Distilling Vision-Language Pre-training to Collaborate with Weakly-Supervised Temporal Action Locali
弱监督时序动作定位(WTAL)旨在仅借助类别标签完成动作实例的检测与分类。现有绝大多数方法均广泛采用现成的基于分类的预训练(CBP)方式生成视频特征,以实现动作定位。然而,分类与定位任务的优化目标存在差异,这使得时序定位结果面临严重的不完整问题。为在不增加额外标注成本的前提下解决该问题,本文提出从视觉-语言预训练(VLP)中挖掘免费的动作知识——研究中我们意外发现,原始VLP的定位结果存在过完整问

标题:蒸馏视觉 - 语言预训练以与弱监督时序动作定位协同工作
原文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Ju_Distilling_Vision-Language_Pre-Training_To_Collaborate_With_Weakly-Supervised_Temporal_Action_Localization_CVPR_2023_paper.pdf
发表:CVPR-2023
摘要
弱监督时序动作定位(WTAL)旨在仅借助类别标签完成动作实例的检测与分类。现有绝大多数方法均广泛采用现成的基于分类的预训练(CBP)方式生成视频特征,以实现动作定位。然而,分类与定位任务的优化目标存在差异,这使得时序定位结果面临严重的不完整问题。为在不增加额外标注成本的前提下解决该问题,本文提出从视觉-语言预训练(VLP)中挖掘免费的动作知识——研究中我们意外发现,原始VLP的定位结果存在过完整问题,而这一特性恰好与CBP的结果形成互补。为融合这种互补性,我们提出一种新颖的蒸馏-协作框架,该框架包含两个分支,分别对应CBP和VLP,并通过双分支交替训练策略完成优化。具体而言,在B步骤中,从CBP分支提取置信度高的背景伪标签;在F步骤中,从VLP分支提取置信度高的前景伪标签。最终,双分支的互补性被有效融合,形成性能优异的整体。在THUMOS14和ActivityNet1.2数据集上开展的大量实验与消融研究表明,本文方法的性能显著优于当前最优方法。
1 引言
时序动作定位(TAL)旨在从未修剪的长视频中定位并分类动作实例,是视频理解领域不可或缺的核心组件[13,72,92]。为避免耗时费力的时序边界标注,弱监督设置下的时序动作定位(WTAL)[31,62,64,78](即仅提供视频级别的类别标签)受到了越来越多的关注。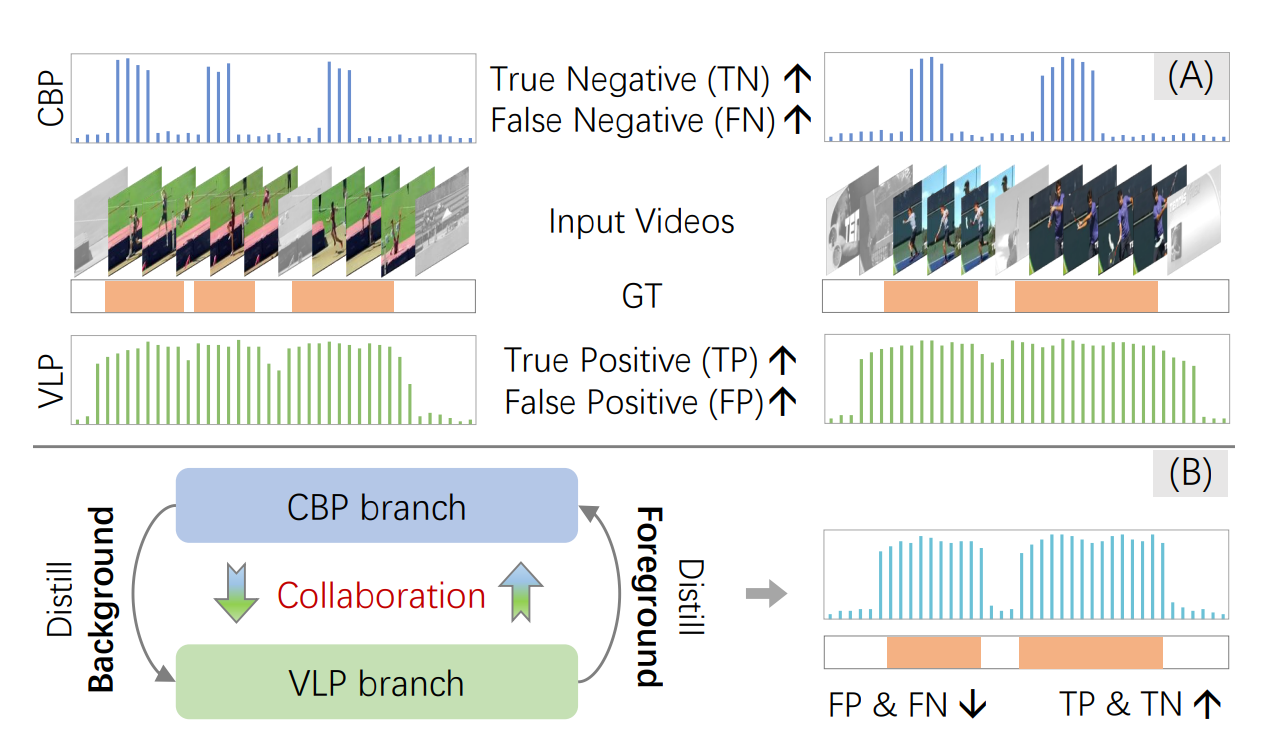
(A) 互补性:现有多数方法采用基于分类的预训练(CBP)完成定位,虽真阴性(TN)高但假阴性(FN)问题严重;原始视觉 - 语言预训练(VLP)易混淆动作与背景,虽真阳性(TP)高但假阳性(FP)问题严重。(B) 本文提出的蒸馏 - 协作框架:从 VLP 分支提取前景信息、从 CBP 分支提取背景信息,促进双分支相互协作,最终得到理想结果。
目前,现有几乎所有的WTAL方法均依赖基于分类的预训练(CBP)来提取视频特征[5,73]。一种主流流程为:利用CBP特征训练动作分类器,随后对帧级分类概率设置阈值,得到最终的定位结果。如图1(A)所示,这些CBP方法存在严重的不完整问题——仅能检测到稀疏的判别性动作帧,导致假阴性率居高不下。核心原因在于,分类预训练的优化目标是筛选出若干判别性帧以完成动作识别,这与完整定位的目标相去甚远。因此,CBP提取的特征不可避免地偏向局部判别性帧。为解决这一不完整问题,研究人员已开展诸多尝试[33,43,56,96],但多数方法陷入了“性能-成本困境”:为控制成本,只能仅从有限的类别标签中挖掘信息。位置标签的缺失从根本上限制了性能,使得弱监督与强监督方法之间存在巨大性能差距。
为跳出这一困境,本文提出一个全新问题:是否存在可利用的免费动作知识,能够在维持低成本标注开销的同时完善检测结果?我们自然将目光投向当前主流的视觉-语言预训练(VLP)[22,66]。VLP已被证实可从大规模网络数据中学习到优质的跨模态视觉-文本表征。由于语言包含丰富的物体、人物-物体交互以及物体间关系等信息,这些学习到的表征能够提供有效的人物-物体共现先验知识——这对动作定位任务而言是宝贵的资源。
本文首次尝试正面回答这一问题,即填补从VLP(具体为CLIP[66])中提取动作先验知识以解决WTAL不完整问题的研究空白。如图1(A)所示,我们首先通过逐帧分类的方式直观评估VLP的时序定位性能,但其结果并不理想,存在严重的过完整问题(即将多个动作实例混淆为一个整体),导致假阳性率较高。我们推测主要原因有二:(1)受数据与计算成本限制,几乎所有VLP均基于图像-文本对训练,因此VLP缺乏足够的时序知识,在定位时更多依赖人物-物体共现信息,难以区分背景上下文视觉相似的动作;(2)部分背景上下文的文本语义与动作相似(易混淆),例如“助跑(run-up)”与“跑步(running)”。
尽管直接将VLP应用于WTAL不可行,但我们幸运地发现CBP与VLP范式之间存在互补性:前者真阴性率高但假阴性问题严重,后者真阳性率高但假阳性问题严重。为利用这种互补性,如图1(B)所示,我们设计了一种新颖的蒸馏-协作框架,该框架包含两个分支,分别承担CBP和VLP的角色。设计思路是从CBP分支提取背景知识,从VLP分支提取前景知识,进而形成性能优异的整体。具体而言,我们首先仅利用类别监督对CBP分支进行预热,以初始化置信度高的背景帧,随后通过交替策略优化该框架。在B步骤中,为VLP分支提取背景伪标签以解决过完整问题,从而得到高质量的前景伪标签;在F步骤中,利用高质量的伪标签辅助CBP分支解决不完整问题。此外,在每个步骤中,我们引入置信知识蒸馏与表征对比学习对伪标签去噪,有效融合互补性以提升结果。
在两个标准基准数据集(THUMOS14和ActivityNet1.2)上,本文方法相较于当前最优方法,平均性能分别提升3.5%和2.7%。我们还开展了大量消融研究,从定量和定性两个维度验证了各组件的有效性。
综上,本文的贡献主要体现在三个方面:
• 首次探索从现成的VLP中提取免费的动作知识,以辅助WTAL任务;
• 设计了一种新颖的蒸馏-协作框架,通过交替优化策略促使CBP分支与VLP分支相互补充;
• 开展了大量实验与消融研究,验证了从VLP中提取知识的重要性,以及本文方法在两个公开基准数据集上的卓越性能。
2 相关工作
2.1 视觉-语言预训练(VLP)
视觉-语言预训练(VLP)旨在从大规模网络数据中学习跨模态表征[10,25,57,82]。相较于视频,图像的标注与计算成本更低,因此几乎所有VLP均基于图像构建,例如[1,22,66,80,91,93]。近年来,已有研究将VLP应用于下游图像任务,为其提供免费的视觉-语义知识,例如检测[16,94]、分割[44,54,67,103]、人机交互[29,36]、合成[47]与生成[9,76,77]等任务。
在视频领域,研究[42,51,79]为VLP配备时序Transformer以实现动作识别;研究[23,24,59]引入提示学习(prompt learning)以实现高效检索或检测。然而,这些研究多聚焦于开放词汇场景或短视频理解。与之不同,本文首次探索在弱监督设置下,将VLP应用于长视频的时序定位任务。
2.2 强监督时序动作定位
强监督时序动作定位在给定精确动作边界与类别标签的前提下,已取得显著进展[38,46,65,95]。目前存在两种主流流程:
- 自上而下框架[6,14,40,69,71,75,81,83,85,104]:基于动作分布先验预定义大量锚点,通过固定长度的滑动窗口生成初始候选框,再通过回归优化边界;
- 自下而上框架[3,8,37,39,41,58,74,85,87,100,101]:训练逐帧边界检测器以识别极端帧(起始帧、结束帧、中心帧),随后对极端帧进行分组或估计动作长度,生成候选框。
此外,部分研究[11,49,88]提出多种融合策略以补充上述框架的不足;另有研究[45,95]致力于优化后处理流程。然而,上述所有方法均需精确的边界标注,而这类标注在实际应用中耗时且成本高昂。
2.3 弱监督时序动作定位
弱监督时序动作定位仅需类别标签即可完成训练,大幅降低了标注成本。其核心组件是基于分类的预训练(CBP)所得到的类别激活序列(CAS)[21,62,64,78]。但由于分类与定位任务的目标差异,CBP存在严重的不完整问题:仅能定位判别性动作片段,甚至可能误定位背景区域。
为解决这一问题,研究[27,56,102]引入擦除策略(erasing strategy);研究[43,52,60]并行生成多个CAS以实现互补;研究[32,33,63,68]提出背景建模与上下文分离方法;研究[12,17,19,97]通过视频内与视频间建模提升特征质量。为迭代优化结果,部分研究[53,89,96]引入自训练策略(self-training strategy);研究[50,70]采用内外对比学习(outer-inner contrastive learning)。
尽管这些方法取得了一定进展,但多数仍陷入“性能-成本困境”:为控制成本,只能仅从有限的类别标签中挖掘信息。而标注信息的缺失导致弱监督与强监督方法之间存在巨大性能差距。为此,研究[26,28,30,55,61,86]尝试增加实例数量或单帧标注以进一步提升性能;部分研究[2,4,84,99]则探索针对时序动作定位(TAL)的长视频预训练方法。
与现有工作不同,本文旨在不增加额外标注成本的前提下提升性能,提出从现成的VLP中提取免费的动作知识,以辅助WTAL任务。
3 方法
3.1 符号与预备知识
任务定义
给定 N N N个未修剪视频 { v i } i = 1 N \{v_i\}_{i=1}^N {vi}i=1N及其视频级别类别标签 { y i ∈ R C } i = 1 N \{y_i \in \mathbb{R}^C\}_{i=1}^N {yi∈RC}i=1N(其中 C C C表示动作类别的总数),弱监督时序动作定位(WTAL)旨在检测并分类所有动作实例,结果以四元组集合 { ( s , e , c , p ) } \{(s, e, c, p)\} {(s,e,c,p)}表示。其中, s s s、 e e e、 c c c、 p p p分别代表动作候选框的起始时间、结束时间、动作类别及检测分数。需注意,单个视频可能包含多个动作实例。
研究动机
正如表3所总结的,基于分类的预训练(CBP)与视觉-语言预训练(VLP)的定位结果存在显著互补性:前者存在结果不完整问题(假阴性严重),但真阴性表现优异;后者存在结果过完整问题(假阳性严重),但真阳性表现优异。这一发现促使我们设计蒸馏-协作框架,融合两者的互补结果以形成性能优异的整体。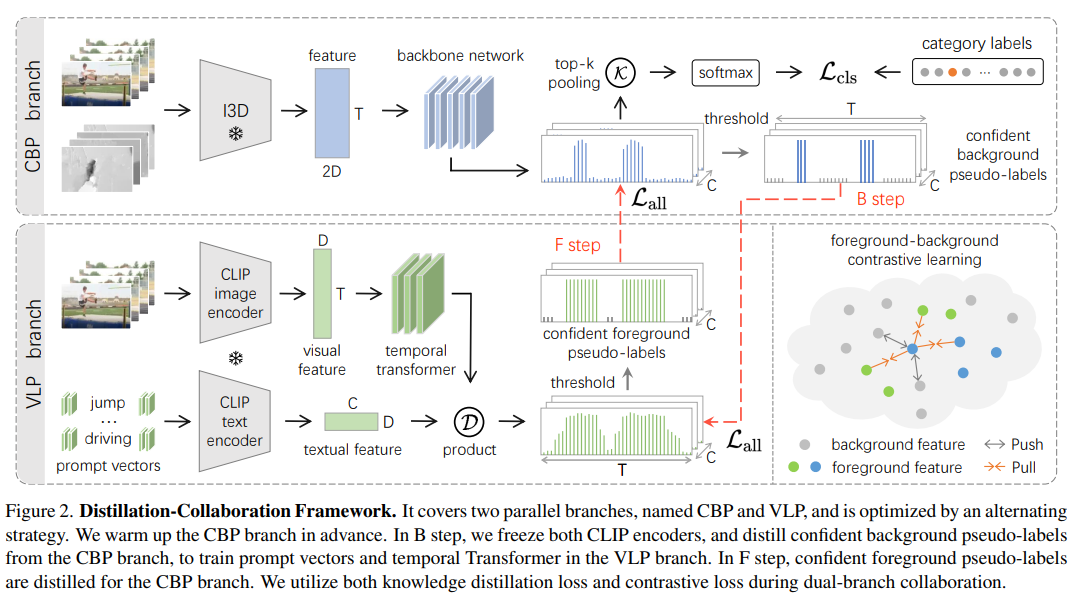
框架概述
如图2所示,蒸馏-协作框架包含两个并行分支(分别称为CBP分支与VLP分支),并通过交替策略完成优化。首先,仅利用分类监督对CBP分支进行“预热”(warm-up),使其生成丰富的背景信息。在B步骤中,从CBP分支提取置信度高的背景伪标签,用于辅助VLP分支解决过完整问题,从而定位高质量的前景与背景信息;在F步骤中,从训练成熟的VLP分支提取优质伪标签,用于辅助CBP分支解决不完整问题。通过这种双分支协作,有效融合两者的互补结果。
3.2 前景与背景的蒸馏
CBP分支
CBP分支利用基于分类的预训练,识别大量背景帧与部分判别性动作帧。
参考现有文献[33,43],我们采用CBP预训练方式——即基于Kinetics数据集[5]预训练的I3D网络结构,分别提取RGB特征与光流(Flow)特征,并将两者拼接形成双流特征 F i 3 d ∈ R T × 2 D F_{i3d} \in \mathbb{R}^{T \times 2D} Fi3d∈RT×2D(其中 T T T表示时间长度, D D D表示特征维度)。随后,将 F i 3 d F_{i3d} Fi3d输入CBP分支,通过骨干网络完成特征微调与定位,最终输出帧级别动作概率 P c b ∈ R T × C P^{cb} \in \mathbb{R}^{T \times C} Pcb∈RT×C。
为实现动作分类,我们采用多实例学习(multiple instance learning):对于骨干网络输出的 P c b P^{cb} Pcb,通过聚合(池化)top-k帧的分数得到视频级别类别分数 y ^ ∈ R C \hat{y} \in \mathbb{R}^C y^∈RC,并利用二元交叉熵损失对其进行监督,公式定义如下:
L c l s = ∑ c = 1 C − y c log y ^ c , y ^ c = σ ( 1 k ∑ K ( P c b ) ) (1) \mathcal{L}_{cls }=\sum_{c=1}^{C}-y_{c} \log \hat{y}_{c}, \quad \hat{y}_{c}=\sigma\left(\frac{1}{k} \sum \mathcal{K}\left(P^{cb}\right)\right) \tag{1} Lcls=c=1∑C−yclogy^c,y^c=σ(k1∑K(Pcb))(1)
其中, K \mathcal{K} K表示在时间维度上选取top-k分数的集合, σ \sigma σ表示softmax函数。
注:在CBP预训练与仅类别监督的设置下, P c b P^{cb} Pcb的特点是聚焦于稀疏的判别性动作帧——即真阴性高但假阴性严重,因此能够提供丰富的背景信息。
VLP分支
VLP分支旨在从视觉-语言预训练(如CLIP[66])中挖掘免费的动作知识。由于图像-文本预训练缺乏足够的时序先验,原始VLP的定位结果存在严重过完整问题(假阳性高)。为解决这一问题,我们提出利用大量背景样本对CLIP进行微调。
不同于线性探测(linear probing),我们采用高效的提示学习(prompt learning)[23,34]进行微调:冻结CLIP的骨干网络,仅优化若干提示向量(prompt vectors)与时序层(temporal layers)。
具体而言,在视觉流(visual stream)中,首先将视频分割为连续帧,随后利用CLIP图像编码器提取帧级别特征 F v i s ∈ R T × D F_{vis} \in \mathbb{R}^{T \times D} Fvis∈RT×D;为构建时序关系,通过简单的时序Transformer层 Φ t e m p ( ⋅ ) \Phi_{temp}(\cdot) Φtemp(⋅)将 F v i s F_{vis} Fvis增强为 F v i d ∈ R T × D F_{vid} \in \mathbb{R}^{T \times D} Fvid∈RT×D。在文本流(textual stream)中,首先在类别名称前后添加若干可学习的提示向量 Φ p r m p ( ⋅ ) \Phi_{prmp}(\cdot) Φprmp(⋅),再将其输入CLIP文本编码器,得到文本特征 F t x t ∈ R C × D F_{txt} \in \mathbb{R}^{C \times D} Ftxt∈RC×D。形式化定义如下:
F v i d = Φ t e m p ( F v i s ) , F t x t = Φ t x t ( Φ p r m p ( C n a m e ) ) (2) F_{vid}=\Phi _{temp}(F_{vis}), \quad F_{txt}=\Phi _{txt}\left( \Phi _{prmp}(C_{name})\right) \tag{2} Fvid=Φtemp(Fvis),Ftxt=Φtxt(Φprmp(Cname))(2)
其中, C n a m e C_{name} Cname表示动作类别名称, Φ t x t ( ⋅ ) \Phi_{txt}(\cdot) Φtxt(⋅)表示CLIP文本编码器。此后,该分支的帧级别定位结果 P v l P^{vl} Pvl可通过以下公式计算:
P v l = σ ( F v i d ⋅ F t x t ⊤ ) ∈ R T × C (3) P^{vl}=\sigma\left( F_{vid} \cdot F_{txt}^{\top}\right) \in \mathbb {R}^{T \times C} \tag{3} Pvl=σ(Fvid⋅Ftxt⊤)∈RT×C(3)
注:对于VLP分支,我们仅优化轻量级模型参数以抑制假阳性,这自然带来两个主要优势:(1)冻结的CLIP骨干网络保留了预训练中的动作先验知识,从而维持高真阳性结果;(2)符合弱监督设置下对监督数据量的低需求,同时节省内存开销。
置信伪标签
由于 P v l P^{vl} Pvl与 P c b P^{cb} Pcb均包含一定噪声,为可靠利用两者的互补信息,我们分别从两个分支中提取前景与背景的置信定位伪标签:即从CBP分支的输出 P c b P^{cb} Pcb中提取大量背景伪标签,从VLP分支的输出 P v l P^{vl} Pvl中提取充足前景伪标签。
对于两个分支,我们采用双阈值 δ h \delta_h δh与 δ l \delta_l δl( δ h > δ l \delta_h>\delta_l δh>δl),将定位结果 P P P转换为三元伪标签 H ∈ R T × C H \in \mathbb{R}^{T \times C} H∈RT×C,形式化定义如下:
h t , c = { 1 若 p t > δ h 且 p c = y c 0 若 p t < δ l 或 p c ≠ y c − 1 其他情况 h_{t, c}=\begin{cases} 1 & \text{若 } p_{t}>\delta_{h} \text{ 且 } p_{c}=y_{c} \\ 0 & \text{若 } p_{t}<\delta_{l} \text{ 或 } p_{c} \neq y_{c} \\ -1 & \text{其他情况} \end{cases} ht,c=⎩
⎨
⎧10−1若 pt>δh 且 pc=yc若 pt<δl 或 pc=yc其他情况
其中,下标 c c c与 t t t分别表示类别索引与帧索引。具体而言,对于任意一个分支:
- 分数大于 δ h \delta_h δh且属于正确动作类别的帧被视为前景;
- 分数小于 δ l \delta_l δl或属于错误动作类别的帧被视为背景;
- 其余帧被视为不确定区域。
最终,伪标签 H c b H^{cb} Hcb包含大量置信背景帧与少量前景帧;伪标签 H v l H^{vl} Hvl包含密集的置信前景帧与部分背景帧。需注意,为避免 trivial 解( trivial solutions )并促进对比特征学习,两个分支均需生成正帧(前景)与负帧(背景)。
3.3 双分支优化的协作
本节旨在促进两个分支的协同工作,从而融合两者的互补定位结果,形成性能优异的整体。为降低伪标签中的严重噪声,我们引入交替训练策略,用于双分支的协同优化。
设计思路为:在B步骤中从CBP分支提取背景知识,在F步骤中从VLP分支提取前景知识。具体而言,首先仅利用类别监督对CBP分支进行预热,以初始化可靠的背景帧。在B步骤中,冻结训练成熟的CBP分支,生成置信背景伪标签 H c b H^{cb} Hcb,用于监督VLP分支——此举可大幅缓解原始CLIP预训练带来的假阳性混淆问题,使生成的伪标签包含大量置信前景帧与背景帧。在F步骤中,从冻结的VLP分支提取高质量伪标签 H v l H^{vl} Hvl,指导CBP分支抑制假阴性。通过这种交替策略,两个分支不仅能够互补,还能相互修正,共同实现更精准、更完整的动作定位。
在每个步骤中,为监督任意一个分支,我们同时采用知识蒸馏损失 L k d \mathcal{L}_{kd} Lkd与前景-背景对比损失 L f b \mathcal{L}_{fb} Lfb。总优化损失可通过平衡系数 λ \lambda λ表示为:
L a l l = L k d ( H ′ , P ) + λ L f b ( Ψ + , Ψ − ) (5) \mathcal{L}_{all }=\mathcal{L}_{kd}\left(H', P\right)+\lambda \mathcal{L}_{fb}\left(\Psi^{+}, \Psi^{-}\right) \tag{5} Lall=Lkd(H′,P)+λLfb(Ψ+,Ψ−)(5)
其中, L k d \mathcal{L}_{kd} Lkd用于正则化一个分支,使其输出与来自另一个分支的伪标签具有相似的检测结果。考虑到伪标签中存在噪声(即不确定帧),我们仅对置信帧进行监督。其公式定义如下:
L k d ( H ′ , P ) = 1 O ∑ c = 1 C ∑ t = 1 O D K L ( h t , c ′ ∥ p t , c ) \mathcal{L}_{kd}\left(H', P\right)=\frac{1}{O} \sum_{c=1}^{C} \sum_{t=1}^{O} D_{KL}\left(h_{t, c}' \| p_{t, c}\right) Lkd(H′,P)=O1c=1∑Ct=1∑ODKL(ht,c′∥pt,c)
其中, D K L ( p ( x ) ∥ q ( x ) ) D_{KL}(p(x) \| q(x)) DKL(p(x)∥q(x))表示分布 p ( x ) p(x) p(x)相对于分布 q ( x ) q(x) q(x)的KL散度(Kullback-Leibler divergence), O O O为置信帧的总数, H ′ H' H′表示来自另一个分支的伪标签。需注意,伪标签包含前景与背景两种置信帧,可避免仅使用单一类型标签导致的trivial解问题。
此外,在未修剪的长视频中,部分背景上下文可能与动作(前景)在视觉上相似。为此,我们进一步引入对比学习,以拉近前景特征、推远背景特征。具体而言,将同一动作类别的置信前景帧视为正样本集 Ψ + \Psi^{+} Ψ+,将所有置信背景帧视为负样本集 Ψ − \Psi^{-} Ψ−,则前景-背景对比损失定义为:
L f b ( Ψ i + , Ψ i − ) = ∑ i − log ∑ m ∈ Ψ i + exp ( f i ⋅ f m / τ ) ∑ j ∈ ∗ exp ( f i ⋅ f j / τ ) (7) \mathcal{L}_{fb}\left(\Psi_{i}^{+}, \Psi_{i}^{-}\right)=\sum_{i}-\log \frac{\sum_{m \in \Psi_{i}^{+}} \exp \left(f_{i} \cdot f_{m} / \tau\right)}{\sum_{j \in *} \exp \left(f_{i} \cdot f_{j} / \tau\right)} \tag{7} Lfb(Ψi+,Ψi−)=i∑−log∑j∈∗exp(fi⋅fj/τ)∑m∈Ψi+exp(fi⋅fm/τ)(7)
其中, f ∈ R D f \in \mathbb{R}^{D} f∈RD表示帧特征, τ \tau τ为用于缩放的温度超参数(temperature hyper-parameter), ∗ * ∗表示 Ψ i + \Psi_{i}^{+} Ψi+与 Ψ i − \Psi_{i}^{-} Ψi−的并集。以VLP分支为例,充足的背景伪标签包含大量难负样本(hard negative samples),有助于区分前景与上下文特征;同时,不确定帧的增强特征也会更具判别性,进一步提升时序动作定位的完整性。
讨论:与多种融合策略相比,我们的交替策略能生成更精准、更完整的结果(详见表4)。该策略的作用类似于多视图协同训练(multi-view co-training)——CBP与VLP分支可视为两种不同视图,因此对伪标签噪声具有较强的鲁棒性。在B步骤中,我们引导VLP分支生成高质量伪标签,其中部分预测冲突的帧仍被视为不确定区域;在F步骤中,通过特征对比损失提升结果的判别性,即进一步去噪。
3.4 推理
在测试阶段,我们采用CBP分支的结果进行后处理——因为视觉-语言预训练无法处理光流(Optical Flow),而光流对WTAL任务至关重要。对于输入视频,首先获取视频级别类别概率与帧级别定位分数:
- 动作分类:选取概率大于 θ c l s \theta_{cls} θcls的类别;
- 定位:对检测分数设置阈值 θ l o c \theta_{loc} θloc,将连续片段拼接为动作候选框,并通过软非极大值抑制(soft non-maximum suppression, NMS)消除冗余候选框。
每个候选框的分数由其区间内的最大检测分数确定。
4 实验
4.1 实验实现
数据集
- THUMOS14:包含413个未修剪视频,涵盖20个类别,每个视频平均包含15个动作实例。按照常规设置,使用200个验证视频进行训练,213个测试视频进行评估。尽管该数据集规模较小,但挑战性较强——视频长度差异大,且动作出现频率高。
- ActivityNet1.2:包含9682个视频,涵盖100个类别。几乎所有视频均为单类别,且动作区域占视频时长的一半以上。使用4619个训练视频进行训练,2383个验证视频进行评估。
评估指标
为评估定位性能,遵循标准协议,采用不同交并比(intersection over union, IoU)阈值下的平均精度均值(mean Average Precision, mAP)。需注意,仅当类别预测正确且IoU超过设定阈值时,候选框才被视为正样本。为清晰评估伪标签质量,还报告了前景类别与背景类别上的平均交并比(mean Intersection over Union, mIoU)。
实现细节
为处理视频时长的巨大差异,对每个视频随机采样 T T T个连续片段:在THUMOS14上 T T T设为1000,在ActivityNet1.2上 T T T设为400。采用TV-L1算法从RGB数据中提取光流。
- CBP分支:以Transformer架构(多头自注意力、层归一化、多层感知机)作为骨干网络;
- VLP分支:采用2层时序Transformer,在文本输入前后添加16个提示向量,均通过 N ( 0 , 0.01 ) N(0,0.01) N(0,0.01)初始化。CLIP的图像编码器与文本编码器均采用ViT-B/16。
框架使用Adam优化器,学习率设为 1 0 − 4 10^{-4} 10−4。所有超参数通过网格搜索确定:伪标签阈值 δ h = 0.3 \delta_h=0.3 δh=0.3、 δ l = 0.1 \delta_l=0.1 δl=0.1;推理阈值 θ c l s = 0.85 \theta_{cls}=0.85 θcls=0.85、 θ l o c = 0.45 \theta_{loc}=0.45 θloc=0.45;平衡系数 λ = 0.05 \lambda=0.05 λ=0.05;温度超参数 τ = 0.07 \tau=0.07 τ=0.07。
4.2 与当前最优方法的对比
本节在多个交并比(IoU)阈值下,与当前最优方法进行全面对比。
性能表现
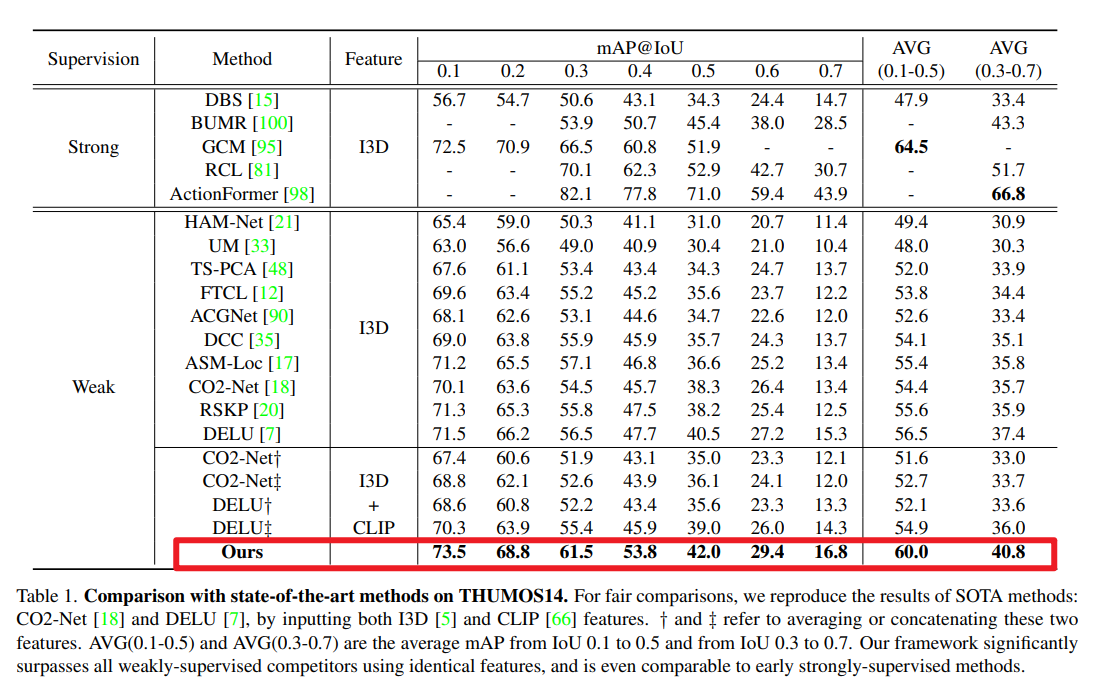
THUMOS14数据集的对比结果如表1所示。为更清晰地量化性能,我们将监督方式分为强监督(strong)和弱监督(weak)两类。总体而言,本文框架在所有IoU区间内均实现了新的最优性能(state-of-the-art)。与最新方法相比,平均mAP(IoU 0.3-0.7)的增益甚至达到4%-5%,进一步缩小了弱监督与强监督之间的性能差距。此外,本文方法在严格与宽松评估场景下均取得了显著提升。例如,与DELU[7]相比,平均mAP(IoU 0.1-0.5)提升3.5%,平均mAP(IoU 0.3-0.7)提升3.4%,这表明本文结果兼具完整性与精准性。值得注意的是,尽管采用弱监督设置,在部分低IoU阈值下,本文框架的性能已可与早期强监督方法[14,15,101]相媲美。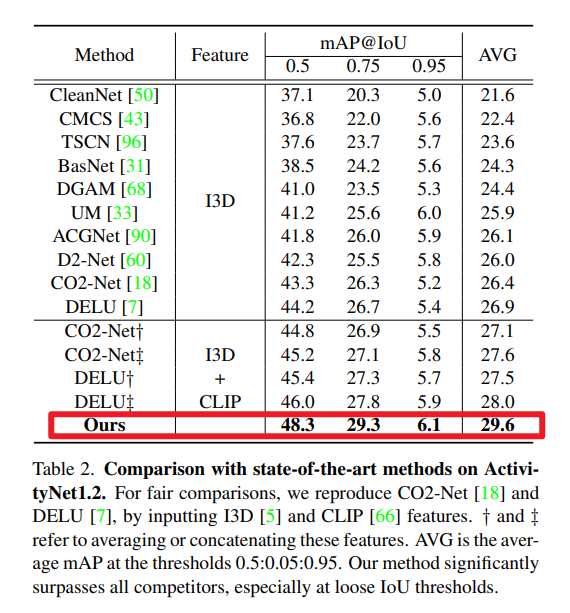
表2展示了ActivityNet1.2数据集的对比结果。在所有IoU阈值下,本文设计的框架均大幅超越现有方法。在平均mAP指标上,性能提升达2.7%,将当前最优水平推向新高度。然而,由于缺乏精准的位置标注,随着IoU阈值的严格化,性能增益会逐渐下降——例如,与DELU[7]相比,IoU 0.5时增益为4.1%,而IoU 0.95时增益仅为0.7%。
性能增益来源
与现有方法不同,本文利用视觉-语言预训练(VLP)获取免费知识。为保证对比的公平性,我们将I3D和CLIP[66]特征通过一种早期融合方式(对两种特征进行平均或拼接)输入到两种当前最优方法[7,18]中。结果显示,在两个数据集上,简单加入CLIP特征仅能带来微小增益,甚至会导致性能下降——这源于CLIP存在的严重过完整问题(详见表3)。对于动作复杂且出现频繁的THUMOS数据集,过完整问题会加剧定位误差;而在ActivityNet数据集中,多数视频仅包含单个动作,且动作区域占视频时长的一半以上,因此能从过完整特性中获得少量收益。尽管如此,在使用相同特征的前提下,本文方法仍显著优于现有竞争方法,充分证明了所提框架的有效性。
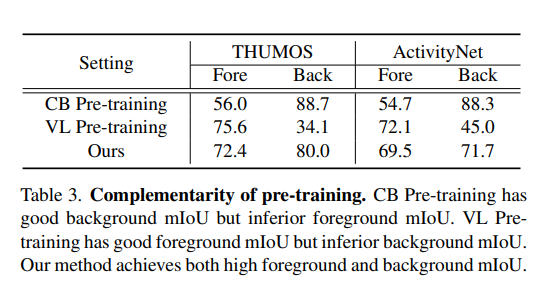
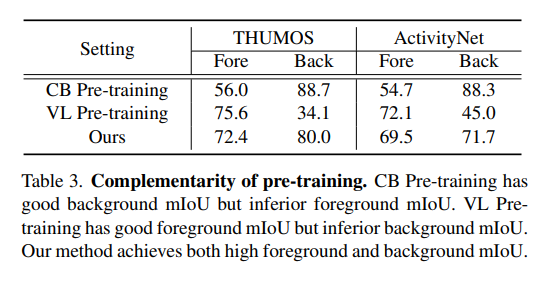
表3(预训练的互补性)显示:基于分类的预训练(CBP)具有优异的背景mIoU,但前景mIoU表现较差;而视觉-语言预训练(VLP)的前景mIoU表现优异,但背景mIoU较差;本文方法则同时实现了高前景mIoU与高背景mIoU。
4.3 消融实验与对比分析
本节通过评估各组件与框架设计的贡献,进一步剖析本文框架的工作机制。
预训练的互补性
定位性能主要由伪标签质量决定,因此本节通过前景mIoU与背景mIoU指标,评估伪标签的质量。表3给出了两种基准数据集上不同设置的完整结果。
对于传统的基于分类的预训练(CBP),其定位结果存在严重的不完整问题:具体表现为背景mIoU优异(即真阴性率高),但前景mIoU较差(即假阴性率高)。核心原因在于,在动作分类数据集上预训练的特征仅会突出稀疏的判别性帧。而视觉-语言预训练(VLP)的结果则恰好相反:存在严重的过完整问题,前景mIoU优异(即真阳性率高),但背景mIoU较差(即假阳性率高)。这主要是因为基于图像-文本对训练的VLP缺乏时序先验知识。上述结果充分证明了两种预训练方式的互补性。
优化策略对比
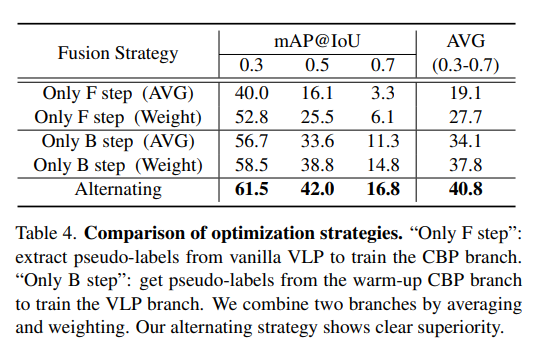
为评估交替策略的有效性,表4对比了另外两种优化方案:(1)“仅F步骤”(Only F step):从原始VLP中提取伪标签,用于训练CBP分支;(2)“仅B步骤”(Only B step):从预热后的CBP分支中提取伪标签,用于训练VLP分支。对于每种方案,我们分别采用平均和加权两种方式融合双分支结果。
“仅F步骤”的性能最差,主要因原始VLP伪标签中存在大量噪声(过完整问题);通过预热后的CBP分支提供的背景帧对原始VLP进行微调,“仅B步骤”的性能得到显著提升,但仍无法充分融合互补信息。此外,加权操作能在一定程度上抑制噪声,因此性能优于平均操作。相比之下,本文提出的交替策略展现出明显优势,证明了融合互补信息的非平凡性(non-trivial nature),以及对伪标签噪声的强鲁棒性。
各损失函数的贡献
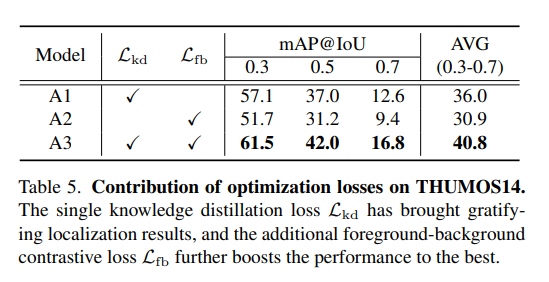
本文方法的训练同时采用知识蒸馏损失 L k d \mathcal{L}_{kd} Lkd与前景-背景对比损失 L f b \mathcal{L}_{fb} Lfb。表5(THUMOS14数据集上各优化损失的贡献)分析了这些损失函数的有效性:仅使用 L k d \mathcal{L}_{kd} Lkd的模型A1已能取得令人满意的性能,这表明通过交替优化,从双分支中提取的前景与背景置信伪标签得到了有效融合;另一方面,仅使用 L f b \mathcal{L}_{fb} Lfb的模型A2也能取得尚可的结果,因为 L f b \mathcal{L}_{fb} Lfb能区分前景与背景特征,从而排除大量不确定帧,降低定位任务的难度。总体而言,两种损失函数共同作用实现了最优性能,证明二者均不可或缺。
框架泛化性
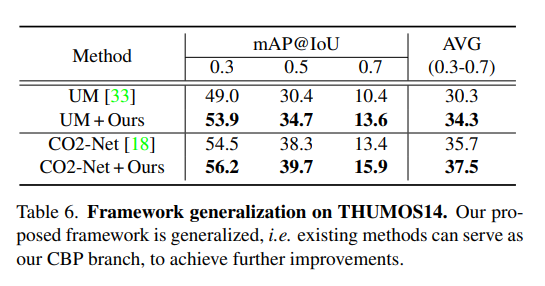
本文提出的蒸馏-协作框架具有良好的泛化性——即现有弱监督时序动作定位(WTAL)方法均可作为框架的CBP分支。表6以两种典型方法(CO2-Net[18]和UM[33])为例进行验证:本文框架能将它们的平均mAP进一步提升2%-4%,证明框架对其他方法及不同骨干网络设计均具有良好的泛化能力。
4.4 定性结果

图3:前两行分别为视频及动作区间真值;后六行依次为帧级别动作概率,以及基于分类的预训练(CBP)、视觉-语言预训练(VLP)与本文框架的定位结果。CBP存在不完整问题,VLP存在过完整问题;本文框架从VLP提取前景知识、从CBP提取背景知识,形成协同优化的性能优异整体,从而输出更完整、更精准的结果。
为直观展示本文方法的优越性,图3对不同类型视频的结果进行了可视化。基于分类的预训练(CBP)仅能突出部分判别性动作帧(存在不完整问题),这种现象在包含低频率动作的视频中更为明显;相反,视觉-语言预训练(VLP)往往会将动作前景过度激活至背景区域(存在过完整问题),在包含高频率动作的视频中该问题尤为突出。
本文设计的蒸馏-协作框架旨在融合两种预训练方式的互补性:在B步骤中,从训练成熟的CBP分支提取大量置信背景,用于监督VLP分支以抑制假阳性;在F步骤中,从VLP分支提取充足的置信前景信息,用于指导CBP分支以消除假阴性。因此,通过协同优化,本文方法形成了性能优异的整体,无论视频中动作密集还是稀疏,均能输出精准且完整的检测结果。
5 结论
本文提出一种新颖的蒸馏-协作框架,旨在从视觉-语言预训练(VLP)中提取免费知识,用于弱监督时序动作定位(WTAL)。本文的核心见解在于:现有VLP的动作定位结果往往存在过完整问题,而这一特性恰好与传统基于分类的预训练(CBP)的不完整结果形成互补。为形成性能优异的整体,我们设计了包含双互补分支的框架,并通过交替优化策略进行训练:从CBP分支提取置信背景伪标签,从VLP分支提取置信前景伪标签,用于协同训练。大量实验验证了从VLP中提取知识的重要性,以及本文方法的卓越性能;同时,通过全面的消融研究,从定量与定性维度深入分析了方法的有效性。
思考
动机1:现成的基于分类的预训练(CBP)方式生成视频特征,以实现动作定位。然而,分类与定位任务的优化目标存在差异,这使得时序定位结果面临严重的不完整问题。
(也就是,分类任务,专注于找到视频中最显著的片段,而定位任务需要找到视频中符合目标的一个完整区间,比如,踢球的动作,分类任务可能专注于与球接触的片段,而定位任务则需要有一个完整的抬腿、踢球等连续的片段)
动机2:通过视觉-语言预训练(VLP)中挖掘免费的动作知识,经过实验发现,CBP存在定位不完整的问题(即存在将前景判断为背景),VLP存在定位过完整的问题(即存在将背景判断为前景)。
我最近也在思考类似这种多模态的方式的做法,或许这个动机是一个不错的切入点。论文的的核心做法就是,把CBP分支的高置信度背景片段作为VLP分支的伪标签,以减少VLP分支的过完整问题;把VLP分支的高置信度前景片段作为CBP分支的伪标签,以减少CBP分支的不完整问题。此外,将两个分支中高置信度的前景片段特征作为正样本,高置信度的背景片段特征作为负样本,进行对比学习。
可学习的点:一个是两张方式分别存在的不完整和过完整问题,以及如何协同互补解决;一个是用高置信度片段特征用以对比学习。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)