强化学习数学基础:MDP、奖励、策略、价值函数——用大白话讲透每个公式
本文用通俗语言解析强化学习的四大数学基础:1. MDP(马尔可夫决策过程)是描述强化学习问题的框架,包含状态、动作、转移概率和奖励;2. 奖励函数是智能体的评分系统,即时奖励和考虑未来折扣的累积奖励;3. 策略是智能体的行动指南,分为确定性策略和随机策略;4. 价值函数评估状态或动作的长期价值,包括状态价值函数V(s)和动作价值函数Q(s,a)。文章还解释了核心的贝尔曼方程,并提供了公式速查表和常
目录
四、价值函数(Value Function):评估"这步棋值多少钱"
摘要
强化学习的论文和教程里满是数学公式,看得人头大?
别怕!本文将用最通俗的大白话带你拆解强化学习的四大数学基石:
MDP:强化学习问题的"游戏规则说明书"
奖励:告诉智能体什么是好、什么是坏的"评分系统"
策略:智能体的"行动指南"
价值函数:评估"这个位置/这步棋值多少钱"
每个公式我都会先给出数学形式,然后用人话翻译,保证你看完能真正理解,而不只是会背!
一、MDP:强化学习的"游戏规则说明书"
1.1 什么是MDP?
MDP(Markov Decision Process,马尔可夫决策过程) 是描述强化学习问题的标准数学框架。
大白话:MDP就像一份详细的"游戏规则说明书",它告诉你:
游戏里有哪些场景(状态)
你能做哪些操作(动作)
做了操作会发生什么(转移)
做得好不好怎么打分(奖励)
1.2 MDP的五元组定义
| 符号 | 名称 | 大白话解释 |
|---|---|---|
| S | 状态空间 | 游戏里所有可能的"场景"集合 |
| A | 动作空间 | 你能做的所有"操作"集合 |
| P | 转移概率 | 做了某操作后,下一步会变成什么场景的概率 |
| R | 奖励函数 | 每一步操作的"得分" |
| γ | 折扣因子 | 未来的分数打几折?(0到1之间) |
1.3 马尔可夫性质
大白话翻译:
"未来只跟现在有关,跟历史无关。"
就像下棋,只要你告诉我现在棋盘长什么样,我就能判断下一步会怎样。至于你是怎么一步步走到现在的,无所谓。
这就是"马尔可夫性"——历史已经浓缩在当前状态里了。
二、奖励(Reward):智能体的"评分系统"
2.1 即时奖励
大白话翻译:
在状态
做了动作
,转移到
后,你获得的即时得分就是
。
举例:
吃豆人吃到豆子:r = +10
碰到鬼:r = -100
普通移动:r = -1(鼓励尽快通关)
2.2 累积奖励(回报)
🗣️ 大白话翻译:
是从 t 时刻开始,一直到游戏结束,你能拿到的总得分。
但注意:未来的分数要打折!
现在拿的分是 100% 的
下一步拿的分只算γ(比如0.99)倍
再下一步只算γ^2(0.98)倍
……
为什么要打折? 因为"现在就能拿到的钱"比"未来可能拿到的钱"更实在!
2.3 折扣因子 γ 的影响
| γ值 | 含义 | 智能体表现 |
|---|---|---|
| γ = 0 | 完全不考虑未来 | 极度短视,只看眼前利益 |
| γ = 0.9 | 未来打9折 | 比较平衡 |
| γ = 0.99 | 几乎不打折 | 非常有远见 |
| γ = 1 | 完全不打折 | 极端长远(可能不收敛) |
记忆口诀:γ 越大越有远见,γ 越小越短视
三、策略(Policy):智能体的"行动指南"
3.1 策略的定义
策略就是告诉智能体"在什么状态下该做什么动作"的规则。
确定性策略
a=π(s)a = π(s)
大白话翻译:
看到状态 s,直接告诉你该做动作 a。一个萝卜一个坑,没有任何随机性。
举例:下棋软件——输入棋盘状态,输出一个确定的落子位置。
随机策略
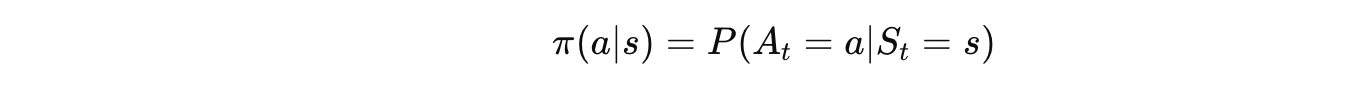
大白话翻译:
看到状态 s,告诉你做每个动作的概率。
比如:$\pi(\text{左}|s)= 0.7$,$\pi(\text{右}|s) = 0.3$
意思是:在状态 s 下,有 70% 概率向左,30% 概率向右。
为什么需要随机? 因为有时候"随机探索"能发现更好的策略,或者能让对手无法预测你。
3.2 策略的数学性质
对于随机策略,所有动作的概率之和必须等于1:
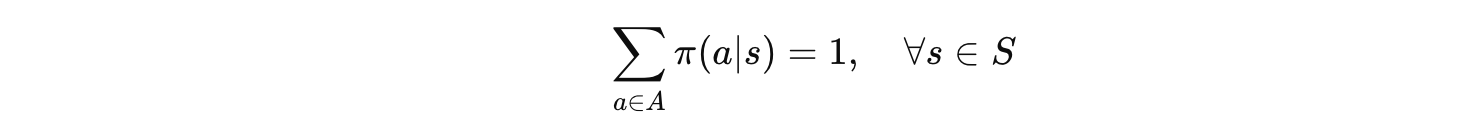
大白话:在任何状态下,你肯定要做"某一个"动作,所以所有动作的概率加起来必须是100%。
四、价值函数(Value Function):评估"这步棋值多少钱"
价值函数是强化学习里最核心的概念之一!
4.1 状态价值函数 V(s)
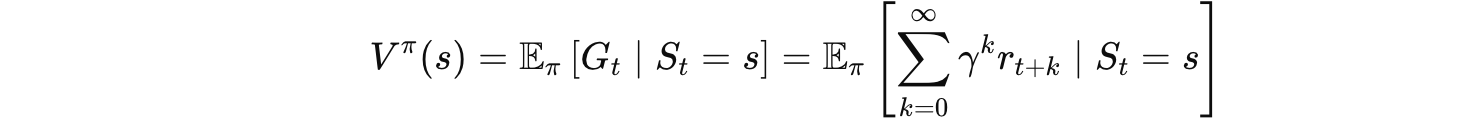
大白话翻译:
"从状态 s 出发,按照策略 π 一直玩下去,平均能拿多少总分?"
V(s) 高 → 这个状态是个"好位置"
V(s) 低 → 这个状态是个"烂摊子"
举例:
象棋里,你车马炮俱全,对方只剩一个王,V(s) 很高
你被将军了、快输了,V(s) 很低
4.2 动作价值函数 Q(s, a)
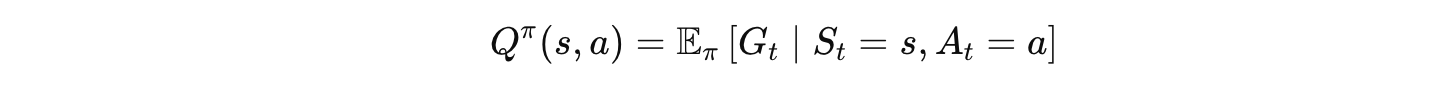
大白话翻译:
"在状态 s 下,如果先做动作 a,然后按策略 π 一直玩下去,平均能拿多少总分?"
Q(s,a) 比 V(s) 多了一个维度——不仅告诉你这个状态好不好,还告诉你在这个状态下做哪个动作最值。
举例:
在十字路口(状态s),向左走 Q(s,左)=100,向右走 Q(s,右)=50
说明在这里,向左走更划算
4.3 V 和 Q 的关系
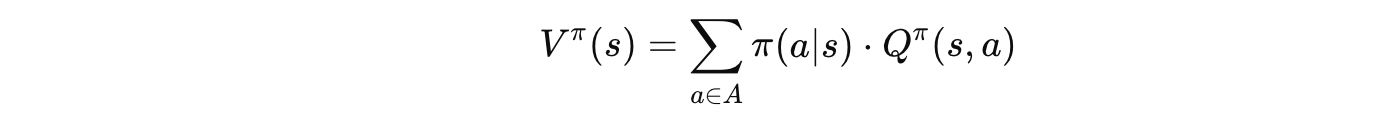
🗣️ 大白话翻译:
状态价值 = 各个动作价值的加权平均(权重是选择该动作的概率)
4.4 最优价值函数
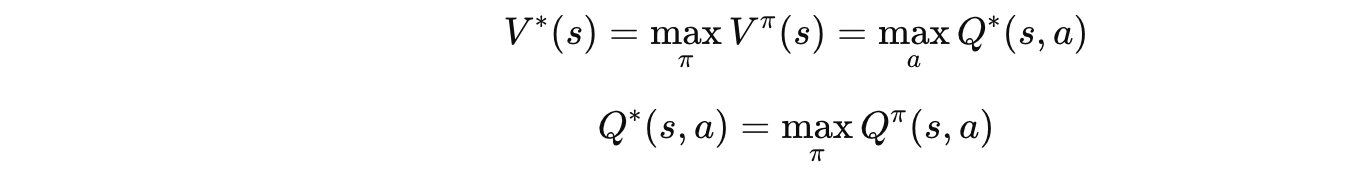
🗣️ 大白话翻译:
V^*(s):在状态 s 下,用最牛的策略能拿到的平均总分
Q^*(s,a):在状态 s 下做动作 a,然后用最牛的策略能拿到的平均总分
五、贝尔曼方程:价值函数的"递归定义"
贝尔曼方程是强化学习的核心数学工具,几乎所有算法都建立在它之上。
5.1 贝尔曼期望方程(针对 $V^\pi$)
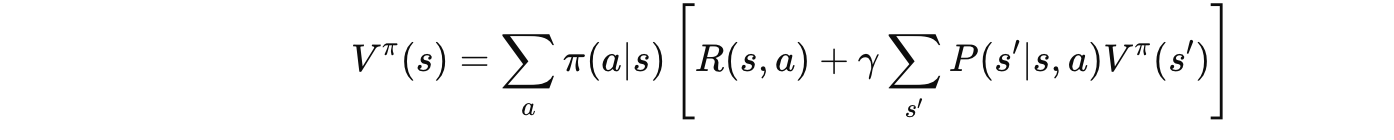
🗣️ 大白话翻译:
"当前状态的价值 = 这一步的奖励 + 下一状态价值的折现"
分解一下:
根据策略 π,我会以概率 π(a|s) 选择动作 a
做了动作a,立刻得到奖励R(s,a)
环境以概率 P(s'|s,a) 转移到下一状态 s'
下一状态 s' 的价值是 V^π(s'),但要打折(乘以 \gamma)
把所有可能性加权求和
5.2 贝尔曼期望方程(针对 $Q^\pi$)
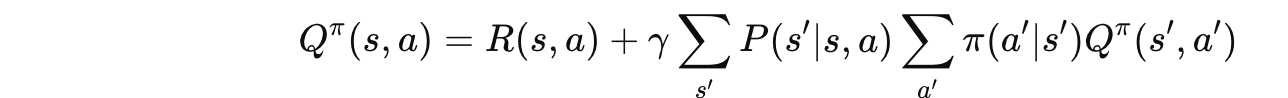
🗣️ 大白话翻译:
"做动作 $a$ 的价值 = 这一步的奖励 + 到达下一状态后,继续按策略行动的价值"
5.3 贝尔曼最优方程
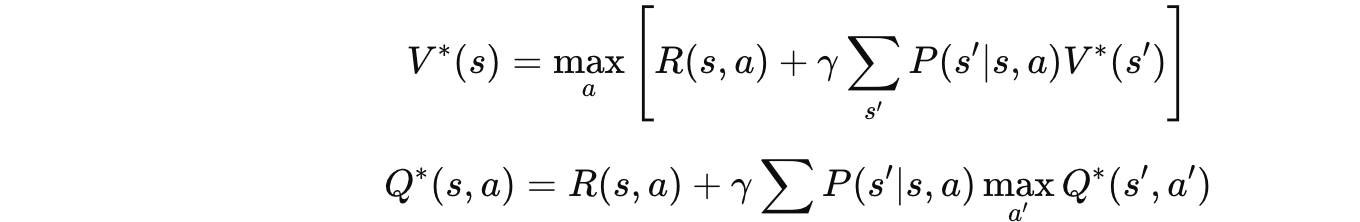
🗣️ 大白话翻译:
和期望方程的唯一区别:把"按策略选"换成"选最好的"!
期望方程:按策略 $\pi$ 的概率加权平均
最优方程:直接取 max,选价值最大的那个动作
5.4 贝尔曼方程的直觉图示
当前状态 s
│
│ 选择动作 a (按策略或取max)
▼
┌────┴────┐
│ 即时奖励 │ ← 这一步得到的分
│ R(s,a) │
└────┬────┘
│
┌───────────┼───────────┐
▼ ▼ ▼
s'_1 s'_2 s'_3 ← 可能转移到的下一状态
│ │ │
▼ ▼ ▼
γ·V(s'_1) γ·V(s'_2) γ·V(s'_3) ← 下一状态的价值(打折后)
│ │ │
└───────────┴───────────┘
│
▼
按概率加权求和
│
▼
V(s) 或 Q(s,a)
六、公式速查表
| 名称 | 公式 | 一句话解释 |
|---|---|---|
| 累积回报 | 从现在到未来的总得分(未来打折) | |
| 状态价值 | 从这个状态出发,平均能拿多少分 | |
| 动作价值 | 在这个状态做这个动作,平均能拿多少分 | |
| V和Q的关系 | 状态价值是动作价值的加权平均 | |
| 最优策略 | 选Q值最大的动作 | |
| 贝尔曼方程 | 当前价值 = 即时奖励 + 折扣后的未来价值 |
七、常见疑问解答
Q1:为什么需要折扣因子 γ
数学上:保证无限序列求和收敛
经济学上:未来的收益有不确定性,要折现
实践上:让智能体更注重近期奖励,加速学习
Q2:V 和 Q 只需要一个不就够了吗?
只有 V:知道状态好不好,但不知道该怎么选动作(除非知道环境模型)
只有 Q:直接 $\max_a Q(s,a)$ 就能选动作,无需环境模型!
所以 Q 函数在 Model-Free 算法(如DQN)中更常用
Q3:贝尔曼方程有什么用?
它是几乎所有RL算法的数学基础:
动态规划(DP):迭代求解贝尔曼方程
Q-Learning:用贝尔曼最优方程做TD更新
Actor-Critic:用贝尔曼期望方程估计价值
八、总结
┌─────────────────────────────────────────┐
│ 强化学习数学基础 │
└───────────────────┬─────────────────────┘
│
┌───────────────────┼───────────────────┐
▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ MDP │ │ 策略 │ │ 价值函数 │
│(游戏规则)│ │(行动指南)│ │(价值评估)│
└────┬────┘ └────┬────┘ └────┬────┘
│ │ │
▼ ▼ ▼
S, A, P, R, γ π(a|s) V(s), Q(s,a)
│ │ │
└──────────────────┴──────────────────┘
│
▼
┌───────────────┐
│ 贝尔曼方程 │
│ (核心等式) │
└───────────────┘
│
▼
RL算法的数学基础
核心公式记忆口诀
回报 G:"现在的分最实在,未来的分要打折"
价值 V:"站在这儿往前看,平均能拿多少分"
Q 值:"先走这一步,再看平均分"
贝尔曼:"现在 = 眼前 + 折扣 × 未来"
💬 写在最后:数学公式看着吓人,但只要用对方法拆解,其实每个公式都在讲一个简单的道理。希望这篇文章能帮你建立对强化学习数学基础的直觉理解!
如果觉得有帮助,欢迎点赞👍收藏⭐关注🔔,下一篇我们来聊聊策略梯度的公式推导!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)