【医学影像 AI】视网膜基础语言-图像模型(FLAIR):通过文本监督编码专家知识
FLAIR,一个专用于视网膜眼底图像分析的视觉-语言基础模型。通过整合284,660张眼底图像和96种病理类别,FLAIR创新性地将专家知识以文本提示形式嵌入模型训练,包括病理细粒度特征描述和层级关系。实验表明,该模型在领域迁移和未知类别场景下展现出卓越的泛化能力,经轻量级微调后性能显著优于CLIP等通用模型及专用模型,为医学影像AI提供了专业化的基础模型解决方案。
【医学影像 AI】视网膜基础语言-图像模型(FLAIR):通过文本监督编码专家知识
0. 论文简介
0.1 基本信息
2025 年 Julio 等在 Medical Image Analysis 发表论文 “视网膜基础语言-图像模型(FLAIR):通过文本监督编码专家知识(A Foundation LAnguage-Image model of the Retina (FLAIR): Encoding expert knowledge in text supervision)”。
本文提出FLAIR,一款针对视网膜眼底图像理解的视觉 - 语言基础模型,通过整合 37 个公开数据集的 284,660 张图像和 96 种目标类别,以文本提示形式嵌入专家领域知识(涵盖病理细粒度特征及层级依赖关系),在领域迁移和未见类别场景下展现出强大的泛化能力,经轻量级线性探针适配后,在少样本等场景中显著优于 CLIP、BiomedCLIP 等通用模型及全训练数据集专用模型,为医疗影像领域专业化基础模型的构建提供了有效方案。
论文标题: A Foundation LAnguage-Image model of the Retina (FLAIR): Encoding expert knowledge in text supervision
论文下载: sciencedirect, arxiv
项目地址:Github-FLAIR
引用格式: J. Silva-Rodríguez, H. Chakor, R. Kobbi, J. Dolz, and I. Ben Ayed, “A Foundation Language-Image Model of the Retina (FLAIR): encoding expert knowledge in text supervision,” Medical Image Analysis, vol. 99, p. 103357, 2025, doi: 10.1016/j.media.2024.103357

0.2 论文速览
研究背景
- 现有技术瓶颈:
- 传统深度学习模型:针对特定任务训练,泛化能力弱,难以应对图像采集差异、患者人口统计学变化及罕见病场景
- 通用视觉 - 语言模型(如 CLIP):无法捕捉医疗领域复杂的细粒度特征、病理层级关系等专业知识,直接应用于医疗影像效果不佳
- 研究目标:构建专用于视网膜眼底图像分析的视觉 - 语言基础模型,通过嵌入专家知识解决文本监督稀缺问题
模型核心设计
- 架构组成:
- 视觉编码器:ResNet-50(预训练于 ImageNet),含输出维度 512 的投影头
- 文本编码器:BioClinicalBERT,含输出维度 512 的投影头
- 专家知识整合:
- 知识来源:临床文献(如 Garner and Ashton, 1979)和行业标准(如 Wilkinson et al., 2003)
- 整合形式:将类别标签映射为文本提示,描述病理细粒度特征(如微动脉瘤为 “小红点”)及层级关系(如轻度 DR 仅含 “少量微动脉瘤”)
- 训练目标:最小化配对图像 - 文本距离,最大化非配对样本距离,优化双向图像 - 语言对齐
核心创新点
将专家领域知识以文本提示形式嵌入视觉 - 语言预训练,具体包括病理细粒度特征(如 “微动脉瘤为小红点”)和层级依赖关系(如轻度 DR 与重度 DR 的特征差异)。
该设计解决了两大痛点:
- 一是视网膜影像文本监督稀缺的问题,通过类别标签与专家知识的映射补充文本信息;
- 二是通用模型难以捕捉医疗专业知识的局限,使模型能精准识别医疗场景中的特殊特征与关系。
0.3 摘要
基础视觉-语言模型正在变革计算机视觉领域,并凭借其卓越的泛化能力在医学影像领域迅速崛起。然而,由于医学影像任务存在显著的领域差异及复杂的专业领域知识,将这一新范式移植到医学影像的初步尝试并未取得像其他领域那样令人瞩目的成效。
基于对领域专家型基础模型的需求,我们提出了FLAIR——一个用于通用视网膜眼底图像理解的预训练视觉-语言模型。为此,我们整合了来自多个机构的38个开放获取、以分类数据集为主的眼底影像数据集,涵盖高达101种不同病理指征及288,307张图像。
我们通过描述性文本提示的形式,在预训练和零样本推理阶段融入专家领域知识,从而增强数据中信息量有限的分类监督信号。这些从相关临床文献和行业标准中提炼的文本化专家知识,既描述了病理特征的细粒度表征,又揭示了其间的层级关系与依赖关系。
综合评估结果表明,专家知识的融入显著提升了模型性能,且FLAIR在存在领域偏移或未知类别的困难场景下展现出强大的泛化能力。当采用轻量级线性探测器进行微调时,FLAIR的表现超越了经过完整训练、专注于特定数据集的模型,这种优势在小样本场景中尤为显著。
值得注意的是,FLAIR以显著优势超越了更大规模的通用视觉-语言模型及视网膜领域专用自监督网络,这既印证了嵌入专家领域知识的巨大潜力,也揭示了通用模型在医学影像领域的局限性。
预训练模型已发布于:https://github.com/jusiro/FLAIR。
1. 引言
全球至少有10亿人患有本可预防或尚未得到治疗的视力障碍问题(WHO, 2019)。在此背景下,彩色眼底影像与计算机视觉系统相结合,为基于人群的筛查和眼科疾病早期检测提供了一种前景广阔且成本效益显著的解决方案(Balyen和Peto, 2019; Bellemo等, 2019)。
在公共数据集的推动下,深度学习已在广泛的眼底图像分析任务中取得了显著性能,例如糖尿病视网膜病变分级(Liu等, 2022)、青光眼检测(Orlando等, 2019)、病变分割(Porwal等, 2020)以及多疾病检测(Cen等, 2021)。然而,若干局限性阻碍了这些方法的广泛采用。特别是,当成像数据或手头任务出现偏移时(例如出现新的或罕见的类别),当前用于眼底图像分析的深度学习解决方案可能泛化能力不佳(Li等, 2021; Sengupta等, 2020)。在视网膜成像乃至更广泛的医学成像领域,当前主流的深度学习范式是针对非常具体的任务来监督模型,例如将糖尿病视网膜病变分为少数几个等级(Liu等, 2022)。由于学习到的表征可能对当前任务和训练图像过于专一,此类以任务为中心的模型可能难以:(i)应对真实临床场景中的高变异性,这源于图像采集和患者人口统计学特征的高度差异(Finlayson等, 2021);(ii)捕捉训练数据中代表性不足的罕见病症。
当前,人工智能算法正在经历一场范式转变,其驱动力是越来越多地在大型多样化数据集上训练的模型,这些模型能够适应广泛的下游任务。这些通常被称为基础模型的模型,日益普及,并在计算机视觉和自然语言处理任务中取得了显著成功(Brown等, 2020; Radford等, 2021)。特别是,视觉-语言模型,如CLIP(Radford等, 2021)和ALIGN(Jia等, 2021),在各种下游计算机视觉任务上进行微调后,展现出了令人印象深刻的泛化能力,成为狭隘监督、任务专注型模型的有力替代方案。通过从大规模图像-文本对中学习,此类模型利用了基于语言的监督中所蕴含的丰富语义知识,从而产生比特定任务模型更具描述性的视觉特征。
在图像分类等计算机视觉任务中,这种新的"预训练-微调"范式增强了对图像数据偏移的鲁棒性,并展现了良好的零样本和少样本可迁移性。尽管如此,直接将这类基础模型应用于医学领域的初步尝试所取得的性能并不尽如人意(Wang等, 2022c)。事实上,像CLIP这样的通用模型可能无法捕捉细粒度的图像特征以及类别间的依赖关系/层级结构,这些可能是专家领域知识中固有的复杂且高度专业化的概念;图1展示了视网膜眼底图像中的一个示例说明。这最近推动了专门针对医学成像应用的基础模型的开发(Wójcik, 2022; Moor等, 2023)。
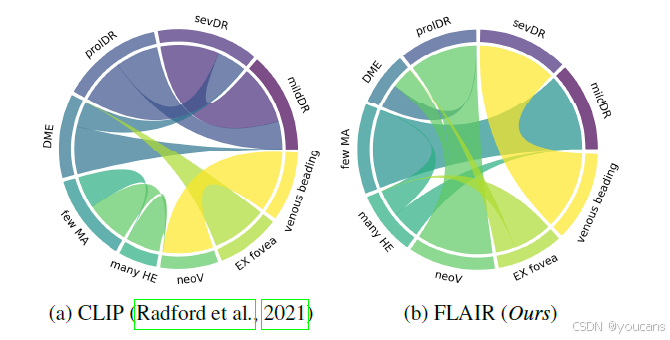
图1:CLIP在医学领域的局限性。
该图显示了常见视网膜疾病和在眼底图像中观察到的病变的文本嵌入的余弦相似度。尽管CLIP主要关注一般的医学关系(例如,“糖尿病性”或“新生血管化-静脉”),但提出的专业领域模型(即FLAIR)能够捕捉概念之间的层次依赖关系(例如,“轻度DR”的眼底图像中仅包含“少数微动脉瘤”,而“新生血管化”是区分“增殖性DR”诊断的鉴别标志)。
视觉-语言模型目前正在医学图像分析领域兴起。最近的几项研究探索了专门针对放射学的基础模型(Zhang等, 2022b; Huang等, 2021b; Wang等, 2022c),主要集中于胸部X射线数据。其动机在于放射学中诊断文本报告的普遍性,以及挖掘此类文本信息的大型领域资源的可用性(Bodenreider, 2004; Jain等, 2021)。然而,其他医学成像模式可能并非如此。例如,在视网膜成像中,文本信息稀缺,大多数数据集都是分类标签(见表1),即每个训练图像的标签是单个类别(或等级),例如"轻度糖尿病视网膜病变"。
我们认为,即使对于分类标签的图像,视觉-语言预训练也是一种有吸引力的解决方案,可以将领域特定的细粒度知识(例如类别之间的依赖关系)整合到视觉表征中。
临床专家对医学图像的分析是一个寻找候选病症鉴别特征的过程。在此过程中,例如,局部病变的存在与全局层面的鉴别诊断之间存在层次化的依赖关系。这类专家的领域知识在传统训练中通常被忽视,但可以以文本描述的形式整合进来,以构建强大的图像-语言模型。为了说明这一点,我们在图2中提供了一些带有分类标签的视网膜成像示例,以及编码了领域知识的相应文本描述。例如,文本描述"仅存在少量微动脉瘤"提供了已知指向轻度糖尿病视网膜病变类别的局部状况信息(Wilkinson等, 2003)。在表S4中,我们提供了分类标签与文本领域知识描述之间对应关系的完整列表,这些列表是我们从相关临床文献和社区标准(Wilkinson等, 2003; Garner和Ashton, 1979; Allen和Vasavada, 2006; Gass, 1988; Hamel, 2006; Ruiz-Medrano等, 2019; Yang等, 2016)中整理而来,用于构建我们的视网膜基础模型。
本文介绍了FLAIR,一个用于彩色眼底图像分析的视网膜基础语言-图像模型。
- FLAIR是在一个我们从未自不同公开可用来源汇编的大型数据集集合(包含288,307张图像和101个不同目标类别)上进行训练和验证的。
- 我们在预训练和零样本预测阶段,以文本监督的形式整合了专家的领域知识,从而增强了数据的分类信息。此类文本化的专家知识描述了病理的细粒度特征以及它们之间的层级和依赖关系。
- 我们报告了全面的评估、比较和消融研究,结果表明了嵌入专家知识的显著效果,以及FLAIR在存在领域偏移或新颖(未见)类别的挑战性场景下强大的泛化能力和可迁移性。
- 当使用轻量级线性探针分类器进行适配时,FLAIR的性能超过了在目标数据集上完全训练的模型,在低数据(少样本)设置下优势更为明显。
- 此外,FLAIR以较大优势超越了更通用、更大规模的图像-语言模型,如CLIP或BiomedCLIP。
我们的结果指出了嵌入专家领域知识的潜力以及通用模型的局限性。
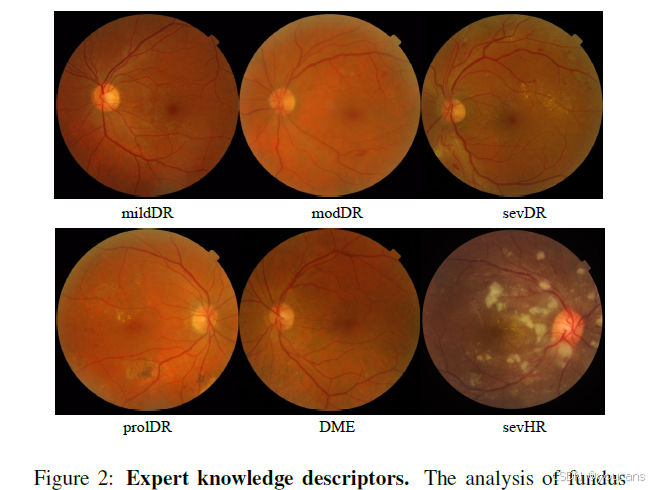
图2:专家知识描述符。
眼科医生分析眼底图像时依赖于层次特征。根据美国眼科学会(Wilkinson et al., 2003),轻度DR的特点是“仅有少数微动脉瘤”,中度DR包括“少数象限内的视网膜出血”、“许多出血”或“棉绒斑”,重度DR和增殖性DR分别由“静脉串珠”/“视网膜内微血管异常”和“新生血管化”区分。DME通常伴有“中心凹硬渗出”。此外,根据(Garner and Ashton, 1979),高血压性视网膜病变通常描述为“视网膜浅层的火焰状出血和棉绒斑”。进一步深入概念之间的层次,渗出物是“小的白色或黄色沉积物”,而微动脉瘤是“小的红色斑点”。
2. 相关工作
2.1 医学图像分析中的迁移学习
从头开始训练稳健的深度学习模型需要大规模数据集和大量计算资源[22]。这些条件在医学成像领域很少得到满足。图像采集的高变异性、特定病症的低发病率以及机构的有限资源,使得标准监督学习模型难以捕捉真实临床环境中的实质性变异。这是因为监督模型通常仅在相对较小的数据集和任务上进行训练和专门化,其根本原因在于数据标注的成本和资源过高。为在一定程度上缓解此问题,从自然图像进行迁移学习——即先在大型标注数据集(如ImageNet)上对深度模型进行预训练,然后将其作为初始化以适应目标任务——已成为事实上的解决方案[77, 49, 63]。特别是,对整个网络或仅对最后几层进行微调,在放射学、心脏病学和眼科等多个领域的广泛医学成像任务中展现了良好的性能[83, 1, 26]。然而,一些深入的实证研究揭示了此类迁移学习解决方案在医学图像分类的某些场景中性能提升有限[77, 68, 63]。利用未标注数据通过自监督进行大规模预训练[15, 43]是一种有前景的替代方案。但监督式的、领域特定的预训练仍然是实现最优迁移学习的主流解决方案[102, 60]。在这种标准监督学习范式下,在DeepDRiD挑战赛(针对眼底图像糖尿病视网膜病变分级)中表现优异的解决方案[61]使用了公共数据集进行了详尽的、任务特定的预训练。
2.2 从监督式任务特定模型到大规模视觉语言预训练
如上所述,监督式任务特定模型目前在医学成像中占主导地位。然而,此类专注于任务的模型在临床场景中遇到的各种条件下能否良好泛化,仍然是其更广泛采用的主要挑战[27]。任务特定模型(例如,将糖尿病视网膜病变分为几个等级的模型)可能产生对于当前任务和训练数据过于专门化的特征。正如我们将在本工作的实证验证中展示的,每当任务(例如,新类别)或成像数据发生偏移时,此类模型的泛化能力都很差。由于图像采集和患者人口统计学特征的高变异性,和/或某些病症的低发病率,这种偏移在医学成像中频繁发生。
最近,视觉语言预训练在计算机视觉和机器学习领域取得了实质性进展,成为提高深度模型泛化能力的有力解决方案。大规模VLP模型通过图像-文本对比学习[76, 46, 98]利用配对的图像-语言数据,产生稳健且通用的特征提取器。此类预训练模型在下游任务上进行微调时,展现了令人印象深刻的迁移学习能力[76]。在自然图像上,这种广泛兴起的"预训练-微调"范式对数据偏移表现出优异的鲁棒性,并对新任务具有很强的泛化能力,且在新任务中无需(即零样本[80, 104])或仅需少量(即少样本[41])标注样本。例如,CLIP [76]通过联合训练的视觉和语言编码器捕捉图像与目标类别的文本描述之间的相似性,提供基于提示的(零样本)分类。此外,在少样本情况下(即目标任务中只有少量标注样本可用),通过在冻结网络之上更新线性分类器层,其视觉表征展现出很强的可迁移性。这种快速微调过程通常称为线性探测。这些观察结果激发了人们日益增长的兴趣,致力于使用轻量级多模态模块(称为适配器[29, 100])以高效形式将CLIP适配到下游任务和领域。尽管这些高效的可迁移特性在医学图像分析中极具价值,但将CLIP直接应用于医学成像数据会产生次优结果[88]。除了成像模态中存在的领域偏移外,部分原因可能在于医学成像中遇到的复杂且高度专业化的术语。
2.3 医学成像中的视觉语言模型
VLP模型在医学成像领域的兴起尚处于起步阶段。最近的几项工作研究了针对医学数据定制的对比性图像-语言模型[102, 44, 88, 62],但主要集中于胸部X光片的应用领域。VLP模型在放射学领域[102]特别有吸引力,因为与图像相关的诊断文本报告在日常放射学实践中很常见。因此,最近开始出现公开的、大规模的、包含配对图像和语言描述的多模态数据集,例如MIMIC-CXR [48]、PadChest [10]或ROCO [72]。此外,还存在大型领域资源,如UMLS [7]、BioClinicalBERT或RadGraph [45],它们有利于从自由文本的放射学报告中处理和提取结构化临床知识。
受这些领域知识存在的推动,最近的一些工作制定了策略来克服CLIP在医学领域的局限性。例如,使用CLIP进行推理的方法集成了模态提示[60]或属性描述[64]用于基于提示的推理,利用预训练的问答模型来描述目标病症的形状和颜色[75]。其他工作则专注于预训练阶段,生成领域专门的VLP模型,如ConVirt [102]、PubMedCLIP [23]、GLorIA [44]、MedCLIP [88]或MedKLIP [94]等[92, 87, 66, 16]。此类预训练的一个主要挑战在于公开数据集中基于文本的监督信息稀缺。为了缓解这个问题,MedCLIP通过标签空间对齐[88]纳入了分类标注的样本。其他方法则利用了放射学中成熟的领域工具,如UMLS和RadGraph,来增强可用的文本报告[16, 94]。
尽管视觉语言预训练策略在医学成像中的开发取得了这些进展,但分类标注数据集的使用一直被忽视。在这项工作中,我们论证并表明,通过将专家领域知识编码到文本监督中,仍然可以利用这种分类监督来训练强大的视觉语言表征。
2.4 专家知识驱动的眼底图像模型
将领域知识整合到医学图像分析的深度学习中的总体思路并不新颖,并在近期的文献中引发了兴趣[97]。特别是,可以从临床医生那里检索领域特定的专家知识,以突出感兴趣区域、相关特征、解剖学先验,或疾病间的依赖关系和层级结构。在视网膜成像领域,专家知识已以多种方式整合。例如,[32]首先分割出渗出物,将其作为检测黄斑水肿的代理指标。类似地,其他几种策略训练注意力模块来增强局部病变,并将其作为疾病分类的代理。与我们的工作密切相关的,我们确定了几种类别,包括:使用像素级标注的病变进行AMD分期[24]、基于糖尿病视网膜病变和糖尿病黄斑水肿之间关系的弱监督策略[96],或为糖尿病视网膜病变分级解缠疾病特定的显著性图[82]。此外,用于眼底图像青光眼检测的专家知识通常通过裁剪视盘区域作为分类的初始步骤来整合[21, 86]。与现有文献不同,我们研究了如何通过视觉语言预训练来利用已确立的视网膜图像分析专家知识,而这在基础模型的背景下很大程度上被忽视了。具体来说,我们提出了一种对比性图像-文本预训练方法,它将相关特征、层级关系、类别间的关系以及表征目标疾病的感兴趣区域信息,以描述性文本提示的形式,与相应的图像配对并加以整合。
3. 结果
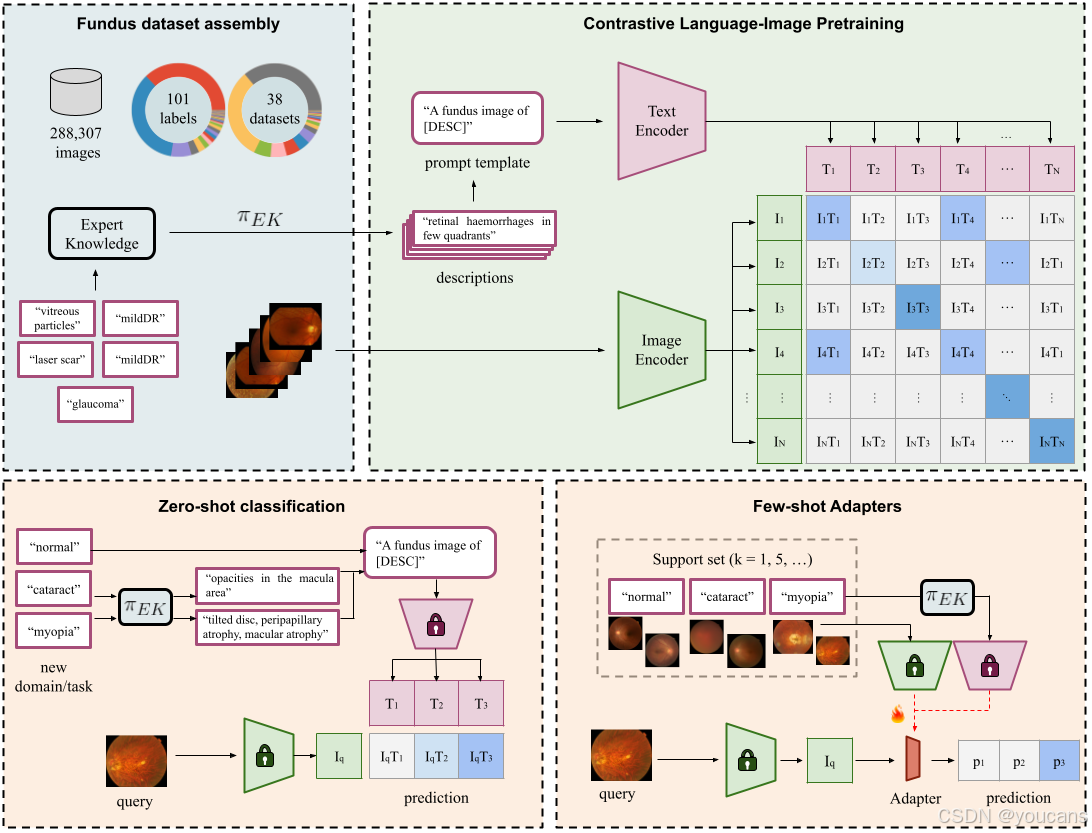
图3展示了我们框架的概览。我们将在以下章节中正式介绍各个方法组成部分。
问题设定
让我们定义一个整合数据集 𝒟 T 𝒟_T DT,其中包含从不同公开可用的眼底图像数据集中收集的 N N N 个样本,涵盖了多种来源和病理发现。对于每个样本,我们构建一个包含图像、分类标签和文本描述的多模态三元组: 𝒟 T = ( 𝐗 n , y n , 𝐓 n ) n = 1 N 𝒟_T = {(𝐗_n, y_n, 𝐓_n)}_{n=1}^N DT=(Xn,yn,Tn)n=1N。其中, 𝐗 n ∈ R Ω n 𝐗_n ∈ ℝ^{Ω_n} Xn∈RΩn 表示二维眼底图像, Ω n Ω_n Ωn 为其空间域; y n ∈ 1 , … , C y_n ∈ {1, …, C} yn∈1,…,C 是整合数据集中 C C C 个独特类别中的一个标签; 𝐓 n ∈ 𝒯 𝐓_n ∈ 𝒯 Tn∈T是与该标签关联的文本描述。
图2 展示了分类标签(如DME)及其对应的编码了领域知识的文本描述(例如"涉及黄斑中心区的硬性渗出物")的若干示例。此类文本领域知识可从相关临床文献[30]和/或社区标准[91]中得出。表S3提供了分类标签与文本领域知识描述之间对应关系的完整列表,这些列表是我们从相关临床文献中整理而来,用于构建我们的视网膜基础模型。
需要注意的是,单个分类标签可能对应多个文本描述,每个描述都阐述了图像中不同的病理发现或特征。我们的视觉-语言预训练目标是提供一个强大的多模态模型,能够学习到一个特征表示空间,在该空间中,图像、类别和文本这三种模态的样本能够相互对齐。
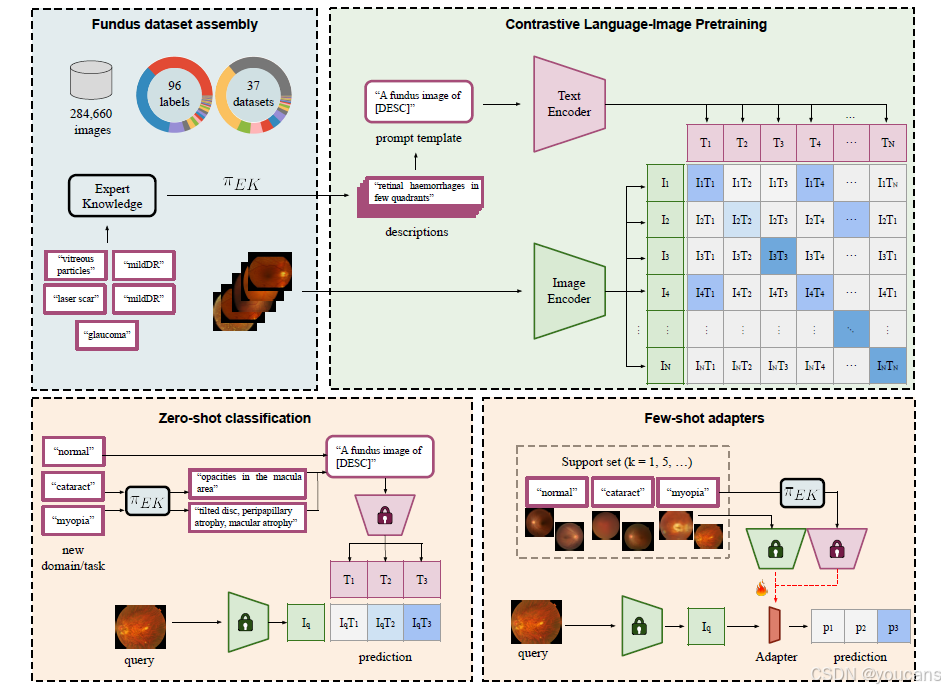
图3:框架概览。
我们从37个公开数据集的组合中开发了一个基于知识的视网膜通用模型,包含284,660张眼底图像和96个不同的类别(见左上角)。
基础模型包括视觉和语言编码器,这些编码器以对比的方式在配对图像和文本描述符上进行训练。
为缓解公开可用的视网膜眼底图像数据集中基于文本的监督稀缺问题,我们提出通过使用成熟的领域知识来扩充类别图像标签(见右上角)。随后的预训练模型能够使用基于领域知识和新疾病局部特征的良好设计描述符以零样本的方式预测新类别;见左下角。此外,通过在视觉和图像编码器上仅使用少量标记样本(支持集)微调轻量级适配器,模型可以适应下游任务和领域;见右下角。
3.1 图像、标签与领域知识文本的对齐
我们的多模态预训练整合了视觉与语言编码器。令 θ = θ f ( ⋅ ) , θ p ( ⋅ ) \theta = {\theta_f(\cdot), \theta_p(\cdot)} θ=θf(⋅),θp(⋅) 表示视觉编码器,其中 θ f ( ⋅ ) \theta_f(\cdot) θf(⋅) 为特征提取器, θ p ( ⋅ ) \theta_p(\cdot) θp(⋅) 为投影头。特征提取器 θ f ( ⋅ ) \theta_f(\cdot) θf(⋅) 对输入图像 X i \mathbf{X}i Xi 生成特征表示 u ~ ∈ R D u \tilde{\mathbf{u}} \in \mathbb{R}^{D\mathbf{u}} u~∈RDu: u ~ i = θ f ( X i ) \tilde{\mathbf{u}}_i = \theta_f(\mathbf{X}i) u~i=θf(Xi),其中 D u D\mathbf{u} Du 为视觉特征空间的维度。类似地,令 ϕ = ϕ f ( ⋅ ) , ϕ p ( ⋅ ) \phi = {\phi_f(\cdot), \phi_p(\cdot)} ϕ=ϕf(⋅),ϕp(⋅) 表示文本编码器, ϕ f ( ⋅ ) \phi_f(\cdot) ϕf(⋅) 为特征提取器, ϕ p ( ⋅ ) \phi_p(\cdot) ϕp(⋅) 为投影头。特征提取器 ϕ f ( ⋅ ) \phi_f(\cdot) ϕf(⋅) 对输入文本 T j \mathbf{T}j Tj 生成嵌入表示 v ~ ∈ R D v \tilde{\mathbf{v}} \in \mathbb{R}^{D\mathbf{v}} v~∈RDv: v ~ j = ϕ f ( T j ) \tilde{\mathbf{v}}_j = \phi_f(\mathbf{T}j) v~j=ϕf(Tj),其中 D v D\mathbf{v} Dv 为文本特征空间的维度。每个投影头 θ p ( ⋅ ) \theta_p(\cdot) θp(⋅) 与 ϕ p ( ⋅ ) \phi_p(\cdot) ϕp(⋅) 将独立模态表示映射至联合单位超球面空间: u = θ p ( u ~ ) ∣ θ p ( u ~ ) ∣ \mathbf{u} = \frac{\theta_p(\tilde{\mathbf{u}})}{|\theta_p(\tilde{\mathbf{u}})|} u=∣θp(u~)∣θp(u~) 与 v = ϕ p ( v ~ ) ∣ ϕ p ( v ~ ) ∣ \mathbf{v} = \frac{\phi_p(\tilde{\mathbf{v}})}{|\phi_p(\tilde{\mathbf{v}})|} v=∣ϕp(v~)∣ϕp(v~)。在此归一化空间中,图像 X i \mathbf{X}_i Xi 与文本描述 T j \mathbf{T}_j Tj 的相似度通过余弦相似度评估: u i T v j \mathbf{u}_i^T \mathbf{v}_j uiTvj,其中 T T T 表示转置算子。
目标在于学习能够最小化成对图像与文本描述间距离,同时最大化非成对样本间距离的特征表示。我们基于可用的类别标签信息构建图像-文本对,从而促使属于相同类别的样本在图像与文本域中均具有相近的特征表示。更形式化地,令 B \mathcal{B} B 表示包含图像集 X i i ∈ X B {\mathbf{X}i}{i \in \mathcal{X}_B} Xii∈XB 与文本描述集 T j j ∈ T B {\mathbf{T}j}{j \in \mathcal{T}_B} Tjj∈TB 的批次,其中 X B ⊂ 1 , … , N \mathcal{X}B \subset {1, \dots, N} XB⊂1,…,N 表示 B \mathcal{B} B 中图像的索引集, T B ⊂ 1 , … , N \mathcal{T}B \subset {1, \dots, N} TB⊂1,…,N 表示 B \mathcal{B} B 中文本描述的索引集。我们最小化类别感知的图像到文本 ( L i 2 t \mathcal{L}{i2t} Li2t) 与文本到图像 ( L t 2 i \mathcal{L}{t2i} Lt2i) 对比目标,其定义如下:
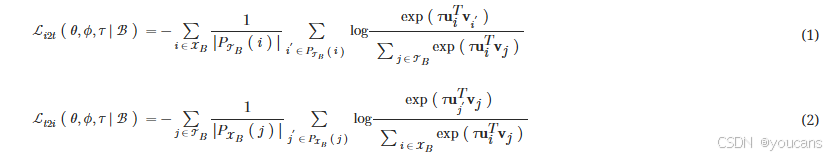
其中 τ ∈ R > 0 \tau \in \mathbb{R}{>0} τ∈R>0 是可训练的缩放参数, ∣ ⋅ ∣ |\cdot| ∣⋅∣ 表示集合的基数, P T B ( i ) P{\mathcal{T}B}(i) PTB(i) 和 P X B ( j ) P{\mathcal{X}_B}(j) PXB(j) 分别包含批次 B \mathcal{B} B 中同类别的子集索引: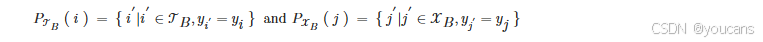
因此,我们通过梯度下降和随机批次采样,对基础眼底模型的视觉与语言编码器进行双向图像-语言对齐优化:
3.2 预训练阶段将专家知识作为附加文本监督
医学影像领域的大规模视觉-语言预训练主要在放射学图像背景下得到研究[102],其中诊断文本报告较为常见。因此,现有大型多模态数据集包含配对的放射学图像和文本描述[48]。然而,在其他医学影像模态(如视网膜眼底图像)中情况并非如此。在我们的整合数据 D T = ( X n , y n , T n ) n = 1 N \mathcal{D}_T = {(\mathbf{X}_n, y_n, \mathbf{T}n)}{n=1}^N DT=(Xn,yn,Tn)n=1N 中,绝大多数数据集的文本表示 T n \mathbf{T}_n Tn 并不可用(见表1)。为此,我们引入一个映射函数 π ( ⋅ ) : Y → T \pi(\cdot): \mathcal{Y} \to \mathcal{T} π(⋅):Y→T,用于从类别标签生成文本描述,从而将多模态数据集构建为 D T = ( X n , y n , π ( y n ) ) n = 1 N \mathcal{D}_T = {(\mathbf{X}n, y_n, \pi(y_n))}{n=1}^N DT=(Xn,yn,π(yn))n=1N。
一种典型解决方案是使用朴素转换函数 π naive ( ⋅ ) \pi_{\text{naive}}(\cdot) πnaive(⋅),其仅包含所用成像模态的信息(例如CT体积的[60]方案)。对于眼底图像,模态提示模板将为“一张[CLS]的眼底照片”,其中“[CLS]”表示类别名称。尽管该方案可能整合同名类别的语义关系,但无法捕捉领域特定的层级结构,因此可能缺乏信息量[64]。
本工作中,我们提出利用成熟的领域专家知识描述,记为 π EK ( ⋅ ) \pi_{\text{EK}}(\cdot) πEK(⋅)。该转换将每个类别映射到包含各疾病相关发现及类别间关系的文本描述。给定类别 y y y,映射生成包含 P P P 个文本描述的集合,即 T 1 P = π EK ( y ∗ ) {\mathbf{T}}1^P = \pi{\text{EK}}(y_*) T1P=πEK(y∗)。例如,“无糖尿病视网膜病变”类别的文本描述可为“无相关出血、微动脉瘤或渗出物”,而“渗出物”类别可描述为“边缘清晰的小型白色或黄白色沉积物”。需要说明的是,文本化专家知识描述的数量 P P P 可能因类别而异。更多示例请参阅补充材料表S3。因此,在公式3的随机梯度下降优化过程中,对于批次 B \mathcal{B} B 中来自类别标注数据集的给定样本,会从包含朴素提示和对应专家知识提示的集合中均匀采样一个文本描述。通过在训练中编码这种领域知识,大规模视觉-语言预训练能够捕捉更强的类别间关系,从而可能产生更丰富的表征。
3.3 利用专家知识增强零样本推理
视觉-语言预训练模型可作为零样本分类的强大工具。这涉及对可能包含新目标任务的未知数据集的泛化。形式化而言,给定目标图像 x ∗ x_* x∗ 和目标数据集中一组新类别 y ′ ∈ C + 1 , … , C ′ y' \in {C+1, \dots, C'} y′∈C+1,…,C′,此时推理由图像编码器生成的图像表示 u ∗ \mathbf{u}_* u∗ 与文本编码器使用各类别语言描述 π ( c ′ C + 1 C ′ ) \pi({c'}{C+1}^{C'}) π(c′C+1C′) 生成的类别表示 v c ′ \mathbf{v}{c'} vc′ 之间的观测余弦相似度驱动。具体而言,预测类别对应最大余弦相似度:

关于文本表示,早期使用类CLIP模型进行推理的研究主要采用基于类别名称的简单提示策略[76]。然而,近期研究表明类别名称可能无法充分挖掘语言模态所能提供的附加信息价值[64]。例如,文献[64]探索了在自然图像背景下如何利用大语言模型增强类别表示,而文献[88, 94]则在放射影像领域采用了领域知识提示。
顺应这些最新进展,我们在推理阶段除利用训练时引入的专家知识提示(见前文所述)外,进一步扩展其应用范畴。基于对病理特征的本质描述,该方法有望增强模型对训练阶段未见病理的判别能力。在此设定下,针对每个新类别 c c c,我们通过计算其对应 P P P个专家知识提示文本嵌入的质心,从而在公式(4)中获得其文本表示 v c \mathbf{v}_c vc。
4. 实验设置
4.1 数据集
构建数据集 D T \mathcal{D}_T DT:
共整合了 37 个公开数据集用于训练和评估所提出的通用模型,数据集概要如表 1 所示。
该整合数据集涵盖了眼底图像分析的主要任务,包括糖尿病视网膜病变分级 [18, 74, 12, 84, 59, 58, 67]、青光眼检测 [56, 51, 21, 54, 86, 70] 和病变分割 [73, 59, 58, 50, 32]。此外,还纳入了针对其他低发病率疾病分类的数据集 [71, 13, 67, 37]。多数数据集包含类别标签,同时也纳入了 3 个含图像文本描述的数据集:EYENET [42]、ODIR-5K 和 STARE [39, 40]。对于含眼底图像像素级标注的数据集,均将其转换为图像级标签。
最终构建的数据集 D T \mathcal{D}_T DT 包含 286,916 张图像,涵盖 96 个不同的目标类别。更多细节请参见补充材料 S1 节。
标准化与数据增强
所有图像均调整至 512 × 512 512 \times 512 512×512 的画布尺寸,并对矩形图像施加零填充以避免形变。此外,所有图像均进行强度归一化至 [ 0 , 1 ] [0,1] [0,1] 区间。训练过程中采用随机图像增强策略,包括水平翻转、 [ − 5 , 5 ] [-5,5] [−5,5] 度随机旋转、 [ 0.9 , 1.1 ] [0.9,1.1] [0.9,1.1] 范围内的缩放变换以及色彩抖动。
表1:来自各种开放访问来源的视网膜眼底图像数据集汇总。
我们通过组合37个公开可用的、主要为类别标签的数据集,开发了一个视觉-语言通用模型以理解眼底图像。
随后的数据集组合包含286,916张图像,对应96个不同的类别。在37个数据集中,只有3个数据集包括基于文本的视网膜眼底图像监督。有关类别缩写的详细信息,请参阅补充材料,第S1节。

4.2 评估方案
本研究针对目标任务在两种不同场景下验证所提出的基础模型:领域偏移(即包含训练阶段已见类别的新数据集)和未见类别(即训练阶段未使用的新疾病类型)。为此,我们在训练过程中刻意排除了部分数据集和类别。
领域偏移
我们选用包含主要眼底图像分析任务的三个数据集进行测试:用于糖尿病视网膜病变分级的MESSIDOR数据集、用于青光眼检测的REFUGE数据集,以及用于异质性疾病分类的FIVES数据集。这些数据集均从训练数据中移除。
未见类别
为评估模型对新疾病的零样本泛化与迁移能力,我们选取四种疾病类别并将其从训练数据中排除:视网膜色素变性(RP)、黄斑裂孔(MHL)、白内障(CAT)和病理性近视(MYA)(这些病症的可视化示例见补充材料图S2)。据此构建两个子集:从1000x39数据集中提取正常、RP和MHL各20张图像组成的20x3子集,以及从ODIR-5K数据集中提取正常、CAT和MYA各200张图像组成的ODIR200x3子集。需要特别说明的是,基础模型训练过程中未使用任何与这些新类别对应的样本。表2汇总了用于评估的主要数据集信息。
适配后泛化能力
我们采用多个附加数据集评估基础模型微调后的泛化性能:用于青光眼检测的ACRIMA数据集、用于糖尿病视网膜病变分级的DeepDRiD数据集,以及针对新类别构建的RP-MHL-2和CAT-MYA-2子集。这些附加子集的详细说明见补充材料S1章节和表S1。
表2:基础模型评估的数据集分布。
为了评估FLAIR的泛化能力,我们从训练阶段中移除了几个数据集。
评估场景包括:i) 在训练期间遇到的类别的领域(图像数据)转移,以及ii) 新的未见过的类别。对于后者场景,对应新目标类别的样本(即RP、MHL、CAT和MYA)未在训练期间使用。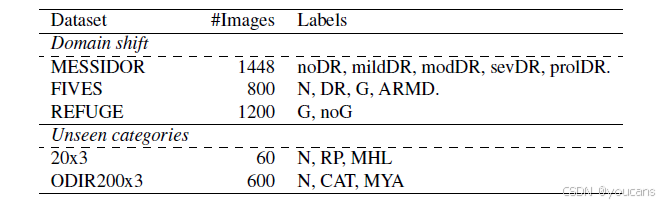
4.3 基础模型的预训练
我们参照医学图像视觉-语言预训练领域的先前研究设计了视觉与语言编码器。
具体而言,遵循ConVIRT[102]、GloRIA[44]和MedCLIP[88]的方案,采用在ImageNet[19]上预训练的ResNet-50[38]作为视觉编码器 θ f \theta_f θf。文本编码器 ϕ f \phi_f ϕf则与MedCLIP[88]类似,使用BioClinicalBERT。两个编码器均采用输出特征维度为 512 512 512的线性层作为投影头( θ p \theta_p θp与 ϕ p \phi_p ϕp)。
所提出的视觉-语言预训练在整合数据集 D T \mathcal{D}T DT上执行,通过最小化公式3进行 15 15 15个epoch的训练,批尺寸设置为 128 128 128张图像。我们采用AdamW优化器,基础学习率为 1 × 1 0 − 4 1\times10^{-4} 1×10−4,并在第一个epoch中使用余弦预热调度器。针对分类标注数据,我们采用领域知识描述符将标签映射为文本(所用描述符详情参见表S3)。
下文将所提出的基础模型称为FLAIR- π EK \pi{\text{EK}} πEK。训练在单张RTX A6000显卡上使用混合精度完成,耗时约16小时。
4.4 基线模型
下文将阐述用于评估所提出基础模型性能的不同基线模型与方法。我们特别针对FLAIR- π EK \pi_{\text{EK}} πEK的泛化与迁移能力,与其他相关策略进行了基准测试。具体包括与以下三类方法的对比:i) 用于零样本泛化的视觉-语言模型;ii) 面向高效迁移学习的视觉编码器预训练方法;iii) 针对各目标数据集进行完整模型训练(而非采用高效适配策略)的方法。
4.4.1 语言驱动的零样本分类
视觉-语言预训练模型
首先,我们为语言驱动(即零样本)分类任务设定基线模型。我们使用CLIP[76]及其原始权重(该模型基于来自异构来源的4亿图像-文本对进行预训练)。需要说明的是,CLIP的预训练数据包含若干医学影像数据集。此外,我们还纳入了近期发布的通用视觉-语言模型BiomedCLIP[101],该模型旨在理解生物医学图像。它采用当前日益流行的策略:通过整合高度多样化的模态与任务的大型生物医学影像数据集(如X光片、CT体积数据、组织学图像、皮肤镜图像、超声图像等)进行视觉-语言预训练,以获取适用于所有生物医学领域的通用基础模型。BiomedCLIP使用从PubMed提取的超过1500万跨医学领域的图像-文本对进行预训练。同时,我们设置了所提出基础模型的一个基础版本作为基线,该版本在训练中未整合领域知识描述符,记为FLAIR- π naive \pi_{\text{naive}} πnaive。需注意,此基础版本的训练实现与提出的知识驱动基础模型完全相同。
4.4.2 预训练-适配基线
任务特定模型
为评估在多任务预训练中引入语言监督的益处,我们设定了在整合数据集上训练的任务特定模型作为基线。针对每个主要评估任务分别训练一个模型:糖尿病视网膜病变分级(TSMDR模型)、青光眼检测(TSMGlaucoma模型)以及多疾病分类(TSMDiseases模型)——各任务详情参见表2。对于每个任务,从整合数据集中检索所有带有相应任务目标类别标签的样本。例如,TSMDR模型使用数据整合中所有标注为noDR、mildDR、modDR、sevDR和prolDR的图像进行预训练。最终得到的每个任务的预训练子数据集规模约为:TSMDR和TSMGlaucoma任务近10万张图像,TSMDiseases任务近1万样本。任务特定模型使用标准多类交叉熵损失进行训练。
其他预训练基线
最后,我们考察了其他用于学习预训练表征的基线。具体而言,我们使用了在ImageNet上预训练的ResNet-50[38]所提取的特征进行适配,记为ImageNet。此外,我们评估了在本研究场景下使用SimCLR[14]作为预训练策略的对比式无监督学习。在此,SimCLR在整个整合数据集上训练,批大小为64张图像,训练15个周期。本设置中应用了与基础模型相同的变换来生成正样本对增强。
4.4.3 全训练上界
数据集特定模型(监督训练)
作为性能上界,我们在目标数据集上训练了数据集特定模型。这意味着并非进行零样本泛化或对预训练模型进行轻量级适配,而是所有模型权重均在目标数据集上微调。具体而言,骨干网络初始化与基础模型相同,使用在ImageNet[38]上预训练的ResNet-50权重,因为这是迁移学习至医学图像的常用方法[77]。训练使用批大小8张图像,通过标准随机梯度下降法进行50个周期,采用线性分类器和多类交叉熵损失。其他超参数包括ADAM优化器和 1 × 1 0 − 4 1\times10^{-4} 1×10−4的学习率。我们将此策略记为Supervised。
4.5 评估指标
评估所用的主要性能指标为各类别准确率以及每个数据集的平衡平均值(ACA)[105]。此外,为便于与现有文献对比,评估中还纳入了任务专用指标:糖尿病视网膜病变(DR)分级采用二次科恩卡帕系数(quadratic Cohen kappa) —— 这是该领域相关文献中最常用的指标 [28];青光眼检测则遵循相关挑战赛的惯例 [70, 86],采用受试者工作特征曲线下面积(AUC) 作为性能指标。所有涉及训练或适配的迁移性实验,其指标结果均通过 5 折交叉验证取平均值获得。
5. 结果
5.1 泛化能力
本节通过直接预测(即不调整可训练参数)的方式,在两种常见场景下评估所提模型的泛化能力:
i)领域迁移场景 —— 类别集合保持不变,但图像存在分布偏移;
ii)未见类别场景 —— 领域保持不变,但需识别未训练过的类别。
5.1.1 领域迁移场景下的性能
首先,我们评估所提预训练视觉 - 语言模型 FLAIR 在领域分布偏移下的性能,并与任务专用模型进行基准对比。为实现这一目标,我们考虑两种推理方式:使用仅包含类别名称的朴素映射提示 ( π n a i v e ( ⋅ ) (\pi_{naive}(\cdot) (πnaive(⋅),以及目标疾病的领域知识描述提示( π E K ( ⋅ ) \pi_{EK}(\cdot) πEK(⋅)),分别记为 “VLP - 推理(使用 π n a i v e \pi_{naive} πnaive)” 和 “VLP - 推理(使用 π E K \pi_{EK} πEK)”。此外,为进一步明确训练阶段融入领域知识描述的影响,我们还评估了两种映射方式分别对应的模型,即 F L A I R − π n a i v e FLAIR-\pi_{naive} FLAIR−πnaive(仅使用朴素映射)和 F L A I R − π E K FLAIR-\pi_{EK} FLAIR−πEK(使用领域知识映射)。
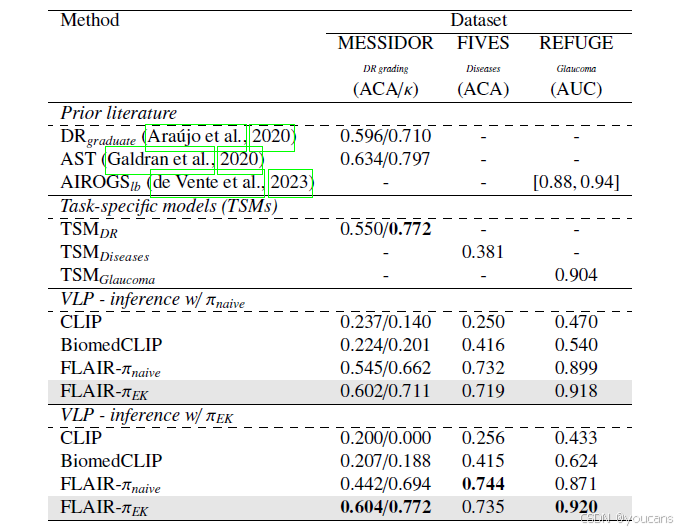
本实验的结果呈现在表3中。首先,我们可以观察到标准视觉-语言预训练方法(即FLAIR- π naive \pi_{\text{naive}} πnaive)在DR和青光眼任务上取得了与传统监督模型相当的结果。相比之下,在FIVES数据集上,视觉-语言预训练方法以显著优势(+34%)超越了其对应的标准监督模型TSMDiseases。需要特别指出的是,任务特定模型TSMDR和TSMGlaucoma使用了大量带标注的目标任务样本进行训练,而TSMDiseases可用数据集的规模则小得多。这或许可以解释不同任务之间,任务特定模型与VLP模型性能差异显著的原因。此外,这些结果清晰地展示了预训练视觉-语言模型的优势:训练时可以利用覆盖更广变异性的多个数据集,从而规避特定任务标注数据量小的问题。
表3的第二个重要观察是,在所提出的基础模型中引入领域知识描述(FLAIR- π EK \pi_{\text{EK}} πEK)通常在MESSIDOR(糖尿病视网膜病变分级)和REFUGE(青光眼检测)任务上带来显著提升,而在FIVES(疾病分类)任务上的性能略有下降。我们认为,观察到的巨大性能提升源于通过整合领域知识提示,FLAIR- π EK \pi_{\text{EK}} πEK引入了DR不同等级间局部发现的层级关系。
最后,所提出的方法取得了与文献中任务特定解决方案相媲美的结果,例如用于DR分级的成本敏感优化[28]和用于青光眼检测的视盘分割(AIROGS排行榜[86])。相比之下,本模型是通用的,提供了眼底图像的通用表征,这使得即使在目标任务场景下,与标准监督方法相比也能实现显著的性能提升。需要强调的是,由于具体实现细节的差异,在标准目标任务设定下与先前工作直接比较可能存在困难。
表3:领域转移下的泛化能力。在领域转移存在的情况下,直接预测预训练语言驱动模型的结果,即不进行适应的情况。提出的FLAIR方法与针对特定任务的标准全监督训练模型以及相应特定任务的现有文献进行比较:糖尿病视网膜病变(MESSIDOR)、疾病分类(FIVES)和青光眼检测(REFUGE)。对于每个任务,我们提供了文献中的代表性评估指标。提出的FLAIR-π-EK方法被阴影表示,而最佳结果以粗体突出显示。
5.1.2 新类别性能表现
我们现在对FLAIR在零样本场景下的表现进行实证评估,即基础模型未针对新的、未见过的类别进行任何适配。在此背景下,我们研究了三种不同的文本提示设计策略。首先,我们将提示生成视为异常检测任务,将所有未见过的疾病均视为异常。此时,用作文本编码器输入的提示仅为"正常"或"疾病"。接着,我们在生成文本提示时引入了每个新疾病的概念。第一种策略以朴素方式直接使用未见疾病名称作为提示。最后,为充分发挥视觉-语言模型的学习能力,我们提出设计领域知识提示,通过文本简要描述每种病症在眼底图像上对应的鉴别性特征。例如,我们不采用朴素方式直接使用"白内障"这一类别名称,而是使用以下发现作为输入文本提示:“黄斑区混浊”。补充材料图S2中提供了为未见类别设计的更多提示示例。
表4展示了相关结果。可以观察到,使用分类提示在整合数据集上训练CLIP(即FLAIR- π naive \pi_{\text{naive}} πnaive)相较于标准CLIP模型通常能带来显著的性能提升,尤其是在多分类场景中(表中中部和底部数据)。然而,FLAIR- π naive \pi_{\text{naive}} πnaive 在很大程度上无法区分新类别,其作用更接近于正常的眼底图像检测器。相比之下,融入领域特定知识则带来了显著的性能提升。首先,在训练阶段使用特定领域描述符相较于朴素FLAIR版本实现了 + 29 +29% +29和 + 4 +4% +4的性能改进(见表4"朴素提示"部分)。这种显著提升可能源于所提出的 π EK \pi_{\text{EK}} πEK方法中使用的文本提示能够生成更具层次结构和领域知识的丰富文本嵌入。值得注意的是,在推理阶段进一步利用这些精心设计的提示可使不同模型性能提升约 13 13% 13(20x3数据集)和 18 18% 18(ODIR200x3数据集),导致与FLAIR- π naive \pi_{\text{naive}} πnaive的性能差距在20x3数据集中达到近33%,在ODIR200x3中达到10%(见表4"专家知识提示"部分)。对医学领域更具意义的是,我们提出的模型在所有场景下均显著优于CLIP,差异幅度最高达65%。这表明在通用计算机视觉任务上训练的通用视觉-语言模型在专业医学影像领域仅能获得次优结果。
这些结果证明,在缺乏带文本监督的大规模数据集的情况下,通过将领域专家知识编码到文本监督中,仍然可以利用带有分类标签的样本来训练强大的视觉-语言表征。此外,FLAIR在异常检测任务上展现出有前景的性能,该任务无需在目标数据集中明确定义疾病类型。最后需要指出的是,使用通用模型(如BiomedCLIP)进行视网膜眼底图像的零样本泛化存在明显局限性:尽管该模型在所有任务上都持续改进了CLIP的性能(见表3和表4),但与专用模型(即FLAIR- π EK \pi_{\text{EK}} πEK)相比,其结果仍然显著落后,特别是在表3所列的任务中;同时,虽然BiomedCLIP在某个未见类别泛化数据集(即ODIR200x3)上表现出竞争力,但当在推理阶段使用描述性提示时,其性能会出现下降,这凸显了其在编码专业层次化专家知识方面的能力有限。
这些结果表明,尽管当前研究热点聚焦于通用模型,但在眼底成像领域,使用如FLAIR这样的领域专用模型展现出更具前景的结果。我们预计这一结论可能同样适用于其他医学影像领域。但需注意,由于这些大规模数据库描述缺乏透明度,难以确认模型是否曾在测试任务相关的数据上受过训练,因此与BiomedCLIP进行直接比较存在困难。
表4:对未见过的类别泛化(零样本分类)。通过基于提示的推理将提出的基础模型转移到新任务的迁移能力。我们评估了三种不同的文本提示生成策略:异常检测(即,“正常”/“疾病”)、通过简单提示进行分类(即,新的疾病名称)和设计提示(即,领域知识描述)。所呈现的指标是每个类别的准确率。提出的FLAIR-π-EK方法被阴影表示,而最佳结果以粗体突出显示。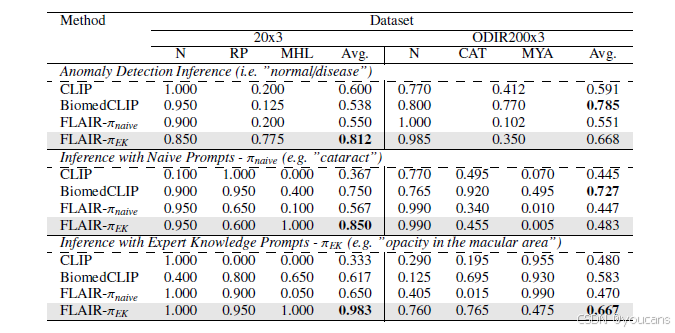
5.2 可迁移性
我们现在评估FLAIR- π EK \pi_{\text{EK}} πEK通过最小化高效微调将学习到的表征迁移到下游领域和任务的能力。因此,我们关注在适配过程中冻结训练好的特征提取器,仅在其顶部添加含可训练参数的轻量级模块(即适配器)的场景。具体而言,我们评估两种策略:i) 仅使用图像模态的线性探测[76];ii) 视觉-语言适配器,在适配过程中结合两种模态。
5.2.1 线性探测
适配策略
我们使用从视觉编码器 θ f ( ⋅ ) \theta_f(\cdot) θf(⋅)提取的特征作为额外线性分类器的输入,该分类器的参数在适配过程中进行微调。这种在文献中通常称为线性探测的策略,在5.2.3节的消融实验中得到了进一步的实证验证。
适配资源
为评估常见场景,我们研究了两种数据规模:i) 低数据规模:仅从目标数据集的每个类别中选取少量支持(即带标注)图像用于适配( k = 1 , 5 , 10 k={1, 5, 10} k=1,5,10);ii) 高数据规模:使用目标数据集中较大比例的样本进行适配,即 {20%, 40%, 60%, 80%} 。
训练/测试划分
在所有数据规模下,测试子集保持不变,均使用目标数据集的 20 20% 20。从训练子集中,仅随机选取与目标数据规模对应数量的样本用于适配预训练模型。此过程在5折交叉验证上取平均结果。
基线模型
为验证所提出基础模型的优势,我们评估了其他常见的迁移学习策略:i) 任务特定模型的线性探测:模型仅使用整合数据集中包含的某类别子集的所有样本,以标准监督方式进行预训练;ii) 无监督预训练的线性探测:使用SimCLR;iii) 从自然图像迁移学习的线性探测:使用在ImageNet上预训练的骨干网络;iv) 数据集特定模型的监督训练:在目标数据集上通过标准监督训练(即全网络微调),权重在ImageNet上预训练。关于不同基线模型的更多细节,请参阅第4.4.2和4.4.3节。
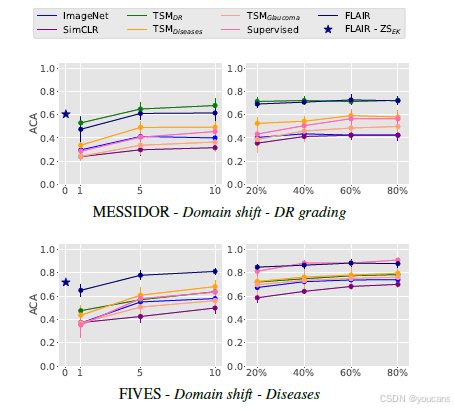
通过图像特征适配在评估数据集上的可迁移性结果如图4所示。
-
任务特定模型:所得结果揭示了任务特定模型在可迁移性方面的局限性。虽然它们在拥有足够预训练数据时,在其专门训练的任务上表现良好(见图4:MESSIDOR上的TSMDR或REFUGE上的TSMGlaucoma),但在更具挑战性的场景中其性能会下降。具体发生在:i) 预训练数据集相对较小(见图4:FIVES上的TSMDiseases);ii) 模型被适配到未见过的任务(见图4:MESSIDOR上的TSMGlaucoma或20x3上的TSMDR)。
-
数据集特定模型(监督训练):从图4中亦可观察到训练数据集特定模型的局限性。该策略在低数据量情况下表现不佳(见图4:所有数据集)。即使在较大数据量情况下,可用样本可能仍不足以达到FLAIR所取得的性能(见图4:MESSIDOR上的监督学习)。此外,由于需要调整整个模型,该方法计算成本高昂。
-
提出的基础模型(FLAIR):使用FLAIR在整合数据集上预训练后进行线性探测适配性能的主要结论包括:i) 在领域偏移场景下与最佳任务特定模型表现相当(见图4:MESSIDOR数据集);ii) 在整合数据集中代表性不足的任务上大幅超越这些模型(见图4:FIVES数据集);iii) 在未见类别上,于低数据量情况下优于监督式数据集特定模型的适配性能(见图4:20x3和ODIR200x3数据集);iv) 在许多情况下,于大数据量情况下也优于这些完全微调的模型(见图4:MESSIDOR、REFUGE和20x3数据集),这与近期关于放射影像视觉语言预训练的相关文献[85]结论一致。
5.2.2 视觉语言适配器
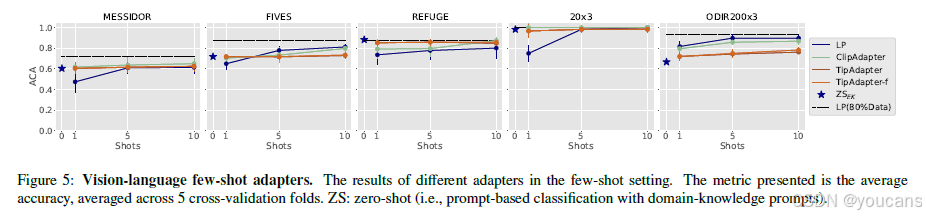
计算机视觉领域近期的前沿文献研究了一种称为适配器的策略,用于在低数据量(少样本)情况下针对目标任务微调视觉语言模型,例如Clip-Adapter[29]和Tip-Adapter[100]。这些策略通常整合预训练语言编码器驱动的知识以及视觉特征,并在网络中使用附加层。然而,这些适配器在医学领域的效用仍很大程度上未被探索。图5展示了使用我们预训练的FLAIR基础模型和专家知识提示的不同视觉语言适配器在各任务上的结果。结果表明了零样本分类在不同场景下的强大能力。在大多数情况下,通过领域专家知识提示增强的零样本推理优于使用 k ≤ 5 k \leq 5 k≤5个样本的适配(见图5 MESSIDOR、FIVES、REFUGE、20x3)。至于视觉语言适配器[100, 29],它们似乎未能提供一致的改进,无论是相对于零样本分类(当 k ≤ 5 k \leq 5 k≤5时)还是相对于基础线性探测(当 k = 10 k = 10 k=10时)。
5.2.3 消融实验
本节通过消融实验说明提出框架设计中不同决策的依据。
知识迁移应使用何种特征
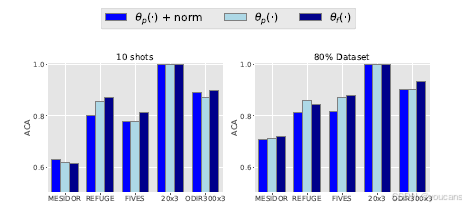
视觉语言预训练模型通过投影 θ p ( ⋅ ) \theta_p(\cdot) θp(⋅)将图像编码器特征 θ f ( ⋅ ) \theta_f(\cdot) θf(⋅)与文本表征对齐,并利用l2归一化映射到单位超球面。关于通过线性探测将预训练视觉特征迁移到下游领域和任务,先前文献中的标准特征表示选择通常基于投影和归一化[76, 29, 100]。在接下来的消融实验中,我们使用以下三种选项评估了不同评估数据集的特征可迁移性:视觉特征、投影特征、以及投影并归一化的特征。我们在低数据量( k = 10 k=10 k=10)和大数据量(数据集的 80 80% 80)两种情况下对这三种选项进行了评估。
图6 展示了结果,表明在大多数任务中,使用视觉表示 θ f ( ⋅ ) \theta_f(\cdot) θf(⋅)进行迁移时,性能优于使用投影特征 θ p ( ⋅ ) \theta_p(\cdot) θp(⋅)或投影并归一化特征 θ p ( ⋅ ) + norm \theta_p(\cdot)+\text{norm} θp(⋅)+norm。基于这些观察,我们在本工作的可迁移性实验中选择了原始特征表示 θ f ( ⋅ ) \theta_f(\cdot) θf(⋅)。
基于线性探测适配在领域偏移下的泛化能力
采用图像-语言模型及计算高效的线性探测适配的"预训练-适配"策略,在下游计算机视觉任务中已展现出良好性能。接下来,我们旨在对此线性探测策略进行更全面的评估,以检验适配阶段应对目标领域新变化(即适配后出现领域偏移)的能力。为此,我们采用了补充评估子集(参见表S1)。具体而言,我们评估了在源域上微调过的线性探测器在新目标域上的性能。更具体地说,适配过程使用两个数据集A和B按如下方式进行:模型在A上微调并在B上测试,反之亦然。我们再次评估了两种特征表示的可迁移性:从视觉编码器 θ f ( ⋅ ) \theta_f(\cdot) θf(⋅)提取的特征,以及基于跨模态投影头 θ p ( ⋅ ) \theta_p(\cdot) θp(⋅)得到的特征。我们将线性探测的性能与在源数据上微调所有模型可训练参数(即使用标准监督学习设置,但参数初始化分别采用FLAIR或Imagenet模型)的性能以及零样本性能进行了并列比较。实验在大数据量情况下进行,以评估可用数据非限制因素时的最佳场景性能。
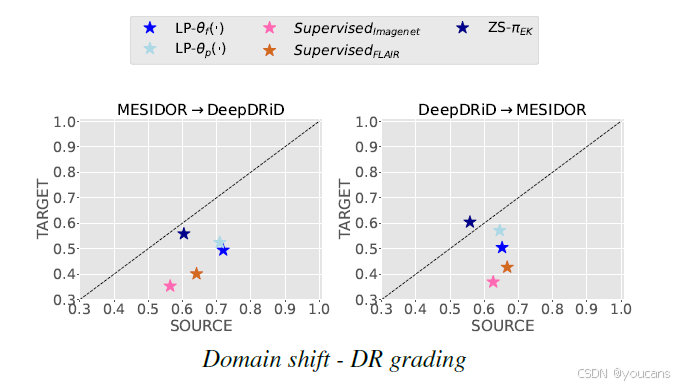
图7展示了这些实验的结果,从中可以得出以下要点:
采用监督学习、针对特定数据集训练的模型(即在源数据上更新所有可训练参数的模型)在源域上能达到良好性能。然而,它们在面对领域偏移时泛化能力不足(参见图7第一、二行)。基于基础模型的线性探测在多种情况下缓解了这一困难(参见图7第一、二、三行)。这些发现强调了基础模型的泛化能力,并与计算机视觉领域近期的观测结果一致[53]。这一特点在使用多模态投影的特征表示 θ p ( ⋅ ) \theta_p(\cdot) θp(⋅)进行适配时尤为明显。
如图6先前所示,视觉编码器特征 θ f ( ⋅ ) \theta_f(\cdot) θf(⋅)似乎对源域更具特异性,因此能产生最佳的整体性能。然而,图7的实验结果表明,这些特征在领域偏移下的性能可能会受到影响(参见图7所有子图)。因此,适配时选用何种特征表示可能取决于预期的数据变异性以及源域与目标域之间随时间推移的一致性。
值得指出的是,当预期存在较大领域偏移时,基于提示的(零样本)分类可能会提供更稳健的解决方案。在许多场景中,线性探测在目标域上的性能低于基于提示的分类。对于基础模型已识别的类别,以零样本方式进行的提示驱动分类在不同领域间能取得更为理想的结果(参见图7第一、二行)。我们在S2.2节提供了更多结果,这些结果说明了文本驱动迁移能力对领域偏移的鲁棒性,与计算机视觉文献中的近期发现一致[93,34]。当然,正如在图5中已指出的,零样本分类对领域变异性的这种鲁棒性是以其源域性能低于线性探测为代价的。
6. 讨论
我们提出了FLAIR——一种用于视网膜眼底图像通用病理检测与分类的新型视觉-语言基础模型。通过以文本提示监督的形式编码专家领域知识,FLAIR在整合的37个公开可用(主要为分类数据集)的数据集上进行训练,涵盖高达96个不同目标类别。通过利用领域知识,我们缓解了视网膜眼底成像数据集中文本监督稀缺的问题,为该应用领域的大规模视觉-语言预训练开辟了新途径。具体而言,我们通过对病理主要特征及其层级关系和相互关联进行文本编码,增强了数据集中的分类信息。这些宝贵的专家知识可从相关临床文献和行业标准中提取。
我们通过实证评估了FLAIR在领域偏移和未见疾病场景下的泛化与迁移能力。该模型在领域知识提示驱动的零样本预测中展现出强大的泛化能力,尤其在测试新型病理时(此时基础分类文本提示信息量不足)表现突出。此外,通过轻量级线性探测适配,FLAIR在目标领域和任务上的表现超越了完全微调的数据集专用模型,这种优势在低数据量(少样本)场景下更为显著。
通过系统的消融研究,我们验证了在视觉-语言预训练和零样本预测中整合领域知识的重要价值。我们的FLAIR模型结合领域知识提示的零样本预测能力,显著优于基于通用计算机视觉数据训练的CLIP模型,同时大幅超越了使用相同视网膜成像数据但仅采用朴素分类文本提示的CLIP变体。这些结果表明,将领域特定的专家知识嵌入面向医学成像不同子领域(甚至超越本研究的眼底应用范畴)的视觉-语言基础模型具有巨大潜力。我们证明,即使缺乏带文本监督的大规模数据集,仍可通过将专家领域知识编码为文本监督,利用分类标注样本来训练强大的视觉-语言表征。
最后,我们通过深入实验加深了对该方法潜力与局限的认知。通过对补充数据集进行多维度消融实验,我们发现当前医学领域视觉-语言预训练范式存在若干局限:首先,零样本泛化对针对新类别设计的提示较为敏感,尽管效果可观,但结果仍存在波动,这与近期其他研究的发现一致[88];其次,尽管基础模型在资源受限情况下对新任务展现出良好的适配能力,但其对分布外数据的迁移效果仍存在困难,这一现象在近期视觉-语言文献中也被重点关注[93,34]。
现有局限可为提升视觉-语言基础模型性能的研究提供新方向:开发面向专业领域(如眼底成像诊断)的新型语言处理可靠工具是值得探索的方向,有望提升文本编码器的鲁棒性;此外,整合能良好泛化至分布外数据的新型适配器,或可推动这种新兴"预训练-适配"范式的发展,其中文本驱动适配器将是颇具前景的研究路径。
7. FLAIR 项目介绍:FLAIR
项目地址:Github-FLAIR,huggingface-FLAIR

7.1 安装 FLAIR
在您的环境中安装与GPU兼容的torch版本。例如:
conda create -n flair_env python=3.11 -y
conda activate flair_env
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124
安装 FLAIR 库:
pip install git+https://github.com/jusiro/FLAIR.git
资源需求:
numpy
scikit-learn
transformers
tqdm
pandas
pillow
kornia
scikit-image
safetensors
7.2 使用方法
from PIL import Image
import numpy as np
# 导入 FLAIR
from flair import FLAIRModel
# 设置模型
model = FLAIRModel.from_pretrained("jusiro2/FLAIR")
# 加载图像并设置目标类别
#(如果未克隆仓库,请下载图像并更改路径!)
image = np.array(Image.open("./documents/sample_macular_hole.png"))
text = ["正常", "健康", "黄斑水肿", "糖尿病视网膜病变", "青光眼", "黄斑裂孔",
"病变", "黄斑区病变"]
# 运行 FLAIR 模型计算相似度
probs, logits = model(image, text)
print("图像-文本相似度:")
print(logits.round(3)) # [[-0.186 -3.092 3.357 4.444 6.223 7.493 7.028 11.395]]
print("概率分布:")
print(probs.round(3)) # [[0. 0. 0. 0.001 0.005 0.019 0.012 0.962]]
7.3 预训练与迁移学习
以下展示模型预训练和迁移学习的脚本。使用时建议克隆完整仓库:
git clone https://github.com/jusiro/FLAIR.git
cd FLAIR
pip install -r requirements.txt
7.4 基础模型预训练
在 ./local_data/constants.py 中定义数据集和数据框的相对路径。
准备 FUNDUS 组合数据集 - 查看 ./local_data/prepare_partitions.py 准备数据框。
支持的数据集列表:
01_EYEPACS 08_ODIR-5K 15_APTOS 22_HEI-MED 29_AIROGS 36_ACRIMA
02_MESIDOR 09_PAPILA 16_FUND-OCT 23_HRF 30_SUSTech-SYSU 37_DeepDRiD
03_IDRID 10_PARAGUAY 17_DiaRetDB1 24_ORIGA 31_JICHI 38_MMAC
04_RFMid 11_STARE 18_DRIONS-DB 25_REFUGE 32_CHAKSU
05_1000x39 12_ARIA 19_Drishti-GS1 26_ROC 33_DR1-2
06_DEN 13_FIVES 20_E-ophta 27_BRSET 34_Cataract
07_LAG 14_AGAR300 21_G1020 28_OIA-DDR 35_ScarDat
注意事项:请谨慎使用数据链接!这些是开放访问仓库,部分数据集可能未由原作者维护。链接可能变更或包含恶意软件。我们会尽力保持链接更新,但无法频繁检查。如遇问题可提交Issue,我们将尽快处理。
视觉语言预训练:
python main_pretrain.py --augment_description True --balance True --epochs 15 --batch_size 128 --num_workers 6
7.5 下游任务/领域迁移
在 ./local_data/constants.py 中定义数据集和数据框的相对路径。
在 ./local_data/experiments.py 中配置目标数据集的实验设置:
if experiment == "02_MESSIDOR":
setting = {"dataframe": PATH_DATAFRAME_TRANSFERABILITY_CLASSIFICATION + "02_MESSIDOR.csv",
"task": "classification",
"targets": {"无糖尿病视网膜病变": 0,
"轻度糖尿病视网膜病变": 1,
"中度糖尿病视网膜病变": 2,
"重度糖尿病视网膜病变": 3,
"增殖性糖尿病视网膜病变": 4}}
零样本学习(无需适配):
python main_transferability.py --experiment 02_MESSIDOR --method zero_shot --load_weights True --domain_knowledge True --shots_train 0% --shots_test 100% --project_features True --norm_features True --folds 1
线性探测:
python main_transferability.py --experiment 02_MESSIDOR --method lp --load_weights True --shots_train 8
8. 参考文献
Abramoff, M.D., Lou, Y., Erginay, A., Clarida, W., Amelon, R., Folk, J.C., Niemeijer, M., 2016. Improved automated detection of diabetic retinopathy on a publicly available dataset through integration of deep learning. Investigative Ophthalmology and Visual Science 57, 5200–5206.
Allen, D., Vasavada, A., 206. Cataract and surgery for cataract. British Medical Journal 333, 128–132.
Ara´ujo, T., Aresta, G., Mendonc¸a, L., Penas, S., Maia, C., Carneiro, A., Mendonc¸a, A.M., Campilho, A., 2020. Dr|graduate: Uncertainty-aware deep learning-based diabetic retinopathy grading in eye fundus images. Medical Image Analysis 63, 101715.
Bajwa, M.N., Singh, G.A.P., Neumeier, W., Malik, M.I., Dengel, A., Ahmed, S., 2020. G1020: A benchmark retinal fundus image dataset for computer-aided glaucoma detection, in: International Joint Conference on Neural Networks (IJCNN), pp. 1–7.
Balyen, L., Peto, T., 2019. Promising artificial intelligence–machine learning–deep learning algorithms in ophthalmology. Asia-Pacific Journal of Ophthalmology 8, 264–272.
Bellemo, V., Lim, Z.W., Lim, G., Nguyen, Q.D., Xie, Y., Yip, M.Y., Hamzah, H., Ho, J., Lee, X.Q., Hsu, W., Lee, M.L., Musonda, L., Chandran, M., Chipalo-Mutati, G., Muma, M., Tan, G.S., Sivaprasad, S., Menon, G., Wong, T.Y., Ting, D.S., 2019. Artificial intelligence using deep learning to screen for referable and vision-threatening diabetic retinopathy in africa: a clinical validation study. The Lancet Digital Health 1, e35–e44.
Bodenreider, O., 2004. The unified medical language system (umls): Integrating biomedical terminology. Nucleic Acids Research 32.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al., 2020. Language models are few-shot learners. Advances in neural information processing systems 33, 1877–1901.
Budai, A., Bock, R., Maier, A., Hornegger, J., Michelson, G., 2013.
Robust vessel segmentation in fundus images. International Journal of Biomedical Imaging , 154860.
Bustos, A., Pertusa, A., Salinas, J.M., de la Iglesia-Vay´a, M., 2019.
Padchest: A large chest x-ray image dataset with multi-label annotated reports. Medical Image Analysis 66.
Carmona, E.J., Rinc´on, M., Garc´ıa-Feijo´o, J., de-la Casa, J.M.M., 2008. Identification of the optic nerve head with genetic algorithms. Artificial Intelligence in Medicine 43, 243–259.
Castillo Ben´ıtez, V.E., Castro Matto, I., Mello Rom´an, J.C., V´azquez Noguera, J.L., Garc´ıa-Torres, M., Ayala, J., Pinto-Roa, D.P., Gardel-Sotomayor, P.E., Facon, J., Grillo, S.A., 2021. Dataset from fundus images for the study of diabetic retinopathy. Data in Brief 36, 107068.
Cen, L.P., Ji, J., Lin, J.W., Ju, S.T., Lin, H.J., Li, T.P., Wang, Y., Yang, J.F., Liu, Y.F., Tan, S., Tan, L., Li, D., Wang, Y., Zheng, D., Xiong, Y., Wu, H., Jiang, J., Wu, Z., Huang, D., Shi, T., Chen, B., Yang, J., Zhang, X., Luo, L., Huang, C., Zhang, G., Huang, Y., Ng, T.K., Chen, H., Chen, W., Pang, C.P., Zhang, M., 2021. Automatic detection of 39 fundus diseases and conditions in retinal photographs using deep neural networks. Nature Communications 12, 4828.
Chen, T., Kornblith, S., Norouzi, M., Hinton, G., 2020. A simple framework for contrastive learning of visual representations, in: International Conference on Machine Learning (ICML), pp. 1–11.
Chen, X., Wang, X., Zhang, K., Fung, K.M., Thai, T.C., Moore, K., Mannel, R.S., Liu, H., Zheng, B., Qiu, Y., 2022a. Recent advances and clinical applications of deep learning in medical image analysis.
Medical Image Analysis 79, 4.
Chen, Z., Li, G., Wan, X., 2022b. Align, reason and learn: Enhancing medical vision-and-language pre-training with knowledge, in: Proceedings of the ACM International Conference on Multimedia, Association for Computing Machinery (ACM). pp. 5152–5161.
Decenciere, E., Cazuguel, G., Zhang, X., Thibault, G., Klein, J.C., Meyer, F., Marcotegui, B., Quellec, G., Lamard, M., Danno, R., Elie, D., Massin, P., Viktor, Z., Erginay, A., La¨y, B., Chabouis, A., 2013. Teleophta: Machine learning and image processing methods for teleophthalmology. IRBM 34, 196–203.
Decenciere, E., Zhang, X., Cazuguel, G., La¨y, B., Cochener, B., Trone, C., Gain, P., Ord´o˜nez-Varela, J.R., Massin, P., Erginay, A., Charton, B., Klein, J.C., 2014. Feedback on a publicly distributed image database: The messidor database. Image Analysis and Stereology 33, 231–234.
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L., 2009. Imagenet: A large-scale hierarchical image database, in: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1–8.
Derwin, D.J., Selvi, S.T., Singh, O.J., Shan, B.P., 2020. A novel automated system of discriminating microaneurysms in fundus images. Biomedical Signal Processing and Control 58, 101839.
Diaz-Pinto, A., Morales, S., Naranjo, V., K¨ohler, T., Mossi, J.M., Navea, A., 2019. Cnns for automatic glaucoma assessment using fundus images: An extensive validation. BioMedical Engineering Online 18.
Erhan, D., Manzagol, P.A., Bengio, Y., Bengio, S., Vincent, P., 2009. The difficulty of training deep architectures and the effect of unsupervised pre-training, in: Proceedings of the International Conference on Artificial Intelligence and Statistics (PMLR), pp. 153–160.
Eslami, S., de Melo, G., Meinel, C., 2021. Does clip benefit visual question answering in the medical domain as much as it does in the general domain?, in: Arxiv Preprint, pp. 1–9.
Fang, L., Wang, C., Li, S., Rabbani, H., Chen, X., Liu, Z., 2019. Attention to lesion: Lesion-aware convolutional neural network for retinal optical coherence tomography image classification. IEEE Transactions on Medical Imaging 38, 1959–1970.
Farnell, D.J., Hatfield, F.N., Knox, P., Reakes, M., Spencer, S., Parry, D., Harding, S.P., 2008. Enhancement of blood vessels in digital fundus photographs via the application of multiscale line operators. Journal of the Franklin Institute 345, 748–765.
Fauw, J.D., Ledsam, J.R., Romera-Paredes, B., Nikolov, S., Tomasev, N., Blackwell, S., Askham, H., Glorot, X., O’Donoghue, B., Visentin, D., van den Driessche, G., Lakshminarayanan, B., Meyer, C., Mackinder, F., Bouton, S., Ayoub, K., Chopra, R., King, D., Karthikesalingam, A., Hughes, C.O., Raine, R., Hughes, J., Sim, D.A., Egan, C., Tufail, A., Montgomery, H., Hassabis, D., Rees, G., Back, T., Khaw, P.T., Suleyman, M., Cornebise, J., Keane, P.A., Ronneberger, O., 2018. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nature Medicine 24, 1342–1350.
Finlayson, S.G., Subbaswamy, A., Singh, K., Bowers, J., Kupke, A., Zittrain, J., Kohane, I.S., Saria, S., 2021. The clinician and dataset shift in artificial intelligence. The New England Journal of Medicine 385, 283–286.
Galdran, A., Dolz, J., Chakor, H., Lombaert, H., Ayed, I.B., 2020. Cost-sensitive regularization for diabetic retinopathy grading from eye fundus images, in: Medical Image Computing and Computer Assisted Intervention (MICCAI), pp. 1–7.
Gao, P., Geng, S., Zhang, R., Ma, T., Fang, R., Zhang, Y., Li, H., Qiao, Y., 2021. Clip-adapter: Better vision-language models with feature adapters, in: ArXiv preprint, pp. 1–11. URL: http:// arxiv.org/abs/2110.04544.
Garner, A., Ashton, N., 1979. Pathogenesis of hypertensive retinopathy: a review’. Journal of the Royal Society of Medicine 72.
Gass, M.J.D.M., 1988. Idiopathic senile macular hole its early stages and pathogenesis. Arch Ophthalmol. 106, 629–639.
Giancardo, L., Meriaudeau, F., Karnowski, T.P., Li, Y., Garg, S., Tobin, K.W., Chaum, E., 2012. Exudate-based diabetic macular edema detection in fundus images using publicly available datasets. Medical Image Analysis 16, 216–226.
Goldberger, A., Amaral, L., Glass, L., Hausdorff, J., Ivanov, P.C., Mark, R., ., Stanley, H.E., 2000. Physiobank, physiotoolkit, and physionet: Components of a new research resource for complex physiologic signals. Circulation 101, 215–220.
Goyal, S., Kumar, A., Garg, S., Raghunathan, Z.K.A., 2023. Finetune like you pretrain: Improved finetuning of zero-shot vision models, in: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), pp. 19338– 19347.
Hamel, C., 2006. Retinitis pigmentosa. Orphanet Journal of Rare Diseases 1.
Hassan, T., Akram, M.U., Masood, M.F., Yasin, U., 2019. Deep structure tensor graph search framework for automated extraction and characterization of retinal layers and fluid pathology in retinal sdoct scans. Computers in Biology and Medicine 105, 112–124.
Hassan, T., Akram, M.U., Werghi, N., Nazir, M.N., 2021. Rag-fw: A hybrid convolutional framework for the automated extraction of retinal lesions and lesion-influenced grading of human retinal pathology. IEEE Journal of Biomedical and Health Informatics 25, 108–120.
He, K., Zhang, X., Ren, S., Sun, J., 2016. Deep residual learning for image recognition, in: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1–12.
Hoover, A., 2000. Locating blood vessels in retinal images by piecewise threshold probing of a matched filter response. IEEE Transactions on Medical Imaging 19, 203–210.
Hoover, A., Goldbaum, M., 2003. Locating the optic nerve in a retinal image using the fuzzy convergence of the blood vessels. IEEE Transactions on Medical Imaging 22, 951–958.
Hu, S.X., Li, D., St¨uhmer, J., Kim, M., Hospedales, T.M., 2022. Pushing the limits of simple pipelines for few-shot learning: External data and fine-tuning make a difference, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9068–9077.
Huang, J.H., Yang, C.H.H., Liu, F., Tian, M., Liu, Y.C., Wu, T.W., Lin, I.H.,Wang, K., Morikawa, H., Chang, H., Tegner, J.,Worring, M., 2021a. Deepopht: medical report generation for retinal images via deep models and visual explanation, in: Proceedings of the Winter Conference on Applications of Computer Vision (WACV), pp. 2442–2452.
Huang, S.C., Pareek, A., Jensen, M., Lungren, M.P., Yeung, S., Chaudhari, A.S., 2023. Self-supervised learning for medical image classification: a systematic review and implementation guidelines. npj Digital Medicine 6.
Huang, S.C., Shen, L., Lungren, M.P., Yeung, S., 2021b. Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition, in: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 3942–3951.
Jain, S., Agrawal, A., Saporta, A., Truong, S.Q., Duong, D.N., Bui, T., Chambon, P., Zhang, Y., Lungren, M.P., Ng, A.Y., Langlotz, C.P., Rajpurkar, P., 2021. Radgraph: Extracting clinical entities and relations from radiology reports. NeurIPS: Track on Datasets and Benchmarks .
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q.V., Sung, Y., Li, Z., Duerig, T., 2021. Scaling up visual and visionlanguage representation learning with noisy text supervision, in: International Conference on Machine Learning (ICML), pp. 1–13.
Jin, K., Huang, X., Zhou, J., Li, Y., Yan, Y., Sun, Y., Zhang, Q., Wang, Y., Ye, J., 2022. Fives: A fundus image dataset for artificial intelligence based vessel segmentation. Scientific Data 9, 475.
Johnson, A.E., Pollard, T.J., Berkowitz, S.J., Greenbaum, N.R., Lungren, M.P., ying Deng, C., Mark, R.G., Horng, S., 2019. Mimiccxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific Data 6.
Kanavati, F., Tsuneki, M., 2021. Partial transfusion: on the expressive influence of trainable batch norm parameters for transfer learning, in: MIDL, pp. 338–353.
Kauppi, T., Kalesnykiene, V., Kamarainen, J.K., Lensu, L., Sorri, I., Raninen, A., Voutilainen, R., Uusitalo, H., Kalviainen, H., Pietila, J., 2007. The diaretdb1 diabetic retinopathy database and evaluation protocol, in: Proceedings of the British Machine Vision Conference (BMVC), pp. 1–18.
Kovalyk, O., Morales-S´anchez, J., Verd´u-Monedero, R., Sell´es- Navarro, I., Palaz´on-Cabanes, A., Sancho-G´omez, J.L., 2022. Papila: Dataset with fundus images and clinical data of both eyes of the same patient for glaucoma assessment. Scientific Data 9, 291.
Krause, J., Gulshan, V., Rahimy, E., Karth, P., Widner, K., Corrado, G.S., Peng, L., Webster, D.R., 2018. Grader variability and the importance of reference standards for evaluating machine learning models for diabetic retinopathy. Ophthalmology 125, 1264–1272.
Kumar, A., Raghunathan, A., Jones, R.M., Ma, T., Liang, P., 2022. Fine-tuning can distort pretrained features and underperform outof- distribution, in: International Conference on Learning Representations (ICLR), pp. 1–42.
Kumar, J.R., Seelamantula, C.S., Gagan, J.H., Kamath, Y.S., Kuzhuppilly, N.I., Vivekanand, U., Gupta, P., Patil, S., 2023. Chaksu: A glaucoma specific fundus image database. Scientific Data 10.
Li, F., Song, D., Chen, H., Xiong, J., Li, X., Zhong, H., Tang, G., Fan, S., Lam, D.S., Pan, W., Zheng, Y., Li, Y., Qu, G., He, J., Wang, Z., Jin, L., Zhou, R., Song, Y., Sun, Y., Cheng, W., Yang, C., Fan, Y., Li, Y., Zhang, H., Yuan, Y., Xu, Y., Xiong, Y., Jin, L., Lv, A., Niu, L., Liu, Y., Li, S., Zhang, J., Zangwill, L.M., Frangi, A.F., Aung, T., yu Cheng, C., Qiao, Y., Zhang, X., Ting, D.S., 2020. Development and clinical deployment of a smartphone-based visual field deep learning system for glaucoma detection. npj Digital Medicine 3.
Li, L., Xu, M., Wang, X., Jiang, L., Liu, H., 2019a. Attention based glaucoma detection: A large-scale database and cnn model, in: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1–10.
Li, T., Bo, W., Hu, C., Kang, H., Liu, H., Wang, K., Fu, H., 2021. Applications of deep learning in fundus images: A review. Medical Image Analysis1 69, 101971.
Li, T., Gao, Y.,Wang, K., Guo, S., Liu, H., Kang, H., 2019b. Diagnostic assessment of deep learning algorithms for diabetic retinopathy screening. Information Sciences 501, 511 – 522.
Lin, L., Li, M., Huang, Y., Cheng, P., Xia, H., Wang, K., Yuan, J., Tang, X., 2020. The sustech-sysu dataset for automated exudate detection and diabetic retinopathy grading. Scientific Data 7.
Liu, J., Zhang, Y., Chen, J.N., Xiao, J., Lu, Y., Landman, B.A., Yuan, Y., Yuille, A., Tang, Y., Zhou, Z., 2023. Clip-driven universal model for organ segmentation and tumor detection, in: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 1–23.
Liu, R.,Wang, X.,Wu, Q., Dai, L., Fang, X., Yan, T., Son, J., Tang, S., Li, J., Gao, Z., Galdran, A., Poorneshwaran, J.M., Liu, H., Wang, J., Chen, Y., Porwal, P., Tan, G.S.W., Yang, X., Dai, C., Song, H., Chen, M., Li, H., Jia, W., Shen, D., Sheng, B., Zhang, P., 2022. Deepdrid: Diabetic retinopathy—grading and image quality estimation challenge. Patterns 3.
Lu, M.Y., Chen, B., Zhang, A., Williamson, D.F.K., Chen, R.J., Ding, T., Le, L.P., Chuang, Y.S., Mahmood, F., 2023. Visual language pretrained multiple instance zero-shot transfer for histopathology images, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 19764–19775.
Matsoukas, C., Haslum, J.F., Sorkhei, M., S¨oderberg, M., Smith, K., 2022. What makes transfer learning work for medical images: Feature reuse and other factors, in: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9225–9234.
Menon, S., Vondrick, C., 2023. Visual classification via description from large language models, in: International Conference of Learning Representations (ICLR), pp. 1–17.
Moor, M., Banerjee, O., Abad, Z.S.H., Krumholz, H.M., Leskovec, J., Topol, E.J., Rajpurkar, P., 2023. Foundation models for generalist medical artificial intelligence. Nature 616, 259–265.
Muller, P., Kaissis, G., Zou, C., Rueckert, D., 2022. Joint learning of localized representations from medical images and reports, in: Proceedings of the European Conference on Computer Vision (ECCV), pp. 1–17.
Nakayama, L.F., Goncalves, M., Zago Ribeiro, L., Santos, H., Ferraz, D., Malerbi, F., Celi, L.A., Regatieri, C., 2023. A brazilian multilabel ophthalmological dataset (brset), in: PhysioNet, p. 1.
Neyshabur, B., Sedghi, H., Zhang, C., 2020. What is being transferred in transfer learning?, in: Advances in Neural Information Processing Systems (NeurIPS), pp. 1–12.
Niemeijer, M., Ginneken, B.V., Cree, M.J., Mizutani, A., Quellec, G., Sanchez, C.I., Zhang, B., Hornero, R., Lamard, M., Muramatsu, C., Wu, X., Cazuguel, G., You, J., Mayo, A., Li, Q., Hatanaka, Y., Cochener, B., Roux, C., Karray, F., Garcia, M., Fujita, H., Abramoff, M.D., 2010. Retinopathy online challenge: Automatic detection of microaneurysms in digital color fundus photographs. IEEE Transactions on Medical Imaging 29, 185–195. Orlando, J.I., Fu, H., Breda, J.B., van Keer, K., Bathula, D.R., Diaz- Pinto, A., Fang, R., Heng, P.A., Kim, J., Lee, J., Lee, J., Li, X., Liu, P., Lu, S., Murugesan, B., Naranjo, V., Phaye, S.S.R., Shankaranarayana, S.M., Sikka, A., Son, J., van den Hengel, A., Wang, S., Wu, J., Wu, Z., Xu, G., Xu, Y., Yin, P., Li, F., Zhang, X., Xu, Y., Zhang, X., Bogunovi´c, H., 2019. Refuge challenge: A unified framework for evaluating automated methods for glaucoma assessment from fundus photographs. Medical Image Analysis 59, 1–21.
Pachade, S., Porwal, P., Thulkar, D., Kokare, M., Deshmukh, G., Sahasrabuddhe, V., Giancardo, L., Quellec, G.,M´eriaudeau, F., 2021. Retinal fundus multi-disease image dataset (rfmid): A dataset for multi-disease detection research. Data 6, 1–14.
Pelka, O., Koitka, S., R¨uckert, J., Nensa, F., Friedrich, C.M., 2018. Radiology objects in context (roco): A multimodal image dataset, in: MICCAI Workshop: Large-scale Annotation of Biomedical Data and Expert Label Synthesis (LABELS), p. 180–189.
Pires, R., Jelinek, H.F., Wainer, J., Valle, E., Rocha, A., 2014. Advancing bag-of-visual-words representations for lesion classification in retinal images. PLoS ONE 9.
Porwal, P., Pachade, S., Kokare, M., Deshmukh, G., Son, J., Bae, W., Liu, L., Wang, J., Liu, X., Gao, L., Wu, T.B., Xiao, J., Wang, F., Yin, B., Wang, Y., Danala, G., He, L., Choi, Y.H., Lee, Y.C., Jung, S.H., Li, Z., Sui, X., Wu, J., Li, X., Zhou, T., Toth, J., Baran, A., Kori, A., Chennamsetty, S.S., Safwan, M., Alex, V., Lyu, X., Cheng, L., Chu, Q., Li, P., Ji, X., Zhang, S., Shen, Y., Dai, L., Saha, O., Sathish, R., Melo, T., Ara´ujo, T., Harangi, B., Sheng, B., Fang, R., Sheet, D., Hajdu, A., Zheng, Y., Mendonc¸a, A.M., Zhang, S., Campilho, A., Zheng, B., Shen, D., Giancardo, L., Quellec, G., M´eriaudeau, F., 2020. Idrid: Diabetic retinopathy – segmentation and grading challenge. Medical Image Analysis 59, 101561.
Qin, Z., Yi, H., Lao, Q., Li, K., 2023. Medical image understanding with pretrained vision language models: a comprehensive study, in: International Conference on Learing Representations (ICLR), pp. 1–20.
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I., 2021. Learning transferable visual models from natural language supervision, in: International Conference on Machine Learning (ICML), pp. 1–16.
Raghu, M., Zhang, C., Kleinberg, J., Bengio, S., 2019. Transfusion: Understanding transfer learning for medical imaging, in: Advances in neural information processing systems (NeurIPS), pp. 1–11.
Ruiz-Medrano, J., Montero, J.A., Flores-Moreno, I., Arias, L., Garc´ıa- Layana, A., Ruiz-Moreno, J.M., 2019. Myopic maculopathy: Current status and proposal for a new classification and grading system (atn). Progress in Retinal and Eye Research 69, 80–115.
Sengupta, S., Singh, A., Leopold, H.A., Gulati, T., Lakshminarayanan, V., 2020. Ophthalmic diagnosis using deep learning with fundus images – a critical review. Artificial Intelligence in Medicine 102, 101758.
Shu, M., Nie, W., Huang, D.A., Yu, Z., Goldstein, T., Anandkumar, A., Xiao, C., 2022. Test-time prompt tuning for zero-shot generalization in vision-language models. Advances in Neural Information Processing Systems 35, 14274–14289.
Sivaswamy, J., Krishnadas, S.R., Joshi, G.D., Jain, M., Tabish, A.U.S., 2014. Drishti-gs retinal image dataset for optic nerve head segmentation, in: International Symposium on Biomedical Imaging (ISBI), pp. 53–56.
Sun, R., Li, Y., Zhang, T., Mao, Z., Wu, F., Zhang, Y., 2021. Lesionaware transformers for diabetic retinopathy grading, in: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10938–10939.
Tajbakhsh, N., Shin, J.Y., Gurudu, S.R., Hurst, R.T., Kendall, C.B., Gotway, M.B., Liang, J., 2017. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Transactions on Medical Imaging 35, 1299–1312.
Takahashi, H., Tampo, H., Arai, Y., Inoue, Y., Kawashima, H., 2017. Applying artificial intelligence to disease staging: Deep learning for improved staging of diabetic retinopathy. PLoS ONE 12.
Tiu, E., Talius, E., Patel, P., Langlotz, C.P., Ng, A.Y., Rajpurkar, P., 2022. Expert-level detection of pathologies from unannotated chest x-ray images via self-supervised learning. Nature Biomedical Engineering . de Vente, C., Vermeer, K.A., Jaccard, N., Wang, H., Sun, H., Khader, F., Truhn, D., Aimyshev, T., Zhanibekuly, Y., Le, T.D., Galdran, A., Gonzalez Ballester, M.A., Carneiro, G., G, D.R., S, H.P., Puthussery, D., Liu, H., Yang, Z., Kondo, S., Kasai, S., Wang, E., Durvasula, A., Heras, J., Zapata, M.A., Araujo, T., Aresta, G., Bogunovic, H., Arikan, M., Lee, Y.C., Cho, H.B., Choi, Y.H., Qayyum, A., Razzak, I., van Ginneken, B., Lemij, H.G., Sanchez, C.I., 2023. Airogs: Artificial intelligence for robust glaucoma screening challenge. ArXiv preprint .
Wang, F., Zhou, Y.,Wang, S., Vardhanabhuti, V., Yu, L., 2022a. Multigranularity cross-modal alignment for generalized medical visual representation learning, in: Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), pp. 1–14.
Wang, Z., Wu, Z., Agarwal, D., Sun, J., 2022b. Medclip: Contrastive learning from unpaired medical images and text, in: Empirical Methods in Natural Language Processing (EMNLP), pp. 1–12.
Wei, Q., Li, X., Wang, H., Ding, D., Yu, W., Chen, Y., 2018. Laser scar detection in fundus images using convolutional neural networks, in: Asian Conference on Computer Vision (ACCV), pp. 191–206.
WHO, 2019. World report of vision. World Health Organization .
Wilkinson, C.P., Ferris, F.L., Klein, R.E., Lee, P.P., Agardh, C.D., Davis, M., Dills, D., Kampik, A., Pararajasegaram, R., Verdaguer, J.T., Lum, F., 2003. Proposed international clinical diabetic retinopathy and diabetic macular edema disease severity scales. Ophthalmology 110, 1677–1682.
Windsor, R., Jamaludin, A., Kadir, T., Zisserman, A., 2023. Visionlanguage modelling for radiological imaging and reports in the low data regime, in: Medical Image with Deep Learning (MIDL), pp. 1–21.
Wortsman, M., Ilharco, G., Kim, J.W., Li, M., Kornblith, S., Roelofs, R., Gontijo-Lopes, R., Hajishirzi, H., Farhadi, A., Namkoong, H., Schmidt, L., 2022. Robust fine-tuning of zero-shot models, in: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7959–7971.
Wu, C., Zhang, X., Zhang, Y., Wang, Y., Xie, W., 2023. Medklip: Medical knowledge enhanced language-image pre-training in radiology, in: ArXiv Preprint, pp. 1–16. URL: http://arxiv.org/ abs/2301.02228.
W´ojcik, M.A., 2022. Foundation models in healthcare: Opportunities, biases and regulatory prospects in europe. EGOVIS 13429 LNCS, 32–46.
Xiaomeng, L., Hu, X., Lequan, Y., Zhu, L., Fu, C.W., Heng, P.A., 2020. Canet: Cross-disease attention network for joint diabetic retinopathy and diabetic macular edema grading. IEEE Transactions on Medical Imaging 5, 1483–1494.
Xie, X., Niu, J., Member, S., Liu, X., Chen, Z., Tang, S., Yu, S., 2021. A survey on incorporating domain knowledge into deep learning for medical image analysis. Medical Image Analysis 69, 101985.
Yang, J., Li, C., Zhang, P., Xiao, B., Liu, C., Yuan, L., Gao, J., 2022. Unified contrastive learning in image-text-label space, in: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), pp. 19163–19173.
Yang, J.J., Li, J., Shen, R., Zeng, Y., He, J., Bi, J., Li, Y., Zhang, Q., Peng, L., Wang, Q., 2016. Exploiting ensemble learning for automatic cataract detection and grading. Computer Methods and Programs in Biomedicine 124, 45–57.
Zhang, R., Fang, R., Zhang, W., Gao, P., Li, K., Dai, J., Qiao, Y., Li, H., 2022a. Tip-adapter: Training-free clip-adapter for better vision-language modeling, in: Proceedings of the European Conference on Computer Vision (ECCV), pp. 1–19.
Zhang, S., Xu, Y., Usuyama, N., Bagga, J., Tinn, R., Preston, S., Rao, R., Wei, M., Valluri, N., Wong, C., Lungren, M., Naumann, T., Poon, H., 2023. Large-scale domain-specific pretraining for biomedical vision-language processing. URL: https://arxiv.org/abs/2303.00915, doi:10.48550/ARXIV.2303.00915.
Zhang, Y., Jiang, H., Miura, Y., Manning, C.D., Langlotz, C.P., 2022b. Contrastive learning of medical visual representations from paired images and text, in: Machine Learning for Healthcare (MLHC), pp. 1–16.
Zhang, Z., Yin, F.S., Liu, J., Wong, W.K., Tan, N.M., Lee, B.H., Cheng, J., Wong, T.Y., 2010. Origa-light: An online retinal fundus image database for glaucoma analysis and research, in: Annual International Conference of the IEEE Engineering in Medicine and Biology, pp. 3065–3068.
Zhao, S., Zhang, Z., Schulter, S., Zhao, L., Vijay Kumar, B., Stathopoulos, A., Chandraker, M., Metaxas, D.N., 2022. Exploiting unlabeled data with vision and language models for object detection, in: European Conference on Computer Vision, pp. 159– 175.
Zhao, Z., Zhang, K., Hao, X., Tian, J., Chua, M.C.H., Chen, L., Xu, X., 2019. Bira-net bilinear attention net for diabetic retinopathy grading, in: International Conference on Image Processing (ICIP), pp. 1385–1389.
版权说明:
本文由 youcans@xidian 对论文 “A Foundation Language-Image Model of the Retina (FLAIR): encoding expert knowledge in text supervision” 进行摘编和翻译。该论文版权属于原文期刊和作者,本译文只供研究学习使用。
引用格式: J. Silva-Rodríguez, H. Chakor, R. Kobbi, J. Dolz, and I. Ben Ayed, “A Foundation Language-Image Model of the Retina (FLAIR): encoding expert knowledge in text supervision,” Medical Image Analysis, vol. 99, p. 103357, 2025, doi: 10.1016/j.media.2024.103357
youcans@xidian 作品,转载必须标注原文链接:
【医学影像 AI】视网膜基础语言-图像模型(FLAIR):通过文本监督编码专家知识
(https://youcans.blog.csdn.net/article/details/155428067)
Crated:2025-12

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 31
31 0
0- 0



 已为社区贡献234条内容
已为社区贡献234条内容

所有评论(0)