当AI开始“打工”:深度拆解 Tree456 全系产品的技术脑洞与落地玩法
如果你看到这里,大概率已经被各种名词轰炸过一轮:RAG、GraphRAG、Text2SQL、多模态、知识图谱、模型 API 网关……最后我们把话放回到一个简单的问题上:作为个人或团队,我怎么在这波 AI 浪潮里,既不掉队,也不被忽悠?先从“具体问题”出发,而不是从“技术名词”出发。你每天最耗时间、最机械、最不想干的工作是什么?在 Tree456 的产品里,是否已经有接近的场景可以对上?搭一个“可演
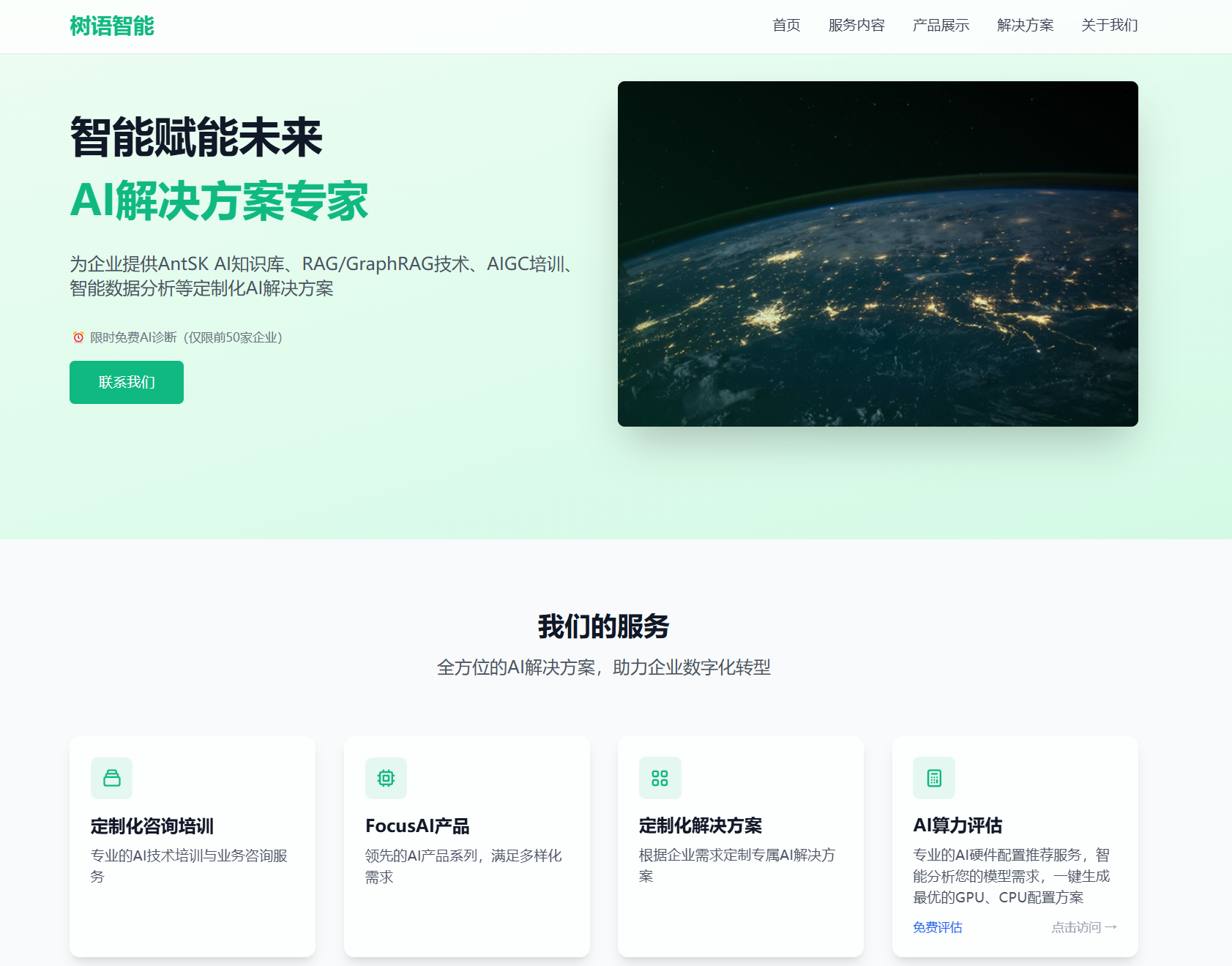
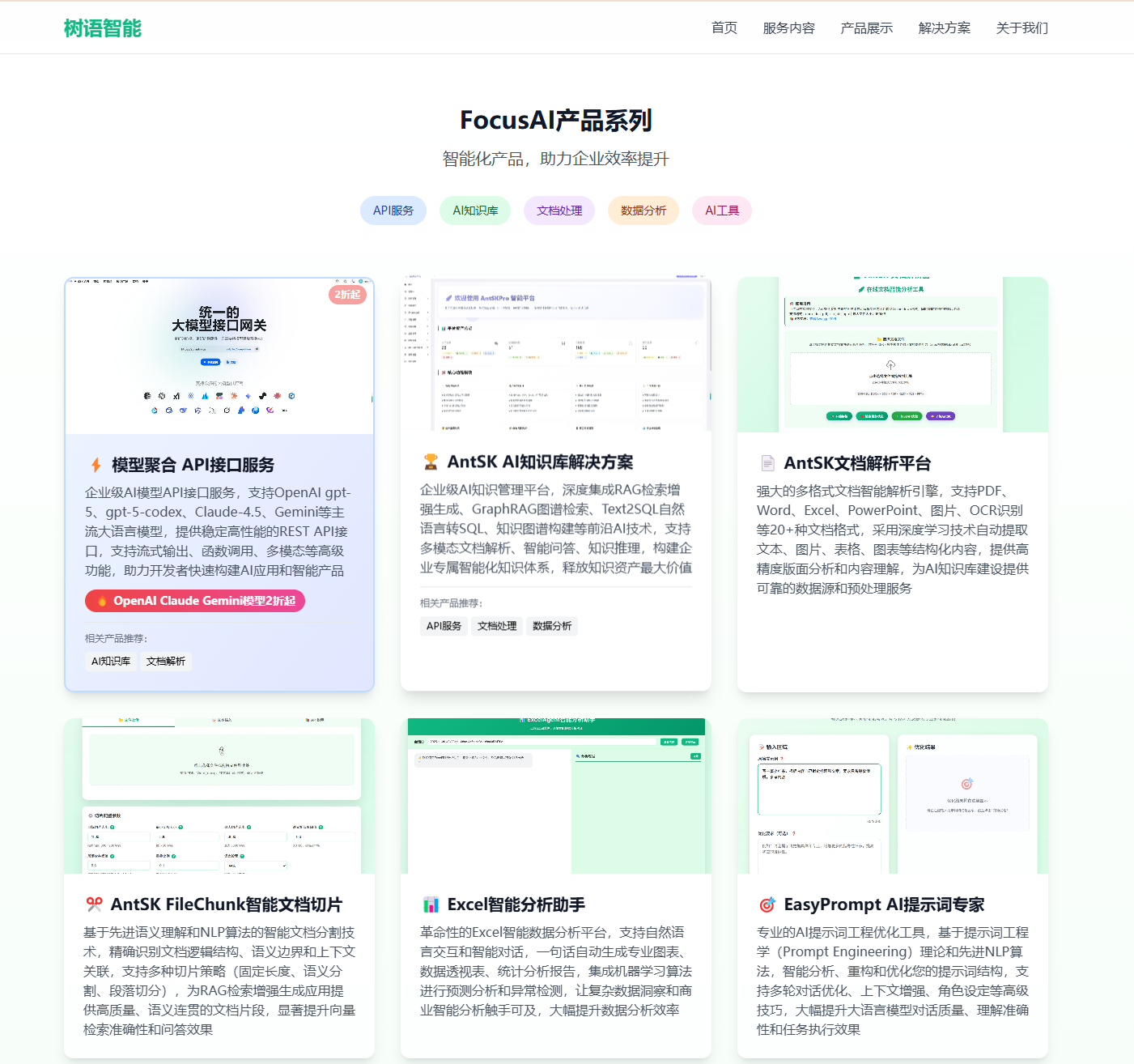
如果说大模型是新时代的“打工人”,那 Tree456 做的事,就是帮企业把这些“打工人”训练好、安排好、管理好,然后让他们每天 7×24 小时不知疲倦地干活。
本文不打算再讲那套「AI 将如何改变世界」的大而空,而是带你扎扎实实扒一扒 Tree456 在官网上列出的这些产品和方案,看看它们到底是怎么落地的、适合谁用、在什么场景能真正省钱省时间、还能少背两口锅。
友情提示:本文偏长(约 4000 字+),适合作为一杯咖啡或一趟地铁的陪读搭子。
一、从“AI 概念股”到“AI 打工人”:Tree456 想解决什么问题?
刷过一圈 AI 相关网站,你很容易产生一种错觉:
-
每个公司都在讲「大模型赋能」;
-
每个产品都说自己能「降本增效」;
-
但真正落地到业务的时候,大家又集体沉默了……
Tree456(武汉树语智能科技)在官网上把自己的定位写得很直接:
「智能赋能未来 · AI 解决方案专家」
结合首页的内容,可以把他们的主战场概括成三件事:
-
帮企业搭好 AI 基建:知识库、RAG/GraphRAG、文档解析、API 等;
-
用 AI 改造具体业务流程:测试、文档对比、数据分析、健康管理等;
-
用项目和培训把能力真正落地:AIGC 培训、行业一体机、定制化项目。
简单说,Tree456 不是在卖一个「单点小工具」,而是围绕企业数字化、智能化,把一整条链路的坑都踩了一遍,然后打包成:
-
一些“开箱即用”的 工具型产品(FocusAI 系列);
-
一套比较完整的 企业级 AI 知识管理与应用底座(AntSK 系列);
-
再加上若干 行业案例和培训体系,证明这玩意儿是真的能跑起来,而不是 PPT。
接下来我们就按产品线,把这些东西拆开聊清楚:
- 上层是各种「看得见摸得着」的业务产品:
-
🧪 测试用例助手
-
📄 DocDiff 文档对比助手
-
🖼️ Gemini 图片生成/分析工具
-
📊 Excel 智能分析助手
-
🎯 EasyPrompt 提示词专家
-
🥗 AI 营养师(企业应用)
-
- 中间是 模型 API 聚合服务:
-
⚡ AntSK 模型聚合 API 接口服务
-
- 底层则是 知识库与数据处理能力:
-
🏆 AntSK AI 知识库解决方案
-
📄 AntSK 文档解析平台
-
✂️ AntSK FileChunk 智能文档切片
-
你可以把这套体系想象成一个“AI 工厂”:
-
文档进厂(解析、切片、建库);
-
知识上架(RAG/GraphRAG、Text2SQL 等);
-
模型排班(多云多模型 API 聚合);
-
业务前台接单(测试、对比、分析、健康等应用)。
下面我们一层一层往下挖。
二、技术架构:从文档到知识,从模型到应用的“四层楼”
虽然官网没有给出完整技术架构图,但从产品列表很容易抽象出一套典型的企业 AI 架构,基本可以分成四层:
1. 数据入口层:文档解析 & 智能切片
代表产品:
-
AntSK 文档解析平台(fileext.antsk.cn) -
AntSK FileChunk 智能文档切片(filechunk.antsk.cn)
解决的是一个几乎所有企业都会遇到的问题:我的知识都在各种乱七八糟的文档里,AI 怎么看得懂?
Tree456 给的答案分两步:
-
先读懂文档长什么样(版面解析):
-
支持 PDF / Word / Excel / PowerPoint / 图片 / OCR 等 20+ 文档格式;
- 不只是简单地“把字识别出来”,而是要分清:
-
哪些是标题、哪些是正文;
-
哪些是表格、哪些是图片说明;
-
页眉页脚、页码之类的“噪音”要过滤掉。
-
-
-
再按语义逻辑切成合适的“知识片段”:
-
支持多种切片策略:固定长度、按段落、按语义边界;
- 重点不是“切多细”,而是“切得刚刚好”:
-
太长:向量检索时不够精确;
-
太短:大模型读完不知道你在说啥。
-
-
这背后常见的技术组合大致是:
-
文档结构分析 + 布局恢复(LayoutLMv3 / DiT / 自研算法等);
-
OCR(对扫描件和图片中的文字);
-
NLP 分句、分段、主题聚类;
-
一些规则与统计特征辅助判断页面元素(如表格边框、字号、缩进等)。
可以想象,大部分企业平时都是这样的数据状态:
网盘里有几个 TB 的 PDF、Word,谁也不知道里面到底写了啥,但所有人都坚信“那里有很多宝贵的知识”。
AntSK 文档解析 + FileChunk 做的,就是把这堆“知识黑盒”拆散、洗干净、装进一个适合 AI 检索和理解的结构化仓库里。
2. 知识与语义层:RAG / GraphRAG / Text2SQL / 知识图谱
代表产品:
-
AntSK AI 知识库解决方案(gw.antsk.cn)
当文档被解析成结构化内容、切成合适的片段之后,第二层要解决的问题就是:
“怎么在大模型面前,既不暴力上全部内容,又能保证回答靠谱且可追溯?”
AntSK 知识库的关键词有几个:
-
RAG(检索增强生成):
-
根据用户问题先做向量检索,找出最相关的文档片段,再给大模型;
- 优点是:
-
数据留在企业侧,安全可控;
-
模型不需要重新训练,更新文档即可生效;
-
回答可给出引用与溯源。
-
-
-
GraphRAG(图谱检索):
- 把知识之间的关系显式建模成图谱:
-
例如:某产品 → 属于哪个线 → 归哪个事业部 → 对应哪些客户;
-
- 适合复杂查询和关系推理:
-
“给我看与产品 X 相关的所有技术文档和典型问题”;
-
“找出最近三个月在两个以上地区暴露过问题的功能模块”。
-
- 把知识之间的关系显式建模成图谱:
-
Text2SQL:
-
自然语言转 SQL,让业务同学也能问数据;
- 典型流程:
-
理解用户问题 → 匹配到对应表结构 → 生成 SQL → 执行 → 结果再自然语言解释。
-
-
这层的关键,不是“用了什么花哨算法”,而是:
-
让知识具备结构与语义两重视角;
-
让业务问题能够以自然语言方式,稳定地落在正确的数据和文档上。
3. 模型与推理层:多模型聚合 API 服务
代表产品:
-
AntSK 模型聚合 API 接口服务(api.antsk.cn)
大模型层的痛点,很多公司已经踩过:
-
供应商多:OpenAI、Claude、Gemini、本地大模型……
-
协议各不相同:请求参数、流式接口、函数调用等都不统一;
-
成本不可控:不同模型、不同供应商,价格和性能差距巨大;
-
合规与稳定性:需要有 fallback 与监控机制。
AntSK API 做的事情,可以理解为一个“模型网关 + 调度层”:
-
对外:暴露统一、稳定的 REST API 接口;
-
对内:可以路由到不同模型供应商与不同模型版本;
- 功能上支持:
-
流式输出
-
函数调用(Tool Calling)
-
多模态(文本 + 图片 + 文件)
-
配额管理、调用统计等(企业常用)。
-
简单画一个伪代码示意(语言用 pseudo-code):
POST /v1/chat/completions
{
"model": "gpt-5-codex", // 逻辑模型名
"messages": [ ... ],
"stream": true,
"tools": [ ... ]
}
// 在 AntSK API 网关内部:
routeRequest(request):
provider = selectProvider(model, tenant, policy)
physicalModel = mapToProviderModel(model, provider)
rewriteRequestForProvider(request, provider, physicalModel)
sendToProvider(provider.endpoint, rewrittenRequest)
handleProviderStreamAndErrors()
returnUnifiedResponseFormat()
这样对上层业务开发者来说:
-
不必被某一家厂商深度锁死;
-
可以按场景灵活切换模型(如测试用便宜模型,核心问答用高质量模型);
-
一套 SDK / 接入方式搞定所有调用场景。
4. 业务应用层:一个个能直接“上手干活”的产品
最上层就是官网上那一长串 FocusAI 应用:
-
🧪 测试用例助手
-
📄 DocDiff 文档对比助手
-
🖼️ Gemini 图片生成 / 分析工具
-
📊 Excel 智能分析助手
-
🎯 EasyPrompt AI 提示词专家
-
🥗 AI 营养师
这些产品的共同点是:
-
都是非常具体的业务场景;
-
都有一个清晰的“输入-输出”闭环;
-
背后都站着前面三层的“基础设施”。
下面我们就逐个拆一下这些产品到底在干嘛,以及适合谁。
三、FocusAI 业务产品:把 AI 塞进真实工作流
1. 🧪 测试用例助手:让大模型帮你写“锅”
一句话定位:
把需求文档丢进去,自动生成一整套功能 / 性能 / 边界测试用例,还能管理和导出 Excel。
1.1 使用方式与典型流程
从官网描述可以梳理出大致流程:
- 上传各种需求文档:
-
Word / PDF / Excel / PPT / 图片 / TXT……
-
- 系统用多模态大模型 + NLP 解析文档:
-
先把内容结构化,变成 Markdown 或结构化需求;
-
- 在结构化需求基础上生成多种类型测试用例:
-
功能测试、边界测试、异常测试、性能测试等;
-
-
支持用例管理与一键导出 Excel。
换句话说,就是把过去“测试工程师拿着文档一条条抠需求写用例”的体力活,尽量交给 AI 来做,再由人工审核与补充。
1.2 技术思路拆解
如果你要自己实现一个简化版,核心可以分三步:
-
文档结构与需求抽取:
rawContent = parseDocument(file) // 文档解析平台 sections = detectSections(rawContent) // 标题、模块、功能点 requirements = extractRequirements(sections) // 用大模型 + 规则过滤出“需求语句” -
测试维度建模与提示词工程:
-
对于每条需求,设计 Prompt 模板:
prompt = { "role": "你是一名资深测试架构师...", "input_requirement": requirement.text, "required_dimensions": ["功能", "边界", "异常", "性能"] } testCases = LLM.generateTestCases(prompt) -
-
结构化与导出:
-
把生成结果约束为结构化 JSON,然后映射到 Excel;
-
一方面方便存库与管理,另一方面方便接入现有测试平台。
-
1.3 适用场景与价值
- 需求文档较为完整、变更频繁的团队:
-
特别是乙方项目、外包项目,需求改一次,理论上用例要改一片;
-
-
测试人力紧张,或希望把更多时间放在探索性测试、自动化脚本上的团队;
-
想要初期快速覆盖大部分“基础用例”,再由测试同学补齐深度场景的团队。
一句不太正经但很真实的总结:
以前是“测试写不完用例背锅”,现在可以是“先让 AI 写一版,再一起优化”,至少锅大了一点,能多分一半给 AI。
2. 📄 DocDiff 文档对比助手:帮你在万字红线里找出那一行变化
一句话定位:
专门对 Word / PDF 文档做智能差异对比,支持字符级 / 句子级 / 段落级,颜色高亮,还能导出结果。
如果你经历过这样的场景:
-
甲方发来《需求文档 v23 最终终稿(真的最终版).docx》;
-
你打开和 v22 对比,只知道“这里那里好像不太一样”;
-
然后在十几页的 Word 里拉来拉去,一边对一边怀疑人生。
那你大概能理解 DocDiff 的爽点在哪里。
2.1 技术要点
普通的 diff 算法(如 LCS)在代码场景很好用,但放到自然语言长文档上会有几个问题:
-
只看字符级,稍微一挪句子位置就一片红绿;
-
对段落级语义变化感知弱;
-
很难和 Word / PDF 的格式结构对上号。
DocDiff 提出的是多粒度对比:
-
字符级:适合找具体数字或关键字变化;
-
句子级:适合同一段落的小修改;
-
段落级:适合看整段移动、增删;
典型流程可能是:
-
文档解析为结构化段落树;
-
对每一层(段落/句子/字符)构建对齐关系;
-
使用编辑距离 + 语义相似度混合判定“是否相同”;
-
生成带标记的差异视图并支持同步滚动。
而对用户来说,这些细节都可以简化成一句话:
“我只想一眼看出这版文档究竟改了哪几处,别让我去当人肉 diff 工具。”
3. 🖼️ Gemini 图片生成/分析:让图片也能参与“对话”
一句话定位:
基于 Google Gemini 的图片分析与生成工具,可上传图片做内容识别、场景理解,也可以用自然语言生成图片。
这类产品的关键价值在于:
- 把「看图说话」这件事交给 AI:
-
对图片中的文字、图表、界面元素进行识别和描述;
-
对视觉内容进行分类、标签化;
-
- 把「脑洞」变成图片:
-
营销、设计同学可以快速出草图;
-
产品经理画原型、交互场景更便捷。
-
和直接用 Gemini API 相比,Tree456 的做法更像是:
-
把复杂的多模态参数和调用过程封装起来;
-
用更友好的 Web 界面和预置场景让“非技术同学”也能用得顺手;
-
同时可以接入前面提到的知识库或 API 网关能力,在企业内网环境下运行。
4. 📊 Excel 智能分析助手:把「会写公式」外包给 AI
一句话定位:
在 Excel 里,用自然语言和表格说话:自动生成专业图表、数据透视表、统计分析报告,甚至做机器学习预测和异常检测。
如果你是程序员,很可能经历过这样的灵魂拷问:
-
“帮我看下这个表,随便做两个分析图。”
而 Excel 智能分析助手的价值就是,让你可以回答:
“你跟 AI 说就行,TA 会帮你搞定的。”
4.1 典型交互方式
-
用户上传或直接在 Excel 中打开数据表;
- 在聊天框里说:
-
“帮我做一个按月份汇总的销售趋势图”;
-
“看一下哪个地区的异常波动比较明显”;
-
“根据历史数据做一个简单的销量预测”;
-
- AI 根据指令:
-
自动识别字段含义与数据类型;
-
选择合适图表类型,生成图表;
-
生成自然语言解读与分析报告。
-
背后通常会包含:
-
对表格的 schema 识别与元数据建模;
-
一套从自然语言到分析任务的映射(NL2BI);
-
简单的统计与机器学习算法封装(如回归预测、聚类等)。
5. 🎯 EasyPrompt 提示词专家:帮你把“我想要”翻译成“模型听得懂”
一句话定位:
专业的提示词工程优化工具,支持对话优化、上下文增强、角色设定等,帮助你系统性地提升大模型对话质量。
当大模型成为基础设施之后,真正的竞争力往往是:
-
你能否稳定、可复现地让模型做对一件事。
EasyPrompt 的存在感就类似于:
-
把“写提示词”这件事,从靠感觉,变成一件有套路、有结构的工程化工作。
典型能力通常包括:
-
对现有 Prompt 进行分析与评分;
-
提出结构化的优化建议;
-
帮你加上必要的约束条件、示例、角色说明;
-
支持多轮对话优化(A/B 测试不同提示词)。
从工程实践看,这类工具特别适合:
-
构建内部 AI 助手(如客服、运维、文档机器人)时,对话行为需要稳定可控的团队;
-
想把“提示词经验”沉淀下来,形成可复用模板与知识库的团队。
6. 🥗 AI 营养师:AI 在垂直行业落地的一个缩影
一句话定位:
基于企业微信生态的智能健康管理应用,结合营养学知识图谱和 AI 算法,做个性化营养建议、膳食搭配、健康监测等。
这个产品乍一看离程序员有点远,但从技术视角看,它是一个非常典型的“垂直领域 AI 应用”模板:
-
知识图谱:把营养学知识结构化,构建食物—营养素—疾病—人群的关系网;
-
个体建模:基于体重、身高、运动量、既往病史、偏好等建立个人画像;
-
推荐引擎:综合知识图谱与个体画像,给出饮食建议与膳食方案;
-
交互界面:嵌入企业微信,接入日常工作流,降低使用门槛。
如果你在考虑做某个垂直行业的 AI 应用(如法务、医疗、制造等),AI 营养师其实提供了一个值得借鉴的落地方向:
不是先想“我能不能搞个自己的大模型”,而是先把:
领域知识结构化;
用户与业务流程建模清楚;
大模型当成一个“推理与对话引擎”嵌进去。
四、AntSK AI 知识库:从“文档坟场”到“活的知识系统”
前面提到的业务产品,大多是站在“具体工作流”的角度去看 AI 的用法。而 AntSK AI 知识库解决方案 更像是整个体系的“大脑和记忆体”。
官网给它的几个关键词非常关键:
-
RAG 检索增强生成
-
GraphRAG 图谱检索
-
Text2SQL 自然语言转 SQL
-
知识图谱构建
-
多模态文档解析
-
智能问答与知识推理
结合前文的数据入口与 API 网关,可以大致画出它的工作流:
文档、表格、图片
↓
文档解析平台(fileext)
↓
FileChunk 语义切片
↓
向量化 + 入库
↓ 结构化业务数据(DB)
RAG / GraphRAG ←────────────┐
↓ │
AntSK 知识库 │
↓ │
智能问答 / Text2SQL ────────┘
在实际项目中,这样的知识库可以被用在很多地方:
- 内部知识问答机器人:
-
员工问“公司年假规定是什么”“这个产品的 SLA 怎么写”;
-
- 外部客服机器人:
-
用户问“某功能怎么用”“如何排查某个错误码”;
-
- 项目交付助手:
-
快速在既往项目文档中检索相似方案;
-
- 管理决策辅助:
-
结合 Text2SQL 做经营数据分析与问答。
-
重点不是“是否用了最前沿的模型”,而是:
能否把过去散落在各处的文档与数据,收拢成一个可以被 AI 持续消费、持续更新、持续沉淀的知识系统。
五、模型聚合 API:给 AI 应用装一个“可换引擎”的底座
AntSK 模型聚合 API 接口服务 在官网上还有一句很关键的话:
「OpenAI、Claude、Gemini 模型 2 折起」
表面上是价格信息,本质上暴露的是这样一种思路:
-
把“和各家模型厂商打交道”的复杂度收敛在一个地方;
-
上层应用只关心模型能力,不关心具体来自谁;
-
可以按业务需求与成本控制策略动态切换模型。
从架构设计上看,这非常像微服务时代的 “Service Mesh” 或数据库层的 “连接池与路由”:
-
对上统一协议、统一认证;
-
对下做多种资源的编排与调度;
-
侧面还可以外挂监控、审计、限流、熔断等能力。
对于在企业内推进 AI 的技术负责人来说,这层能力有两点非常实在:
-
避免过早技术锁定:
-
模型迭代速度比很多人的职业生涯还快;
-
提前留出“可插拔”的空间,是一种健康的工程习惯。
-
-
统一成本与权限管理:
-
不同部门、不同项目可以有不同的模型与配额策略;
-
从一个地方集中看调用量和账单,不用到处对账。
-
六、实际应用案例:游戏、医疗、教育,AI 不只会写代码
官网列出的案例中,有三个代表性行业:
-
大型游戏公司
-
医疗集团
-
教育科技公司
虽然没有披露所有技术细节,但从描述中可以抽象出几种典型模式:
1. AIGC 赋能培训(游戏公司)
关键词:
-
员工 AIGC 技能掌握率 95%
-
工作效率提升 70%+
-
创新项目孵化数量增加 200%
这类项目通常包括:
- 系统性培训:
-
从大模型基础、提示词工程,到各类生产工具(文案、代码、设计等);
-
- 结合企业实际工作流设计“练习任务”:
-
比如:策划同学用 AI 辅助写剧情、关卡设计;
-
程序同学用 AI 辅助重构与代码审查;
-
- 最后沉淀一套内部最佳实践与规范:
-
包括安全、合规、版权等注意事项;
-
以及各岗位的推荐工具与使用 SOP。
-
换个角度说,这是在做一件很现实但常被忽略的事:
“让人真正学会用 AI”,而不仅仅是“给大家开了个账号,你们自己摸索吧”。
2. 医疗 AI 一体机系统(医疗集团)
关键词:
-
医生诊断效率提高 40%
-
患者在线咨询准确率 95%
-
基于大模型技术定制开发
医疗场景的特点是:
-
知识高度专业,更新快;
-
合规与隐私要求极高;
-
错误成本巨大。
在这样的前提下,大模型很难直接“端到端做诊断”,但却非常适合做:
-
医疗知识问答与病历检索;
-
医患沟通辅助(把专业术语翻译成人话,或反之);
-
文书工作自动化(如病历小结、出院记录、随访提醒)。
结合 AntSK 知识库,可以想象这样一个闭环:
-
把指南、规范、病例库结构化,变成可检索的知识库;
-
给医生和患者提供不同界面的问答与辅助;
-
敏感数据与核心决策环节始终在医院内部可控范围内。
3. 教育 AI 一体机系统(教育科技)
关键词:
-
学生满意度提升 50%
-
课程完成率增加 45%
-
教师效率提升 60%
教育行业非常适合用 AI 做:
-
个性化练习与错题分析;
-
教案与课件辅助生成;
-
学情分析与预警;
-
学生问答机器人。
这些场景本质上都是:
把大量重复性知识讲解与题目组织工作,交给 AI 先跑一遍,再由老师做「二次加工与把关」。
这跟前面说的测试、文档、分析等场景,本质上是同一套思路,只是领域知识和业务流程不同而已。
七、如果你是开发/架构/业务负责人,Tree456 能帮你什么?
站在不同角色视角来看这套产品矩阵,会有不同关注点:
1. 对开发/架构师来说
你大概率会关心:
-
是否有统一的接入方式? → 模型聚合 API;
-
企业知识怎么用起来? → 文档解析 + FileChunk + 知识库;
-
能否快速验证业务场景? → FocusAI 现成工具可以先“打样”。
如果你正在搭一套内部 AI 平台,可以借鉴的一个落地顺序是:
-
先搭文档解析与切片 → 把现有文档资产结构化;
-
再建 RAG/GraphRAG 知识库 → 内外部问答先跑起来;
-
同时接入模型聚合 API → 留足未来切换模型的空间;
-
最后围绕具体业务流程(测试、客服、运营等)做垂直应用。
2. 对测试/运维/数据分析等业务团队来说
你更可能关心:
-
有没有现成工具可用,而不是重新搞一套平台?
-
平时 80% 的体力活,AI 能替你干多少?
这时可以重点考虑:
-
测试团队:
测试用例助手 + DocDiff; -
文档密集团队(法务、标书、合同):
DocDiff + 知识库; -
运营/BI 团队:
Excel 智能分析助手 + Text2SQL; -
需要与用户/员工大量交互的团队:知识库 + 聊天机器人方案。
3. 对业务与管理者来说
你会更关心:
-
投入产出比如何?
-
能否在不大幅打乱现有流程的前提下,稳步引入 AI?
Tree456 在官网呈现的一条隐含路线是:
-
从具体的“小点工具”开始(测试、文档、分析);
-
再逐步把知识和数据沉淀进一个统一的 AI 知识库;
-
在这个过程中,通过培训和项目实战把团队 AI 能力抬起来;
-
最终形成一套“人+AI”协同的常态化工作模式。
八、未来趋势:从“有 AI”到“用得好 AI”
看完 Tree456 的产品体系,其实可以顺手聊聊几个未来几年很可能持续强化的趋势:
趋势 1:知识库从“搜索引擎”进化为“业务中枢”
过去很多知识库系统,本质上就是一个高级搜索框:
-
能全文检索,能打标签,能做权限。
而结合大模型之后,知识库正在悄悄变化:
-
既是“记忆体”,也是“推理场”;
-
可以承载越来越多的业务逻辑与决策辅助;
-
与 BI、CRM、工单系统打通后,会变成企业的“第二操作系统”。
AntSK 的 RAG + GraphRAG + Text2SQL 组合,其实就是朝这个方向迈的一大步。
趋势 2:模型多元化与网关化是常态,而非选项
大模型的世界,迭代速度堪比换手机壳:
-
一两年内,主力模型可能会换好几拨;
-
不同国家/行业的合规要求各不相同;
-
私有化、本地化模型的诉求越来越强。
在这种环境下,提前装备一个类似 AntSK API 的“模型网关”,不再是“高级选配”,而会变成:
“就像你现在写代码默认会加个日志系统一样自然”。
趋势 3:垂直行业 AI,从“炫技”转向“精细打磨”
AI 营养师、医疗一体机、教育一体机这些案例都有一个共同点:
-
不再强调“我们用了多大参数的大模型”;
- 而是强调:
-
在这个具体场景里,
-
哪些任务可以放心让 AI 干;
-
哪些环节一定要留给人来拍板;
-
怎么把两者衔接得既顺滑又安全。
-
这背后真正需要的能力,是对行业理解 + AI 工程的双向打磨,而不仅是「会调一个 API」。
九、写在最后:如何不被 AI 潮水淹没?
如果你看到这里,大概率已经被各种名词轰炸过一轮:RAG、GraphRAG、Text2SQL、多模态、知识图谱、模型 API 网关……
最后我们把话放回到一个简单的问题上:
作为个人或团队,我怎么在这波 AI 浪潮里,既不掉队,也不被忽悠?
结合 Tree456 的产品与案例,我会给出三个很务实的建议:
-
先从“具体问题”出发,而不是从“技术名词”出发。
-
你每天最耗时间、最机械、最不想干的工作是什么?
-
在 Tree456 的产品里,是否已经有接近的场景可以对上?
-
-
搭一个“可演化”的基础设施,再慢慢铺场景。
-
文档解析 + 智能切片 + 知识库 + 模型网关,这四件事一旦搭好,
-
之后新增任何 AI 场景,成本都会越来越低。
-
-
别指望 AI 取代所有人,而是尽量让每个人都有一个“AI 副手”。
-
测试有测试助手;
-
产品有文档与对比助手;
-
运营有数据分析助手;
-
管理者有决策与知识检索助手。
-
当 AI 不再是一个“高冷项目”,而是每个人日常打开浏览器时顺手点开的几个小工具,它才真正算是落地。
而 Tree456 正是在做这样一件看似“不那么炸裂”,却足够扎实的事:
用一整套从底层数据处理、知识库管理、模型网关,到上层具体业务应用的体系,
把“大模型时代”的那些宏大愿景,拆解成一个个可以今天就用起来的按钮和界面。
如果你正在思考“我们公司到底该怎么上 AI”,不妨带着你现在最头疼的一个具体流程,去官网上把这些产品多点几下,想象一下:
-
如果这一步交给 AI 做,会省掉多少来回沟通?
-
如果这块知识沉到知识库里,下一个人还会不会再踩同样的坑?
当这些问题有了比较清晰的答案,也许你的 AI 项目就已经悄悄起跑了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)