榨干算力每一毫秒:指令级并行与流水线掩盖实战
2025年昇腾CANN训练营第二季推出系列专题课程,助力开发者提升算子开发技能。本文深入探讨AI计算中的指令级并行优化技术,通过分析硬件架构特点,提出三种关键优化策略:1) 双缓冲技术实现计算与数据传输并行;2) 标量掩盖优化地址计算瓶颈;3) 指令间隙填充技术提升硬件利用率。文章采用接力赛与乐队合奏的生动比喻,形象说明从串行到并行的转变,并给出AscendC中的具体实现方法。这些微观层面的优化可
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
在高性能计算中,“等待”是最大的犯罪。
当我们写出 CopyIn -> Compute -> CopyOut 这样的代码时,直觉上认为是“先搬运,再计算,再搬出”。但在 AI Core 的硬件视角里,这三个动作是由完全独立的硬件单元执行的:
-
MTE2: 搬入数据
-
Vector/Cube: 计算
-
MTE3: 搬出数据
-
Scalar: 标量计算(控制循环、计算地址)
如果代码写得太串行,当 Vector 在疯狂计算时,MTE 单元就在旁边“抽烟摸鱼”。理想的状态是:Vector 在算当前块,MTE2 在搬下一块,MTE3 在写上一块,Scalar 在算下一次的地址。
本期文章将深入微架构层面,探讨如何通过代码编排实现指令级并行 (ILP),消除流水线气泡。
一、 核心图解:从“接力赛”到“大合奏”
-
串行模式(接力赛):第一棒跑完给第二棒,同一时间只有一个人在跑。效率低。
-
并行模式(大合奏):钢琴、小提琴、鼓手同时演奏不同的乐章。效率高。
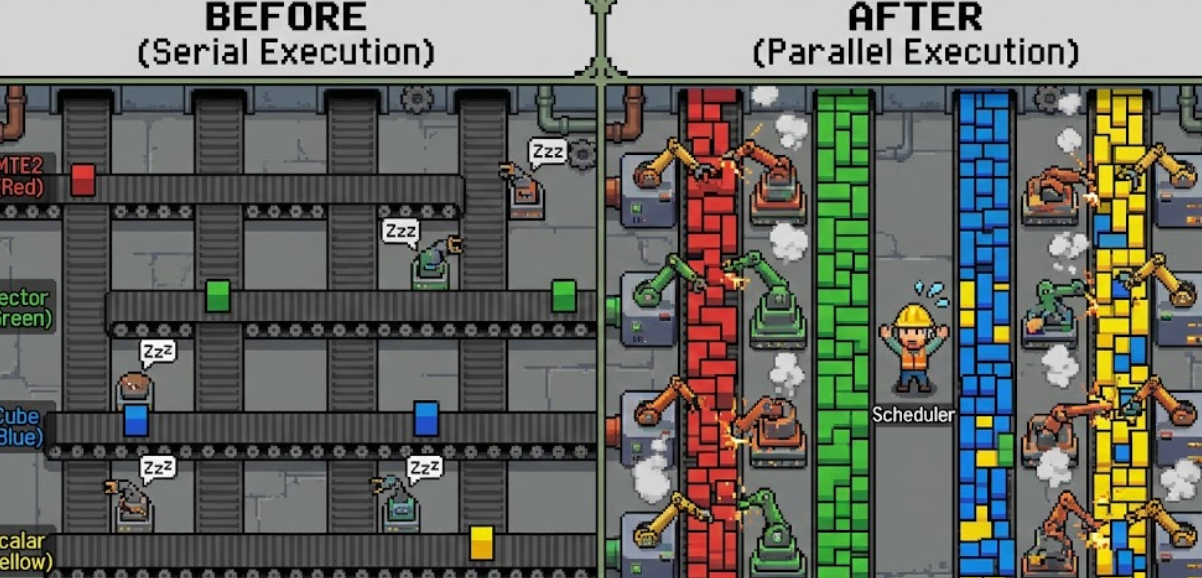
二、 掩盖技术一:双缓冲 (Double Buffering) 的指令本质
我们在基础篇讲过 Double Buffer,这里从指令角度再看一遍。
无 Double Buffer 指令流:
WAIT_FLAG(0) // 等待 CopyIn 完成
VADD(...) // Vector 忙,MTE 闲
SET_FLAG(1) // 通知 CopyIn 可以搬下一块
// 这里存在巨大的 Gap
有 Double Buffer 指令流:
// Ping 块在计算
VADD(Ping)
// 同时,MTE 接到了搬运 Pong 块的指令
DATA_COPY(Pong)
// 此时 VADD 和 DATA_COPY 在硬件上是并行执行的!
实战技巧: 在 Ascend C 中,只要通过 pipe.InitBuffer(queue, 2, ...) 开启双倍空间,并严格遵守 Alloc -> EnQue -> DeQue -> Free 流程,编译器会自动帮你生成并行的指令流。不需要手写汇编。
三、 掩盖技术二:标量掩盖 (Scalar Hiding)
这是进阶优化的重灾区。 Scalar 单元负责计算循环变量 i、计算 Tensor 的偏移地址 offset。 Vector 单元负责 Add, Mul。
如果你的代码长这样:
for (int i = 0; i < N; i++) {
// 复杂的地址计算 (Scalar 工作)
int offset_a = i * stride_a + base_a;
int offset_b = i * stride_b + base_b;
// 简单的向量计算 (Vector 工作)
Add(zLocal, xGm[offset_a], yGm[offset_b], len);
}
问题:Vector 计算很快,但每次都要等 Scalar 算出地址才能发射指令。Vector 会出现“饥饿”。
优化策略:
-
地址预计算:尽量简化循环内的地址计算,或者将地址计算逻辑提前。
-
指令重排:编译器通常会尝试优化,但在复杂场景下,我们可以手动展开循环(Unroll),让 Scalar 有机会提前计算下一轮的地址。
四、 掩盖技术三:指令发射间隙填充
有些指令(如 Exp, Div, Cube Matmul)延迟很高。在等待结果出来的几十个周期里,我们可以插入一些不依赖当前结果的轻量级指令。
案例:Softmax 计算 Softmax 需要算 Exp(耗时),然后 Sum,然后 Div。
// 优化前:串行等待
Exp(tmp, src); // 慢指令
ReduceSum(sum, tmp); // 必须等 Exp 算完
优化后:插入无关计算 假设我们需要同时算两行 Softmax(Row A 和 Row B)。
Exp(tmpA, srcA); // 发射 Exp A
Exp(tmpB, srcB); // 在 A 计算期间,发射 Exp B (流水线填充)
// ... 等待 A 完成 ...
ReduceSum(sumA, tmpA);
// ... 等待 B 完成 ...
ReduceSum(sumB, tmpB);
Ascend C 实现: 利用 多级队列(Multi-Queue) 或 手动循环展开。
// 一次处理 2 个 Tile
CopyIn(i);
CopyIn(i+1); // 连续发射两次搬运
Compute(i);
Compute(i+1); // 连续发射两次计算
这样能让 MTE 和 Vector 的队列里始终有积压的任务,避免硬件空转。
五、 总结
指令级并行是性能优化的“微操”。
-
宏观并行:靠多核(BlockDim)。
-
中观并行:靠流水线(Double Buffer)。
-
微观并行:靠指令重排和循环展开,让 Scalar、MTE、Vector 互不等待。
当你发现 Tiling 已经调无可调,但性能距离理论峰值还有 20% 的差距时,请拿起“指令级并行”这把手术刀,去切除那些肉眼不可见的微小气泡。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)