强化学习入门第一课:RL到底解决什么问题?与监督学习、模仿学习的本质区别
摘要:本文系统解析了强化学习的核心概念及其与监督学习、模仿学习的区别。强化学习通过试错机制解决序贯决策问题,以最大化长期奖励为目标,适合游戏AI、机器人控制等场景。与监督学习依赖标注数据不同,强化学习需要自主探索;模仿学习则通过模仿专家行为获取策略。文章通过对比表格和流程图,帮助读者理解三种范式的适用场景与优缺点,并指出实际应用中常将三者结合使用(如RLHF)。最后澄清常见误区,为初学者提供清晰的
摘要
刚接触强化学习时,你是否有过这样的困惑:
强化学习和监督学习到底有什么区别?
什么时候该用强化学习,什么时候该用监督学习?
模仿学习又是什么?和强化学习有什么关系?
本文将从问题本质出发,带你彻底搞懂强化学习的核心定位,并通过对比分析帮助你建立清晰的认知框架。无论你是AI初学者还是想系统梳理知识的开发者,这篇文章都将为你扫清迷雾!
一、强化学习到底解决什么问题?
1.1 一句话概括
强化学习(Reinforcement Learning, RL)解决的是:智能体(Agent)如何在与环境的交互中,通过试错学习,找到能够最大化长期累积奖励的最优策略。
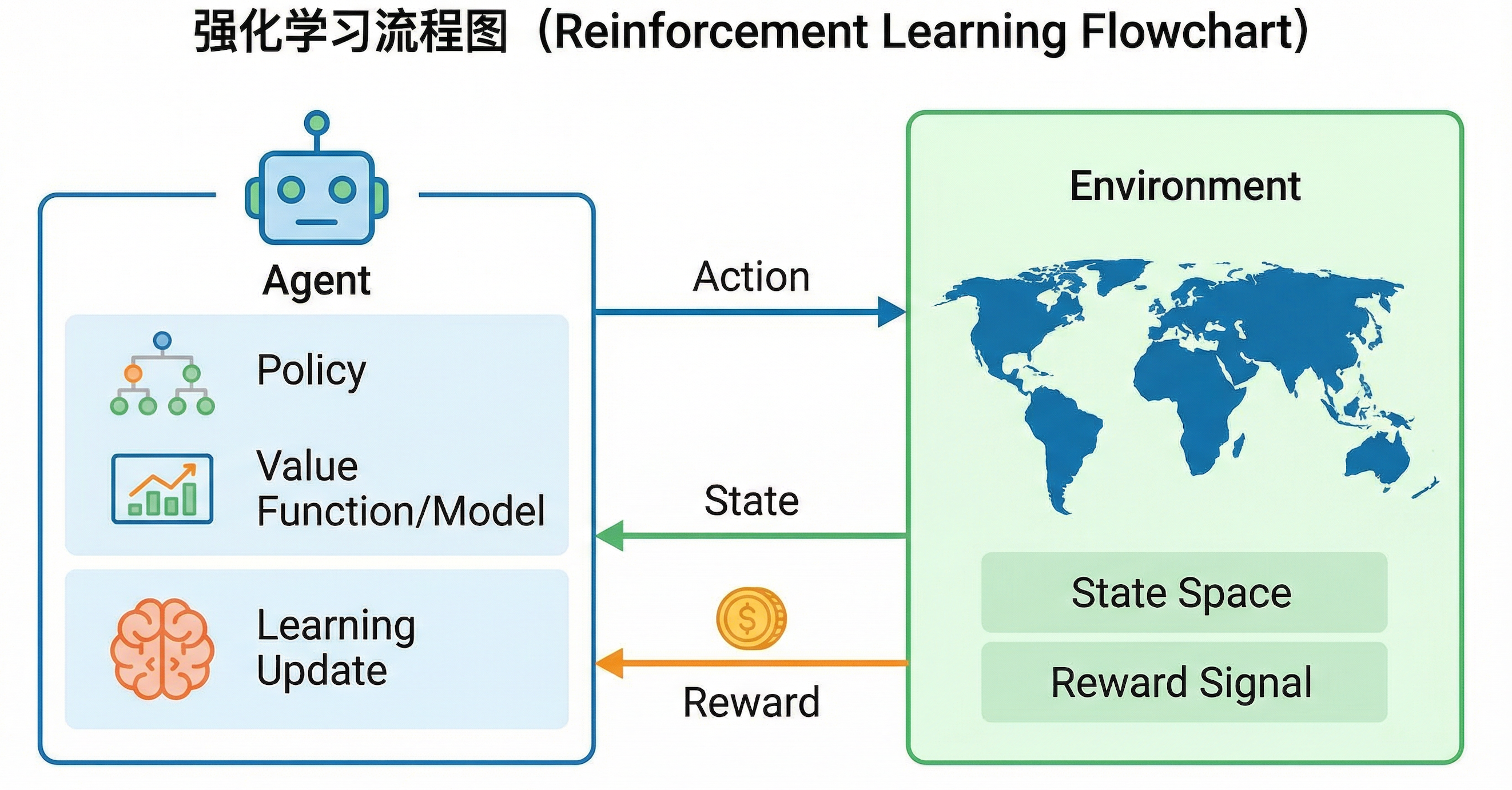
用更通俗的话说:
强化学习就像教一个"小白"玩游戏——没有攻略、没有标准答案,只能自己不断尝试,根据得分(奖励)来判断什么操作是好的,最终学会通关。
1.2 核心要素:MDP框架
强化学习问题通常用马尔可夫决策过程(MDP) 来形式化描述:
MDP = (S, A, P, R, γ)
| 符号 | 含义 | 说明 |
|---|---|---|
| S | 状态空间(State Space) | 环境所有可能的状态集合 |
| A | 动作空间(Action Space) | 智能体可执行的所有动作集合 |
| P | 状态转移概率(Transition Probability) | P(s′∣s,a) |
| R | 奖励函数(Reward Function) | R(s,a,s') 执行动作后获得的即时奖励 |
| γ | 折扣因子(Discount Factor) | γ∈[0,1],衡量未来奖励的重要程度 |
1.3 强化学习的目标
智能体的目标是找到一个最优策略 π*,使得累积折扣奖励的期望值最大化: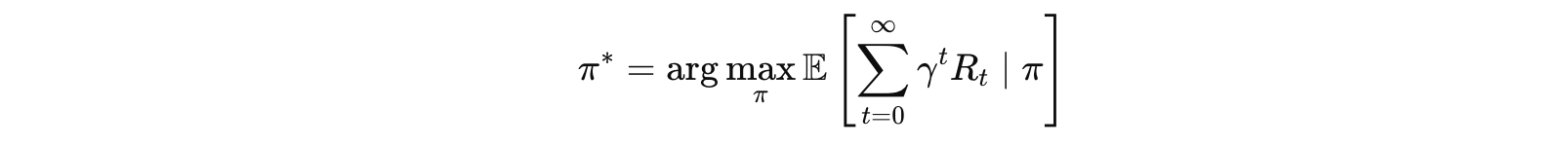
1.4 强化学习的核心特点
| 特点 | 说明 |
|---|---|
| 序贯决策 | 决策是连续的,当前决策会影响未来状态 |
| 延迟奖励 | 好的行为可能不会立即得到奖励,需要长远考虑 |
| 试错学习 | 没有"标准答案",通过不断尝试来学习 |
| 探索与利用权衡 | 既要尝试新动作(探索),又要利用已知好动作(利用) |
1.5 强化学习适合解决什么问题?
适合场景:
-
游戏AI(围棋AlphaGo、Atari游戏、星际争霸)
-
机器人控制(机械臂操作、行走控制)
-
自动驾驶(决策规划层)
-
推荐系统(长期用户留存优化)
-
资源调度(数据中心能耗优化)
-
金融交易(量化策略)
不适合场景:
-
有大量标注数据的分类/回归问题
-
无需序贯决策的静态问题
-
奖励难以定义或获取的问题
🔍 二、强化学习 vs 监督学习 vs 模仿学习
2.1 三种学习范式的本质区别
┌─────────────────────────────────────────────────────────────────┐
│ 机器学习三大范式 │
├─────────────────┬─────────────────┬─────────────────────────────┤
│ 监督学习 │ 强化学习 │ 模仿学习 │
│ Supervised │ Reinforcement │ Imitation Learning │
│ Learning │ Learning │ │
├─────────────────┼─────────────────┼─────────────────────────────┤
│ │ │ │
│ 输入 → 标签 │ 状态 → 动作 │ 专家轨迹 → 策略 │
│ (x, y) │ (s, a, r, s') │ {τ_expert} │
│ │ │ │
│ "告诉答案" │ "自己探索" │ "模仿老师" │
│ │ │ │
└─────────────────┴─────────────────┴─────────────────────────────┘
2.2 详细对比表
| 维度 | 监督学习 | 强化学习 | 模仿学习 |
|---|---|---|---|
| 数据来源 | 人工标注的(输入,标签)对 | 与环境交互产生的(s,a,r,s') | 专家示范的轨迹数据 |
| 反馈信号 | 明确的标签(监督信号) | 稀疏/延迟的奖励信号 | 专家行为(隐式监督) |
| 学习目标 | 最小化预测误差 | 最大化累积奖励 | 模仿专家行为 |
| 是否需要环境 | 不需要 | 需要(核心) | ⚡ 可选(离线/在线) |
| 数据独立性 | i.i.d. 假设(独立同分布) | 非i.i.d.(序贯相关) | 通常假设i.i.d. |
| 探索需求 | ❌ 无需探索 | ✅ 需要探索 | ❌ 依赖专家覆盖 |
| 典型算法 | CNN, Transformer, SVM | DQN, PPO, SAC | BC, GAIL, DAgger |
| 代表应用 | 图像分类、NLP | 游戏AI、机器人 | 自动驾驶、机器人模仿 |
2.3 形象类比
| 学习范式 | 类比场景 |
|---|---|
| 监督学习 | 学生做习题,每道题都有标准答案,对照答案学习 |
| 强化学习 | 玩游戏,没有攻略,只能通过得分高低判断操作好坏 |
| 模仿学习 | 学徒跟着师傅,观察师傅怎么做,然后模仿 |
2.4 数据与反馈的核心差异
监督学习的数据
# 监督学习数据示例
dataset = [
(image_1, "cat"), # 输入图片,标签是"猫"
(image_2, "dog"), # 输入图片,标签是"狗"
(text_1, "positive"), # 输入文本,标签是"正面情感"
...
]
# 特点:每个样本独立,标签明确
强化学习的数据
# 强化学习数据示例(一条轨迹)
trajectory = [
(s0, a0, r0, s1), # 在状态s0执行动作a0,获得奖励r0,转移到s1
(s1, a1, r1, s2), # 在状态s1执行动作a1,获得奖励r1,转移到s2
(s2, a2, r2, s3), # ...
...
(sT, aT, rT, terminal) # 最终状态
]
# 特点:数据是序贯的,奖励可能稀疏(只在结束时给出)
模仿学习的数据
# 模仿学习数据示例(专家轨迹)
expert_demos = [
[(s0, a0_expert), (s1, a1_expert), ...], # 专家轨迹1
[(s0, a0_expert), (s1, a1_expert), ...], # 专家轨迹2
...
]
# 特点:只有状态-动作对,没有奖励信号
2.5 各自的优缺点分析
监督学习
| 优点 | 缺点 |
|---|---|
| 理论成熟,训练稳定 | 需要大量标注数据 |
| 收敛快,效果可预期 | 无法处理序贯决策问题 |
| 可解释性相对较好 | 标注成本高 |
强化学习
| 优点 | 缺点 |
|---|---|
| 无需标注,自主探索 | 样本效率低,训练慢 |
| 能处理复杂序贯决策 | 奖励函数设计困难 |
| 可发现超越人类的策略 | 训练不稳定,调参困难 |
模仿学习
| 优点 | 缺点 |
|---|---|
| 无需设计奖励函数 | 受限于专家水平(天花板效应) |
| 学习效率比RL高 | 分布偏移问题(Covariate Shift) |
| 适合难以定义奖励的任务 | 需要高质量专家数据 |
2.6 三者的联系与结合
实际应用中,三种方法经常结合使用:
┌─────────────────┐
│ 混合方法 │
└────────┬────────┘
│
┌────────────────────┼────────────────────┐
│ │ │
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ 模仿学习预训练 │ │RL + 监督辅助 │ │ RLHF │
│ + RL微调 │ │ 损失 │ │(人类反馈RL) │
│ │ │ │ │ │
│ 例:机器人 │ │ 例:带专家 │ │ 例:ChatGPT │
│ 先模仿再强化 │ │ 指导的RL │ │ 对齐训练 │
└───────────────┘ └───────────────┘ └───────────────┘
RLHF:三者融合的典型代表
大语言模型(如ChatGPT)的训练就是三种方法的完美结合:
-
监督学习(SFT):用人工标注的对话数据微调模型
-
模仿学习:本质上SFT也是在模仿人类标注者
-
强化学习(PPO):用人类偏好训练奖励模型,再用RL优化
三、常见误区与澄清
误区1:"强化学习一定比监督学习更强"
✅ 正确理解:没有万能的算法,只有适合的场景。如果你有大量高质量标注数据,监督学习往往更高效。
误区2:"模仿学习就是监督学习"
✅ 正确理解:虽然行为克隆(BC)形式上类似监督学习,但模仿学习面临独特的分布偏移问题,且目标是学习决策策略而非简单的输入输出映射。
误区3:"强化学习不需要任何先验知识"
✅ 正确理解:好的奖励函数设计、状态表示、网络架构选择都需要领域知识。RL并非"完全从零学习"。
误区4:"有了专家数据就不需要RL"
✅ 正确理解:模仿学习受限于专家水平。如果想超越专家,还是需要RL进行自主探索和优化。
四、总结
4.1 核心要点回顾
| 问题 | 答案 |
|---|---|
| 强化学习解决什么问题? | 序贯决策问题,通过试错最大化累积奖励 |
| 与监督学习的本质区别? | 无标签、有延迟奖励、需要探索、数据非i.i.d. |
| 与模仿学习的关系? | 模仿学习借助专家示范,可作为RL的初始化 |
| 如何选择? | 有标签用监督,有专家用模仿,需探索用RL |
4.2 选择指南流程图
开始
│
▼
┌───────────────┐
│ 有大量标注数据?│
└───────┬───────┘
│
Yes │ No
┌───────┴───────┐
▼ ▼
┌──────────┐ ┌───────────────┐
│ 监督学习 │ │ 有专家示范数据?│
└──────────┘ └───────┬───────┘
│
Yes │ No
┌───────┴───────┐
▼ ▼
┌──────────┐ ┌──────────┐
│ 模仿学习 │ │ 强化学习 │
│ (可+RL) │ │ │
└──────────┘ └──────────┘
下一步学习建议
-
理论基础:深入学习MDP、贝尔曼方程、策略梯度
-
经典算法:DQN → A2C → PPO → SAC
-
实践项目:从Gym环境开始,逐步挑战复杂任务
-
进阶方向:Offline RL、Multi-Agent RL、Model-based RL
参考资料
-
Sutton & Barto, "Reinforcement Learning: An Introduction"
-
OpenAI Spinning Up: https://spinningup.openai.com
-
《动手学强化学习》
-
CS285 (UC Berkeley) Deep Reinforcement Learning
💬 写在最后:强化学习是一个充满魅力的领域,它让机器能够像人类一样通过试错来学习。希望这篇文章能帮助你建立清晰的认知框架!如果觉得有帮助,欢迎点赞👍收藏⭐关注🔔,我们下篇文章见!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 31
31 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)