【AI】十行代码让AI“长出身体“:魔珐星云3D数字人完整实战
本文介绍了如何将魔珐星云SDK集成到Vue项目中,实现3D数字人与GPT流式对话的完整方案。作者首先对比了市面上数字人方案的优缺点,选择魔珐星云作为具身智能解决方案。文章详细展示了平台配置流程、SDK核心功能,并提供了Vue项目中的代码实现,包括数字人初始化、GPT流式交互等关键模块。该方案具有低延时、高并发、低成本等特点,可快速为AI应用添加逼真的3D数字人交互体验。
从平台配置到Vue项目集成,从GPT流式对话到数字人实时表达
最近在做一个AI陪伴项目,需要给用户提供一个有形象、能表达的智能助手。调研了一圈市面上的数字人方案后发现,要么需要自己搭GPU服务器(成本顶不住),要么就是2D卡通形象(用户反馈太假)。
直到发现魔珐星云这个平台,真的被惊艳到了。这篇文章记录我从零开始接入魔珐星云SDK,并对接GPT实现流式对话的完整过程,包括平台配置、SDK集成、核心代码实现以及踩过的所有坑。
一、为什么选择魔珐星云
打开魔珐星云官网(https://xingyun3d.com/?utm_campaign=daily&utm_source=jixinghuiKoc21),首页就直接点明了核心定位:“让AI从’有大脑’升级到’有身体’”。
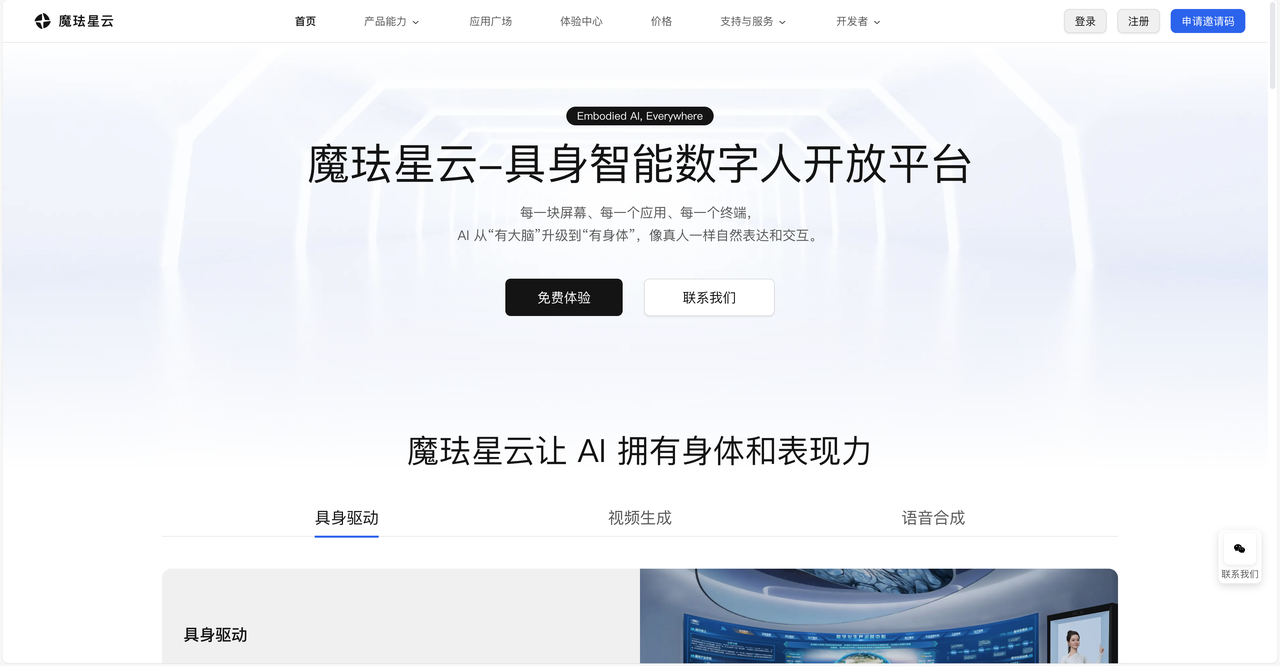
这个slogan一语中正我的需求痛点。大模型已经给了AI强大的"大脑",但在实际应用中,用户需要的不只是文字或语音回复,而是一个会微笑、会点头、能做手势的数字人。
官网列出了三大核心能力:具身驱动、视频生成、语音合成。我需要的正是具身驱动能力。
1.1 具身驱动到底是什么
往下滚动页面,看到更详细的能力介绍:
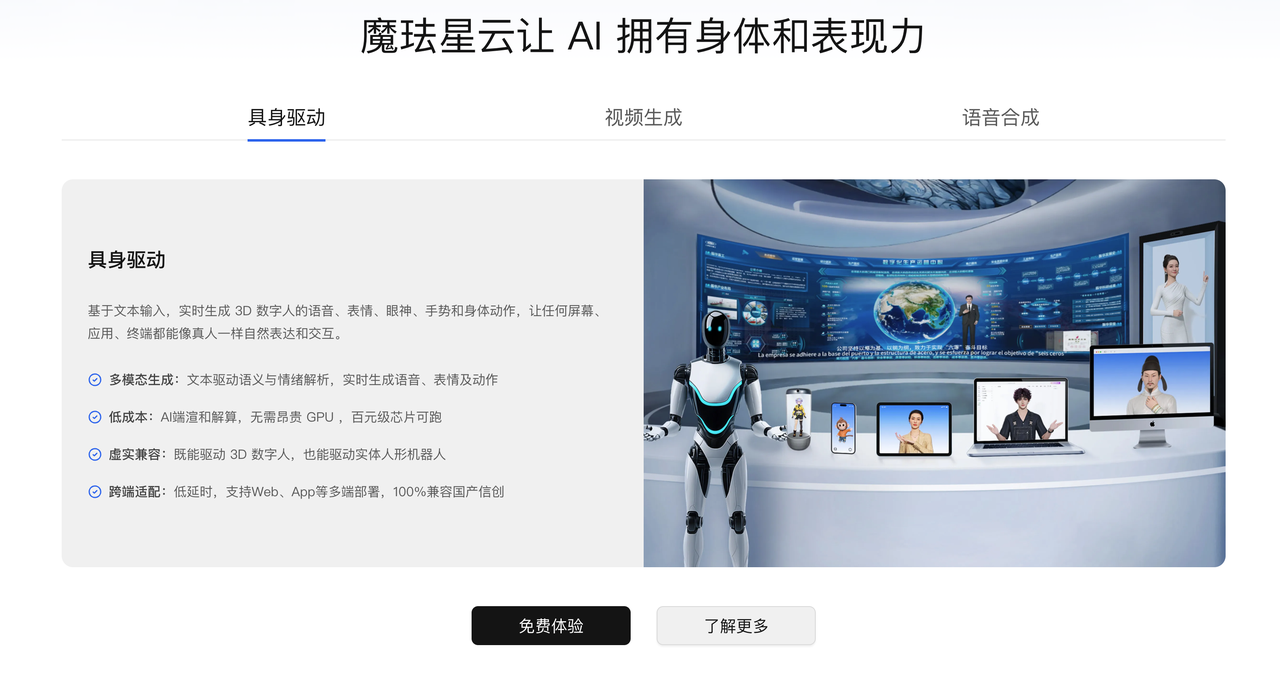
核心原理:基于文本输入,实时生成3D数字人的语音、表情、眼神、手势和身体动作。不是简单的TTS(文字转语音),而是真正的"多模态生成"——文本驱动语义与情绪解析,一次性生成语音、表情、动作。
关键技术特点:
- 多模态生成:不需要分别调用TTS、表情生成、动作生成,一个接口搞定
- 低成本部署:无需GPU,百元级芯片可运行
- 虚实兼容:既能驱动3D数字人,也能驱动实体人形机器人
- 跨端适配:支持Web、App等多端部署,100%兼容国产信创
1.2 六大核心特点
继续往下看,魔珐星云总结了支撑具身智能3D数字人规模化落地的六大能力:
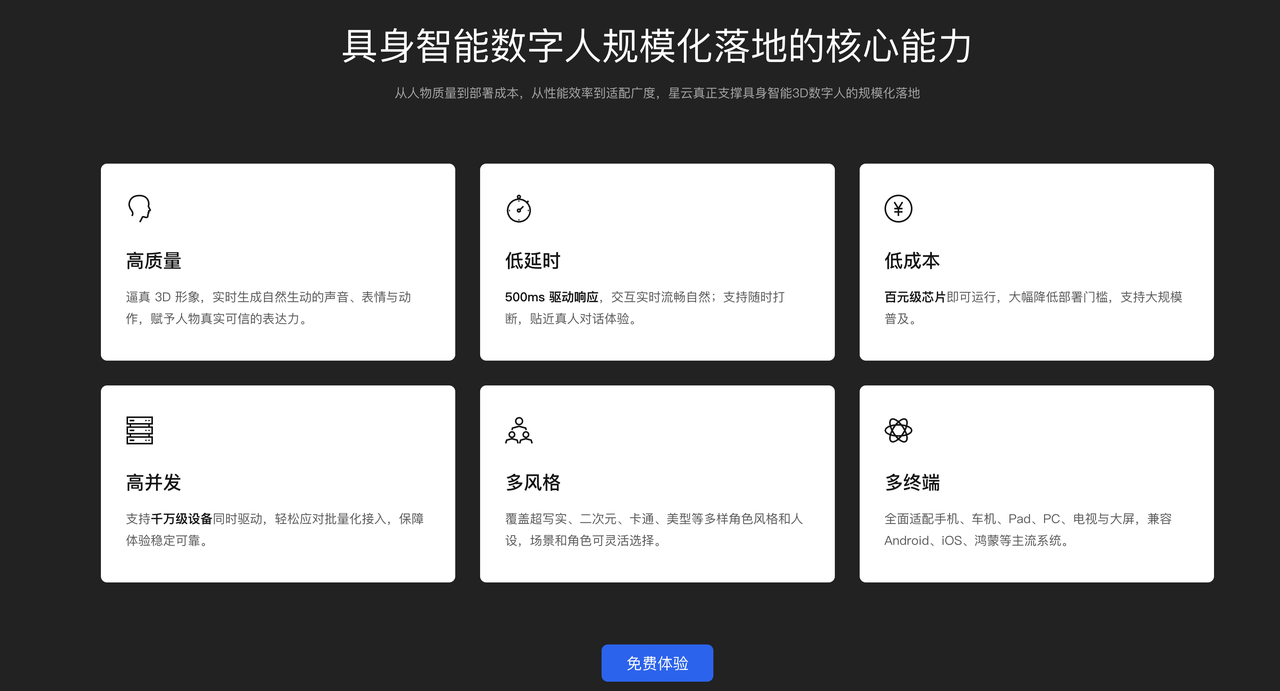
从官网截图可以看到:
高质量 - 逼真3D形象,实时生成自然生动的声音、表情与动作,赋予人物真实可信的表达力
低延时 - 500ms驱动响应,交互实时流畅自然,支持随时打断,贴近真人对话体验
低成本 - 百元级芯片即可运行,大幅降低部署门槛,支持大规模普及
高并发 - 支持千万级设备同时驱动,轻松应对批量化接入,保障体验稳定可靠
多风格 - 覆盖超写实、二次元、卡通、美型等多样角色风格和人设,场景和角色可灵活选择
多终端 - 全面适配手机、车机、Pad、PC、电视与大屏,兼容Android、iOS、鸿蒙等主流系统
这六点完全解决了我在调研阶段遇到的所有痛点。决定深入试试。
二、在线体验:先看看效果
在正式接入前,魔珐星云提供了在线体验中心,可以直接感受数字人的驱动效果。
点击顶部导航的"体验中心",进入后可以看到一个3D数字人实时渲染在浏览器中:
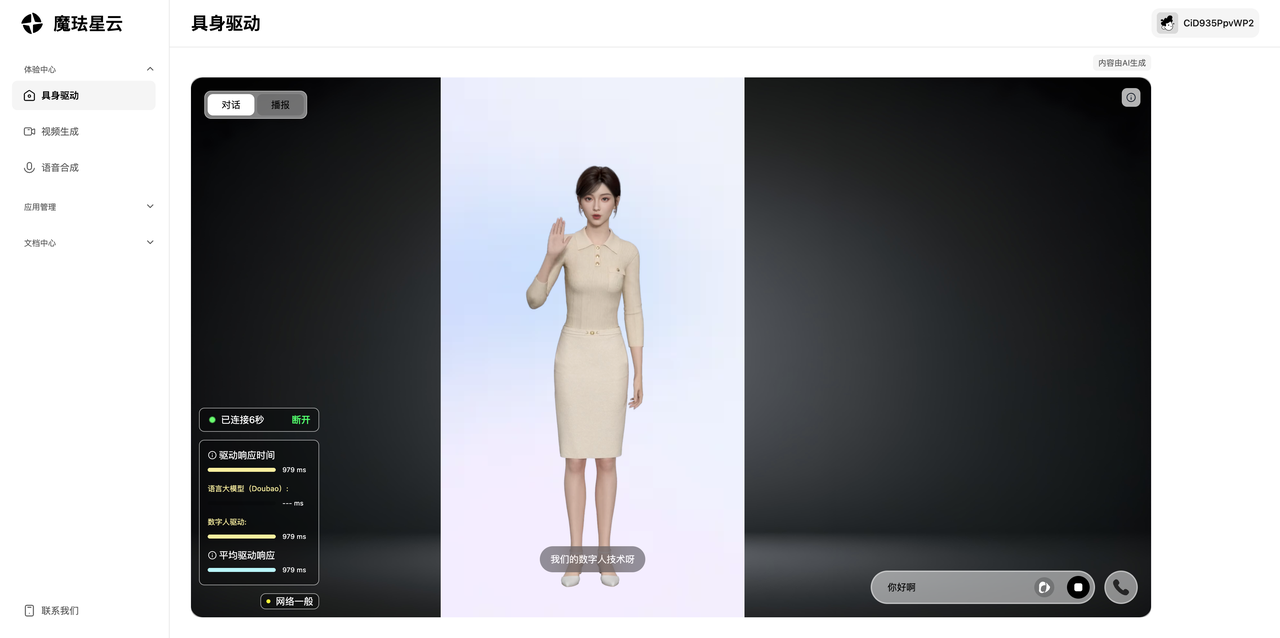
这个页面非常直观,左侧是3D数字人,右侧显示驱动响应时间。从截图可以看到,平台对接了豆包大模型,整体驱动响应时间在979ms左右。
实际体验下来,对话非常流畅,数字人的表情、口型、手势都很自然。体验完在线demo后,确认效果符合预期,开始准备正式接入。
三、创建驱动应用:平台配置全流程
3.1 注册登录
访问 https://xingyun3d.com/?utm_campaign=daily&utm_source=jixinghuiKoc21 注册账号(支持手机号或邮箱注册)。登录后进入控制台,点击"创建驱动应用"。
3.2 配置数字人形象
进入创建页面后,可以看到完整的可视化配置界面:
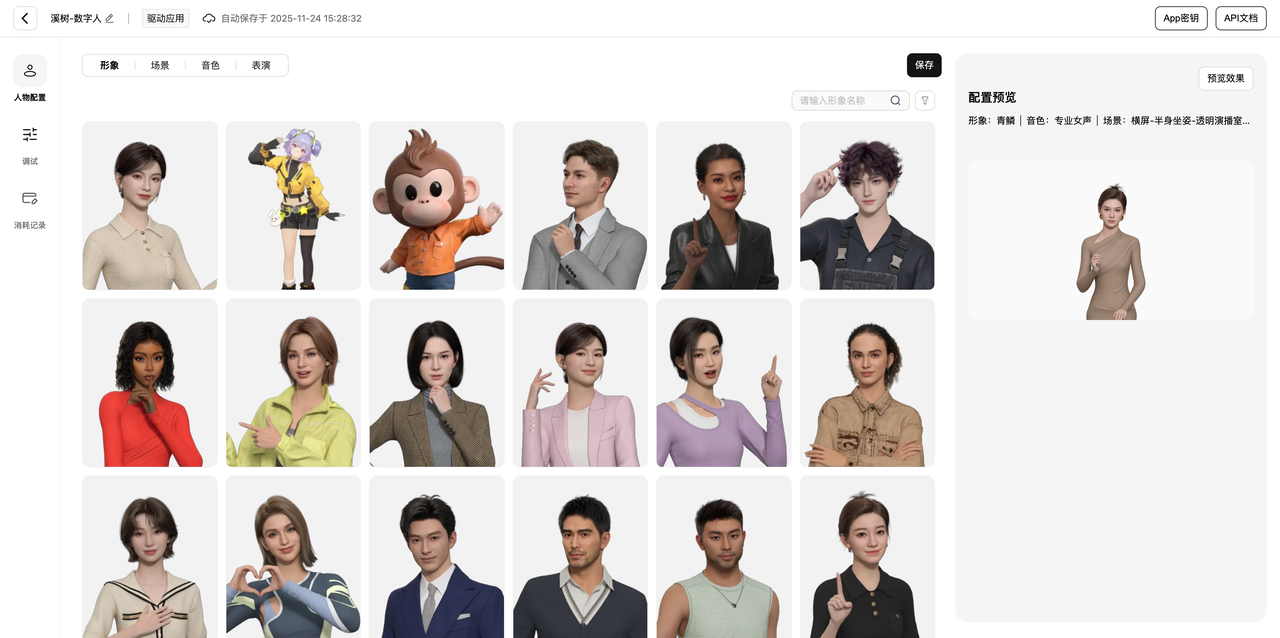
配置项包括四个核心部分:
形象选择 - 我选的是"青婳"(超写实女性形象),平台提供了多种风格的预置角色,包括超写实、二次元、卡通等风格。
场景选择 - 选择"横屏-半身坐姿-透明演播室"。场景会影响数字人的显示范围和背景,透明背景方便后期自定义UI。
音色配置 - 选择"专业女声"。平台提供了多种音色,包括温柔型、知性型、活泼型等。
表演风格 - 这个选项控制数字人的动作幅度和表情丰富度。专业型动作幅度较小,适合严肃场景;活泼型表情丰富,适合互动场景。
右侧实时预览区域可以看到配置效果。调整完成后点击保存,系统会生成两个关键凭证:
- App ID:应用唯一标识
- App Secret:应用密钥
这两个凭证在后续SDK初始化时会用到,记得保存好。
四、SDK文档查看
配置完应用后,需要了解SDK的接入方式。点击顶部导航的"开发者",进入SDK文档页面:
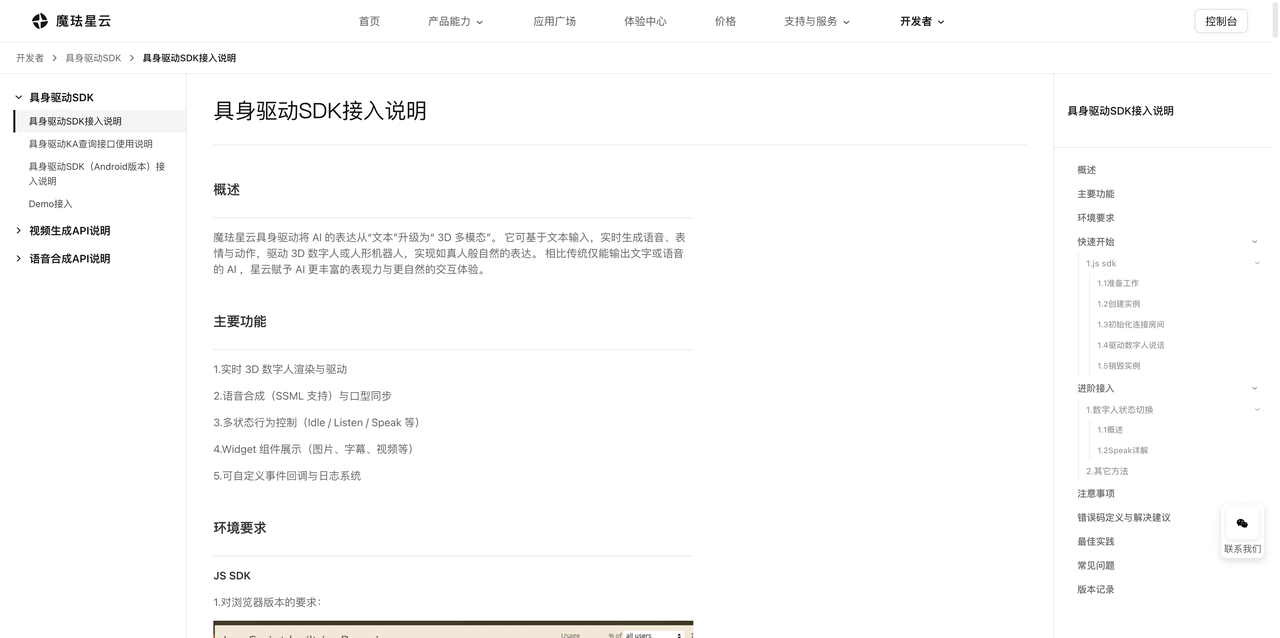
文档页面结构很清晰,左侧是导航目录,右侧是详细说明。核心内容包括:
概述 - 魔珐星云具身驱动将AI的表达从"文本"升级为"3D多模态",可基于文本输入实时生成语音、表情与动作。
主要功能:
- 实时3D数字人渲染与驱动
- 语音合成(SSML支持)与口型同步
- 多状态行为控制(Idle / Listen / Speak等)
- Widget组件(展示图片、字幕、视频等)
- 可自定义事件回调与日志系统
环境要求 - 对浏览器版本有要求,需要支持WebGL 2.0。主流浏览器(Chrome 79+, Safari 14+)都没问题。
浏览完文档后,对SDK的使用方式有了清晰的认识,开始正式编码。
五、Vue项目实战:核心代码实现
5.1 项目初始化
创建一个新的Vue 3项目:
npm create vite@latest xingyun-gpt-demo -- --template vue
cd xingyun-gpt-demo
npm install
5.2 引入SDK
在 index.html 中通过CDN引入SDK:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>魔珐星云 × GPT 智能数字人</title>
</head>
<body>
<div id="app"></div>
<!-- 引入魔珐星云SDK -->
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
<script type="module" src="/src/main.js"></script>
</body>
</html>
5.3 封装魔珐星云SDK
创建 src/composables/useXingyunAvatar.js:
import { ref, onUnmounted } from 'vue'
export function useXingyunAvatar() {
const avatar = ref(null)
const isInitialized = ref(false)
const isSpeaking = ref(false)
const config = {
appId: 'your-app-id-here',
appSecret: 'your-app-secret-here',
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session'
}
const init = async (containerId) => {
avatar.value = new window.XmovAvatar({
containerId,
...config,
onVoiceStateChange(status) {
isSpeaking.value = (status === 'start')
}
})
await avatar.value.init()
isInitialized.value = true
}
const speak = (text, isStart, isEnd) => {
avatar.value?.speak(text, isStart, isEnd)
}
const listen = () => avatar.value?.listen()
const think = () => avatar.value?.think()
const interactiveIdle = () => avatar.value?.interactiveidle()
onUnmounted(() => avatar.value?.destroy())
return { isInitialized, isSpeaking, init, speak, listen, think, interactiveIdle }
}
5.4 封装GPT流式API
创建 src/composables/useGPT.js:
import { ref } from 'vue'
export function useGPT() {
const isGenerating = ref(false)
const streamChat = async (userMessage, onChunk, onComplete) => {
isGenerating.value = true
const response = await fetch('https://api.voct.top/v1/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer your-api-key-here'
},
body: JSON.stringify({
model: 'gpt-4.1-mini',
messages: [
{ role: 'system', content: '你是一个友好的AI助手,回答控制在100字以内。' },
{ role: 'user', content: userMessage }
],
stream: true
})
})
const reader = response.body.getReader()
const decoder = new TextDecoder()
let buffer = ''
let fullText = ''
while (true) {
const { done, value } = await reader.read()
if (done) break
buffer += decoder.decode(value, { stream: true })
const lines = buffer.split('\n')
buffer = lines.pop() || ''
for (const line of lines) {
if (line.startsWith('data: ') && line !== 'data: [DONE]') {
const data = JSON.parse(line.slice(6))
const content = data.choices?.[0]?.delta?.content
if (content) {
fullText += content
onChunk(content, fullText)
}
}
}
}
isGenerating.value = false
onComplete(fullText)
}
return { isGenerating, streamChat }
}
5.5 主组件核心逻辑
src/App.vue 中的关键代码:
// 流式调用GPT并驱动数字人说话
const streamChatWithAvatar = async (userMessage) => {
let chunkBuffer = ''
let isFirstChunk = true
const CHUNK_SIZE = 10
listen()
setTimeout(() => think(), 500)
await streamChat(
userMessage,
(chunk) => {
chunkBuffer += chunk
if (chunkBuffer.length >= CHUNK_SIZE) {
speak(chunkBuffer, isFirstChunk, false)
chunkBuffer = ''
isFirstChunk = false
}
},
(finalText) => {
if (chunkBuffer.length > 0) {
speak(chunkBuffer, isFirstChunk, true)
} else if (!isFirstChunk) {
speak('', false, true)
}
setTimeout(() => {
if (!isSpeaking.value) {
interactiveIdle()
}
}, 1000)
}
)
}
核心要点:
- 积累10个字符后发送给数字人(避免调用过于频繁)
- 第一次调用
speak(text, true, false) - 中间调用
speak(text, false, false) - 最后调用
speak(text, false, true) - 说话完成后必须调用
interactiveIdle()切换状态
5.6 运行效果
启动项目:
npm run dev
访问 http://localhost:3000,可以看到初始界面:
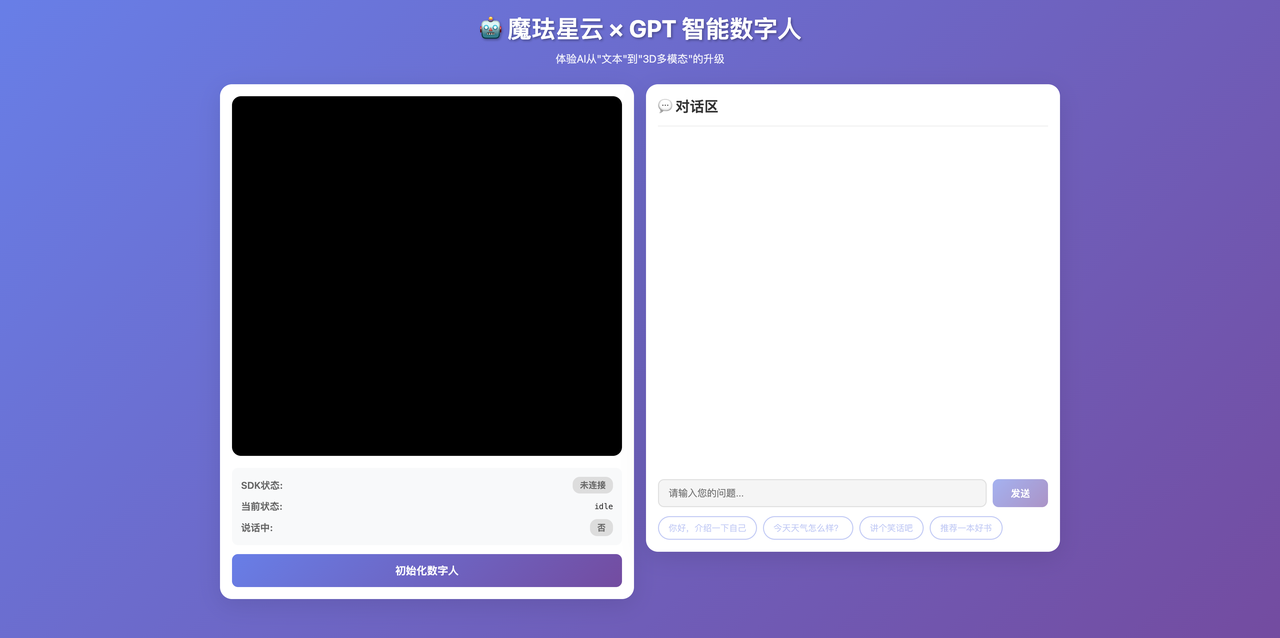
从截图可以看到,左侧是数字人容器区域(黑色背景,等待初始化),右侧是对话区域。状态面板显示"SDK状态:未连接",“当前状态:idle”,“说话中:否”。
点击"初始化数字人"按钮后,SDK开始加载资源。等待几秒后,数字人渲染完成:
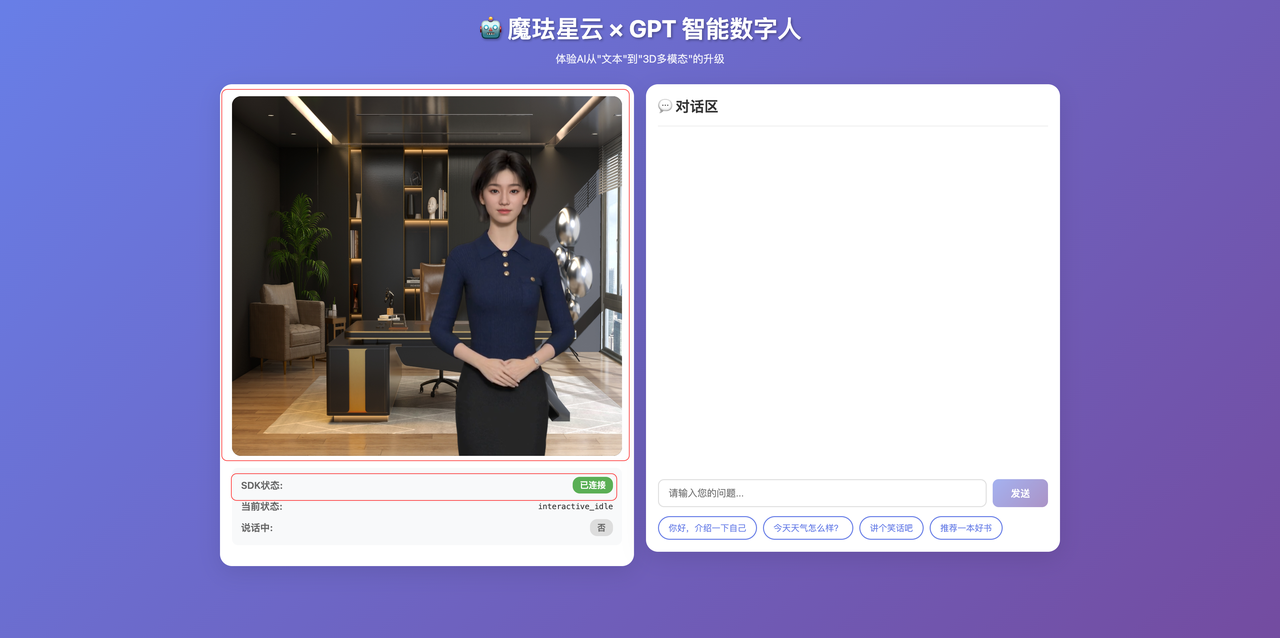
从界面可以看到,3D数字人已经渲染在容器中,状态面板显示"当前状态:interactive_idle"。这个状态表示数字人已经准备好,可以开始交互。
在对话区输入"你好,介绍一下自己",点击发送。可以观察到完整的交互流程:
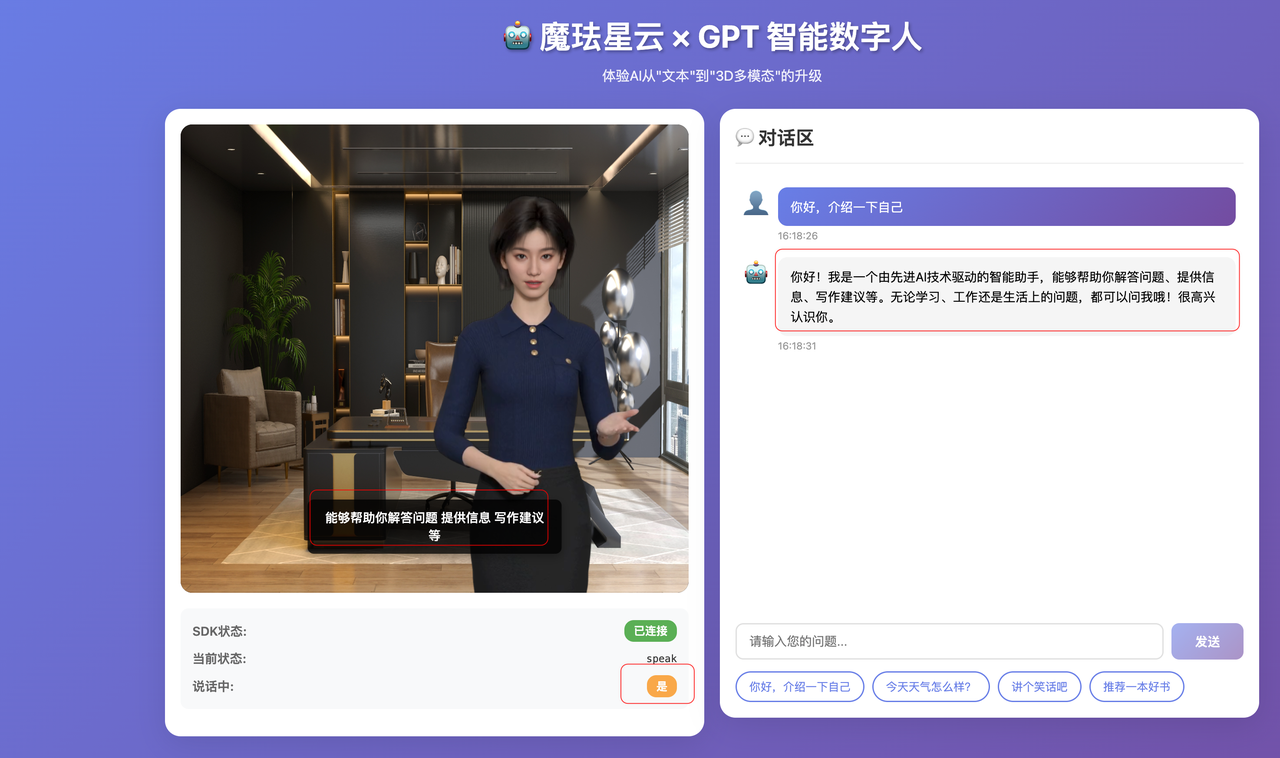
从截图可以看到,数字人正在说话(当前状态:speak),右侧对话区实时显示GPT生成的内容。整个响应流程非常流畅:用户输入 → 数字人切换到倾听状态 → 短暂思考 → GPT开始流式生成 → 数字人边生成边说话 → 说完后回到待机状态。
六、核心技术特点验证
通过完整的项目开发,我验证了魔珐星云官网宣传的六大特点确实可以实现:
高质量 - 3D数字人在浏览器中实时渲染,表情、口型、动作都能同步。从实际效果看,确实达到了较高的视觉质量。
低延时 - 官方说的500ms驱动响应,在实际使用中感受不到明显卡顿。支持随时打断,调用 interactiveIdle() 可以立即停止数字人说话。
低成本 - 这是最大的亮点。SDK在客户端渲染(WebGL),不需要GPU服务器。服务端只负责驱动数据,流量很小。官方说百元级芯片(RK3566、RK3588)都能跑。
高并发 - 官方说支持千万级设备同时驱动。因为渲染在客户端,服务端压力相对较小。
多风格 - 平台提供了10+种预置角色,包括超写实、二次元、卡通等风格,音色也很丰富。
多终端 - SDK支持Chrome、Safari、Edge等主流浏览器,也支持微信浏览器。需要注意的是,SDK要求HTTPS或localhost环境。
七、可能的应用场景
根据魔珐星云的技术特点,以下几个场景值得探索:
7.1 AI陪伴类应用
做一个AI男友/女友App,用户可以聊天、倾诉。传统方案只有文字或语音对话,而魔珐星云可以提供3D数字人 + 大模型对话,会做表情、手势,甚至可以通过SSML标记控制特定动作,增强情感连接。
7.2 虚拟偶像 / 游戏NPC
让虚拟IP"活"起来,能和粉丝真正互动。游戏NPC接入大模型,实现动态对话而不是固定脚本。虚拟偶像自动驱动,能唱能跳能聊天。支持KA技能动作(跳舞、比心、挥手)。
7.3 企业数字员工
银行、医院、政务大厅等场景需要智能导办。部署在业务大屏上,24/7不间断服务,主动问候、手势引导,对接业务系统查询办事进度、推荐业务。相比传统触摸屏,数字人形式更加亲和,降低使用门槛。
八、踩坑记录
开发过程中踩了几个坑,记录一下:
8.1 HTTPS要求
SDK需要HTTPS或localhost环境,用IP地址访问会报错。开发环境用localhost,生产环境必须上HTTPS。
8.2 容器尺寸
数字人容器必须有明确的宽高,否则渲染异常。
<!-- 正确 -->
<div id="avatar" style="width: 400px; height: 600px;"></div>
8.3 speak连续调用
不能在上一次 speak 结束(is_end=true)后立即再次调用。必须中间调用一次 interactiveIdle() 或 listen():
avatar.speak("第一句话", true, true)
avatar.interactiveIdle()
setTimeout(() => {
avatar.speak("第二句话", true, true)
}, 100)
8.4 onVoiceStateChange回调
这个回调非常重要,用来判断数字人是否说完话:
onVoiceStateChange(status) {
if (status === 'end') {
// 说话结束,可以切换状态
}
}
九、总结
整个项目从调研到完成开发,用了大概两天时间。魔珐星云给我最大的感受是接入门槛真的低,十行代码就能跑起来,不需要GPU服务器,性能还很强。从产品角度看,六大核心特点都在实际开发中得到了验证,500ms低延时、百元芯片可跑、多终端适配,这些都不是PPT上的噱头。对于想做具身智能应用的开发者来说,魔珐星云是目前我见过的最完整、最易用的方案,真正把"给AI装上身体"这件事变得和"调用一个API"一样简单。
相关资源
官网地址:https://xingyun3d.com/?utm_campaign=daily&utm_source=jixinghuiKoc21
开发文档:https://xingyun3d.com/developers/52-183
如果你也想体验具身智能数字人,可以通过下面的专属链接注册,享受新人福利:
👉 https://xingyun3d.com/?utm_campaign=daily&utm_source=jixinghuiKoc21

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)