基于python的网络爬虫
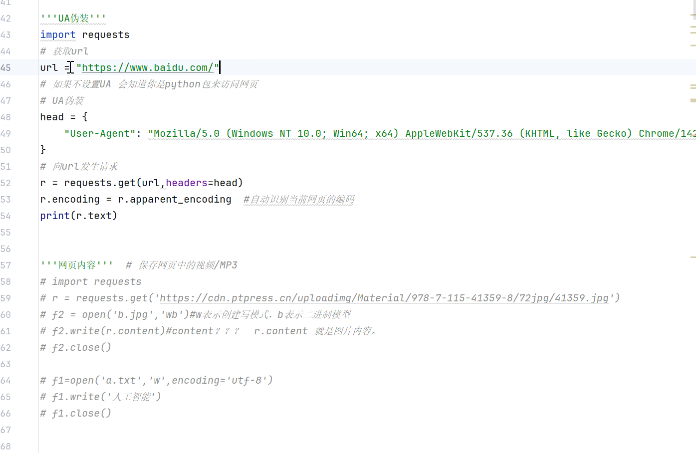
以ua伪装为例:ua即urser agent(用户代理):指客户端(如浏览器、手机 App、爬虫程序)向服务器发送请求时,附带的一段 “身份标识字符串”,用于告诉服务器 “我是什么设备 / 程序”。如下图,ua伪装通过获取网页内容时添加头文件中ua的伪装实现反反爬。伪装身份在哪里找:以获取浏览器访问百度的ua为例:浏览器打开百度,鼠标右击选择检查 ,选择网络,选择第一项双击进入,刚进来不会显示ua
网络爬虫通俗的讲就是使用代码将HTML网页上的内容(例如网页中的数据,图片,视频等)下载到本地的过程。python语言提供了多个具有网络爬虫功能的库,下面具体介绍。
urllib库:python自带的标准库,包含大量网络爬虫功能,但是其代码编写比较复杂。
requests库:第三方库,需要自行安装,是依赖于urllib的库,使用起来更加简洁方便。
scrapy库:适用于专业开发应用程序的第三方库,是专业的网络爬虫库。
selenium库:用于自动驱动浏览器实现办公自动化和web应用程序测试的第三官方库。
1、robots.txt 文件的作用
robots.txt 是一个位于网站根目录的文本文件,用于告知网络爬虫(如搜索引擎蜘蛛)哪些页面或目录可以访问,哪些应被限制。它遵循 Robots 排除协议(REP),是网站与爬虫之间的通信工具。
robots.txt 的基本语法:
文件由多条规则组成,每条规则包含以下部分:
- User-agent: 指定规则适用的爬虫名称(如
*表示所有爬虫)。 - Disallow: 禁止爬虫访问的路径。
- Allow: 允许爬虫访问的路径(优先级高于
Disallow)。 - sitemap:网站地图,用于提供网站中所有可以被爬取的url。
只需要在官网域名后后面加上/robots.txt就可以进入robots.txt规则界面。
以百度的robots.txt为例:
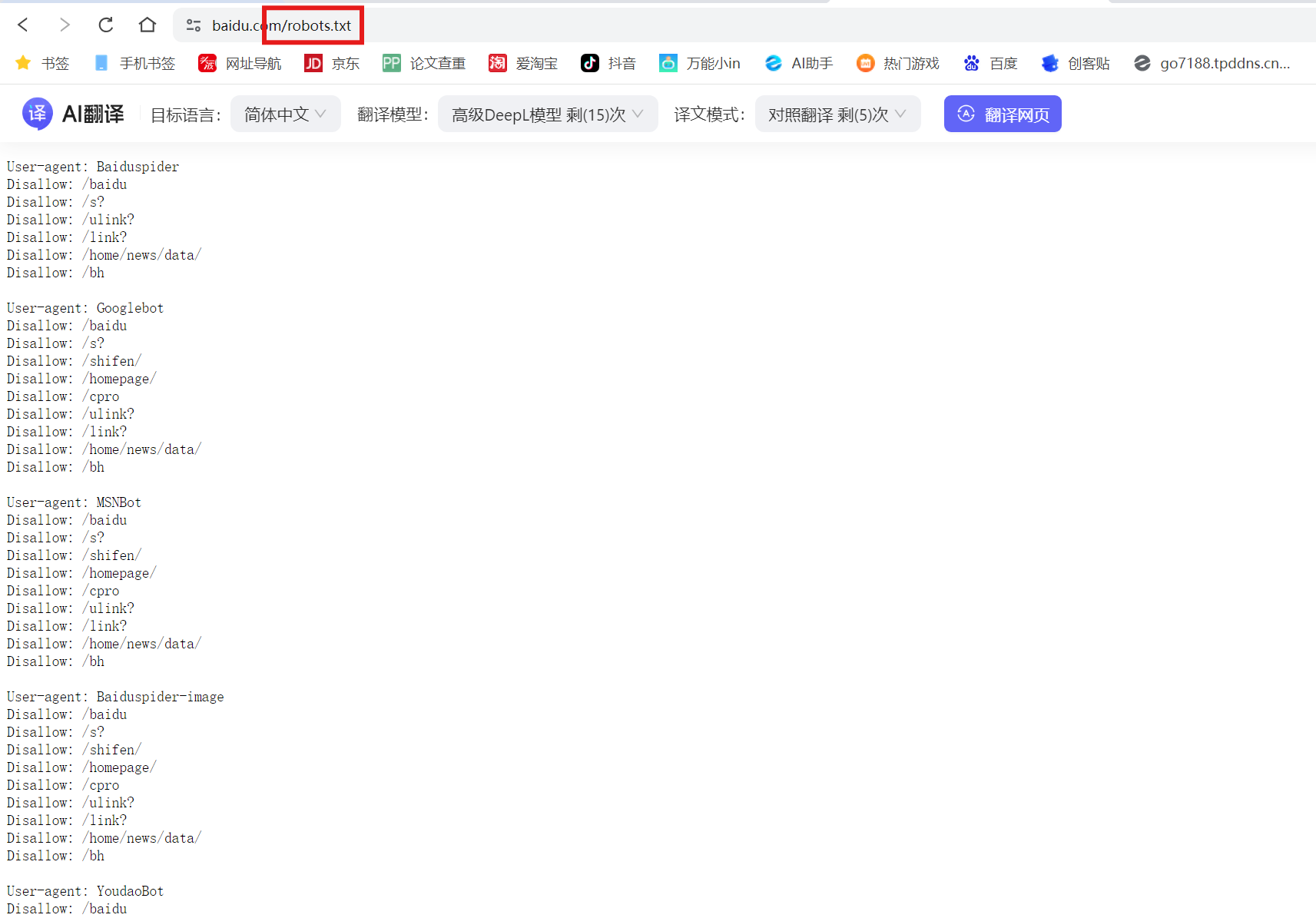
使用网络爬虫应该遵守相关协议及规定。
2、requests库
requests是一个流行的HTTP库,用于发送各种HTTP请求。它简化了与Web服务的交互过程,支持GET、POST等常见HTTP方法。
1、安装:
pip install requests -i https://mirrors.aliyun.com/pypi/simple/
2、get()函数:
requests库中获取HTML网页内容的方法。使用requests.get()方法可以发送GET请求。该方法会返回一个Response对象,包含服务器返回的所有信息。
import requests
response = requests.get('https://www.example.com')
print(response.status_code) # 打印状态码
print(response.text) # 打印响应内容
1、Response对象提供了多种属性和方法来处理返回的数据:
response.status_code:HTTP状态码(状态码是HTTP协议中服务器对客户端请求的响应结果的三位数字代码,用于表示请求的处理状态,常见的如200表示请求成功,404 Not Found表示请求的资源不存在)。response.text:以字符串形式返回响应内容(这里返回的内容和网页的源代码是一样的)。response的属性还包括:headers,url,encoding,cookies等。
2、传递参数:
通过params参数可以在GET请求中传递查询参数:参数需要时字典的形式,用{}创建。
params = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://www.example.com/api', params=params)
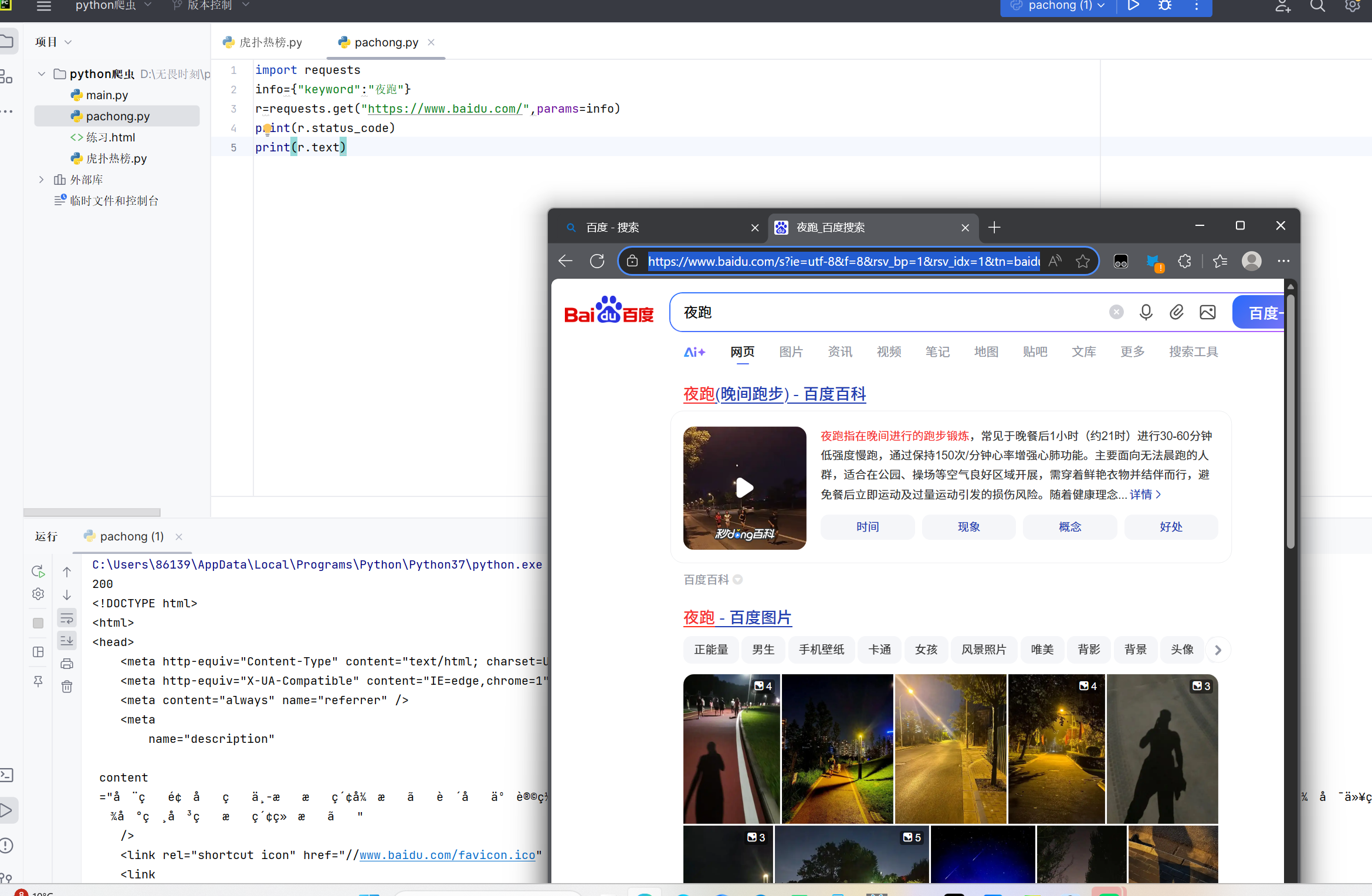
3、实例:访问百度官网搜索夜跑
执行代码会自动进入百度官网并搜索夜跑,如下图
4、实例:实现爬取虎扑热点
目标:使用我们刚才学的requests库中get方法获取网页内容,利用re库findall函数匹配网页HTML文件中的热榜信息。
实现步骤:
1、观察网页源代码中热榜信息格式的特点: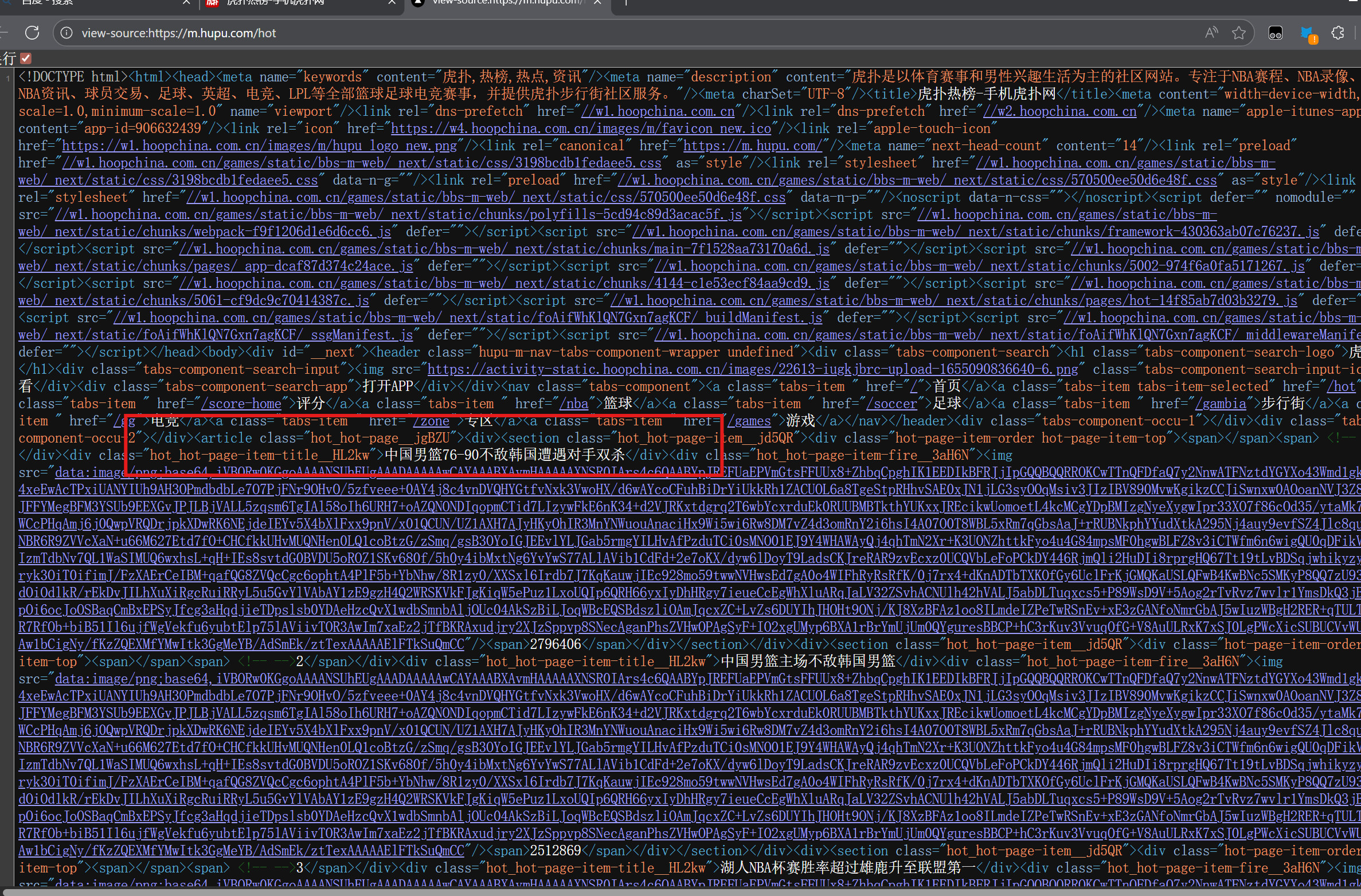
热点信息总是在class="hot_hot-page-item-title__HL2kw">和</div>之间。
2、设计代码:
import requests #导入爬虫库
import re #导入re库,以使用正则表达式匹配热榜信息
result=requests.get(url="https://m.hupu.com/hot") #get方法获取网页内容
rebang=re.findall(r'class="hot_hot-page-item-title__HL2kw">(.+?)</div>',result.text) #根据热点信息格式特点,设计正则表达式匹配热点信息
#采用了组()的方式,匹配result.text(字符串形式返回的网页文件源代码)中所有形如class="hot_hot-page-item-title__HL2kw">(.+?)</div>的字符串,并以列表的形式返回组()中的内容
for i in range(1,len(rebang)+1):
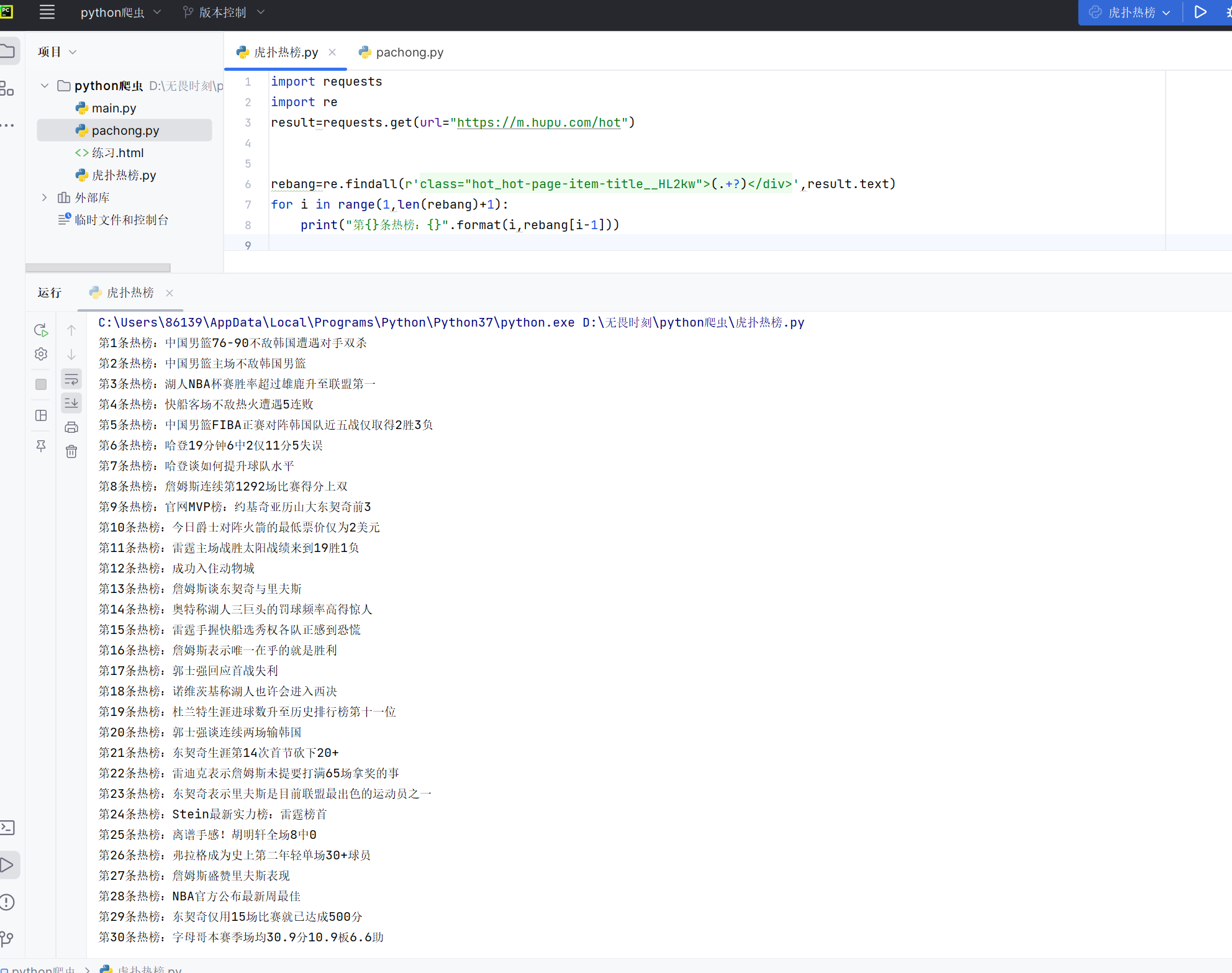
print("第{}条热榜:{}".format(i,rebang[i-1]))
#循环结构输出列表中的热点信息3、运行结果:
3、简单介绍反爬与反反爬:

以ua伪装为例:
ua即urser agent(用户代理):指客户端(如浏览器、手机 App、爬虫程序)向服务器发送请求时,附带的一段 “身份标识字符串”,用于告诉服务器 “我是什么设备 / 程序”。
如下图,ua伪装通过获取网页内容时添加头文件中ua的伪装实现反反爬。
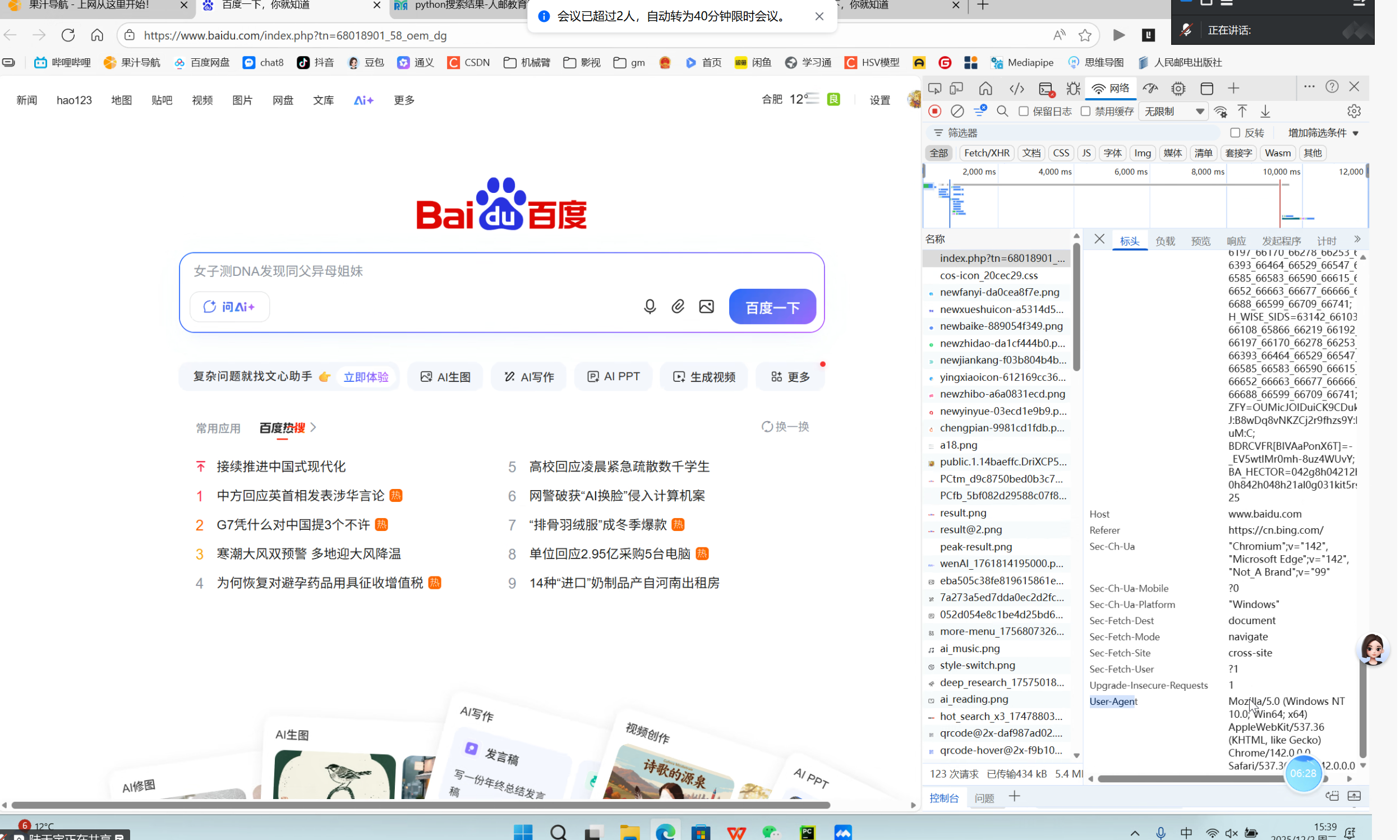
伪装身份在哪里找:
以获取浏览器访问百度的ua为例:
浏览器打开百度,鼠标右击选择检查 ,选择网络,选择第一项双击进入,刚进来不会显示ua需要刷新网页,最后一行就是ua,复制就行。
4、解析库lxml
lxml 是 Python 生态中 高性能、功能强大的 XML/HTML 解析库,基于 C 语言编写的 libxml2 和 libxslt 库封装而成,兼顾了速度与易用性,广泛用于网页爬虫、数据提取、XML 文档处理等场景(比如爬虫框架 Scrapy 就默认使用 lxml 作为核心解析器)。
lxml是第三方库,需要自行安装。
有了lxml我们爬取网页内容就不需要使用前面的正则表达式匹配的方法爬取网页内容,lxml提供了很方便的方法获取指定位置的内容,展开来讲:
在爬虫开发中,提取网页内容的核心需求是 “精准定位并获取目标数据”。之前我们可能会用正则表达式(Regex)匹配内容,但正则需要编写复杂的匹配规则,还容易因 HTML 结构微小变化导致匹配失效(比如标签属性顺序调整、多一个空格),维护成本很高。
而 lxml 解析库的出现,彻底解决了这个痛点—— 它结合 XPath 语法,提供了直观、高效的方式获取网页指定位置的内容,无需纠结正则的符号细节,直接按 HTML 结构 “导航” 就能拿到数据。
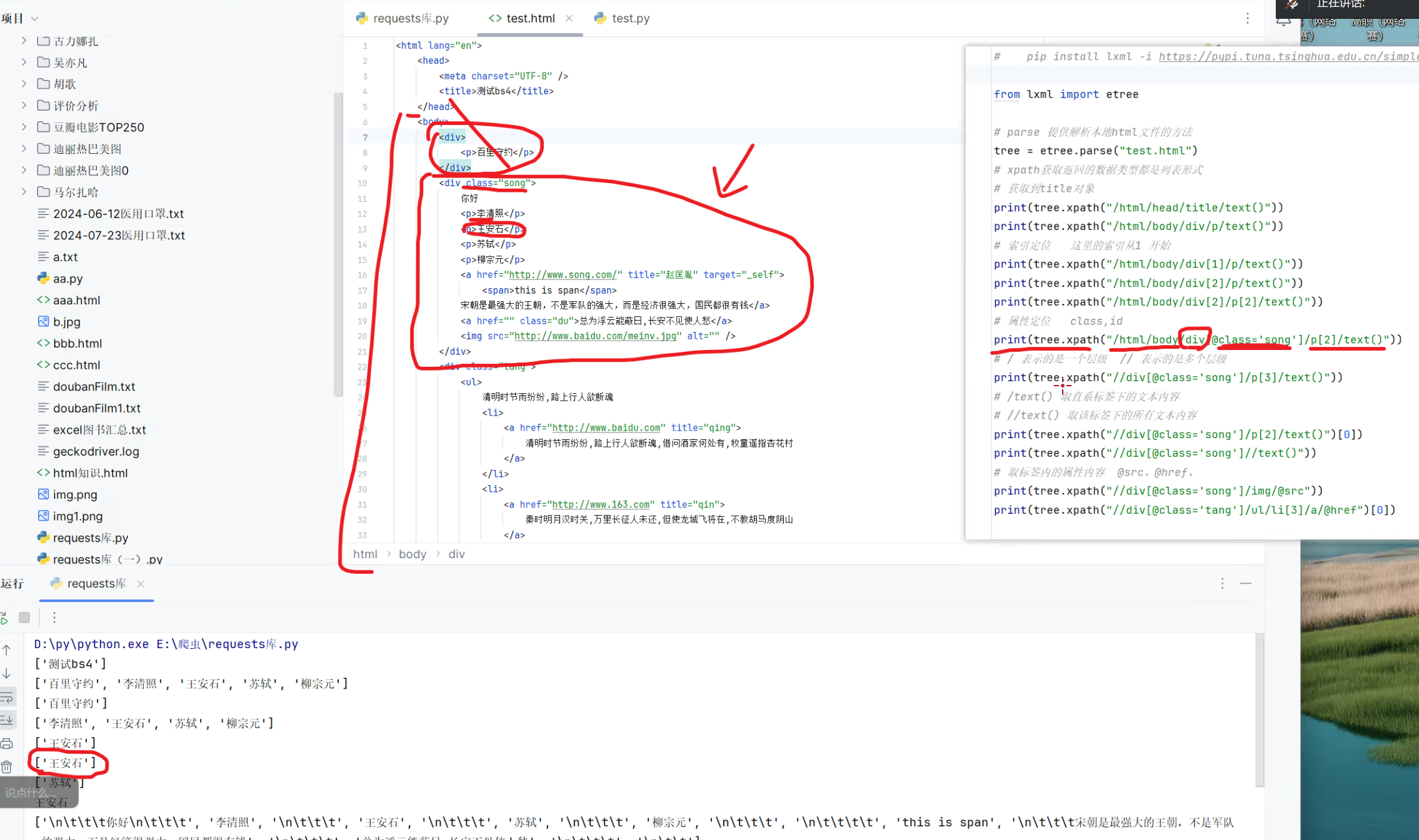
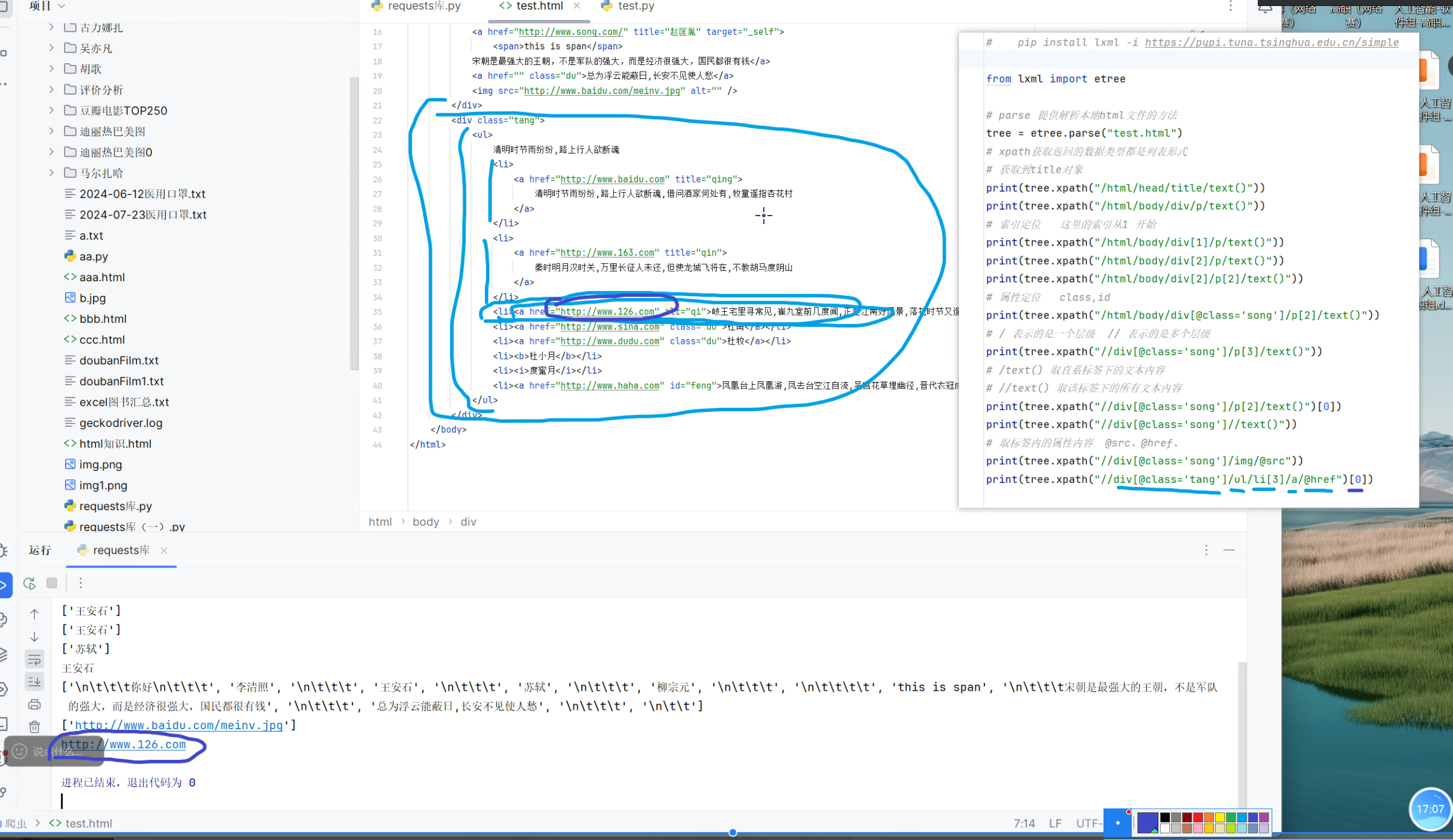
XPath 的核心是通过 “路径” 定位 HTML/XML 节点,其中最基础的两个符号就能覆盖大部分场景:
- /(单斜杠):表示 “当前节点的直接子节点”(严格的层级关系,只能往下走一层);
//(双斜杠):表示 “从当前节点开始,向下查找所有符合条件的节点”(忽略中间层级,直接穿透到目标节点)。
实例:
介于篇幅有限,为了更好的掌握知识点,读者应当自己多阅读多分析库的与那代码,多实践和验证源代码中给出的方法和函数。
爬虫有风险,读者切莫使用本博客所学知识爬取非法网络资源、侵害网络安全秩序,请读者务必遵守《中华人名共和国网络安全法》。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 50
50 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)