Supporting Our AI Overlords:Redesigning Data Systems to be Agent-First
大语言模型(LLM)代理能够代表用户操作和分析数据,这很可能成为未来数据系统的主流工作负载。在处理数据时,代理会采用一种高吞吐量的探索和方案制定过程来完成既定任务,我们将这种过程称为代理推测(agentic speculation)。代理推测的巨大体量和低效性可能会给当今的数据系统带来挑战。我们认为,数据系统需要进行调整,以更原生得支持代理工作负载。利用我们所识别出的代理推测的特征——即。
(个人论文阅读记录,新手,2025年大四,仅仅为记录,错了我会改正)
支持我们的 AI 主宰:
将数据系统重构为“代理优先(Agent-First)”架构
作者: Shu Liu, Soujanya Ponnapalli, Shreya Shankar, Sepanta Zeighami, Alan Zhu, Shubham Agarwal, Ruiqi Chen, Samion Suwito, Shuo Yuan, Ion Stoica, Matei Zaharia, Alvin Cheung, Natacha Crooks, Joseph E. Gonzalez, Aditya G. Parameswaran
所属机构: 加州大学伯克利分校 (UC Berkeley)
摘要:
大语言模型(LLM)代理能够代表用户操作和分析数据,这很可能成为未来数据系统的主流工作负载。在处理数据时,代理会采用一种高吞吐量的探索和方案制定过程来完成既定任务,我们将这种过程称为代理推测(agentic speculation)。代理推测的巨大体量和低效性可能会给当今的数据系统带来挑战。我们认为,数据系统需要进行调整,以更原生得支持代理工作负载。利用我们所识别出的代理推测的特征——即规模性(scale)、异构性(heterogeneity)、冗余性(redundancy)和可引导性(steerability)——我们勾勒了一系列新的研究机会,旨在构建一种新的“代理优先”数据系统架构,涵盖从新的查询接口、新的查询处理技术到新的代理存储器等各个方面。
1.引言(介绍)
在大语言模型(LLM)的驱动下,现在的 AI 能够推理、调用工具、编写代码并相互通信。我们正处于一场新的代理革命的边缘,这将改变数据系统的使用方式。现代 LLM 的内部效率远超以往,其能力已匹敌一年前规模大几个数量级的模型,并且在理解和操作结构化及非结构化数据方面变得越来越高效。随着它们变得既廉价又强大,未来的 LLM 代理将代表用户行事:提取、分析、转换和更新数据——这有可能成为数据系统的主流工作负载。
虽然 LLM 代理可能在推理能力上匹敌人类,但它们不具备接地性(grounding)——即对底层数据及其存储系统特性的感知。然而,它们可以通过不知疲倦地尝试给定数据转换任务的各种可能解决方案来弥补这种感知的缺失,其程度远超任何人类能够或愿意做的。单个 LLM 代理理论上每秒可以发出成百上千个请求,这个速率还会随着 LLM 代理数量的增加而扩展。这些请求中有许多并不是为了直接得出最终方案,而是作为元数据发现(例如,表结构、列统计信息)探索过程的一部分,并伴随着部分解决方案和验证。我们将这种发现与方案制定的结合称为代理推测(agentic speculation)——即高吞吐量、探索性的查询,旨在确定最佳行动方案。
代理推测代表了与当今数据系统工作负载的实质性背离。当今的工作负载要么更加间歇性(例如,来自人类或代表人类操作的工具),要么更加具有针对性(例如,来自终端用户应用程序)。设想有一群 LLM 代理,任务是找出为什么今年伯克利的咖啡豆销售利润低于去年。由于不受人类认知带宽和响应时间的限制,这群代理可能会对数据系统使用海量的查询,远超任何人类所能——而这仅仅是为了一个任务。其中许多查询可能是浪费的,仅仅是为了给代理提供“接地”感知。再举一个例子,如果一个 LLM 代理的任务是为延误的航班确定新的机组人员,它需要考虑各种假设的交易方案以呈现给人类决策者,每个方案都涉及对各种数据库的数十次更新。对于此类任务,代理可能会通过分叉(forking)数据库状态、运行推测性更新并回滚分支来并行探索许多替代方案。总体而言,随着代理工作负载变得越来越普遍,代理推测的巨大规模和低效性将成为瓶颈,我们的数据系统需要为此做出演进。
因此,我们要问:数据系统如何演进以更好地支持代理工作负载? 特别是,数据系统能否原生且高效地支持代理推测,帮助 LLM 代理确定最佳行动方案?这个问题——正如我们所论证的,我们的社区完全有能力回答——是释放代理作为我们与数据交互的主要机制所带来的难以想象的生产力收益的关键。
值得庆幸的是,虽然代理推测对数据系统构成了新的挑战,但其特征也为数据系统的重新设计提供了新的机会。正如我们将展示的,代理推测具有以下特征:
-
高吞吐量(High Throughput): 受益于向后端系统发出的大量请求(顺序和/或并行),以确定如何解决给定任务。(本质就是高并发,一个任务就可以发送大量的查询,针对不同的数据库表等等,不停的尝试试探。)
-
异构性(Heterogeneous): 涵盖粗粒度的数据和元数据探索、部分及完整的方案制定以及验证——允许 LLM 代理在早期阶段利用近似或不完整的输出取得进展。(本质就是说,代理的查询是阶段性的探索,一点点进行查询,通过试探,从最初的盲目探索到一点点精确定位信息和定位有效信息并验证制定解决方案)
-
冗余性(Redundancy): 许多请求可能访问相似的数据或执行重叠的操作,从而提供了共享计算或消除冗余工作的机会。(可能会产生大量的冗余查询)
-
可引导性(Steerable): 由于推测本质上是探索性的,如果我们超越传统的“提问-回答”范式,允许数据系统更直接地与 LLM 代理通信,这可以帮助将 LLM 的请求引导至最有希望的方向。(本质就是 数据库是否可以和代理智能体间进行对话)
-
规模性要求系统扛得住海量并发。
-
异构性要求系统懂得“看人下菜碟”(根据阶段提供不同精度的答案)。
-
冗余性要求系统善于“偷懒”(复用计算结果)。
-
可引导性要求系统学会“说话”(主动与代理沟通和反馈)。
在本文中,我们利用上述推测的特征——规模性、异构性、冗余性和可引导性,提出了围绕为代理重新设计数据系统的新研究愿景。在第 2 节中,我们将通过案例研究说明当今代理推测的特征。在第 3 节中,我们提出了一种代理优先的数据系统新架构。在第 4、5 和 6 节中,我们将分别确定在接口层、查询处理层和存储层的新研究机会。
2. 案例研究 (Case Studies)
在本节中,我们将通过两个案例研究来探讨代理工作负载的特征,并识别这些查询中存在的优化机会。虽然这些案例研究很简单,但它们更容易评估正确性。
(图 1: BIRD 数据集上的结果。展示了成功率随请求次数(K)和轮数(Turns)的增加而提高。)
我们在第一个研究中使用了 BIRD text2SQL 基准测试。我们要探索当今的 LLM 是否能从增加请求数量(并行或顺序)中受益。我们使用 DuckDB 作为后端,使用 GPT-4o-mini 和 Qwen2.5-Coder-7B-Instruct 作为两个 LLM。为了首先评估并行请求,我们模拟了一个“主管”LLM 代理的行为,它拥有若干个独立尝试任务的“前线”代理,随后由主管代理在相应的解决方案中挑选一个。我们在图 1a 中绘制了平均成功率与 LLM 尝试次数的关系。为了评估顺序请求,我们让单个 LLM 代理发出查询直到它满意为止,并在图 1b 中再次绘制了成功率与所采取步骤数的关系。我们发现:
代理推测——无论是顺序还是并行——都有助于提高准确性。
代理工作负载的成功率随着请求数量的增加而增加,在我们的案例研究中提高了 14%–70%。
(图 2: 在整个 BIRD 数据集上,GPT-4o-mini 每个问题生成的 50 次尝试中,总子表达式与唯一子表达式的数量对比。)
接下来,我们量化跨请求共享工作的可能性。我们将注意力集中在并行设置上,进行了 50 次独立尝试,并评估这些尝试之间的冗余度。在图 2a 中,我们绘制了针对给定任务生成的 50 个查询计划中,每种大小的子计划或子表达式的总数和不同(distinct)数量。图 2b 展示了按根操作符类型分组的类似图表。我们发现:
代理推测在请求之间具有显著的冗余性。
在所有查询中,每种大小的不同子计划的数量通常只占总数的不到 10-20%,这代表了共享计算的巨大潜力。
(图 3: 标记的代理活动热力图。代理首先探索表和列,然后制定查询,各阶段经常重叠。)
我们的第二个案例研究比 text2SQL 更复杂,有助于我们研究代理推测的各个阶段。我们评估了一个数据代理的性能,该代理必须结合来自两个独立后端数据库的信息(选自 PostgreSQL, SQLite, MongoDB 和 DuckDB)。例如,一项任务涉及从 MongoDB 清洗客户信息,以便与 DuckDB 中的用户交互数据(如点赞)进行连接。因此,不可能一次性完成此任务,成功的尝试通常涉及与两个后端交互,随后在 Python 中进行一些计算。我们收集了 OpenAI 的 o3 模型尝试 22 个任务各两次的 44 个顺序轨迹,其中约一半得出了正确答案。然后,我们手动标记了 LLM 采取的每一个行动:探索元数据和样本数据(针对模式或使用 LIMIT)、探索列统计信息(不同值或聚合)、尝试部分查询或完整查询。正如我们在图 3 的聚合热力图中看到的,探索元数据和样本数据通常最先发生,其次是统计信息,之后出现后两个阶段。然而,这些阶段并没有明确的界限,每个阶段都贯穿于整个轨迹中。因此我们发现:
代理推测在其信息需求上具有异构性。
代理的请求在必要信息方面差异很大,从粗粒度的元数据和数据统计探索,到解决任务的部分或更完整的尝试。粗粒度的探索性请求通常发生在早期。
在下文中,我们将早期阶段描述为元数据探索(metadata exploration),将后期阶段描述为方案制定(solution formulation)。
接下来,我们想探索后端系统提供的“接地(grounding)”是否可以帮助减少达成解决方案所需的步骤数。因此,我们通过向提示(prompt)中注入“提示(hints)”来模拟这一点,其中提示提供了对任务有用的背景信息,例如哪一列包含与任务相关的信息。再次,我们收集了 44 个提供了提示的顺序轨迹,然后测量了提供提示与未提供提示时,跨尝试和任务所需的平均步骤数。如表 1 所示,提示的影响是巨大的。我们发现:
代理推测可以通过接地提示进行引导。
如果主动提供与任务相关的接地信息,推测轨迹的效率可以大大提高——根据阶段不同,查询量减少超过 20%。
基于我们通过案例研究收集到的特征,我们接下来提出一种代理优先的数据系统新架构。
为了让你更直观地理解这段话的含义,我们构想一个具体的场景。
场景设定:
假设有一个 AI 代理(Agent),它的任务是回答用户的一个问题:“请找出 2023 年在‘加州(California)’地区销售额最高的‘电子产品’类别是什么?”
数据库中可能有上百张表,列名也千奇百怪。
情况一:没有“接地(Grounding)”提示(Agent “盲猜”模式)
在这种情况下,代理就像一个刚入职且没人带的新员工,它对数据库一无所知,必须通过不断的试错来探索。
阶段 1:元数据探索(Metadata Exploration)—— 漫长且浪费
Agent: SHOW TABLES; (查看所有表名)
DB: 返回 200 张表的列表,包括 t_sales_2023, users, products, logs, config...
Agent: (猜测)“可能是 products 表。” -> SELECT * FROM products LIMIT 5;
DB: 返回数据,但发现里面只有 product_id,没有类别名称。
Agent: “那类别在哪?” -> SELECT * FROM categories LIMIT 5;
DB: 找到了类别名,但不知道怎么和销售表关联。
Agent: “销售数据在哪?试一下 t_sales_2023。” -> DESCRIBE t_sales_2023;
DB: 返回列名:uid, pid, sid, amt...
Agent: “sid 是什么?是 Store ID 还是 State ID?” -> SELECT DISTINCT sid FROM t_sales_2023 LIMIT 10;
DB: 返回 1, 2, 3... (看不出来是州还是商店)。
阶段 2:方案制定(Solution Formulation)—— 容易出错
6. Agent: 尝试写一个复杂的 SQL JOIN 查询,但因为不知道“加州”是用 'CA' 还是 'California' 还是 ID 6 来表示,第一次尝试失败。
7. Agent: 再次修正查询……
8. Agent: 最终得出结果。总结: 这一过程可能需要 8-10 个步骤,消耗大量 Token 和时间。
情况二:有“接地(Grounding)”提示(Agent “开卷考试”模式)
现在,我们引入论文中提到的**“后端系统主动提供提示”**。
当 Agent 收到任务时,具备“接地”能力的数据系统(或系统内的潜伏代理)会先分析任务意图,然后主动在 Prompt 中注入以下提示(Hints):
系统注入的提示 (Grounding Hint):
相关表: 销售数据在 t_sales_2023,产品信息在 dim_products,地区信息在 geo_locations。
关键列: t_sales_2023.amt 是销售额。
数据特征: “电子产品”对应的 category_id 是 105;“加州”在数据库中存储为缩写 'CA',对应 state_code 列。
阶段变化:
Agent: 收到任务 + 系统提示。
Agent: 因为已经知道表名、列名和特定值的写法('CA', 105),它跳过了元数据探索阶段,直接进入方案制定。
Agent: 直接写出正确的 SQL:
codeSQLSELECT p.product_name, SUM(s.amt) FROM t_sales_2023 s JOIN dim_products p ON s.pid = p.product_id JOIN geo_locations g ON s.geo_id = g.id WHERE g.state_code = 'CA' AND p.category_id = 105 GROUP BY p.product_name ORDER BY SUM(s.amt) DESC LIMIT 1;Agent: 任务完成。
总结: 这一过程可能只需要 1-2 个步骤。
对论文结论的解读
“元数据探索”被压缩了:
在情况二中,Agent 不需要花好几轮对话去问“表叫什么名字?”、“列是什么意思?”,因为系统直接把跟当前任务相关的元数据(Background Information)告诉它了。“方案制定”更精准了:
论文中提到“哪一列包含与任务相关的信息”。在例子中,系统告诉 Agent 用 state_code 且值为 'CA'。如果没有这个提示,Agent 可能会去 search 'California',从而导致查询失败或结果为空。“查询量减少超过 20%”:
在这个例子中,步骤从 ~8 步减少到 ~2 步,效率提升远超 20%。这正是论文想要表达的核心观点:通过让数据系统变得“主动”,告诉 Agent 数据的“地形图”(Grounding),可以极大地节省 Agent 的探索成本。
3. 代理优先的数据系统架构 (Agent-First Data System Architecture)
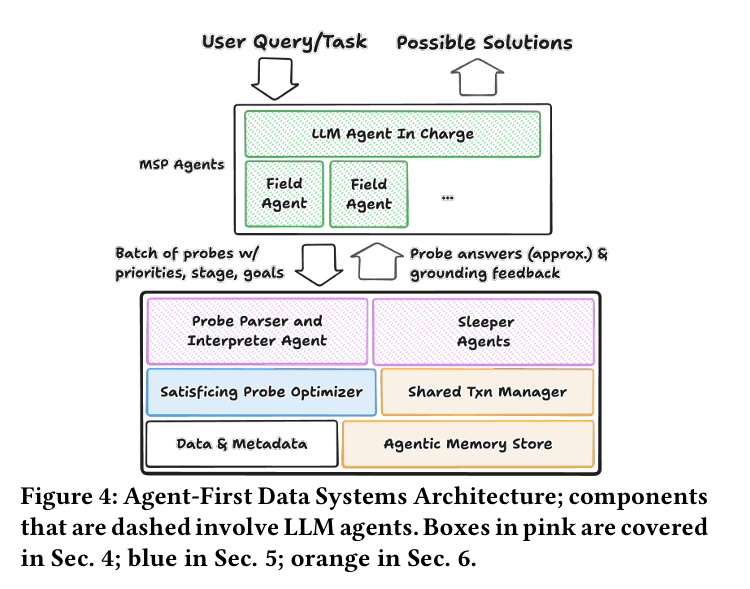
在这里,我们概述了一个“代理优先”的数据系统潜在架构,如图 4 所示。
这张架构图(论文中的 Figure 4)展示了作者提出的核心解决方案:一个专门为 AI 代理(Agents)而非人类设计的全新数据系统架构。
传统的数据库架构(如 MySQL、PostgreSQL)是为“接收确定的 SQL
返回确定的结果”设计的。而这个新架构是为了适应我们之前讨论的代理推测的四个特性(高吞吐、异构、冗余、可引导)。→→我们可以从上到下,分层来详细解读这个结构图:
第一层:代理层(顶部的绿色/虚线框部分)
角色:用户与系统的“中间人”
这一层发生在数据系统之外,是发起请求的一方。
User Query/Task(用户任务):
这是源头,例如:“帮我分析为什么今年利润下降了”。
LLM Agent In Charge(主管代理):
这是总指挥。它将用户的模糊任务拆解成具体的子任务。
Field Agents(前线代理):
这是实际干活的“工蚁”。每个前线代理负责一个具体的子问题(例如,一个查库存,一个查天气,一个查销售)。
关键动作: 它们发出的不再是简单的 SQL,而是一批 Probes(探针)。
Probe 内容: 包含优先级(Priorities)、当前阶段(Stage,是探索还是验证)、以及目标(Goals)。
第二层:接口层(粉色框 - 对应论文第 4 节)
角色:智能的前台与向导
这一层是数据系统的“大门”,负责理解代理的意图并进行沟通。
Probe Parser and Interpreter Agent(探针解析与解释代理):
功能: 它不仅解析 SQL 语法,还能读懂自然语言的“简报”(Briefs)。
作用: 它会分析前线代理传来的目标。例如,如果代理说“我只是在探索”,解释器就会告诉后端“不用算太准,给个大概就行”。
Sleeper Agents(潜伏代理):
功能: 这是系统内部的“卧底”或“助手”。当外部请求进来时,它们会被唤醒。
作用: 它们并行工作,去寻找额外的接地(Grounding)信息。比如当前线代理在查数据时,潜伏代理可能会说:“嘿,那张表是空的,别查了,试试这张”,或者“你要的这个数据已经被另一个代理算过了,直接给你结果”。
输出: 图中向上的箭头 "Probe answers (approx) & grounding feedback"。它不仅返回查询结果,还返回反馈意见,引导外部代理修正下一步的行动。
第三层:处理层(蓝色框 - 对应论文第 5 节)
角色:懂得“差不多就行”的调度员
这一层是查询优化的核心,但逻辑完全变了。
Satisficing Probe Optimizer(满足即可的探针优化器):
概念来源: "Satisficing" 是 Satisfy(满足)+ Suffice(足够)的组合词,意为“令人满意的/凑合的”。
核心逻辑: 传统优化器追求“最快地给出 100% 准确的答案”。这个优化器追求**“在预算内给出一个足够好的答案”**。
工作方式:
剪枝: 发现某些查询对代理的目标没有帮助(基于语义理解),直接扔掉不跑。
近似计算: 代理处于“探索阶段”时,它可能只扫描 1% 的数据来估算结果,从而极大地节省时间。
多查询优化: 它会看一眼手里的一堆探针,发现 50 个代理都在查类似的表,就把它们合并成一次计算。
第四层:存储与事务层(橙色框 - 对应论文第 6 节)
角色:拥有记忆和并行能力的仓库
这一层是底层的存储引擎,为了应对代理的“暴力”用法做了改造。
Data & Metadata(数据与元数据):
最基础的数据存储。
Agentic Memory Store(代理存储器):
这是新概念。 它可以被理解为一个**“语义缓存”或“经验库”**。
存什么? 存储之前代理探索过的元数据、部分查询结果、甚至是“哪些查询是失败的”这种经验。
作用: 当下一个代理来问类似问题时,系统直接从这里调取“记忆”,而不需要重新去扫描底层的原始数据表。这就是实现**接地(Grounding)**和复用的物理基础。
Shared Txn Manager(共享事务管理器):
解决的问题: 代理喜欢搞“What-if”分析(如果 A 发生会怎样?如果 B 发生会怎样?),这会产生无数个并行的分支(Fork)。
功能: 它允许这些分支在逻辑上隔离,但在物理上共享数据(Copy-on-Write),并且支持超快速的回滚。这让成百上千个代理同时修改数据进行推演成为可能,而不会把数据库锁死。
总结:数据流转的全过程
输入: 外部的 Field Agents 发送一堆带有“意图说明书”的 Probes。
接待: Interpreter 读懂说明书,Sleeper Agents 准备好辅助建议。
决策: Optimizer 决定:“这个查询不需要全跑,跑个采样就行;那个查询跟之前的重复了,直接拿缓存;这几个查询没用,删掉。”
执行: 去 Memory Store 找记忆,或者通过 Txn Manager 安全地访问数据。
输出: 返回**“近似的答案”** + “接地反馈(指导建议)” 给外部代理。
一句话总结:
这个架构把数据库从一个**“只会死板执行命令的计算器”,变成了一个“能理解意图、能主动提建议、懂得通过模糊计算来省力”的智能合作伙伴**。
给定一个用户任务,一群 LLM 代理可以向后端系统发出一个或多个探针(probes),可能带有相关的优先级。我们称这些为探针而不是查询,原因有二。首先,它们可以在提供关于请求性质的背景信息方面超越 SQL,例如阶段(元数据探索或方案制定)、发出请求的代理身份、所需的准确度、总体目标等。我们设想这些信息以自然语言或其他灵活格式指定,由库内代理(in-database agents)解释。其次,探针可以超越针对数据或元数据的 SQL(例如,通过 information_schema),去搜索可能存在于任何表(列或行)中的标记(tokens),以帮助识别需要访问哪些表。
然后,这些探针由数据库内的**代理解释器(agentic interpreter)组件解析和解释。对于每一个探针,系统可以提供答案(可能是近似的),还可以主动提供超越答案的信息,通过接地反馈来引导(steer)**代理。我们在第 4 节描述我们的接口以及主动反馈。
给定一个或多个探针,我们的探针优化器(probe optimizer)尝试满足即可(satisfice),即产生解决需求的合理结果,而无需完全评估查询(详见第 5 节);该优化器利用并扩展了传统的关于多查询优化和近似查询处理的数据库研究。
为了提高效率,我们需要改进数据系统的存储和事务组件,详见第 6 节。我们引入了一个**代理存储器(agentic memory store)来存储收集到的任何接地信息,以便在未来的探针中使用。对于更新,我们的共享事务管理器(shared transaction manager)**可以高效地处理涉及许多潜在事务的巨大状态冗余。
4. 查询接口 (Query Interfaces)
在本节中,我们关注代理与数据库的交互。我们首先在 4.1 节描述探针(即代理对数据系统的输入)如何超越 SQL。然后,在 4.2 节讨论数据系统如何超越“查询-结果”范式,提供额外的接地信息以帮助引导代理。
4.1 从代理到数据系统
来自代理的探针需要超越 SQL,说明为什么或如何回答给定的查询。此外,对于某些类型的信息需求,SQL 可能受到限制,需要新的操作符。我们将依次描述每个方面。
提供背景信息。 如果代理所能做的只是指定 SQL 查询,那么数据系统所能做的就是提供这些查询的精确结果,这使得推测性探测变得低效。虽然指定 LIMIT 或精确的近似程度是一种选择,但它提供的表达能力有限。因此,作为探针的一部分,代理可以指定一个或多个 SQL 查询,以及我们称之为**简报(brief)**的内容:关于探针目标和意图、其当前阶段(元数据探索或方案制定)、查询间的近似需求和优先级的自然语言陈述,以及任何其他开放式信息。这些简报随后由数据系统内的探针解释器代理检查,并用于指导优化和执行,例如,按什么顺序执行查询(如果有的话)以及基于目标和阶段的近似(或准确)程度。如何根据这种自然语言输入确定准确度是一个开放问题,同时也需要考虑相对查询执行成本。
在一批探针内的查询中,探针可以额外指定超越简单准确度的开放式目标,例如成对优先级,或指示在 N个特定查询中只需要完成 K个(数据系统可以决定哪一个以最大化效率)。例如,如果处于探索阶段的前线代理(field agent)想要了解美国西海岸与东海岸商店销售业绩的差异,它可以作为探针的一部分指定数据系统需要为每个海岸生成各两个州的统计数据,数据系统可以自行选择是哪两个州。该接口还可以允许其他形式的近似指标,这些指标对人类来说编写耗时,但现在可以由代理完成,例如指定终止标准(termination criteria)——即数据系统可以在部分结果集上评估的函数,以了解某些查询是否可以提前终止。例如,一个终止标准可以被定义为:如果在执行过程中答案与之前的太相似(在部分结果集上评估代理定义的函数以确定答案相似性),则停止执行多个“大海捞针”类型的查询。
通过灵活的探针扩展能力。 在许多情况下,代理甚至不确定从哪里开始以及针对给定任务查询哪些表——因为它们缺乏数据组织方式的知识。假设一个代理的任务是找出某家公司将如何“受到电子产品进口关税增加的影响”。该代理可能希望查找名称与“电子产品”语义相似的表,或者其行包含语义相似数据的表。这种要求查找与特定短语(位于任何地方)语义相似的内容(无论是表、列还是行)的探针,在 SQL 中是不可能解决的,但在早期探索阶段非常有价值。因此,我们需要原生支持语义相似性操作符(超越 LIKE),这些操作符应用于数据系统中的任何数据或元数据。此外,正如我们在第 6 节将讨论的,代理将依赖存储在代理存储器中的元数据(关于单元格、行、列和表,通常由代理自己编写)来理解数据语义,因此需要频繁查询或更新此元数据。虽然上述功能可以通过工具组合实现(例如,将元数据单独存储在向量数据库中,查找后再发出 SQL 查询),但确定实际存储什么和如何存储,以及如何保持其最新是一个挑战。此外,一个全面支持所有数据和元数据需求的数据系统能被代理更有效地使用。
4.2 从数据系统到代理
除了简单地回答探针外,数据系统还应该引导代理走向更好的探针,这反过来可以提高效率。通过这种方式,数据系统以一种更加主动(proactive)的方式行事,类似于数据工程师或管理员可能协助数据分析师尽可能高效地满足信息需求。此信息可以在探针答案之外或代替答案以自然语言提供。这种引导可以服务于两个目的:(1)通过旁路(side-channel)提供数据系统认为相关的辅助数据中心信息来帮助代理;(2)提供关于效率和成本的反馈以协助代理设计其探针。我们设想数据系统内部有潜伏代理(sleeper agents),按需调用以在回答探针的同时并行收集信息,并在探针答案之外返回。
辅助信息。 正如我们在表 1 中所见,提供接地提示或反馈可以减少代理完成任务所需的探针数量。我们设想潜伏代理的任务是识别并提供此类提示作为辅助信息以及答案。例如,潜伏代理可以查找并分享其他相关表——以便进行连接(如连接发现),或者取代当前表作为分析焦点,特别是如果当前表证明是不相关的。或者,与其让代理猜测为什么得到空结果,潜伏代理可以提供类似于“Why-Not Provenance”的反馈,例如,探针假设州是用像“CA”这样的两个字母缩写编码的,但实际上它们是完整列出的。
成本估算和基于成本的反馈。 接地也可以采用成本估算的形式;例如,甚至在执行查询之前,可以将预估成本(特别是如果高于预期)提供给代理,以帮助确定是否必须完全运行该探针,并建议代理修改探针(例如,只关注加利福尼亚而不是全美国),或增加近似程度。这同样可以应用于跨探针的情况。例如,如果潜伏代理预测探针正在按顺序执行一组任务,它可以建议前线代理将它们批处理,如果这样证明更便宜的话。潜伏代理还可以考虑相关的物化答案(materialized answers),或者刚刚为另一个代理回答的类似查询。在这种情况下,潜伏代理可以建议将输入探针修改为具有此类预定义答案的探针以提高效率——或者它可以在旁路中输出此类相关探针的答案。
接下来,我们将讨论如何高效地为探针提供答案。
5. 处理和优化探针 (Processing and Optimizing Probes)
如第 2 节所述,代理探针的吞吐量将远高于人类来源(例如 Web 应用程序)发出的吞吐量。重要的是,在代理优先的数据系统中,我们的目标不是像传统数据库那样优化整体吞吐量,而是充分评估探针,以便代理可以决定在下一轮如何进行。考虑到这一点,本节讨论数据系统需要做出哪些改变以有效支持探针。
5.1 支持探索
我们的代理探针将包含建立接地的探索性查询。一些探索将不可避免地使用自然语言 (NL),因为代理缺乏关于底层数据库的知识(例如,“如何找出存储了多少个表?”),而其他探索则使用 SQL 表达(例如,SELECT count(*) FROM information_schema.tables)。今天的数据库并非设计用于回答 NL 查询。因此,我们的代理优先数据系统中的探针优化器必须通过利用不同代理在探针规模上编排 NL 和 SQL 查询的混合。
为了说明,考虑识别显示销售趋势增长的商店。我们的代理首先需要找出哪些表用于存储销售数据。一个简单的探针执行计划是向网络搜索代理提出 NL 问题,以发现如何查找表模式,并在我们的数据库上执行找到的查询。虽然这些是对数据库元数据表的简单查询,但此类查询返回的输出通常包含大量不必要的信息。例如,PostgreSQL 即使在没有定义任何用户表的情况下也维护数百个内部表和索引。再加上用户表,结果很容易增长到数千行。将所有行都喂给我们的查询制定代理简直是对其有限上下文长度的浪费。
随后,为了发现什么构成了增长趋势,一种策略是使用网络搜索代理用 NL 查找“趋势查询”的示例,然后将返回的信息反馈给查询制定代理以转换为 SQL。我们可能会在线获得大量示例查询,而我们的数据库将被大量不适用的查询轰炸(例如,它们引用不存在的表,或识别错误的趋势)。更糟糕的是,所有这些探索将与制定解决方案的其他代理混合在一起。在当今的数据系统中,我们没有办法识别哪些查询是代理探索的一部分(因此不需要完全评估)。我们设想我们的探针优化器将根据其阶段对查询进行优先级排序(即一种形式的准入控制)。
此外,我们将使用我们的代理存储器存储先前收集的信息,以避免重复查询相同的信息,并训练代理查询我们的存储器,而不是每次都将此类信息作为提示的一部分。
5.2 探针优化
如前所述,代理发出的探针与人类发出的查询不同,不需要完整的答案。数据库接口允许代理通过简报(briefs)用自然语言指定目标和近似需求,数据库随后使用这些简报来决定执行哪些探针以及达到何种准确度。这意味着查询优化器的目标与传统数据系统不同,是决定执行什么查询(以及何种近似程度)以满足(satisfice)探针,以及如何执行它们。在此过程中,优化有一个新目标:在给定可用计算资源的情况下,最小化回答前线代理探针所花费的总时间。 解决这个优化问题需要数据库在内部平衡成本/准确性权衡:如果数据库选择以高近似度回答查询,提供不充分的答案以节省前期成本,代理可能会提出许多后续要求以提高准确性要求,从而增加回答代理探针的总时间。我们接下来讨论我们设想如何解决这样一个优化问题,包括在一个交互轮次采样的探针批次内(5.2.1 节),以及跨轮次和代理的探针批次之间(5.2.2 节)。
5.2.1 探针内优化 (Intra-Probe Optimization)
我们首先讨论如何优化给定的一批探针,以便为代理提供足够的信息,同时最小化计算成本。
决定执行什么。 数据库必须首先决定运行哪些查询以及达到何种近似程度,同时考虑探针及其简报。这要求数据库推理数据和探针语义,包括代理的目标和阶段。为此,数据库可以使用语义查询和数据理解来检查它们是否符合用户意图,并修剪掉它认为语义上无意义的查询。例如,在探索阶段,数据库可以检查探针中的投影列,看它们是否与用户意图相关,如果不相关,则修剪此类列,或将探针作为一个整体修剪掉。此外,数据库可以比较批次内的探针,由可能指定了跨探针近似需求的探针简报指导。然后,数据库可以进行成本估算并比较探针的信息增益,以决定哪些探针更有帮助和/或更便宜。例如,给定两个探针P和 p‘,如果 p'-p返回的行被认为与代理的目标无关,数据库可以修剪掉 p'
。这让人想起先前关于作为可视化推荐一部分的修剪查询的工作,以及给定用户提供的输入/输出示例作为查询合成一部分来决定查询等价性的工作,尽管在代理工作负载中计算差异的查询规模将大得多。最后,数据库可以将代理的阶段纳入考量;例如,在探索期间返回粗粒度的近似值,但在方案制定期间返回更准确的答案。除了修剪查询,我们设想代理将能够检查其他内部数据库状态(例如,缓冲池、查询操作符的输出)以确定是否应继续进行查询评估,或移动到下一轮。
高效执行。 如第 2 节所述,探针具有大量冗余,我们可以通过跨探针共享计算来利用这一点。多查询优化、近似查询处理和部分查询结果缓存可用于提高效率。然而,这带来了新的独特挑战。例如,不同的探针将有不同的近似要求,并可能伴随终止标准(可在部分结果上评估以知晓其是否充分的函数,见第 4 节),这使得推理其语义和可共享内容变得更加困难。此外,数据库可以增量评估查询,类似于增量查询处理,但面临跨查询决策的新挑战;例如,数据库必须决定哪个探针通过先提供更高准确度对代理最有用,然后再增加其他探针的准确度。最后,查询规划和处理可以与优化联合进行,例如,数据库随着获得更多信息,可以重新评估其关于运行哪些查询的决定,或在规划或处理期间增加某些查询的近似水平。
5.2.2 探针间优化 (Inter-Probe Optimization)
数据库还可以利用跨轮次与代理的顺序交互,进一步优化它决定运行的查询及其执行。
决定执行什么。 除了 5.2.1 节讨论的策略外,数据库可以考虑与代理的所有交互来决定运行哪些查询。首先,它可以根据查询是否提供给定过去已回答查询之外的任何新信息来决定运行哪些查询。例如,当代理在连续轮次中给出探针p和 p' 时,如果预期 p和 p'之间的输出不会向代理提供新信息——例如,p'只是添加了与代理目标无关的新列——那么 p'可以被丢弃。此外,数据库可以决定运行哪些查询以最小化未来后续探针的数量。例如,基于探针简报中指定的代理目标,它可以运行一个它认为对代理最大程度有用的查询,精确且完整地运行,而不是近似运行,即使当前查询可能花费更长时间,预期额外的前期计算将减少与代理未来交互的总运行时间。
高效执行。 数据库可以通过观察查询历史并考虑代理的意图来决定物化和缓存答案。例如,基于历史和代理的意图,数据库可以预期未来的探针将继续涉及某些表的连接,并可以将该连接物化。
6. 索引、存储和事务 (Indexing, Storage, and Transactions)
代理推测工作负载的异构性和冗余性从根本上挑战了当今数据存储层的假设,具体来说,即工作负载是静态和独立的。
对于静态工作负载,数据系统依赖于预定义的索引和固定的存储布局(例如,用于 OLAP 的列式存储),基于重复的工作负载模式。相比之下,代理探针从粗粒度的元数据探索演变为最终验证。这种动态性使得静态调优无效。同时,不同探针的探索(或方案制定)阶段可能相似,并可受益于相似的布局。
在独立性方面,数据系统将查询视为不相关的,因此来自这些查询的并发访问(特别是写入)必须相互隔离。虽然这简化了应用程序逻辑并确保了一致性,但这些机制阻止了状态的协作共享(极少数例外除外)。代理工作负载不是隔离,而是需要一种更协作的模型——一种可以安全地跨不同探针共享中间状态的模型,其中许多探针可能是相似的。
因此,我们提出两个关键思想来提高性能。首先,我们提出一个代理存储器(agentic memory store),充当“伪索引”,帮助代理探针快速找到可能有用的信息,可以直接由它们访问,或由潜伏代理代表它们访问。其次,我们提出一个新的事务框架,以跨探针的状态共享为中心,每个探针可能独立地试图完成用户定义的一系列更新。
6.1 代理存储器 (Agentic Memory Store)
代理推测的探索阶段旨在识别要操作的正确表和列。为了提高效率,数据系统应维护一个持久的、可查询的代理存储器——一种提供接地的语义缓存。
伪影(Artifacts)。 第一个问题是应该存储什么。一个想法是存储先前探针和部分解决方案的结果,以便代理可以重用关于数据和元数据的已知信息,使类似的探针更高效。此外,我们可以存储关于数据和元数据的信息,可能与表本身相关联。我们可以存储列的编码格式、缺失值信息以及时间和位置粒度。例如,试图探索各种销售分区的代理可能会检索其中的一部分,连同代理存储器中指示与每个分区关联的日期范围或位置范围的元数据——以便它可以就在哪里进一步探测做出更明智的决定。
为了实现这个存储,我们可以将代理元数据直接嵌入表中,以便在查询表时检索。对于所有其他开放式信息,一种方法是使用向量索引来支持嵌入上的语义相似性搜索(例如,用探针查询可能会检索其他类似的探针,以及对它们有效的方法)。然而,这种方法对于更有针对性或更结构化的查找可能效果不佳。
对存储的更新。 另一个关注点是在更新期间如何维护此存储器。更新可以是正在执行的新探针的形式,这可能提供增强或取代现有信息的新信息。或者,它可能是对底层数据或元数据的更新,这需要更新代理存储器中的任何相关信息。例如,如果有模式更新,使用该表的先前探针的结果可能不再相关。一种方法是允许此存储器与数据/元数据不一致,而是通过任何发现信息陈旧的新探针来更新。然而,缺点是陈旧信息可能导致新探针犯错。例如,假设代理存储器指示唯一相关的销售信息可以在三个表中找到,但在那之后,添加了额外的相关表;在这里,新探针最终可能会返回不正确的结果。支持多用户的访问控制也会出现额外的挑战。例如,代表不同用户行事的代理可能会问类似的问题(例如,“员工的可用性存储在哪里?”)。跨此类代理共享答案可以提高效率——但会引发隐私问题,特别是在聚合层面。解决这些挑战需要从知识库以及模式演进的工作中汲取灵感。
6.2 执行分支更新 (Performing Branched Updates)
在转换或更新数据时,代理通常会探索多个“假设(what-if)”假设,即分支。例如,在 Neon 中,我们观察到代理创建的分支比人类多 20 倍,执行的回滚多 50 倍。传统的事务保证是在线性执行线程内操作的。在这里,对于代理推测,我们需要多世界隔离(multi-world isolation),其中每个分支必须逻辑上隔离,但物理上可能重叠。
分支隔离。 在弱一致性时代开发的现有分支一致性模型(例如,在 Bayou, Dynamo 或 Tardis 中)可以提供灵感。然而,代理推测走得更远:多个代理可能创建最终必须协调的分叉——不仅是与主线协调,而且是彼此协调。这需要多代理、多版本隔离的新模型。大多数分支将是相似的——例如,相同的模式,90% 相同的数据——但隔离要求它们的效果保持逻辑上的分离。
高效的分叉和回滚。 天真地为每个分支复制整个数据库极其昂贵且低效,这使得支持高效分叉变得至关重要。像 Neon, Aurora 这样的工业系统和像 Tardis 这样的学术系统采用写时复制(copy-on-write)方法来懒加载克隆状态。然而,这离大规模推测所需还很远。我们需要新的并发机制,利用分支间的相似性并保持逻辑隔离(无交叉污染),以实现大规模并行分叉。这类似于极致强化版的 MVCC(MVCC on steroids):分叉可能有数千个几乎相同的快照,并回滚除一个之外的所有快照。与回滚很少发生的传统数据系统不同,我们需要超快速回滚(即,对失败分支的快速中止)。
7. 结论 (Conclusion)
我们描述了支持新兴代理工作负载的数据系统愿景。这些工作负载涉及大规模的推测性探测,其特征是发现和验证的高吞吐量冗余混合,由查询和自然语言的组合指定。我们提出了这种重新设计的数据系统的架构,并讨论了涌现的研究挑战。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)