智算数据中心的参数面组网多平面网络设计
转自微信公众号:西贝吹风
前文我们讨论了Scale Out、Scale Up区别,Scale Up是向上扩展(纵向扩展),增加单节点内的GPU/NPU算卡数量,提升单节点性能;Scale Out是向外扩展(横向扩展),增加节点的数量,扩大整体组网规模,以支持单一节点无法完成的大模型训练任务。本文重点介绍一下Scale Out组网架构及发展趋势。
智算中心组网的通常架构
智算中心组网有多种形式,如CLOS、Dragonfly、Slim Fly、Torus等,此外还演进出了多种变种的组网模式,如Rail-only、Rail-optimized、MPFT、ZCube等,其中,胖树CLOS架构由于其高效的路由设计、良好的可扩展性及方便管理等优势,在大模型训练场景下被广泛应用,通常采用Spine-Leaf两层CLOS架构,两层架构无法满足规模扩展时,可以增加一层Super-Spine来进行扩展。
两层CLOS架构:
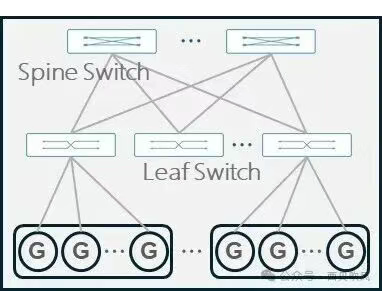
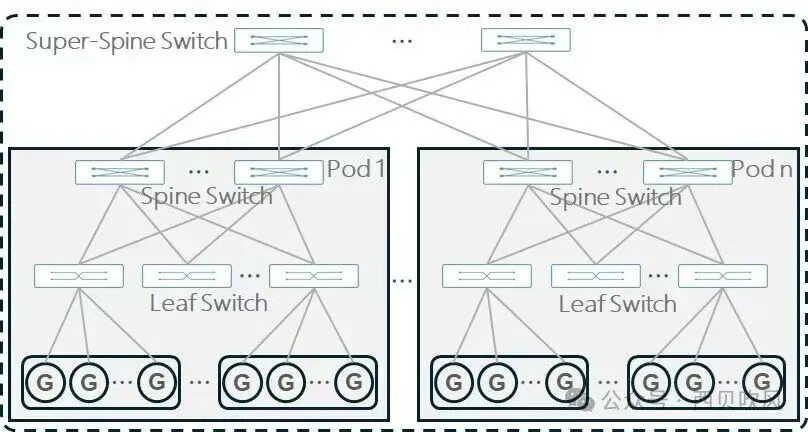
三层CLOS架构:
Rail-only架构:MIT于2023年提出Rail-only网络架构,Rail-only网络保留了HB域和Rail交换机,移除了Spine交换机,可以显著降低网络成本和功耗。

以51.2T的交换机组网为例,8台51.2T的交换机(128 x 400G端口),就可以组成一个千卡训练集群。
Rail-optimized胖树架构(Rail-Optimized Fat-Tree,ROFT架构),如下图所示,在多轨道网络架构中,AI训练产生的通信需求,可以用多个轨道并行传输加速,并且大部分流量都聚合在轨道内传输(只经过一级交换),小部分流量进行跨轨道传输(需要经过二级或多级),从而减轻网络通信压力。

双平面网络架构
阿里云2024年提出双端口双平面组网架构,目前已经应用于HPN-7.0,该架构的目的主要是为了提升性能、增加可靠性、避免哈希极化,这种多轨-双平面的设计模式在ROFT架构基础上,将每个网卡的400G端口拆分成双端口2*200G,分别连接到两个不同的Leaf(图中的ToR交换机)交换机,Leaf交换机下行400G端口被拆分为两条200G链路,连接不同网卡端口。
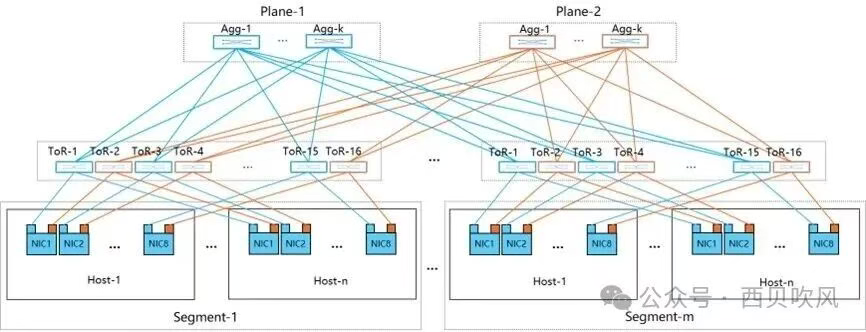
HPN双平面设计具有如下主要特点:
-
消除哈希极化:在传统网络中,大模型训练的低熵、突发流量易导致哈希极化,使流量分布不均。双平面设计将ToR交换机分为两个独立组,流量进入上行链路后路径固定,避免了汇聚层的哈希极化,确保流量均匀分布,显著降低队列长度,提升网络性能;
-
扩展性提升与成本控制:两层组网即可容纳15K以上的GPU,相比传统3层CLOS架构减少一层网络,降低部署成本;
-
增强可靠性与容错能力:GPU双上联连接两个独立ToR交换机,消除单点故障风险;故障时,仅需更新局部ECMP组,无需全局控制器介入,恢复效率提升。上述特点提高了网络的容错能力,保障大模型训练的稳定性。
多平面网络架构
2025年5月,DeepSeek团队发表的文章(Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures),参见https://www.arxiv.org/pdf/2505.09343,其中,提出了多平面组网理念,随着LLM(大型语言模型)参数规模的指数级增长,传统的三层胖树CLOS拓扑在成本、可扩展性和鲁棒性方面逐渐暴露出局限性。
DeepSeek-V3采用基于IB的多平面两层胖树网络(Multi-Plane Fat-Tree,MPFT)替代传统的三层胖树架构,该架构下,每个节点配备8块GPU和8个400Gbps IB NIC,每块GPU对应一个独立的IB NIC,属于不同的“网络平面”(Plane),每个节点8块GPU卡对应连接到8个不同的Plane(即8个两层胖树平面)。交换机采用64 x 400G的IB交换机,在两层胖树网络架构情况下,可以最大接入16,384个GPU(一个Plane包括32个Spine和64个Leaf,可以接入64 x 32个GPU,一共8个平面16,384个GPU),从而实现两层万卡集群,涉及跨平面流量交换时,必须通过节点内转发(Intra-node forwarding)。
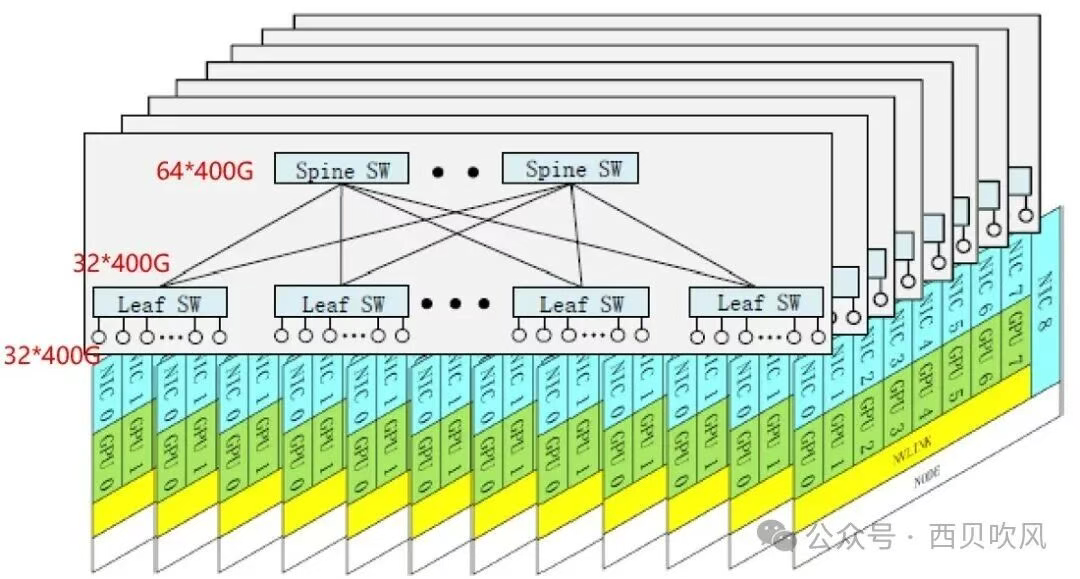
这种多平面组网模式的优点与双平面组网类似,唯一的区别是每个GPU是单上行连接到独立的平面,不具备单卡双上行的容错能力:
-
成本更低:相比三层胖树架构,MPFT可节省高达40%的网络成本;
-
更高的可扩展性:理论上支持最多16,384个GPU;
-
流量隔离:每个平面独立运行,避免跨平面拥塞。
论文中对几种组网模式进行了比较(FT2-两层胖树架构、MPFT-多平面胖树架构、FT3-三层胖树架构、SF-Slim Fly架构、DF-Dragonfly架构):
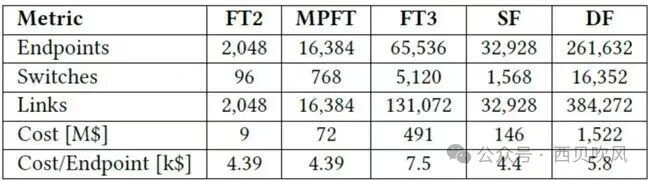
由此可以看出MPFT在每节点成本、扩展性等方面存在明显的优势。
但是,上面的这种MPFT并非最佳的实现模式,比较理想的多平面组网模式如下图所示:

每块网卡配备多个物理端口(这里是4个200G接口),每个端口连接至独立的网络平面(类似阿里云HPN7.0的双平面的模式,只不过HPN7.0是每块网卡2个接口)。单个QP(Queue Pair)可同时利用所有可用端口进行数据包收发。
我们把这个多平面部署图的局部放大细化,如下图所示:
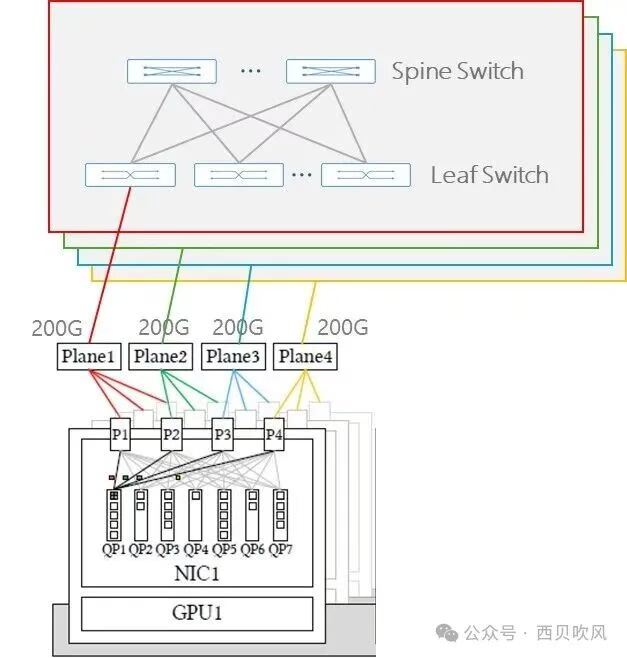
这里以102.4T交换机为例,提供128个800G端口或通过Shuffle提供512个200G(关于Shuffle我们将在后续的专题中加以详细介绍,如果采用Shuffle内置的话,交换机可以直接提供512个200G的链路,也可以采用外置Shuffle Box或Breakout Shuffle的模式进行光纤链路分配和映射),每个GPU通过4个200G的分别连接到4个不同Plane平面,用一个QP驱动4个port,进行逐包负载均衡选路,这种模式对MoE all-to-all流量更友好。
详细组网如下图所示:
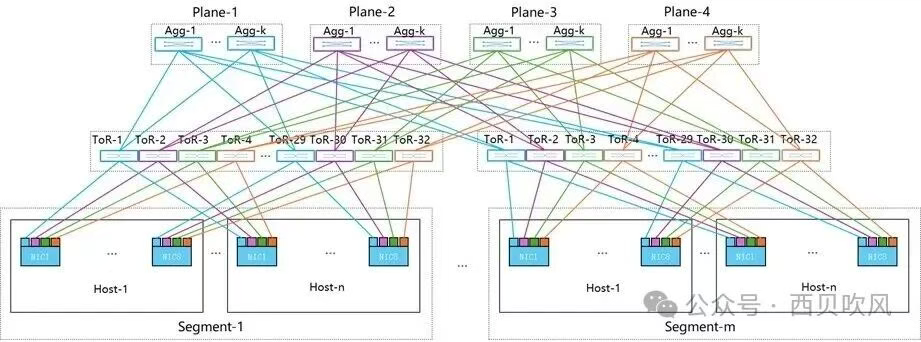
在两层4平面组网下,也可以实现16,384个GPU的接入(需要注意的是,此时由于每个网卡实际接入了4个200G的端口,因此,两层4平面组网下的交换机数量也有所增加,需要1,024个Spine和2,048个Leaf,是单端口MPFT组网交换机数量768的4倍)。
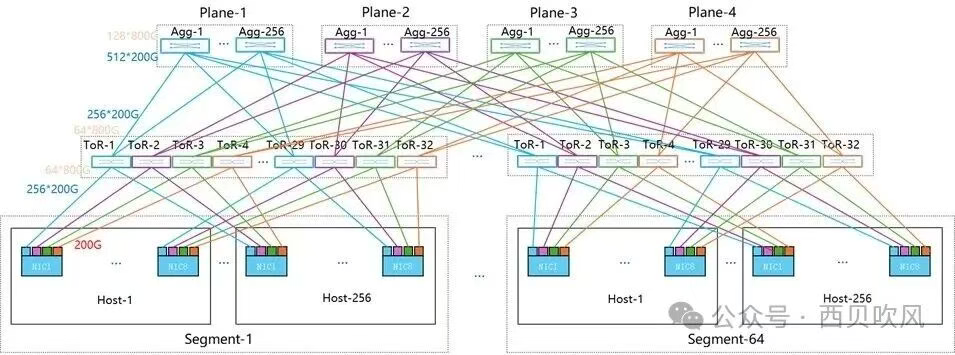
另外,为了实现上述功能,对网卡方面也提出了新的要求,需要网卡支持多平面通信,可以实现QP数据包在多个平面上的负载均衡,另外,由于数据包通过不同平面到达时存在乱序的情况,这就要求网卡能够原生支持乱序处理功能。
当前英伟达的最新CX-8已原生支持4个网络平面(4-Plane),可以在一个QP上实现多路径数据包喷洒(multi-path packet spraying),并支持硬件级乱序包处理,确保数据一致性。
综上,在Scale Out组网扩展方面,三层组网变二层组网、二层万卡/十万卡、多端口多平面组网可能是未来一段时间的发展大趋势。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)