【LangChain4j 03】【Agents and Agentic AI】
根据Anthropic研究人员最近发表的一篇文章,这些智能体系统架构可分为两大类:工作流和纯智能体。
一、前言
本系列仅做个人笔记使用,绝大部分内容基于 LangChain4j 官网 ,内容个人做了一定修改,可能存在错漏,一切以官网为准。
本系列使用 LangChain4j 版本:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>1.8.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
本系列完整代码地址 :langchain4j-hwl
官网描述 :本节介绍如何使用langchain4j-agentic模块构建具有智能体特性的人工智能应用程序。请注意,整个模块仍处于试验阶段,未来版本可能会有变动。
根据Anthropic研究人员最近发表的一篇文章,这些智能体系统架构可分为两大类:工作流和纯智能体。
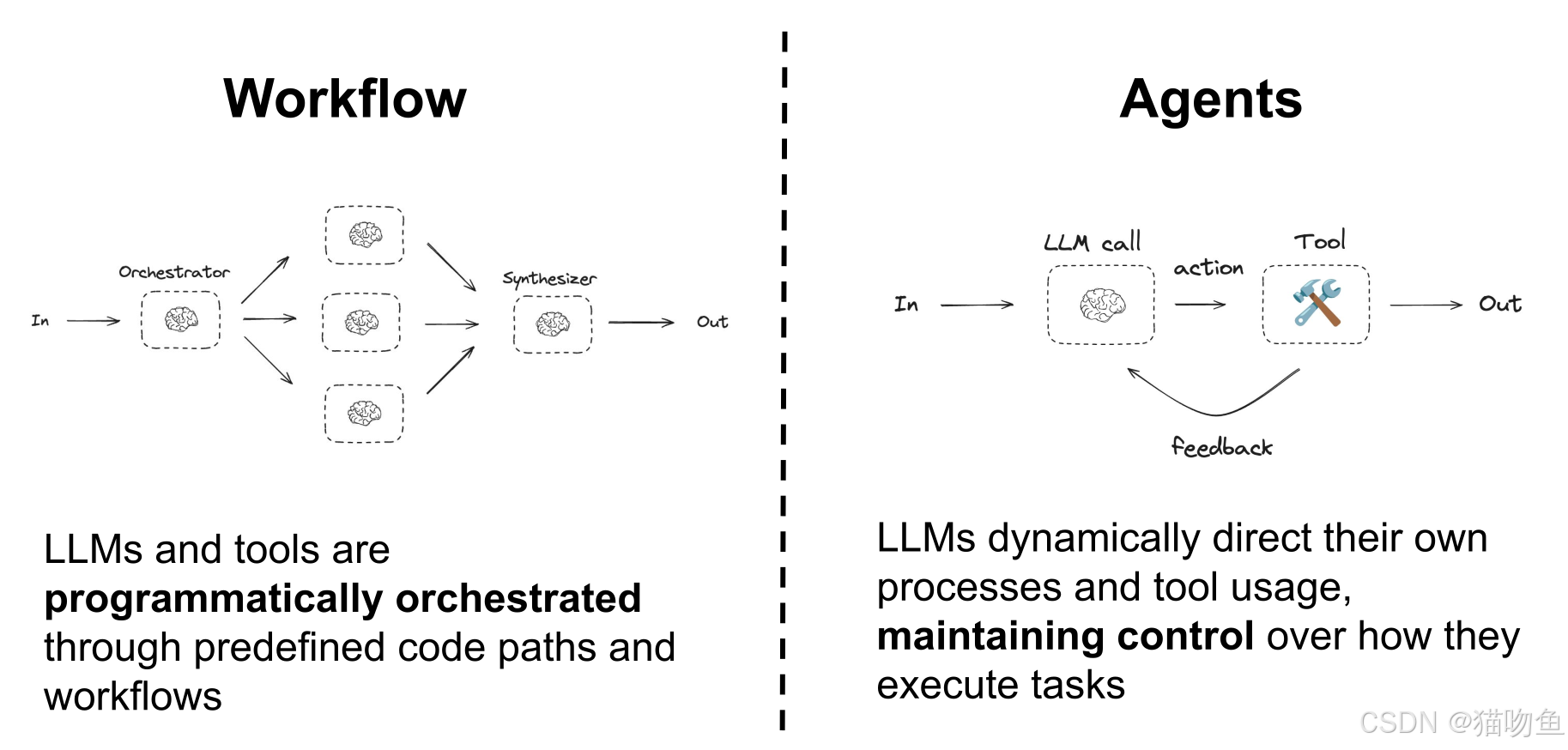
二、Agents
1. Agent
LangChain4j中的智能体使用大语言模型执行特定任务或一系列任务。可以通过一个具有单一方法的接口来定义智能体,这与普通的 AI Service 类似,只需在接口上添加 @Agent 注解即可。
官方建议 :在使用 @Agent 注解时,同时附上智能体用途的简短描述是一个很好的做法,尤其是当智能体打算用于纯智能体模式时,在这种模式下,其他智能体需要了解该智能体的能力,以便就如何以及何时使用它做出明智的决定。在构建智能体时,也可以通过智能体构建器的description方法以编程方式提供此描述。
智能体还必须有一个在智能体系统中唯一标识它们的名称。这个名称既可以在 @Agent 注解中指定,也可以通过智能体构建器的 name 方法以编程方式指定。如果未指定,该名称将取自带有 @Agent 注解的方法的名称。
创建一个 Agent 的简单示例如下:
-
在使用 Agent 功能前需要先引入
langchain4j-agentic依赖, 如下:<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-agentic</artifactId> </dependency> -
定义 Agent 接口,如下 :
public interface CreativeWriter { @UserMessage(""" 你是一名创意作家。 围绕给定主题生成一篇不超过3句话的故事草稿。 只返回故事,其他什么都不要。 主题是{{topic}}。 """) @Agent(name = "CreativeWriter", description = "基于给定话题生成一篇不超过3句话的故事草稿") String generateStory(@V("topic") String topic); } -
通过 AgenticServices#agentBuilder 创建智能体的实例:
CreativeWriter creativeWriter = AgenticServices .agentBuilder(CreativeWriter.class) .chatModel(myChatModel) .outputKey("story") .build();
本质上,Agent 就是 简单的 AI services,具备相同的功能,但能够与其他 Agent 结合,以创建更复杂的工作流和智能体系统。
2. AgenticScope
对于一个工作流和智能体系统来说,肯定需要记录调用过程的上下文信息,因此Agent 还有一个 outputKey 参数,该参数用于指定共享变量的名称,智能体调用的结果将存储在这个共享变量中,以便同一智能体系统中的其他智能体可以使用该结果。此外,输出名称也可以直接在 @Agent 注解中声明,而不是像本例中这样通过编程方式声明,这样就可以在代码中省略该名称,而在此处添加。如下:
@Agent(outputKey = "story", description = "Generates a story based on the given topic")
仅仅通过一个 outputKey 参数无法完全记录调用上下文,因此 langchain4j-agentic 模块引入了 AgenticScope 的概念,它是参与智能体系统的各智能体之间共享的数据集合。AgenticScope用于存储共享变量,智能体可以写入这些变量以传递其生成的结果,其他智能体则可以读取这些变量来整合执行自身任务所需的信息。这使得智能体能够高效协作,根据需要共享信息和结果。
AgenticScope 还会自动记录其他相关信息,例如所有智能体的调用顺序及其响应。它会在智能体系统的主智能体被调用时自动创建,并在必要时通过回调以编程方式提供。在下文会展示 AgenticScope 的使用场景。
三、Workflow
langchain4j-agentic 模块提供了一组抽象概念,用于以编程方式编排多个智能体并创建智能体工作流模式。这些模式可以组合起来,以创建更复杂的工作流。
类似 Dify、Coze 的工作流
1. 顺序工作流
顺序工作流(Sequential workflow )是最简单的模式,其中多个智能体依次被调用,每个智能体的输出作为输入传递给下一个智能体。当你有一系列需要按特定顺序执行的任务时,这种模式非常有用。
简单示例如下:
-
编写三个对应的 Agent
public interface CreativeWriter { @UserMessage(""" 你是一名创意作家。 围绕给定主题生成一篇不超过3句话的故事草稿。 只返回故事,其他什么都不要。 主题是{{topic}}。 """) @Agent(name = "CreativeWriter", description = "基于给定话题生成一篇不超过3句话的故事草稿", outputKey = "story") String generateStory(@V("topic") String topic); } public interface AudienceEditor { @UserMessage(""" 你是一名专业编辑。 分析并改写以下故事,使其更贴合{{audience}}这一目标受众。 仅返回故事本身,不要其他内容。 故事内容为“{{story}}”。". """) @Agent(name = "AudienceEditor", description = "修改一个故事,使其更适合特定的受众") String editStory(@V("story") String story, @V("audience") String audience); } public interface StyleEditor { @UserMessage(""" 你是一名专业编辑。 分析并改写以下故事,使其更符合 {{style}} 风格,且连贯性更强。 只返回故事,不要其他内容。 故事内容为 {{story}} """) @Agent(name = "StyleEditor", description = "编辑故事以使其更符合给定的风格") String editStory(@V("story") String story, @V("style") String style); } -
Config 中注入属性 :
storyAgent是 创建一个结合这三个智能体的顺序工作流,其中 CreativeWriter 的输出会作为输入传递给 AudienceEditor 和 StyleEditor ,而最终输出则是经过编辑的故事。@Bean public CreativeWriter creativeWriter(OpenAiChatModel openAiChatModel) { return AgenticServices .agentBuilder(CreativeWriter.class) // 打印输出内容 .afterAgentInvocation(agentResponse -> log.info("afterAgentInvocation: {}", agentResponse)) .chatModel(openAiChatModel) .outputKey("story") .build(); } @Bean public AudienceEditor audienceEditor(OpenAiChatModel openAiChatModel) { return AgenticServices .agentBuilder(AudienceEditor.class) .afterAgentInvocation(agentResponse -> log.info("afterAgentInvocation: {}", agentResponse)) .chatModel(openAiChatModel) .outputKey("story") .build(); } @Bean public StyleEditor styleEditor(OpenAiChatModel openAiChatModel) { return AgenticServices .agentBuilder(StyleEditor.class) .afterAgentInvocation(agentResponse -> log.info("afterAgentInvocation: {}", agentResponse)) .chatModel(openAiChatModel) .outputKey("story") .build(); } @Bean("storyAgent") public UntypedAgent untypedAgent(CreativeWriter creativeWriter, AudienceEditor audienceEditor, StyleEditor styleEditor) { return AgenticServices .sequenceBuilder() .subAgents(creativeWriter, audienceEditor, styleEditor) .outputKey("story") .build(); } -
实际发起调用
@Override
public String generateCompletedStory(String topic, String style, String audience) {
Map<String, Object> input = Map.of(
"topic", topic,
"style", style,
"audience", audience
);
return (String) storyAgent.invoke(input);
}
当我们发起调用时,完整执行链路为:
- 用户输入参数(topic=地球是圆的、audience=青少年、style=奇幻)存入
AgenticScope; - 调用
CreativeWriter:读取“topic”生成故事,输出存入“story”; - 调用
AudienceEditor:读取“story”和“audience”,修改后覆盖“story”; - 调用
StyleEditor:读取“story”和“style”,修改后再次覆盖“story”; novelCreator返回“story”变量的最终值,即编辑完成的故事。
基于上面的内容,我们来说明几点内容:
- AgenticScope 共享变量 :作为智能体间的 “数据中转站”,存储输入参数和各智能体的输出。
- 用户输入(如代码中
Map.of传入的topic,audience,style)会自动存入AgenticScope; - 前序智能体的输出通过
outputKey指定变量名存入,供后续智能体读取。如 CreativeWriter 生成的内容会以 story 的名称存入 AgenticScope 中,后序 Agent 获取到的 name = story 的值就是 CreativeWriter 生成的 结果,然后对其重写后再覆盖。
- 用户输入(如代码中
- 非类型化调用(UntypedAgent) :
storyAgent智能体实际上是一个智能体系统,它实现了一个顺序工作流,将三个子智能体依次调用。我们这里创建的storyAgent没有提供类型化接口,因此序列智能体构建器返回一个dev.langchain4j.agentic.UntypedAgent 实例,这是一个可以通过输入映射调用的通用智能体。
1.1 类型化调用
工作流智能体也可以配备类型化接口完成类型化调用,即使用指定的 Agent 接口以及入参形式,这样就可以使用强类型的输入和输出来调用它。 在这种情况下,UntypedAgent 接口可以替换为更具体的接口,例如:
public interface NovelCreator {
@Agent
String createNovel(@V("topic") String topic, @V("audience") String audience, @V("style") String style);
}
以便可以按如下方式创建和使用 novelCreator 智能体:
NovelCreator novelCreator = AgenticServices
.sequenceBuilder(NovelCreator.class)
.subAgents(creativeWriter, audienceEditor, styleEditor)
.outputKey("story")
.build();
String story = novelCreator.createNovel("dragons and wizards", "young adults", "fantasy");
2. 循环工作流
循环工作流(Loop workflow)即通过循环方式调用智能体,直到满足特定条件为止。
简单示例如下:
-
创建一个 StyleScorer 智能体可用于根据风格与要求的匹配程度生成分数。
public interface StyleScorer { @UserMessage(""" 你是一名评论家。 请根据以下故事与“{{style}}”风格的契合程度,为其给出0.0到1.0之间的评分。 只返回分数,不要其他内容。 故事内容为:“{{story}}” """) @Agent("根据故事与给定风格的匹配程度为其打分") double scoreStyle(@V("story") String story, @V("style") String style); } -
将这个 StyleScorer 智能体与 StyleEditor 一起置于循环中,以迭代方式改进故事,直到分数达到某个阈值(比如0.8),或者达到最大迭代次数为止。
@Bean("styleReviewLoopAgent") public UntypedAgent untypedAgent(StyleScorer styleScorer, StyleEditor styleEditor) { return AgenticServices .loopBuilder() .subAgents(styleScorer, styleEditor) .maxIterations(5) // 设置仅在循环结束时检查退出条件,从而强制在测试该条件之前调用所有智能体 .testExitAtLoopEnd(true) .exitCondition((agenticScope, loopCounter) -> { // 如果循环次数小于等于3,评分大于等于0.8则退出 // 如果循环次数大于3,评分大于等于0.6则退出 double score = agenticScope.readState("score", 0.0); return loopCounter <= 3 ? score >= 0.8 : score >= 0.6; }) .build(); }这里
styleReviewLoopAgent的逻辑是 :首先调用styleScorer对当前故事和风格匹配度进行打分,如果在前3次循环中分数至少为0.8,将使循环退出;否则,将降低质量预期,以至少0.6的分数终止循环。而testExitAtLoopEnd设置保证了即使在满足退出条件后,也会强制最后调用一次styleEditor智能体。上面几个参数的作用如下:
maxIterations:最大循环次数exitCondition:退出条件判断,满足条件则会退出循环。testExitAtLoopEnd:默认情况下 exitCondition 会在每调用一个子智能体后就会检查该条件。一旦条件满足,循环立即退出,目的是尽可能减少智能体调用次数,避免不必要的执行。若需调整为仅在一轮循环(所有子智能体都调用完)结束后检查退出条件(即强制执行完本轮所有子智能体再判断是否退出),可将该参数设置为 true。
-
配置好这个 styleReviewLoop 后,它可以被视为一个单独的智能体,并与 CreativeWriter 智能体按顺序组合,从而创建一个StyledWriter 智能体。如下:
@Bean("storyAgent") public UntypedAgent untypedAgent(CreativeWriter creativeWriter, AudienceEditor audienceEditor, @Qualifier("styleReviewLoopAgent") UntypedAgent styleReviewLoopAgent) { return AgenticServices .sequenceBuilder() .subAgents(creativeWriter, audienceEditor, styleReviewLoopAgent) .outputKey("story") .build(); }
3. 并行工作流
并行工作流 (Parallel workflow) 可以实现并行调用多个智能体,它们的输出被合并为一个单一结果。
简单示例如下:
-
基础 Agent
public interface FoodExpert { @UserMessage(""" 你是一位出色的晚间策划师。 请根据给定的氛围提出3份餐食清单。 氛围是{{mood}}。 对于每份餐食,只需给出餐食的名称。 提供包含3个项目的清单,除此之外不要有其他内容。 """) @Agent List<String> findMeal(@V("mood") String mood); } public interface MovieExpert { @UserMessage(""" 你是一位出色的晚间规划师。 根据给定的情绪,推荐3部匹配的电影。 情绪是{{mood}}。 只需提供包含这3部电影的列表,其他内容无需提供。 """) @Agent List<String> findMovie(@V("mood") String mood); } -
注入容器
@Bean public EveningPlannerAgent eveningPlannerAgent(FoodExpert foodExpert, MovieExpert movieExpert) { return AgenticServices .parallelBuilder(EveningPlannerAgent.class) .subAgents(foodExpert, movieExpert) // 并行执行,最多2个线程 .executor(Executors.newFixedThreadPool(2)) .outputKey("plans") .output(agenticScope -> { // 处理输出结果 List<String> movies = agenticScope.readState("movies", List.of()); List<String> meals = agenticScope.readState("meals", List.of()); List<EveningPlannerAgent.EveningPlan> moviesAndMeals = new ArrayList<>(); for (int i = 0; i < movies.size(); i++) { if (i >= meals.size()) { break; } moviesAndMeals.add(new EveningPlannerAgent.EveningPlan(movies.get(i), meals.get(i))); } return moviesAndMeals; }) .build(); } -
直接调用
@Override public List<EveningPlannerAgent.EveningPlan> planEvening(String mood) { return eveningPlannerAgent.plan(mood); }
4. 条件工作流
条件工作流(Conditional workflow )是特定条件满足时调用某个智能体。例如,在处理用户请求之前对其进行分类可能会很有用,这样就可以根据请求的类别由不同的智能体来进行处理。这可以通过使用以下 CategoryRouter 来实现。
简单示例如下:
-
构建需要的 Agent
public interface CategoryRouter { @UserMessage(""" 分析以下用户请求,并将其归类为“法律的”“医疗的”或“技术的”。如果该请求不属于上述任何类别,则将其归类为“未知的”。仅用其中一个词回复,不要添加其他内容。用户请求为:“{{request}}”. """) @Agent("对用户请求进行分类") RequestCategory classify(@V("request") String request); enum RequestCategory { LEGAL, MEDICAL, TECHNICAL, UNKNOWN } } public interface MedicalExpert { @UserMessage(""" 你是一名医学专家。 请从医学角度分析以下用户请求,并提供尽可能好的答案。 用户请求是{{request}}。 """) @Agent("一名医学专家") String medical(@V("request") String request); } public interface LegalExpert { @UserMessage(""" 你是一名法律专家。 请从法律角度分析以下用户请求,并提供尽可能好的答案。 用户请求是{{request}}。 """) @Agent("一名法律专家") String legal(@V("request") String request); } public interface TechnicalExpert { @UserMessage(""" 你是一名技术专家。 请从技术角度分析以下用户请求,并提供尽可能好的答案。 用户请求是{{request}}。 """) @Agent("一名技术专家") String technical(@V("request") String request); } -
容器注入ExpertRouterAgent
@Bean public ExpertRouterAgent expertRouterAgent(CategoryRouter categoryRouter, MedicalExpert medicalExpert, LegalExpert legalExpert, TechnicalExpert technicalExpert) { // 构建一个条件工作流 : 根据分类路由到不同的专家 UntypedAgent expertsAgent = AgenticServices.conditionalBuilder() .subAgents(agenticScope -> agenticScope.readState("category", CategoryRouter.RequestCategory.UNKNOWN) == CategoryRouter.RequestCategory.MEDICAL, medicalExpert) .subAgents(agenticScope -> agenticScope.readState("category", CategoryRouter.RequestCategory.UNKNOWN) == CategoryRouter.RequestCategory.LEGAL, legalExpert) .subAgents(agenticScope -> agenticScope.readState("category", CategoryRouter.RequestCategory.UNKNOWN) == CategoryRouter.RequestCategory.TECHNICAL, technicalExpert) .build(); // 构建一个顺序工作流 : 先通过 categoryRouter 对问题进行分类分类,再路由到不同的专家 Agent 进行处理 return AgenticServices .sequenceBuilder(ExpertRouterAgent.class) .subAgents(categoryRouter, expertsAgent) .outputKey("response") .build(); } -
调用
@Override public String askExpert(String request) { return expertRouterAgent.ask(request); }
除了上面编码形式指定工作流外,我们也可以通过 @SequenceAgent、@LoopAgent、@ParallelAgent、@ConditionalAgent注解形式创建工作流。
五、Agent的其他特性
1. 异步 Agent
LangChain4j 中,智能体系统默认采用 同步调用 逻辑:
- 所有智能体调用共享“根智能体”的线程,必须等前一个智能体执行完,才能开始下一个;
- 适合任务有强依赖(如“先生成故事,再编辑故事”)的场景,但对 无依赖的独立任务 会造成效率浪费(比如“找电影”和“找餐食”本可同时进行,却要排队执行)。
为解决同步的效率问题,LangChain4j 提供 async(true) 配置,核心作用是:
- 将指定智能体的调用分配到 独立线程 执行,不阻塞整个智能体系统的流程;
- 异步智能体的结果会实时存入
AgenticScope(共享数据容器),仅当后续其他智能体 必须依赖该结果 时,AgenticScope才会短暂阻塞等待,避免不必要的停滞。
简单示例如下:
FoodExpert foodExpert = AgenticServices
.agentBuilder(FoodExpert.class)
.chatModel(BASE_MODEL)
// 标记为异步执行
.async(true)
.outputKey("meals")
.build();
MovieExpert movieExpert = AgenticServices
.agentBuilder(MovieExpert.class)
.chatModel(BASE_MODEL)
// 标记为异步执行
.async(true)
.outputKey("movies")
.build();
EveningPlannerAgent eveningPlannerAgent = AgenticServices
// 即使在顺序工作流的场景下 FoodExpert 和 MovieExpert 也会并行执行
.sequenceBuilder(EveningPlannerAgent.class)
.subAgents(foodExpert, movieExpert)
.executor(Executors.newFixedThreadPool(2))
.outputKey("plans")
.output(agenticScope -> {
List<String> movies = agenticScope.readState("movies", List.of());
List<String> meals = agenticScope.readState("meals", List.of());
List<EveningPlan> moviesAndMeals = new ArrayList<>();
for (int i = 0; i < movies.size(); i++) {
if (i >= meals.size()) {
break;
}
moviesAndMeals.add(new EveningPlan(movies.get(i), meals.get(i)));
}
return moviesAndMeals;
})
.build();
List<EveningPlan> plans = eveningPlannerAgent.plan("romantic");
2. 异常处理
在一个复杂的智能体系统中,可能会出现很多问题,例如智能体无法生成结果、外部工具不可用,或者智能体执行过程中发生意外错误。
LangChain4j 通过 errorHandler 方法为系统注入「错误处理器」,该处理器接收 ErrorContext(错误上下文),并返回 ErrorRecoveryResult(错误恢复结果),支持三种核心恢复策略:
| 恢复策略 | 行为说明 | 适用场景 |
|---|---|---|
throwException() |
默认行为,直接将错误向上传播到根调用方,终止流程 | 错误无法恢复(如核心工具彻底不可用),需明确报错 |
retry() |
重试当前智能体调用(可先执行纠正操作) | 错误可修复(如参数缺失、临时网络波动) |
result(Object result) |
忽略错误,用自定义结果替代失败智能体的输出 | 错误不影响核心流程(如非关键信息缺失,用默认值填充) |
其中,ErrorContext 是关键上下文载体,包含三个核心信息:
agentName:出错智能体的名称;agenticScope:智能体共享数据域(可读写共享变量,用于修复参数等);exception:具体的异常对象(如MissingArgumentException)。
简单示例如下:
UntypedAgent novelCreator = AgenticServices.sequenceBuilder()
.subAgents(creativeWriter, audienceEditor, styleEditor)
// 处理错误信息
.errorHandler(errorContext -> {
if (errorContext.agentName().equals("generateStory") &&
errorContext.exception() instanceof MissingArgumentException mEx && mEx.argumentName().equals("topic")) {
errorContext.agenticScope().writeState("topic", "dragons and wizards");
errorRecoveryCalled.set(true);
return ErrorRecoveryResult.retry();
}
return ErrorRecoveryResult.throwException();
})
.outputKey("story")
.build();
3. 可观测性
Agent 提供两个监听方法,实现调用过程的追踪:
beforeAgentInvocation:在智能体被调用前触发,可捕获调用前的关键信息;afterAgentInvocation:在智能体完成任务、返回结果后触发,可捕获调用后的输出信息。
简单示例如下:
CreativeWriter creativeWriter = AgenticServices.agentBuilder(CreativeWriter.class)
.chatModel(baseModel())
.outputKey("story")
// 打印调用前日志
.beforeAgentInvocation(request ->
System.out.println("Invoking CreativeWriter with topic: " + request.inputs().get("topic")))
// 打印调用后日志
.afterAgentInvocation(response ->
System.out.println("CreativeWriter generated this story: " + response.output()))
.build();
六、声明式API
传统实现工作流(如并行调用 FoodExpert 和 MovieExpert)需要写大量代码(如 parallelBuilder()、配置线程池、定义结果合并逻辑);而声明式 API 通过 在接口中嵌入注解,直接「声明」工作流的结构、依赖和规则,框架自动解析执行,无需手动编写流程控制代码。
1. 基础示例
以 EveningPlannerAgent 并行工作流为例,核心注解和功能一一对应,实现「定义即逻辑」:
| 核心注解/组件 | 作用 | 示例对应场景 |
|---|---|---|
@ParallelAgent |
声明当前接口方法是「并行工作流」,指定输出键(outputKey)和子智能体(subAgents) |
标注 plan() 方法,明确并行调用 FoodExpert 和 MovieExpert,结果存到 plans 中 |
@SubAgent |
在工作流中声明「子智能体」,指定子智能体类型和其输出存储键 | 定义 FoodExpert 输出存 meals、MovieExpert 输出存 movies |
@ParallelExecutor |
为并行工作流指定线程池(若不指定则用默认线程池) | 静态方法 executor() 返回固定 2 线程的线程池,供并行调用子智能体使用 |
@Output |
定义「子智能体输出的合并逻辑」,替代编程式中的 output() 函数 |
静态方法 createPlans() 将 movies 和 meals 按索引配对,生成 EveningPlan 列表 |
@ChatModelSupplier |
为特定子智能体「单独指定大模型」(覆盖全局默认模型) | FoodExpert 通过该注解绑定专属的 FOOD_MODEL,而非用系统默认的 BASE_MODEL |
简单示例如下:
-
声明式定义 Agent
public interface EveningPlannerAgentByApi { @ParallelAgent(outputKey = "plans", subAgents = { @SubAgent(type = MovieExpert.class, outputKey = "meals"), @SubAgent(type = FoodExpert.class, outputKey = "movies") }) List<EveningPlannerAgent.EveningPlan> plan(@V("mood") String mood); @ParallelExecutor static Executor executor() { return Executors.newFixedThreadPool(2); } @Output static List<EveningPlannerAgent.EveningPlan> createPlans( @V("movies") List<String> movies, @V("meals") List<String> meals) { List<EveningPlannerAgent.EveningPlan> moviesAndMeals = new ArrayList<>(); for (int i = 0; i < movies.size(); i++) { if (i >= meals.size()) { break; } moviesAndMeals.add(new EveningPlannerAgent.EveningPlan(movies.get(i), meals.get(i))); } return moviesAndMeals; } }在这种情况下,用
@Output标注的静态方法用于定义如何将子智能体的输出组合成一个单一结果,其方式与将AgenticScope的函数传递给 output 方法时所采用的方式完全相同。 -
注入到容器中 :可以使用
AgenticServices#createAgenticSystem方法创建EveningPlannerAgent的实例,然后完全像以前一样使用它。@Bean public EveningPlannerAgentByApi eveningPlannerAgentByApi(OpenAiChatModel chatModel) { // 这里使用 createAgenticSystem 来创建 return AgenticServices .createAgenticSystem(EveningPlannerAgentByApi.class, chatModel); }
2. 声明式注解
在上面的情况下,AgenticServices#createAgenticSystem 方法还会被提供一个ChatModel,该模型默认用于创建此智能体系统中的所有子智能体。不过,也可以为特定子智能体选择性地指定不同的ChatModel,具体方式是在其定义中添加一个带有@ChatModelSupplier 注解的静态方法,该方法返回将用于该智能体的ChatModel。例如,FoodExpert Agent 可以按如下方式定义自己的ChatModel:
public interface FoodExpert {
@UserMessage("""
你是一位出色的晚间策划师。
请根据给定的氛围提出3份餐食清单。
氛围是{{mood}}。
对于每份餐食,只需给出餐食的名称。
提供包含3个项目的清单,除此之外不要有其他内容。
""")
@Agent
List<String> findMeal(@V("mood") String mood);
/**
* 提供用于执行Agent的ChatModel
* @return
*/
@ChatModelSupplier
static ChatModel chatModel() {
return SpringUtil.getBean(OpenAiChatModel.class);
}
}
与之类似的,在智能体接口中对其他 static 方法进行注解,可以声明式地配置智能体的其他方面,例如其聊天记忆、它可以使用的工具等等。这些方法必须没有参数,除非下表中另有规定。用于此目的的注解列表如下:
| 注解 | 描述 |
|---|---|
| @ChatModelSupplier | 返回此智能体将要使用的ChatModel。 |
| @ChatMemorySupplier | 返回此智能体将要使用的ChatMemory。 |
| @ChatMemoryProviderSupplier | 返回此智能体将要使用的ChatMemoryProvider。 |
| @ContentRetrieverSupplier | 返回此智能体将使用的ContentRetriever |
| @BeforeAgentInvocation | 在执行智能体调用前立即通知。 |
| @AfterAgentInvocation | 当智能体调用完成时收到通知。 |
| @RetrievalAugmentorSupplier | 返回此智能体将使用的RetrievalAugmentor。 |
| @ToolsSupplier | 返回此智能体将使用的工具或工具集。 |
| @ToolProviderSupplier | 返回此智能体将使用的ToolProvider。 |
通过上述内容,这里可以给出重新定义在条件工作流部分展示的ExpertsAgent 示例:
public interface ExpertsAgent {
@ConditionalAgent(outputKey = "response", subAgents = {
@SubAgent(type = MedicalExpert.class, outputKey = "response"),
@SubAgent(type = TechnicalExpert.class, outputKey = "response"),
@SubAgent(type = LegalExpert.class, outputKey = "response")
})
String askExpert(@V("request") String request);
@ActivationCondition(MedicalExpert.class)
static boolean activateMedical(@V("category") RequestCategory category) {
return category == RequestCategory.MEDICAL;
}
@ActivationCondition(TechnicalExpert.class)
static boolean activateTechnical(@V("category") RequestCategory category) {
return category == RequestCategory.TECHNICAL;
}
@ActivationCondition(LegalExpert.class)
static boolean activateLegal(@V("category") RequestCategory category) {
return category == RequestCategory.LEGAL;
}
}
在这种情况下,@ActivationCondition注解的值指向的是当用它注解的方法返回true时被激活的智能体类集合。
八、Agent 的 记忆上下文
在 【LangChain4j 01】【基本使用】 中我们提到过 Chat memory 可以赋予 单个智能体 记忆功能,但这种方式 对于 参与智能体系统的智能体而言可能存在局限性。
以上面 条件工作流场景下:如果第一次对话对话是律师(LegalExpert),第二次对话是医生(MedicalExpert) ,则第二次与医生专家的对话时无法携带第一次与律师对话的记忆。
针对这种情况,我们可以通过 AgenticScope实现多智能体上下文共享。
1. AgenticScope 上下文
AgenticScope 作为多智能体系统的“共享数据池”,自动记录所有智能体的调用序列和交互内容,并能生成一个将这些调用串联成单一对话的上下文。
AgenticScope 中记录的上下文信息可以直接使用,但必要时也可以总结为更简短的版本,这种情况方式我们可以通过定义一个ContextSummarizer 智能体来对上下文内容进行总结,如下是 dev.langchain4j.agentic.internal.Context.ContextSummarizer 的定义:
public interface ContextSummarizer {
@UserMessage("""
Create a short summary of the following conversation between one or more AI agents and a user.
Mention all the agents involved in the conversation.
Do not provide any additional information, just the summary.
The user conversation is: '{{it}}'.
""")
Summary summarize(String conversation);
}
通过使用该智能体,法律专家的角色可以被重新定义,并且能获得之前对话的语境总结,这样在回答新问题时,它就能考虑到之前的互动内容。
LegalExpertWithMemory legalExpert = AgenticServices
.agentBuilder(LegalExpertWithMemory.class)
.chatModel(BASE_MODEL)
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.withMaxMessages(10))
// TODO : 可以对 agent 进一步过滤,只关心其中部分 agent 的上下文
.context(agenticScope -> contextSummarizer.summarize(agenticScope.contextAsConversation()))
.outputKey("response")
.build();
AgenticServices 在定义 Agent 时提供了更为方便的方法(AgenticServices#summarizedContext)。构建智能体时直接调用 summarizedContext方法,可指定 “仅汇总特定智能体的上下文”(如summarizedContext("medical")表示只汇总医学专家的交互记录,忽略其他无关智能体),框架会自动复用默认的摘要逻辑,减少代码量。
简单示例如下:
-
定义基础的 Agent
public interface ExpertRouterAgentWithMemory { @Agent String ask(@MemoryId String memoryId, @V("request") String request); } public interface LegalExpertWithMemory { @UserMessage(""" 你是一名法律专家。 请从法律角度分析以下用户请求,并提供尽可能好的答案。 用户请求是{{request}}。 """) @Agent("一名法律专家") String legal(@MemoryId String memoryId, @V("request") String request); } public interface MedicalExpertWithMemory { @UserMessage(""" 你是一名医学专家。 请从医学角度分析以下用户请求,并提供尽可能好的答案。 用户请求是{{request}}。 """) @Agent("一名医学专家") String medical(@MemoryId String memoryId, @V("request") String request); } public interface TechnicalExpertWithMemory { @UserMessage(""" 你是一名技术专家。 请从技术角度分析以下用户请求,并提供尽可能好的答案。 用户请求是{{request}}。 """) @Agent("一名技术专家") String technical(@MemoryId String memoryId, @V("request") String request); } -
配置工作流
@Bean
public CategoryRouterWithMemory categoryRouterWithMemory(ChatMemoryProvider chatMemoryProvider, @Qualifier("aliQwenModel") ChatModel chatModel) {
return AgenticServices
.agentBuilder(CategoryRouterWithMemory.class)
.afterAgentInvocation(this::log)
.chatModel(chatModel)
.chatMemoryProvider(chatMemoryProvider)
.outputKey("category")
.build();
}
@Bean
public LegalExpertWithMemory legalExpertWithMemory(ChatMemoryProvider chatMemoryProvider, @Qualifier("aliQwenModel") ChatModel chatModel) {
return AgenticServices
.agentBuilder(LegalExpertWithMemory.class)
.afterAgentInvocation(this::log)
.chatModel(chatModel)
.chatMemoryProvider(chatMemoryProvider)
.summarizedContext("medical", "technical")
.outputKey("response")
.build();
}
@Bean
public TechnicalExpertWithMemory technicalExpertWithMemory(ChatMemoryProvider chatMemoryProvider, @Qualifier("aliQwenModel") ChatModel chatModel) {
return AgenticServices
.agentBuilder(TechnicalExpertWithMemory.class)
.afterAgentInvocation(this::log)
.chatModel(chatModel)
.chatMemoryProvider(chatMemoryProvider)
.summarizedContext("medical", "legal")
.outputKey("response")
.build();
}
@Bean
public MedicalExpertWithMemory medicalExpertWithMemory(ChatMemoryProvider chatMemoryProvider, @Qualifier("aliQwenModel") ChatModel chatModel) {
return AgenticServices
.agentBuilder(MedicalExpertWithMemory.class)
.afterAgentInvocation(this::log)
.chatModel(chatModel)
.chatMemoryProvider(chatMemoryProvider)
.summarizedContext("technical", "legal")
.outputKey("response")
.build();
}
@Bean("expertRouterAgentWithMemory")
public ExpertRouterAgentWithMemory expertRouterAgentWithMemory(CategoryRouterWithMemory categoryRouter, MedicalExpertWithMemory medicalExpert,
LegalExpertWithMemory legalExpert, TechnicalExpertWithMemory technicalExpert) {
// 构建一个条件工作流 : 根据分类路由到不同的专家
UntypedAgent expertsAgent = AgenticServices.conditionalBuilder()
.subAgents(agenticScope -> agenticScope.readState("category",
CategoryRouter.RequestCategory.UNKNOWN) == CategoryRouter.RequestCategory.MEDICAL, medicalExpert)
.subAgents(agenticScope -> agenticScope.readState("category",
CategoryRouter.RequestCategory.UNKNOWN) == CategoryRouter.RequestCategory.LEGAL, legalExpert)
.subAgents(agenticScope -> agenticScope.readState("category",
CategoryRouter.RequestCategory.UNKNOWN) == CategoryRouter.RequestCategory.TECHNICAL, technicalExpert)
.build();
// 构建一个顺序工作流 : 先通过 categoryRouter 对问题进行分类分类,再路由到不同的专家 Agent 进行处理
return AgenticServices
.sequenceBuilder(ExpertRouterAgentWithMemory.class)
.subAgents(categoryRouter, expertsAgent)
.outputKey("response")
.build();
}
在上面对 LegalExpertWithMemory、TechnicalExpertWithMemory、MedicalExpertWithMemory 的注入时,除了通过 chatMemoryProvider(chatMemoryProvider) 指定了消息持久化的方式,还通过 summarizedContext("technical", "legal") 总结了上下文内容发送给 大模型。summarizedContext("technical", "legal") 的入参是关联 Agent 的名称。
2. AgenticScope 的持久化
AgenticScope是智能体系统执行期间的临时数据容器,核心作用是存储智能体间共享的变量(如前序智能体的输出、用户输入参数等),支撑多智能体协作(比如顺序工作流中传递任务结果)。
AgenticScope 严格遵循“每个用户-每个智能体系统”的隔离规则——即同一用户在不同智能体系统中拥有独立的AgenticScope,不同用户即使使用同一系统,其数据也不会互通,保障数据独立性。
AgenticScope 的存活逻辑完全取决于智能体系统是否使用ChatMemory(内存) ,分为两种场景:
| 场景 | 生命周期管理方式 |
|---|---|
| 无状态执行(无ChatMemory) | 执行结束后自动丢弃,状态不持久化(适合一次性任务,如单次故事生成、临时查询)。 |
| 有状态执行(有ChatMemory) | 执行后存入内部注册表并永久保留,支撑用户与系统的“对话式交互”(如多轮医疗咨询);若需删除,需通过根智能体实现AgenticScopeAccess接口,调用evictAgenticScope(memoryId)显式清除。 |
由于默认情况下,AgenticScope及其注册表均为纯内存结构(ChatMemory 结构,默认是内存存储),若需更可靠的存储(如避免服务重启后数据丢失),可通过两种方式接入自定义持久层:
- 编程式配置:直接调用
AgenticScopePersister.setStore(new MyAgenticScopeStore()),其中MyAgenticScopeStore是开发者实现AgenticScopeStore接口的自定义类(可对接数据库、文件系统等)。 - SPI接口配置:通过Java标准服务提供者机制,在项目中创建
META-INF/services/dev.langchain4j.agentic.scope.AgenticScopeStore文件,文件内写入AgenticScopeStore实现类的全限定名(如com.example.MyAgenticScopeStore),框架会自动加载该持久层。
不太好持久化 DefaultAgenticScope 类,无法序列化其中属性
九、Pure agentic AI
上面提到的智能体系统(如顺序、循环、并行、条件工作流),本质是 “确定性” 的:开发者需提前通过代码 “硬编码” 智能体的组合逻辑(比如 “先调用创意写作智能体,再调用受众编辑智能体”“满足分数≥0.8 则退出循环”),智能体自身无法自主决策下一步动作,所有流程都是固定的 “有线连接” 模式。
这种模式的问题在于灵活性不足—— 当任务场景复杂、上下文多变(比如用户需求模糊、中间结果超出预期)时,固定流程无法适配,需开发者反复调整工作流逻辑。
“纯智能体人工智能” 是为解决上述局限性而生,核心特点是 “智能体自主决策”:不再依赖开发者预设的固定流程,而是允许智能体根据当前上下文(如用户输入、前序智能体的输出结果)动态判断 “下一步该调用哪个子智能体”“是否已完成任务无需继续”,让系统具备自适应复杂场景的能力。
为实现 “纯智能体 AI”,LangChain4j 提供了监督智能体(Supervisor Agent) 这一核心组件,SupervisorAgent(监督者代理) 是一类承担“协调、决策与监控”核心职责的高阶代理,本质是管理其他子代理(如执行具体任务的 Worker Agent)的“代理管理者”,而非直接执行底层任务。其核心作用可简要解析为以下3点:
-
任务分配与路由
它会根据任务目标或输入信息,判断“该调用哪些子代理”。例如面对复杂需求(如“分析市场数据并生成可视化报告”),SupervisorAgent 会拆解任务为“数据爬取→数据清洗→分析→可视化”,并将各子任务分配给对应专业子代理(如 DataCrawlAgent、DataCleanAgent 等),避免单一代理能力不足的问题。 -
执行监控与纠错
它会跟踪子代理的执行过程:若某子代理执行失败(如数据爬取超时)、输出不符合预期(如分析结果逻辑错误),SupervisorAgent 会触发纠错机制——可能是重新调用该子代理、切换备用子代理,或通过 ErrorHandler 补充必要参数(类似 LangChain4j 中 ErrorRecoveryResult 的重试/结果修正逻辑),确保整体任务不中断。 -
结果聚合与决策闭环
当所有子代理完成任务后,SupervisorAgent 会整合各子结果(如将“分析结论”与“可视化图表”合并为完整报告),并判断是否满足最终目标:若未满足(如报告缺少关键维度),则重新发起子任务流程;若满足,则输出最终结果,形成“任务拆解→分配→监控→聚合”的闭环。
简言之,SupervisorAgent 是 LangChain4j 复杂代理系统的“大脑”,通过统筹子代理协作,让分散的代理能力形成合力,适配更复杂的任务场景(如多步骤业务流程、跨领域需求处理)。
简单示例如下:该功能的作用是可以通过 SupervisorAgent 完成从银行账户中贷记或取款,或者将给定的金额从一种货币兑换成另一种货币。
-
创建各个功能 Agent
public interface WithdrawAgent { @SystemMessage(""" 你是一名银行工作人员,只能从用户账户中提取美元(USD)。 """) @UserMessage(""" 从{{user}}的账户中提取{{amount}}美元,并返回新的余额。 """) @Agent("从账户中提取美元的银行工作人员") String withdraw(@V("user") String user, @V("amount") Double amount); } public interface CreditAgent { @SystemMessage(""" 你是一名银行工作人员,只能只能向用户账户中存入美元(USD)。 """) @UserMessage(""" 向{{user}}的账户中存入{{amount}}美元,并返回新的余额。 """) @Agent("向账户中存入美元的银行工作人员") String credit(@V("user") String user, @V("amount") Double amount); } public interface BalanceAgent { @SystemMessage(""" 你是一名银行工作人员,查询指定用户的余额。 """) @UserMessage(""" 查询{{user}}的账户余额,并返回余额。 """) @Agent("查询指定用户的余额的银行工作人员") Double getBalance(@V("user") String user); } public interface ExchangeAgent { @UserMessage(""" 你是一名名货币兑换操作员。 使用工具将{{amount}}{{originalCurrency}}兑换为{{targetCurrency}}, 仅返回工具提供的最终金额,不添加其他内容。 """) @Agent("将指定金额的货币从原始货币兑换为目标货币的兑换员") Double exchange(@V("originalCurrency") String originalCurrency, @V("amount") Double amount, @V("targetCurrency") String targetCurrency); } -
创建 Agent 使用的 Tool :上面这些代理都使用外部工具(Tools)来执行他们的任务,这里提供 BankTool (完成从 Bank 中查询、存取操作) 、ExchangeTool (完成币制汇率换算操作)
-
BankTool
public class BankTool { private final Map<String, Double> accounts = new HashMap<>(); void createAccount(String user, Double initialBalance) { if (accounts.containsKey(user)) { throw new RuntimeException("Account for user " + user + " already exists"); } accounts.put(user, initialBalance); } @Tool("查询指定用户的余额") double getBalance(String user) { Double balance = accounts.get(user); if (balance == null) { throw new RuntimeException("No balance found for user " + user); } return balance; } @Tool("向指定用户存入指定金额并返回新余额") Double credit(@P("user name") String user, @P("amount") Double amount) { Double balance = accounts.get(user); if (balance == null) { throw new RuntimeException("No balance found for user " + user); } Double newBalance = balance + amount; accounts.put(user, newBalance); return newBalance; } @Tool("从指定用户账户提取指定金额并返回新余额") Double withdraw(@P("user name") String user, @P("amount") Double amount) { Double balance = accounts.get(user); if (balance == null) { throw new RuntimeException("No balance found for user " + user); } Double newBalance = balance - amount; accounts.put(user, newBalance); return newBalance; } } -
ExchangeTool,可用于将货币从一种货币兑换成另一种货币,可能使用提供最新汇率的REST服务。
@Slf4j public class ExchangeTool { @Tool("将指定金额的货币从原始货币兑换为目标货币") Double exchange(@P("originalCurrency") String originalCurrency, @P("amount") Double amount, @P("targetCurrency") String targetCurrency) { // Invoke a REST service to get the exchange rate if (originalCurrency.equals(targetCurrency)) { log.info("原始货币和目标货币相同,无需兑换"); return amount; } if (originalCurrency.equals("CNY") && targetCurrency.equals("USD")) { log.info("将%s元兑换为%s美元,汇率为 0.7".formatted(amount, amount / 7.0)); return amount / 7.0; } if (originalCurrency.equals("USD") && targetCurrency.equals("CNY")) { log.info("将%s美元兑换为%s元,汇率为 7".formatted(amount, amount * 7)); return amount * 7; } throw new IllegalArgumentException("不支持的货币类型"); } }
-
-
创建 SupervisorAgent :通过 AgenticServices#agentBuilder方法创建这些代理的实例,将它们配置为使用这些工具,然后将它们用作主管代理的子代理。
子智能体也可以是实现工作流的复杂智能体,这些子智能体在监管智能体看来将是单个智能体。
@Bean
public SupervisorAgent supervisorAgent(ChatModel chatModel) {
BankTool bankTool = new BankTool();
// 初始化两个账户:张三和李四,初始余额均为 1000.0
bankTool.createAccount("张三", 1000.0);
bankTool.createAccount("李四", 1000.0);
WithdrawAgent withdrawAgent = AgenticServices
.agentBuilder(WithdrawAgent.class)
.chatModel(chatModel)
.tools(bankTool)
.build();
CreditAgent creditAgent = AgenticServices
.agentBuilder(CreditAgent.class)
.chatModel(chatModel)
.tools(bankTool)
.build();
BalanceAgent balanceAgent = AgenticServices
.agentBuilder(BalanceAgent.class)
.chatModel(chatModel)
.tools(bankTool)
.build();
ExchangeAgent exchangeAgent = AgenticServices
.agentBuilder(ExchangeAgent.class)
.chatModel(chatModel)
.tools(new ExchangeTool())
.build();
// 创建 SupervisorAgent (监督智能体)
return AgenticServices
.supervisorBuilder()
.chatModel(chatModel)
.subAgents(withdrawAgent, creditAgent, balanceAgent, exchangeAgent)
.responseStrategy(SupervisorResponseStrategy.SUMMARY)
.build();
}
根据上面的内容,我们发起下面的调用请求
bankSupervisor.invoke("将 100 人民币从张三账户转到李四账户")
对于这一个请求,监管者可以生成如下一系列调用:
Agent Invocation: AgentInvocation{agentName='exchange$28', arguments={originalCurrency=人民币, amount=70, targetCurrency=美元}}
将70.0元兑换为10.0美元,汇率为 0.7
Agent Invocation: AgentInvocation{agentName='withdraw$25', arguments={user=张三, amount=10.0}}
Agent Invocation: AgentInvocation{agentName='credit$26', arguments={user=李四, amount=10.0}}
Agent Invocation: AgentInvocation{agentName='done', arguments={response=已将70块钱的人民币从张三账户提取出,并兑换为10.0美元,之后存入李四的账户,完成了整个转账过程。}}
最后一个调用是一个特殊的调用,它表明主管认为任务已经完成,并作为响应返回所有执行操作的摘要。
这里在实际调用时会偶尔存在 AI 不进行币制计算或仅扣减账户不增加账户的情况,也就是这种方式并没有那么可靠,慎用
1. SupervisorAgent 的响应策略
上面的调用后会将 已将70块钱的人民币从张三账户提取出,并兑换为10.0美元,之后存入李四的账户,完成了整个转账过程。 当做请求响应返回,这个结果是 SupervisorAgent 将与子代理交互的内容做了摘要进行返回(我们通过 responseStrategy(SupervisorResponseStrategy.SUMMARY) 指定的方式)。
但并非所有场景都需要 “操作摘要”:例如用监督者智能体替代 “顺序工作流” 生成故事(如先创作、再按风格 / 受众编辑)时,用户只需要最终故事文本,而非中间步骤的总结。这种情况我们可以通过 dev.langchain4j.agentic.supervisor.SupervisorAgentService#responseStrategy 来指定 SupervisorAgent 的响应策略,这里的取值是 SupervisorResponseStrategy枚举类。
SupervisorResponseStrategy 存在三个枚举值,如下:
SCORED:当我们无法提前知道两种响应(即由监督者生成的摘要和最后调用的智能体的最后一条响应)中哪一种更适合返回时,可以选择该策略。它会收到这两种可能的响应以及原始的用户请求,并对它们进行评分,以确定哪一种更符合请求,进而决定返回哪一种,如下:- 候选 1:最后一个被调用的子代理的最终响应。
- 候选 2:主管与所有子代理交互过程的摘要(即任务执行流程的总结)。
- 评分依据是 “与原始用户请求的匹配度”,最终返回得分更高的那个响应。
SUMMARY:返回主管与所有子代理交互过程的摘要,将整个任务的执行流程(包括调用了哪些子代理、做了哪些操作)以总结的形式呈现给用户。LAST:仅返回最后一个被调用的子代理的最终响应,不额外处理或总结流程。(默认逻辑)
我们可以通过如下方式对上述该属性进行设置:
AgenticServices.supervisorBuilder()
.responseStrategy(SupervisorResponseStrategy.SCORED)
.build();
2. SupervisorAgent 的上下文策略
监督者的核心作用是“决定下一步行动”(如调用哪个子智能体、是否继续流程),而其决策依赖的“信息”(上下文)是关键——默认仅用自身的“本地聊天记忆”(即与用户/系统的直接交互记录),但实际场景中可能需要更全面的信息(如子智能体间的对话内容),因此提供了 SupervisorContextStrategy 中的3种策略可选,如下:
- CHAT_MEMORY(默认策略)
- 信息来源:仅依赖主管代理自身的 ChatMemory(聊天记忆),即主管与用户 / 系统的历史交互记录(例如用户的历史请求、主管的历史决策、未完成的任务状态等)。
- 信息粒度:聚焦 “主管自身的对话上下文”,不包含子代理的交互细节。
- 决策逻辑:主管基于 “自己的记忆” 做决策,与子代理的执行过程完全解耦。
- 适用场景:
- 主管的决策逻辑相对独立,不需要参考子代理的执行细节,例如简单指令执行(如 “帮我生成一段 50 字的产品介绍”)。
- 子代理是无状态的 “工具型执行者”,仅需主管下达指令,不需要反馈调整,例如单步工具调用(如 “调用翻译工具把这句话译成英文”)。
- 示例:用户连续请求 “生成科幻故事”,主管通过 ChatMemory 记住 “用户偏好科幻题材”,直接调用故事生成子代理,无需参考子代理的历史交互。
- SUMMARIZATION
- 信息来源:仅依赖主管与所有子代理的交互过程摘要(例如调用了哪些子代理、子代理返回了什么结果、任务执行到哪一步等)。
- 信息粒度:聚焦 “子代理的执行流程和结果”,不包含主管自身的历史对话。
- 决策逻辑:主管基于 “子代理的交互反馈” 做决策,完全依赖当前任务的执行细节。
- 适用场景:
- 需要让主管明确 “子代理做了什么”,并基于此调整后续步骤,例如多工具协作的复杂任务(如 “先调用天气 API 查北京天气,再根据天气推荐穿搭”)。
- 子代理的执行结果对决策至关重要,例如纠错型任务(子代理返回错误结果后,主管需要根据摘要判断是否重试或换用其他子代理)。
- 示例:用户请求 “规划一场巴黎 3 日游”,主管调用 “景点推荐子代理” 后,根据其返回的 “埃菲尔铁塔、卢浮宫” 等结果的摘要,决定下一步调用 “酒店推荐子代理”,全程不依赖自身历史对话。
- CHAT_MEMORY_AND_SUMMARIZATION
- 信息来源:同时结合主管自身的 ChatMemory 和与子代理交互的摘要,是前两种策略的信息合集。
- 信息粒度:既包含 “主管的历史对话上下文”,又包含 “子代理的执行细节”,信息最全面。
- 决策逻辑:主管需要在 “用户历史偏好” 和 “当前子代理的执行反馈” 之间做平衡,决策依据最丰富。
- 适用场景:
- 复杂的长期任务或多轮交互,需要同时记住用户的历史需求,并结合子代理的执行情况动态规划,例如个性化服务任务(如 “基于我之前喜欢的咖啡口味,推荐新的咖啡豆,并帮我查最近的线下门店库存”)。
- 子代理的执行结果需要结合历史上下文才能生效,例如多步骤协作的智能助手(如 “先帮我整理会议纪要,再根据纪要生成行动项,并关联我上周未完成的任务”)。
- 示例:用户长期请求 “优化我的健身计划”,主管通过 ChatMemory 记住 “用户目标是增肌、每周训练 3 次”,同时结合 “健身计划生成子代理返回的‘每日训练内容’摘要”,决定是否调用 “营养建议子代理” 补充饮食方案。
我们可以通过如下方式对上述两个属性进行设置:
AgenticServices.supervisorBuilder()
.contextGenerationStrategy(SupervisorContextStrategy.SUMMARIZATION)
.build();
3. 设置 SupervisorAgent 背景信息
SupervisorContext 为监管者智能体提供“规划时的指导依据”,比如业务约束(不调用外部服务)、政策要求(货币用美元)、偏好设置(优先内部工具),避免智能体在执行任务(如银行转账、工具调用)时偏离规则。
SupervisorContext统一存放在
AgenticScope(智能体共享数据空间)中,变量名固定为supervisorContext,确保所有子智能体(如示例中的转账、信贷智能体)都能读取到规则。
LangChain4j 提供了两种配置 supervisorContext的方式
- 构建时配置(Build-time configuration)
- 时机:在创建监管者智能体(SupervisorAgent)实例时设置,是“全局默认规则”。
- 特点:一旦配置,后续所有调用若不单独指定,都会沿用这个默认规则。
- 示例场景:银行监管者默认“优先内部工具、货币为美元、不调用外部API”,所有常规转账任务都遵循此规则。
SupervisorAgent bankSupervisor = AgenticServices .supervisorBuilder() .chatModel(PLANNER_MODEL) .supervisorContext("政策:优先使用内部工具;货币为美元;不使用外部API") .subAgents(withdrawAgent, creditAgent, exchangeAgent) .responseStrategy(SupervisorResponseStrategy.SUMMARY) .build();
- 调用时配置(Invocation configuration)
- 时机:每次调用监管者智能体时临时设置,用于覆盖默认规则,适配单次任务的特殊需求。
- 两种形式:
-
类型化监管者(Typed Supervisor):在接口方法参数中加
@V("supervisorContext")注解,调用时传特殊规则(如“先转成美元、仅用银行工具”)。// 自定义 SupervisorAgent public interface SupervisorAgent { @Agent String invoke(@V("request") String request, @V("supervisorContext") String supervisorContext); } // Example call (overrides the build-time value for this invocation) bankSupervisor.invoke( "将 50 美元从李四账户提取到张三账户", "政策:优先使用内部工具;货币为美元;不使用外部API" ); -
非类型化监管者(Untyped Supervisor):在输入Map中直接设置
"supervisorContext"键值对,传临时规则。Map<String, Object> input = Map.of( "将 50 美元从李四账户提取到张三账户", "政策:优先使用内部工具;货币为美元;不使用外部API" ); String result = (String) bankSupervisor.invoke(input);
-
若同时提供“构建时配置”和“调用时配置”,调用时的规则会覆盖构建时的默认规则,确保单次特殊任务能灵活适配,而不影响全局默认逻辑(如示例中默认“货币USD”,但单次任务临时要求“先转USD再操作”,以调用时规则为准)。
十、非AI 智能体
与依赖 LLM 处理自然语言任务(如生成故事、分类请求)的 AI 智能体不同,非 AI 智能体专注于 无自然语言处理需求的“机械性任务”,例如调用 REST API(如货币兑换接口)、执行系统命令、数据格式转换等。它更接近“工具”,但 LangChain4j 将其建模为“智能体”——目的是让它能和 AI 智能体 用相同方式调用、无缝混合,避免工具与智能体的使用割裂,简化复杂系统的搭建。
1. 使用
非 AI 智能体的定义只需是 有且仅有一个带 @Agent 注解方法的 Java 类,无需依赖 LLM。并且可与 AI 智能体一同作为“子智能体”参与系统。
例如,在上面的监管者示例中使用的 ExchangeAgent 可能并不适合被建模为AI智能体,它更适合被定义为一个非AI智能体,仅通过调用REST API来执行货币兑换操作,因此就可以做出如下改造:
-
定义一个非 AI 智能体,替代 ExchangeAgent
@Slf4j public class ExchangeOperator { @Agent(value = "一个货币兑换器,可将给定金额的货币从原始货币转换为目标货币", outputKey = "exchange") public Double exchange(@V("originalCurrency") String originalCurrency, @V("amount") Double amount, @V("targetCurrency") String targetCurrency) { if (originalCurrency.equals(targetCurrency)) { log.info("原始货币和目标货币相同,无需兑换"); return amount; } if (originalCurrency.equals("CNY") && targetCurrency.equals("USD")) { log.info("将%s元兑换为%s美元,汇率为0.15".formatted(amount, amount * 0.15)); return amount * 0.15; } if (originalCurrency.equals("USD") && targetCurrency.equals("CNY")) { log.info("将%s美元兑换为%s元,汇率为 7".formatted(amount, amount * 7)); return amount * 7; } throw new IllegalArgumentException("不支持的货币类型"); } } -
重新构建SupervisorAgent
SupervisorAgent bankSupervisor = AgenticServices .supervisorBuilder() .chatModel(chatModel) .subAgents(withdrawAgent, creditAgent, balanceAgent, new ExchangeOperator()) .responseStrategy(SupervisorResponseStrategy.SUMMARY) .build();
本质上,langchain4j-agentic中的智能体可以是任何Java类,只要它有且仅有一个用@Agent注解标注的方法。
2. AgentAction
除此之外,非 AI 智能体也可用于读取 AgenticScope 的状态或对其执行小型操作,AgenticServices提供了一个 agentAction 工厂方法,用于通过 Consumer<AgenticServices>创建简单的智能体。
简单示例如下:假设有一个scorer智能体,它生成一个字符串类型的score,而后续的reviewer智能体需要将该score作为双精度浮点型数据使用。在这种情况下,这两个智能体将不兼容,但可以使用agentAction将第一个智能体的输出转换为第二个智能体所需的格式,如下所示重写AgenticScope的score状态:
UntypedAgent editor = AgenticServices.sequenceBuilder()
.subAgents(
scorer,
AgenticServices.agentAction(agenticScope -> agenticScope.writeState("score", Double.parseDouble(agenticScope.readState("score", "0.0")))),
reviewer)
.build();
3. 人在回路
人在回路(Human-in-the-Loop)被定义为**“特殊的非AI智能体”**,核心作用是解决智能体系统在执行中可能遇到的“信息缺失”或“需人工确认”问题——比如生成星座运势时缺少用户的“星座”信息,或执行敏感操作前需用户批准,此时系统可通过该智能体主动向人类请求输入。
简单来说就是让系统能够在执行特定操作前,就缺失的信息向用户询问输入或请求批准。这种人工参与能力也可以被视为一种特殊的非AI智能体,因此可以照此方式实现。
LangChain4j提供的HumanInTheLoop智能体,定义如下:
// dev.langchain4j.agentic.workflow.HumanInTheLoop
public record HumanInTheLoop(
String inputKey,
String outputKey,
String description,
Consumer<?> requestWriter,
boolean async,
Supplier<?> responseReader)
implements AgentSpecsProvider {
@Agent("An agent that asks the user for missing information")
public Object askUser(Object request) {
((Consumer<Object>) requestWriter).accept(request);
return responseReader.get();
}
...
}
HumanInTheLoop 通过两个核心函数实现与人类的交互:
requestWriter(请求发送器):属于Consumer<String>类型,负责将系统需要的信息(如“请提供你的星座”)传递给人类(示例中是打印到控制台);responseReader(响应接收器):属于Supplier<String>类型,负责阻塞式等待并获取人类的输入(示例中是从控制台读取用户输入的内容)。
同时,可通过配置绑定AgenticScope的“输入/输出变量”供后续AI智能体(如AstrologyAgent)调用。
以“生成星座运势”为例,完整流程是:
- 定义
AstrologyAgent(AI智能体):需name(姓名)和sign(星座)两个参数生成运势; - 创建
HumanInTheLoop智能体:配置“向用户要星座”的逻辑(控制台打印请求、读输入),输出变量绑定sign; - 构建
SupervisorAgent(监督者智能体):整合前两者,当用户调用时(如“我叫Mario,我的运势是什么?”),监督者发现sign缺失,自动触发HumanInTheLoop向用户询问,获取后再调用AstrologyAgent生成结果。
简单示例如下 :
- 定义 AstrologyAgent Agent
public interface AstrologyAgent {
@SystemMessage("""
你是一名占星师,会根据用户的姓名和星座生成星座运势。
""")
@UserMessage("""
为身为{{sign}}的{{name}}生成星座运势。
""")
@Agent("一位根据用户的姓名和星座生成星座运势的占星师。")
String horoscope(@V("name") String name, @V("sign") String sign);
}
- 创建一个SupervisorAgent,它同时使用该AI智能体和一个 HumanInTheLoop 智能体,在生成星座运势之前询问用户的星座,将问题发送到控制台标准输出,并从标准输入读取用户的响应,具体如下:
@Bean("horoscopeAgent")
public SupervisorAgent horoscopeAgent(ChatModel chatModel) {
AstrologyAgent astrologyAgent = AgenticServices
.agentBuilder(AstrologyAgent.class)
.chatModel(chatModel)
.build();
HumanInTheLoop humanInTheLoop = AgenticServices
.humanInTheLoopBuilder()
.description("一个询问用户星座的智能体")
.outputKey("sign")
.requestWriter(request -> {
// 控制台打印出请求内容
System.out.println(request);
System.out.print("> ");
})
.responseReader(() -> {
// 用户输入内容
Scanner scanner = new Scanner(System.in);
return scanner.nextLine();
})
.build();
return AgenticServices
.supervisorBuilder()
.chatModel(chatModel)
.subAgents(astrologyAgent, humanInTheLoop)
.build();
}
SupervisorAgent 会发现用户的星座信息缺失,并会调用 HumanInTheLoop 向用户询问,等待用户提供答案,该答案随后将用于调用 AstrologyAgent 并生成星座运势。
需要注意的是:虽建议将HumanInTheLoop设为“异步模式”(避免等待用户输入时阻塞其他无关智能体),但在监督者(Supervisor)架构下无效——因为监督者需要确保所有智能体的状态都被完整纳入AgenticScope,才能规划下一步行动,因此会强制所有智能体执行“阻塞式操作”。
十一、A2A Integration
参照官网 : https://docs.langchain4j.dev/tutorials/agents/#a2a-integration
十二、参考内容

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)