ICLR2025 源码论文大全集+算法流程图+思维导图+逐篇可视化解读 (Part-2)
访问下述每篇论文的 studyai.com 站点链接即可看到每篇论文的可视化解读以及各个大模型对这篇论文的全方位解读
Decoupled Graph Energy-based Model for Node Out-of-Distribution Detection on Heterophilic Graphs
异质图中基于解耦图能量的节点分布外检测模型
文章解读: 异质图中基于解耦图能量的节点分布外检测模型
http://www.studyai.com/xueshu/paper/detail/5876538239
Q1: 这篇论文的主要内容是什么?
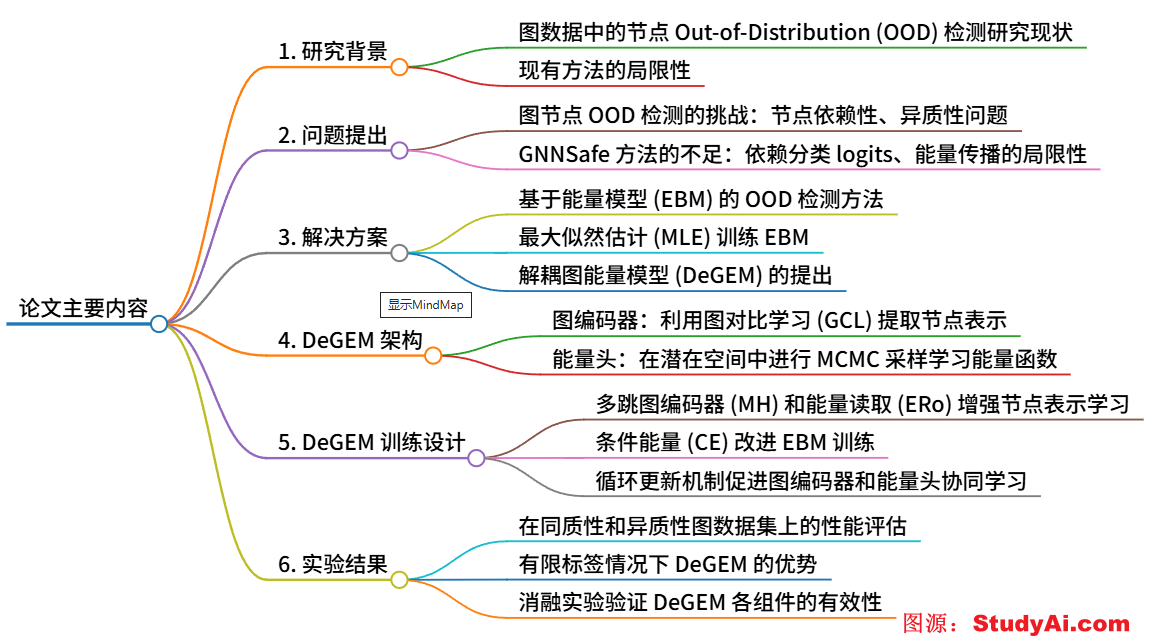
Q4: 这篇论文的主要动机是什么?
- 图数据 OOD 检测的不足:尽管在图像领域关于 Out-of-Distribution (OOD)检测的研究很多,但在图数据节点 OOD 检测方面仍有很大的探索空间。图节点之间的相互依赖性使得直接将图像领域的 OOD 检测方法应用于图数据变得困难。
- 现有方法的局限性:现有的图 OOD 检测方法,如 GNNSafe,虽然考虑了节点依赖性,但存在两个主要问题:一是节点能量是从分类 logits 中推导出来的,没有专门针对数据分布建模进行训练,导致识别 OOD 数据的效果不佳;二是高度依赖于能量传播技术,而能量传播技术基于同质性假设,在异质性图上会导致显著的性能下降。
- 异质性图的挑战:异质性图中,节点的邻居往往具有不同的类别分布,这会导致基于同质性假设的能量传播技术性能大幅下降,而现有的图 OOD 检测方法并未充分考虑到这一点。
- 计算挑战:通过最大似然估计 (MLE) 训练能量模型 (EBM) 需要在节点特征和节点邻居上执行马尔可夫链蒙特卡罗 (MCMC) 抽样,这对于具有复杂拓扑结构的图来说是一个挑战。
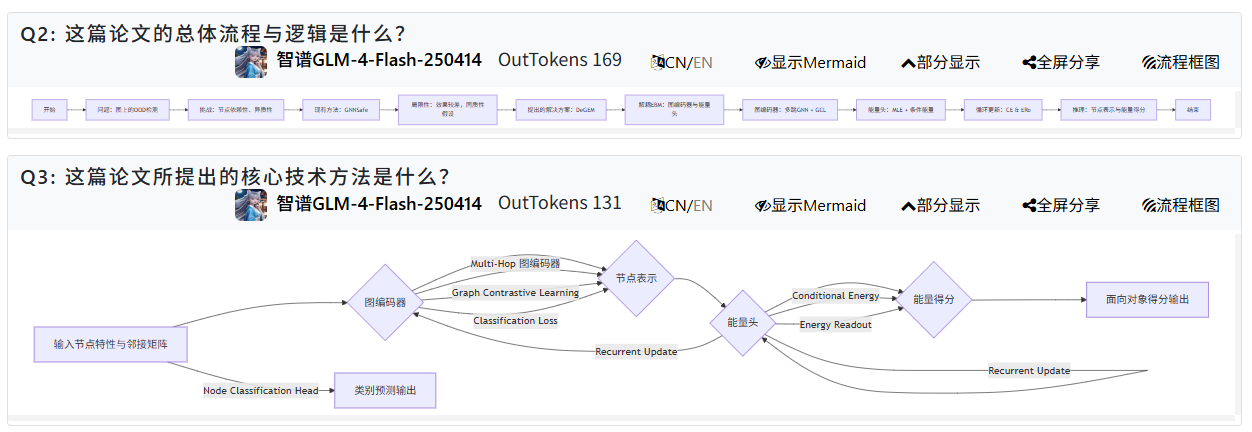
基于以上动机和灵感,论文提出了 Decoupled Graph Energy-based Model (DeGEM) 方法,以解决现有方法的局限性,并克服异质性图上的计算挑战。
Q5: 这篇论文的主要创新点是什么?
- **解耦图能量模型(Decoupled Graph Energy-based Model,DeGEM)**:将图能量模型分解为图编码器和能量头两部分,图编码器用于提取拓扑信息,能量头用于估计密度,避免了在训练时对邻接矩阵进行采样,并防止了在异质图上的性能严重下降。
- 首次在异质图上评估节点异常检测性能:评估了现有基于图的方法在异质图上的性能,并提供了对现有基于图的方法的全面评估。
- 提出多种训练设计:包括多跳图编码器(Multi-Hop Graph encoder,MH)和能量读取(Energy Readout,ERo)来增强节点表示学习,条件能量(Conditional Energy,CE)来改进 EBM 训练,以及循环更新(Recurrent Update)来促进图编码器和能量头相互促进。
- 无异常数据暴露的训练方法:DeGEM 在训练过程中无需异常数据暴露,即可超越最先进的方法,在异质图和同质图上均取得了优异的性能。
Efficient Active Imitation Learning with Random Network Distillation
基于随机网络蒸馏的高效主动模仿学习
文章解读: 基于随机网络蒸馏的高效主动模仿学习
http://www.studyai.com/xueshu/paper/detail/5902711822
UV-Attack: Physical-World Adversarial Attacks on Person Detection via Dynamic-NeRF-based UV Mapping
UV-攻击:基于动态NeRF的UV映射对行人检测的物理世界对抗性攻击
文章解读: UV-攻击:基于动态NeRF的UV映射对行人检测的物理世界对抗性攻击
http://www.studyai.com/xueshu/paper/detail/5905220069
What is Wrong with Perplexity for Long-context Language Modeling?
困惑度在长上下文语言建模中的问题是什么?
文章解读: 困惑度在长上下文语言建模中的问题是什么?
http://www.studyai.com/xueshu/paper/detail/5908313510
VideoGrain: Modulating Space-Time Attention for Multi-Grained Video Editing
VideoGrain:调节时空注意力用于多粒度视频编辑
文章解读: VideoGrain:调节时空注意力用于多粒度视频编辑
http://www.studyai.com/xueshu/paper/detail/5920203908
ReSi: A Comprehensive Benchmark for Representational Similarity Measures
ReSi:表征相似性度量方法的综合基准
文章解读: ReSi:表征相似性度量方法的综合基准
http://www.studyai.com/xueshu/paper/detail/5928728908
Scaling up Masked Diffusion Models on Text
在文本上扩展掩码扩散模型
文章解读: 在文本上扩展掩码扩散模型
http://www.studyai.com/xueshu/paper/detail/5951625278
CogCoM: A Visual Language Model with Chain-of-Manipulations Reasoning
CogCoM:一种基于操作链推理的视觉语言模型
文章解读: CogCoM:一种基于操作链推理的视觉语言模型
http://www.studyai.com/xueshu/paper/detail/5953852989
Self-Correcting Decoding with Generative Feedback for Mitigating Hallucinations in Large Vision-Language Models
具有生成式反馈的自校正解码,用于减轻大型视觉语言模型的幻觉
文章解读: 具有生成式反馈的自校正解码,用于减轻大型视觉语言模型的幻觉
http://www.studyai.com/xueshu/paper/detail/5962910835
CycleResearcher: Improving Automated Research via Automated Review
CycleResearcher:通过自动化评审改进自动化研究
文章解读: CycleResearcher:通过自动化评审改进自动化研究
http://www.studyai.com/xueshu/paper/detail/5973171716
GPS: A Probabilistic Distributional Similarity with Gumbel Priors for Set-to-Set Matching
GPS:基于Gumbel先验的概率分布相似性方法用于集合到集合的匹配
文章解读: GPS:基于Gumbel先验的概率分布相似性方法用于集合到集合的匹配
http://www.studyai.com/xueshu/paper/detail/5975155266
Dualformer: Controllable Fast and Slow Thinking by Learning with Randomized Reasoning Traces
双形式:通过学习随机推理轨迹实现可控的快速和慢速思考
文章解读: 双形式:通过学习随机推理轨迹实现可控的快速和慢速思考
http://www.studyai.com/xueshu/paper/detail/5979113537
Mitigating the Backdoor Effect for Multi-Task Model Merging via Safety-Aware Subspace
通过安全感知子空间缓解多任务模型合并中的后门效应
文章解读: 通过安全感知子空间缓解多任务模型合并中的后门效应
http://www.studyai.com/xueshu/paper/detail/5995021929
RaSA: Rank-Sharing Low-Rank Adaptation
RaSA:秩共享低秩自适应
文章解读: RaSA:秩共享低秩自适应
http://www.studyai.com/xueshu/paper/detail/5999509792
Weighted-Reward Preference Optimization for Implicit Model Fusion
加权奖励偏好优化用于隐式模型融合
文章解读: 加权奖励偏好优化用于隐式模型融合
http://www.studyai.com/xueshu/paper/detail/6001961202
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
RDT-1B:用于双手操作的扩散基础模型
文章解读: RDT-1B:用于双手操作的扩散基础模型
http://www.studyai.com/xueshu/paper/detail/6002897923
Mitigate the Gap: Improving Cross-Modal Alignment in CLIP
缩小差距:改进CLIP中的跨模态对齐
文章解读: 缩小差距:改进CLIP中的跨模态对齐
http://www.studyai.com/xueshu/paper/detail/6006720671
Toward Exploratory Inverse Constraint Inference with Generative Diffusion Verifiers
面向生成扩散验证器的探索性逆约束推理
文章解读: 面向生成扩散验证器的探索性逆约束推理
http://www.studyai.com/xueshu/paper/detail/6013561078
Cross-Embodiment Dexterous Grasping with Reinforcement Learning
基于强化学习的跨本体灵巧抓取
文章解读: 基于强化学习的跨本体灵巧抓取
http://www.studyai.com/xueshu/paper/detail/6050909020
DICE: End-to-end Deformation Capture of Hand-Face Interactions from a Single Image
DICE:从单张图像中实现手-脸交互的端到端变形捕捉
文章解读: DICE:从单张图像中实现手-脸交互的端到端变形捕捉
http://www.studyai.com/xueshu/paper/detail/6052676608
MMIU: Multimodal Multi-image Understanding for Evaluating Large Vision-Language Models
MMIU:多模态多图像理解,用于评估大型视觉语言模型
文章解读: MMIU:多模态多图像理解,用于评估大型视觉语言模型
http://www.studyai.com/xueshu/paper/detail/6068617380
EC-Diffuser: Multi-Object Manipulation via Entity-Centric Behavior Generation
EC-Diffuser:基于实体中心行为生成的多物体操作
文章解读: EC-Diffuser:基于实体中心行为生成的多物体操作
http://www.studyai.com/xueshu/paper/detail/6087188277
MLLM can see? Dynamic Correction Decoding for Hallucination Mitigation
MLLM能看见吗?用于幻觉缓解的动态校正解码
文章解读: MLLM能看见吗?用于幻觉缓解的动态校正解码
http://www.studyai.com/xueshu/paper/detail/6087589225
ADAM: An Embodied Causal Agent in Open-World Environments
ADAM:开放世界环境中的一个具身因果代理体
文章解读: ADAM:开放世界环境中的一个具身因果代理体
http://www.studyai.com/xueshu/paper/detail/6096275088
Navigation-Guided Sparse Scene Representation for End-to-End Autonomous Driving
基于导航引导的稀疏场景表示用于端到端自动驾驶
文章解读: 基于导航引导的稀疏场景表示用于端到端自动驾驶
http://www.studyai.com/xueshu/paper/detail/6103865672
Aria-MIDI: A Dataset of Piano MIDI Files for Symbolic Music Modeling
Aria-MIDI:用于符号音乐建模的钢琴MIDI文件数据集
文章解读: Aria-MIDI:用于符号音乐建模的钢琴MIDI文件数据集
http://www.studyai.com/xueshu/paper/detail/6107556301
Rectified Diffusion: Straightness Is Not Your Need in Rectified Flow
整流扩散:在整流流中,直线并非必需
文章解读: 整流扩散:在整流流中,直线并非必需
http://www.studyai.com/xueshu/paper/detail/6110068282
One-Prompt-One-Story: Free-Lunch Consistent Text-to-Image Generation Using a Single Prompt
单提示单故事:使用单个提示实现免费午餐式文本到图像生成
文章解读: 单提示单故事:使用单个提示实现免费午餐式文本到图像生成
http://www.studyai.com/xueshu/paper/detail/6116889832
Capability Localization: Capabilities Can be Localized rather than Individual Knowledge
能力本地化:能力可以本地化而非个体知识
文章解读: 能力本地化:能力可以本地化而非个体知识
http://www.studyai.com/xueshu/paper/detail/6118266050
Dream to Manipulate: Compositional World Models Empowering Robot Imitation Learning with Imagination
梦想操控:具有想象力的组合世界模型赋能机器人模仿学习
文章解读: 梦想操控:具有想象力的组合世界模型赋能机器人模仿学习
http://www.studyai.com/xueshu/paper/detail/6122599136
CFD: Learning Generalized Molecular Representation via Concept-Enhanced Feedback Disentanglement
CFD:通过概念增强反馈解耦学习广义分子表征
文章解读: CFD:通过概念增强反馈解耦学习广义分子表征
http://www.studyai.com/xueshu/paper/detail/6137871796
Dissecting Adversarial Robustness of Multimodal LM Agents
剖析多模态语言模型代理的对抗鲁棒性
文章解读: 剖析多模态语言模型代理的对抗鲁棒性
http://www.studyai.com/xueshu/paper/detail/6152792787
LeanQuant: Accurate and Scalable Large Language Model Quantization with Loss-error-aware Grid
LeanQuant:基于损失误差感知网格的精确且可扩展的大语言模型量化
文章解读: LeanQuant:基于损失误差感知网格的精确且可扩展的大语言模型量化
http://www.studyai.com/xueshu/paper/detail/6158671262
Subgraph Federated Learning for Local Generalization
本地泛化子图联邦学习
文章解读: 本地泛化子图联邦学习
http://www.studyai.com/xueshu/paper/detail/6160731937
HQGS: High-Quality Novel View Synthesis with Gaussian Splatting in Degraded Scenes
HQGS:在退化场景中基于高斯 splatting 的高质量新颖视图合成
文章解读: HQGS:在退化场景中基于高斯 splatting 的高质量新颖视图合成
http://www.studyai.com/xueshu/paper/detail/6163621328
Learning Molecular Representation in a Cell
在细胞中学习分子表示
文章解读: 在细胞中学习分子表示
http://www.studyai.com/xueshu/paper/detail/6173123700
Equivariant Masked Position Prediction for Efficient Molecular Representation
等变掩码位置预测用于高效的分子表示
文章解读: 等变掩码位置预测用于高效的分子表示
http://www.studyai.com/xueshu/paper/detail/6189353599
A General Framework for Producing Interpretable Semantic Text Embeddings
生成可解释语义文本嵌入的通用框架
文章解读: 生成可解释语义文本嵌入的通用框架
http://www.studyai.com/xueshu/paper/detail/6198335605
Residual Stream Analysis with Multi-Layer SAEs
多层自编码器残差流分析
文章解读: 多层自编码器残差流分析
http://www.studyai.com/xueshu/paper/detail/6209811277
DenseMatcher: Learning 3D Semantic Correspondence for Category-Level Manipulation from a Single Demo
DenseMatcher:从单个演示中学习用于类别级操作的3D语义对应关系
文章解读: DenseMatcher:从单个演示中学习用于类别级操作的3D语义对应关系
http://www.studyai.com/xueshu/paper/detail/6268320726
Visual Haystacks: A Vision-Centric Needle-In-A-Haystack Benchmark
视觉干草堆:以视觉为中心的寻找针于干草堆基准
文章解读: 视觉干草堆:以视觉为中心的寻找针于干草堆基准
http://www.studyai.com/xueshu/paper/detail/6272151051
AutoCGP: Closed-Loop Concept-Guided Policies from Unlabeled Demonstrations
AutoCGP:从无标签演示中获取的闭环概念引导策略
文章解读: AutoCGP:从无标签演示中获取的闭环概念引导策略
http://www.studyai.com/xueshu/paper/detail/6273283867
Test-time Adaptation for Regression by Subspace Alignment
回归测试时自适应通过子空间对齐
文章解读: 回归测试时自适应通过子空间对齐
http://www.studyai.com/xueshu/paper/detail/6278930256
SOO-Bench: Benchmarks for Evaluating the Stability of Offline Black-Box Optimization
SOO-Bench:用于评估离线黑盒优化稳定性的基准测试
文章解读: SOO-Bench:用于评估离线黑盒优化稳定性的基准测试
http://www.studyai.com/xueshu/paper/detail/6286260026
Cross the Gap: Exposing the Intra-modal Misalignment in CLIP via Modality Inversion
跨越鸿沟:通过模态反转揭示CLIP中的模态间不匹配问题
文章解读: 跨越鸿沟:通过模态反转揭示CLIP中的模态间不匹配问题
http://www.studyai.com/xueshu/paper/detail/6286780306
Optimal Transport for Time Series Imputation
时间序列最优传输填充
文章解读: 时间序列最优传输填充
http://www.studyai.com/xueshu/paper/detail/6287227909
Model-Agnostic Knowledge Guided Correction for Improved Neural Surrogate Rollout
模型无关知识引导校正以改进神经代理滚动
文章解读: 模型无关知识引导校正以改进神经代理滚动
http://www.studyai.com/xueshu/paper/detail/6287979066
Competing Large Language Models in Multi-Agent Gaming Environments
多智能体游戏环境中的竞争性大语言模型
文章解读: 多智能体游戏环境中的竞争性大语言模型
http://www.studyai.com/xueshu/paper/detail/6308010819
Noise Separation guided Candidate Label Reconstruction for Noisy Partial Label Learning
基于噪声分离指导的候选标签重建用于噪声部分标签学习
文章解读: 基于噪声分离指导的候选标签重建用于噪声部分标签学习
http://www.studyai.com/xueshu/paper/detail/6309329773
Streamlining Prediction in Bayesian Deep Learning
简化贝叶斯深度学习中的预测
文章解读: 简化贝叶斯深度学习中的预测
http://www.studyai.com/xueshu/paper/detail/6309785158
Diff3DS: Generating View-Consistent 3D Sketch via Differentiable Curve Rendering
Diff3DS:通过可微曲线渲染生成视图一致的3D草图
文章解读: Diff3DS:通过可微曲线渲染生成视图一致的3D草图
http://www.studyai.com/xueshu/paper/detail/6350799819
Multimodal Unsupervised Domain Generalization by Retrieving Across the Modality Gap
跨模态鸿沟检索的多模态无监督域泛化
文章解读: 跨模态鸿沟检索的多模态无监督域泛化
http://www.studyai.com/xueshu/paper/detail/6355128559
Precise Parameter Localization for Textual Generation in Diffusion Models
扩散模型中文本生成的精确参数定位
文章解读: 扩散模型中文本生成的精确参数定位
http://www.studyai.com/xueshu/paper/detail/6357676671
ARB-LLM: Alternating Refined Binarizations for Large Language Models
ARB-LLM:交替精细二值化用于大语言模型
文章解读: ARB-LLM:交替精细二值化用于大语言模型
http://www.studyai.com/xueshu/paper/detail/6367609703
Federated Domain Generalization with Data-free On-server Matching Gradient
基于无服务器数据匹配梯度的联邦域泛化
文章解读: 基于无服务器数据匹配梯度的联邦域泛化
http://www.studyai.com/xueshu/paper/detail/6377071972
Causal Graph Transformer for Treatment Effect Estimation Under Unknown Interference
未知干扰下的治疗效果估计因果图转换器
文章解读: 未知干扰下的治疗效果估计因果图转换器
http://www.studyai.com/xueshu/paper/detail/6377558883
TempMe: Video Temporal Token Merging for Efficient Text-Video Retrieval
TempMe:视频时序令牌合并,用于高效的文本-视频检索
文章解读: TempMe:视频时序令牌合并,用于高效的文本-视频检索
http://www.studyai.com/xueshu/paper/detail/6383797888
Training-free LLM-generated Text Detection by Mining Token Probability Sequences
基于挖掘标记概率序列的无监督LLM生成文本检测
文章解读: 基于挖掘标记概率序列的无监督LLM生成文本检测
http://www.studyai.com/xueshu/paper/detail/6389786836
ImpScore: A Learnable Metric For Quantifying The Implicitness Level of Sentences
ImpScore:一种可学习的度量标准,用于量化句子的隐含程度
文章解读: ImpScore:一种可学习的度量标准,用于量化句子的隐含程度
http://www.studyai.com/xueshu/paper/detail/6392827812
CREAM: Consistency Regularized Self-Rewarding Language Models
CREAM:一致性正则化自奖励语言模型
文章解读: CREAM:一致性正则化自奖励语言模型
http://www.studyai.com/xueshu/paper/detail/6397722386
Fine-tuning with Reserved Majority for Noise Reduction
使用保留多数进行噪声减少的微调
文章解读: 使用保留多数进行噪声减少的微调
http://www.studyai.com/xueshu/paper/detail/6399085123
AtomSurf: Surface Representation for Learning on Protein Structures
AtomSurf:蛋白质结构学习中的表面表示
文章解读: AtomSurf:蛋白质结构学习中的表面表示
http://www.studyai.com/xueshu/paper/detail/6502990538
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
CogVideoX:具有专家Transformer的文本到视频扩散模型
文章解读: CogVideoX:具有专家Transformer的文本到视频扩散模型
http://www.studyai.com/xueshu/paper/detail/6516871970
A Second-Order Perspective on Model Compositionality and Incremental Learning
从二阶视角看模型组合性和增量学习
文章解读: 从二阶视角看模型组合性和增量学习
http://www.studyai.com/xueshu/paper/detail/6526167571
Multimodal Large Language Models for Inverse Molecular Design with Retrosynthetic Planning
用于逆向分子设计与合成规划的多模态大语言模型
文章解读: 用于逆向分子设计与合成规划的多模态大语言模型
http://www.studyai.com/xueshu/paper/detail/6529378198
REEF: Representation Encoding Fingerprints for Large Language Models
REEF:用于大语言模型的表示编码指纹
文章解读: REEF:用于大语言模型的表示编码指纹
http://www.studyai.com/xueshu/paper/detail/6536375927
Bringing NeRFs to the Latent Space: Inverse Graphics Autoencoder
将NeRFs带到潜在空间:逆图形自动编码器
文章解读: 将NeRFs带到潜在空间:逆图形自动编码器
http://www.studyai.com/xueshu/paper/detail/6553693876
Enhancing Federated Domain Adaptation with Multi-Domain Prototype-Based Federated Fine-Tuning
增强联邦域适应的多域原型联邦微调
文章解读: 增强联邦域适应的多域原型联邦微调
http://www.studyai.com/xueshu/paper/detail/6557713512
Vision and Language Synergy for Rehearsal Free Continual Learning
视觉与语言协同的无排练持续学习
文章解读: 视觉与语言协同的无排练持续学习
http://www.studyai.com/xueshu/paper/detail/6566212631
No Pose, No Problem: Surprisingly Simple 3D Gaussian Splats from Sparse Unposed Images
无姿态,无问题:从稀疏无姿态图像中令人惊讶地简单的3D高斯斑点
文章解读: 无姿态,无问题:从稀疏无姿态图像中令人惊讶地简单的3D高斯斑点
http://www.studyai.com/xueshu/paper/detail/6570963171
Closed-Form Merging of Parameter-Efficient Modules for Federated Continual Learning
参数高效模块在联邦持续学习中的闭式合并
文章解读: 参数高效模块在联邦持续学习中的闭式合并
http://www.studyai.com/xueshu/paper/detail/6572209936
Robustness Inspired Graph Backdoor Defense
基于鲁棒性的图后门防御
文章解读: 基于鲁棒性的图后门防御
http://www.studyai.com/xueshu/paper/detail/6587010172
Systematic Relational Reasoning With Epistemic Graph Neural Networks
基于认知图神经网络的系统关系推理
文章解读: 基于认知图神经网络的系统关系推理
http://www.studyai.com/xueshu/paper/detail/6597156756
Skill Expansion and Composition in Parameter Space
参数空间中的技能扩展与组合
文章解读: 参数空间中的技能扩展与组合
http://www.studyai.com/xueshu/paper/detail/6608866736
GlycanML: A Multi-Task and Multi-Structure Benchmark for Glycan Machine Learning
GlycanML:一种用于糖类机器学习的多任务和多结构基准
文章解读: GlycanML:一种用于糖类机器学习的多任务和多结构基准
http://www.studyai.com/xueshu/paper/detail/6611571570
Mitigating Information Loss in Tree-Based Reinforcement Learning via Direct Optimization
基于树的强化学习中通过直接优化减轻信息损失
文章解读: 基于树的强化学习中通过直接优化减轻信息损失
http://www.studyai.com/xueshu/paper/detail/6618773729
Towards Foundation Models for Mixed Integer Linear Programming
面向混合整数线性规划的基础模型
文章解读: 面向混合整数线性规划的基础模型
http://www.studyai.com/xueshu/paper/detail/6621610313
Concept Pinpoint Eraser for Text-to-image Diffusion Models via Residual Attention Gate
基于残差注意力门控的文本到图像扩散模型概念定位擦除器
文章解读: 基于残差注意力门控的文本到图像扩散模型概念定位擦除器
http://www.studyai.com/xueshu/paper/detail/6629819233
Equivariant Denoisers Cannot Copy Graphs: Align Your Graph Diffusion Models
等变去噪器无法复制图:对齐你的图扩散模型
文章解读: 等变去噪器无法复制图:对齐你的图扩散模型
http://www.studyai.com/xueshu/paper/detail/6630578365
Perplexity Trap: PLM-Based Retrievers Overrate Low Perplexity Documents
困惑陷阱:基于PLM的检索器高估低困惑度文档
文章解读: 困惑陷阱:基于PLM的检索器高估低困惑度文档
http://www.studyai.com/xueshu/paper/detail/6633292800
SRSA: Skill Retrieval and Adaptation for Robotic Assembly Tasks
SRSA:机器人装配任务的技能检索与适应
文章解读: SRSA:机器人装配任务的技能检索与适应
http://www.studyai.com/xueshu/paper/detail/6639379603
SVG: 3D Stereoscopic Video Generation via Denoising Frame Matrix
SVG:通过去噪帧矩阵生成3D立体视频
文章解读: SVG:通过去噪帧矩阵生成3D立体视频
http://www.studyai.com/xueshu/paper/detail/6653935861
Diffusion Feedback Helps CLIP See Better
扩散反馈有助于CLIP看得更清楚
文章解读: 扩散反馈有助于CLIP看得更清楚
http://www.studyai.com/xueshu/paper/detail/6665363931
Can LLMs Understand Time Series Anomalies?
大语言模型能否理解时间序列异常?
文章解读: 大语言模型能否理解时间序列异常?
http://www.studyai.com/xueshu/paper/detail/6675210211
On Speeding Up Language Model Evaluation
加快语言模型评估
文章解读: 加快语言模型评估
http://www.studyai.com/xueshu/paper/detail/6686500225
Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models
Cybench:一个用于评估语言模型网络安全能力和风险的框架
文章解读: Cybench:一个用于评估语言模型网络安全能力和风险的框架
http://www.studyai.com/xueshu/paper/detail/6712703861
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
深度专业版:秒级锐利单目度量深度
文章解读: 深度专业版:秒级锐利单目度量深度
http://www.studyai.com/xueshu/paper/detail/6756620553
Stable Segment Anything Model
稳定任意物体分割模型
文章解读: 稳定任意物体分割模型
http://www.studyai.com/xueshu/paper/detail/6759852877
Combatting Dimensional Collapse in LLM Pre-Training Data via Submodular File Selection
通过子模态文件选择对抗LLM预训练数据中的维度坍塌
文章解读: 通过子模态文件选择对抗LLM预训练数据中的维度坍塌
http://www.studyai.com/xueshu/paper/detail/6759960221
LoRA-Pro: Are Low-Rank Adapters Properly Optimized?
LoRA-Pro:低秩适配器是否得到了适当优化?
文章解读: LoRA-Pro:低秩适配器是否得到了适当优化?
http://www.studyai.com/xueshu/paper/detail/6783805103
MMDisCo: Multi-Modal Discriminator-Guided Cooperative Diffusion for Joint Audio and Video Generation
MMDisCo:多模态判别器引导协同扩散,用于联合音频和视频生成
文章解读: MMDisCo:多模态判别器引导协同扩散,用于联合音频和视频生成
http://www.studyai.com/xueshu/paper/detail/6807396090
Revisiting Random Walks for Learning on Graphs
重新审视图上的随机游走学习
文章解读: 重新审视图上的随机游走学习
http://www.studyai.com/xueshu/paper/detail/6811337971
Improving Long-Text Alignment for Text-to-Image Diffusion Models
改进文本到图像扩散模型的文本对齐长文本
文章解读: 改进文本到图像扩散模型的文本对齐长文本
http://www.studyai.com/xueshu/paper/detail/6819107167
QMP: Q-switch Mixture of Policies for Multi-Task Behavior Sharing
QMP:用于多任务行为共享的Q开关策略混合
文章解读: QMP:用于多任务行为共享的Q开关策略混合
http://www.studyai.com/xueshu/paper/detail/6827069608
GenARM: Reward Guided Generation with Autoregressive Reward Model for Test-Time Alignment
GenARM:基于自回归奖励模型的测试时对齐的奖励引导生成
文章解读: GenARM:基于自回归奖励模型的测试时对齐的奖励引导生成
http://www.studyai.com/xueshu/paper/detail/6827589682
PaPaGei: Open Foundation Models for Optical Physiological Signals
PaPaGei:用于光学生理信号的开源基础模型
文章解读: PaPaGei:用于光学生理信号的开源基础模型
http://www.studyai.com/xueshu/paper/detail/6833029327
Perturbation-Restrained Sequential Model Editing
扰动约束序列模型编辑
文章解读: 扰动约束序列模型编辑
http://www.studyai.com/xueshu/paper/detail/6855352991
ZeroDiff: Solidified Visual-semantic Correlation in Zero-Shot Learning
ZeroDiff:在零样本学习中固化的视觉语义关联
文章解读: ZeroDiff:在零样本学习中固化的视觉语义关联
http://www.studyai.com/xueshu/paper/detail/6860225973
HyPoGen: Optimization-Biased Hypernetworks for Generalizable Policy Generation
HyPoGen:用于通用策略生成的优化偏向超网络
文章解读: HyPoGen:用于通用策略生成的优化偏向超网络
http://www.studyai.com/xueshu/paper/detail/6885750683
MMAD: A Comprehensive Benchmark for Multimodal Large Language Models in Industrial Anomaly Detection
MMAD:工业异常检测中多模态大语言模型的综合基准
文章解读: MMAD:工业异常检测中多模态大语言模型的综合基准
http://www.studyai.com/xueshu/paper/detail/6887921836
Learning to Adapt Frozen CLIP for Few-Shot Test-Time Domain Adaptation
学习适应冻结的CLIP进行小样本测试时域自适应
文章解读: 学习适应冻结的CLIP进行小样本测试时域自适应
http://www.studyai.com/xueshu/paper/detail/6889118078
Progressive Parameter Efficient Transfer Learning for Semantic Segmentation
面向语义分割的渐进式参数高效迁移学习
文章解读: 面向语义分割的渐进式参数高效迁移学习
http://www.studyai.com/xueshu/paper/detail/6911523130
TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
TokenFormer:重新思考基于分词模型参数的Transformer扩展
文章解读: TokenFormer:重新思考基于分词模型参数的Transformer扩展
http://www.studyai.com/xueshu/paper/detail/6919129369
Measuring And Improving Persuasiveness Of Large Language Models
测量和提升大语言模型的说服力
文章解读: 测量和提升大语言模型的说服力
http://www.studyai.com/xueshu/paper/detail/6927673638
Animate Your Thoughts: Reconstruction of Dynamic Natural Vision from Human Brain Activity
让你的想法生动起来:从人脑活动中重建动态自然视觉
文章解读: 让你的想法生动起来:从人脑活动中重建动态自然视觉
http://www.studyai.com/xueshu/paper/detail/6950188378
Weak-to-Strong Preference Optimization: Stealing Reward from Weak Aligned Model
弱到强偏好优化:从弱对齐模型中窃取奖励
文章解读: 弱到强偏好优化:从弱对齐模型中窃取奖励
http://www.studyai.com/xueshu/paper/detail/6966397567
Neural Exploratory Landscape Analysis for Meta-Black-Box-Optimization
元黑盒优化的神经探索景观分析
文章解读: 元黑盒优化的神经探索景观分析
http://www.studyai.com/xueshu/paper/detail/6978078198
ComLoRA: A Competitive Learning Approach for Enhancing LoRA
ComLoRA:一种用于增强LoRA的竞争学习方法
文章解读: ComLoRA:一种用于增强LoRA的竞争学习方法
http://www.studyai.com/xueshu/paper/detail/6985991671
TGB-Seq Benchmark: Challenging Temporal GNNs with Complex Sequential Dynamics
TGB-Seq基准测试:用复杂的序列动态挑战时序GNN
文章解读: TGB-Seq基准测试:用复杂的序列动态挑战时序GNN
http://www.studyai.com/xueshu/paper/detail/6988277188
Strength Estimation and Human-Like Strength Adjustment in Games
游戏中的力量估计与类人力量调整
文章解读: 游戏中的力量估计与类人力量调整
http://www.studyai.com/xueshu/paper/detail/6990872906
Analyzing and Boosting the Power of Fine-Grained Visual Recognition for Multi-modal Large Language Models
分析和提升细粒度视觉识别在多模态大语言模型中的能力
文章解读: 分析和提升细粒度视觉识别在多模态大语言模型中的能力
http://www.studyai.com/xueshu/paper/detail/6997760303
SelKD: Selective Knowledge Distillation via Optimal Transport Perspective
SelKD:基于最优传输视角的选择性知识蒸馏
文章解读: SelKD:基于最优传输视角的选择性知识蒸馏
http://www.studyai.com/xueshu/paper/detail/7009333322
Trajectory-LLM: A Language-based Data Generator for Trajectory Prediction in Autonomous Driving
轨迹-LLM:自动驾驶中轨迹预测的语言数据生成器
文章解读: 轨迹-LLM:自动驾驶中轨迹预测的语言数据生成器
http://www.studyai.com/xueshu/paper/detail/7021326372
Atlas Gaussians Diffusion for 3D Generation
基于Atlas的高斯扩散模型用于3D生成
文章解读: 基于Atlas的高斯扩散模型用于3D生成
http://www.studyai.com/xueshu/paper/detail/7025009120
Fast Feedforward 3D Gaussian Splatting Compression
快速前馈3D高斯喷溅压缩
文章解读: 快速前馈3D高斯喷溅压缩
http://www.studyai.com/xueshu/paper/detail/7032605675
The Superposition of Diffusion Models Using the Itô Density Estimator
使用伊藤密度估计器进行扩散模型的叠加
文章解读: 使用伊藤密度估计器进行扩散模型的叠加
http://www.studyai.com/xueshu/paper/detail/7051206289
SiReRAG: Indexing Similar and Related Information for Multihop Reasoning
SiReRAG:用于多跳推理的相似和相关信息索引
文章解读: SiReRAG:用于多跳推理的相似和相关信息索引
http://www.studyai.com/xueshu/paper/detail/7053866399
Towards Robust and Parameter-Efficient Knowledge Unlearning for LLMs
面向面向大语言模型的鲁棒且参数高效的知识去学习
文章解读: 面向面向大语言模型的鲁棒且参数高效的知识去学习
http://www.studyai.com/xueshu/paper/detail/7060038557
RMP-SAM: Towards Real-Time Multi-Purpose Segment Anything
RMP-SAM:面向实时多用途的任何事物分割
文章解读: RMP-SAM:面向实时多用途的任何事物分割
http://www.studyai.com/xueshu/paper/detail/7060660226
VoxDialogue: Can Spoken Dialogue Systems Understand Information Beyond Words?
VoxDialogue:口语对话系统能否理解超越文字的信息?
文章解读: VoxDialogue:口语对话系统能否理解超越文字的信息?
http://www.studyai.com/xueshu/paper/detail/7069815975
LARP: Tokenizing Videos with a Learned Autoregressive Generative Prior
LARP:使用学习型自回归生成先验对视频进行分词
文章解读: LARP:使用学习型自回归生成先验对视频进行分词
http://www.studyai.com/xueshu/paper/detail/7076513933
Attribute-based Visual Reprogramming for Vision-Language Models
基于属性的视觉重编程方法用于视觉-语言模型
文章解读: 基于属性的视觉重编程方法用于视觉-语言模型
http://www.studyai.com/xueshu/paper/detail/7100522395
Towards Hierarchical Rectified Flow
面向分层整流流
文章解读: 面向分层整流流
http://www.studyai.com/xueshu/paper/detail/7133631515
AVHBench: A Cross-Modal Hallucination Benchmark for Audio-Visual Large Language Models
AVHBench:一种用于音频-视觉大语言模型的跨模态幻觉基准
文章解读: AVHBench:一种用于音频-视觉大语言模型的跨模态幻觉基准
http://www.studyai.com/xueshu/paper/detail/7159020308
Improving Pretraining Data Using Perplexity Correlations
使用困惑度相关性改进预训练数据
文章解读: 使用困惑度相关性改进预训练数据
http://www.studyai.com/xueshu/paper/detail/7161598750
BANGS: Game-theoretic Node Selection for Graph Self-Training
BANGS:基于博弈论的图自训练节点选择
文章解读: BANGS:基于博弈论的图自训练节点选择
http://www.studyai.com/xueshu/paper/detail/7166123572
A Unified Framework for Forward and Inverse Problems in Subsurface Imaging using Latent Space Translations
用于地下成像的正向与反向问题的统一框架:基于潜在空间转换
文章解读: 用于地下成像的正向与反向问题的统一框架:基于潜在空间转换
http://www.studyai.com/xueshu/paper/detail/7169702098
SymmetricDiffusers: Learning Discrete Diffusion on Finite Symmetric Groups
对称扩散器:在有限对称群上学习离散扩散
文章解读: 对称扩散器:在有限对称群上学习离散扩散
http://www.studyai.com/xueshu/paper/detail/7170218102
How new data permeates LLM knowledge and how to dilute it
新数据如何渗透大语言模型的知识以及如何稀释它
文章解读: 新数据如何渗透大语言模型的知识以及如何稀释它
http://www.studyai.com/xueshu/paper/detail/7172862357
Reading Your Heart: Learning ECG Words and Sentences via Pre-training ECG Language Model
读懂你的心:通过预训练心电图语言模型学习心电图词汇和句子
文章解读: 读懂你的心:通过预训练心电图语言模型学习心电图词汇和句子
http://www.studyai.com/xueshu/paper/detail/7175067650
Beyond correlation: The impact of human uncertainty in measuring the effectiveness of automatic evaluation and LLM-as-a-judge
超越相关性:人类不确定性对衡量自动评估和LLM作为裁判有效性的影响
文章解读: 超越相关性:人类不确定性对衡量自动评估和LLM作为裁判有效性的影响
http://www.studyai.com/xueshu/paper/detail/7181160690
CL-DiffPhyCon: Closed-loop Diffusion Control of Complex Physical Systems
CL-DiffPhyCon:复杂物理系统的闭环扩散控制
文章解读: CL-DiffPhyCon:复杂物理系统的闭环扩散控制
http://www.studyai.com/xueshu/paper/detail/7186060288
HShare: Fast LLM Decoding by Hierarchical Key-Value Sharing
HShare:基于层次化键值共享的快速LLM解码
文章解读: HShare:基于层次化键值共享的快速LLM解码
http://www.studyai.com/xueshu/paper/detail/7188219965
MOFFlow: Flow Matching for Structure Prediction of Metal-Organic Frameworks
MOFFlow:用于金属有机框架结构预测的流匹配
文章解读: MOFFlow:用于金属有机框架结构预测的流匹配
http://www.studyai.com/xueshu/paper/detail/7197108275
Bidirectional Decoding: Improving Action Chunking via Guided Test-Time Sampling
双向解码:通过引导测试时采样改进动作分块
文章解读: 双向解码:通过引导测试时采样改进动作分块
http://www.studyai.com/xueshu/paper/detail/7202176885
UNIP: Rethinking Pre-trained Attention Patterns for Infrared Semantic Segmentation
UNIP:重新思考红外语义分割的预训练注意力模式
文章解读: UNIP:重新思考红外语义分割的预训练注意力模式
http://www.studyai.com/xueshu/paper/detail/7215378378
Large Language Models Often Say One Thing and Do Another
大语言模型常常言行不一
文章解读: 大语言模型常常言行不一
http://www.studyai.com/xueshu/paper/detail/7220567802
Correlated Proxies: A New Definition and Improved Mitigation for Reward Hacking
相关代理:新的定义和改进的奖励攻击缓解方法
文章解读: 相关代理:新的定义和改进的奖励攻击缓解方法
http://www.studyai.com/xueshu/paper/detail/7223999297
Towards Calibrated Deep Clustering Network
面向校准深度聚类网络
文章解读: 面向校准深度聚类网络
http://www.studyai.com/xueshu/paper/detail/7225823683
CaPo: Cooperative Plan Optimization for Efficient Embodied Multi-Agent Cooperation
CaPo:协同计划优化,用于高效的具身多智能体合作
文章解读: CaPo:协同计划优化,用于高效的具身多智能体合作
http://www.studyai.com/xueshu/paper/detail/7229277535
Adding Conditional Control to Diffusion Models with Reinforcement Learning
使用强化学习为扩散模型添加条件控制
文章解读: 使用强化学习为扩散模型添加条件控制
http://www.studyai.com/xueshu/paper/detail/7251615203
Universal Image Restoration Pre-training via Degradation Classification
基于退化分类的通用图像恢复预训练
文章解读: 基于退化分类的通用图像恢复预训练
http://www.studyai.com/xueshu/paper/detail/7252768533
ACES: Automatic Cohort Extraction System for Event-Stream Datasets
ACES:用于事件流数据集的自动队列提取系统
文章解读: ACES:用于事件流数据集的自动队列提取系统
http://www.studyai.com/xueshu/paper/detail/7260273862
From Commands to Prompts: LLM-based Semantic File System for AIOS
从指令到提示:面向AIOS的基于LLM的语义文件系统
文章解读: 从指令到提示:面向AIOS的基于LLM的语义文件系统
http://www.studyai.com/xueshu/paper/detail/7279072658
ReAttention: Training-Free Infinite Context with Finite Attention Scope
ReAttention:无需训练的无穷上下文与有限注意力范围
文章解读: ReAttention:无需训练的无穷上下文与有限注意力范围
http://www.studyai.com/xueshu/paper/detail/7287381709
CheapNet: Cross-attention on Hierarchical representations for Efficient protein-ligand binding Affinity Prediction
CheapNet:基于层次化表示的交叉注意力机制用于高效的蛋白质-配体结合亲和力预测
文章解读: CheapNet:基于层次化表示的交叉注意力机制用于高效的蛋白质-配体结合亲和力预测
http://www.studyai.com/xueshu/paper/detail/7296315280
Adaptive Q Q Q-Network: On-the-fly Target Selection for Deep Reinforcement Learning
自适应Q网络:深度强化学习中的动态目标选择
文章解读: 自适应Q网络:深度强化学习中的动态目标选择
http://www.studyai.com/xueshu/paper/detail/7306061773
NRGBoost: Energy-Based Generative Boosted Trees
NRGBoost:基于能量的生成式提升树
文章解读: NRGBoost:基于能量的生成式提升树
http://www.studyai.com/xueshu/paper/detail/7306892893
MLLM as Retriever: Interactively Learning Multimodal Retrieval for Embodied Agents
MLLM作为检索器:交互式学习具身智能体的多模态检索
文章解读: MLLM作为检索器:交互式学习具身智能体的多模态检索
http://www.studyai.com/xueshu/paper/detail/7307222609
Learning Gain Map for Inverse Tone Mapping
逆色调映射的学习增益图
文章解读: 逆色调映射的学习增益图
http://www.studyai.com/xueshu/paper/detail/7320268809
Teaching Human Behavior Improves Content Understanding Abilities Of VLMs
教授人类行为能够提升VLMs的内容理解能力
文章解读: 教授人类行为能够提升VLMs的内容理解能力
http://www.studyai.com/xueshu/paper/detail/7322188786
Zero-shot Model-based Reinforcement Learning using Large Language Models
基于大语言模型的零样本模型强化学习
文章解读: 基于大语言模型的零样本模型强化学习
http://www.studyai.com/xueshu/paper/detail/7325119201
CapeX: Category-Agnostic Pose Estimation from Textual Point Explanation
CapeX:基于文本点解释的类别无关姿态估计
文章解读: CapeX:基于文本点解释的类别无关姿态估计
http://www.studyai.com/xueshu/paper/detail/7332825306
Neuralized Markov Random Field for Interaction-Aware Stochastic Human Trajectory Prediction
交互感知随机人类轨迹预测的神经化马尔可夫随机场
文章解读: 交互感知随机人类轨迹预测的神经化马尔可夫随机场
http://www.studyai.com/xueshu/paper/detail/7337705391
DexTrack: Towards Generalizable Neural Tracking Control for Dexterous Manipulation from Human References
DexTrack:面向灵巧操作中基于人类参考的泛化神经跟踪控制
文章解读: DexTrack:面向灵巧操作中基于人类参考的泛化神经跟踪控制
http://www.studyai.com/xueshu/paper/detail/7357327535
FreeCG: Free the Design Space of Clebsch-Gordan Transform for Machine Learning Force Fields
FreeCG:释放克莱布什-高登变换的设计空间以用于机器学习力场
文章解读: FreeCG:释放克莱布什-高登变换的设计空间以用于机器学习力场
http://www.studyai.com/xueshu/paper/detail/7363881229
Hyperbolic Genome Embeddings
双曲基因组嵌入
文章解读: 双曲基因组嵌入
http://www.studyai.com/xueshu/paper/detail/7365779860
ADePT: Adaptive Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning
ADePT:自适应分解提示微调,用于参数高效的微调
文章解读: ADePT:自适应分解提示微调,用于参数高效的微调
http://www.studyai.com/xueshu/paper/detail/7379922230
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
MLE-bench:评估机器学习代理在机器学习工程上的表现
文章解读: MLE-bench:评估机器学习代理在机器学习工程上的表现
http://www.studyai.com/xueshu/paper/detail/7395525520
Contextualizing biological perturbation experiments through language
通过语言对生物扰动实验进行背景化
文章解读: 通过语言对生物扰动实验进行背景化
http://www.studyai.com/xueshu/paper/detail/7502037238
GPUDrive: Data-driven, multi-agent driving simulation at 1 million FPS
GPUDrive:基于数据的百万帧每秒多智能体驾驶模拟
文章解读: GPUDrive:基于数据的百万帧每秒多智能体驾驶模拟
http://www.studyai.com/xueshu/paper/detail/7509153836
Beyond Content Relevance: Evaluating Instruction Following in Retrieval Models
超越内容相关性:评估检索模型中的指令遵循
文章解读: 超越内容相关性:评估检索模型中的指令遵循
http://www.studyai.com/xueshu/paper/detail/7523957050
EqNIO: Subequivariant Neural Inertial Odometry
EqNIO:亚等变神经惯性里程计
文章解读: EqNIO:亚等变神经惯性里程计
http://www.studyai.com/xueshu/paper/detail/7528725663
Toward Generalizing Visual Brain Decoding to Unseen Subjects
迈向将视觉大脑解码推广到未见过的对象
文章解读: 迈向将视觉大脑解码推广到未见过的对象
http://www.studyai.com/xueshu/paper/detail/7532313397
Are Large Vision Language Models Good Game Players?
大型视觉语言模型是好的游戏玩家吗?
文章解读: 大型视觉语言模型是好的游戏玩家吗?
http://www.studyai.com/xueshu/paper/detail/7538380905
Mastering Task Arithmetic: τ \tau τJp as a Key Indicator for Weight Disentanglement
掌握任务算术: τ \tau τJp作为权重解耦的关键指标
文章解读: 掌握任务算术: τ \tau τJp作为权重解耦的关键指标
http://www.studyai.com/xueshu/paper/detail/7566365796
Spatial-Mamba: Effective Visual State Space Models via Structure-Aware State Fusion
空间Mamba:通过结构感知状态融合实现高效视觉状态空间模型
文章解读: 空间Mamba:通过结构感知状态融合实现高效视觉状态空间模型
http://www.studyai.com/xueshu/paper/detail/7576526061
ADAPT: Attentive Self-Distillation and Dual-Decoder Prediction Fusion for Continual Panoptic Segmentation
ADAPT:用于持续全景分割的注意力自蒸馏和双解码器预测融合
文章解读: ADAPT:用于持续全景分割的注意力自蒸馏和双解码器预测融合
http://www.studyai.com/xueshu/paper/detail/7579918912
Noisy Test-Time Adaptation in Vision-Language Models
视觉-语言模型中的噪声测试时适应
文章解读: 视觉-语言模型中的噪声测试时适应
http://www.studyai.com/xueshu/paper/detail/7581587258
Quantized Spike-driven Transformer
量化脉冲驱动Transformer
文章解读: 量化脉冲驱动Transformer
http://www.studyai.com/xueshu/paper/detail/7581717510
Scaling FP8 training to trillion-token LLMs
将FP8训练扩展到万亿token的大语言模型
文章解读: 将FP8训练扩展到万亿token的大语言模型
http://www.studyai.com/xueshu/paper/detail/7586656389
AdaFisher: Adaptive Second Order Optimization via Fisher Information
AdaFisher:基于Fisher信息的自适应二阶优化
文章解读: AdaFisher:基于Fisher信息的自适应二阶优化
http://www.studyai.com/xueshu/paper/detail/7601639226
Earlier Tokens Contribute More: Learning Direct Preference Optimization From Temporal Decay Perspective
早期标记贡献更大:从时间衰减视角学习直接偏好优化
文章解读: 早期标记贡献更大:从时间衰减视角学习直接偏好优化
http://www.studyai.com/xueshu/paper/detail/7603259517
4K4DGen: Panoramic 4D Generation at 4K Resolution
4K4DGen:4K分辨率的全景4D生成
文章解读: 4K4DGen:4K分辨率的全景4D生成
http://www.studyai.com/xueshu/paper/detail/7616231757
FLOPS: Forward Learning with OPtimal Sampling
FLOPS:基于最优采样的正向学习
文章解读: FLOPS:基于最优采样的正向学习
http://www.studyai.com/xueshu/paper/detail/7629359508
SiMHand: Mining Similar Hands for Large-Scale 3D Hand Pose Pre-training
SiMHand:挖掘相似手部图像用于大规模3D手部姿态预训练
文章解读: SiMHand:挖掘相似手部图像用于大规模3D手部姿态预训练
http://www.studyai.com/xueshu/paper/detail/7630095021
PianoMotion10M: Dataset and Benchmark for Hand Motion Generation in Piano Performance
PianoMotion10M:钢琴演奏中手势生成数据集与基准
文章解读: PianoMotion10M:钢琴演奏中手势生成数据集与基准
http://www.studyai.com/xueshu/paper/detail/7635099222
SpikeLLM: Scaling up Spiking Neural Network to Large Language Models via Saliency-based Spiking
SpikeLLM:基于显著性脉冲将脉冲神经网络扩展到大语言模型
文章解读: SpikeLLM:基于显著性脉冲将脉冲神经网络扩展到大语言模型
http://www.studyai.com/xueshu/paper/detail/7639150738
Trusted Multi-View Classification via Evolutionary Multi-View Fusion
基于进化多视图融合的可信多视图分类
文章解读: 基于进化多视图融合的可信多视图分类
http://www.studyai.com/xueshu/paper/detail/7662020258
Test-time Alignment of Diffusion Models without Reward Over-optimization
测试时扩散模型的奖励无过优化对齐
文章解读: 测试时扩散模型的奖励无过优化对齐
http://www.studyai.com/xueshu/paper/detail/7668589912
IRIS: LLM-Assisted Static Analysis for Detecting Security Vulnerabilities
IRIS:基于LLM的静态分析技术,用于检测安全漏洞
文章解读: IRIS:基于LLM的静态分析技术,用于检测安全漏洞
http://www.studyai.com/xueshu/paper/detail/7669238666
Looking Backward: Retrospective Backward Synthesis for Goal-Conditioned GFlowNets
回顾过去:目标条件GFlowNets的回顾性逆向合成
文章解读: 回顾过去:目标条件GFlowNets的回顾性逆向合成
http://www.studyai.com/xueshu/paper/detail/7689606278
From Search to Sampling: Generative Models for Robust Algorithmic Recourse
从搜索到采样:用于鲁棒算法回溯的生成模型
文章解读: 从搜索到采样:用于鲁棒算法回溯的生成模型
http://www.studyai.com/xueshu/paper/detail/7696277970
M^3PC: Test-time Model Predictive Control using Pretrained Masked Trajectory Model
M^3PC:基于预训练掩码轨迹模型的测试时模型预测控制
文章解读: M^3PC:基于预训练掩码轨迹模型的测试时模型预测控制
http://www.studyai.com/xueshu/paper/detail/7705836732
Glimpse: Enabling White-Box Methods to Use Proprietary Models for Zero-Shot LLM-Generated Text Detection
一瞥:使白盒方法能够使用专有模型进行零样本LLM生成文本检测
文章解读: 一瞥:使白盒方法能够使用专有模型进行零样本LLM生成文本检测
http://www.studyai.com/xueshu/paper/detail/7712135687
SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration
SageAttention:精确的8位注意力机制,用于即插即用推理加速
文章解读: SageAttention:精确的8位注意力机制,用于即插即用推理加速
http://www.studyai.com/xueshu/paper/detail/7715880666
Exact Byte-Level Probabilities from Tokenized Language Models for FIM-Tasks and Model Ensembles
用于FIM任务和模型集成的分词语言模型的精确字节级概率
文章解读: 用于FIM任务和模型集成的分词语言模型的精确字节级概率
http://www.studyai.com/xueshu/paper/detail/7720082711
Open-CK: A Large Multi-Physics Fields Coupling benchmarks in Combustion Kinetics
Open-CK:燃烧动力学中大物理场耦合基准测试
文章解读: Open-CK:燃烧动力学中大物理场耦合基准测试
http://www.studyai.com/xueshu/paper/detail/7727737925
q q q-exponential family for policy optimization
策略优化的 q q q-指数族
文章解读: 策略优化的 q q q-指数族
http://www.studyai.com/xueshu/paper/detail/7727976671
Breaking Mental Set to Improve Reasoning through Diverse Multi-Agent Debate
打破思维定势,通过多样化多智能体辩论提升推理能力
文章解读: 打破思维定势,通过多样化多智能体辩论提升推理能力
http://www.studyai.com/xueshu/paper/detail/7752238950
Fragment and Geometry Aware Tokenization of Molecules for Structure-Based Drug Design Using Language Models
基于语言模型的分子片段和几何感知分词在基于结构的药物设计中的应用
文章解读: 基于语言模型的分子片段和几何感知分词在基于结构的药物设计中的应用
http://www.studyai.com/xueshu/paper/detail/7753136709
DataEnvGym: Data Generation Agents in Teacher Environments with Student Feedback
DataEnvGym:在教师环境中具有学生反馈的数据生成代理
文章解读: DataEnvGym:在教师环境中具有学生反馈的数据生成代理
http://www.studyai.com/xueshu/paper/detail/7755137959
KaSA: Knowledge-Aware Singular-Value Adaptation of Large Language Models
KaSA:知识感知的大语言模型的奇异值自适应
文章解读: KaSA:知识感知的大语言模型的奇异值自适应
http://www.studyai.com/xueshu/paper/detail/7755885803
OmniRe: Omni Urban Scene Reconstruction
OmniRe:全息城市场景重建
文章解读: OmniRe:全息城市场景重建
http://www.studyai.com/xueshu/paper/detail/7770208818
Aligning Generative Denoising with Discriminative Objectives Unleashes Diffusion for Visual Perception
将生成式降噪与判别性目标相结合,释放了扩散模型在视觉感知中的应用
文章解读: 将生成式降噪与判别性目标相结合,释放了扩散模型在视觉感知中的应用
http://www.studyai.com/xueshu/paper/detail/7773157366
Dreamweaver: Learning Compositional World Models from Pixels
Dreamweaver:从像素中学习组合世界模型
文章解读: Dreamweaver:从像素中学习组合世界模型
http://www.studyai.com/xueshu/paper/detail/7776855587
Exploring the Design Space of Visual Context Representation in Video MLLMs
探索视频MLLMs中视觉上下文表示的设计空间
文章解读: 探索视频MLLMs中视觉上下文表示的设计空间
http://www.studyai.com/xueshu/paper/detail/7780662829
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
NV-Embed:作为通用嵌入模型的LLM训练的改进技术
文章解读: NV-Embed:作为通用嵌入模型的LLM训练的改进技术
http://www.studyai.com/xueshu/paper/detail/7787726155
DeFT: Decoding with Flash Tree-attention for Efficient Tree-structured LLM Inference
DeFT:使用闪存树注意力进行高效树状LLM推理的解码
文章解读: DeFT:使用闪存树注意力进行高效树状LLM推理的解码
http://www.studyai.com/xueshu/paper/detail/7791851778
Bootstrapping Language Models with DPO Implicit Rewards
使用DPO隐式奖励引导语言模型
文章解读: 使用DPO隐式奖励引导语言模型
http://www.studyai.com/xueshu/paper/detail/7792321196
Beyond FVD: An Enhanced Evaluation Metrics for Video Generation Distribution Quality
超越FVD:视频生成分发质量增强评估指标
文章解读: 超越FVD:视频生成分发质量增强评估指标
http://www.studyai.com/xueshu/paper/detail/7797805933
AnalogGenie: A Generative Engine for Automatic Discovery of Analog Circuit Topologies
AnalogGenie:一种用于自动发现模拟电路拓扑的生成引擎
文章解读: AnalogGenie:一种用于自动发现模拟电路拓扑的生成引擎
http://www.studyai.com/xueshu/paper/detail/7798866661
A Distributional Approach to Uncertainty-Aware Preference Alignment Using Offline Demonstrations
基于离线演示的不确定性感知偏好对齐的分布方法
文章解读: 基于离线演示的不确定性感知偏好对齐的分布方法
http://www.studyai.com/xueshu/paper/detail/7819015022
DeepLTL: Learning to Efficiently Satisfy Complex LTL Specifications for Multi-Task RL
DeepLTL:学习高效满足多任务强化学习中的复杂LTL规范
文章解读: DeepLTL:学习高效满足多任务强化学习中的复杂LTL规范
http://www.studyai.com/xueshu/paper/detail/7820668962
CURIE: Evaluating LLMs on Multitask Scientific Long-Context Understanding and Reasoning
CURIE:在多任务科学长上下文理解和推理上评估大语言模型
文章解读: CURIE:在多任务科学长上下文理解和推理上评估大语言模型
http://www.studyai.com/xueshu/paper/detail/7822589839
Implicit In-context Learning
隐式情境学习
文章解读: 隐式情境学习
http://www.studyai.com/xueshu/paper/detail/7827873036
ConvCodeWorld: Benchmarking Conversational Code Generation in Reproducible Feedback Environments
ConvCodeWorld:在可复现反馈环境中对对话式代码生成进行基准测试
文章解读: ConvCodeWorld:在可复现反馈环境中对对话式代码生成进行基准测试
http://www.studyai.com/xueshu/paper/detail/7862653095
F 3 S e t F^3Set F3Set: Towards Analyzing Fast, Frequent, and Fine-grained Events from Videos
F 3 S e t F^3Set F3Set:迈向分析视频中的快速、频繁和细粒度事件
文章解读: F 3 S e t F^3Set F3Set:迈向分析视频中的快速、频繁和细粒度事件
http://www.studyai.com/xueshu/paper/detail/7869551292
What’s the Move? Hybrid Imitation Learning via Salient Points
什么行动?基于显著点的混合模仿学习
文章解读: 什么行动?基于显著点的混合模仿学习
http://www.studyai.com/xueshu/paper/detail/7871328125
Learning LLM-as-a-Judge for Preference Alignment
学习将LLM作为裁判进行偏好对齐
文章解读: 学习将LLM作为裁判进行偏好对齐
http://www.studyai.com/xueshu/paper/detail/7872112763
Sensitivity-Constrained Fourier Neural Operators for Forward and Inverse Problems in Parametric Differential Equations
参数微分方程的正向与反向问题中的敏感度约束傅里叶神经算子
文章解读: 参数微分方程的正向与反向问题中的敏感度约束傅里叶神经算子
http://www.studyai.com/xueshu/paper/detail/7878820230
CtrLoRA: An Extensible and Efficient Framework for Controllable Image Generation
CtrLoRA:一个可扩展且高效的可控图像生成框架
文章解读: CtrLoRA:一个可扩展且高效的可控图像生成框架
http://www.studyai.com/xueshu/paper/detail/7896611608
Restyling Unsupervised Concept Based Interpretable Networks with Generative Models
使用生成模型重构无监督概念基础可解释网络
文章解读: 使用生成模型重构无监督概念基础可解释网络
http://www.studyai.com/xueshu/paper/detail/7905232998
FlickerFusion: Intra-trajectory Domain Generalizing Multi-agent Reinforcement Learning
FlickerFusion:轨迹内域泛化多智能体强化学习
文章解读: FlickerFusion:轨迹内域泛化多智能体强化学习
http://www.studyai.com/xueshu/paper/detail/7905502603
Multi-Label Test-Time Adaptation with Bound Entropy Minimization
带熵最小化的多标签测试时自适应
文章解读: 带熵最小化的多标签测试时自适应
http://www.studyai.com/xueshu/paper/detail/7926793333
FakeShield: Explainable Image Forgery Detection and Localization via Multi-modal Large Language Models
FakeShield:基于多模态大语言模型的可解释图像伪造检测与定位
文章解读: FakeShield:基于多模态大语言模型的可解释图像伪造检测与定位
http://www.studyai.com/xueshu/paper/detail/7938076728
Learning Efficient Positional Encodings with Graph Neural Networks
使用图神经网络学习高效的位置编码
文章解读: 使用图神经网络学习高效的位置编码
http://www.studyai.com/xueshu/paper/detail/7939195953
MP-Mat: A 3D-and-Instance-Aware Human Matting and Editing Framework with Multiplane Representation
MP-Mat:一个具有多平面表示的3D和实例感知的人体抠图与编辑框架
文章解读: MP-Mat:一个具有多平面表示的3D和实例感知的人体抠图与编辑框架
http://www.studyai.com/xueshu/paper/detail/7961752117
VTDexManip: A Dataset and Benchmark for Visual-tactile Pretraining and Dexterous Manipulation with Reinforcement Learning
VTDexManip:用于视觉触觉预训练和基于强化学习的灵巧操作的数据集与基准
文章解读: VTDexManip:用于视觉触觉预训练和基于强化学习的灵巧操作的数据集与基准
http://www.studyai.com/xueshu/paper/detail/7990537230
Learning to Discover Regulatory Elements for Gene Expression Prediction
学习发现用于基因表达预测的调控元件
文章解读: 学习发现用于基因表达预测的调控元件
http://www.studyai.com/xueshu/paper/detail/7990928200
GETS: Ensemble Temperature Scaling for Calibration in Graph Neural Networks
GETS:用于图神经网络校准的集成温度缩放
文章解读: GETS:用于图神经网络校准的集成温度缩放
http://www.studyai.com/xueshu/paper/detail/8011270768
GameGen-X: Interactive Open-world Game Video Generation
GameGen-X:交互式开放世界游戏视频生成
文章解读: GameGen-X:交互式开放世界游戏视频生成
http://www.studyai.com/xueshu/paper/detail/8017002982
Improving Deep Regression with Tightness
改进深度回归的紧致性
文章解读: 改进深度回归的紧致性
http://www.studyai.com/xueshu/paper/detail/8022183669
UniCoTT: A Unified Framework for Structural Chain-of-Thought Distillation
UniCoTT:一种用于结构化思维链蒸馏的统一框架
文章解读: UniCoTT:一种用于结构化思维链蒸馏的统一框架
http://www.studyai.com/xueshu/paper/detail/8022308565
Discrete Distribution Networks
离散分布网络
文章解读: 离散分布网络
http://www.studyai.com/xueshu/paper/detail/8026011172
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
CS-Bench:面向计算机科学掌握的大语言模型的综合性基准
文章解读: CS-Bench:面向计算机科学掌握的大语言模型的综合性基准
http://www.studyai.com/xueshu/paper/detail/8029221770
ThinkBot: Embodied Instruction Following with Thought Chain Reasoning
ThinkBot:基于思维链推理的具身指令遵循
文章解读: ThinkBot:基于思维链推理的具身指令遵循
http://www.studyai.com/xueshu/paper/detail/8035008792
ToolACE: Winning the Points of LLM Function Calling
ToolACE:赢得LLM函数调用的要点
文章解读: ToolACE:赢得LLM函数调用的要点
http://www.studyai.com/xueshu/paper/detail/8035126688
Discovering Influential Neuron Path in Vision Transformers
发现视觉变换器中的关键神经元路径
文章解读: 发现视觉变换器中的关键神经元路径
http://www.studyai.com/xueshu/paper/detail/8039796059
Population Transformer: Learning Population-level Representations of Neural Activity
种群转换器:学习神经活动层面的种群级表示
文章解读: 种群转换器:学习神经活动层面的种群级表示
http://www.studyai.com/xueshu/paper/detail/8052708193
RocketEval: Efficient automated LLM evaluation via grading checklist
RocketEval:通过评分清单实现高效的LLM自动化评估
文章解读: RocketEval:通过评分清单实现高效的LLM自动化评估
http://www.studyai.com/xueshu/paper/detail/8071796926
Measuring and Enhancing Trustworthiness of LLMs in RAG through Grounded Attributions and Learning to Refuse
通过基于证据的归因和拒绝学习来衡量和增强RAG中LLMs的可信度
文章解读: 通过基于证据的归因和拒绝学习来衡量和增强RAG中LLMs的可信度
http://www.studyai.com/xueshu/paper/detail/8076327683
Multimodality Helps Few-shot 3D Point Cloud Semantic Segmentation
多模态技术有助于小样本三维点云语义分割
文章解读: 多模态技术有助于小样本三维点云语义分割
http://www.studyai.com/xueshu/paper/detail/8098990198
FaceShot: Bring Any Character into Life
FaceShot:让任何角色栩栩如生
文章解读: FaceShot:让任何角色栩栩如生
http://www.studyai.com/xueshu/paper/detail/8106628982
On Quantizing Neural Representation for Variable-Rate Video Coding
对可变比特率视频编码中神经表征的量化
文章解读: 对可变比特率视频编码中神经表征的量化
http://www.studyai.com/xueshu/paper/detail/8110058352
STAMP: Scalable Task- And Model-agnostic Collaborative Perception
STAMP:可扩展的任务和模型无关的协同感知
文章解读: STAMP:可扩展的任务和模型无关的协同感知
http://www.studyai.com/xueshu/paper/detail/8111222361
Think while You Generate: Discrete Diffusion with Planned Denoising
边生成边思考:计划性去噪的离散扩散
文章解读: 边生成边思考:计划性去噪的离散扩散
http://www.studyai.com/xueshu/paper/detail/8128728383
Scalable Mechanistic Neural Networks
可扩展机制神经网络
文章解读: 可扩展机制神经网络
http://www.studyai.com/xueshu/paper/detail/8128758297
TAU-106K: A New Dataset for Comprehensive Understanding of Traffic Accident
TAU-106K:一个用于全面理解交通事故的新数据集
文章解读: TAU-106K:一个用于全面理解交通事故的新数据集
http://www.studyai.com/xueshu/paper/detail/8130197998
FairMT-Bench: Benchmarking Fairness for Multi-turn Dialogue in Conversational LLMs
FairMT-Bench:对话式大语言模型多轮对话公平性基准测试
文章解读: FairMT-Bench:对话式大语言模型多轮对话公平性基准测试
http://www.studyai.com/xueshu/paper/detail/8132261282
Immunogenicity Prediction with Dual Attention Enables Vaccine Target Selection
基于双重注意力机制的免疫原性预测助力疫苗靶点选择
文章解读: 基于双重注意力机制的免疫原性预测助力疫苗靶点选择
http://www.studyai.com/xueshu/paper/detail/8139851079
S4M: S4 for multivariate time series forecasting with Missing values
S4M:用于多变量时间序列预测的S4方法(含缺失值处理)
文章解读: S4M:用于多变量时间序列预测的S4方法(含缺失值处理)
http://www.studyai.com/xueshu/paper/detail/8152637368
Long-Sequence Recommendation Models Need Decoupled Embeddings
长序列推荐模型需要解耦嵌入
文章解读: 长序列推荐模型需要解耦嵌入
http://www.studyai.com/xueshu/paper/detail/8156887200
IgGM: A Generative Model for Functional Antibody and Nanobody Design
IgGM:用于功能抗体和纳米抗体设计的生成模型
文章解读: IgGM:用于功能抗体和纳米抗体设计的生成模型
http://www.studyai.com/xueshu/paper/detail/8160012860
Multi-Task Corrupted Prediction for Learning Robust Audio-Visual Speech Representation
多任务损坏预测学习鲁棒视听语音表征
文章解读: 多任务损坏预测学习鲁棒视听语音表征
http://www.studyai.com/xueshu/paper/detail/8166881886
D-FINE: Redefine Regression Task of DETRs as Fine-grained Distribution Refinement
D-FINE:重新定义DETRs回归任务为细粒度分布细化
文章解读: D-FINE:重新定义DETRs回归任务为细粒度分布细化
http://www.studyai.com/xueshu/paper/detail/8181210272
Solving Token Gradient Conflict in Mixture-of-Experts for Large Vision-Language Model
解决专家混合模型中大型视觉语言模型的Token梯度冲突问题
文章解读: 解决专家混合模型中大型视觉语言模型的Token梯度冲突问题
http://www.studyai.com/xueshu/paper/detail/8183761260
MCNC: Manifold-Constrained Reparameterization for Neural Compression
MCNC:带流形约束的神经网络压缩重参数化
文章解读: MCNC:带流形约束的神经网络压缩重参数化
http://www.studyai.com/xueshu/paper/detail/8192527751
ShortcutsBench: A Large-Scale Real-world Benchmark for API-based Agents
ShortcutsBench:一个基于API的代理的大规模真实世界基准
文章解读: ShortcutsBench:一个基于API的代理的大规模真实世界基准
http://www.studyai.com/xueshu/paper/detail/8192709882
Understanding Long Videos with Multimodal Language Models
使用多模态语言模型理解长视频
文章解读: 使用多模态语言模型理解长视频
http://www.studyai.com/xueshu/paper/detail/8193060367
Inverse Constitutional AI: Compressing Preferences into Principles
逆宪法人工智能:将偏好压缩为原则
文章解读: 逆宪法人工智能:将偏好压缩为原则
http://www.studyai.com/xueshu/paper/detail/8211535593
RB-Modulation: Training-Free Stylization using Reference-Based Modulation
基于参考的调制:无需训练的风格化
文章解读: 基于参考的调制:无需训练的风格化
http://www.studyai.com/xueshu/paper/detail/8212091577
Multi-Scale Fusion for Object Representation
多尺度融合用于对象表示
文章解读: 多尺度融合用于对象表示
http://www.studyai.com/xueshu/paper/detail/8225261597
SPORTU: A Comprehensive Sports Understanding Benchmark for Multimodal Large Language Models
SPORTU:面向多模态大语言模型的全面体育理解基准
文章解读: SPORTU:面向多模态大语言模型的全面体育理解基准
http://www.studyai.com/xueshu/paper/detail/8227720889
ViBiDSampler: Enhancing Video Interpolation Using Bidirectional Diffusion Sampler
ViBiDSampler:利用双向扩散采样器增强视频插值
文章解读: ViBiDSampler:利用双向扩散采样器增强视频插值
http://www.studyai.com/xueshu/paper/detail/8238718217
Benchmarking Agentic Workflow Generation
基准测试代理式工作流生成
文章解读: 基准测试代理式工作流生成
http://www.studyai.com/xueshu/paper/detail/8257232902
MQuAKE-Remastered: Multi-Hop Knowledge Editing Can Only Be Advanced with Reliable Evaluations
MQuAKE-Remastered:多跳知识编辑只能依靠可靠的评估才能进步
文章解读: MQuAKE-Remastered:多跳知识编辑只能依靠可靠的评估才能进步
http://www.studyai.com/xueshu/paper/detail/8259558628
GOAL: A Generalist Combinatorial Optimization Agent Learner
目标:一个通用的组合优化代理学习器
文章解读: 目标:一个通用的组合优化代理学习器
http://www.studyai.com/xueshu/paper/detail/8259760526
GraphArena: Evaluating and Exploring Large Language Models on Graph Computation
GraphArena:在图计算上评估和探索大语言模型
文章解读: GraphArena:在图计算上评估和探索大语言模型
http://www.studyai.com/xueshu/paper/detail/8261522727
MMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models
MMDT:解码多模态基础模型的可信度和安全性
文章解读: MMDT:解码多模态基础模型的可信度和安全性
http://www.studyai.com/xueshu/paper/detail/8261696911
Adaptive Shrinkage Estimation for Personalized Deep Kernel Regression in Modeling Brain Trajectories
个性化深度核回归中脑轨迹建模的自适应收缩估计
文章解读: 个性化深度核回归中脑轨迹建模的自适应收缩估计
http://www.studyai.com/xueshu/paper/detail/8263359856
GraphBridge: Towards Arbitrary Transfer Learning in GNNs
图桥:面向GNNs的任意迁移学习
文章解读: 图桥:面向GNNs的任意迁移学习
http://www.studyai.com/xueshu/paper/detail/8268799203
Residual-MPPI: Online Policy Customization for Continuous Control
残差-MPPI:连续控制中的在线策略定制
文章解读: 残差-MPPI:连续控制中的在线策略定制
http://www.studyai.com/xueshu/paper/detail/8271551030
Atomas: Hierarchical Adaptive Alignment on Molecule-Text for Unified Molecule Understanding and Generation
Atomas:分子-文本层次自适应对齐,用于统一分子理解与生成
文章解读: Atomas:分子-文本层次自适应对齐,用于统一分子理解与生成
http://www.studyai.com/xueshu/paper/detail/8280396911
Density estimation with LLMs: a geometric investigation of in-context learning trajectories
使用LLMs进行密度估计:对情境学习轨迹的几何研究
文章解读: 使用LLMs进行密度估计:对情境学习轨迹的几何研究
http://www.studyai.com/xueshu/paper/detail/8282879513
6DGS: Enhanced Direction-Aware Gaussian Splatting for Volumetric Rendering
6DGS:增强方向感知高斯喷溅用于体素渲染
文章解读: 6DGS:增强方向感知高斯喷溅用于体素渲染
http://www.studyai.com/xueshu/paper/detail/8290316002
Understanding Matrix Function Normalizations in Covariance Pooling through the Lens of Riemannian Geometry
通过黎曼几何视角理解协方差池化中的矩阵函数归一化
文章解读: 通过黎曼几何视角理解协方差池化中的矩阵函数归一化
http://www.studyai.com/xueshu/paper/detail/8298938385
Self-play with Execution Feedback: Improving Instruction-following Capabilities of Large Language Models
使用执行反馈进行自我博弈:提升大语言模型的指令跟随能力
文章解读: 使用执行反馈进行自我博弈:提升大语言模型的指令跟随能力
http://www.studyai.com/xueshu/paper/detail/8316750510
Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models
动态专家混合:高效Transformer模型的自调方法
文章解读: 动态专家混合:高效Transformer模型的自调方法
http://www.studyai.com/xueshu/paper/detail/8318687513
AgentSquare: Automatic LLM Agent Search in Modular Design Space
AgentSquare:模块化设计空间中自动LLM代理搜索
文章解读: AgentSquare:模块化设计空间中自动LLM代理搜索
http://www.studyai.com/xueshu/paper/detail/8329352012
Flat Reward in Policy Parameter Space Implies Robust Reinforcement Learning
在策略参数空间中的平坦奖励意味着鲁棒的强化学习
文章解读: 在策略参数空间中的平坦奖励意味着鲁棒的强化学习
http://www.studyai.com/xueshu/paper/detail/8331810319
Causal Discovery via Bayesian Optimization
基于贝叶斯优化的因果发现
文章解读: 基于贝叶斯优化的因果发现
http://www.studyai.com/xueshu/paper/detail/8358856167
Mix-LN: Unleashing the Power of Deeper Layers by Combining Pre-LN and Post-LN
Mix-LN:通过结合预LN和后LN释放更深层的力量
文章解读: Mix-LN:通过结合预LN和后LN释放更深层的力量
http://www.studyai.com/xueshu/paper/detail/8362680028
SG-I2V: Self-Guided Trajectory Control in Image-to-Video Generation
SG-I2V:图像到视频生成中的自引导轨迹控制
文章解读: SG-I2V:图像到视频生成中的自引导轨迹控制
http://www.studyai.com/xueshu/paper/detail/8363966165
Jailbreaking Leading Safety-Aligned LLMs with Simple Adaptive Attacks
使用简单自适应攻击破解主要安全对齐的大语言模型
文章解读: 使用简单自适应攻击破解主要安全对齐的大语言模型
http://www.studyai.com/xueshu/paper/detail/8391000105
WorkflowLLM: Enhancing Workflow Orchestration Capability of Large Language Models
WorkflowLLM:增强大语言模型的工作流编排能力
文章解读: WorkflowLLM:增强大语言模型的工作流编排能力
http://www.studyai.com/xueshu/paper/detail/8393925972
Robust Weight Initialization for Tanh Neural Networks with Fixed Point Analysis
针对Tanh神经网络的鲁棒权重初始化与定点分析
文章解读: 针对Tanh神经网络的鲁棒权重初始化与定点分析
http://www.studyai.com/xueshu/paper/detail/8397888285
DelTA: An Online Document-Level Translation Agent Based on Multi-Level Memory
DelTA:一种基于多级记忆的在线文档级翻译代理
文章解读: DelTA:一种基于多级记忆的在线文档级翻译代理
http://www.studyai.com/xueshu/paper/detail/8508369997
HiRA: Parameter-Efficient Hadamard High-Rank Adaptation for Large Language Models
HiRA:参数高效的Hadamard高秩自适应方法用于大语言模型
文章解读: HiRA:参数高效的Hadamard高秩自适应方法用于大语言模型
http://www.studyai.com/xueshu/paper/detail/8525727930
CollabEdit: Towards Non-destructive Collaborative Knowledge Editing
CollabEdit:迈向非破坏性协作知识编辑
文章解读: CollabEdit:迈向非破坏性协作知识编辑
http://www.studyai.com/xueshu/paper/detail/8528535190
COFlowNet: Conservative Constraints on Flows Enable High-Quality Candidate Generation
COFlowNet:保守约束在流上实现高质量候选生成
文章解读: COFlowNet:保守约束在流上实现高质量候选生成
http://www.studyai.com/xueshu/paper/detail/8559382309
Making Text Embedders Few-Shot Learners
使文本嵌入器成为小样本学习者
文章解读: 使文本嵌入器成为小样本学习者
http://www.studyai.com/xueshu/paper/detail/8562633018
A Transfer Attack to Image Watermarks
针对图像水印的迁移攻击
文章解读: 针对图像水印的迁移攻击
http://www.studyai.com/xueshu/paper/detail/8568639273
SplatFormer: Point Transformer for Robust 3D Gaussian Splatting
SplatFormer:用于鲁棒3D高斯喷溅的点变换器
文章解读: SplatFormer:用于鲁棒3D高斯喷溅的点变换器
http://www.studyai.com/xueshu/paper/detail/8573588769
Projection Head is Secretly an Information Bottleneck
投影头实际上是信息瓶颈
文章解读: 投影头实际上是信息瓶颈
http://www.studyai.com/xueshu/paper/detail/8588913807
Slot-Guided Adaptation of Pre-trained Diffusion Models for Object-Centric Learning and Compositional Generation
基于槽位引导的预训练扩散模型在以对象为中心的学习和组合生成中的应用
文章解读: 基于槽位引导的预训练扩散模型在以对象为中心的学习和组合生成中的应用
http://www.studyai.com/xueshu/paper/detail/8602795827
Implicit Search via Discrete Diffusion: A Study on Chess
通过离散扩散进行隐式搜索:对国际象棋的研究
文章解读: 通过离散扩散进行隐式搜索:对国际象棋的研究
http://www.studyai.com/xueshu/paper/detail/8617898099
Bootstrapped Model Predictive Control
自举模型预测控制
文章解读: 自举模型预测控制
http://www.studyai.com/xueshu/paper/detail/8622799252
Solving Video Inverse Problems Using Image Diffusion Models
使用图像扩散模型解决视频逆问题
文章解读: 使用图像扩散模型解决视频逆问题
http://www.studyai.com/xueshu/paper/detail/8626782886
NutriBench: A Dataset for Evaluating Large Language Models in Nutrition Estimation from Meal Descriptions
NutriBench:一个用于评估从餐食描述中估计营养的大语言模型的数据库
文章解读: NutriBench:一个用于评估从餐食描述中估计营养的大语言模型的数据库
http://www.studyai.com/xueshu/paper/detail/8633281093
Exponential Topology-enabled Scalable Communication in Multi-agent Reinforcement Learning
基于指数拓扑的可扩展通信在多智能体强化学习中
文章解读: 基于指数拓扑的可扩展通信在多智能体强化学习中
http://www.studyai.com/xueshu/paper/detail/8636376756
Generalized Consistency Trajectory Models for Image Manipulation
图像操作的广义一致性轨迹模型
文章解读: 图像操作的广义一致性轨迹模型
http://www.studyai.com/xueshu/paper/detail/8655626857
The Belief State Transformer
信念状态转换器
文章解读: 信念状态转换器
http://www.studyai.com/xueshu/paper/detail/8660215919
FlashRNN: I/O-Aware Optimization of Traditional RNNs on modern hardware
FlashRNN:面向现代硬件的传统RNN的I/O感知优化
文章解读: FlashRNN:面向现代硬件的传统RNN的I/O感知优化
http://www.studyai.com/xueshu/paper/detail/8660578211
SqueezeAttention: 2D Management of KV-Cache in LLM Inference via Layer-wise Optimal Budget
SqueezeAttention:通过逐层最优预算对LLM推理中的KV缓存进行二维管理
文章解读: SqueezeAttention:通过逐层最优预算对LLM推理中的KV缓存进行二维管理
http://www.studyai.com/xueshu/paper/detail/8666109290
SafeWatch: An Efficient Safety-Policy Following Video Guardrail Model with Transparent Explanations
SafeWatch:一种具有透明解释的、高效的、遵循安全策略的视频护栏模型
文章解读: SafeWatch:一种具有透明解释的、高效的、遵循安全策略的视频护栏模型
http://www.studyai.com/xueshu/paper/detail/8671208761
SimulPL: Aligning Human Preferences in Simultaneous Machine Translation
SimulPL:同步机器翻译中的人类偏好对齐
文章解读: SimulPL:同步机器翻译中的人类偏好对齐
http://www.studyai.com/xueshu/paper/detail/8672765563
ProtoSnap: Prototype Alignment For Cuneiform Signs
ProtoSnap:楔形文字原型的对齐
文章解读: ProtoSnap:楔形文字原型的对齐
http://www.studyai.com/xueshu/paper/detail/8673356397
PN-GAIL: Leveraging Non-optimal Information from Imperfect Demonstrations
PN-GAIL:利用不完美演示中的非最优信息
文章解读: PN-GAIL:利用不完美演示中的非最优信息
http://www.studyai.com/xueshu/paper/detail/8685598811
A Spark of Vision-Language Intelligence: 2-Dimensional Autoregressive Transformer for Efficient Finegrained Image Generation
一点视觉语言智能之光:二维自回归Transformer用于高效细粒度图像生成
文章解读: 一点视觉语言智能之光:二维自回归Transformer用于高效细粒度图像生成
http://www.studyai.com/xueshu/paper/detail/8687951571
Catastrophic Failure of LLM Unlearning via Quantization
量化导致的LLM去学习灾难性失败
文章解读: 量化导致的LLM去学习灾难性失败
http://www.studyai.com/xueshu/paper/detail/8689839687
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
AndroidWorld:自主代理的动态基准测试环境
文章解读: AndroidWorld:自主代理的动态基准测试环境
http://www.studyai.com/xueshu/paper/detail/8695355507
OmniKV: Dynamic Context Selection for Efficient Long-Context LLMs
OmniKV:针对高效长上下文LLMs的动态上下文选择
文章解读: OmniKV:针对高效长上下文LLMs的动态上下文选择
http://www.studyai.com/xueshu/paper/detail/8696296593
FOSP: Fine-tuning Offline Safe Policy through World Models
FOSP:通过世界模型微调离线安全策略
文章解读: FOSP:通过世界模型微调离线安全策略
http://www.studyai.com/xueshu/paper/detail/8701033237
Hierarchical World Models as Visual Whole-Body Humanoid Controllers
分层世界模型作为视觉全身人形控制器
文章解读: 分层世界模型作为视觉全身人形控制器
http://www.studyai.com/xueshu/paper/detail/8717537731
HyperFace: Generating Synthetic Face Recognition Datasets by Exploring Face Embedding Hypersphere
HyperFace:通过探索人脸嵌入超球面生成合成人脸识别数据集
文章解读: HyperFace:通过探索人脸嵌入超球面生成合成人脸识别数据集
http://www.studyai.com/xueshu/paper/detail/8722725001
IterComp: Iterative Composition-Aware Feedback Learning from Model Gallery for Text-to-Image Generation
IterComp:从模型库中进行迭代式构图感知反馈学习以生成文本到图像
文章解读: IterComp:从模型库中进行迭代式构图感知反馈学习以生成文本到图像
http://www.studyai.com/xueshu/paper/detail/8728797118
BLEND: Behavior-guided Neural Population Dynamics Modeling via Privileged Knowledge Distillation
BLEND:基于特权知识蒸馏的行为引导神经群体动力学建模
文章解读: BLEND:基于特权知识蒸馏的行为引导神经群体动力学建模
http://www.studyai.com/xueshu/paper/detail/8733931817
Dense Video Object Captioning from Disjoint Supervision
基于分离监督的密集视频对象描述
文章解读: 基于分离监督的密集视频对象描述
http://www.studyai.com/xueshu/paper/detail/8763580337
Medium-Difficulty Samples Constitute Smoothed Decision Boundary for Knowledge Distillation on Pruned Datasets
中等难度样本构成剪枝数据集上知识蒸馏的平滑决策边界
文章解读: 中等难度样本构成剪枝数据集上知识蒸馏的平滑决策边界
http://www.studyai.com/xueshu/paper/detail/8766752958
Learning a Fast Mixing Exogenous Block MDP using a Single Trajectory
使用单个轨迹学习快速混合外生块MDP
文章解读: 使用单个轨迹学习快速混合外生块MDP
http://www.studyai.com/xueshu/paper/detail/8767923170
Robots Pre-train Robots: Manipulation-Centric Robotic Representation from Large-Scale Robot Datasets
机器人预训练机器人:基于大规模机器人数据集的以操作为中心的机器人表示
文章解读: 机器人预训练机器人:基于大规模机器人数据集的以操作为中心的机器人表示
http://www.studyai.com/xueshu/paper/detail/8776615277
JPEG Inspired Deep Learning
基于JPEG的深度学习
文章解读: 基于JPEG的深度学习
http://www.studyai.com/xueshu/paper/detail/8786759612
A Closer Look at Machine Unlearning for Large Language Models
对大语言模型的机器卸载进行深入探讨
文章解读: 对大语言模型的机器卸载进行深入探讨
http://www.studyai.com/xueshu/paper/detail/8787798659
An Exploration with Entropy Constrained 3D Gaussians for 2D Video Compression
基于熵约束3D高斯模型对2D视频压缩的探索
文章解读: 基于熵约束3D高斯模型对2D视频压缩的探索
http://www.studyai.com/xueshu/paper/detail/8788339967
DECO: Unleashing the Potential of ConvNets for Query-based Detection and Segmentation
DECO:释放卷积神经网络在基于查询的检测和分割中的潜力
文章解读: DECO:释放卷积神经网络在基于查询的检测和分割中的潜力
http://www.studyai.com/xueshu/paper/detail/8788393936
What Secrets Do Your Manifolds Hold? Understanding the Local Geometry of Generative Models
你的流形隐藏着什么秘密?理解生成模型的本体几何
文章解读: 你的流形隐藏着什么秘密?理解生成模型的本体几何
http://www.studyai.com/xueshu/paper/detail/8792156786
Energy-Based Diffusion Language Models for Text Generation
基于能量的扩散语言模型用于文本生成
文章解读: 基于能量的扩散语言模型用于文本生成
http://www.studyai.com/xueshu/paper/detail/8797658615
Towards Fast, Specialized Machine Learning Force Fields: Distilling Foundation Models via Energy Hessians
面向快速、专业的机器学习力场:通过能量Hessian蒸馏基础模型
文章解读: 面向快速、专业的机器学习力场:通过能量Hessian蒸馏基础模型
http://www.studyai.com/xueshu/paper/detail/8799383339
High-Precision Dichotomous Image Segmentation via Probing Diffusion Capacity
高精度二值图像分割方法:探测扩散能力
文章解读: 高精度二值图像分割方法:探测扩散能力
http://www.studyai.com/xueshu/paper/detail/8802176198
Understanding the Stability-based Generalization of Personalized Federated Learning
理解基于稳定性的个性化联邦学习泛化
文章解读: 理解基于稳定性的个性化联邦学习泛化
http://www.studyai.com/xueshu/paper/detail/8803729015
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
双注意力机制:结合检索和流式头的长上下文LLM高效推理
文章解读: 双注意力机制:结合检索和流式头的长上下文LLM高效推理
http://www.studyai.com/xueshu/paper/detail/8805693181
SWIFT: On-the-Fly Self-Speculative Decoding for LLM Inference Acceleration
SWIFT:用于LLM推理加速的即时自推测解码
文章解读: SWIFT:用于LLM推理加速的即时自推测解码
http://www.studyai.com/xueshu/paper/detail/8818527032
Transition Path Sampling with Improved Off-Policy Training of Diffusion Path Samplers
基于改进的扩散路径采样器的离线策略训练的转换路径采样
文章解读: 基于改进的扩散路径采样器的离线策略训练的转换路径采样
http://www.studyai.com/xueshu/paper/detail/8829012392
Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models
用眼饱餐:多模态大语言模型的混合分辨率适应方法
文章解读: 用眼饱餐:多模态大语言模型的混合分辨率适应方法
http://www.studyai.com/xueshu/paper/detail/8830822219
Accelerating Neural ODEs: A Variational Formulation-based Approach
加速神经常微分方程:基于变分公式的Approach
文章解读: 加速神经常微分方程:基于变分公式的Approach
http://www.studyai.com/xueshu/paper/detail/8830869737
Hummingbird: High Fidelity Image Generation via Multimodal Context Alignment
蜂鸟:通过多模态上下文对齐实现高保真图像生成
文章解读: 蜂鸟:通过多模态上下文对齐实现高保真图像生成
http://www.studyai.com/xueshu/paper/detail/8836007832
InsightBench: Evaluating Business Analytics Agents Through Multi-Step Insight Generation
InsightBench:通过多步洞察生成评估商业分析代理
文章解读: InsightBench:通过多步洞察生成评估商业分析代理
http://www.studyai.com/xueshu/paper/detail/8857301320
Spreading Out-of-Distribution Detection on Graphs
在图上扩展分布外检测
文章解读: 在图上扩展分布外检测
http://www.studyai.com/xueshu/paper/detail/8860527218
LR0.FM: Low-Res Benchmark and Improving robustness for Zero-Shot Classification in Foundation Models
LR0.FM:低分辨率基准测试及改进基础模型在零样本分类中的鲁棒性
文章解读: LR0.FM:低分辨率基准测试及改进基础模型在零样本分类中的鲁棒性
http://www.studyai.com/xueshu/paper/detail/8876790108
Simple, Good, Fast: Self-Supervised World Models Free of Baggage
简单、优秀、快速:无负担的自监督世界模型
文章解读: 简单、优秀、快速:无负担的自监督世界模型
http://www.studyai.com/xueshu/paper/detail/8881060597
Reconstruction-Guided Policy: Enhancing Decision-Making through Agent-Wise State Consistency
重建引导策略:通过智能体状态一致性增强决策制定
文章解读: 重建引导策略:通过智能体状态一致性增强决策制定
http://www.studyai.com/xueshu/paper/detail/8892793053
Zigzag Diffusion Sampling: Diffusion Models Can Self-Improve via Self-Reflection
Z字形扩散采样:扩散模型可通过自我反思实现自我改进
文章解读: Z字形扩散采样:扩散模型可通过自我反思实现自我改进
http://www.studyai.com/xueshu/paper/detail/8895673197
Advantage-Guided Distillation for Preference Alignment in Small Language Models
基于优势引导的蒸馏在小语言模型中的偏好对齐
文章解读: 基于优势引导的蒸馏在小语言模型中的偏好对齐
http://www.studyai.com/xueshu/paper/detail/8897738693
Think-on-Graph 2.0: Deep and Faithful Large Language Model Reasoning with Knowledge-guided Retrieval Augmented Generation
Think-on-Graph 2.0:基于知识引导检索增强生成的深度与忠实的大语言模型推理
文章解读: Think-on-Graph 2.0:基于知识引导检索增强生成的深度与忠实的大语言模型推理
http://www.studyai.com/xueshu/paper/detail/8910105923
U-shaped and Inverted-U Scaling behind Emergent Abilities of Large Language Models
大语言模型涌现能力背后的U形和倒U形缩放
文章解读: 大语言模型涌现能力背后的U形和倒U形缩放
http://www.studyai.com/xueshu/paper/detail/8917131356
GALA: Geometry-Aware Local Adaptive Grids for Detailed 3D Generation
GALA:感知几何的局部自适应网格,用于精细3D生成
文章解读: GALA:感知几何的局部自适应网格,用于精细3D生成
http://www.studyai.com/xueshu/paper/detail/8927163222
Image Watermarks are Removable using Controllable Regeneration from Clean Noise
图像水印可以通过从干净噪声的可控再生中移除
文章解读: 图像水印可以通过从干净噪声的可控再生中移除
http://www.studyai.com/xueshu/paper/detail/8928883996
STORM: Spatio-TempOral Reconstruction Model For Large-Scale Outdoor Scenes
STORM:用于大规模户外场景的时空重建模型
文章解读: STORM:用于大规模户外场景的时空重建模型
http://www.studyai.com/xueshu/paper/detail/8930570335
Rodimus*: Breaking the Accuracy-Efficiency Trade-Off with Efficient Attentions
罗迪厄斯*:通过高效注意力打破准确率-效率权衡
文章解读: 罗迪厄斯*:通过高效注意力打破准确率-效率权衡
http://www.studyai.com/xueshu/paper/detail/8952251926
API Pack: A Massive Multi-Programming Language Dataset for API Call Generation
API Pack:一个用于API调用生成的海量多编程语言数据集
文章解读: API Pack:一个用于API调用生成的海量多编程语言数据集
http://www.studyai.com/xueshu/paper/detail/8952778139
DGQ: Distribution-Aware Group Quantization for Text-to-Image Diffusion Models
DGQ:面向文本到图像扩散模型的分布感知分组量化
文章解读: DGQ:面向文本到图像扩散模型的分布感知分组量化
http://www.studyai.com/xueshu/paper/detail/8956836505
MM-EMBED: UNIVERSAL MULTIMODAL RETRIEVAL WITH MULTIMODAL LLMS
MM-EMBED:通用多模态检索与多模态LLM
文章解读: MM-EMBED:通用多模态检索与多模态LLM
http://www.studyai.com/xueshu/paper/detail/8960563296
ESE: Espresso Sentence Embeddings
ESE:意式浓缩句子嵌入
文章解读: ESE:意式浓缩句子嵌入
http://www.studyai.com/xueshu/paper/detail/8962578220
Cheating Automatic LLM Benchmarks: Null Models Achieve High Win Rates
欺骗自动LLM基准测试:零模型获得高胜率
文章解读: 欺骗自动LLM基准测试:零模型获得高胜率
http://www.studyai.com/xueshu/paper/detail/8968353250
TULIP: Token-length Upgraded CLIP
TULIP:基于token长度的改进型CLIP
文章解读: TULIP:基于token长度的改进型CLIP
http://www.studyai.com/xueshu/paper/detail/8985196108
Be More Diverse than the Most Diverse: Optimal Mixtures of Generative Models via Mixture-UCB Bandit Algorithms
比最多样化更多样化:通过混合UCB bandit算法实现生成模型的最佳组合
文章解读: 比最多样化更多样化:通过混合UCB bandit算法实现生成模型的最佳组合
http://www.studyai.com/xueshu/paper/detail/8985298690
Diffusion Bridge AutoEncoders for Unsupervised Representation Learning
用于无监督表征学习的扩散桥自动编码器
文章解读: 用于无监督表征学习的扩散桥自动编码器
http://www.studyai.com/xueshu/paper/detail/8988350187
ClimaQA: An Automated Evaluation Framework for Climate Question Answering Models
ClimaQA:一种用于气候问答模型的自动化评估框架
文章解读: ClimaQA:一种用于气候问答模型的自动化评估框架
http://www.studyai.com/xueshu/paper/detail/9018796118
Proximal Mapping Loss: Understanding Loss Functions in Crowd Counting & Localization
邻近映射损失:理解人群计数与定位中的损失函数
文章解读: 邻近映射损失:理解人群计数与定位中的损失函数
http://www.studyai.com/xueshu/paper/detail/9022832916
ColPali: Efficient Document Retrieval with Vision Language Models
ColPali:基于视觉语言模型的文档高效检索
文章解读: ColPali:基于视觉语言模型的文档高效检索
http://www.studyai.com/xueshu/paper/detail/9028306667
BitStack: Any-Size Compression of Large Language Models in Variable Memory Environments
BitStack:在可变内存环境中对大语言模型进行任意大小压缩
文章解读: BitStack:在可变内存环境中对大语言模型进行任意大小压缩
http://www.studyai.com/xueshu/paper/detail/9052137165
Agent-Oriented Planning in Multi-Agent Systems
面向代理的规划在多智能体系统中
文章解读: 面向代理的规划在多智能体系统中
http://www.studyai.com/xueshu/paper/detail/9053702978
Boltzmann-Aligned Inverse Folding Model as a Predictor of Mutational Effects on Protein-Protein Interactions
玻尔兹曼对齐的逆向折叠模型作为预测蛋白质-蛋白质相互作用突变效应的预测模型
文章解读: 玻尔兹曼对齐的逆向折叠模型作为预测蛋白质-蛋白质相互作用突变效应的预测模型
http://www.studyai.com/xueshu/paper/detail/9060389277
Text-to-Image Rectified Flow as Plug-and-Play Priors
文本到图像的整流流作为即插即用的先验
文章解读: 文本到图像的整流流作为即插即用的先验
http://www.studyai.com/xueshu/paper/detail/9068807666
Fine-Grained Verifiers: Preference Modeling as Next-token Prediction in Vision-Language Alignment
细粒度验证器:在视觉-语言对齐中,偏好建模作为下一词预测
文章解读: 细粒度验证器:在视觉-语言对齐中,偏好建模作为下一词预测
http://www.studyai.com/xueshu/paper/detail/9069117958
Watermark Anything With Localized Messages
使用本地化信息为任何内容添加水印
文章解读: 使用本地化信息为任何内容添加水印
http://www.studyai.com/xueshu/paper/detail/9069627289
Training-Free Diffusion Model Alignment with Sampling Demons
无训练扩散模型对齐与采样恶魔
文章解读: 无训练扩散模型对齐与采样恶魔
http://www.studyai.com/xueshu/paper/detail/9078025871
Is Large-scale Pretraining the Secret to Good Domain Generalization?
大规模预训练是领域泛化的秘诀吗?
文章解读: 大规模预训练是领域泛化的秘诀吗?
http://www.studyai.com/xueshu/paper/detail/9080538960
Train Small, Infer Large: Memory-Efficient LoRA Training for Large Language Models
小规模训练,大规模推理:适用于大语言模型的内存高效LoRA训练
文章解读: 小规模训练,大规模推理:适用于大语言模型的内存高效LoRA训练
http://www.studyai.com/xueshu/paper/detail/9085136150
LoRanPAC: Low-rank Random Features and Pre-trained Models for Bridging Theory and Practice in Continual Learning
LoRanPAC:低秩随机特征和预训练模型,用于连接持续学习中的理论与实践
文章解读: LoRanPAC:低秩随机特征和预训练模型,用于连接持续学习中的理论与实践
http://www.studyai.com/xueshu/paper/detail/9085952633
Boltzmann priors for Implicit Transfer Operators
隐式转移算子的玻尔兹曼先验
文章解读: 隐式转移算子的玻尔兹曼先验
http://www.studyai.com/xueshu/paper/detail/9086180179
Agent S: An Open Agentic Framework that Uses Computers Like a Human
代理S:一个像人类一样使用计算机的开源智能框架
文章解读: 代理S:一个像人类一样使用计算机的开源智能框架
http://www.studyai.com/xueshu/paper/detail/9088907769
MMR: A Large-scale Benchmark Dataset for Multi-target and Multi-granularity Reasoning Segmentation
MMR:面向多目标多粒度推理分割的大规模基准数据集
文章解读: MMR:面向多目标多粒度推理分割的大规模基准数据集
http://www.studyai.com/xueshu/paper/detail/9095562768
Learning system dynamics without forgetting
在不遗忘的情况下学习系统动力学
文章解读: 在不遗忘的情况下学习系统动力学
http://www.studyai.com/xueshu/paper/detail/9096003022
Moner: Motion Correction in Undersampled Radial MRI with Unsupervised Neural Representation
Moner:非监督神经表征在欠采样径向MRI中的运动校正
文章解读: Moner:非监督神经表征在欠采样径向MRI中的运动校正
http://www.studyai.com/xueshu/paper/detail/9106575367
Breaking the Reclustering Barrier in Centroid-based Deep Clustering
基于质心的深度聚类中的重聚类障碍突破
文章解读: 基于质心的深度聚类中的重聚类障碍突破
http://www.studyai.com/xueshu/paper/detail/9111036031
VL-ICL Bench: The Devil in the Details of Multimodal In-Context Learning
VL-ICL基准:多模态情境学习的细节之魔鬼
文章解读: VL-ICL基准:多模态情境学习的细节之魔鬼
http://www.studyai.com/xueshu/paper/detail/9115156991
From Pixels to Tokens: Byte-Pair Encoding on Quantized Visual Modalities
从像素到标记:量化视觉模态的二元对齐编码
文章解读: 从像素到标记:量化视觉模态的二元对齐编码
http://www.studyai.com/xueshu/paper/detail/9130687306
RAPID: Retrieval Augmented Training of Differentially Private Diffusion Models
RAPID:差分隐私扩散模型的检索增强训练
文章解读: RAPID:差分隐私扩散模型的检索增强训练
http://www.studyai.com/xueshu/paper/detail/9133188636
Adversarial Score identity Distillation: Rapidly Surpassing the Teacher in One Step
对抗得分身份蒸馏:一步之内迅速超越导师
文章解读: 对抗得分身份蒸馏:一步之内迅速超越导师
http://www.studyai.com/xueshu/paper/detail/9137800885
Streamlining Redundant Layers to Compress Large Language Models
精简冗余层以压缩大语言模型
文章解读: 精简冗余层以压缩大语言模型
http://www.studyai.com/xueshu/paper/detail/9186363327
Sports-Traj: A Unified Trajectory Generation Model for Multi-Agent Movement in Sports
Sports-Traj:一种用于体育中多智能体运动的统一轨迹生成模型
文章解读: Sports-Traj:一种用于体育中多智能体运动的统一轨迹生成模型
http://www.studyai.com/xueshu/paper/detail/9200130852
CATCH: Channel-Aware Multivariate Time Series Anomaly Detection via Frequency Patching
CATCH:频谱块感知多元时间序列异常检测
文章解读: CATCH:频谱块感知多元时间序列异常检测
http://www.studyai.com/xueshu/paper/detail/9211851185
NExT-Mol: 3D Diffusion Meets 1D Language Modeling for 3D Molecule Generation
NExT-Mol:3D扩散与1D语言模型结合用于3D分子生成
文章解读: NExT-Mol:3D扩散与1D语言模型结合用于3D分子生成
http://www.studyai.com/xueshu/paper/detail/9221377127
SyllableLM: Learning Coarse Semantic Units for Speech Language Models
SyllableLM:为语音语言模型学习粗粒度语义单元
文章解读: SyllableLM:为语音语言模型学习粗粒度语义单元
http://www.studyai.com/xueshu/paper/detail/9256180667
TopoNets: High performing vision and language models with brain-like topography
TopoNets:具有类脑拓扑结构的高性能视觉和语言模型
文章解读: TopoNets:具有类脑拓扑结构的高性能视觉和语言模型
http://www.studyai.com/xueshu/paper/detail/9258022225
Tree of Attributes Prompt Learning for Vision-Language Models
基于属性树的视觉-语言模型提示学习
文章解读: 基于属性树的视觉-语言模型提示学习
http://www.studyai.com/xueshu/paper/detail/9259887556
GOFA: A Generative One-For-All Model for Joint Graph Language Modeling
GOFA:一种用于联合图语言建模的生成式One-For-All模型
文章解读: GOFA:一种用于联合图语言建模的生成式One-For-All模型
http://www.studyai.com/xueshu/paper/detail/9266586681
When Prompt Engineering Meets Software Engineering: CNL-P as Natural and Robust "APIs’’ for Human-AI Interaction
当提示工程遇见软件工程:CNL-P作为自然且鲁棒的“API”用于人机交互
文章解读: 当提示工程遇见软件工程:CNL-P作为自然且鲁棒的“API”用于人机交互
http://www.studyai.com/xueshu/paper/detail/9269006623
Enhancing Pre-trained Representation Classifiability can Boost its Interpretability
增强预训练表示的可分类性可以提升其可解释性
文章解读: 增强预训练表示的可分类性可以提升其可解释性
http://www.studyai.com/xueshu/paper/detail/9298198017
Montessori-Instruct: Generate Influential Training Data Tailored for Student Learning
蒙台梭利教学:生成针对学生学习定制的影响性训练数据
文章解读: 蒙台梭利教学:生成针对学生学习定制的影响性训练数据
http://www.studyai.com/xueshu/paper/detail/9301529185
GReaTer: Gradients Over Reasoning Makes Smaller Language Models Strong Prompt Optimizers
GReaTer:推理梯度使更小的语言模型成为强大的提示优化器
文章解读: GReaTer:推理梯度使更小的语言模型成为强大的提示优化器
http://www.studyai.com/xueshu/paper/detail/9312135738
Think Thrice Before You Act: Progressive Thought Refinement in Large Language Models
三思而后行:大语言模型中的渐进式思维完善
文章解读: 三思而后行:大语言模型中的渐进式思维完善
http://www.studyai.com/xueshu/paper/detail/9351115832
ThinK: Thinner Key Cache by Query-Driven Pruning
Think:通过查询驱动剪枝实现更薄的键缓存
文章解读: Think:通过查询驱动剪枝实现更薄的键缓存
http://www.studyai.com/xueshu/paper/detail/9353176689
An Undetectable Watermark for Generative Image Models
一种用于生成图像模型的不可检测水印
文章解读: 一种用于生成图像模型的不可检测水印
http://www.studyai.com/xueshu/paper/detail/9355620958
VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents
VisualAgentBench:迈向作为视觉基础智能体的多模态大型模型
文章解读: VisualAgentBench:迈向作为视觉基础智能体的多模态大型模型
http://www.studyai.com/xueshu/paper/detail/9360380778
SpinQuant: LLM Quantization with Learned Rotations
SpinQuant:基于学习旋转的LLM量化
文章解读: SpinQuant:基于学习旋转的LLM量化
http://www.studyai.com/xueshu/paper/detail/9361109297
InfoGS: Efficient Structure-Aware 3D Gaussians via Lightweight Information Shaping
InfoGS:基于轻量级信息塑形的结构感知高效3D高斯
文章解读: InfoGS:基于轻量级信息塑形的结构感知高效3D高斯
http://www.studyai.com/xueshu/paper/detail/9362115272
Stem-OB: Generalizable Visual Imitation Learning with Stem-Like Convergent Observation through Diffusion Inversion
Stem-OB:通过扩散反转实现类似主干式的收敛观察,从而实现可泛化的视觉模仿学习
文章解读: Stem-OB:通过扩散反转实现类似主干式的收敛观察,从而实现可泛化的视觉模仿学习
http://www.studyai.com/xueshu/paper/detail/9362171587
FreDF: Learning to Forecast in the Frequency Domain
FreDF:学习频域预测
文章解读: FreDF:学习频域预测
http://www.studyai.com/xueshu/paper/detail/9371931302
Linear Partial Gromov-Wasserstein Embedding
线性部分Gromov-Wasserstein嵌入
文章解读: 线性部分Gromov-Wasserstein嵌入
http://www.studyai.com/xueshu/paper/detail/9375606768
Multiview Equivariance Improves 3D Correspondence Understanding with Minimal Feature Finetuning
多视角等变性通过最小特征微调提升三维对应理解
文章解读: 多视角等变性通过最小特征微调提升三维对应理解
http://www.studyai.com/xueshu/paper/detail/9380709560
Advancing Graph Generation through Beta Diffusion
通过Beta扩散推进图生成
文章解读: 通过Beta扩散推进图生成
http://www.studyai.com/xueshu/paper/detail/9382805689
Shape as Line Segments: Accurate and Flexible Implicit Surface Representation
形状为线段:精确且灵活的隐式表面表示
文章解读: 形状为线段:精确且灵活的隐式表面表示
http://www.studyai.com/xueshu/paper/detail/9390399083
Rethinking Light Decoder-based Solvers for Vehicle Routing Problems
重新思考基于光解码器的车辆路径问题求解器
文章解读: 重新思考基于光解码器的车辆路径问题求解器
http://www.studyai.com/xueshu/paper/detail/9392390871
Fantastic Targets for Concept Erasure in Diffusion Models and Where To Find Them
扩散模型中概念擦除的绝佳目标及其寻找方法
文章解读: 扩散模型中概念擦除的绝佳目标及其寻找方法
http://www.studyai.com/xueshu/paper/detail/9500366589
PathGen-1.6M: 1.6 Million Pathology Image-text Pairs Generation through Multi-agent Collaboration
PathGen-1.6M:通过多智能体协作生成160万个病理图像-文本对
文章解读: PathGen-1.6M:通过多智能体协作生成160万个病理图像-文本对
http://www.studyai.com/xueshu/paper/detail/9501718212
GoodDrag: Towards Good Practices for Drag Editing with Diffusion Models
GoodDrag:面向基于扩散模型的拖拽编辑的良好实践
文章解读: GoodDrag:面向基于扩散模型的拖拽编辑的良好实践
http://www.studyai.com/xueshu/paper/detail/9502527150
BodyGen: Advancing Towards Efficient Embodiment Co-Design
BodyGen:迈向高效的化身协同设计
文章解读: BodyGen:迈向高效的化身协同设计
http://www.studyai.com/xueshu/paper/detail/9511695028
Efficient and Context-Aware Label Propagation for Zero-/Few-Shot Training-Free Adaptation of Vision-Language Model
高效且上下文感知的标签传播用于视觉-语言模型的零/少样本无训练适应
文章解读: 高效且上下文感知的标签传播用于视觉-语言模型的零/少样本无训练适应
http://www.studyai.com/xueshu/paper/detail/9516733783
SOAP: Improving and Stabilizing Shampoo using Adam for Language Modeling
SOAP:使用Adam改进和稳定洗发水进行语言建模
文章解读: SOAP:使用Adam改进和稳定洗发水进行语言建模
http://www.studyai.com/xueshu/paper/detail/9522237836
NeRAF: 3D Scene Infused Neural Radiance and Acoustic Fields
NeRAF:融合3D场景的神经辐射和声场
文章解读: NeRAF:融合3D场景的神经辐射和声场
http://www.studyai.com/xueshu/paper/detail/9527257273
LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models
LOKI:基于大型多模态模型的综合合成数据检测基准
文章解读: LOKI:基于大型多模态模型的综合合成数据检测基准
http://www.studyai.com/xueshu/paper/detail/9529683509
HAMSTER: Hierarchical Action Models for Open-World Robot Manipulation
HAMSTER:用于开放世界机器人操作的层次化动作模型
文章解读: HAMSTER:用于开放世界机器人操作的层次化动作模型
http://www.studyai.com/xueshu/paper/detail/9555117657
Understanding and Mitigating Bottlenecks of State Space Models through the Lens of Recency and Over-smoothing
通过时效性和过度平滑的视角理解和缓解状态空间模型的瓶颈
文章解读: 通过时效性和过度平滑的视角理解和缓解状态空间模型的瓶颈
http://www.studyai.com/xueshu/paper/detail/9557008321
GravMAD: Grounded Spatial Value Maps Guided Action Diffusion for Generalized 3D Manipulation
GravMAD:基于定位空间价值图的引导行动扩散,用于通用3D操作
文章解读: GravMAD:基于定位空间价值图的引导行动扩散,用于通用3D操作
http://www.studyai.com/xueshu/paper/detail/9560508373
SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency
SV4D:具有多帧和多视图一致性的动态3D内容生成
文章解读: SV4D:具有多帧和多视图一致性的动态3D内容生成
http://www.studyai.com/xueshu/paper/detail/9562956596
SEAL: Safety-enhanced Aligned LLM Fine-tuning via Bilevel Data Selection
SEAL:通过双层数据选择实现安全增强型对齐LLM微调
文章解读: SEAL:通过双层数据选择实现安全增强型对齐LLM微调
http://www.studyai.com/xueshu/paper/detail/9569199351
MTSAM: Multi-Task Fine-Tuning for Segment Anything Model
MTSAM:用于Segment Anything模型的跨任务微调
文章解读: MTSAM:用于Segment Anything模型的跨任务微调
http://www.studyai.com/xueshu/paper/detail/9573172108
Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo
通过序贯蒙特卡洛方法对大语言模型进行句法和语义控制
文章解读: 通过序贯蒙特卡洛方法对大语言模型进行句法和语义控制
http://www.studyai.com/xueshu/paper/detail/9576803751
A Large-scale Training Paradigm for Graph Generative Models
图生成模型的大规模训练范式
文章解读: 图生成模型的大规模训练范式
http://www.studyai.com/xueshu/paper/detail/9578537283
What Matters When Repurposing Diffusion Models for General Dense Perception Tasks?
在将扩散模型应用于通用密集感知任务时,什么才是关键?
文章解读: 在将扩散模型应用于通用密集感知任务时,什么才是关键?
http://www.studyai.com/xueshu/paper/detail/9581775717
Reflexive Guidance: Improving OoDD in Vision-Language Models via Self-Guided Image-Adaptive Concept Generation
反思性指导:通过自我引导图像自适应概念生成提升视觉语言模型的OoDD性能
文章解读: 反思性指导:通过自我引导图像自适应概念生成提升视觉语言模型的OoDD性能
http://www.studyai.com/xueshu/paper/detail/9583232655
Learning Transformer-based World Models with Contrastive Predictive Coding
基于对比预测编码学习Transformer世界模型
文章解读: 基于对比预测编码学习Transformer世界模型
http://www.studyai.com/xueshu/paper/detail/9589760708
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solver
互惠推理使更小的LLM成为更强的解决问题者
文章解读: 互惠推理使更小的LLM成为更强的解决问题者
http://www.studyai.com/xueshu/paper/detail/9619283001
Leveraging Driver Field-of-View for Multimodal Ego-Trajectory Prediction
利用驾驶员视野进行多模态自车轨迹预测
文章解读: 利用驾驶员视野进行多模态自车轨迹预测
http://www.studyai.com/xueshu/paper/detail/9626961651
Improving Semantic Understanding in Speech Language Models via Brain-tuning
通过脑部调谐提升语音语言模型的语义理解能力
文章解读: 通过脑部调谐提升语音语言模型的语义理解能力
http://www.studyai.com/xueshu/paper/detail/9629967219
Circuit Representation Learning with Masked Gate Modeling and Verilog-AIG Alignment
使用掩码门建模和Verilog-AIG对齐的电路表示学习
文章解读: 使用掩码门建模和Verilog-AIG对齐的电路表示学习
http://www.studyai.com/xueshu/paper/detail/9631970519
Hidden in the Noise: Two-Stage Robust Watermarking for Images
噪声中的隐藏:图像的两阶段鲁棒水印
文章解读: 噪声中的隐藏:图像的两阶段鲁棒水印
http://www.studyai.com/xueshu/paper/detail/9657331895
SD-LoRA: Scalable Decoupled Low-Rank Adaptation for Class Incremental Learning
SD-LoRA:可扩展解耦低秩自适应方法,用于类别增量学习
文章解读: SD-LoRA:可扩展解耦低秩自适应方法,用于类别增量学习
http://www.studyai.com/xueshu/paper/detail/9671388016
Dynamic-LLaVA: Efficient Multimodal Large Language Models via Dynamic Vision-language Context Sparsification
动态-LLaVA:通过动态视觉-语言上下文稀疏化实现高效多模态大语言模型
文章解读: 动态-LLaVA:通过动态视觉-语言上下文稀疏化实现高效多模态大语言模型
http://www.studyai.com/xueshu/paper/detail/9676253798
MMRole: A Comprehensive Framework for Developing and Evaluating Multimodal Role-Playing Agents
MMRole:一个用于开发和评估多模态角色扮演代理的全面框架
文章解读: MMRole:一个用于开发和评估多模态角色扮演代理的全面框架
http://www.studyai.com/xueshu/paper/detail/9678678383
MDSGen: Fast and Efficient Masked Diffusion Temporal-Aware Transformers for Open-Domain Sound Generation
MDSGen:快速高效的掩码扩散时序感知Transformer模型用于开放域声音生成
文章解读: MDSGen:快速高效的掩码扩散时序感知Transformer模型用于开放域声音生成
http://www.studyai.com/xueshu/paper/detail/9679576338
RAG-DDR: Optimizing Retrieval-Augmented Generation Using Differentiable Data Rewards
RAG-DDR:使用可微数据奖励优化检索增强生成
文章解读: RAG-DDR:使用可微数据奖励优化检索增强生成
http://www.studyai.com/xueshu/paper/detail/9682725685
PT-T2I/V: An Efficient Proxy-Tokenized Diffusion Transformer for Text-to-Image/Video-Task
PT-T2I/V: 一种用于文本到图像/视频任务的高效代理标记化扩散Transformer
文章解读: PT-T2I/V: 一种用于文本到图像/视频任务的高效代理标记化扩散Transformer
http://www.studyai.com/xueshu/paper/detail/9690255380
Tool-Planner: Task Planning with Clusters across Multiple Tools
工具规划器:跨多个工具的集群任务规划
文章解读: 工具规划器:跨多个工具的集群任务规划
http://www.studyai.com/xueshu/paper/detail/9702883067
TASAR: Transfer-based Attack on Skeletal Action Recognition
TASAR:基于迁移的骨骼动作识别攻击
文章解读: TASAR:基于迁移的骨骼动作识别攻击
http://www.studyai.com/xueshu/paper/detail/9705793557
LoRA3D: Low-Rank Self-Calibration of 3D Geometric Foundation models
LoRA3D:三维几何基础模型的低秩自校准
文章解读: LoRA3D:三维几何基础模型的低秩自校准
http://www.studyai.com/xueshu/paper/detail/9706503996
PIG: Physics-Informed Gaussians as Adaptive Parametric Mesh Representations
PIG:物理信息高斯作为自适应参数化网格表示
文章解读: PIG:物理信息高斯作为自适应参数化网格表示
http://www.studyai.com/xueshu/paper/detail/9710902522
AHA: A Vision-Language-Model for Detecting and Reasoning Over Failures in Robotic Manipulation
AHA:一种用于检测和推理机器人操作中故障的视觉-语言模型
文章解读: AHA:一种用于检测和推理机器人操作中故障的视觉-语言模型
http://www.studyai.com/xueshu/paper/detail/9723159516
CBGBench: Fill in the Blank of Protein-Molecule Complex Binding Graph
CBGBench:填补蛋白质分子复合物结合图空白
文章解读: CBGBench:填补蛋白质分子复合物结合图空白
http://www.studyai.com/xueshu/paper/detail/9723525522
Gaussian-Based Instance-Adaptive Intensity Modeling for Point-Supervised Facial Expression Spotting
基于高斯模型的实例自适应强度建模用于点监督面部表情识别
文章解读: 基于高斯模型的实例自适应强度建模用于点监督面部表情识别
http://www.studyai.com/xueshu/paper/detail/9731552671
NarrativeBridge: Enhancing Video Captioning with Causal-Temporal Narrative
叙事桥:通过因果-时序叙事增强视频字幕
文章解读: 叙事桥:通过因果-时序叙事增强视频字幕
http://www.studyai.com/xueshu/paper/detail/9732367776
Fat-to-Thin Policy Optimization: Offline Reinforcement Learning with Sparse Policies
脂肪到瘦政策优化:稀疏策略的离线强化学习
文章解读: 脂肪到瘦政策优化:稀疏策略的离线强化学习
http://www.studyai.com/xueshu/paper/detail/9767077157
Learning Long Range Dependencies on Graphs via Random Walks
通过随机游走学习图上的长距离依赖关系
文章解读: 通过随机游走学习图上的长距离依赖关系
http://www.studyai.com/xueshu/paper/detail/9768879338
ReCogLab: a framework testing relational reasoning & cognitive hypotheses on LLMs
ReCogLab:一个在大语言模型上测试关系推理与认知假设的框架
文章解读: ReCogLab:一个在大语言模型上测试关系推理与认知假设的框架
http://www.studyai.com/xueshu/paper/detail/9770677075
KBLaM: Knowledge Base augmented Language Model
KBLaM:基于知识库增强的语言模型
文章解读: KBLaM:基于知识库增强的语言模型
http://www.studyai.com/xueshu/paper/detail/9778556319
EDiT: A Local-SGD-Based Efficient Distributed Training Method for Large Language Models
EDiT:一种基于局部SGD的大语言模型的分布式高效训练方法
文章解读: EDiT:一种基于局部SGD的大语言模型的分布式高效训练方法
http://www.studyai.com/xueshu/paper/detail/9781290611
Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
Loopy:具有长期运动依赖性的音频驱动肖像化身控制技术
文章解读: Loopy:具有长期运动依赖性的音频驱动肖像化身控制技术
http://www.studyai.com/xueshu/paper/detail/9795307396
Aligning Human Motion Generation with Human Perceptions
将人类动作生成与人类感知相协调
文章解读: 将人类动作生成与人类感知相协调
http://www.studyai.com/xueshu/paper/detail/9799875109
Procedural Synthesis of Synthesizable Molecules
可合成分子的程序合成
文章解读: 可合成分子的程序合成
http://www.studyai.com/xueshu/paper/detail/9806315701
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling
WavTokenizer:一种用于音频语言模型的声学离散编解码器分词器
文章解读: WavTokenizer:一种用于音频语言模型的声学离散编解码器分词器
http://www.studyai.com/xueshu/paper/detail/9810730396
Dynamic Low-Rank Sparse Adaptation for Large Language Models
动态低秩稀疏适配用于大语言模型
文章解读: 动态低秩稀疏适配用于大语言模型
http://www.studyai.com/xueshu/paper/detail/9826916586
ProtComposer: Compositional Protein Structure Generation with 3D Ellipsoids
ProtComposer:基于3D椭球体的组合蛋白质结构生成
文章解读: ProtComposer:基于3D椭球体的组合蛋白质结构生成
http://www.studyai.com/xueshu/paper/detail/9832316375
R2Det: Exploring Relaxed Rotation Equivariance in 2D Object Detection
R2Det:探索二维目标检测中的松弛旋转等变性
文章解读: R2Det:探索二维目标检测中的松弛旋转等变性
http://www.studyai.com/xueshu/paper/detail/9835085620
HiSplat: Hierarchical 3D Gaussian Splatting for Generalizable Sparse-View Reconstruction
HiSplat:分层3D高斯喷溅用于泛化稀疏视图重建
文章解读: HiSplat:分层3D高斯喷溅用于泛化稀疏视图重建
http://www.studyai.com/xueshu/paper/detail/9859922833
MedTrinity-25M: A Large-scale Multimodal Dataset with Multigranular Annotations for Medicine
MedTrinity-25M:一个具有多粒度标注的大规模多模态医学数据集
文章解读: MedTrinity-25M:一个具有多粒度标注的大规模多模态医学数据集
http://www.studyai.com/xueshu/paper/detail/9861265361
Efficient Neuron Segmentation in Electron Microscopy by Affinity-Guided Queries
电子显微镜下的高效神经元分割方法:基于亲和力引导查询
文章解读: 电子显微镜下的高效神经元分割方法:基于亲和力引导查询
http://www.studyai.com/xueshu/paper/detail/9878099773
Leveraging Flatness to Improve Information-Theoretic Generalization Bounds for SGD
利用平坦性提升SGD的信息理论泛化界限
文章解读: 利用平坦性提升SGD的信息理论泛化界限
http://www.studyai.com/xueshu/paper/detail/9883000519
ContraDiff: Planning Towards High Return States via Contrastive Learning
ContraDiff:通过对比学习规划至高回报状态
文章解读: ContraDiff:通过对比学习规划至高回报状态
http://www.studyai.com/xueshu/paper/detail/9889691112
Dysca: A Dynamic and Scalable Benchmark for Evaluating Perception Ability of LVLMs
Dysca:一个用于评估LVLMs感知能力的动态可扩展基准
文章解读: Dysca:一个用于评估LVLMs感知能力的动态可扩展基准
http://www.studyai.com/xueshu/paper/detail/9897667181
Dist Loss: Enhancing Regression in Few-Shot Region through Distribution Distance Constraint
分布距离约束下通过少样本区域增强回归的Dist Loss
文章解读: 分布距离约束下通过少样本区域增强回归的Dist Loss
http://www.studyai.com/xueshu/paper/detail/9900790755
EMMA: Empowering Multi-modal Mamba with Structural and Hierarchical Alignment
EMMA:通过结构和层次对齐赋能多模态Mamba
文章解读: EMMA:通过结构和层次对齐赋能多模态Mamba
http://www.studyai.com/xueshu/paper/detail/9909071551
An Engorgio Prompt Makes Large Language Model Babble on
一个Engorgio提示让大语言模型喋喋不休
文章解读: 一个Engorgio提示让大语言模型喋喋不休
http://www.studyai.com/xueshu/paper/detail/9921107888
AdaIR: Adaptive All-in-One Image Restoration via Frequency Mining and Modulation
AdaIR:基于频率挖掘和调制的自适应一体化图像修复
文章解读: AdaIR:基于频率挖掘和调制的自适应一体化图像修复
http://www.studyai.com/xueshu/paper/detail/9931065786
CO-MOT: Boosting End-to-end Transformer-based Multi-Object Tracking via Coopetition Label Assignment and Shadow Sets
CO-MOT:通过合作竞争标签分配和阴影集提升基于端到端Transformer的多目标跟踪
文章解读: CO-MOT:通过合作竞争标签分配和阴影集提升基于端到端Transformer的多目标跟踪
http://www.studyai.com/xueshu/paper/detail/9962535185
Optimizing 4D Gaussians for Dynamic Scene Video from Single Landscape Images
基于单张风景图像优化动态场景视频中的4D高斯
文章解读: 基于单张风景图像优化动态场景视频中的4D高斯
http://www.studyai.com/xueshu/paper/detail/9968807823
SSLAM: Enhancing Self-Supervised Models with Audio Mixtures for Polyphonic Soundscapes
SSLAM:通过音频混合增强多音部声景的自监督模型
文章解读: SSLAM:通过音频混合增强多音部声景的自监督模型
http://www.studyai.com/xueshu/paper/detail/9986900872
From Promise to Practice: Realizing High-performance Decentralized Training
从承诺到实践:实现高性能分布式训练
文章解读: 从承诺到实践:实现高性能分布式训练
http://www.studyai.com/xueshu/paper/detail/9987056116
Adversarially Robust Out-of-Distribution Detection Using Lyapunov-Stabilized Embeddings
基于李雅普诺夫稳定嵌入的对抗鲁棒异常分布检测
文章解读: 基于李雅普诺夫稳定嵌入的对抗鲁棒异常分布检测
http://www.studyai.com/xueshu/paper/detail/9989907202

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 27
27 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)