爆款预定:NeurIPS 2025 顶会爆款!吴恩达团队 DeepCluster++ 框架,让 CRC 病理 AI 泛化性碾压现有方案!
今天给大家分享一下吴恩达团队NeurIPS 2025新作:STARC-9。随着数字病理普及,深度学习驱动的多类别组织分类成为核心基础任务,可支撑多种下游应用并减轻医生负担。但现有公开 CRC 数据集存在形态多样性不足、类别不平衡、含错标或低质量切片等痛点,且传统人工标注数据集耗时主观,缺乏标准化构建框架,严重阻碍鲁棒 AI 模型开发。为此,吴恩达团队推出大规模高质量数据集 STARC-9 与 De
今天给大家分享一下吴恩达团队NeurIPS 2025新作:STARC-9。随着数字病理普及,深度学习驱动的多类别组织分类成为核心基础任务,可支撑多种下游应用并减轻医生负担。但现有公开 CRC 数据集存在形态多样性不足、类别不平衡、含错标或低质量切片等痛点,且传统人工标注数据集耗时主观,缺乏标准化构建框架,严重阻碍鲁棒 AI 模型开发。为此,吴恩达团队推出大规模高质量数据集 STARC-9 与 DeepCluster++ 框架,旨在破解上述困境,为 CRC 病理 AI 研究提供可靠数据支撑。
本篇论文代码以及【CV 热门 80+ 】计算机视觉热门方向论文合集已经整理好,感兴趣的自取希望能帮到你!
1. 【导读】

论文标题:STARC-9: A Large-scale Dataset for Multi-Class Tissue Classification for CRC Histopathology
作者:Barathi Subramanian*, Rathinaraja Jeyaraj*, Mitchell Nevin Peterson, Terry Guo, Nigam Shah, Curtis Langlotz, Andrew Y. Ng, Jeanne Shen
作者机构:Stanford University, USA;DeepLearning.AI, USA
论文来源:NeurIPS 2025
论文链接:https://openreview.net/forum?id=rGWjTlK6Ev
代码数据链接:https://huggingface.co/datasets/Path2AI/STARC-9/tree/main;https://github.com/Path2AI/STARC-9/
2. 【论文速读】
结直肠癌(CRC)病理图像多类别组织分类需优质数据集,而现有公开数据集存在形态多样性不足等问题。为此,吴恩达团队推出STARC-9数据集(63万张切片,覆盖9类临床相关组织),通过DeepCluster++ 框架构建:经自编码器提特征、聚类+等频分箱采样后,由病理学家验证确保质量。基准测试显示,基于该数据集训练的模型在下游任务中展现更优泛化性,且框架可灵活复用于各类WSI数据集构建。
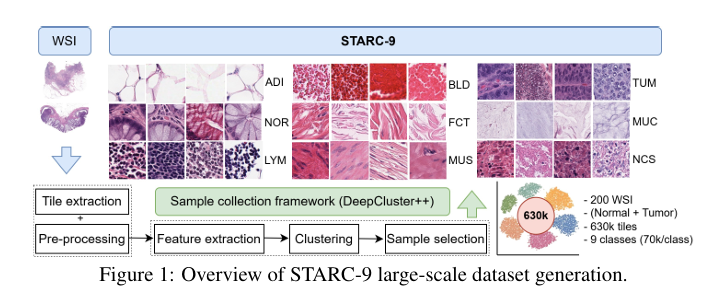
3.【破解CRC病理AI困境:为何需要STARC-9与新框架?】
3.1 研究背景
- CRC临床重要性:结直肠癌(CRC)是全球第三大常见癌症、第二大癌症相关死亡原因,病理组织评估对诊断、预后判断及治疗决策至关重要。
- AI技术需求:数字病理普及下,深度学习驱动的多类别组织分类是核心基础任务,可支撑组织分割、生物标志物预测等下游应用,还能减轻病理医生诊断负担。
- 现有数据集瓶颈:公开CRC数据集存在三大问题——①形态多样性不足,无法覆盖组织各类外观;②类别不平衡,优势组织(如肿瘤上皮)样本远超关键小众组织(如黏液、坏死);③含错标/低质量切片,影响模型可解释性与性能。
- 构建流程痛点:传统数据集依赖人工标注,耗时且主观,难保证组织形态全覆盖;无标准化框架,进一步阻碍鲁棒模型开发。
3.2 相关工作
3.2.1 现有CRC公开数据集
- NCT-CRC-HE-100K:早期重要贡献,含10万张224×224像素切片(9类组织),但存在JPEG压缩伪影。
- HMU-GC-HE-30K:胃癌相关数据集(3万张切片),部分组织类别与CRC重叠,但含错标切片,易让模型学习虚假特征。
- TCGA-COAD/READ:仅提供未标注全切片图像(WSI),需手动提取切片才能用于机器学习,实用性受限。
- 其他数据集:多存在访问受限、标注不完整等问题,难以支撑高质量模型训练。
3.2.2 现有数据集构建方法
- 手动标注:依赖QuPath等工具,耗时主观,易偏向“易标注区域”,漏检罕见形态且难平衡类别。
- 随机采样:易出现采样误差,错过临床关键罕见形态,导致组织异质性表征失衡。
- 深度聚类:虽能自动分组切片,但偏向聚类中心采样,低估类内变异,不利于模型鲁棒性。
- 主动学习:需预标注种子数据且迭代标注,流程复杂,不适用于大规模数据集构建。
4.【三步解锁CRC病理数据集新范式:DeepCluster++的硬核操作指南】
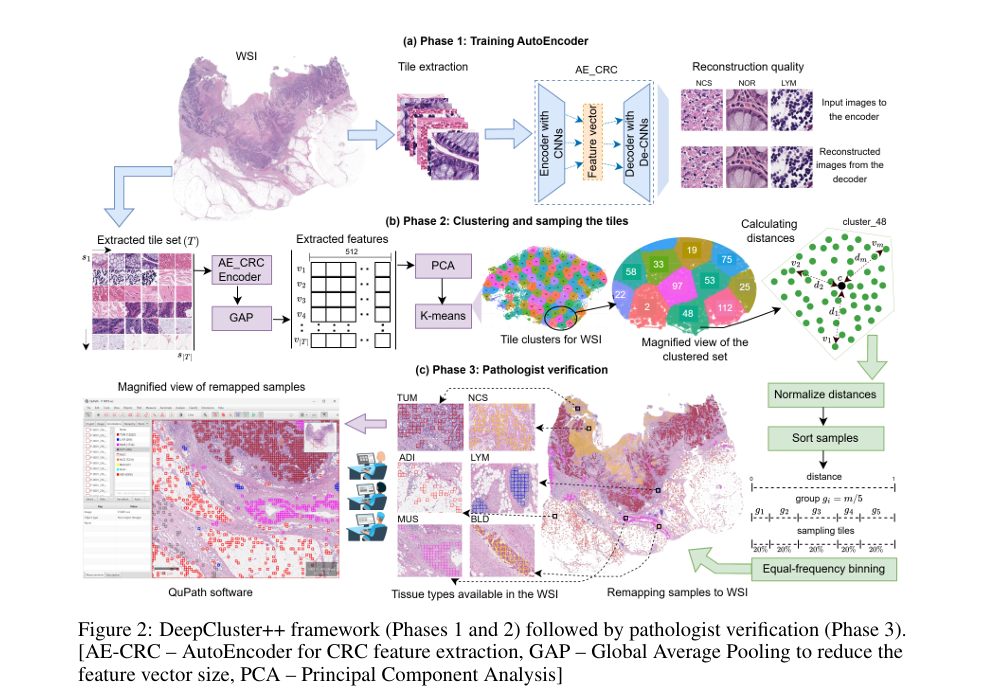
4.1 阶段1:自编码器训练(AE_CRC)—— 提取领域特异性特征
为捕捉CRC病理切片的精细形态特征,先训练专属自编码器(AE_CRC),核心步骤如下:
- 训练数据准备:从10个独立于STARC-9的代表性WSI(5个肿瘤、5个正常组织)中,采样10万张256×256像素切片,覆盖全部9类组织;通过直方图阈值法(32倍下采样、25%组织占比阈值)提取切片,同时去除伪影和空白切片。
- 数据增强与模型结构:采用随机旋转、翻转、仿射变换、颜色抖动、高斯模糊等增强手段;编码器含6个卷积层(带批量归一化和Leaky ReLU激活),输出32768维 latent 向量;解码器结构对称,以反卷积层构建,最终层用sigmoid激活实现切片重建。
- 损失函数选择:使用结构相似性指数(SSIM)损失函数,优先捕捉病理切片的结构、纹理等关键特征,而非仅优化像素级误差;对比MSE损失,AE_CRC重建质量更优(验证集平均SSIM 0.9262 vs 0.8863)。
- 核心优势:相比通用病理基础模型,AE_CRC计算成本更低,且能生成更贴合CRC组织形态的特征嵌入,为后续聚类提供可靠基础。
4.2 阶段2:聚类与切片采样—— 保障组织形态多样性
基于AE_CRC的冻结编码器生成特征,通过聚类+分箱采样实现“无偏覆盖”,步骤如下:
- 特征降维与聚类:
- 设某WSI的切片集为 T = { s 1 , s 2 , . . . , s ∣ T ∣ } T=\{s_{1}, s_{2}, ..., s_{|T|}\} T={s1,s2,...,s∣T∣},每个切片 s i s_i si经编码器生成32768维向量 v i v_i vi;
- 用全局平均池化(GAP)将 v i v_i vi压缩至512维,再通过主成分分析(PCA)降至256维,降低计算复杂度;
- 采用K-means算法聚类,设聚类数量 m = 400 m=400 m=400(经实验验证: m < 400 m<400 m<400会减少形态变异, m > 400 m>400 m>400易混入多类组织),确保同类切片形态相似且不同聚类覆盖多样模式。
- 等频分箱与采样:
- 对每个聚类,计算中心 c c c与切片的欧氏距离 d i = ∥ v i − c ∥ d_{i}=\left\|v_{i}-c\right\| di=∥vi−c∥,并归一化至[0,1];
- 按距离排序后进行等频分箱(设箱数 g = 5 g=5 g=5, g < 5 g<5 g<5易导致样本重叠, g > 5 g>5 g>5易碎片化),每个箱含等量切片;
- 从每个箱采样20%切片,确保同时覆盖“聚类中心(典型形态)”和“聚类边缘(罕见形态)”,避免采样偏差。
- 聚类标签关联:手动标注1个“种子聚类”(如标注为“肿瘤(TUM)”),利用嵌入空间邻近性,将语义标签推广至邻近聚类(如聚类48的邻近聚类2、97等也标注为TUM),大幅减少手动标注量。
4.3 阶段3:病理学家验证与数据集组装—— 确保临床准确性
通过专家审核把关,形成最终高质量数据集,关键步骤:
- 切片定位与审核:用QuPath软件将采样切片映射回原WSI,方便病理学家结合组织空间位置验证类别;参与审核的3名胃肠(GI)病理学家均为-board认证,分别拥有13年、41年、15年经验,其中2人审核子集,1人全面复核63万张切片。
- 数据集规模固定:为保证类别平衡,每类组织最终保留7万张切片,9类共63万张,构成STARC-9数据集;该数量可根据下游任务需求调整(如小样本任务可减少单类切片数)。
- 质量控制结果:经审核后,切片类别准确率显著提升,排除错标、低质量样本,为后续模型训练提供可靠“金标准”数据。
5.【STARC-9实战成绩单:模型性能与泛化性双丰收】
5.1 核心结果1:多类别组织分类性能碾压
- STARC-9训练模型优势显著:
- 基线模型:EfficientNet-B7在STARC-9上达98.80%准确率,比NCT(82.47%)高14.7%、HMU(84.45%)高8.6%;
- 病理基础模型:CTransPath(87M参数)达99%准确率,远超NCT上的UNI(80.43%)、HMU上的HiPT(91.99%);
- 自定义模型:从头训练的CNN也达97.81%准确率,证明数据质量比预训练更关键。
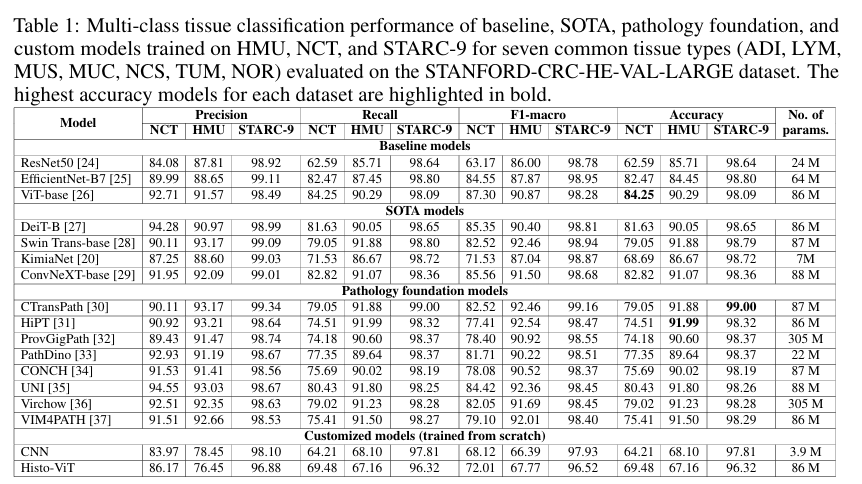
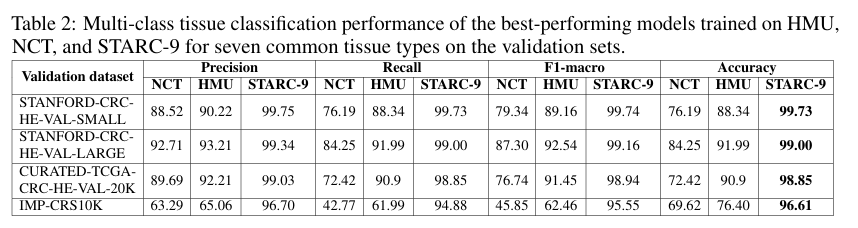
- 泛化性突出:在TCGA-CRC验证集上,STARC-9训练模型准确率98.85%,远超NCT(72.42%)、HMU(90.9%)。
5.2 核心结果2:肿瘤分割任务表现优异
- IoU评分:混合组织样本中,STARC-9模型IoU 92.91%(NCT 73.39%、HMU 71.6%);纯肿瘤样本IoU 99.48%(NCT 84.17%、HMU 92.17%)。
- Dice评分:斯坦福验证集达90.47%(NCT高14%、HMU高17%),TCGA集达89.38%(NCT高35%、HMU高23%);且标准差更小,分割更稳定。

5.3 可视化佐证:模型聚焦诊断关键区域
- 特征图:STARC-9训练模型能精准聚焦肿瘤、正常黏膜等诊断区域,而NCT/HMU模型常激活无关区域(如混合组织切片中,仅STARC-9模型正确识别肿瘤)。

- 组织图:STARC-9模型对坏死(NCS)分类准确率比HMU高45%、NCT高90%;混合切片分类准确率85%,远超HMU(55%)、NCT(42%)。

6.【STARC-9的现在与未来:CRC病理AI的新起点与待解方向】
本研究提出针对CRC病理的大规模高质量数据集STARC-9(含63万张切片、覆盖9类临床相关组织),并通过DeepCluster++框架(自编码器提特征+聚类分箱采样+病理学家验证)解决现有数据集形态多样性不足、类别不平衡等痛点;实验证实,基于STARC-9训练的模型在多类别组织分类(准确率超98%)与肿瘤分割任务中,泛化性显著优于基于NCT、HMU等公开数据集训练的模型。但STARC-9仍存局限:未穷尽CRC resection中所有组织类型、仅覆盖CRC(对其他癌症适用性待验证)、样本源自单机构且少数族裔代表性不足;未来可拓展细分类别、增加多模态数据(如图像-文本对)、将框架应用于其他癌症,并整合多中心数据以提升模型公平性与泛化性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 16
16 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)