周卫林|大数据通往大模型的钥匙:NoETL to Trusted AI
此时此刻,站在 Data 和 AI 的十字路口,我不禁扪心自问:是创造还是涅灭,大数据如何通往大模型,数据资产如何成为 AI 资产?是廿年戎马终归碌碌无为,还是四载厚积一朝破茧成蝶——让 Aloudata 成为大数据通往大模型的钥匙,开启数据智能变革的黄金十年。
此时此刻,站在 Data 和 AI 的十字路口,我不禁扪心自问:是创造还是涅灭,大数据如何通往大模型,数据资产如何成为 AI 资产?是廿年戎马终归碌碌无为,还是四载厚积一朝破茧成蝶——让 Aloudata 成为大数据通往大模型的钥匙,开启数据智能变革的黄金十年。
过去 20 年:让业务用上好数据
2003 年,我走出校园,加入一家当年规模不小的软件公司,做运营商的经分系统。经分系统是数据仓库一个早期典型应用场景。我当时是 ETL 工程师,也是 Cognos/BIEE 工程师,在客户现场梳理业务数据模型和指标口径,写 SQL 代码,做报表开发。3 年后,我加入阿里巴巴的数据仓库团队,独立对接业务线,从数据需求沟通、数据模型设计、 ETL 作业开发到任务运维监控,端到端交付需求。
2012 年,随着大数据开源和阿里自研的深入,我工作变动到支付宝,围绕“为数据人提供工作环境”,从 0 到 1 自研从数据集成开发、分析洞察到机器学习的数据平台,并开始负责蚂蚁集团整体的数据工作,深感 ETL 工程师的专家经验有上限,产生了“让数据治理数据”的理念。
2021 年, Aloudata 创立,秉承“让数据治理数据”这一理念,我们创新性地提出“NoETL”这一数据架构,完成了数据虚拟化、主动元数据和数据语义层的产品化落地,推出了逻辑数据编织平台 Aloudata AIR、主动元数据平台 Aloudata BIG、自动化指标平台 Aloudata CAN,在不同环节大大提升了 ETL 自动化的水平, 并成功落地到数十个行业头部客户的生产环境中。
过去 20 年,是我从大数据新人成长为大数据专家的 20 年,也是“让业务用上好数据”不断实践的 20 年,更是大数据波澜壮阔发展的一个时代缩影。
未来 10 年:让 AI 用上好数据
2022 年 11 月 30 日,OpenAI 推出 ChatGPT,时至今日,短短三年,恍如一世。
我们站在 AI 的浪潮之巅,不得不重新审视一切:当数据消费者从数据分析师转向数字分析师,数据生产方式将如何重构?当数据不止服务碳基员工,还要服务硅基员工,企业数据资产又将如何在 AI 时代释放价值?
回望来时路,不负少年心,“人人都是数据分析师”、“让每一个微小的业务念头都值得数据灌溉”、……,这些数据人的愿景和情怀,在“智力普惠”的 AI 时代,第一次显得如此真切。
在“算力普惠”和“算法普惠”之后,数据成为企业智能竞赛最大的差异要素,大数据在互联网、移动互联网时代造就的企业分野,在 AI 时代不仅不会缩小,反而将会急剧放大。
凡有的,还要加给他,数据是企业在 AI 时代产生马太效应和黑洞效应的第一推进力。
未来 10 年,“让 AI 用上好数据”成为一个巨大的时代机会,是所有数据人的共同课题,也是 Aloudata 难得一见的历史机遇,我们必然会全心投入,奋力向前,“让 AI 用上好数据”,将从一句口号变成每一家企业都可触及的现实。

从 Data Warehouse 到 Semantic Fabric
2003 年 Palantir 成立,为美国情报部门搭建软件系统 Gotham,为了缝合不同客户现场、不同业务场景的差异,Palantir 创造性地提出了“Ontology”(本体论),屏蔽了真实数据库里“表”、“字段”等概念,成为 Palantir FDE(前置部署工程师)跟客户沟通场景和业务逻辑的语义载体,实现了跨场景和跨客户的抽象和复用,并在过去一年多时间里通过引入 AI ,构建 AIP 平台,帮助客户和自己获得了巨大的成功。
分析 Palantir 能够在 AI 时代一骑绝尘,核心原因是经过 Ontology 重组后的数据可以提供丰富的业务语义,为 AI 大规模解决企业内部大量复杂场景提供了统一的业务知识库(Context)和业务操作指令(Tools)。
回想 2003 年我在客户现场的情形,一样有着相似的经历,比如通过调研设计业务数据模型,构建 BI 语义模型(Semantic Model,Cognos 是 Framework Manager ,BIEE 是 Repository),屏蔽了数据仓库里“表”、“字段”等概念,交付出各个报表看板和专题分析报告,实现一致并且联动的数据分析体验。
从最近的观察也不难发现,2025 年年初 DeepSeek 爆火之后,各类企业级的数据 Agent 都需要或轻或重定义和维护指标语义,以便大模型可以理解企业私域大数据,并完成业务用户与大模型之间的口径对齐和确认,这一点尤为关键,否则用户不敢用大模型给出的结果,而找 IT 核数对数,反而降低了业务效率,增加了 IT 成本。
数据语义层(Semantic Layer)已成为企业数据 Agent 落地推广的“胜负手”。我们推出的 Aloudata CAN 指标平台已经是业内公认的数据语义层的最佳产品,获得了客户的广泛认可,我们结合 Aloudata CAN 指标语义引擎推出的数据分析与决策智能体 Aloudata Agent 也有了多个生产环境落地实践,成功交付了准确、灵活和深入的智能数据分析体验。
Ontology 是 Palantir 的数据语义层,是现实业务运营的数字孪生,解决的是业务决策逻辑如何定义和映射到业务 IT 系统的问题。
Aloudata CAN 是 Aloudata Agent 的数据语义层,是现实经营决策的数字孪生,解决的是数据分析逻辑如何定义和映射到数据 IT 系统的问题。
显而易见,数据语义层除了定义能力,还需要有执行能力,Palantir 通过 Gotham 或 Foundry 平台完成 Ontology 的执行,Cognos / BIEE 通过 BI Server / Query Engine 完成 Semantic Model 的执行。
同样,在 Agent 的世界里,自然语言可以完成前端的“定义”,但也离不开后端的“执行”,比如 AI 编程产品 Lovable、Bolt.new 等需要通过 Supabase 来构建可执行的后端服务。
那么,谁能提供数据 Agent 背后的“Supabase”服务?这样的“Supabase”服务需要数据语义引擎具备什么样的“执行”能力?
首要的能力是 ETL 的编排能力,因为数据 Agent 的数据语义查询是基于数据语义层动态生成的,传统的通过 ETL 工程师排期发布数据宽表、汇总表的查询性能优化方式无法适配数据 Agent 的场景要求。为了保障数据语义的查询性能,数据语义引擎需要在成千上万个复杂的数据语义定义中提前找到查询物化加速方案,并能自动化的完成 ETL 编排。
其次的能力是语义的编译能力,优秀的数据语义引擎会提供功能完备的数据语义 DSL,定义数据分析逻辑(如模型、维度、指标、实体等),数据语义引擎需要能够将任意复杂的 DSL 翻译成可执行的性能优良的数据库 SQL,并可以智能路由命中 ETL 编排后的数据物化表,以提升数据查询性能。
最后的能力是跨库、跨源、跨云的连接能力,因为数据语义的查询执行和物化构建要依赖和复用企业已有的数据存算资源,而企业现有存算架构往往是湖仓多引擎架构和混合的多云架构。相比只能单库、单源、单云适配的数据语义引擎,具备跨库、跨源、跨云连接能力的数据语义引擎提供了足够的数据架构灵活性,会极大降低企业应用 Agent 的计存成本,增强数据语义层作为企业数据资产中心这一架构定位的持久性。
相比数据编织( Data Fabric),我更愿意把上述的能力统称为数据语义层的语义编织能力(Semantic Fabric),这也是数据 Agent 的“最后一公里”的能力,直接影响 Agent 的真实可用性。
以上,回归 Data Warehouse 的业务起点和架构源点,大数据通往大模型,数据资产成为 AI 资产,让数据 Agent 也能有强大的后端服务,大数据存在两点变革:从 Data 到 Semantic,从 Warehouse 到 Fabric。
数据语义层,让数据 Agent 成为 “Trusted AI”
我们当下所处的蓬勃发展的生成式 AI (Generative AI)时代,普遍存在一种现象:Easy To Make,Hard To Detect。我们能够评价 AI 交付物是否足够“好”,但我们越来越难判断 AI 交付物是否足够“真”。当场景对“好”的要求大于“真”的要求时,AI 的“Easy To Make”的优势就足够明显地发挥出来,比如 AI 生成文章、图片、视频、代码等场景,用户可以很直观地评估出“好”,所以这类场景就优先跑出了 PMF,诞生了不少增长很快的创业公司。而数据分析这类企业场景却恰恰相反,数据分析的前提是“真”,只有“真”才有“好”,只有“真”的取到与业务口径一致的准确数据,才能产出“好”的报表和报告。
那么什么是数据分析的“真”呢?观察业务人员与数据分析师的实际工作,我觉得至少要有三点“真”:
首先是口径是“真”的,也就是数据名称与数据取值口径是一致的,做到“同名同义”。实际工作中,业务人员与数据分析师之间会仔细比较对齐双方的口径理解。
其次是数据是“真”的,也就是数据的统计是来源于企业数据库中正确表的真实值,做到“取对表、用对数”。实际工作中,面对成千上万张数据仓库中的表,数据分析师也面临数据不好找、不敢用、取不对的问题。
最后是血缘是“真”的,也就是口径与数据的“真”,要靠血缘来证明,做到“正本清源”。实际工作中,只有当指标口径、计算逻辑、数据来源之间形成完整的血缘链条,“有源可溯、有据可查”,分析结果才能被验证、被信任。
以上数据分析师遇到的三点“真”,数据 Agent 也一样会遇到。
那么什么是数据分析的“好”呢,观察业务人员与数据分析师的实际工作,我同样觉得至少要有三点“好”:
首先是“听力”要“好”,也就是能听得懂业务的问题,做到“听得懂、答得准”。实际工作中,业务人员提出的数据需求不仅只有公司的业务指标,往往还带有个人、部门或者行业的黑话,数据分析师需要学习建立业务术语与数据口径的对应关系。
其次是“眼力”要“好”,也就是能看得全数据的脉络,做到“看得细、看得透”。实际工作中,面向业绩目标或指标波动,数据分析师需要能够从点带面从更多数据维度中敏锐地捕捉到业务趋势和经营异常,找到业务发力点。
最后是“脑力”要“好”,也就是给出的分析报告能够指导业务动作,做到“想得清、用得上”。实际工作中,数据分析师要帮助业务构建从分析、决策到行动的闭环,打通从指标到标签、从数据到业务的价值流转通道。
以上对数据分析师要求的三点“好”,对数据 Agent 也一样会要求。
只有一个数据 Agent 同时具备“三真”“三好”,才会让人信任,才能从工具到伙伴,才能被称之为“Trusted AI”(可信 AI)。
显而易见,数据 Agent 的“三真”“三好”离不开数据语义层的支持,数据语义层是数据 Agent 实现“Trusted AI”特性的载体和基石,它们的逻辑关系如下表:
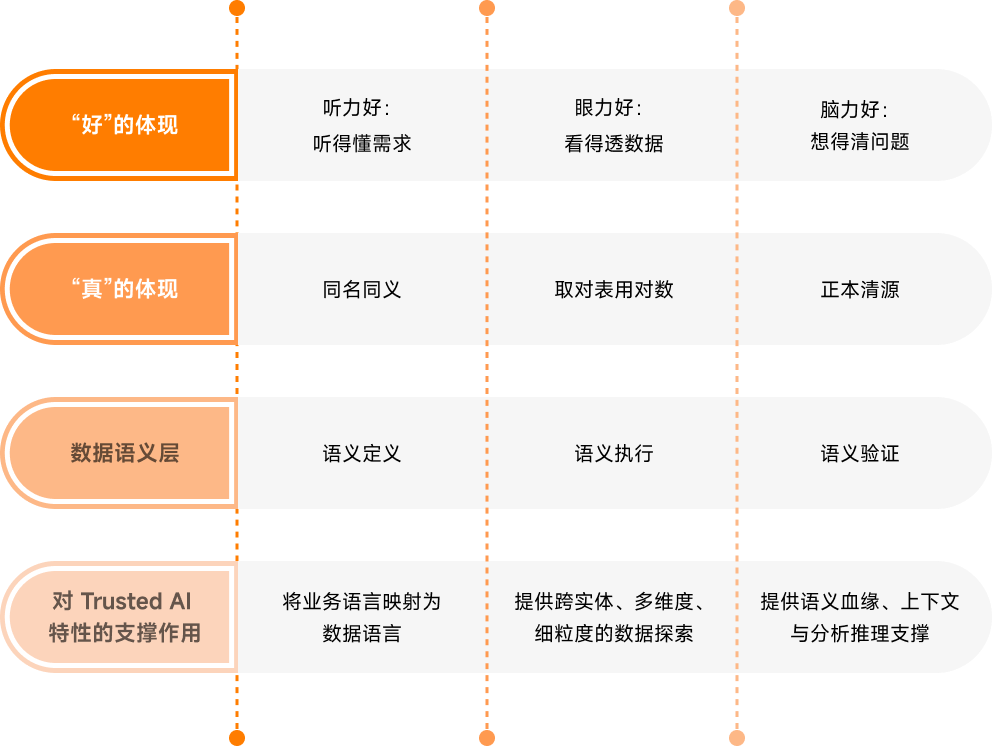
NoETL To Trusted AI
数据 Agent 的“三真”“三好”,也给数据语义层的建设提出要求:
-
“三真”要求数据语义层必须具备“管研用一体化”的能力,否则无法“取对表、用对数”、“正本清源”。
-
“三好”要求数据语义层必须是基于明细数据构建的,否则无法“看得细、看得透”、“想得清、用得上”。
为什么数据语义层必须具备“管研用一体化的能力?因为如果数据口径管理与数据开发割裂,数据指标需要跨工具、跨场景、跨系统重复定义,那么必定管理、开发、应用是三张皮,数据必定会同名不同义、同义不同名。
为什么数据语义层必须是基于明细数据构建的?因为“真理藏在细节里”,数据洞察分析,无论是指标拆解、归因分析,还是人群筛选,都应该是基于同一份明细数据通过跨实体多维度地上卷下钻切片等操作完成。
要基于明细数据构建“管研用一体化”的数据语义层,对数据语义引擎提出了高要求,要求数据语义引擎必须具备强大的 Semantic Fabric(语义编织)能力,不仅能够跨源跨库跨云定义各类复杂指标,还能自动化完成 ETL 编排,并能智能地对语义查询进行 SQL 生成、优化和改写。
具备 Semantic Fabric 能力的数据语义引擎能够在多个 ETL 环节无需 ETL 工程师干预就可以自动完成工作,我称之为“NoETL”。NoETL 的实质是 ETL 自动化,其目标是实现 ETL Agent。
NoETL 由 Aloudata 在全球首次提出,是 Aloudata 对 Semantic Fabric 的技术实现,我们通过自研数据虚拟化和数据语义化技术,完成对数据仓库数据应用层的完全业务语义建模,并创造性地引入“实体”概念,实现指标与标签的打通,让企业在一个数据语义平台中完成从分析、决策到行动的闭环。
至此,我详细描述了我对大数据通往大模型、数据资产成为 AI 资产的理解:“ NoETL To Trusted AI”:
-
大模型要懂大数据,数据 Agent 要成为“Trusted AI”,需要数据语义层。
-
Semantic Fabric 让数据资产变成 AI 资产(AI-Ready Data)。
-
NoETL 是 Aloudata 对 Semantic Fabric 的技术实现。
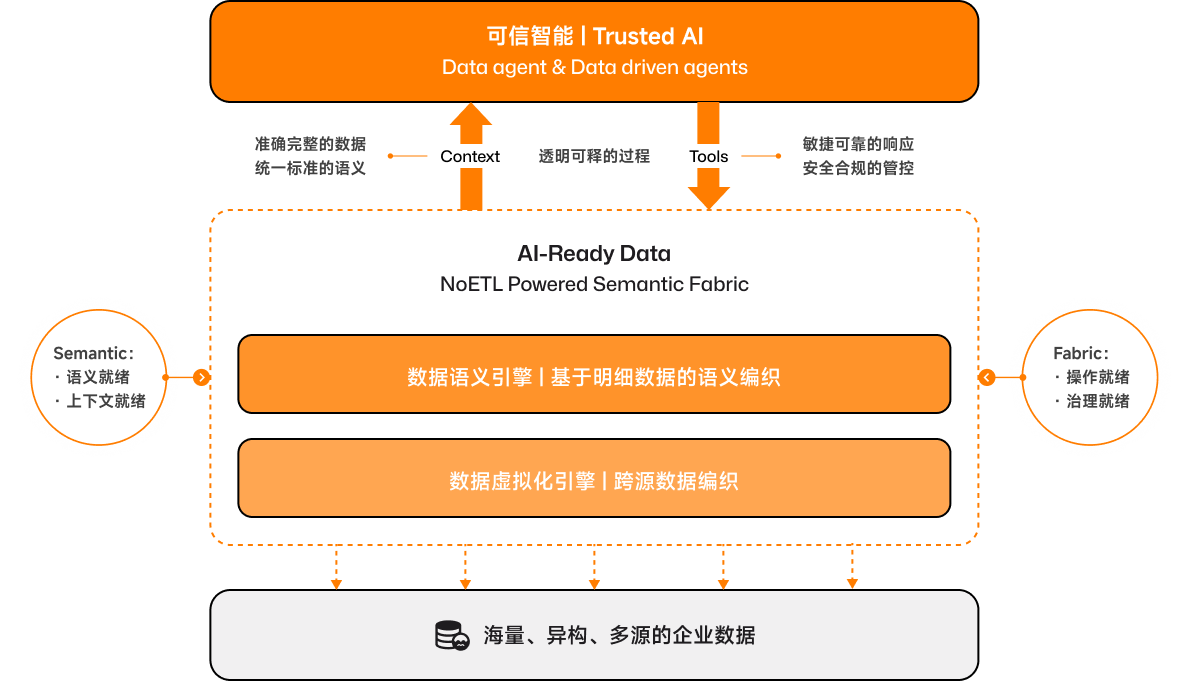
此时此刻,站在 Data 和 AI 的十字路口,我更加坚定:我们正处于 AI 变革的起点,二十年的大数据行业经验、四年多的产品沉淀和数十个与客户共创的经验让我思考——大数据通往大模型、数据资产成为 AI 资产的钥匙就藏在“NoETL To Trusted AI”里。
奔跑吧,Aloudata,好数据创造真智能!
奔跑吧,数据人,一起开启数据智能变革的黄金十年!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)