即插即用,涨点神器!AAAI 2026模块MHCB+DPA:特征提取+双池化注意力,无需魔改结构,性能显著提升
遥感图像在军事、资源勘探等领域应用广泛,但单一传感器难以同时获取高空间分辨率和高光谱分辨率的图像。全色(PAN)图像空间分辨率高但为灰度,多光谱(MS)图像色彩丰富但空间分辨率低。现有方法通常将图像**超分辨率(Super-Resolution, SR)**与图像着色作为独立任务处理,前者无法提升光谱信息,后者无法提升空间细节,而全色锐化等融合方法又需要配准的图像对作为输入。为解决这一困境,本文提
遥感图像在军事、资源勘探等领域应用广泛,但单一传感器难以同时获取高空间分辨率和高光谱分辨率的图像。全色(PAN)图像空间分辨率高但为灰度,多光谱(MS)图像色彩丰富但空间分辨率低。现有方法通常将图像**超分辨率(Super-Resolution, SR)**与图像着色作为独立任务处理,前者无法提升光谱信息,后者无法提升空间细节,而全色锐化等融合方法又需要配准的图像对作为输入。
为解决这一困境,本文提出了一种名为 MFmamba 的多功能网络。该网络构建于 UNet++ 架构之上,创新性地集成状态空间模型(State-Space Model),旨在仅通过单张 PAN 图像输入,实现超分辨率、光谱恢复(即着色)、以及二者联合的高质量图像复原。
本文的主要贡献在于:设计了基于 Mamba 的高效上采样模块(MUB),提出了用于浅层特征提取的多尺度混合交叉块(MHCB),并引入双池化注意力机制(DPA)以优化特征表示,从而在一个统一框架内高效协同地完成多项分辨率复原任务。
01 论文基本信息

- 标题: MFmamba: A Multi-function Network for Panchromatic Image Resolution Restoration Based on State-Space Model
- 核心模块: 多尺度混合交叉块 (Multi-scale Hybrid Cross Block, MHCB), 双池化注意力 (Dual Pool Attention, DPA), Mamba上采样模块 (Mamba Upsampling Block, MUB)
02 算法框架与核心模块
2.1 算法框架
本文提出的 MFmamba 整体框架。该框架以 UNet++ 为骨干网络,首先采用 MHCB 模块进行初始的浅层特征提取。在 UNet++ 的编码器和解码器之间,使用创新的 DPA 模块取代了原有的跳跃连接,以增强同层级特征图的信息传递。最后,在网络的上采样阶段,集成了基于状态空间模型的 MUB 模块,用于执行高效的图像分辨率恢复和重建。
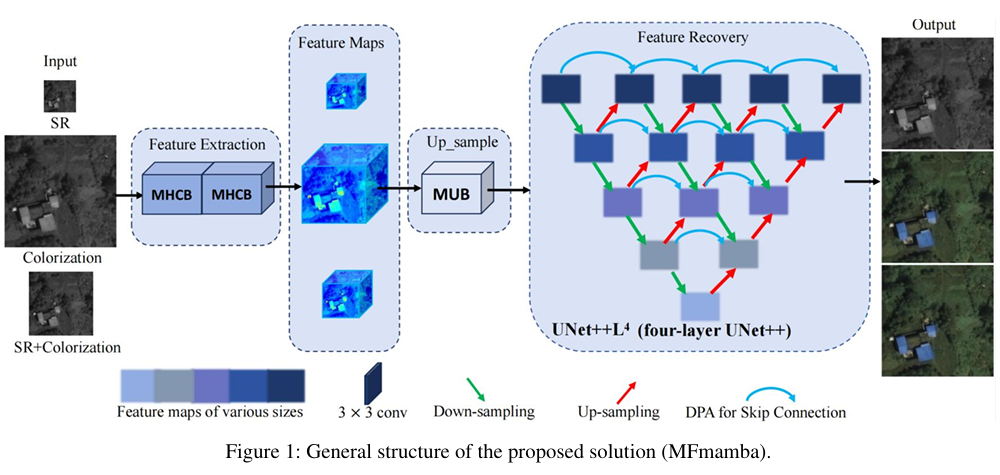
2.2 核心模块
模块一:多尺度混合交叉块 (MHCB)
-
核心功能: 作为网络的初始特征提取单元,旨在高效捕获输入图像的局部细节和多尺度上下文信息。
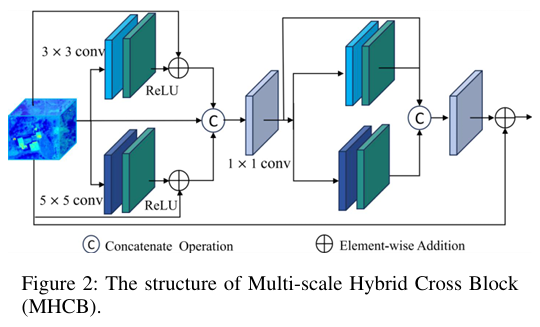
-
实现逻辑: 该模块并行设置了多个不同感受野的卷积路径。具体而言,它同时使用 3x3 卷积和 5x5 卷积分别提取局部和全局特征,并结合残差连接增强信息流。随后,通过 1x1 卷积对不同尺度的特征进行融合,并再次进行多尺度提取与融合,从而强化关键特征的持久性。其核心计算过程如下:
{X1=ReLU(3×3Conv(X))⊕X,X2=ReLU(5×5Conv(X))⊕X, \begin{cases} X_1 = \text{ReLU}(3 \times 3\text{Conv}(X)) \oplus X, \\ X_2 = \text{ReLU}(5 \times 5\text{Conv}(X)) \oplus X, \end{cases} {X1=ReLU(3×3Conv(X))⊕X,X2=ReLU(5×5Conv(X))⊕X,
X3=1×1Conv(Concat(X1,X2,X)), X_3 = 1 \times 1\text{Conv}(\text{Concat}(X_1, X_2, X)), X3=1×1Conv(Concat(X1,X2,X)),
{X4=ReLU(3×3Conv(X3)),X5=ReLU(5×5Conv(X3)), \begin{cases} X_4 = \text{ReLU}(3 \times 3\text{Conv}(X_3)), \\ X_5 = \text{ReLU}(5 \times 5\text{Conv}(X_3)), \end{cases} {X4=ReLU(3×3Conv(X3)),X5=ReLU(5×5Conv(X3)),
MHCBout=1×1Conv((Concat(X3,X4,X5))⊕X, \text{MHCB}_{\text{out}} = 1 \times 1\text{Conv}((\text{Concat}(X_3, X_4, X_5)) \oplus X, MHCBout=1×1Conv((Concat(X3,X4,X5))⊕X, -
优势: 相比单一尺寸的卷积核,MHCB能够同时关注不同范围的图像信息,有效提升了模型对复杂细节的提取能力,并利用密集的残差分组设计保证了梯度在网络中稳定传播。
模块二:双池化注意力 (DPA)
- 核心功能: 用于替代 UNet++ 中的标准跳跃连接,旨在通过动态调整通道权重来优化特征传递,使模型能聚焦于更重要的特征通道。
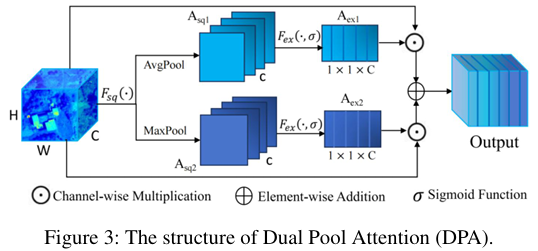
- 实现逻辑: DPA 采用了一种双流架构进行通道特征校准。它并行使用**自适应全局平均池化 (Adaptive Average Pooling)和最大池化 (Maximum Pooling)**来压缩全局空间信息,分别生成两个不同的通道描述符。这两个描述符经过 Sigmoid 函数激活后,生成两组通道权重,并分别与输入特征相乘。最后,将两个加权后的特征图相加,得到最终输出。
{Asq1=APc(i,j)=1H×W∑i=1H∑j=1WXi,j,c,Asq2=MPc(i,j)=maxp,q∈{1,...,k}Xp,q,c, \begin{cases} A_{sq1} = \text{AP}_c(i,j) = \frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} X_{i,j,c}, \\ A_{sq2} = \text{MP}_c(i,j) =\max_{p,q\in\{1,...,k\}} X_{p,q,c}, \end{cases} {Asq1=APc(i,j)=H×W1∑i=1H∑j=1WXi,j,c,Asq2=MPc(i,j)=maxp,q∈{1,...,k}Xp,q,c,
{Aex1=sigmoid(Asq1),Aex2=sigmoid(Asq2), \begin{cases} A_{ex1} = \text{sigmoid}(A_{sq1}), \\ A_{ex2} = \text{sigmoid}(A_{sq2}), \end{cases} {Aex1=sigmoid(Asq1),Aex2=sigmoid(Asq2),
DPAout=(X⊙Aex1)⊕(X⊙Aex2), \text{DPA}_{\text{out}} = (X \odot A_{ex1}) \oplus (X \odot A_{ex2}), DPAout=(X⊙Aex1)⊕(X⊙Aex2), - 优势: 传统注意力机制常单独使用平均池化。DPA 通过额外引入最大池化,能够更好地捕捉特征图中显著的、高激活度的信息(如边缘和纹理),与平均池化关注的全局平滑信息形成互补,从而实现更全面的特征信息保留和增强。
模块三:Mamba上采样模块 (MUB)
- 核心功能: 承担图像的上采样和分辨率恢复任务,利用状态空间模型的长序列建模能力来提升上下文信息的感知和重建效果。
- 实现逻辑: MUB 的核心是二维选择性扫描机制 (2D-SSM),它源于Mamba模型。该机制将一个一维序列输入 x(t)x(t)x(t) 通过一个隐状态 h(t)h(t)h(t) 映射到输出 y(t)y(t)y(t)。其连续形式由线性常微分方程 (ODE) 定义:
h′(t)=Ah(t)+Bx(t),y(t)=Ch(t)+Dx(t), h'(t) = Ah(t) + Bx(t), \quad y(t) = Ch(t) + Dx(t), h′(t)=Ah(t)+Bx(t),y(t)=Ch(t)+Dx(t),
通过零阶保持(ZOH)离散化后,得到适合深度学习模型使用的离散形式:
hτ=Aˉhτ−1+Bˉxτ,yτ=Chτ+Dxτ, h_{\tau} = \bar{A}h_{\tau-1} + \bar{B}x_{\tau}, \quad y_{\tau} = Ch_{\tau} + Dx_{\tau}, hτ=Aˉhτ−1+Bˉxτ,yτ=Chτ+Dxτ,
在 MUB 中,作者将该机制应用于2D图像特征。特别地,它将传统的四个扫描方向扩展到了六个(增加了两个对角线方向),以更全面地捕捉空间依赖关系。特征图在每个方向上被展平为1D序列进行处理,最后结果被整合回2D特征图。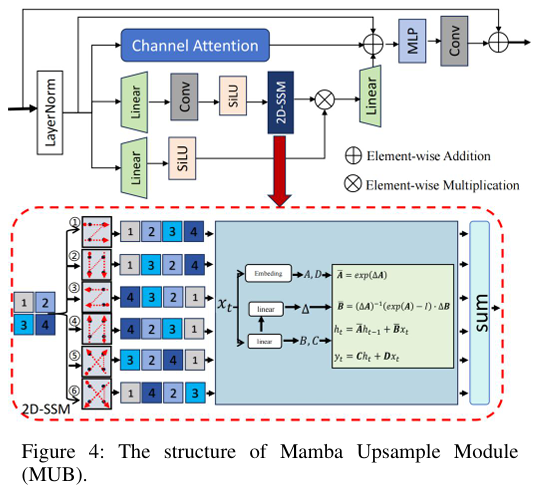
- 优势: 相比于 Transformer 在处理长序列时的高计算复杂度,基于状态空间模型的 Mamba 具有线性计算复杂度的优势,更为高效。同时,其选择性扫描机制使模型能够根据输入动态调整参数,从而更灵活地捕捉长距离依赖关系,有助于在分辨率恢复过程中重建更精准的全局结构和纹理。
03 模块适用任务
-
核心应用场景: 本方法主要针对遥感全色图像的分辨率复原。具体涵盖三个子任务:
- 单图像超分辨率 (Single Image Super-Resolution):提升灰度PAN图像的空间分辨率。
- 光谱恢复 (Spectral Recovery):为灰度PAN图像进行着色。
- 联合超分与光谱恢复 (Joint SR and Spectral Recovery):同时提升PAN图像的空间分辨率和光谱分辨率,即从低分辨率灰度图生成高分辨率彩色图。
-
方法论核心: 其核心思想是在一个统一的深度网络框架内,集成多功能模块以协同解决耦合的图像复原任务。它通过专门设计的特征提取、注意力机制和基于状态空间模型的重建模块,实现了从单一输入源到多重增强输出的高效转换,避免了传统多阶段方法的误差累积。
-
启发性拓展:
- 推广至其他医学/自然图像复原: MFmamba 的框架设计具有普适性,其集成的 MHCB、DPA 和 MUB 模块可被迁移至其他领域的图像复原任务,如医学图像去噪、常规照片的低光增强或伪影去除。
- 轻量化与实时化: 尽管 Mamba 比 Transformer 高效,但整个网络的参数量和计算成本仍是挑战。未来的研究可以探索模型剪枝、知识蒸馏等技术,开发适用于星上实时处理或移动端应用的轻量级版本。
04 实验结果与可视化分析
核心实验与结论
本文的核心贡献在于实现对PAN图像的联合超分辨率和光谱恢复,因此选择该任务的对比实验进行阐述。
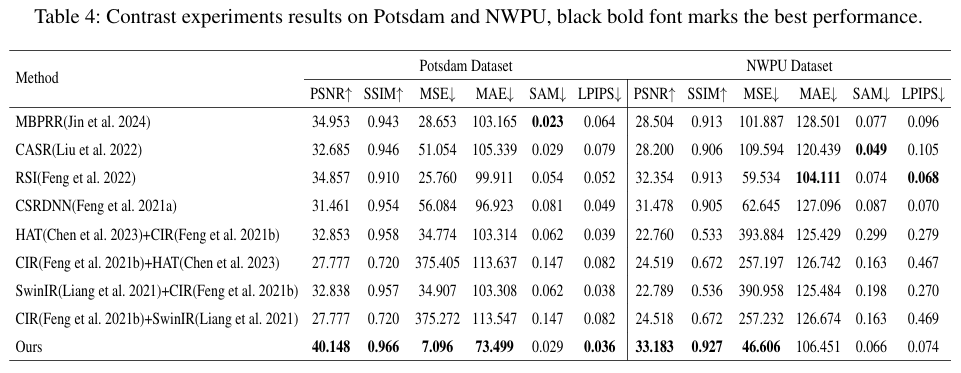
- 实验目的: 该实验旨在验证 MFmamba 模型在同时执行超分辨率(x2)和着色任务时,相较于其他现有集成模型(如MBPRR, CASR, RSI)以及串联不同SOTA模型(如HAT+CIR, SwinIR+CIR)的优越性。
- 关键结果: 实验在 Potsdam 和 NWPU 等多个数据集上进行。从论文表4的数据可以看出,MFmamba 在各项关键评估指标上均表现出显著优势。例如,在Potsdam数据集上,MFmamba的PSNR达到40.148,SSIM为0.967,远高于其他方法(如MBPRR的PSNR为34.953)。同样,在MSE和MAE等误差指标上,MFmamba 的值(7.096和73.499)也远低于对手。论文图5的可视化结果直观地展示了MFmamba生成的图像在色彩真实性、纹理细节和整体清晰度上最接近标签(Label)图像。
- 作者结论: 作者基于上述实验结果得出结论:MFmamba 作为一个统一的端到端网络,在联合SR和光谱恢复任务上具有卓越的性能。它不仅超越了专门为该联合任务设计的模型,也优于将顶级的SR模型和着色模型简单串联的策略,证明了其一体化设计的有效性,能够更好地提取和恢复图像的细节与关键信息。

05 即插即用模块代码
多尺度混合交叉块(MHCB)
- 核心功能:并行多尺度卷积(3×3与5×5)与瓶颈融合,完成浅层多尺度特征提取与残差增强
- 核心优势:同时覆盖局部与更大感受野的信息,并通过密集融合稳固梯度传播与关键细节保留
- 核心代码(片段):
import torch
import torch.nn as nn
from model import net_common as common
class MDCB(nn.Module):
def __init__(self, ch_in, ch_out, bias=True, activation=nn.ReLU(inplace=True)):
super(MDCB, self).__init__()
kernel_size_1 = 3
kernel_size_2 = 5
self.conv_3_1 = common.default_conv(ch_in=ch_in, ch_out=ch_in, kernel_size=kernel_size_1, bias=bias)
self.conv_3_2 = common.default_conv(ch_in=ch_out, ch_out=ch_out, kernel_size=kernel_size_1, bias=bias)
self.conv_5_1 = common.default_conv(ch_in=ch_in, ch_out=ch_in, kernel_size=kernel_size_2, bias=bias)
self.conv_5_2 = common.default_conv(ch_in=ch_out, ch_out=ch_out, kernel_size=kernel_size_2, bias=bias)
self.confusion_3 = nn.Conv2d(ch_in * 3, ch_out, 1, padding=0, bias=True)
self.confusion_5 = nn.Conv2d(ch_in * 3, ch_out, 1, padding=0, bias=True)
self.confusion_bottle = nn.Conv2d(ch_in * 3 + ch_out * 2, ch_out, 1, padding=0, bias=True)
self.activation = activation
def forward(self, x):
input_1 = x
output_3_1 = self.activation(self.conv_3_1(input_1))
output_3_1 += x
output_5_1 = self.activation(self.conv_5_1(input_1))
output_5_1 += x
input_2 = torch.cat([input_1, output_3_1, output_5_1], 1)
input_2_3 = self.confusion_3(input_2)
input_2_5 = self.confusion_5(input_2)
output_3_2 = self.activation(self.conv_3_2(input_2_3))
output_5_2 = self.activation(self.conv_5_2(input_2_5))
input_3 = torch.cat([input_1, output_3_1, output_5_1, output_3_2, output_5_2], 1)
output = self.confusion_bottle(input_3)
return output
双池化注意力(DPA)
- 核心功能:并行通道全局平均池化与最大池化,经轻量MLP/卷积生成通道校准权重,对输入进行双路加权并融合
- 核心优势:平均池化提供全局稳定性,最大池化捕获显著纹理,二者互补提升通道选择性与跨层特征传递质量
- 核心代码(片段):
import torch
import torch.nn as nn
class Multi_SEAttention(nn.Module):
def __init__(self, in_planes, reduction=16):
super(Multi_SEAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Sequential(
nn.Linear(in_planes, in_planes // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_planes // reduction, in_planes, bias=False),
nn.Sigmoid()
)
self.fc2 = nn.Sequential(
nn.Linear(in_planes, in_planes // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_planes // reduction, in_planes, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc1(y).view(b, c, 1, 1)
z = self.max_pool(x).view(b, c)
z = self.fc2(z).view(b, c, 1, 1)
x1 = x * y.expand_as(x)
x2 = x * z.expand_as(x)
x_sum = x1 + x2 + x
return x_sum
替换建议:在 UNet++ 组装处将 se_block=No_Multi_SEAttention 改为 se_block=Multi_SEAttention(model/net.py:433–439);另一实现(卷积版DPA)见 model/net_common.py:33–49
Mamba上采样模块(MUB)
- 核心功能:基于状态空间模型的二维选择性扫描(含多方向序列展平与并行SSM推理),深特征重建后接像素重排上采样
- 核心优势:线性复杂度的长程依赖建模与方向性上下文聚合,较Transformer更高效,适配高分辨率重建
- 核心代码(片段):
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import repeat
from mamba_ssm.ops.selective_scan_interface import selective_scan_fn
class SS2D(nn.Module):
def __init__(self, d_model, d_state=16, d_conv=3, expand=2., dt_rank="auto",
dt_min=0.001, dt_max=0.1, dt_init="random", dt_scale=1.0, dt_init_floor=1e-4,
dropout=0., conv_bias=True, bias=False, device=None, dtype=None, **kwargs):
super().__init__()
self.d_model = d_model
self.d_state = d_state
self.d_conv = d_conv
self.expand = expand
self.d_inner = int(self.expand * self.d_model)
self.dt_rank = math.ceil(self.d_model / 16) if dt_rank == "auto" else dt_rank
self.in_proj = nn.Linear(self.d_model, self.d_inner * 2, bias=bias)
self.conv2d = nn.Conv2d(self.d_inner, self.d_inner, groups=self.d_inner, bias=conv_bias,
kernel_size=d_conv, padding=(d_conv - 1) // 2)
self.act = nn.SiLU()
self.x_proj_weight = nn.Parameter(torch.empty(4, self.d_inner, (self.dt_rank + self.d_state * 2)))
self.dt_projs_weight = nn.Parameter(torch.empty(4, self.d_inner, self.dt_rank))
self.dt_projs_bias = nn.Parameter(torch.empty(4 * self.d_inner))
self.A_logs = nn.Parameter(torch.log(repeat(torch.arange(1, d_state + 1, dtype=torch.float32), "n -> d n", d=self.d_inner)))
self.Ds = nn.Parameter(torch.ones(4 * self.d_inner))
self.selective_scan = selective_scan_fn
self.out_norm = nn.LayerNorm(self.d_inner)
self.out_proj = nn.Linear(self.d_inner, self.d_model, bias=bias)
self.dropout = nn.Dropout(dropout) if dropout > 0. else None
def forward_core(self, x: torch.Tensor):
B, C, H, W = x.shape
L = H * W
K = 4
x_hwwh = torch.stack([x.view(B, -1, L), torch.transpose(x, 2, 3).contiguous().view(B, -1, L)], dim=1).view(B, 2, -1, L)
xs = torch.cat([x_hwwh, torch.flip(x_hwwh, dims=[-1])], dim=1)
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs.view(B, K, -1, L), self.x_proj_weight)
dts, Bs, Cs = torch.split(x_dbl, [self.dt_rank, self.d_state, self.d_state], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts.view(B, K, -1, L), self.dt_projs_weight)
xs = xs.float().view(B, -1, L)
dts = dts.contiguous().float().view(B, -1, L)
Bs = Bs.float().view(B, K, -1, L)
Cs = Cs.float().view(B, K, -1, L)
Ds = self.Ds.float().view(-1)
As = -torch.exp(self.A_logs.float()).view(-1, self.d_state)
dt_projs_bias = self.dt_projs_bias.float().view(-1)
out_y = self.selective_scan(xs, dts, As, Bs, Cs, Ds, z=None, delta_bias=dt_projs_bias, delta_softplus=True,
return_last_state=False).view(B, K, -1, L)
inv_y = torch.flip(out_y[:, 2:4], dims=[-1]).view(B, 2, -1, L)
wh_y = torch.transpose(out_y[:, 1].view(B, -1, W, H), 2, 3).contiguous().view(B, -1, L)
invwh_y = torch.transpose(inv_y[:, 1].view(B, -1, W, H), 2, 3).contiguous().view(B, -1, L)
view5_y = torch.transpose(out_y[:, 3].view(B, -1, W, H), 2, 3).contiguous().view(B, -1, L)
inv_view5_y = torch.flip(view5_y, dims=[-1]).view(B, -1, L)
view6_y = torch.transpose(out_y[:, 3].view(B, -1, W, H), 2, 3).contiguous().view(B, -1, L)
inv_view6_y = torch.flip(view6_y, dims=[-1]).view(B, -1, L)
return out_y[:, 0], inv_y[:, 0], wh_y, invwh_y, inv_view5_y, inv_view6_y
def forward(self, x: torch.Tensor, **kwargs):
B, H, W, C = x.shape
xz = self.in_proj(x)
x, z = xz.chunk(2, dim=-1)
x = x.permute(0, 3, 1, 2).contiguous()
x = self.act(self.conv2d(x))
y1, y2, y3, y4, y5, y6 = self.forward_core(x)
y = y1 + y2 + y3 + y4 + y5 + y6
y = torch.transpose(y, 1, 2).contiguous().view(B, H, W, -1)
y = self.out_norm(y)
y = y * F.silu(z)
out = self.out_proj(y)
if self.dropout is not None:
out = self.dropout(out)
return out
集成位置(用于2×上采样的头部):model/net.py:263–269,完整网络封装见 mambaIR.py:401–501 与工厂函数 mambaIR.py:705–724

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)