从追赶到引领:2025年末,看中国AI开源模型如何定义全球技术新纪元
中国AI开源模型正引领全球技术革新,从追赶者转变为定义者。2025年,中国开源模型在国际社区下载量前十中占据半数,DeepSeek-V3.2等模型在代码和数学推理任务上达到世界领先水平。中国采取"开源即服务"战略,构建全栈式开源生态,大幅降低技术使用门槛。多模态领域实现真正模态融合,视频生成模型支持专业级构图控制。特别值得一提的是仅6B参数的Z-Image模型,通过创新架构实现
从追赶到引领:2025年末,看中国AI开源模型如何定义全球技术新纪元
当你还在热议某个国外模型的API调用次数时,Hugging Face上中国开源模型的日均下载量已悄然突破百万次,全球开发者正用代码为“中国范式”投票。
2023年初,当全球开发者还在为ChatGPT的横空出世而震撼时,一场静默的革命正在中国AI实验室中酝酿。一年半后的今天,国际顶级AI社区Hugging Face上,下载量前十的开源模型中超过半数来自中国团队。
从文本到图像,从视频到3D生成,中国AI开源生态正以前所未有的速度和广度,重新定义着全球人工智能的发展轨迹。
01 历史转折:从技术追赶到生态引领
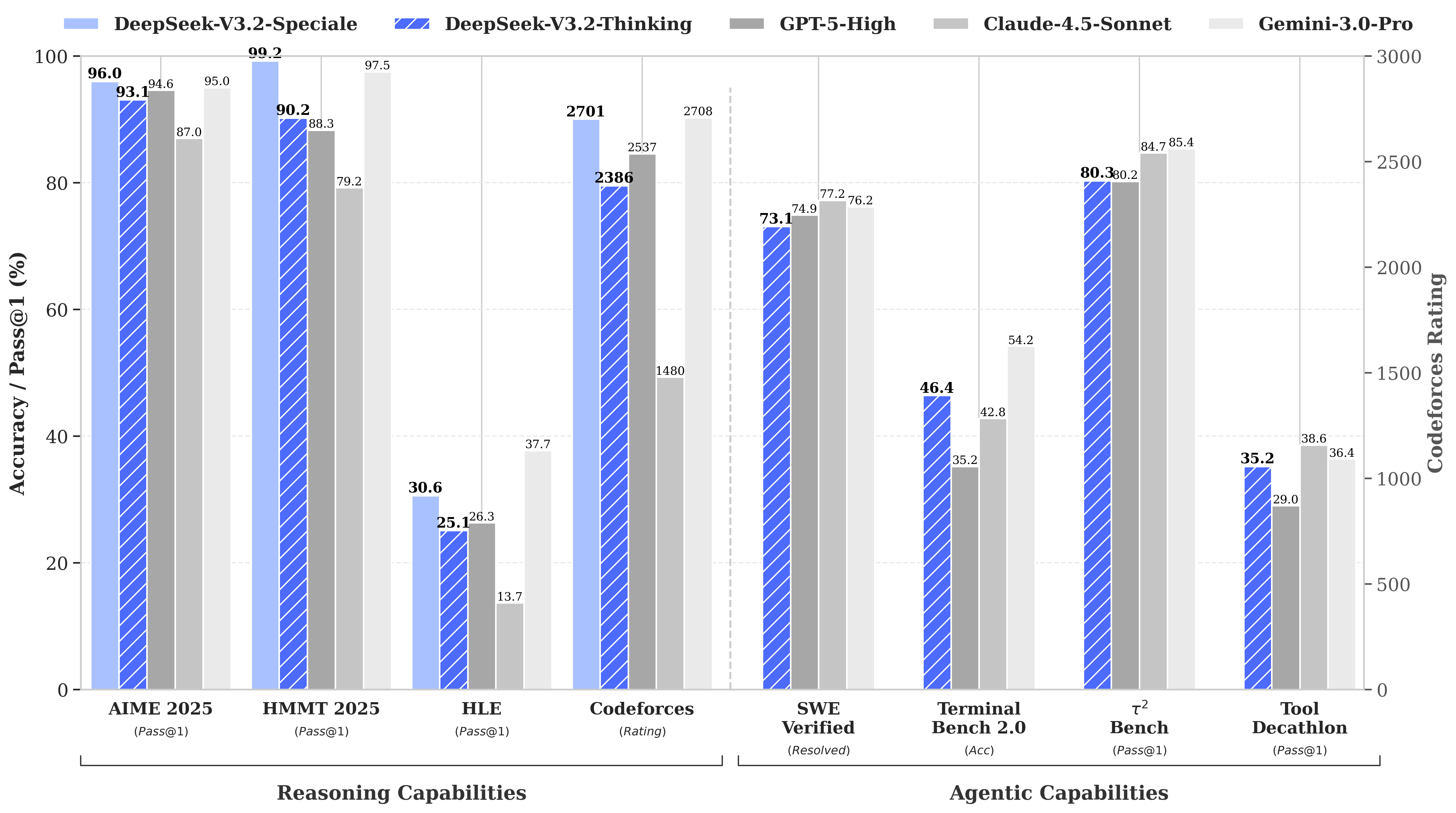
2024年10月,大模型竞技场排名中,智谱GLM-4.6与通义Qwen3-Max-Preview并列全球开源模型第一;仅仅两个月后,DeepSeek-V3.2正式版于2025年12月1日发布,DeepSeek-V3.2-Speciale
在代码和数学推理任务上超越前代并达到世界领先水平。
这不是孤例,而是中国AI开源力量系统性崛起的缩影。
这种转变背后是中国科技公司对开源理念的深刻重构。不同于传统的“发布即完成”,中国公司采取了“开源即服务”的战略思维。
以通义系列为例,其在Hugging Face平台上的模型库包含了从7亿到720亿参数的全尺寸模型,满足从移动端到数据中心的多样化需求。这种全栈式开源策略,大幅降低了全球开发者使用先进AI技术的门槛。
与此同时,中国AI开源社区呈现出鲜明的“应用驱动”特征。与国际同行偏重基础研究不同,中国开源模型从设计之初就考虑了产业落地的实际需求。
腾讯混元3D模型特别优化了对工业设计常用格式的支持,百度文心大模型则强化了对中文古籍、法律文书等垂直领域的理解能力。这种产研结合的导向,使中国开源模型在实际应用中展现出独特优势。
02 技术全景:三大领域的领先表现
大语言模型的效率革命
2025年12月1日,DeepSeek正式发布V3.2版本。这个更新不只是版本号的改变,而是推理效率与性能平衡的新标杆。
DeepSeek-V3.2在编程和数学相关任务上表现优于其前身。更值得关注的是其技术实现——采用了称为DSA的新注意力机制实现,通过减少模型为确定词义而必须审查的文本量来降低硬件使用需求。
对于那些优先考虑输出质量而非硬件效率的场景,DeepSeek还同步发布了性能优化版本DeepSeek-V3.2-Special。
与此同时,中国已经形成了多层次、全尺寸的开放模型体系。下表展示了主要中国开源LLM的关键特性:
| 模型系列 | 代表模型 | 核心优势 | 技术特点 | 开源协议 |
|---|---|---|---|---|
| DeepSeek | V3.2 (2025-12-01) | 代码与数学推理,硬件效率优化 | DSA注意力机制,高性能版本Special | MIT |
| 通义Qwen | Qwen2.5-72B | 多语言能力强,代码生成优异 | 长上下文支持1M tokens | Apache 2.0 |
| 智谱GLM | GLM-4.6 | 长上下文,中文优化 | 支持128K上下文 | 商用友好 |
| 百度文心 | ERNIE 4.5-47B | 产业知识丰富,工具调用强 | 垂直领域深度优化 | 宽松开源 |
| 零一万物 | Yi-34B | 性价比高,中英平衡 | 均衡架构设计 | Apache 2.0 |
在国际公认的评测基准如MMLU、GSM8K和HumanEval上,这些模型的表现已经与国际顶级开源模型不相上下,在某些中文特定任务上甚至实现了超越。
特别值得注意的是,中国开源LLM在长上下文处理方面取得了显著突破。GLM-4.6支持128K上下文长度,而Qwen2.5系列更是将这一数字提升至惊人的1M tokens,为处理超长文档、复杂代码库和多轮对话提供了强大支持。
多模态模型的突破性进展
多模态大模型领域,中国团队的创新尤为突出。传统多模态模型往往将不同模态“拼接”在一起,而中国研究者提出了更加一体化的架构。
以通义Qwen3-Omni为代表的“全模态”模型,能够在统一框架下处理文本、图像、音频、视频等多种输入,实现了真正的模态融合而非简单拼接。这种设计不仅提升了模型效率,也增强了跨模态理解和生成的一致性。
更值得关注的是,中国多模态开源模型在具身智能这一前沿方向上的探索。例如,上海人工智能实验室开发的InternVL系列,专门针对机器人感知与控制进行了优化,为智能体与物理世界交互提供了新可能。
生成式模型的实用化突破
在视频生成领域,阿里巴巴的通义万相WAN2.2系列持续进化。2025年8月,WAN2.2国际版开源,其新构图和镜头控制功能让用户能更轻松地获得专业级画面构图。
同年9月,通义万相团队进一步开源了Wan2.2-Animate动作生成模型。该模型能够驱动人物、动漫形象及动物照片生成动态视频,支持动作模仿与角色扮演双模式。
在动作模仿模式下,用户只需提供一张角色图片和一段参考视频,模型即可将视频中的动作与表情迁移到静态角色上;在角色扮演模式中,则能在保留原始视频动作、表情及环境的基础上替换角色。
在图像生成领域,阿里巴巴推出的Z-Image模型代表了全新的设计哲学——“效率优先” 。这个仅6B参数的模型挑战了行业“不计成本扩展规模”的范式。
Z-Image采用了创新的单流扩散Transformer架构(S3-DiT),在资源使用效率上树立了新标杆。其完整训练流程仅需31.4万H800 GPU小时,成本约62.8万美元,远低于行业常见水平。
同时,基于Z-Image优化的Z-Image-Turbo版本,实现了在消费级硬件(显存<16GB VRAM)上的亚秒级图像生成,让高性能图像生成真正走向普及。
03 生态优势:开源策略与社区共建
技术领先只是中国AI开源故事的一部分,真正使其形成全球影响力的是独特的开源生态建设策略。与传统的“发布即完成”的开源模式不同,中国科技公司采取了一种更加积极主动的生态培育方式。
中国AI开源的一个显著特点是“全链路开放”。这不仅包括模型权重和推理代码,还涵盖了训练数据、训练脚本、评估工具乃至部署方案。以百度文心大模型为例,其开源项目包含了从数据清洗、模型预训练、指令微调到强化学习的完整工具链。
这种全链路开放使全球研究者不仅能够使用这些模型,还能深入理解其训练过程,甚至在此基础上进行创新。根据GitHub数据,基于中国主流开源模型创建的衍生项目数量已超过30万个,形成了活跃的二次创新生态。
中国AI开源生态还表现出强大的产学研协同特征。清华大学、北京大学等高校的研究团队与工业界保持着紧密合作,共同推动开源模型的发展。
这种合作模式加速了学术成果向工业应用的转化,也为工业界提供了前沿研究的洞察。例如,智谱AI与清华大学KEG实验室的合作,使得GLM系列模型在学术严谨性与工程实用性之间找到了良好平衡。
更值得关注的是中国开源模型对全球多样化需求的响应能力。与主要针对英语世界优化的国际模型不同,中国开源模型从一开始就考虑了多语言、多文化的需求。
Qwen系列对超过100种语言的支持,文心大模型对亚洲文化的深入理解,都体现了这种全球化视野。这种多元化设计使中国开源模型在非英语地区获得了广泛欢迎,形成了独特的竞争优势。
04 产业赋能:从技术到应用的价值转化
中国AI开源模型的领先不仅体现在学术论文和基准测试中,更体现在对实际产业的赋能效果上。不同于纯粹的研究导向,中国开源模型在设计之初就考虑了产业落地的需求,形成了从技术到应用的高效转化路径。
在金融领域,基于开源大模型的智能投研系统正在改变传统研究模式。通义Qwen的金融微调版本能够实时分析海量财经新闻、公司财报和行业报告,自动生成投资摘要和风险提示。某头部券商使用这类系统后,研究报告的撰写效率提升了40%,同时覆盖的公司数量增加了三倍。
教育行业是另一个成功案例。百度文心大模型的开源版本被广泛应用于个性化学习系统,能够根据学生的学习历史和知识掌握情况,动态生成定制化的练习题目和讲解内容。这一应用不仅提高了个性化教育的可行性,也使优质教育资源能够惠及更广泛的学生群体。
下表展示了中国开源AI模型在不同行业的应用案例与效果:
| 行业领域 | 应用场景 | 使用模型 | 关键成效 | 典型用户 |
|---|---|---|---|---|
| 金融科技 | 智能投研 | Qwen-Finance | 研报效率+40%,覆盖公司3倍 | 头部券商 |
| 教育培训 | 个性化学习 | ERNIE-Edu | 学生参与度+35%,成绩提升显著 | 在线教育平台 |
| 工业设计 | 3D建模辅助 | Hunyuan3D | 设计周期缩短50%,成本降低30% | 制造企业 |
| 内容创作 | 视频生成 | Wan2.2-Animate | 动作视频制作效率提升70% | MCN机构 |
| 医疗健康 | 辅助诊断 | GLM-Medical | 影像分析准确率提升15% | 三甲医院 |
工业设计领域的变革尤为显著。腾讯混元3D开源后,迅速被国内多家制造企业采用,用于产品原型设计和可视化展示。一家家电企业引入该技术后,新产品设计周期从平均3个月缩短至6周,同时降低了原型制作成本。
更值得关注的是,像Z-Image这样的高效模型正在推动AI普惠化进程。其仅6B的参数规模和高效的推理能力,使得高质量图像生成可以在消费级硬件上实现,大幅降低了创意工作的技术门槛。
05 成本效率:重新定义AI模型经济学
在AI模型竞争日趋白热化的背景下,“效率”已成为衡量模型综合实力的关键指标。中国开源模型在成本效率方面的突破,特别是Z-Image所展现的优势,正在重新定义AI模型的经济学。
下面的对比表格清晰地展示了Z-Image在参数效率和训练成本方面的卓越表现:
| 模型 | 参数规模 | 总训练成本 | 核心效率优势 |
|---|---|---|---|
| Z-Image | 6B | 314K H800 GPU小时 (约$628K) | 参数效率极高,训练成本大幅降低 |
| Qwen-Image | 20B | N/A | 性能强劲但参数规模较大 |
| Hunyuan-Image-3.0 | 80B | N/A | 顶尖性能但参数量巨大 |
| FLUX.2 | 32B | N/A | 性能优秀但资源需求高 |
Z-Image的6B参数量仅为Qwen-Image的30%、Hunyuan-Image-3.0的7.5%,但其通过系统性的全链路优化,实现了与这些大模型相媲美的性能。
这种效率突破主要得益于四大技术支柱:
- 高效数据基础设施:通过数据画像引擎、跨模态向量引擎等模块,最大化每GPU小时的知识获取率
- 创新架构设计(S3-DiT):单流多模态扩散Transformer实现密集跨模态交互,参数利用率极高
- 渐进式训练策略:低分辨率预训练→全能预训练→监督微调的三阶段课程
- 高效推理优化:Z-Image-Turbo通过几步蒸馏实现仅8NFE的快速生成,兼容消费级硬件
这种“效率优先”的设计哲学,不仅降低了模型开发的门槛,也使得AI技术能够更广泛地渗透到各行各业。Z-Image-Turbo在企业级H800 GPU上可实现亚秒级推理,同时在显存低于16GB的消费级硬件上也能流畅运行,真正实现了高性能AI的普及。
06 全球影响:开源模型的中国范式
中国AI开源模型的崛起不仅改变了技术格局,更在全球范围内形成了一种独特的“中国开源范式”。这种范式强调开放协作、产业结合与生态共建,与国际主流开源文化形成了有意义的对话与互补。
在国际开源社区中,中国模型的参与度与影响力与日俱增。根据Hugging Face的统计数据,2024年中国机构开源模型的下载量同比增长超过300%,增速远超其他地区。
特别值得注意的是中国模型对全球AI研究社区的贡献。许多国际研究团队开始基于中国开源模型开展前沿探索。例如,斯坦福大学的研究者利用Qwen2.5的代码能力开发了新的程序合成工具,伯克利的研究团队则基于混元3D进行了机器人三维场景理解的实验。
中国开源模型的成功也促进了全球AI治理的多元化讨论。传统上,AI伦理和安全标准主要由西方机构制定。随着中国模型影响力的扩大,关于文化适应性、多元价值对齐等议题得到了更广泛的关注。中国团队在模型安全、价值对齐方面的开源实践,为全球AI治理提供了新的视角和解决方案。
从技术标准角度看,中国开源模型的创新也开始影响国际规范。例如,通义Qwen提出的多模态统一表示方法,已被考虑纳入下一代多模态模型的标准架构讨论。中国开源模型正从技术接受者转变为标准贡献者。
07 挑战与展望:持续领先的路径思考
尽管取得了显著成就,中国AI开源模型仍面临多重挑战。保持并扩大当前的领先优势,需要在整个技术栈和生态系统中进行持续创新。
算力基础设施的自主可控是首要挑战。当前中国AI模型训练仍然严重依赖国际高端芯片,这构成了潜在的技术风险。虽然国内芯片企业在奋起直追,但在软件生态和开发者体验方面仍有差距。建立完整的自主AI算力体系,需要芯片、框架、模型和应用的全栈协同优化。
数据资源的质量与多样性是另一个关键问题。随着模型规模的扩大,对高质量训练数据的需求呈指数级增长。中国模型在中文数据方面具有优势,但在多语言、多文化数据的覆盖上仍有提升空间。此外,合成数据生成、数据质量控制等前沿领域需要更多原创性研究。
从技术创新的角度看,中国AI开源需要从“应用创新”向“基础创新”深化。当前许多突破是在现有架构上的优化和改进,而在下一代AI基础架构(如神经符号系统、世界模型等)方面的原创贡献相对有限。加强基础研究投入,鼓励高风险高回报的探索,是维持长期竞争力的关键。
人才生态的建设同样至关重要。虽然中国拥有庞大的AI工程师群体,但在顶尖研究人才方面仍有缺口。吸引和培养能够定义下一代AI方向的领军人物,需要学术环境、评价体系和资源支持的系统性改革。
展望未来,中国AI开源模型有望在以下几个方向实现突破:
首先是超级对齐技术的突破,使大模型能够更安全、更可靠地服务于人类价值观;其次是AI for Science的深度融合,将大模型能力应用于基础科学研究;最后是边缘AI的普及,让强大的模型能力能够在资源受限的设备上运行。
从2023年的追赶者到2025年的定义者,中国AI开源模型已经走过了从技术追赶到生态引领的完整历程。面对充满不确定性的未来,坚持开放协作、深耕产业需求、勇于基础创新,将是中国模型持续引领全球AI发展的重要保证。
这场由中国AI开源力量引领的技术变革,才刚刚拉开序幕。
技术资源链接
- DeepSeek-V3.2官方信息:了解2025年12月1日发布的最新版本特性与技术细节
- Z-Image模型论文:深入阅读阿里巴巴Z-Image模型的技术架构与效率创新
- 通义万相WAN2.2-Animate体验:了解如何让静态照片动起来的动作生成模型
当全球开发者以每分钟数次的频率在GitHub下载中国开源模型,这场静默的革命已成澎湃浪潮。从最初的仰望到如今的引领,中国AI开源走过的道路揭示了一个智能时代的真理:真正的技术领先,不在于拥有最先进的模型,而在于能让这先进技术成为全球共享的价值与工具。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献155条内容
已为社区贡献155条内容

所有评论(0)