Easy Dataset调用本地大模型
本文介绍了如何在EasyDataset平台上使用本地部署的大模型制作数据集。首先详细说明了Ollama的安装步骤,包括下载安装程序和模型(如qwen3-vl:4b),并验证API服务是否正常启动。接着指导用户在EasyDataset中配置本地模型,包括设置接口地址、模型名称和API Key(可随意填写)。最后演示了上传PDF文件进行智能分割和问题生成的过程,提示使用本地小模型时速度较慢。作者表示后
上个博客https://blog.csdn.net/qq_37867431/article/details/154876024?spm=1001.2014.3001.5502
已经介绍了如何安装Easy Dataset,这篇博客主要介绍如何在Easy Dataset上使用本地部署的大模型进行数据集制作。
1、本地部署大模型。
本来是想直接用deepseek-R1模型的,但是这个要按token进行收费,不划算,还是本地自己部署一个比较方便,我安装的是ollamma,也可以安装别的,都大差不差。
1.1安装ollama
首先进入
-
Ollama 下载:https://ollama.com/download
-
Ollama 官方主页:https://ollama.com
-
Ollama 官方 GitHub 源代码仓库:https://github.com/ollama/ollama/ 上述三个选择一个下载对应的系统的安装程序,我是在window10上安装,选择的是Windows。下载后全选择install一路即可。安装成功后会出现如下对话框,可以自行下载不同的模型到本地,下载完成就可以进行对话了,我这里下载的qwen3-vl:4b.
1.2确保Ollama本地API已经启动。
ollama兼容OpenAI的API为:
http://localhost:11434/v1
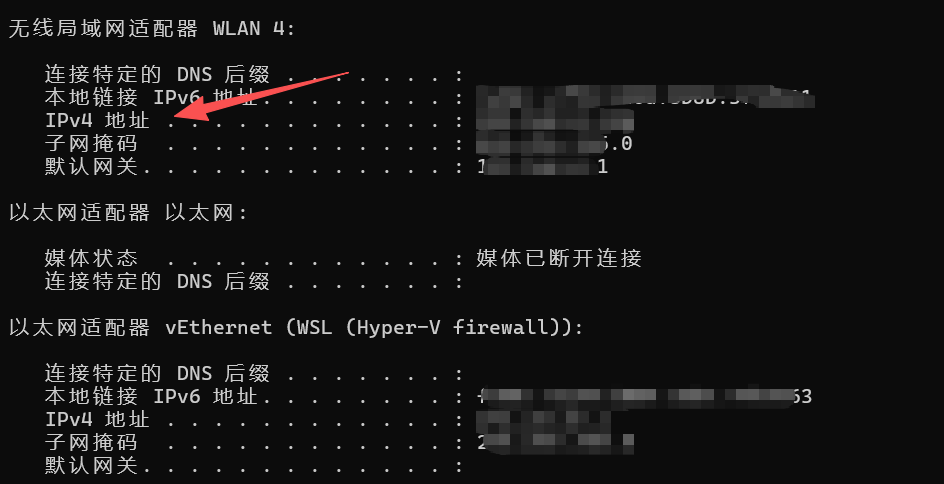
你自己电脑的IP,可以在cmd通过Ipconfig指令查看,IPv4地址即为你的IP地址。
可以先用curl测试一下,指令如下:
curl http://localhost:11434/api/tags
如果返回如下模型列表,说明服务是正常的。

2.Easy Dataset中调用本地模型配置。
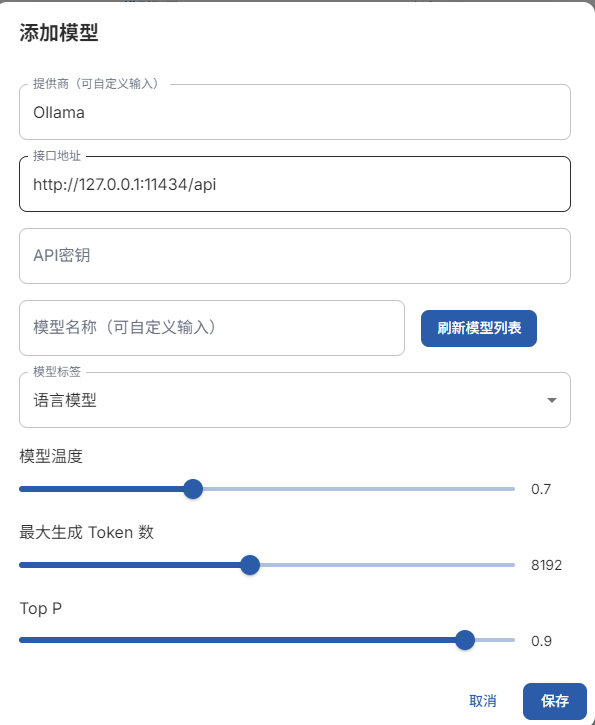
首先,进入Easy Dataset中创建一个项目,先起个项目名字,然后选择模型,我这里选择的是ollama,想要免费调用的同学可以按我这个来,选择ollama模型,然后修改配置内容。
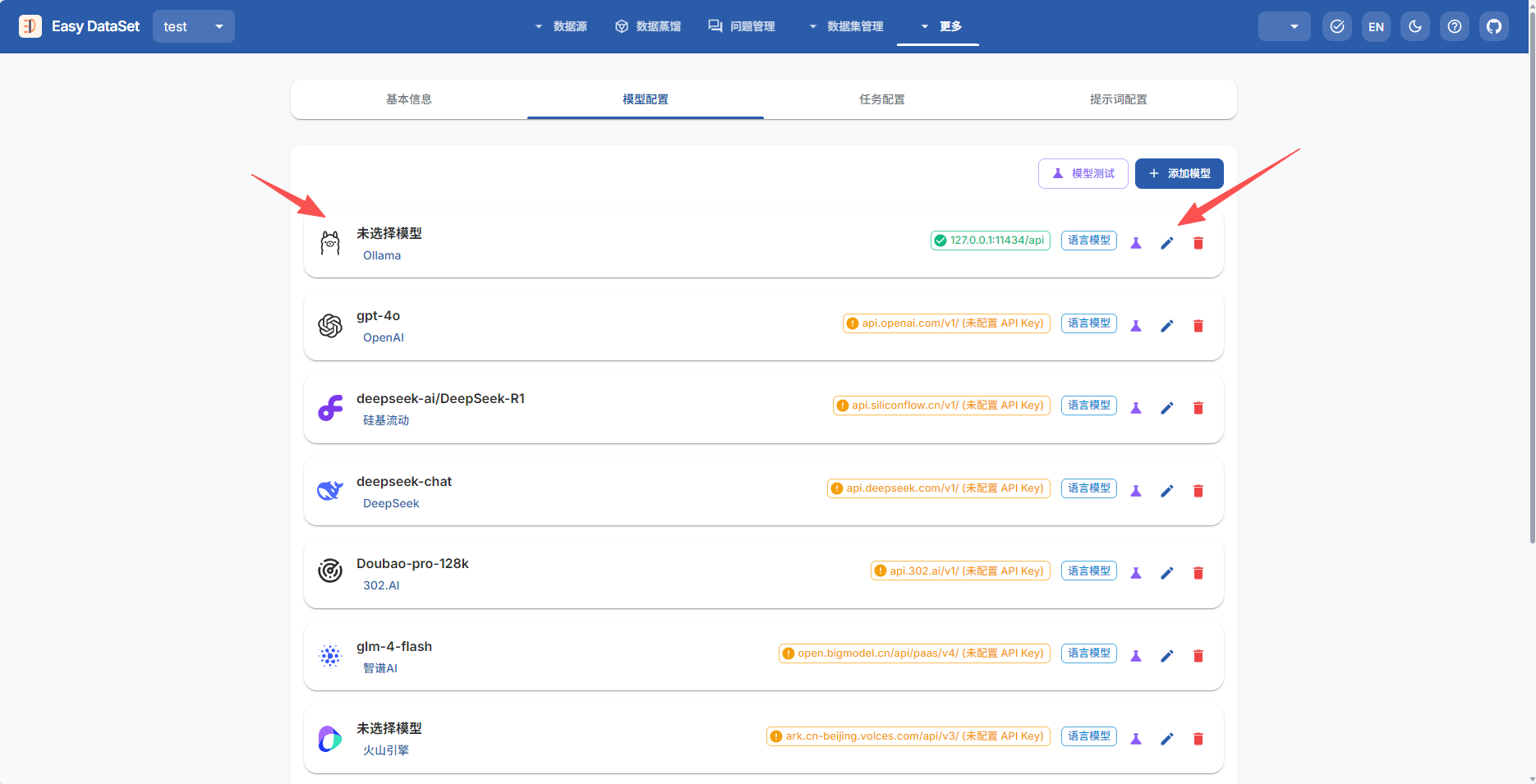
配置内容如下,其中,
接口地址:
为http://localhost:11434/v1,
模型名称:
为你本地下载的模型,我下载的是gemma3:4b,就填gemma3:4b就行,根据你下载的模型填。
API Key:
Ollama是不需要Key的,但是EasyDataset中又需要一个字符串,所以你可以随便输入几个字符。
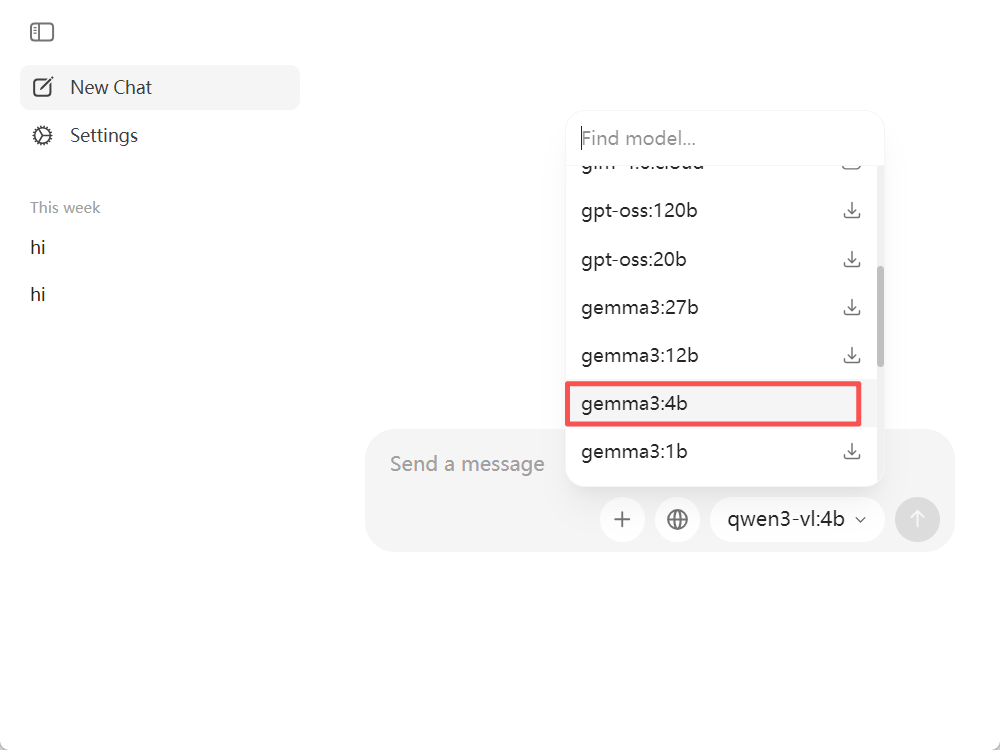
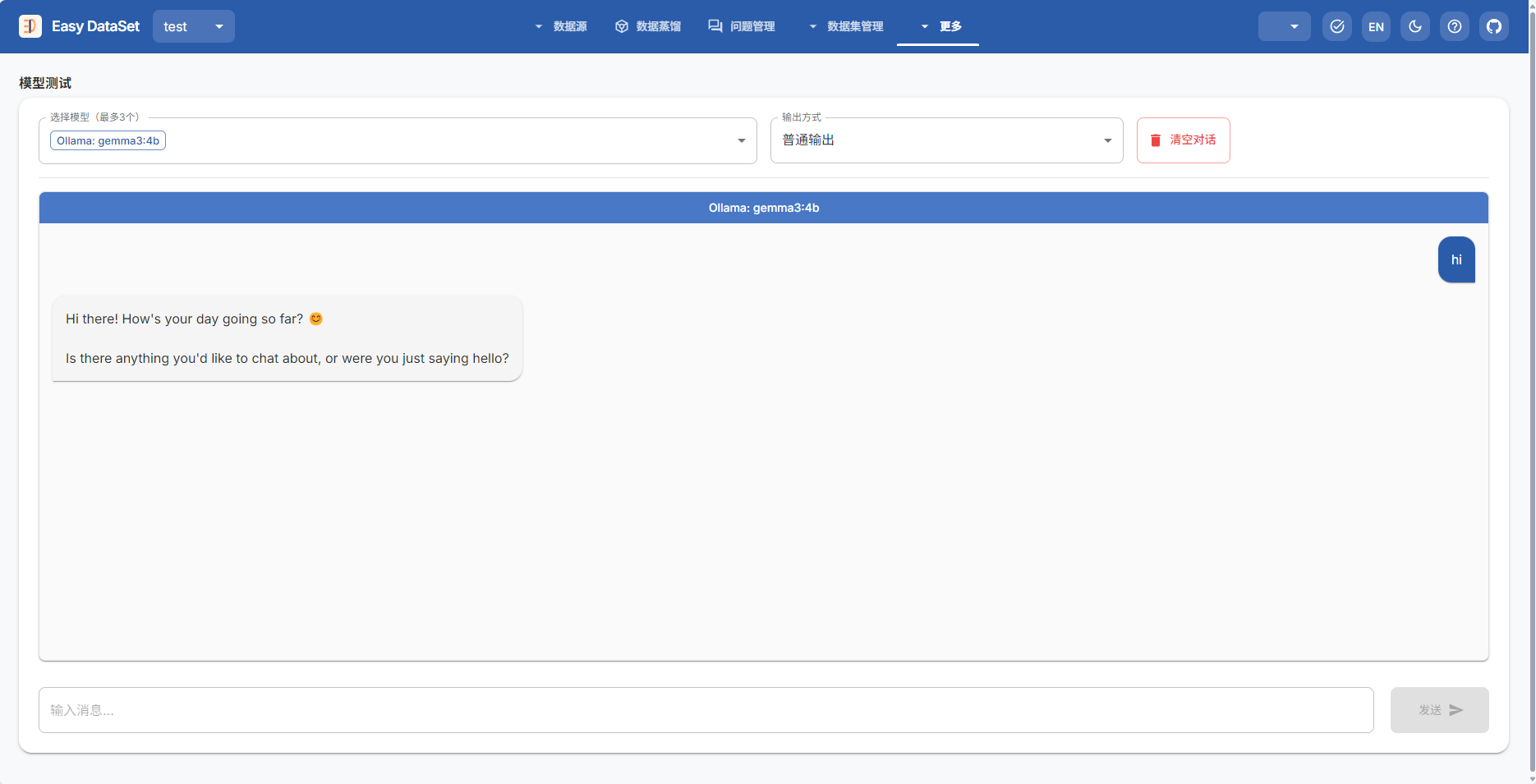
按照上述内容输入配置文件后,可以测试一下,选择模型测试,随便发送一些内容,看有没有内容生成,如下图,这就是调用成功了~
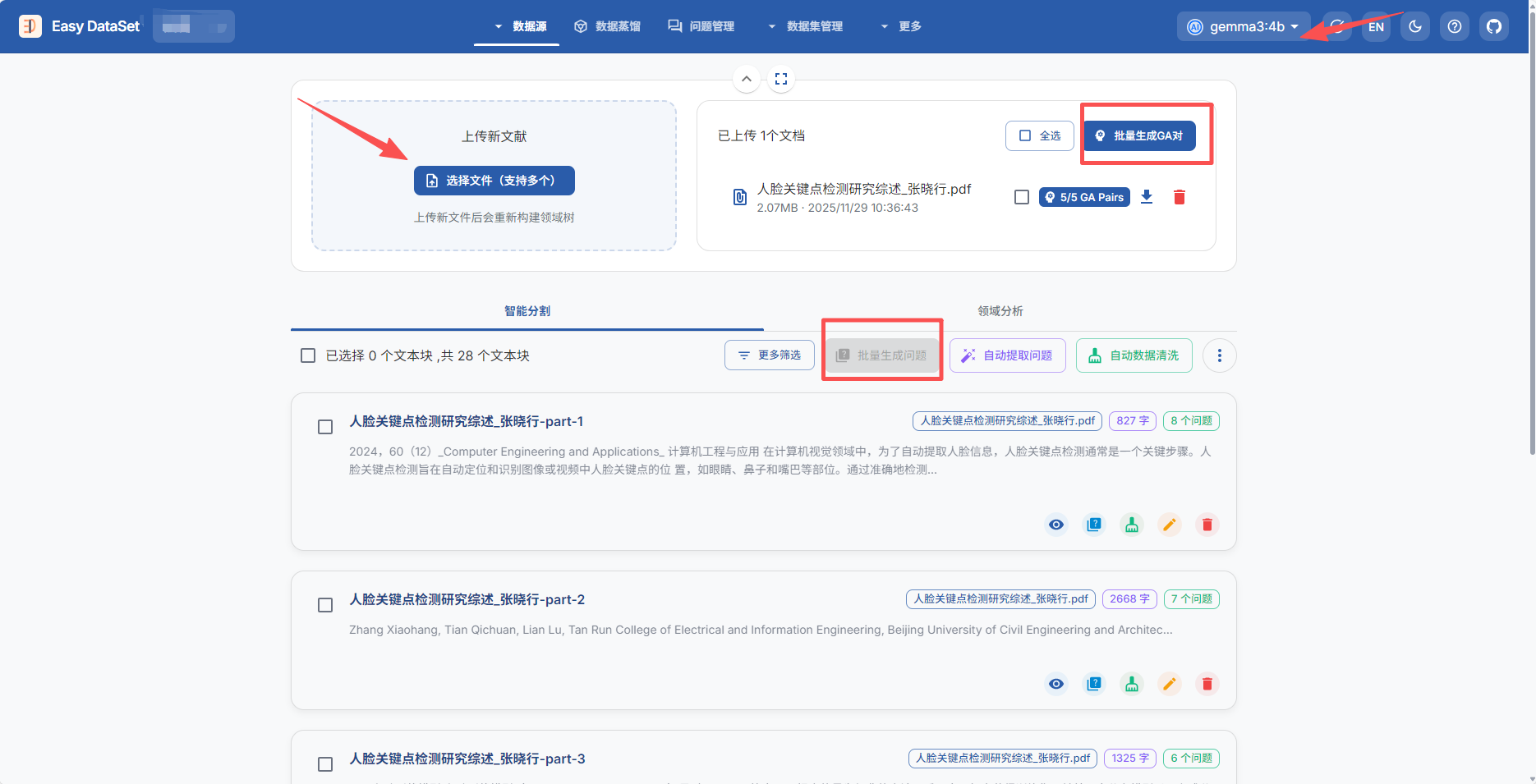
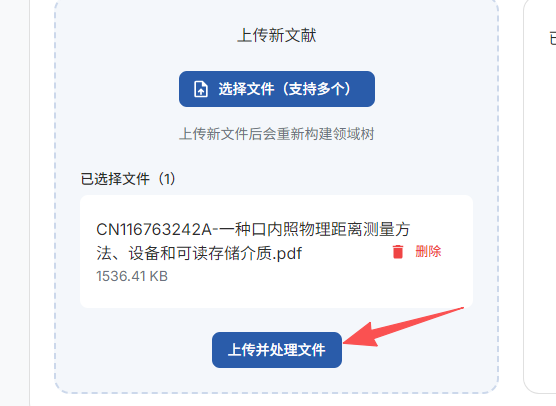
3、上传PDFj进行数据集制作。
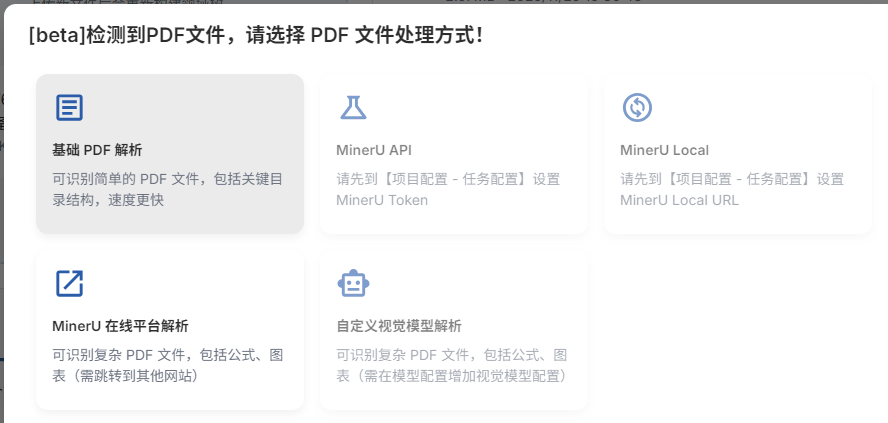
首先可以选择文件,然后选择解析方式,简单的选择基础PDF解析就行。
上传成功后选择,上传并处理文件。
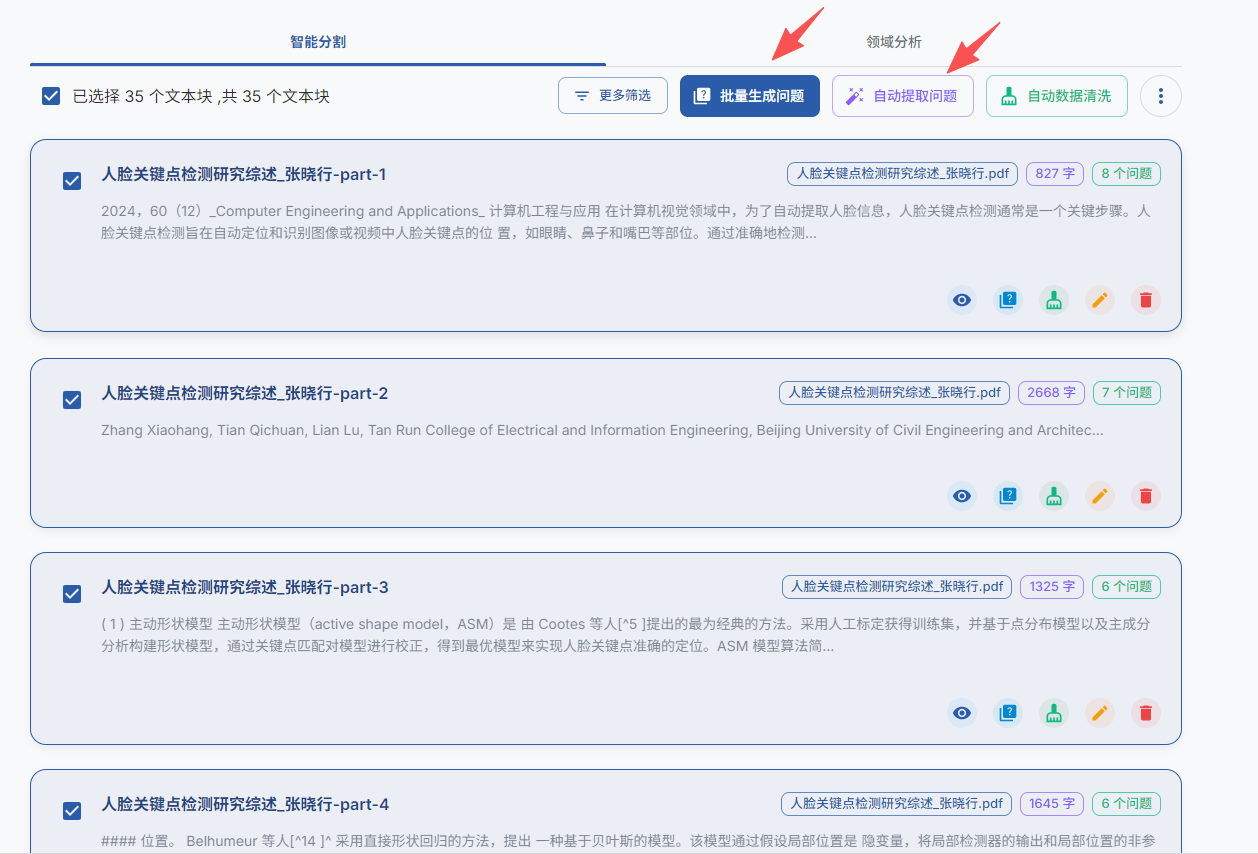
EasyDataset首先会对PDF进行智能分割,分割成多个文本块,勾选全部的文本块后可以选择批量生成问题,然后耐心等待即可,由于我调用的本地的4b的gemma,所以会比较慢。后续如何对生成的问题进行处理并进行大模型微调,等我后续弄明白再继续更新嗷,敬请期待~~后面也会一直更新大模型相关的内容,感兴趣的同学可以点点关注哦,关注我,不迷路,点赞收藏转发就更好了嘿嘿。想听别的内容的同学,也欢迎私信或者评论区告诉我~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 45
45 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)