MySQL索引从入门到精通:让查询效率提升100倍的实战指南
MySQL索引是提升查询性能的关键技术,但也不是越多越好。好的索引设计需要深入理解业务需求,结合表结构和查询模式,才能创建出高效的索引。记住,没有放之四海而皆准的索引设计规则,最好的方法是:理解业务查询需求创建合适的索引使用EXPLAIN分析查询计划根据实际性能反馈调整索引希望本文能帮助你掌握MySQL索引技术,让你的数据库查询性能提升一个台阶!如果你有任何问题或建议,欢迎在评论区留言讨论。
为什么你需要学习MySQL索引
想象一下,当你在图书馆找一本书时,如果没有图书分类目录,你可能需要翻遍整个图书馆才能找到目标书籍。MySQL索引就相当于图书馆的分类目录,它能让数据库查询效率提升几十倍甚至上百倍!
在实际开发中,一个未加索引的查询可能需要10秒才能返回结果,而添加合适的索引后,相同的查询可能只需要0.01秒。这就是为什么每个MySQL开发者都必须掌握索引技术的原因。
索引基础:四大类型及其应用场景
主键索引:表的"身份证"
主键索引是表中最重要的索引,它就像每个人的身份证号码,唯一标识一行数据。在创建表时指定主键,MySQL会自动创建主键索引。
定义:专门针对表中主键创建的索引,在建表时若指定了主键,数据库会自动为该主键创建索引。主键索引在一张表中只能有一个,对应的关键字为primary。
创建示例:
CREATE TABLE TB_user(
id INT PRIMARY KEY, -- 主键字段,自动创建主键索引
name VARCHAR(20)
);
使用场景:当需要通过唯一标识快速定位一行数据时使用,例如用户ID、订单编号等。
唯一索引:确保数据不重复
唯一索引用于保证字段值的唯一性,就像我们生活中的手机号,每个人的手机号都是唯一的。当为字段添加唯一约束时,MySQL会自动创建唯一索引。
定义:用于避免表中某字段的值重复,一张表中可以有多个唯一索引,对应的关键字为unique。值得注意的是,当为字段添加唯一约束时,数据库会自动为该字段创建唯一索引。
创建示例:
-- 方式一:创建表时指定
CREATE TABLE TB_user(
id INT PRIMARY KEY,
phone VARCHAR(20) UNIQUE -- 唯一约束,自动创建唯一索引
);
-- 方式二:ALTER语句添加
ALTER TABLE TB_user ADD UNIQUE (phone);
使用场景:适用于需要唯一标识但不是主键的字段,如手机号、邮箱地址等。
常规索引:提升查询速度的利器
常规索引是最常用的索引类型,它没有唯一性约束,主要用于加速查询操作。
定义:核心作用是快速定位数据,无唯一性要求,一张表中可创建多个,是日常开发中使用频率较高的索引类型。
创建示例:
-- 方式一:CREATE INDEX语句
CREATE INDEX idx_user_name ON TB_user(name);
-- 方式二:CREATE TABLE时指定
CREATE TABLE TB_user(
id INT PRIMARY KEY,
name VARCHAR(20),
INDEX idx_user_name (name) -- 常规索引
);
使用场景:适用于WHERE子句中频繁出现的查询条件字段,如用户名、商品名称等。
全文索引:文本内容搜索专家
全文索引与其他索引不同,它不匹配索引中的具体值,而是检索文本内容中的关键字,适用于文章内容、评论等大段文本的搜索。
定义:与其他索引不同,它不匹配索引中的具体值,而是检索文本内容中的关键字,对应的关键字为fulltext,在实际开发中使用相对较少。
创建示例:
-- 创建表时指定全文索引
CREATE TABLE article(
id INT PRIMARY KEY,
content TEXT,
FULLTEXT INDEX idx_article_content (content)
);
-- 使用全文索引查询
SELECT * FROM article
WHERE MATCH(content) AGAINST('数据库 索引');
使用场景:适用于对大段文本进行关键字搜索的场景,如博客内容、新闻文章等。
InnoDB索引原理:B+树与数据存储的完美结合
B+树结构:MySQL索引的底层实现
MySQL索引的底层数据结构是B+树,这是一种平衡多路查找树,它能让查询操作更加高效。B+树的结构类似于一棵倒挂的树,分为根节点、中间节点和叶子节点。
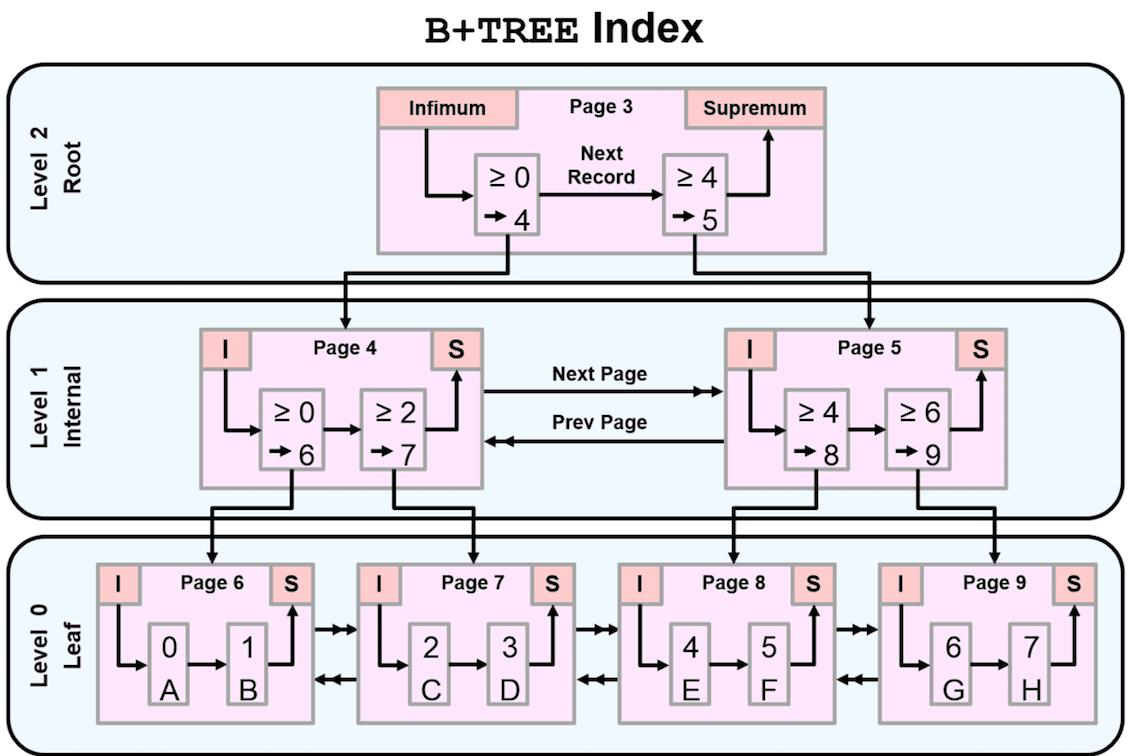
B+树的特点:
-
层级少:通常2-3层就能存储千万级数据
-
叶子节点相连:所有叶子节点通过指针连接,便于范围查询
-
有序排列:节点中的数据按顺序排列,支持二分查找
聚集索引:数据即索引,索引即数据
在InnoDB存储引擎中,表的数据按照聚集索引的顺序存储,也就是说聚集索引的叶子节点就是数据本身。
定义:将数据存储与索引结构融合在一起,索引的叶子节点直接保存了完整的行数据。聚集索引是表的"基础索引",一张表必须有且只能有一个,否则表中的行数据无法有序存储。
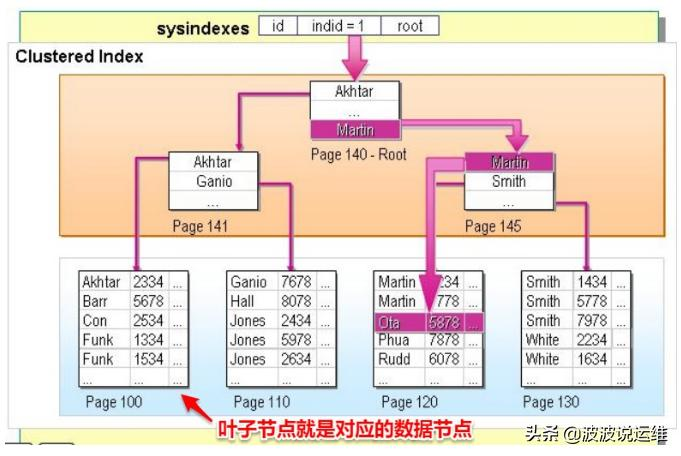
聚集索引的选取规则:
-
优先以主键索引作为聚集索引
-
若表中无主键,则选取第一个唯一索引作为聚集索引
-
若既无主键也无唯一索引,InnoDB引擎会自动生成一个隐藏的Rowid作为聚集索引
示例说明:当我们创建一个以id为主键的表时,id的主键索引就是聚集索引,该索引的B+树叶子节点上不仅存储了id值,还包含了该行的所有字段数据。
二级索引:指向数据的"指针"
除了聚集索引外,表上的其他所有索引都称为二级索引(也叫辅助索引)。二级索引的叶子节点不存储完整行数据,只存储索引字段值和对应的主键值。
定义:又称辅助索引、非聚集索引,索引结构与数据存储分开,其B+树的叶子节点不存储完整行数据,仅关联对应行的主键值。一张表中可以创建多个二级索引。
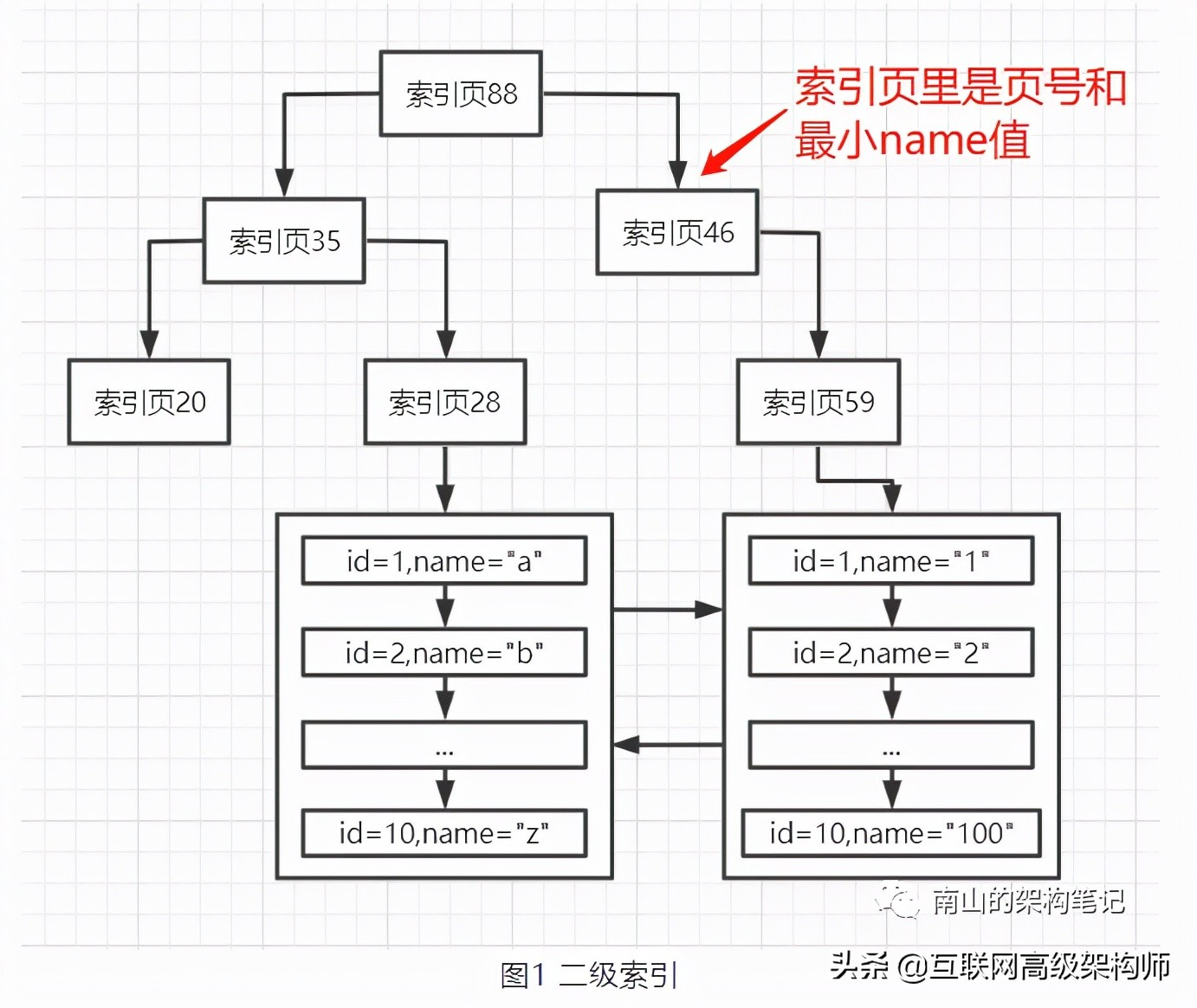
示例说明:为name字段创建的常规索引就是二级索引,该索引的叶子节点中存储的是name值和对应的id值(如name='张三'对应id=10),而非张三的完整用户信息。
索引查询原理:为什么有些查询更快
回表查询:二级索引的"二次查找"
当使用二级索引查询数据时,如果查询的字段不是索引字段或主键,就需要先通过二级索引找到主键值,再通过主键到聚集索引中获取完整数据,这个过程称为回表查询。
定义:通过二级索引查询数据时,先在二级索引中找到对应的主键值,再通过主键值到聚集索引中获取完整行数据,这个"二次查询"的过程就是回表查询。
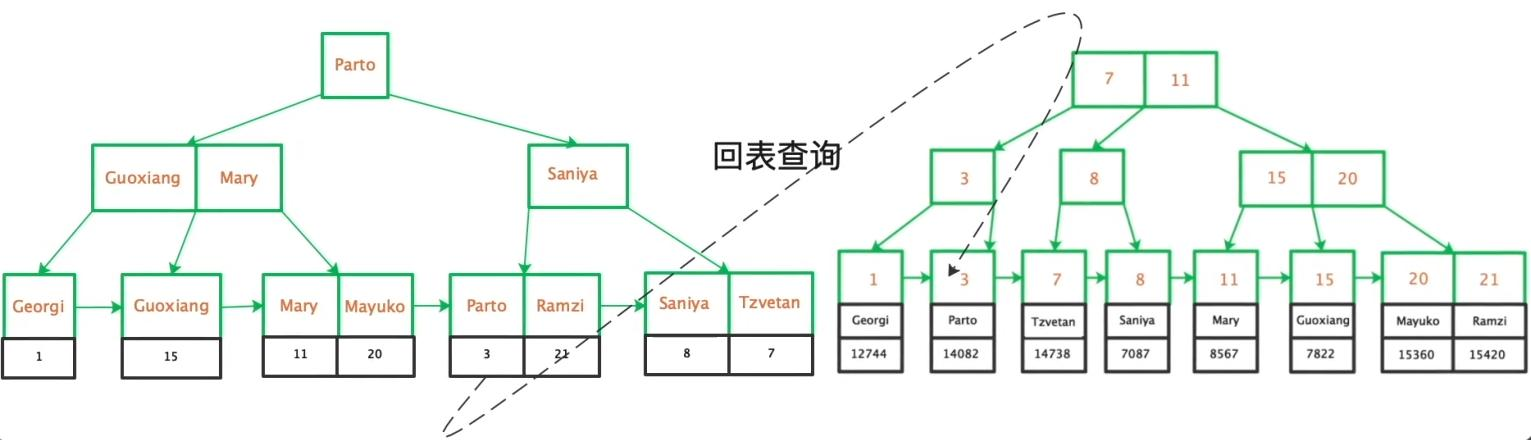
示例说明:执行SELECT * FROM TB_user WHERE name = '张三'时:
-
第一步:在name字段的二级索引中找到name='张三'对应的主键id=10
-
第二步:拿着id=10到聚集索引中,找到id=10对应的完整行数据
-
最终返回查询结果
索引覆盖:避免回表的查询技巧
如果查询的字段全部包含在二级索引中,MySQL会直接从二级索引中获取数据,而不需要回表查询,这种情况称为索引覆盖。
示例:
-- 假设为name字段创建了二级索引
-- 这个查询需要回表,因为查询了所有字段
SELECT * FROM TB_user WHERE name = '张三';
-- 这个查询不需要回表,因为只查询了索引字段和主键
SELECT id, name FROM TB_user WHERE name = '张三';
SQL查询性能对比:为什么主键查询更快
我们通过一个实例来对比不同索引的查询性能差异:
题目:对比两条SQL的执行效率
-
SELECT * FROM TB_user WHERE id = 10(id是主键)
-
SELECT * FROM TB_user WHERE name = '张三'(name已创建索引)
性能分析:
-
语句①:直接通过聚集索引查询,找到id=10对应的叶子节点,即可获取完整行数据,仅需一次索引扫描
-
语句②:需先通过name的二级索引找主键,再到聚集索引查数据,需两次索引扫描且包含回表查询
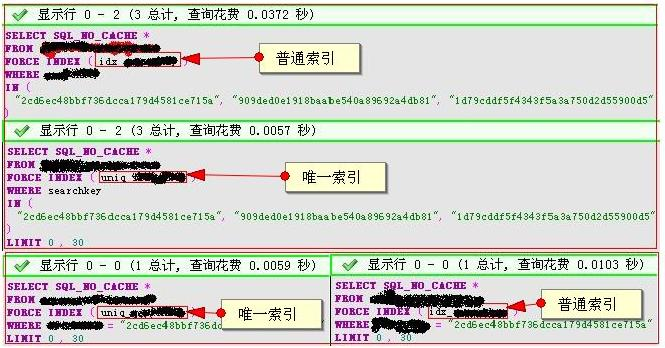
结论:语句①的执行效率远高于语句②,因为主键查询不需要回表,直接通过聚集索引即可获取完整数据。
B+树高度计算:为什么MySQL查询这么快
InnoDB中B+树的高度直接影响查询性能,我们来估算一下B+树的存储能力:
核心前提假设:
-
InnoDB中B+树的每个节点对应磁盘上的一个页,每页大小固定为16KB
-
一行数据大小假设为1KB
-
InnoDB指针占用6字节
-
主键类型为bigint(占用8字节)
-
非叶子节点仅存储主键值和指针,且指针数量永远比主键值数量多1
高度为2时的存储能力:
非叶子节点可存储的主键值数量n满足公式:8n + 6(n+1) = 16×1024
计算得出n≈1170,即非叶子节点有1170个主键值和1171个指针
每个指针指向的叶子节点(数据页)可存储16行数据(16KB÷1KB=16)
总数据量≈1171×16=18736条
高度为3时的存储能力:
在高度2的基础上,根节点的每个指针指向一个高度2的子B+树
总数据量≈1171×1171×16≈2200万条
结论:InnoDB表存储2200万条以内数据时,主键索引B+树高度仅为3,检索效率极高;当数据量达四五千万甚至上亿时,树高可能超过3,此时需考虑分库分表。
索引操作实战:创建、查看与删除
索引操作核心语法
创建索引
-- 创建常规索引
CREATE INDEX idx_user_name ON TB_user(name);
-- 创建唯一索引
CREATE UNIQUE INDEX idx_user_phone ON TB_user(phone);
-- 创建联合索引
CREATE INDEX idx_user_prof_age_status ON TB_user(profession, age, status);
-- 创建全文索引
CREATE FULLTEXT INDEX idx_article_content ON article(content);
查看索引
-- 查看表中所有索引
SHOW INDEX FROM TB_user;
-- 查看表中所有索引,格式化输出
SHOW INDEX FROM TB_user\G;
删除索引
-- 删除指定索引
DROP INDEX idx_user_email ON TB_user;
-- 删除主键索引(需先移除主键约束)
ALTER TABLE TB_user DROP PRIMARY KEY;
TB_user表索引实操演示
假设我们有一个用户表TB_user,包含以下字段:id, name, phone, email, profession, age, gender, status, create_time
需求1:为name字段创建常规索引
-- 创建索引
CREATE INDEX idx_user_name ON TB_user(name);
-- 验证索引是否创建成功
SHOW INDEX FROM TB_user WHERE Key_name = 'idx_user_name';
需求2:为phone字段创建唯一索引
-- 创建唯一索引
CREATE UNIQUE INDEX idx_user_phone ON TB_user(phone);
-- 测试唯一约束
INSERT INTO TB_user(phone) VALUES('13800138000');
-- 再次插入相同手机号会报错:Duplicate entry '13800138000' for key 'idx_user_phone'
需求3:为profession、age、status创建联合索引
-- 创建联合索引
CREATE INDEX idx_user_prof_age_status ON TB_user(profession, age, status);
联合索引的最左匹配原则:
联合索引(profession, age, status)可以匹配以下查询条件:
SELECT * FROM TB_user WHERE profession = '工程师'
--(匹配最左列,可使用联合索引中profession部分);
SELECT * FROM TB_user WHERE profession = '教师' AND age = 30;
--(连续匹配最左两列,可使用联合索引中profession+age部分)
SELECT * FROM TB_user WHERE profession = '医生' AND age = 28 AND status = 1;
--(完整匹配所有列,可使用联合索引全部)
但无法匹配以下查询条件:
SELECT * FROM TB_user WHERE age = 26;
--(未包含最左列profession,完全无法使用联合索引)
SELECT * FROM TB_user WHERE status = 1;
--(未包含最左列profession,完全无法使用联合索引)
SELECT * FROM TB_user WHERE age = 32 AND status = 0;
--(未包含最左列profession,完全无法使用联合索引)
SELECT * FROM TB_user WHERE profession = '护士' AND status = 1;
(跳过中间的age字段,status无法使用索引,仅profession可能走单列索引(若存在),但无法使用该联合索引)需求4:为email字段创建常规索引并删除
-- 创建索引
CREATE INDEX idx_user_email ON TB_user(email);
-- 查看索引
SHOW INDEX FROM TB_user WHERE Key_name = 'idx_user_email';
-- 删除索引
DROP INDEX idx_user_email ON TB_user;
-- 再次查看,确认索引已删除
SHOW INDEX FROM TB_user WHERE Key_name = 'idx_user_email';
索引设计最佳实践:避免这些常见错误
不要过度索引:索引并非越多越好
虽然索引能加速查询,但也会带来以下负面影响:
-
降低写入性能:插入、更新、删除操作需要维护索引
-
占用存储空间:每个索引都需要占用磁盘空间
-
增加优化器负担:索引过多会让MySQL优化器难以选择最优索引
建议:一个表的索引数量控制在5个以内,最多不超过10个。
选择合适的字段创建索引
适合创建索引的字段:
-
频繁出现在WHERE子句中的字段
-
用于JOIN操作的关联字段
-
用于排序(ORDER BY)的字段
-
用于分组(GROUP BY)的字段
不适合创建索引的字段:
-
数据量少的表:表中数据行数少于1000行
-
更新频繁的字段:如最后登录时间
-
重复值多的字段:如性别(只有男、女、未知三个值)
-
长度过长的字符串字段:可考虑前缀索引
联合索引字段顺序:选择性高的字段放前面
联合索引中,字段的顺序遵循最左匹配原则,同时应将选择性高(即字段值不重复的比例高)的字段放在前面。
示例:
对于联合索引(profession, age, status),如果profession的选择性最高,age次之,status最低,这样的顺序就是合理的。
选择性计算:SELECT COUNT(DISTINCT profession)/COUNT(*) FROM TB_user;
避免索引失效的常见情况
-
使用函数或表达式操作索引字段
-- 索引失效
SELECT * FROM TB_user WHERE SUBSTR(name, 1, 3) = '张';
-- 索引有效
SELECT * FROM TB_user WHERE name LIKE '张%';
-
使用不等于(!=、<>)、NOT IN、IS NOT NULL
-- 可能导致索引失效
SELECT * FROM TB_user WHERE age != 20;
SELECT * FROM TB_user WHERE age NOT IN (20, 30);
SELECT * FROM TB_user WHERE name IS NOT NULL;
-
使用OR连接包含非索引字段的条件
-- 如果phone没有索引,整个查询可能全表扫描
SELECT * FROM TB_user WHERE name = '张三' OR phone = '13800138000';
-
字符串不加引号
-- 索引失效,因为发生了类型转换
SELECT * FROM TB_user WHERE name = 123;
-- 索引有效
SELECT * FROM TB_user WHERE name = '123';
-
使用LIKE以%开头
-- 索引失效
SELECT * FROM TB_user WHERE name LIKE '%三';
-- 索引有效
SELECT * FROM TB_user WHERE name LIKE '张%';
索引设计Checklist:创建索引前必看
在创建索引时,建议按照以下Checklist进行检查:
1. 业务需求检查
-
该索引是否支持了主要的查询场景?
-
是否考虑了读写比例?(写多的表应减少索引)
-
是否有更合适的索引类型?(常规索引/唯一索引/联合索引)
2. 索引字段检查
-
字段是否频繁出现在WHERE/JOIN/ORDER BY/GROUP BY中?
-
字段选择性是否足够高?(选择性低的字段不适合建索引)
-
字段长度是否过长?(长字符串考虑前缀索引)
-
字段是否经常更新?(频繁更新的字段谨慎建索引)
3. 索引设计检查
-
是否遵循了最左匹配原则?
-
联合索引字段顺序是否合理?(选择性高的字段放前面)
-
是否存在冗余索引?(如已存在(a,b),无需再建(a))
-
是否控制了索引数量?(单表索引不超过5个)
4. 性能影响检查
-
是否测试了索引对查询性能的提升?
-
是否评估了索引对写入性能的影响?
-
是否考虑了索引的存储空间占用?
总结:索引是把双刃剑
MySQL索引是提升查询性能的关键技术,但也不是越多越好。好的索引设计需要深入理解业务需求,结合表结构和查询模式,才能创建出高效的索引。
记住,没有放之四海而皆准的索引设计规则,最好的方法是:
-
理解业务查询需求
-
创建合适的索引
-
使用EXPLAIN分析查询计划
-
根据实际性能反馈调整索引
希望本文能帮助你掌握MySQL索引技术,让你的数据库查询性能提升一个台阶!如果你有任何问题或建议,欢迎在评论区留言讨论。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)