深入解析KVCache:大模型推理加速利器
摘要: KVCache(Key-Value Cache)是大语言模型(LLM)推理加速的关键技术,通过缓存历史token的Key和Value向量,避免重复计算自注意力,显著降低计算复杂度(从O(L²)到O(L))。其核心原理是在自回归生成时复用缓存的K/V向量,仅计算当前token的新向量。虽然KVCache大幅提升推理速度,但会占用显存(与模型层数、头数、序列长度成正比)。优化方案包括多查询注意
🚀 LLM 加速神器:深入理解 KV Cache(Key-Value Cache)
🌟 摘要与导语
大语言模型(LLM)在生成长文本时,其计算成本是巨大的。每次生成新的 token,模型都需要重新计算整个序列的自注意力(Self-Attention),这导致了推理速度慢和内存占用高的两大瓶颈。
**KV Cache(Key-Value Cache)**正是为了解决这些问题而生。它通过缓存之前计算过的 Key (K) 和 Value (V) 向量,避免了重复计算,从而显著加速了 LLM 的推理过程,并降低了内存开销。本文将深入解析 KV Cache 的工作原理、数学基础、优缺点以及它如何成为现代 LLM 部署的关键优化技术。
💡 一、自注意力机制的瓶颈
在深入 KV Cache 之前,我们首先回顾一下 Transformer 的 Self-Attention 机制。
对于一个输入序列 X = (x_1, x_2, \dots, x_L),Self-Attention 层会为每个 token x_t 生成一个 Query (Q_t)、Key (K_t) 和 Value (V_t) 向量。然后,通过计算 Q_i 与所有 K_j 的点积来衡量相关性,并用这些相关性作为权重对所有 V_j 进行加权求和,得到最终的输出。
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
瓶颈所在:
当 LLM 处于自回归生成模式时(即一个词一个词地生成),每次生成一个新的 token x_{L+1} 时,模型都需要计算 Q_{L+1} 与 整个历史序列 (K_1, \dots, K_L, K_{L+1}) 的相关性,并加权求和 (V_1, \dots, V_L, V_{L+1})。这意味着随着生成长度的增加,每次计算都要重复处理之前已经计算过的 K 和 V 向量,造成大量的冗余计算和内存浪费。
举例:
假设模型已经生成了 "Hello world, how are you",现在要生成下一个词 "today"。
在计算 "today" 的注意力时,它需要用到 "Hello", "world", "how", "are", "you" 这些词的 K 和 V 向量,以及 "today" 自身的 K 和 V 向量。而 "Hello" 到 "you" 这些词的 K 和 V 向量在生成它们自己或前一个词时就已经计算过了。
🔄 二、KV Cache 的工作原理
KV Cache 的核心思想非常直观:将已经计算过的 Key 和 Value 向量缓存起来,以便在后续的生成步骤中直接重用,而不是重新计算。
1. 缓存什么?
KV Cache 缓存的是 Transformer 模型中每个注意力层(Attention Layer)的 Key (K) 和 Value (V) 向量。
2. 如何工作?
假设模型需要生成一个长度为 L 的序列。
-
初始输入阶段(Prompt Processing):
-
当模型第一次接收到输入提示(Prompt)时,它会像往常一样,并行计算所有输入 token 的 Q, K, V 向量。
-
KV Cache 介入: 对于每个注意力层,计算得到的 K_1, \dots, K_L 和 V_1, \dots, V_L 向量会被存储起来,形成一个缓存。
-
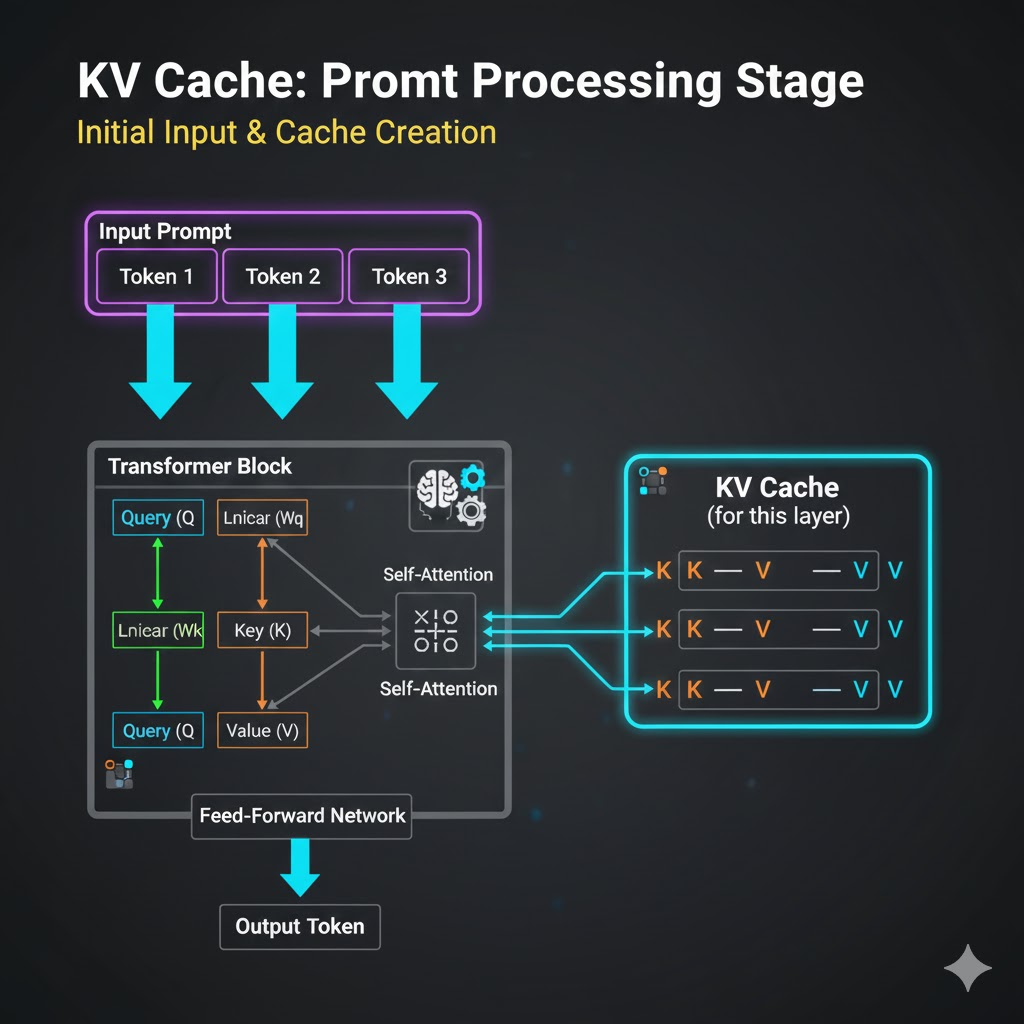
-
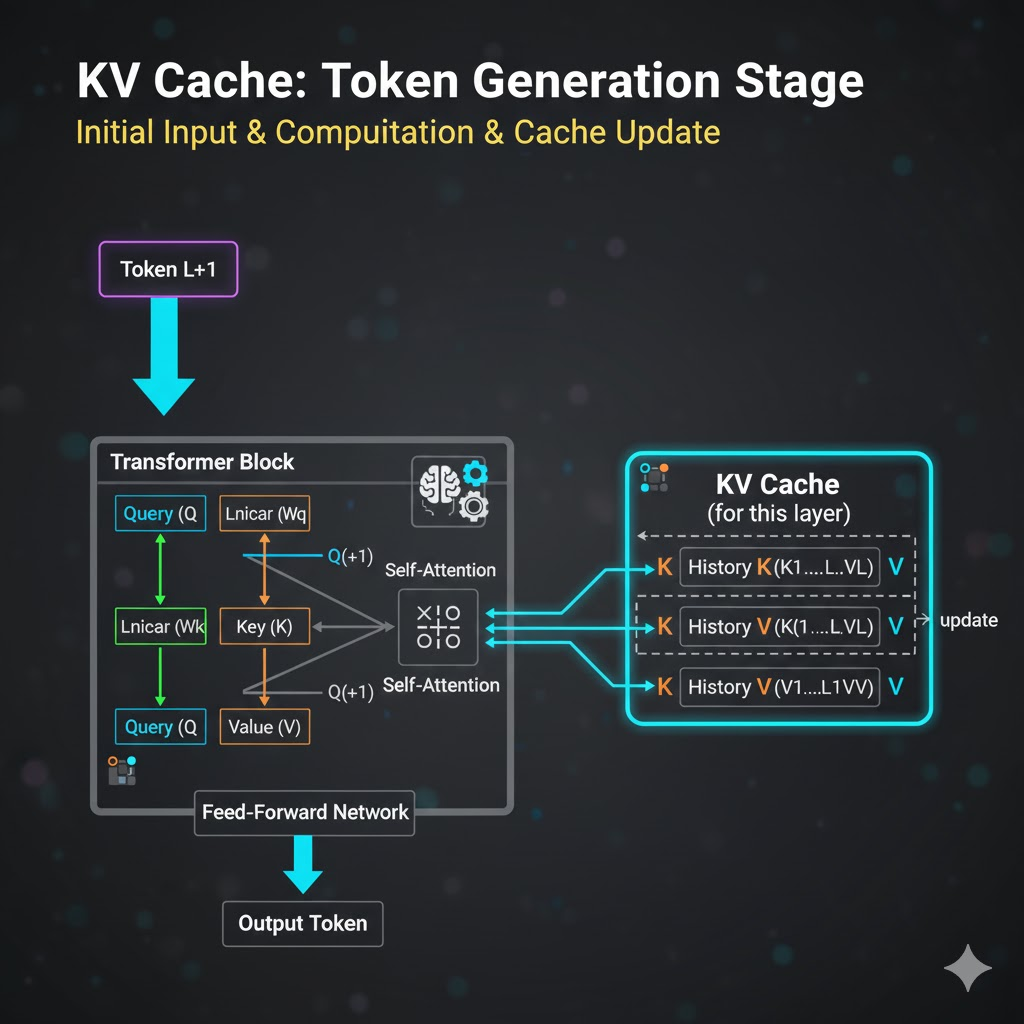
自回归生成阶段(Token Generation):
-
生成第一个新 Token: 模型接收到新的输入 x_{L+1}。
-
模型只计算 x_{L+1} 的 Q_{L+1} 向量,以及新的 K_{L+1} 和 V_{L+1} 向量。
-
在计算注意力时,Q_{L+1} 会与 KV Cache 中存储的历史 K 向量 (K_1, \dots, K_L) 和 当前计算出的 K_{L+1} 组合在一起进行点积运算。
-
然后用这些注意力权重对 KV Cache 中存储的历史 V 向量 (V_1, \dots, V_L) 和 当前计算出的 V_{L+1} 进行加权求和。
-
更新 KV Cache: 将 K_{L+1} 和 V_{L+1} 追加到 KV Cache 中。
-
-
生成后续 Token: 同样的逻辑重复,每次只计算当前新 token 的 Q, K, V 向量,并利用 KV Cache 中的历史 K, V 向量,然后更新 KV Cache。
-
3. 数学解释
没有 KV Cache 时,生成第 t 个 token 的 Attention 计算:
\text{Attention}(Q_t, [K_1, \dots, K_t], [V_1, \dots, V_t]) = \text{softmax}\left(\frac{Q_t [K_1, \dots, K_t]^T}{\sqrt{d_k}}\right) [V_1, \dots, V_t]
其中 K 和 V 是 t 个 token 对应的矩阵。
使用 KV Cache 时,生成第 t 个 token 的 Attention 计算:
-
Q_t 是只由当前 token 生成的 Query 向量。
-
[K_{\text{cached}}, K_t] 是 KV Cache 中存储的历史 K 向量和当前 K_t 的拼接。
-
[V_{\text{cached}}, V_t] 是 KV Cache 中存储的历史 V 向量和当前 V_t 的拼接。
\text{Attention}(Q_t, [K_{\text{cached}}, K_t], [V_{\text{cached}}, V_t]) = \text{softmax}\left(\frac{Q_t [K_{\text{cached}}, K_t]^T}{\sqrt{d_k}}\right) [V_{\text{cached}}, V_t]
KV Cache 的关键在于,每次生成新 token 时,我们只需要计算当前 token 的 K_t, V_t,而 K_{\text{cached}} 和 V_{\text{cached}} 已经存在,无需重新计算。
🚀 三、KV Cache 的优缺点
优点:
-
显著提升推理速度: 避免了重复计算历史 token 的 K, V 向量,将每次生成 token 的计算复杂度从 O(L^2) 降低到 O(L)(只计算当前 token 与历史 token 的 Attention)。
-
降低计算资源消耗: 减少了 GPU 计算量,提高了吞吐量。
缺点:
-
增加内存占用: KV Cache 需要为每个注意力层、每个 Head 存储历史的 Key 和 Value 向量。对于大模型(多层、多头)和长序列,KV Cache 会占用大量显存。
-
内存开销估算:
对于一个模型,如果它有 N 层,每个注意力头维度为 d_h,有 H 个头,生成长度为 L 的序列。
则 KV Cache 存储的 Key 和 Value 向量总大小约为:
2 \times N \times H \times L \times d_h \times \text{sizeof(float)}
(2 是因为 Key 和 Value 各一份)
例如,Llama-2-7B 模型,Llama 家族通常有 32 层,32 个头,头维度为 128。如果生成 2048 个 token,KV Cache 大小约为 2 \times 32 \times 32 \times 2048 \times 128 \times 2 \text{ bytes (FP16)} \approx 536 \text{ MB}。这对于单个用户来说尚可,但对于高并发场景,内存压力巨大。
-
-
管理复杂性: 在批量推理(Batch Inference)和多用户场景下,如何高效地管理和调度 KV Cache(例如,对不同用户的不同长度序列进行缓存,以及如何进行缓存淘汰策略)是一个复杂的工程问题。
优化 KV Cache 内存的方法
由于内存是 KV Cache 的主要瓶颈,许多优化技术应运而生:
-
多查询注意力(Multi-Query Attention, MQA)/ 分组查询注意力(Grouped-Query Attention, GQA): 允许多个注意力头共享同一个 Key 和 Value 投影,从而大大减少 KV Cache 的内存占用。Llama-2、Mistral 等现代 LLM 广泛采用 GQA。
-
量化(Quantization): 将 Key 和 Value 向量从 FP32/FP16 降到 INT8 或 INT4 存储,以减少内存占用。
-
动态 KV Cache 大小: 根据实际生成长度动态分配缓存空间,而不是预分配最大长度。
-
流式注意力(Streaming Attention): 限制 Attention 计算的窗口大小,只关注最近的 K/V 向量,牺牲一些上下文来换取更低的内存占用。
-
PagedAttention: 借鉴操作系统的内存分页思想,将 KV Cache 存储在不连续的块中,有效管理变长序列和碎片化内存,显著提高 GPU 利用率。vLLM 等推理框架就采用了这一技术。
总结
KV Cache 是现代大语言模型推理管道中不可或缺的优化技术。它通过避免重复计算,极大地提升了模型的生成速度。虽然带来了额外的内存开销,但通过 MQA/GQA、量化、PagedAttention 等一系列创新技术,KV Cache 的内存效率正在不断提高。
理解 KV Cache 对于优化 LLM 的部署和成本效益至关重要,它让 LLM 从实验室走向了更广泛的实际应用。
✍️ 互动与提问
您在 LLM 推理优化中遇到过哪些 KV Cache 相关的挑战?您认为哪种 KV Cache 优化技术最有前景?欢迎在评论区分享您的见解!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)