AIOPS如何落地实践?
数据采集与聚合(Data Collection & Aggregation)支持多源异构数据(日志、指标、链路追踪、告警、工单、配置项等)的统一接入。数据标准化与上下文关联(如将日志与服务拓扑关联)。实时流处理(Streaming Telemetry Processing)对高吞吐、低延迟的监控数据进行实时处理(如 Kafka + Flink 架构)。机器学习与模式识别(Machine Learn
AIOPS(Artificial Intelligence for IT Operations,智能运维)是由Gartner于2016年提出的概念,指将人工智能(AI)、机器学习(ML)、大数据分析等技术应用于IT运维(IT Operations)领域,以提升系统可观测性、自动化水平和故障响应效率。其核心目标是实现从“被动响应”到“主动预测与自愈”的运维范式转变。
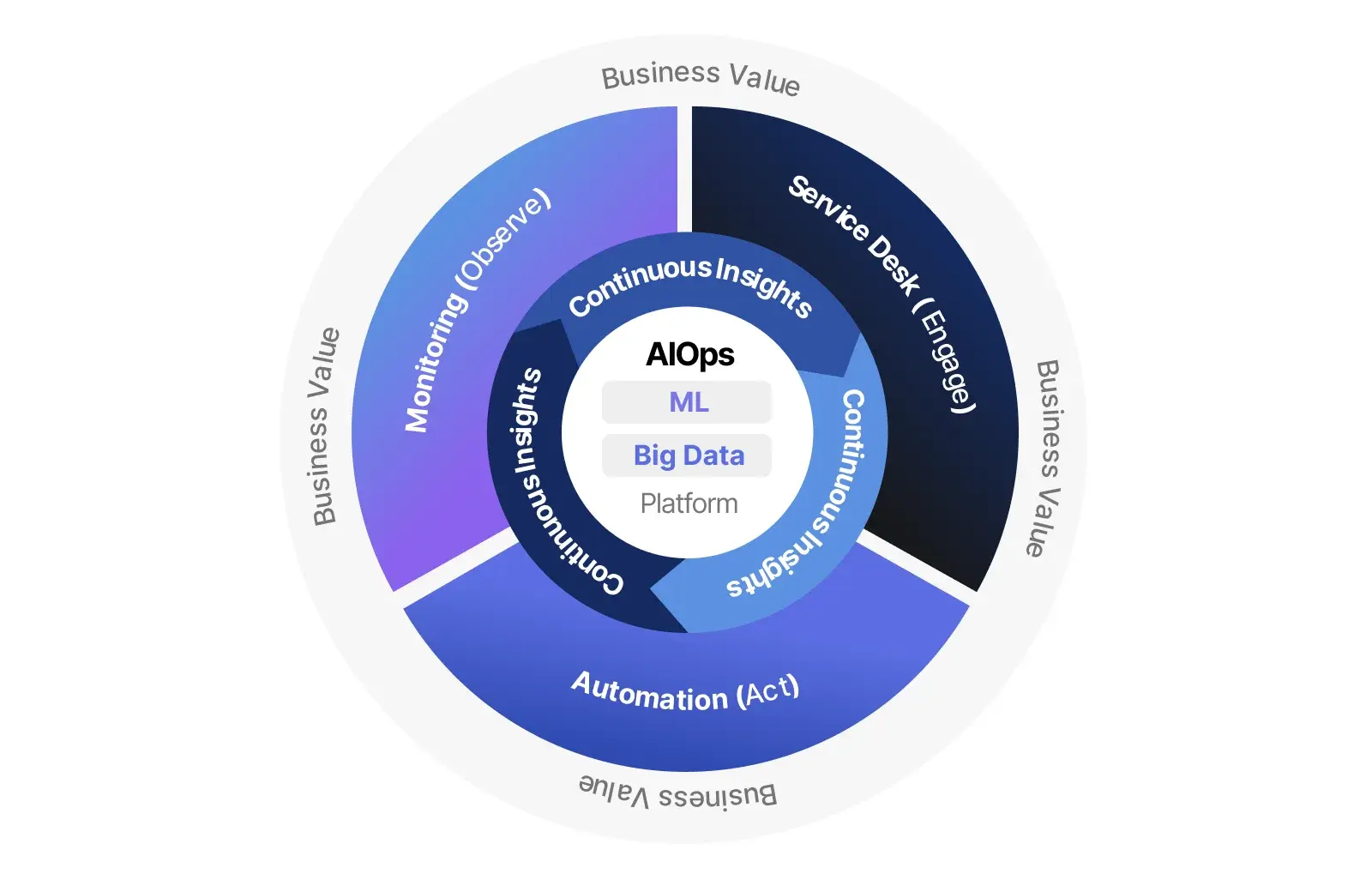
一、AIOPS 的定义与核心能力(严格依据 Gartner 及行业共识)
根据 Gartner 定义,AIOPS 平台应具备以下五大核心能力:
-
数据采集与聚合(Data Collection & Aggregation)
- 支持多源异构数据(日志、指标、链路追踪、告警、工单、配置项等)的统一接入。
- 数据标准化与上下文关联(如将日志与服务拓扑关联)。
-
实时流处理(Streaming Telemetry Processing)
- 对高吞吐、低延迟的监控数据进行实时处理(如 Kafka + Flink 架构)。
-
机器学习与模式识别(Machine Learning & Pattern Recognition)
- 异常检测(Anomaly Detection):如基于时间序列的动态基线。
- 根因分析(Root Cause Analysis, RCA):通过依赖图或因果推理定位故障源头。
- 趋势预测(Forecasting):预测资源瓶颈或服务退化。
-
自动化响应(Automated Response)
- 触发预定义剧本(Playbook)或工作流(如自动扩容、重启容器、隔离故障节点)。
- 与 ITSM(如 ServiceNow)、ChatOps(如 Slack/钉钉机器人)集成。
-
可视化与协作(Visualization & Collaboration)
- 提供可解释的 AI 决策依据(如异常点标注、影响范围图)。
- 支持 SRE 团队协同诊断。
注:AIOPS 不等于“用 Python 跑个模型”,而是工程化、产品化的智能运维体系。
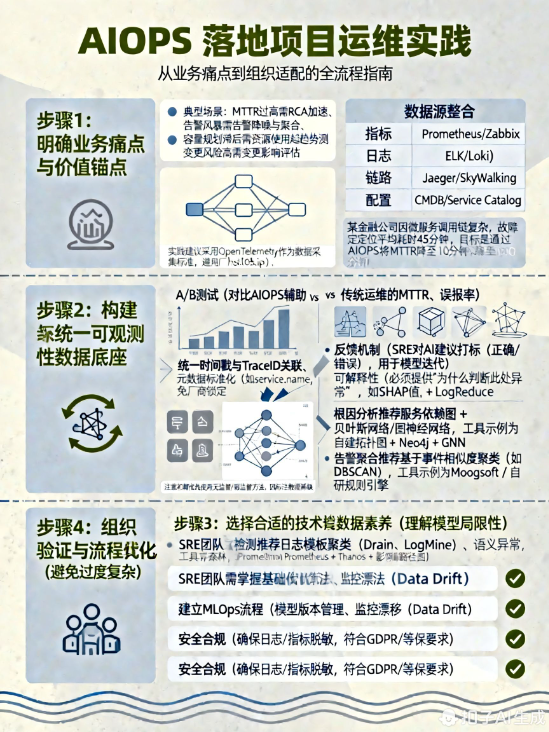
二、AIOPS 落地项目运维实践
步骤 1:明确业务痛点与价值锚点
避免“为 AI 而 AI”。典型场景包括:
- MTTR(平均修复时间)过高 → 需 RCA 加速
- 告警风暴(Alert Storm)→ 需告警降噪与聚合
- 容量规划滞后 → 需资源使用趋势预测
- 变更风险高 → 需变更影响评估
示例:某金融公司因微服务调用链复杂,故障定位平均耗时 45 分钟。目标:通过 AIOPS 将 MTTR 降至 10 分钟内。
步骤 2:构建统一可观测性数据底座
- 数据源整合:
- 指标:Prometheus / Zabbix
- 日志:ELK / Loki
- 链路:Jaeger / SkyWalking
- 配置:CMDB / Service Catalog
- 关键要求:
- 统一时间戳与 TraceID 关联
- 元数据标准化(如 service.name, host.ip)
实践建议:采用 OpenTelemetry 作为数据采集标准,避免厂商锁定。
步骤 3:选择合适的技术栈与算法(避免过度复杂)
| 场景 | 推荐方法 | 工具示例 |
|---|---|---|
| 指标异常检测 | 动态基线(如 Holt-Winters、LSTM)、孤立森林 | Prometheus + Thanos + 自研 ML 模块 |
| 日志异常检测 | 日志模板聚类(Drain、LogMine)、语义异常 | ELK + LogReduce |
| 根因分析 | 服务依赖图 + 贝叶斯网络 / 图神经网络 | 自建拓扑图 + Neo4j + GNN |
| 告警聚合 | 基于事件相似度聚类(如 DBSCAN) | Moogsoft / 自研规则引擎 |
注意:初期优先使用无监督/弱监督方法,因标注数据稀缺。
步骤 4:闭环验证与持续优化
- A/B 测试:对比 AIOPS 辅助 vs 传统运维的 MTTR、误报率。
- 反馈机制:SRE 对 AI 建议打标(正确/错误),用于模型迭代。
- 可解释性:必须提供“为什么判断此处异常”(如 SHAP 值、影响路径图)。
步骤 5:组织与流程适配
- SRE 团队需掌握基础数据素养(理解模型局限性)
- 建立 MLOps 流程:模型版本管理、监控漂移(Data Drift)
- 安全合规:确保日志/指标脱敏,符合 GDPR/等保要求

三、典型落地案例(真实公开信息)
-
阿里巴巴:
- 内部 AIOps 平台“云脑”用于双11大促,实现:
- 自动根因定位(准确率 >85%)
- 故障自愈(如自动回滚发布)
- 技术栈:Flink 实时计算 + 自研图算法 + 大规模日志聚类
- 内部 AIOps 平台“云脑”用于双11大促,实现:
-
Netflix:
- 使用 Atlas(指标系统)+ Vector(主机监控) + 自研异常检测(Robust Seasonal Decomposition)
- 目标:在用户感知前发现视频流质量下降
-
招商银行:
- 基于 AIOPS 实现“智能告警中心”,告警量减少 70%,RCA 时间从小时级降至分钟级
四、常见误区(需警惕)
- ❌ “买一个 AIOPS 产品就能解决问题” → 需深度定制与数据治理
- ❌ “模型准确率 99% 就可用” → 运维场景对召回率和可解释性要求更高
- ❌ 忽视数据质量 → “垃圾进,垃圾出”(Garbage In, Garbage Out)

结论
AIOPS 的本质是以数据驱动、算法赋能、自动化执行为核心的下一代运维体系。其成功落地依赖于:
- 清晰的业务目标对齐
- 高质量的可观测性数据底座
- 合理的技术选型(不盲目追新)
- 工程化闭环与组织协同
最终目标不是取代运维工程师,而是将人力从重复告警中解放,聚焦于架构优化与创新。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)