【值得收藏】揭秘大模型幻觉:原理剖析与实战抑制技巧
在大模型语境下,“幻觉”指的是模型生成的内容虽然语言上连贯、逻辑通顺,但与事实不符。比如:·模型编造不存在的论文;·模型凭空虚构数据、代码;·模型回答问题时“自信地胡说八道”。本质上,这是一种模型生成偏离真实语义空间的现象。
大模型幻觉是指模型生成内容语言连贯但与事实不符的现象。其本质原因是模型作为条件概率生成器,学习的是"下一个词的概率分布"而非事实真实性。幻觉产生于三个层面:语言层面(追求流畅性而非真实性)、语义层面(知识表示不精确导致伪联想)和推理层面(采样策略偏差)。抑制幻觉可通过训练层面(知识监督、指令对齐等)和推理层面(RAG、多采样验证等)实现,核心是让模型"有依据地说话",从概率生成走向事实对齐。
一、什么是幻觉?
在大模型语境下,“幻觉”指的是模型生成的内容虽然语言上连贯、逻辑通顺,但与事实不符。

比如:
·模型编造不存在的论文;
·模型凭空虚构数据、代码;
·模型回答问题时“自信地胡说八道”。
本质上,这是一种模型生成偏离真实语义空间的现象。
二、幻觉的本质
要理解幻觉,得先回到最本质的事实:
大模型不是知识系统,而是条件概率生成器。
在自回归框架下,语言模型的目标是:
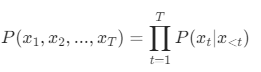
也就是说,模型只学到了“下一个词的概率分布”,它并不真正“知道”事实是否真实。
所以,当语境不充分、分布外样本出现、或概率混乱时,模型就可能选择一个语义上合理但事实错误的词。
这,就是幻觉的起点。
三、从三层视角看幻觉产生的机制
1. 语言层面:训练目标与真实性错位
语言模型的目标函数是最大化似然(MLE):
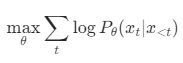
问题是:
·它学习的是“表达概率”,不是“事实正确性”;
·高似然的句子往往是“听起来合理”的句子;
·所以模型会优先输出语法连贯的内容,而非真实内容。
语言模型追求的是流畅性,不是真实性。
2. 语义层面:知识表示的不精确性
大模型的知识是通过分布式向量表示(embedding)隐式存储的。
当知识关联不清或相似概念混叠时,就会产生“伪联想”。
比如:
“爱因斯坦提出了相对论”
“牛顿提出了万有引力”
模型可能学到“物理学家 + 提出 + 理论”这种统计模板,于是当你问“爱迪生提出了什么理论?”时,它就很可能“编”一个。
这类幻觉是表示空间混叠的结果。
3. 推理层面:采样与解码过程的偏差
生成时,大模型并不是每次都取最高概率词,而是根据策略采样:
·Greedy Search:容易陷入局部模式;
·Top-k / Top-p Sampling:可能选到“语言上合理但事实不对”的词;
·Temperature 过高:输出随机性增加,幻觉概率上升。
也就是说,即使模型本身概率分布没问题,推理策略也可能人为放大幻觉。
四、从训练角度如何抑制幻觉?
抑制幻觉的核心思想是让模型不只学习‘语言的合理性’,而要学习‘事实的正确性’。
常见训练层面的解决思路
1. 增强知识监督(Knowledge Grounding)
在预训练或微调阶段引入外部知识库(如 Wikipedia、Wikidata、检索模块),让模型的生成有事实支撑。
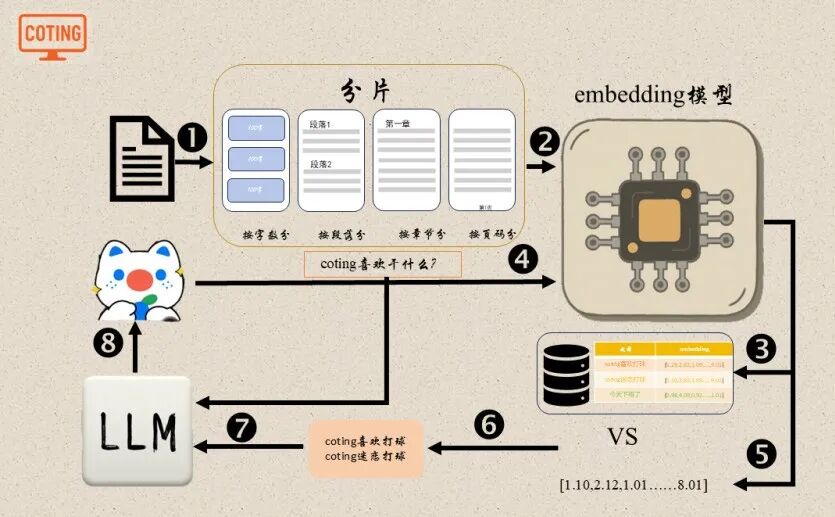
典型做法:
·Retrieval-Augmented Generation (RAG)模型先检索知识 → 再根据检索内容生成;
·Atlas, REALM, RETRO 等架构;
·多模态 Grounding:让语言与视觉、表格等信息绑定。
知识监督可以有效降低事实性幻觉,但是检索质量决定上限。
2. 指令对齐(Instruction Tuning + RLHF)
RLHF(Reinforcement Learning from Human Feedback)本质上就是让模型学会“人认为对的回答方式”。
流程:
1.用人类反馈训练奖励模型;
2.用 PPO 等算法让语言模型生成更“符合人意”的内容;
3.奖励模型会惩罚“自信胡说”的输出。
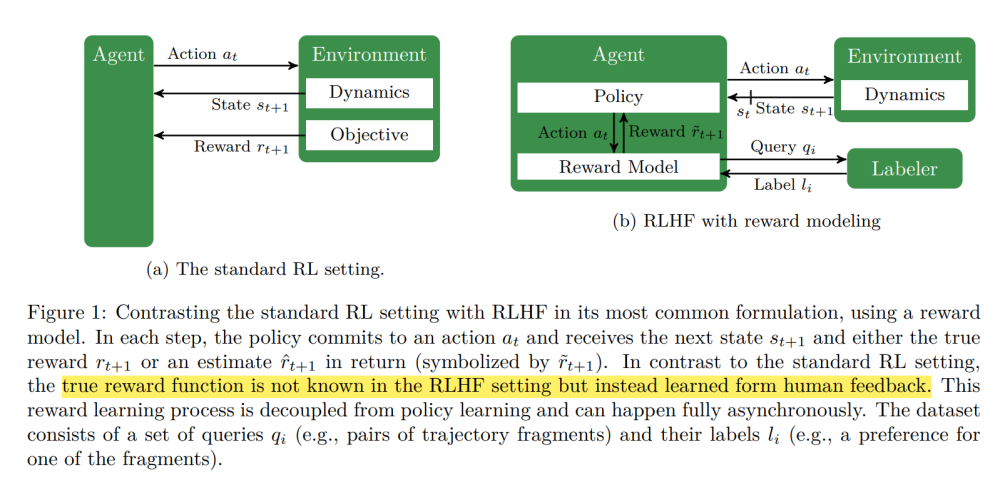
这一步其实相当于事实性与风格性的软约束融合。但 RLHF 并不能消灭幻觉,只是让它更不容易说错。
3. 对比学习(Contrastive Fine-tuning)
通过成对样本(正确 vs 虚构)进行优化,让模型学会区分真伪。
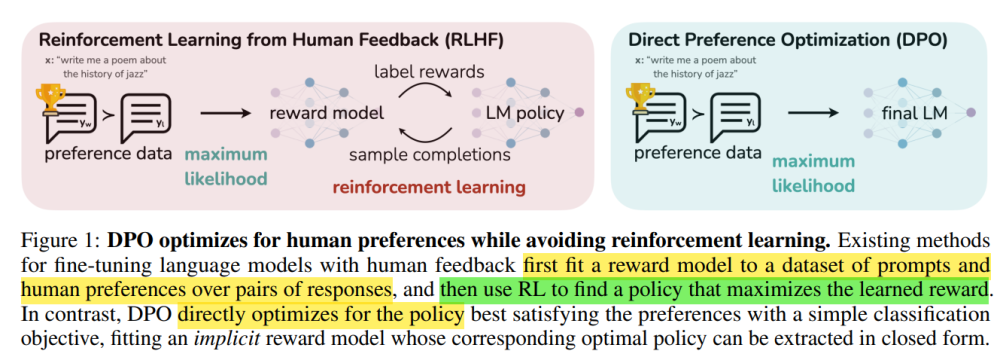 例如:
例如:
Input: 爱因斯坦提出了什么理论?
Good: 相对论。
Bad: 量子力学。
模型通过对比学习优化隐空间,使“正确输出”靠近上下文向量。
4. 知识编辑与持续学习
当模型学错事实时,可以通过:
·Fine-tune 局部层;
·低秩适配(LoRA)局部更新;
·参数编辑(ROME, MEMIT)直接修改内部权重。
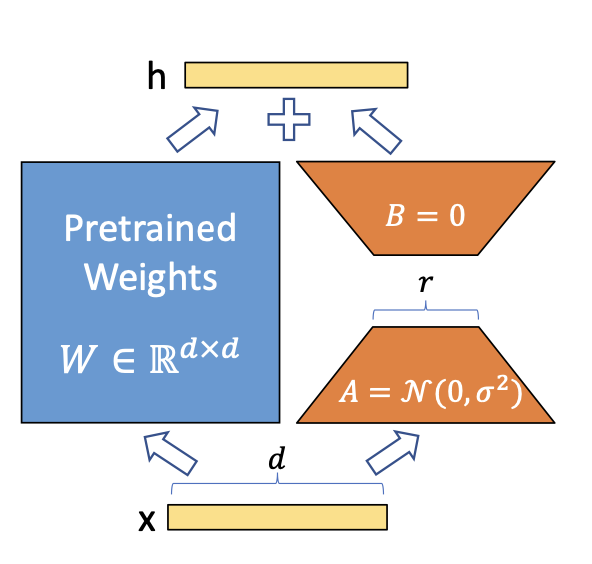
这种方式类似“纠错记忆”,让模型在不遗忘旧知识的前提下修正特定幻觉源。
五、从推理角度如何抑制幻觉?
训练能“减少”,推理才能“控制”。几种工程上常用的推理层面技巧如下
1. 检索增强推理(RAG, RETRO)
在推理阶段动态检索外部信息:模型不凭空生成,而是参考事实再生成。相当于让模型边查资料边回答,而不是瞎编。
2. Self-consistency / 多样性采样验证
让模型多次独立生成答案,然后对结果求一致性:
问:太阳系中最大的行星是什么?
→ 第1次:木星
→ 第2次:木星
→ 第3次:土星
如果答案不一致,则触发“再生成或检索”。这利用了大模型自身的统计稳定性来自我校验。
3. COT + Faithful Reasoning
在推理时让模型显式地写出推理链条(Chain-of-Thought),把“直接生成结论”改成“先推理,再总结”。

这有两个好处:
·推理路径透明,可检测逻辑错误;
·减少“跳步式幻觉”。
进一步的改进是 Faithful CoT:引导模型在每一步推理中引用真实依据(如 RAG + CoT)。
4. 校验型解码(Verifier / Critic Model)
训练一个小模型或模块专门判断输出的真实性,类似于:“主模型负责写,副模型负责挑错。”
代表方案有G-Eval(LLM-based Evaluation)和CriticGPT / VerifierGPT。
5. 降低采样温度 / 调整 top-p
推理时如果温度(temperature)太高,模型更容易“探索”,幻觉概率随之上升。在知识问答或事实任务中,通常:
temperature = 0.2 ~ 0.4
top_p = 0.8
能有效减少幻觉。
总结一下,大模型的幻觉不是撒谎,而是它在不确定下仍然要生成“最像真的”答案。
它的根本原因是:
·语言建模目标与事实目标不一致;
·向量空间知识混叠;
·推理采样带来随机偏差。
解决的核心思想则是“让模型有依据地说话”,从概率生成走向事实对齐(faithful generation)。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献693条内容
已为社区贡献693条内容

所有评论(0)