微调已死?Agentic上下文工程登场,无需微调实现模型进化
同时课程详细介绍了。
斯坦福、SambaNova和UC伯克利团队提出的Agentic Context Engineering(ACE)技术,通过"生成-反思-整合"框架,将上下文视为动态演化的"作战手册",使语言模型无需微调也能实现自我提升。ACE解决了现有方法的"简约偏置"和"上下文塌缩"问题,在智能体任务和金融分析等领域实验中表现优异,性能提升显著。该技术为传统微调提供了更高效、灵活的替代方案,有望成为持续学习的核心机制。
机器之心报道
编辑:Panda
是什么,让一位 AI 自动化架构师发出了「微调已死」的感慨?

一篇来自斯坦福大学、SambaNova、UC 伯克利的论文近日引发了广泛讨论。他们提出了一种名为 Agentic Context Engineering(智能体 / 主动式上下文工程)的技术,让语言模型无需微调也能实现自我提升!

- 论文标题:Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
- 论文地址:https://www.arxiv.org/abs/2510.04618
一切要从上下文适应说起
当代基于大型语言模型(LLM)的 AI 系统(如 LLM 智能体与复合式 AI 系统)越来越依赖于上下文自适应(context adaptation)。
具体来说,上下文自适应是在模型训练完成后,通过在输入中引入更明确的指令、结构化的推理步骤或领域特定的输入格式,从而提升模型性能。很显然,这与直接修改模型参数的微调方法大不相同。
我们知道,上下文构成了众多 AI 系统组件的基础,包括:引导下游任务的系统提示词、承载既往事实与经验的记忆机制以及用于减少幻觉、补充知识的事实证据。
而与参数更新相比,通过上下文进行适应具有若干核心优势:上下文对于用户与开发者而言更具可解释性;能够在运行时快速整合新知识;并且可以在复合系统的多个模型或模块之间共享。与此同时,长上下文语言模型的进展以及高效推理机制(如 KV 缓存复用)也使基于上下文的方法愈发具有现实可行性。因此,上下文自适应正逐渐成为构建高性能、可扩展且具备自我改进能力的 AI 系统的核心范式。
然而,现有上下文自适应方法仍存在两大局限。
其一是「简约偏置」(brevity bias):许多提示词优化器倾向于追求简洁、普适的指令,而忽略了知识的充分积累。例如,GEPA 将简短视为优点,但这种抽象化可能遗漏实践中至关重要的领域启发式规则、工具使用指南或常见错误模式。此类优化目标虽能在部分指标上奏效,却常无法捕捉智能体或知识密集型应用所需的细节策略。
其二是「上下文塌缩」(context collapse):依赖 LLM 对整体提示进行重写的方式,往往会随着时间推移退化为更短、更模糊的摘要,从而造成性能骤降(见图 2)。在诸如交互式智能体、领域特定编程、以及金融或法律分析等任务中,系统性能依赖于保留细致的、任务相关的知识,而非将其压缩掉。
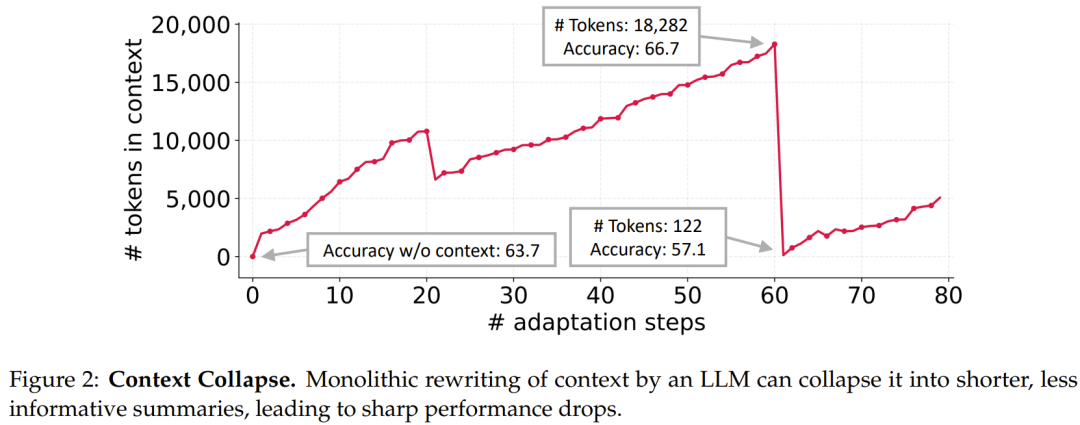
随着智能体与知识密集型推理对可靠性的要求不断提高,近期研究逐渐转向构建「信息饱和」的上下文,也就是借助长上下文 LLM 的进展来容纳更多潜在有用信息。
但这个斯坦福大学、SambaNova、UC 伯克利联合团队认为:上下文不应是简短的摘要,而应成为全面、动态演化的「作战手册(playbooks)」—— 内容详实、包容、富含领域洞见。与人类不同,LLM 在提供长而细致的上下文时表现更好,并能自主提炼关键信息。因此,与其压缩领域启发与策略,不如将其保留,让模型在推理时自行决定哪些信息最为重要。
在这一见解的基础上,主动式上下文工程(ACE)应运而生。
主动式上下文工程(ACE)
该团队提出的 ACE(Agentic Context Engineering) 框架能够实现可扩展且高效的上下文自适应,并且离线(如系统提示优化)与在线(如测试时记忆自适应)场景都适用。
与以往将知识蒸馏为简短摘要或静态指令的方法不同,ACE 是将上下文视为不断演化的作战手册,能够持续积累、蒸馏与组织策略。
基于 Dynamic Cheatsheet(参阅 arXiv:2504.07952)的 agentic 架构,ACE 引入三种协作角色:
- 生成器(Generator):生成推理轨迹;
- 反思器(Reflector):从成功与错误中蒸馏具体洞见;
- 整编器(Curator):将这些洞见整合进结构化的上下文更新。
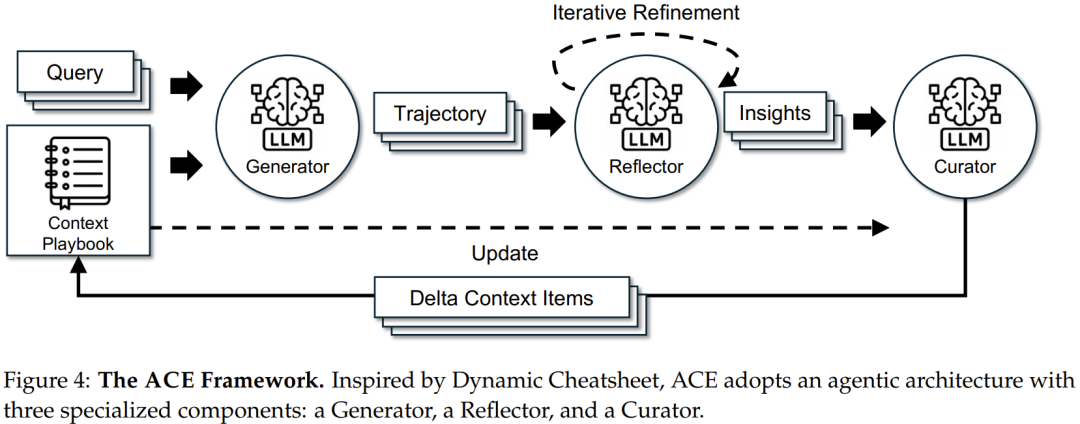
这一设计模仿了人类的学习方式,即「实验–反思–整合」,同时可避免让单一模型承担所有职能所导致的瓶颈。
为应对前文提到的简约偏置与上下文塌缩问题,ACE 引入了三项关键创新:
- 专职反思者模块:将评估与洞见提取与整编(curation)过程解耦,提高上下文质量与下游性能;
- 增量式 Delta 更新机制:以局部编辑替代整体重写,显著降低延迟与计算开销;
- grow-and-refine 机制:在持续扩充的同时抑制冗余,实现上下文的稳态演化。
在工作流程上,生成器首先会针对新任务生成推理轨迹,揭示出有效策略与常见陷阱;反思器对这些轨迹进行评析,提炼经验并可多轮迭代优化;整编器再将这些经验整合为紧凑的增量条目(delta entries),并通过轻量的、非 LLM 的逻辑机制合并至现有上下文中。
由于更新项是局部化的,多个增量可并行合并,从而实现批量适应与扩展。ACE 还支持多轮(multi-epoch)自适应,使相同任务可被多次重访以持续强化上下文。
增量式 Delta 更新
ACE 的核心设计理念是:将上下文表示为结构化的条目集合(bullets),而非单一的整体提示词。
每个条目包含两部分:
- 元数据(metadata):唯一标识符,以及「有用 / 有害」计数器;
- 内容(content):比如可复用策略、领域概念或常见错误模式。
在解决新问题时,生成器会标记哪些条目起到了帮助或误导作用,从而为反思器提供改进依据。
这种条目化设计带来了三大特性:
- 局部化(localization):只更新相关条目;
- 细粒度检索:生成器可聚焦于最相关的知识;
- 增量式适应:推理时可高效进行合并、剪枝与去重。
ACE 不会重写整个上下文,而是生成紧凑的增量上下文(delta contexts):由反思器提炼、整编器整合的一小组候选条目。
这种方式既避免了整体重写的高计算成本与延迟,又能保持旧知识并持续吸收新见解。随着上下文的增长,该机制为长周期或高知识密度的任务提供了必要的可扩展性。
Grow-and-Refine
在持续增长的基础上,ACE 通过定期或延迟蒸馏来确保上下文保持紧凑与相关性。
在 Grow-and-Refine 过程中,新条目会被追加到上下文中,而已有条目则通过元数据更新(如计数器递增)进行原地修订。
去重步骤则通过语义嵌入比较条目相似度来消除冗余。
该过程可在每次增量更新后主动执行,也可在上下文窗口超限时被动触发,具体取决于延迟与精度要求。
增量更新与 Grow-and-Refine 机制共同维持了上下文的动态可扩展性与高相关性。
ACE 的效果如何?
该团队进行了实验,对新提出的方法进行了验证。
具体来说,他们在两类任务上进行了实验:智能体类任务与领域特定任务。
- 智能体任务采用 AppWorld 基准,该基准涵盖多轮推理、工具调用与环境交互等复杂行为,包含不同难度的场景(普通与挑战模式),并设有公开排行榜以评估智能体的真实表现。
- 领域特定任务则聚焦于金融分析,使用 FiNER 与 Formula 两个数据集:前者要求识别 XBRL 财报文档中的细粒度实体类型,后者则考察模型在结构化财报中的数值推理与计算能力。
而作为对比的基线方法则包括以下几种:
- ICL(In-Context Learning):通过在输入中提供示例演示实现少样本学习;
- MIPROv2 与 GEPA:两种主流提示优化算法,分别基于贝叶斯优化与反思进化策略;
- Dynamic Cheatsheet(DC):一种测试时自适应记忆机制,可积累可复用的策略与知识。
相比之下,ACE 在相同基模型与运行条件下,通过其「生成–反思–整合」的主动上下文工程框架,实现了更高的准确度、更快的适应速度以及更低的计算成本。
实验下来,ACE 表现优异,下图给出了其整体表现 —— 毫无疑问地优势明显。
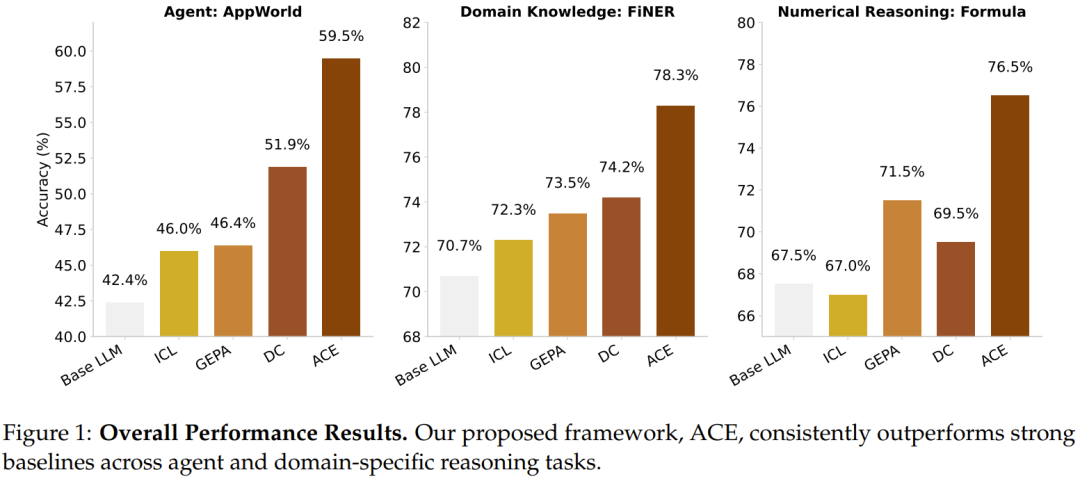
首先,ACE 确实能实现高性能、自我改进的智能体。
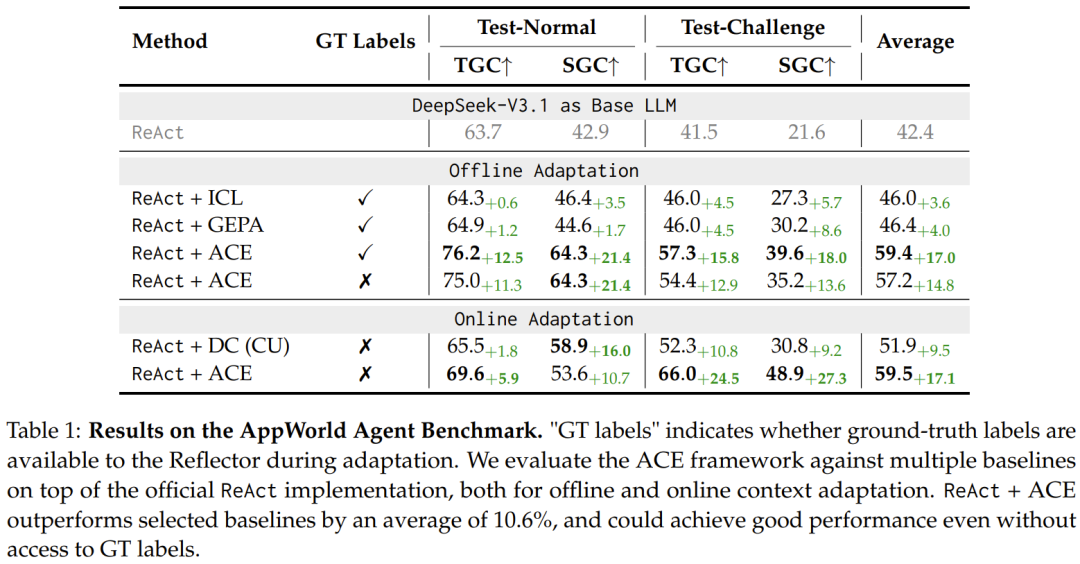
通过动态优化输入上下文,ACE 实现了智能体的自我改进。在 AppWorld 基准上,ACE 在无需标注数据的情况下,仅凭执行反馈就能提升性能高达 17.1%,使开源小模型的表现接近最强商用系统。
下图展示了在 AppWorld 基准上,ACE 生成的上下文示例(部分)。可以看到,ACE 生成的上下文包含了详细的、领域特定的洞见,以及可直接使用的工具与代码,构成了一个面向大型语言模型应用的完整「作战手册」。

同时,ACE 也能大幅提升在领域特定任务上的表现:在复杂的金融推理任务中,ACE 通过构建含丰富领域知识的「作战手册」,平均性能提升 8.6%。
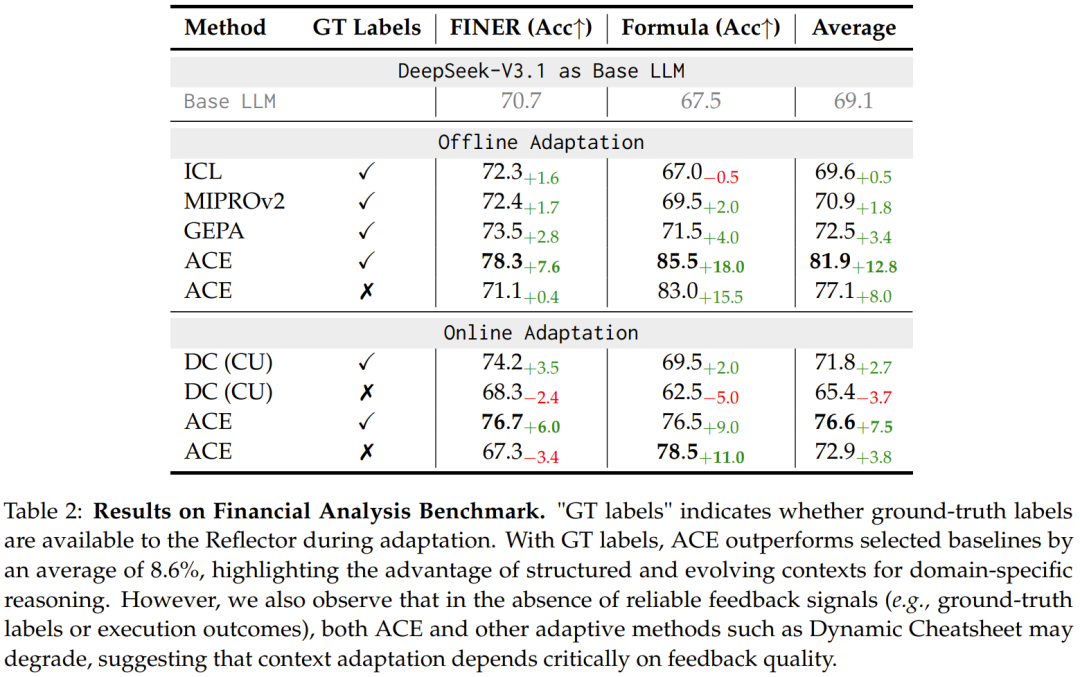
该团队也通过消融实验验证了其新设计的有效性,结果表明:反思器与多轮蒸馏等组件对性能提升至关重要。
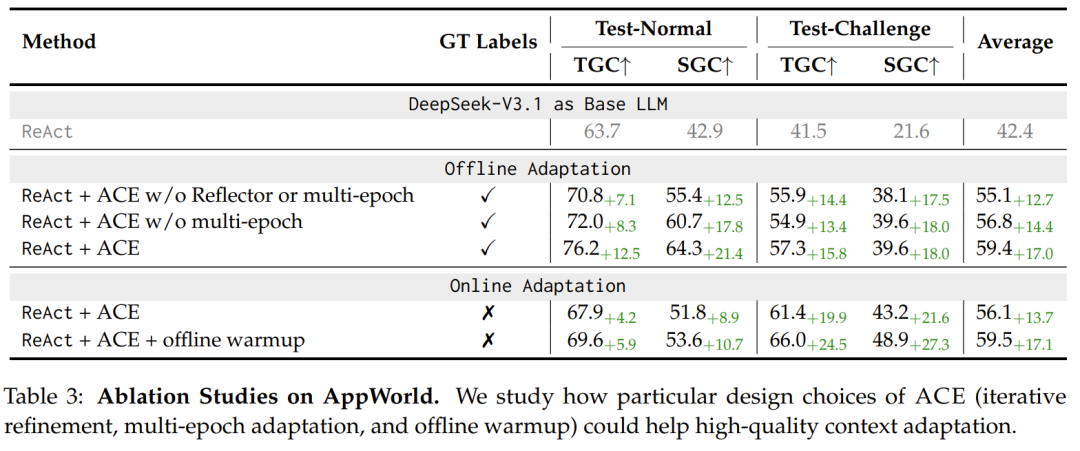
最后,该团队也分析了 ACE 的成本与延迟,发现这两个指标都有显著下降:ACE 通过增量更新与轻量化合并机制,使适应延迟平均降低 86.9%,并减少了生成消耗。
至于 ACE 究竟能否做到让「微调已死」,还需要读者您自己判断,毕竟该研究也在网上遭到了一些批评。

结语
该团队总结道:「长上下文 ≠ 更高 Serving 成本。」尽管 ACE 生成的上下文比 GEPA 等方法更长,但并不会导致推理成本或显存使用线性增加。
现代 serving 基础设施已通过 KV 缓存复用、压缩与卸载等机制,对长上下文负载进行了优化,使得常用的上下文片段可被缓存,避免重复计算。随着系统层优化的持续进步,长上下文方法(如 ACE)的实际部署成本将进一步下降。
同时,该团队还分析了这项研究对在线与持续学习带来的启示。
在线学习与持续学习是应对分布漂移(distribution shifts)与训练数据有限性的重要方向。ACE 为传统模型微调提供了一种灵活且高效的替代方案:更新上下文通常比更新模型参数更低成本,同时具备可解释性,还可能实现选择性遗忘(selective unlearning)—— 这可用于隐私保护、合规以及剔除错误或过时信息。
该团队认为,ACE 未来有望成为推动持续学习与负责任学习的核心机制之一。
那么,如何系统的去学习大模型LLM?
如果你也想系统学习AI大模型技术,想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习*_,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献239条内容
已为社区贡献239条内容

所有评论(0)