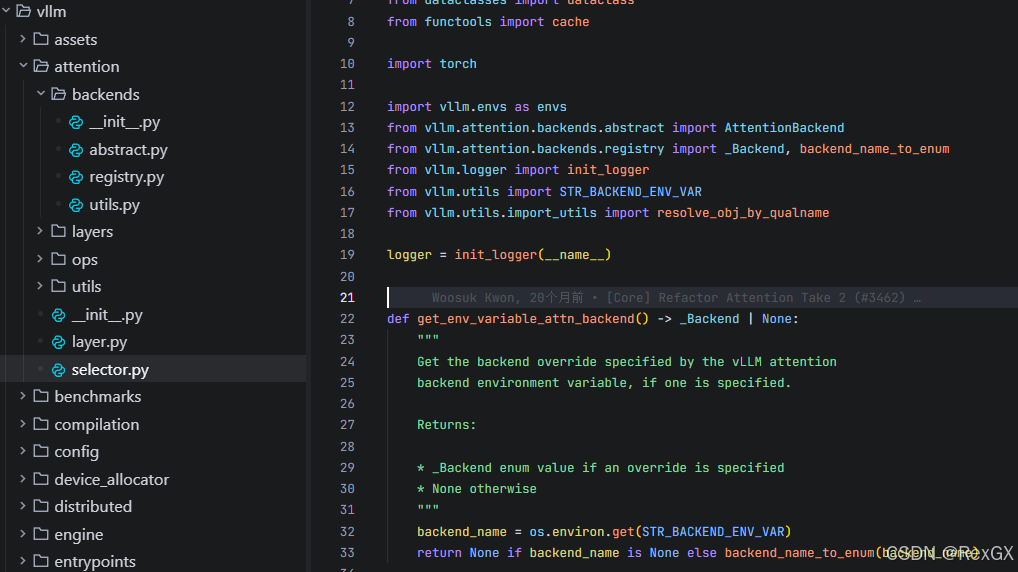
selector.py 内,如果通过 参数 指定了使用哪种 attn backend,则 backend_name_to_enum() 会从 attn backend 注册过的 类型中进行选择,即 registery.py,这里可以看到各种 attn backend 实现:
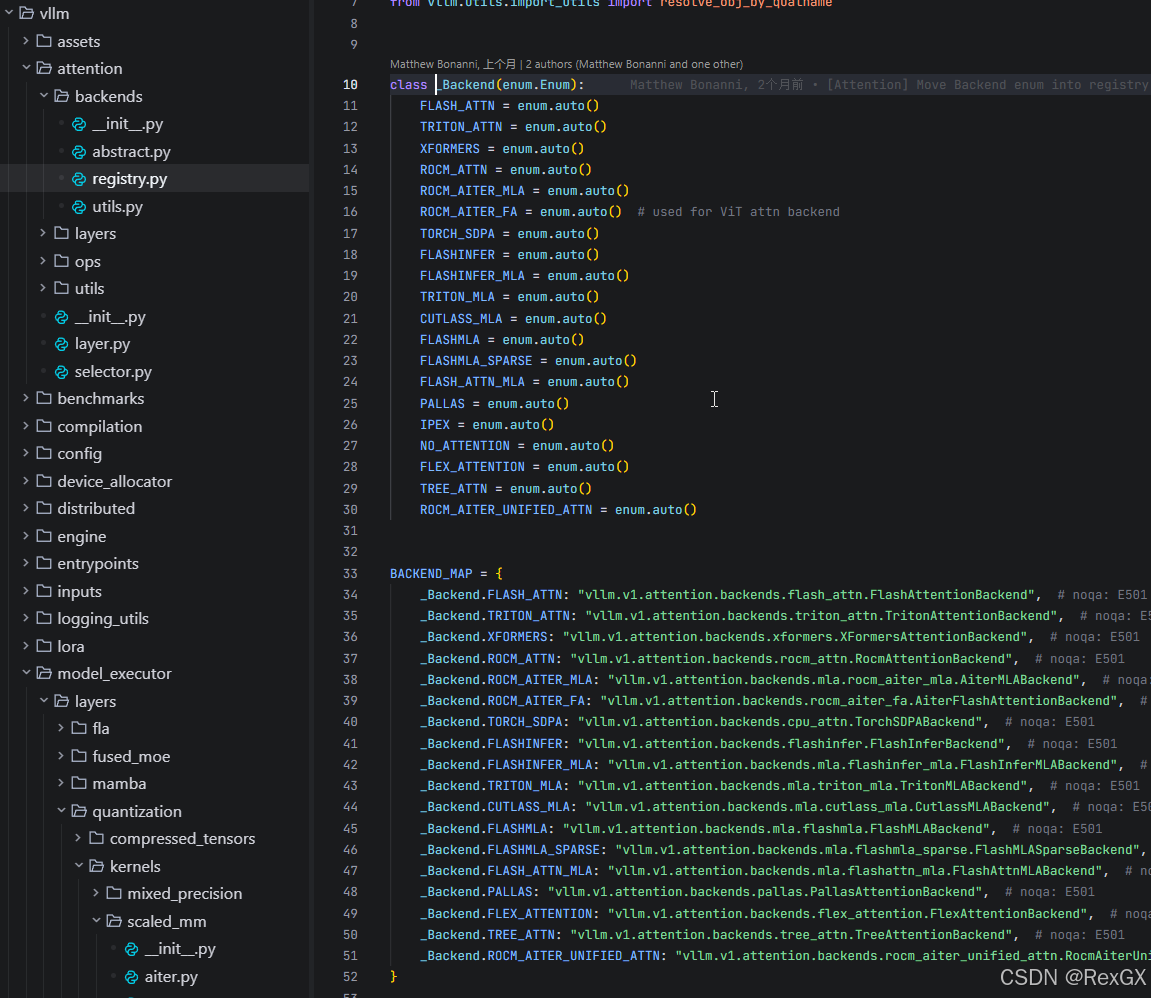
看起来很不错是吧,啥都有,开箱即用;
但如果没指定的话,selector.py 的 get_attn_backend 方法会调用一个 LRU_Cache 缓存的 _cached_get_attn_backend
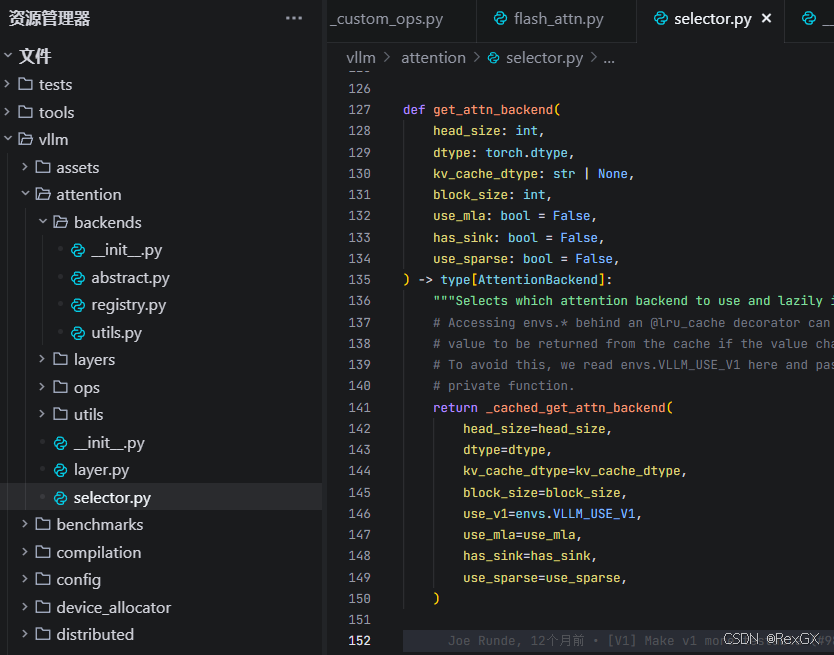
第一次看到这就好奇,这有啥可cache的,直到看了 current_platform.get_attn_backend_cls() 方法的实现
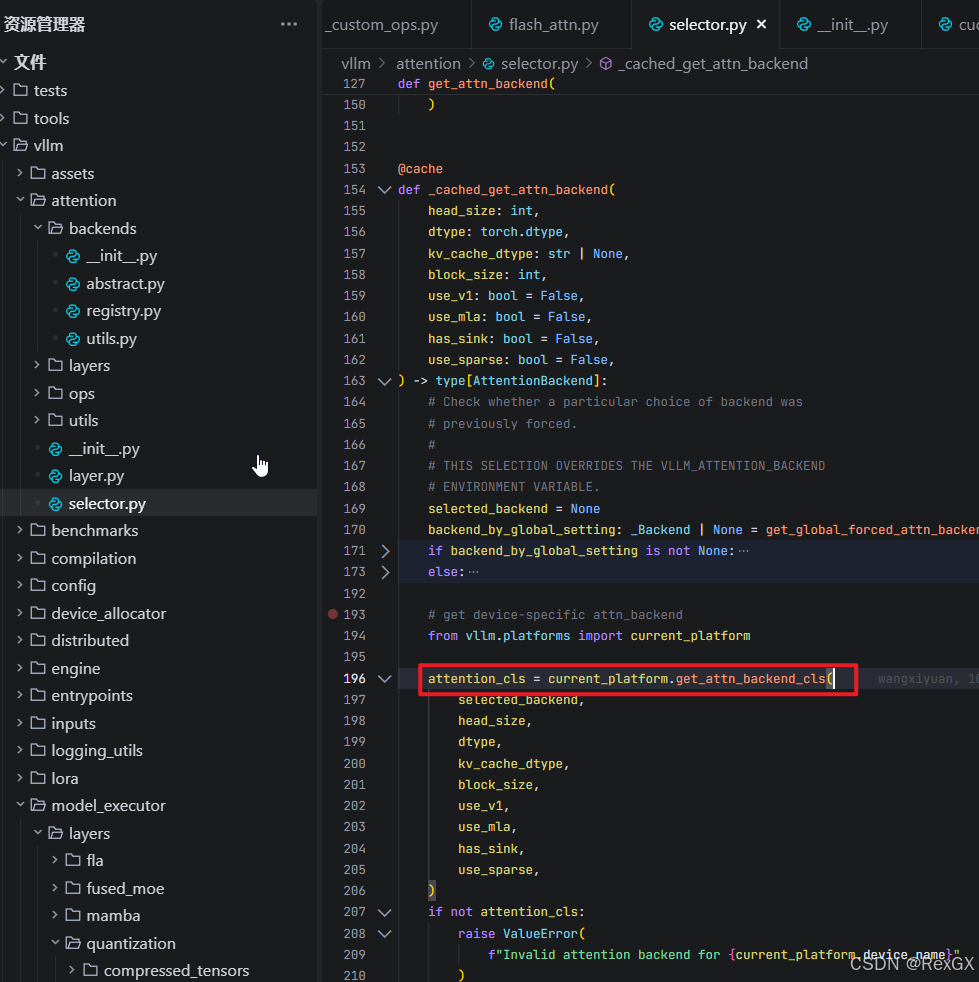
current_platform 是一个 动态的、平台感知代理,它有很多实现:感知当前平台是CPU、GPU、TPU 还是 AMD
之后会在特定平台内,再根据不同架构、块大小等各种环境条件,进行复杂的硬件检测、兼容性验证…
例如下面GPU平台下的部分逻辑:
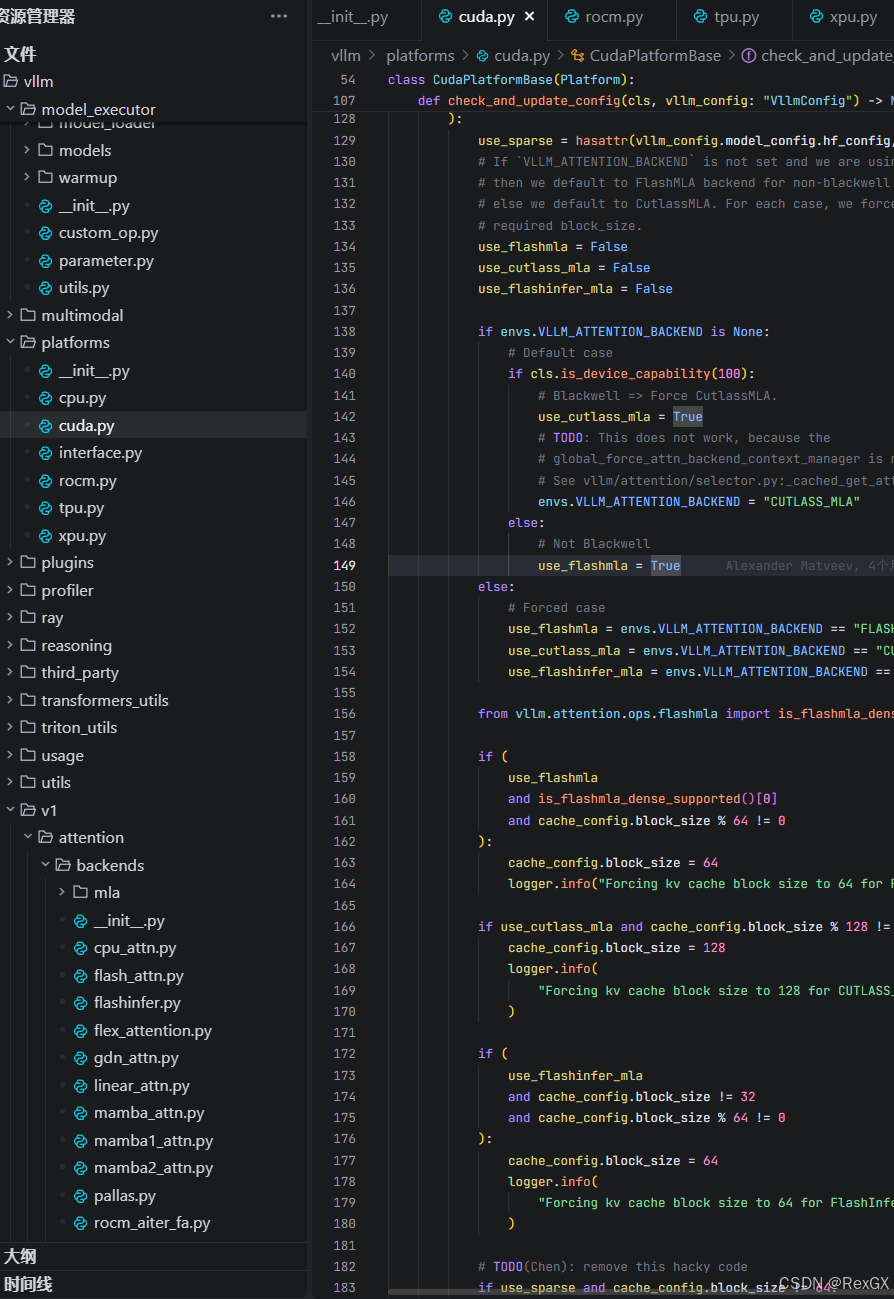
各种 if-else 分支,这也就解释了啥需要搞一个 LRU-Cache 了,不然每次都要执行;
具体每种 attn backend 就不深入看了;
上图这段代码中看到了 cutlass,所以下面就稍微瞅瞅 vLLM 中都有哪些其他的内核优化;
cuBLAS
cuBLAS 是 Nvidia 提供的高性能 GPU 矩阵运算优化库,在 vLLM 中 cuBLAS 被用于:
- 高效执行 GEMM 矩阵乘运算
- 针对不同精度、数据类型等的优化实现
下面展示vLLM中的一个cuBLAS应用;
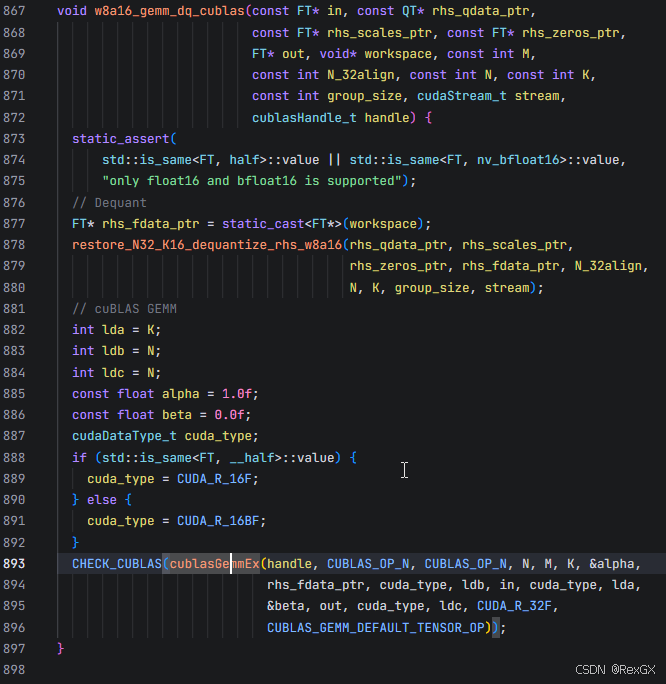
vLLM实现了一个高效的量化线性层kernel AllSparkLinearKernel 继承自 MPLinearKernel,主要用于执行 混合精度矩阵乘 w8a16
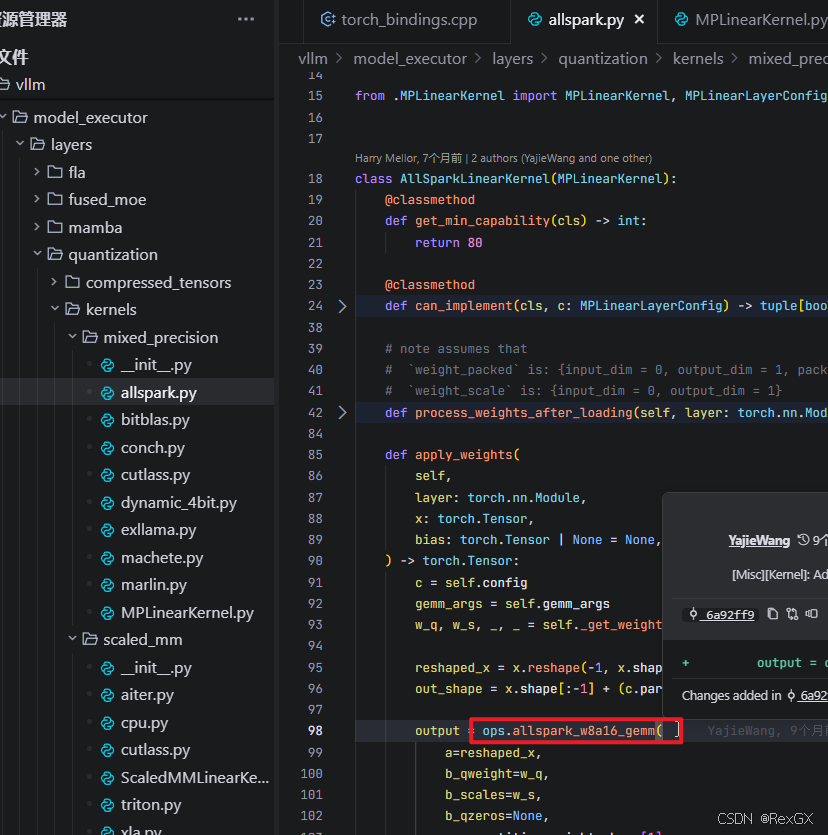
上图中的 allspark_w8a16_gemm 也注册到了 PyTorch 中

方法 all_spark_w8a16_gemm 会先执行一系列的 assert check,然后根据矩阵大小选择使用 cuBLAS 还是 自定义的内核进行计算:
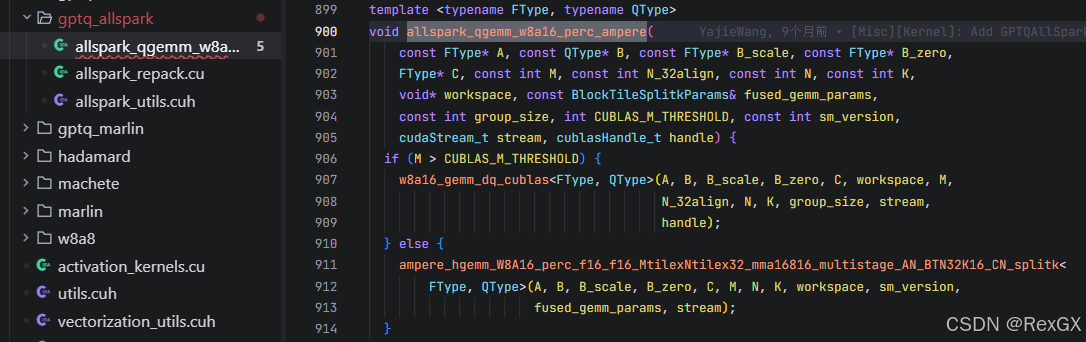
如果大于阈值的话,最终会直接调用 cuBLAS 进行 gemm
CUTLASS
CUTLASS 是 Nvidia 提供的偏底层的模板库,对比 cuBLAS:
cuBLAS属于高级抽象API,可以直接调用,但更黑盒;CUTLASS偏底层,属于低级API,"低级"指的是它更底层cuBLAS灵活性较低,因为属于高层抽象API,所以都是固定API;CUTLASS底层API可以更好的定制,灵活度更高cuBLAS开箱即用,简单上手直接调用;CUTLASS难度更高,上手相对更困难
所以总结起来就是,简单直接的任务,使用 cuBLAS,需要精细定制化的任务,使用 CUTLASS
下面以 CUTLASS 处理量化的矩阵乘为例;
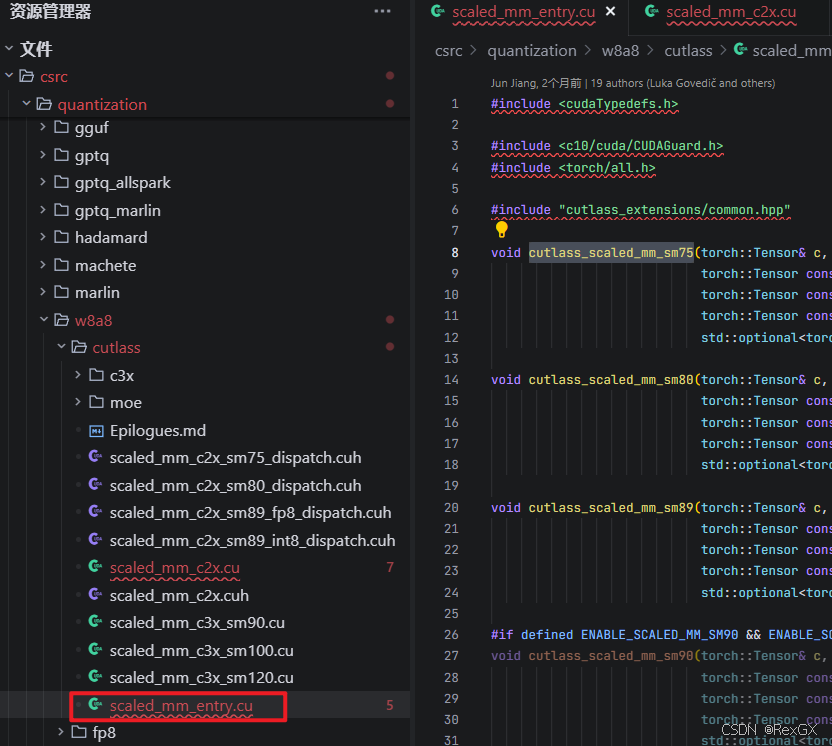
在vLLM中,通过 scaled_mm_entry 根据GPU架构自动选择具体实现;
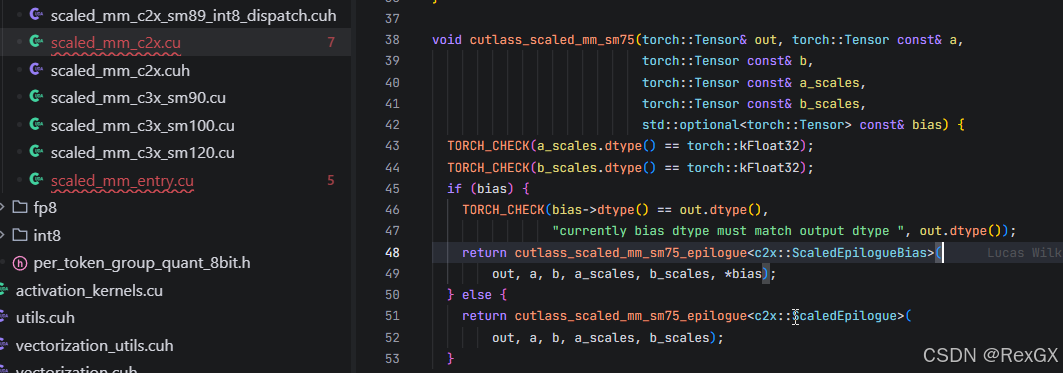
以其中的 cutlass_scaled_mm_sm75 图灵架构为例,根据是否有bias偏执使用不同的实现
再根据不同的数据类型,进行分派dispatch
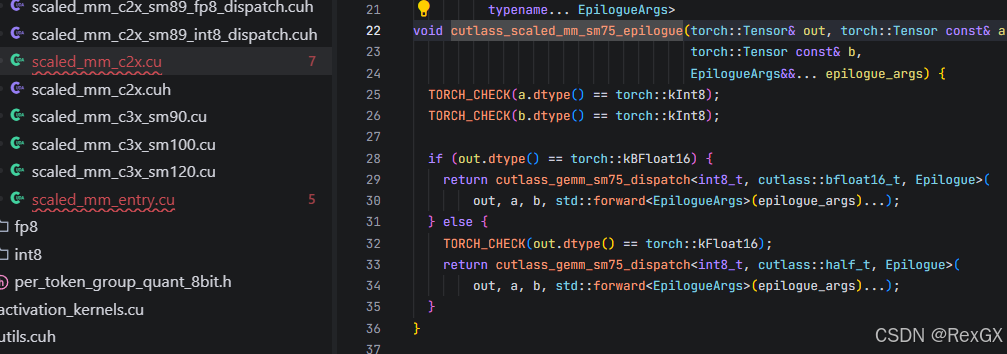
在dispatch内部,针对不同尺寸定义了多种配置,其中的默认配置 Cutlass2xGemmDefault 是为了共享内存不足时,进行回退;
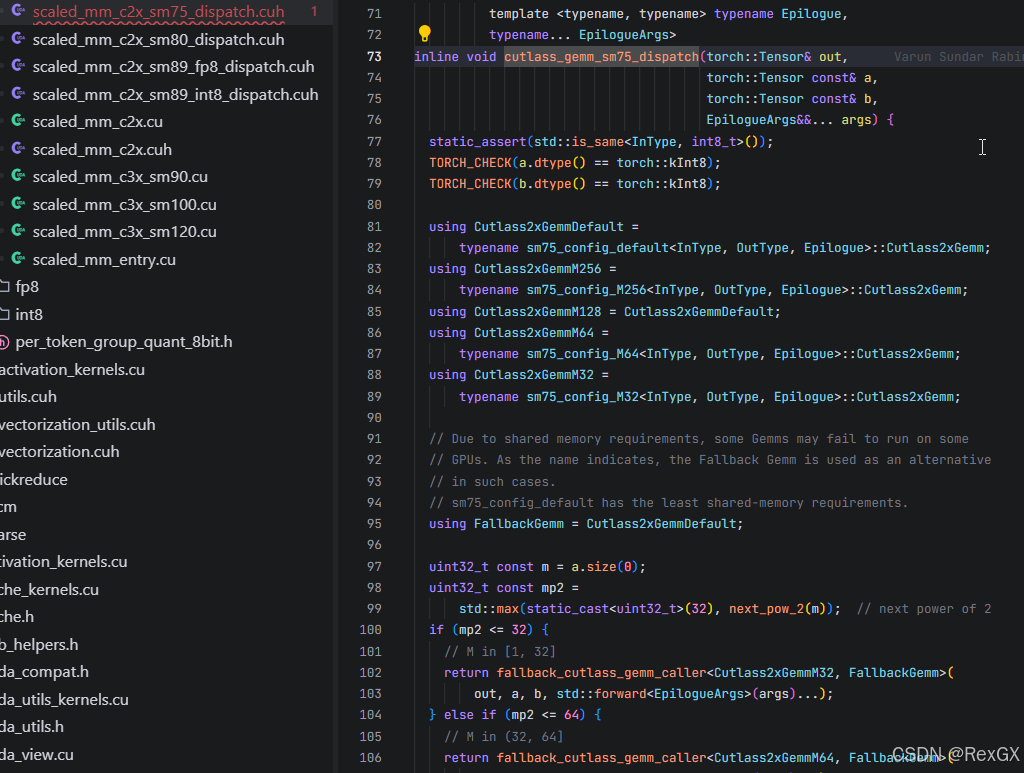
再底层自定义的结构体,以及优化的cutlass gemm操作,由于之前没研究过,知识储备不足,精力也有限,暂时就不深入了~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)