老板说换个 AI 模型,我花了 5 分钟搞定
本文通过程序员小刘的故事,生动讲解了适配器模式的应用场景和实现方法。面对OpenAI、Ollama和NVIDIANIM三种大模型API调用方式不一致的问题,小刘采用适配器模式定义了统一接口ModelAdapter,并为每个模型创建对应的适配器类,将不同API封装成一致的调用方式。结合工厂模式,只需修改配置文件即可切换不同模型,彻底解决了if-else泛滥的问题。文章还强调了错误处理、日志记录和测试

阅读大约需 8 分钟
上一篇回顾
上回说到,小刘用工厂模式治好了 if-else 泛滥的毛病。
产品经理再加新模型,他只需要写一行注册代码,5 分钟搞定。
小刘以为可以安心喝咖啡了。
直到老板走进了办公室。

新的噩梦
"小刘啊,"老板笑眯眯的,"OpenAI 的 API 太贵了,一个月烧了两万块。"
小刘心里咯噔一下。
"我听说 Ollama 可以本地跑模型,免费的。你把项目改成 Ollama 吧。"
小刘想了想,这不难啊,工厂模式不是白学的。改个配置就行。
"还有,"老板补充道,"客户 A 说他们公司只能用 OpenAI,客户 B 要用 NVIDIA NIM,客户 C……"
小刘的咖啡突然不香了。
问题在哪?
小刘打开代码,发现问题比想象的严重。
虽然工厂模式解决了"创建哪个对象"的问题,但不同模型的调用方式完全不一样:
# OpenAI 的调用方式
response = openai_client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
# Ollama 的调用方式
response = requests.post(
"http://localhost:11434/api/generate",
json={"model": "qwen", "prompt": prompt}
)
result = response.json()["response"]
# NVIDIA NIM 的调用方式
response = nim_client.generate(
model="llama-3.1-70b",
prompt=prompt,
max_tokens=1024
)
result = response.text
三个模型,三种 API,三种响应格式。
小刘的业务代码里到处是这样的判断:
def generate_story(prompt):
if settings.LLM_TYPE == "openai":
# OpenAI 的一套逻辑...
response = openai_client.chat.completions.create(...)
return response.choices[0].message.content
elif settings.LLM_TYPE == "ollama":
# Ollama 的一套逻辑...
response = requests.post(...)
return response.json()["response"]
elif settings.LLM_TYPE == "nvidia-nim":
# NVIDIA 的一套逻辑...
pass
等等,这不是又回到 if-else 地狱了吗?
工厂模式解决的是"创建对象"的问题,但"使用对象"的方式不统一,照样一团乱。

小刘意识到,他需要另一个武器。
充电器的启示
小刘去倒水的时候,看到同事在给 iPhone 充电。
插座是国标三孔,充电器是美版双扁头,中间插着一个转换器。
小刘突然愣住了。
转换器!
不管是什么插头,转换器都能把它变成统一的接口。
代码不也可以这样吗?
不管是 OpenAI、Ollama 还是 NVIDIA NIM,都给它们套一个"转换器",对外提供统一的接口。
这就是适配器模式。
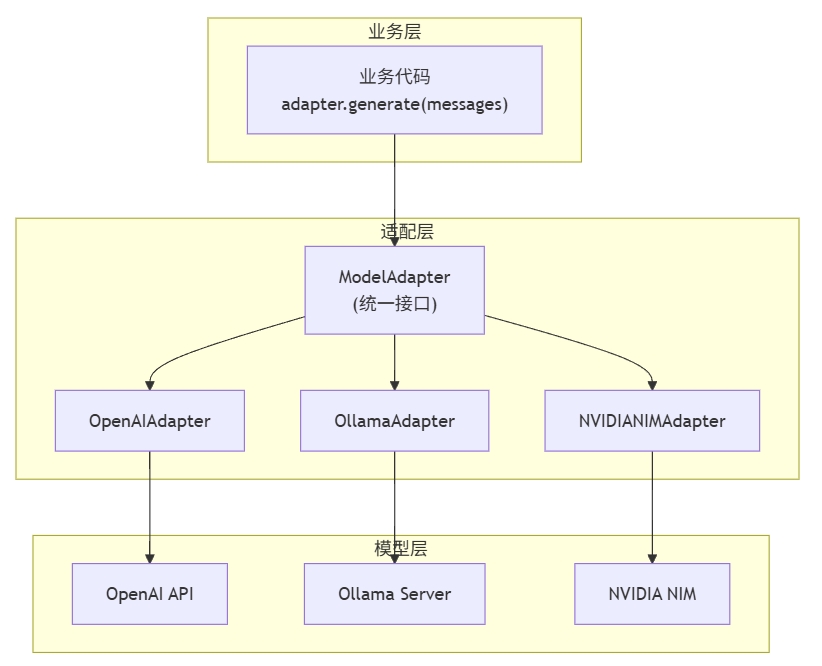
定义统一接口
小刘回到工位,首先定义了一个"标准插座"——所有模型都要遵守的接口:
from abc import ABC, abstractmethod
class ModelAdapter(ABC):
"""LLM 适配器的统一接口"""
@abstractmethod
def generate(self, messages: list, temperature: float = 0.7) -> str:
"""
生成回复
不管底层是什么模型,调用方式都一样:
- 输入:消息列表
- 输出:字符串
"""
pass
@property
@abstractmethod
def model_name(self) -> str:
"""返回模型名称,方便日志和调试"""
pass
这个基类就像一份"合同":
"不管你是 OpenAI 还是 Ollama,只要继承我,就必须提供
generate()方法,而且输入输出格式都按我的来。"

给每个模型做转换器
接下来,小刘给每个模型写了一个适配器。
OpenAI 适配器
class OpenAIAdapter(ModelAdapter):
"""OpenAI 的适配器"""
def __init__(self, api_key: str, model: str = "gpt-4"):
self.client = OpenAI(api_key=api_key)
self._model = model
def generate(self, messages: list, temperature: float = 0.7) -> str:
# 把统一格式转成 OpenAI 的格式
openai_messages = [
{"role": msg["role"], "content": msg["content"]}
for msg in messages
]
response = self.client.chat.completions.create(
model=self._model,
messages=openai_messages,
temperature=temperature
)
# 把 OpenAI 的响应转成统一格式
return response.choices[0].message.content
@property
def model_name(self) -> str:
return f"openai/{self._model}"
Ollama 适配器
class OllamaAdapter(ModelAdapter):
"""Ollama 的适配器"""
def __init__(self, base_url: str, model_name: str):
self.base_url = base_url
self._model_name = model_name
def generate(self, messages: list, temperature: float = 0.7) -> str:
# Ollama 不支持 messages 格式,要转成单个 prompt
prompt = "\n".join([
f"{msg['role']}: {msg['content']}"
for msg in messages
])
response = requests.post(
f"{self.base_url}/api/generate",
json={
"model": self._model_name,
"prompt": prompt,
"stream": False,
"options": {"temperature": temperature}
}
)
return response.json()["response"]
@property
def model_name(self) -> str:
return f"ollama/{self._model_name}"
NVIDIA NIM 适配器
class NVIDIANIMAdapter(ModelAdapter):
"""NVIDIA NIM 的适配器"""
def __init__(self, api_key: str, model: str = "meta/llama-3.1-70b-instruct"):
self.client = OpenAI(
api_key=api_key,
base_url="https://integrate.api.nvidia.com/v1"
)
self._model = model
def generate(self, messages: list, temperature: float = 0.7) -> str:
response = self.client.chat.completions.create(
model=self._model,
messages=messages,
temperature=temperature
)
return response.choices[0].message.content
@property
def model_name(self) -> str:
return f"nvidia-nim/{self._model}"
业务代码的蜕变
现在,小刘的业务代码变得无比清爽:
def generate_story(adapter: ModelAdapter, prompt: str) -> str:
"""生成故事 - 完全不关心用的是什么模型"""
messages = [
{"role": "system", "content": "你是一个故事创作大师"},
{"role": "user", "content": prompt}
]
return adapter.generate(messages)
没有 if-else。
没有模型细节。
就是这么干净。
配合工厂模式,效果更佳
还记得上篇的工厂模式吗?小刘把它和适配器模式结合起来:
class ModelAdapterFactory:
"""适配器工厂"""
_adapters = {
"openai": OpenAIAdapter,
"ollama": OllamaAdapter,
"nvidia-nim": NVIDIANIMAdapter,
}
@classmethod
def create(cls, adapter_type: str, **kwargs) -> ModelAdapter:
if adapter_type not in cls._adapters:
available = ", ".join(cls._adapters.keys())
raise ValueError(f"不支持: {adapter_type},可用: {available}")
return cls._adapters[adapter_type](**kwargs)
使用方式:
# 从配置创建适配器
adapter = ModelAdapterFactory.create(
settings.LLM_TYPE, # "openai" / "ollama" / "nvidia-nim"
**settings.LLM_CONFIG # api_key, model 等参数
)
# 业务代码完全不变
story = generate_story(adapter, "写一个关于程序员的故事")
切换模型?改配置文件就行:
# .env
LLM_TYPE=ollama
OLLAMA_BASE_URL=http://localhost:11434
OLLAMA_MODEL=qwen3:32b
5 分钟?太慢了。5 秒钟!
三个细节,决定成败
适配器模式看起来简单,但有几个细节处理不好,会踩大坑。
细节 1:错误要统一包装
不同模型的错误格式不一样:
- • OpenAI 抛
openai.APIError - • Ollama 返回 HTTP 错误
- • NVIDIA NIM 抛
requests.exceptions.RequestException
业务代码不应该关心这些。小刘在基类里统一处理:
class ModelAdapter(ABC):
def generate(self, messages: list, **kwargs) -> str:
try:
return self._do_generate(messages, **kwargs)
except Exception as e:
# 统一包装成自定义异常
raise LLMError(
model=self.model_name,
message=f"生成失败: {str(e)}",
original_error=e
)
@abstractmethod
def _do_generate(self, messages: list, **kwargs) -> str:
"""子类实现这个方法"""
pass
细节 2:日志要带上模型信息
出问题时,第一个问题永远是"用的哪个模型?"
def generate(self, messages: list, **kwargs) -> str:
start_time = time.time()
result = self._do_generate(messages, **kwargs)
# 自动记录调用信息
logger.info(
f"LLM 调用完成 | "
f"model={self.model_name} | "
f"耗时={time.time() - start_time:.2f}s | "
f"输出长度={len(result)}"
)
return result
凌晨三点查问题时,你会感谢自己的。
细节 3:测试要能 mock
适配器模式的一大好处是方便测试:
class MockAdapter(ModelAdapter):
"""测试用的 Mock 适配器"""
def __init__(self, response: str = "这是模拟回复"):
self._response = response
def generate(self, messages: list, **kwargs) -> str:
return self._response
@property
def model_name(self) -> str:
return "mock"
# 测试代码
def test_generate_story():
mock_adapter = MockAdapter("从前有个程序员...")
result = generate_story(mock_adapter, "写个故事")
assert "程序员" in result
不用真的调 API,不花钱,不等待,测试飞快。
故事的结局
周一早会。
老板:"小刘,模型切换的事情搞得怎么样了?"
小刘:"搞定了。"
老板:"这么快?那客户 A 用 OpenAI,客户 B 用 NVIDIA NIM,客户 C 用 Ollama,都能支持?"
小刘打开配置文件:"您看,改这里就行。"
# 客户 A
llm_type: openai
# 客户 B
llm_type: nvidia-nim
# 客户 C
llm_type: ollama
老板愣了一下:"就这?"
小刘:"就这。"
老板满意地点点头,转身走了。
小刘端起咖啡,看着窗外的阳光。
适配器 + 工厂,这套组合拳真香。
一张图总结
适配器 vs 工厂:别搞混了
| 工厂模式 | 适配器模式 | |
|---|---|---|
| 解决什么问题 | 创建哪个对象 | 如何使用对象 |
| 关注点 | 实例化过程 | 接口统一 |
| 类比 | 餐厅点菜(选哪道菜) | 充电转换器(统一接口) |
| 一起用 | 工厂负责创建适配器,适配器负责统一接口 |
它们是最佳拍档,不是二选一。
下一篇,我们聊聊 AI 返回的 JSON 总是格式错误怎么办。小刘又要头疼了。
敬请期待。
#Python #设计模式 #适配器模式 #LLM #OpenAI #Ollama

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)