四足机器狗代码学习__Lite3_rl_deploy-main
继承自StateBase维护机器人观测状态(如 IMU、关节数据)异步执行强化学习策略并生成控制指令处理状态进入 / 退出逻辑安全检查(防止机器人姿态失控)通过异步线程周期性执行强化学习策略:主循环(Run())负责更新机器人观测数据,策略线程()根据观测数据和降频参数生成控制指令,同时通过安全检查确保机器人不会因姿态异常失控。整个流程实现了强化学习策略从观测到控制指令的闭环执行。
一、具体框架
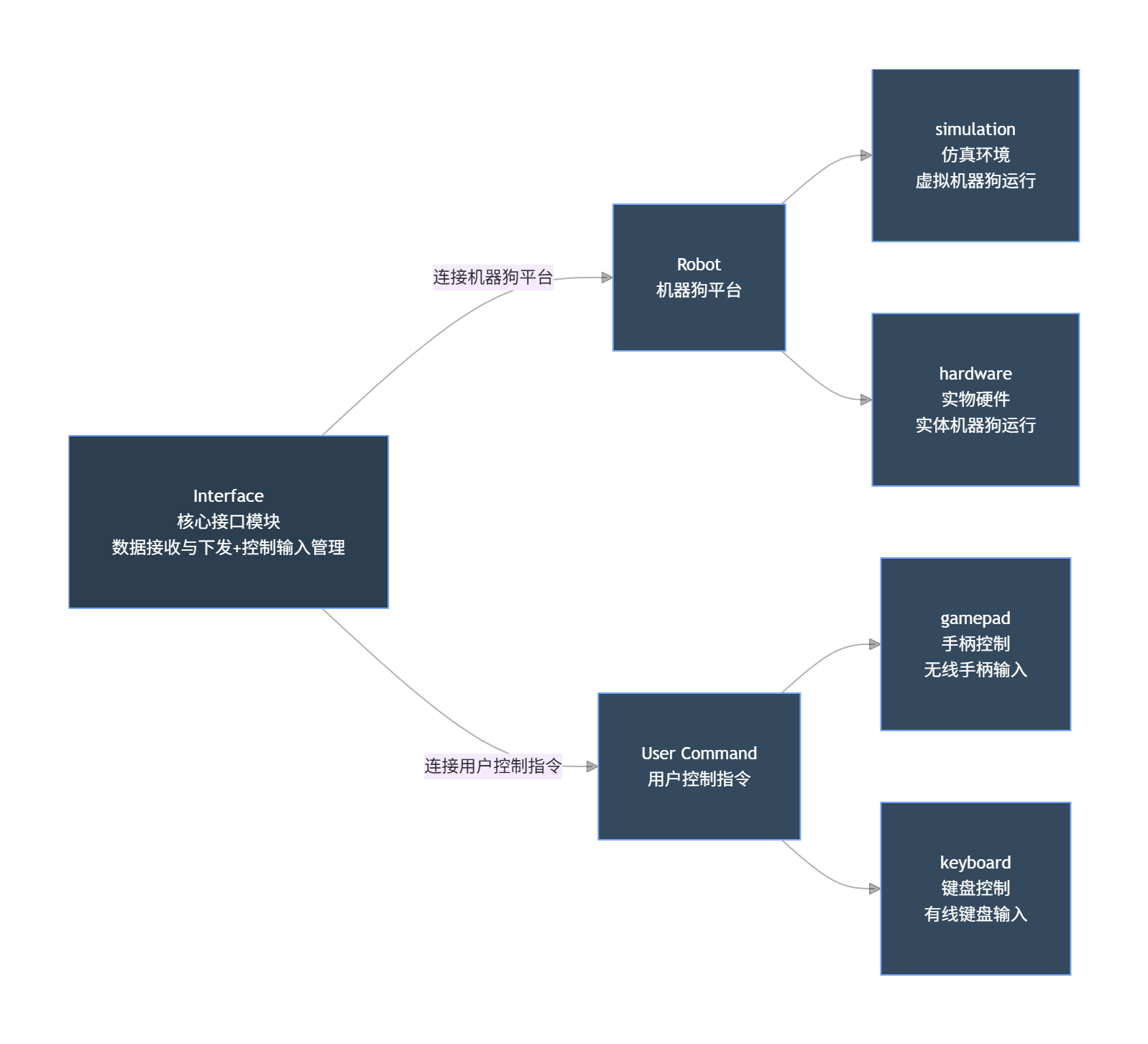
- interface 模块:以
Interface为核心,上连机器狗运行平台(Robot,分仿真 / 实物),下连用户控制输入(User Command,分手柄 / 键盘),清晰展示数据交互的层级和渠道。
std::shared_ptr<UserCommandInterface> uc_ptr_; //User Command用户控制指令

std::shared_ptr<RobotInterface> ri_ptr_; //Robot 机器狗平台
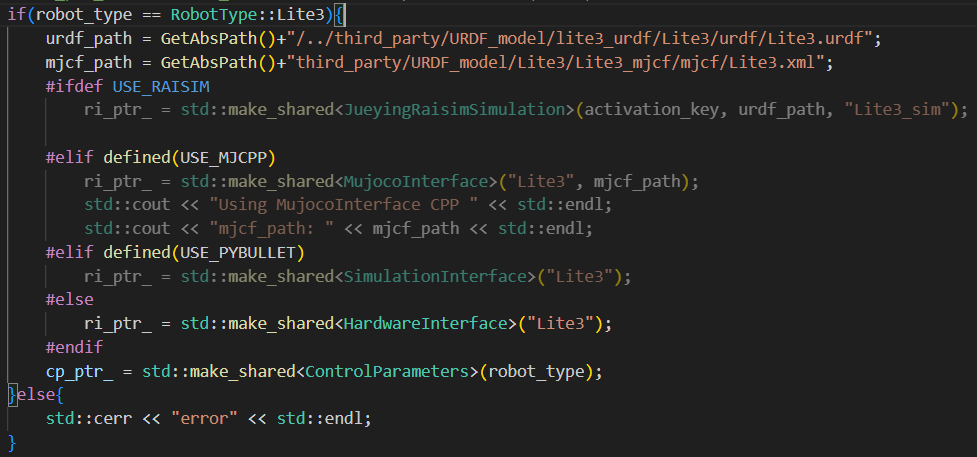
这是个基于状态机用来进行各个状态调用的框架,用来继承方式对各个状态进行切换和跳出:
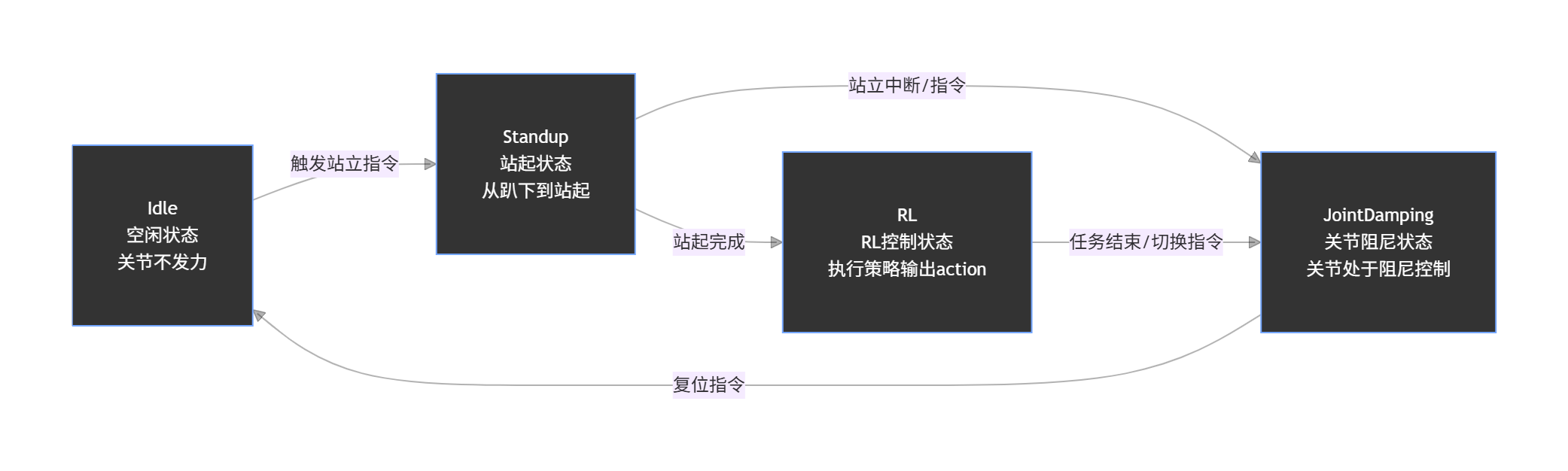
- 状态节点:每个节点包含状态名称(如 Idle)、中文描述及核心功能,直观区分各状态作用。
- 转换关系:
- 空闲状态(Idle)通过 “触发站立指令” 切换至站起状态(Standup);
- 站起状态(Standup)完成后进入 RL 控制状态(RL),也可因 “站立中断” 或直接指令切换至关节阻尼状态(JointDamping);
- RL 控制状态(RL)在 “任务结束” 或切换指令下进入关节阻尼状态(JointDamping);
- 关节阻尼状态(JointDamping)通过 “复位指令” 回到空闲状态(Idle)。
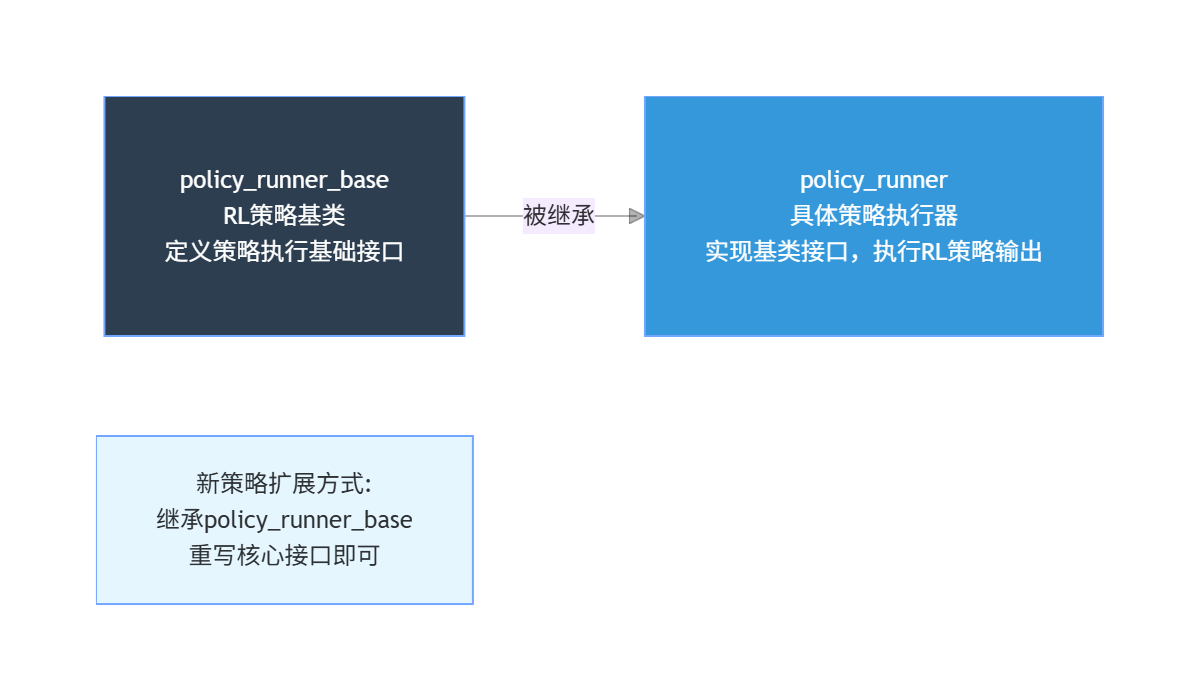
二、模块解析
A)state_machine:
a.1)paramaters:
state_machine/parameters
- 功能:定义 Lite3 机器人的控制参数初始化逻辑,为状态机提供物理参数和控制增益。
- 核心内容:
- 函数
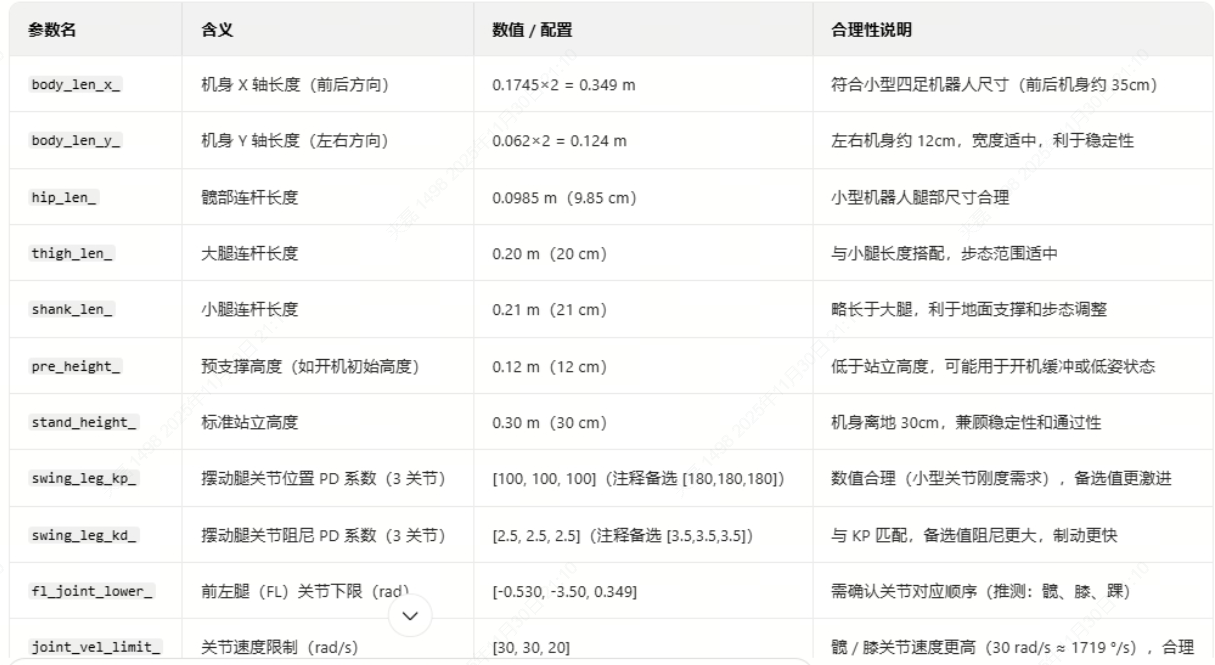
GenerateLite3Parameters:初始化机器人的物理参数和控制参数,包括:- 身体尺寸:
body_len_x_(身体前后长度)、body_len_y_(身体左右宽度)。 - 肢体长度:
hip_len_(髋部长度)、thigh_len_(大腿长度)、shank_len_(小腿长度)。 - 高度参数:
pre_height_(预备高度)、stand_height_(站立高度)。 - 控制增益:
swing_leg_kp_(摆动腿比例增益)、swing_leg_kd_(摆动腿微分增益)。 - 关节限制:
fl_joint_lower_/fl_joint_upper_(前左腿关节角度上下限)、joint_vel_limit_(关节速度限制)、torque_limit_(关节扭矩限制)
- 身体尺寸:
a.2)state_base.h
- 功能:定义状态机的基础状态类
StateBase,作为所有具体状态(如空闲、站立、RL 控制等)的基类,统一接口规范。 - 核心内容:
ControllerData结构体:封装机器人控制所需的核心接口指针,包括:- 机器人接口(
ri_ptr)、用户命令接口(uc_ptr)、控制参数(cp_ptr)、数据流(ds_ptr)。
- 机器人接口(
StateBase类:- 纯虚函数(接口):
OnEnter(进入状态时执行)、OnExit(退出状态时执行)、Run(状态运行时的主逻辑)、LoseControlJudge(判断是否失控)、GetNextStateName(获取下一个状态名)。 - 成员变量:状态名(
state_name_)、机器人类型(robot_type_)、核心接口指针(继承自ControllerData)、静态运动状态反馈(msfb_,记录机器人当前运动状态)。
- 纯虚函数(接口):
a.3)state_machine.hpp
- 功能:实现状态机核心逻辑,管理各状态的创建、切换和运行,是机器人状态控制的中枢。
- 核心内容:
StateMachine类:- 私有成员:各状态控制器指针(
idle_controller_、standup_controller_等)、当前 / 下一个状态名、核心接口指针(机器人接口、用户命令接口等)。 - 构造函数:根据机器人类型(如 Lite3)初始化接口(物理接口或仿真接口)、创建各状态实例,并默认进入
idle状态。 Run方法:状态机主循环,执行当前状态的Run逻辑,检查状态切换条件(通过LoseControlJudge和GetNextStateName),并处理状态切换(调用OnExit和OnEnter)。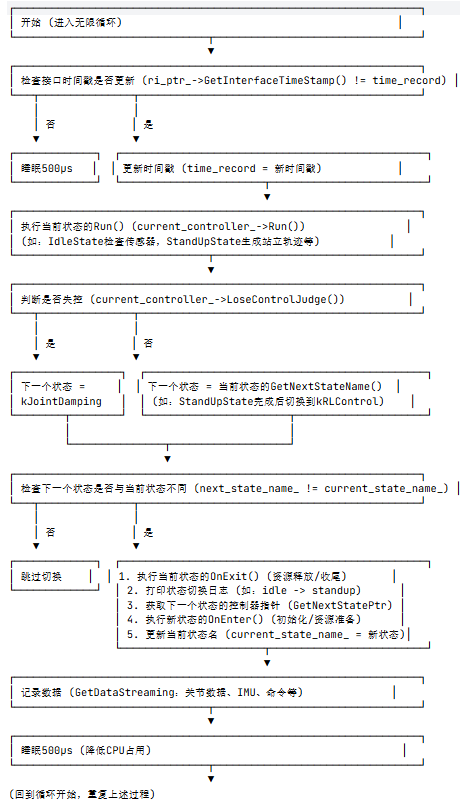
- 私有成员:各状态控制器指针(
其中失控判断:调用当前状态的 LoseControlJudge(),若返回 true(如机器人姿态失衡、收到紧急指令),强制切换到关节阻尼状态(kJointDamping,被动缓冲,保护机器人)
-
-
- 辅助函数:
GetNextStatePtr(根据状态名获取状态指针)、GetDataStreaming(记录并发送关节位置,速度,力矩、IMU6轴信息、命令等数据)。
命令:
- 辅助函数:
-
现在即一个个状态看下这个框架内容:
a.4)rl_control_state.hpp
1. 类定义与核心作用
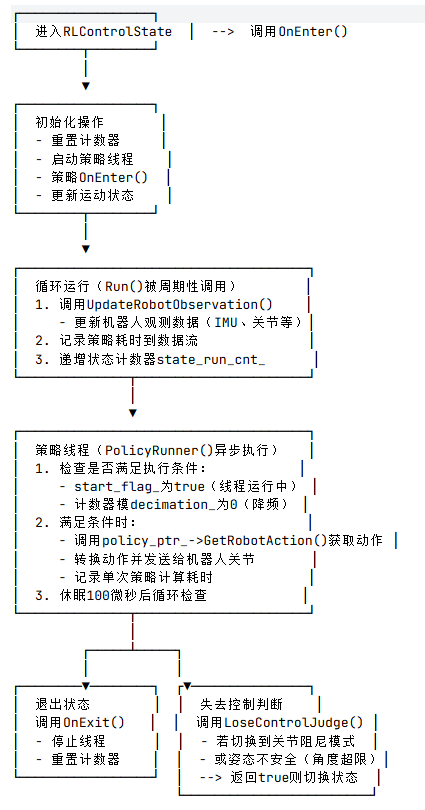
RLControlState 继承自 StateBase,是机器人强化学习(RL)控制模式的状态类,负责:
- 维护机器人观测状态(如 IMU、关节数据)
- 异步执行强化学习策略并生成控制指令
- 处理状态进入 / 退出逻辑
- 安全检查(防止机器人姿态失控)
2. 私有成员变量
| 变量名 | 作用 |
|---|---|
rbs_ |
存储机器人基本观测状态(RobotBasicState类型),包括姿态、关节数据、指令速度等 |
state_run_cnt_ |
状态运行计数器,用于配合降频参数控制策略执行频率 |
policy_ptr_ |
策略运行器基类智能指针(多态),指向具体策略(如Lite3TestPolicyRunner) |
test_policy_ |
具体的测试策略实例(Lite3TestPolicyRunner),是policy_ptr_的实际指向对象 |
run_policy_thread_ |
异步执行策略的线程,避免策略计算阻塞主控制流程 |
start_flag_ |
线程控制标志(true表示运行,false表示停止) |
policy_cost_time_ |
记录单次策略计算的耗时(毫秒),用于性能监控 |
3. 私有成员函数
UpdateRobotObservation()
- 功能:更新机器人观测数据到
rbs_中,是策略输入的核心数据来源。 - 具体操作:
- 从硬件接口(
ri_ptr_)获取 IMU 数据(姿态base_rpy、旋转矩阵base_rot_mat、角速度base_omega、加速度base_acc) - 获取关节数据(位置
joint_pos、速度joint_vel、扭矩joint_tau) - 从用户命令接口(
uc_ptr_)获取归一化的控制指令(前进 / 侧向 / 转向速度cmd_vel_normlized)
- 从硬件接口(
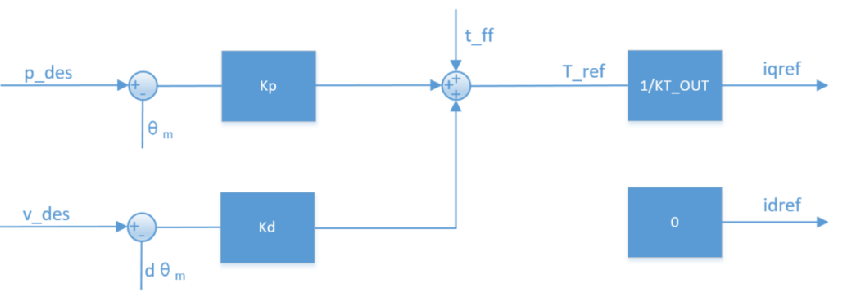
PolicyRunner()
- 功能:策略执行的核心线程函数,异步生成控制指令并发送给机器人。
- 执行逻辑:
- 循环检查
start_flag_(线程是否需要运行) - 当
state_run_cnt_ % policy_ptr_->decimation_ == 0时(满足降频条件,控制策略执行频率):- 记录开始时间,调用
policy_ptr_->GetRobotAction(rbs_)获取策略输出的机器人动作(ra) - 将动作转换为矩阵(
ConvertToMat()),并通过ri_ptr_->SetJointCommand(res)发送给关节 - 记录结束时间,计算并更新
policy_cost_time_(单次策略耗时)
- 记录开始时间,调用
- 每次循环休眠 100 微秒(降低 CPU 占用)
- 循环检查
4. 公共成员函数
在构造函数 RLControlState(...)
- 初始化
rbs_为零值 - 创建
Lite3TestPolicyRunner实例(test_policy_),并赋值给policy_ptr_(多态绑定) - 检查策略是否初始化成功,失败则退出程序
- 调用
policy_ptr_->DisplayPolicyInfo()显示策略信息
OnEnter()
- 状态进入时的初始化操作:
- 重置计数器
state_run_cnt_为 - 1,设置start_flag_为true - 启动
run_policy_thread_线程(绑定PolicyRunner函数) - 调用策略的
OnEnter()(策略自身的初始化) - 更新机器人运动状态为
RLControlMode,并反馈给用户命令接口
- 重置计数器
OnExit()
- 状态退出时的清理操作:
- 设置
start_flag_为false(停止策略线程) - 等待线程结束(
run_policy_thread_.join()) - 重置计数器
state_run_cnt_为 - 1
- 设置
Run()
- 状态运行时的周期性操作(被主控制循环调用):
- 调用
UpdateRobotObservation()更新观测数据 - 将策略耗时
policy_cost_time_记录到数据流(ds_ptr_->InsertScopeData,用于监控) - 递增计数器
state_run_cnt_
- 调用
LoseControlJudge()
- 判断是否需要退出 RL 控制状态:
- 若用户命令目标模式为
JointDamping(关节阻尼模式),返回true(需要切换状态) - 否则调用
PostureUnsafeCheck()检查姿态安全性,返回结果
- 若用户命令目标模式为
PostureUnsafeCheck()
- 姿态安全检查:
- 获取 IMU 的姿态角(
rpy) - 若翻滚角(
rpy(0))绝对值 > 30° 或俯仰角(rpy(1))绝对值 > 45°,判定为不安全(返回true),否则返回false
- 获取 IMU 的姿态角(
GetNextStateName()
- 返回当前状态的下一个状态名称(默认仍为
kRLControl,即保持当前状态)
核心逻辑总结
RLControlState通过异步线程周期性执行强化学习策略:主循环(Run())负责更新机器人观测数据,策略线程(PolicyRunner())根据观测数据和降频参数生成控制指令,同时通过安全检查确保机器人不会因姿态异常失控。整个流程实现了强化学习策略从观测到控制指令的闭环执行。
a.4)joint_damping_state.hpp
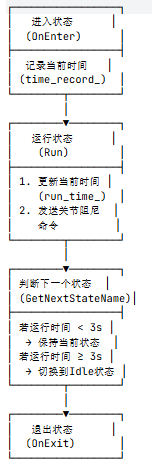
1.构造函数中
JointDampingState(const RobotType& robot_type, const std::string& state_name,
std::shared_ptr<ControllerData> data_ptr):StateBase(robot_type, state_name, data_ptr){
VecXf kd_ = cp_ptr_->swing_leg_kd_.replicate(4, 1);
joint_cmd_ = MatXf::Zero(12, 5);
joint_cmd_.col(2) = kd_;
}- 初始化父类
StateBase,传入机器人类型、状态名称和控制数据指针(包含机器人接口、用户命令接口等)。 - 从控制参数(
cp_ptr_)中获取单腿的阻尼系数(swing_leg_kd_),并复制 4 次(适配 4 条腿共 12 个关节),得到 12 个关节的阻尼系数kd_。 - 初始化关节命令矩阵
joint_cmd_为全零,然后将第 2 列(索引 2,对应阻尼系数 Kd)设置为kd_,其他参数(如刚度 Kp、目标位置等)保持为 0。
2.状态运行
virtual void Run() {
run_time_ = ri_ptr_->GetInterfaceTimeStamp();
ri_ptr_->SetJointCommand(joint_cmd_);
}- 实时更新当前时间
run_time_(从机器人接口获取时间戳)。 - 通过机器人接口(
ri_ptr_)发送关节命令joint_cmd_,实现阻尼控制。由于命令中仅设置了阻尼系数(Kd),关节会根据当前速度产生阻力( torque = -Kd * 速度 ),减缓运动,起到缓冲保护作用。
3.下一个状态判断方法(GetNextStateName)
virtual StateName GetNextStateName() {
if(run_time_ - time_record_ < 3.){
return StateName::kJointDamping;
}
return StateName::kIdle;
}- 若状态持续时间(
run_time_ - time_record_)小于 3 秒,保持当前关节阻尼状态(kJointDamping)。 - 若持续时间超过 3 秒,自动切换到空闲状态(
kIdle),等待用户进一步指令。
核心逻辑总结
JointDampingState 是机器人的 “安全保护状态”,主要用于以下场景:
- 其他状态(如站立、强化学习控制)判断机器人失控时(如姿态失衡),会切换到该状态,通过关节阻尼减缓运动,避免机械结构受损。
- 状态持续 3 秒后自动回到空闲状态,确保机器人在短暂保护后恢复到可操作状态。
其核心逻辑是通过设置关节阻尼系数,让关节产生被动阻力,实现 “缓冲保护” 功能

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)