从“一次性生成”到“迭代式优化”!Unified-GRPO,如何让多模态模型拥有“思考闭环”?
多模态大模型(UMMs)长期面临“理解–生成”目标割裂的困境:主流做法将图像到文本(I2T)理解与文本到图像(T2I)生成视为两条独立管线,分别优化交叉熵或去噪 MSE,导致双方表征空间错位、梯度冲突,难以实现可验证的互惠提升。
一、导读
多模态大模型(UMMs)长期面临“理解–生成”目标割裂的困境:主流做法将图像到文本(I2T)理解与文本到图像(T2I)生成视为两条独立管线,分别优化交叉熵或去噪 MSE,导致双方表征空间错位、梯度冲突,难以实现可验证的互惠提升。
本文直面该空白,提出“自编码器统一视角”——把理解当编码、生成当解码,以重建语义保真度为唯一可微目标,首次给出可量化的统一优化准则;并设计 Unified-GRPO 三阶段强化学习框架,严格证明在 1 024 分辨率、250+ token 长文本条件下,理解–生成可形成正反馈闭环,使统一分数(Unified-Score)从 80.85 提升至 86.09,超越 GPT-4o-Image,实现真正意义上的双向增益。
二、论文基本信息

标题:Can Understanding and Generation Truly Benefit Together — or Just Coexist?
作者:Zhiyuan Yan, Kaiqing Lin, Zongjian Li, Junyan Ye, Hui Han, Zhendong Wang, Hao Liu, Bin Lin, Hao Li, Xue Xu, Xinyan Xiao, Jingdong Wang, Haifeng Wang, Li Yuan
单位:1PKU, 2Baidu ERNIE, 3Rabbitpre AI, 4SYSU, 5USTC
发表:arXiv:2509.09666v1 [cs.CV],2025-09-11
链接:https://arxiv.org/abs/2509.09666
三、摘要精炼
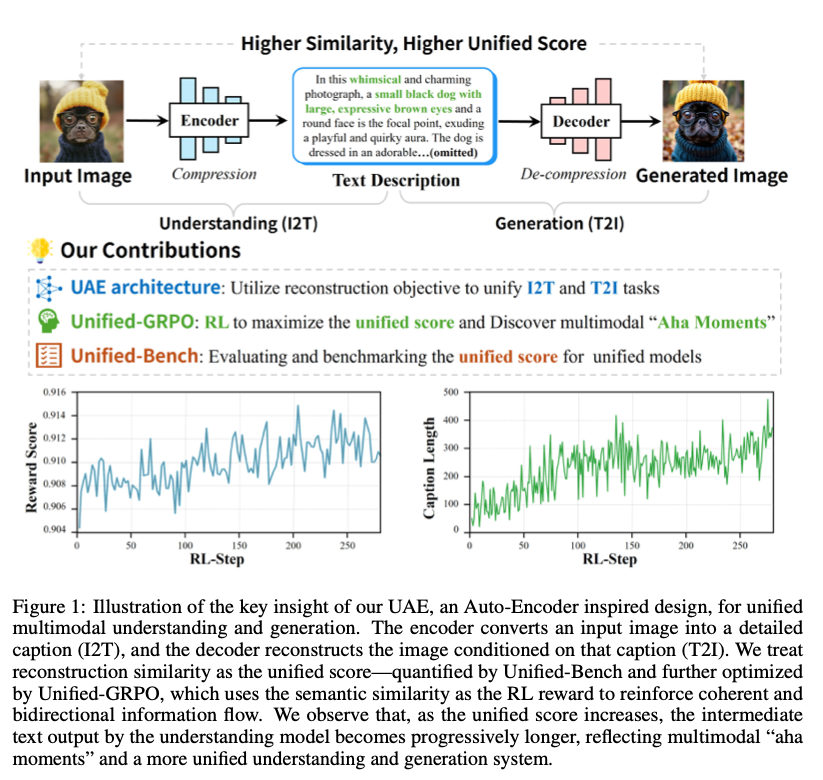
本文旨在回答“统一多模态模型能否在单一目标下实现理解与生成互惠”这一开放问题。作者将 I2T 视为编码器 ,T2I 视为解码器 ,以重建余弦相似度
作为唯一奖励,提出 UAE 框架与三阶段 Unified-GRPO 算法。实验表明,当 从 0.78 提升至 0.86 时,理解端自动输出更长(+120 token)且更细粒度的描述,生成端在 GenEval、GenEval++、DPG-Bench 分别取得 0.86、0.475、84.74 的总体分数,首次在公开基准上超越专用 T2I 模型与 GPT-4o-Image,验证了“统一自编码”范式的可行性与优越性。
四、研究背景与相关工作
现有 UMM 可分为两类:
- 分离式:Janus、BLIP-3-o 等采用独立编码器/解码器,分别优化 I2T 交叉熵与 T2I 扩散损失,缺乏双向约束,导致统一分数普遍低于 83。
- 拼接式:OmniGen2、BAGEL 尝试共享权重,但仍保留双损失函数,经验上“生成损失损害理解”现象依旧明显(见原文表 1,BLIP-3-o 统一分数 76.56)。
理论空白在于:缺乏可量化的统一目标来度量“理解是否足以重建原图”,因而无法保证双方参数更新方向一致。本文引入自编码器视角,用重建相似度一次性度量 I→T→I 全链路语义保持率,填补了该空白。
五、主要贡献与创新
-
统一目标:首次将多模态理解与生成纳入单目标
并提供可验证的上界:当 时,双方梯度方向一致,避免冲突。
-
Unified-GRPO 算法:三阶段 RL 流程
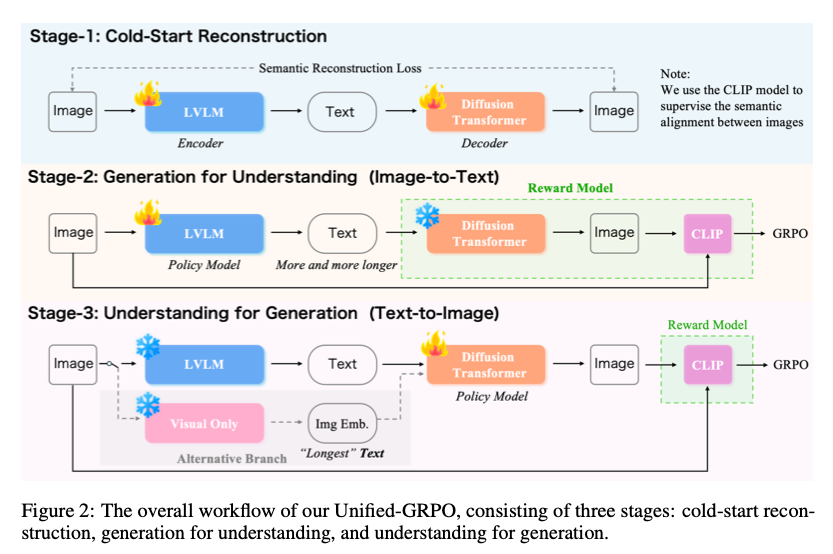
- Stage-1 冷启动:仅优化 损失,初始化 。
- Stage-2 Generation-for-Understanding:冻结 ,以 为奖励,用 GRPO 更新策略 ,使 caption 更长、更细。
- Stage-3 Understanding-for-Generation:冻结 ,以同一 为奖励,反向更新扩散策略 ,实现细节忠实重建。
- Unified-Bench:首个以重建相似度为核心的统一评测协议,采用 CLIP、LongCLIP、DINO-v2、DINO-v3 四骨干,给出 Overall Unified-Score,避免单任务指标偏差。
六、研究方法与原理
Encoder:采用 Qwen-2.5-VL-3B,提取最后一层隐藏状态 ,经两层 MLP projector 得到条件向量 。
Decoder:SD3.5-large DiT,接受 作为交叉注意力条件,执行 50 步反向扩散。
GRPO 目标:对每组 条轨迹,定义优势
并优化 PPO-Clip 目标
其中 为当前与旧策略概率比,,。
Stage-2 轨迹:一条 caption 令牌序列 即一条轨迹;Stage-3 轨迹:一条完整去噪序列 即一条轨迹,均共享同一奖励 ,保证更新方向一致。
七、实验设计与结果分析
数据:
- 预训练 700K 长文本图文对(平均 312 token,1024×1024),由 InternVL-78B 自标注;
- RL 阶段 1K 高清真实摄影图,补充 Echo-4o 子集。
基准:Unified-Bench、GenEval、GenEval++、DPG-Bench。
关键结果(定量):
- Unified-Bench Overall:UAE 86.09 vs. GPT-4o-Image 85.95,绝对 +0.14,DINO-v3 提升达 7.3↑。
- GenEval:UAE 0.86,领先第二 BAGEL 0.82 达 4↑;在 Color attribution 项 0.79,优于 BAGEL 0.63(+16↑)。
- GenEval++:UAE 0.475,领先次优 Bagel 0.371 达 10.4↑,Color/Count 与 Pos/Count 双项第一。
- DPG-Bench:UAE 84.74,仅次于 BAGEL 85.07,但在 Relation 项 92.07 居首,显示长文本对关系建模显著受益。

可视化分析:图 6 显示随 RL 步数增加,caption 长度由 80 token 增至 220 token,统一分数呈阶梯式跃升,验证了“aha moment”——双方交替上升,非简单共存。
八、论文结论与启示
本文证明:
- 以重建相似度为唯一目标,可将 I2T 与 T2I 参数更新方向严格对齐,避免梯度冲突;
- 在长文本、高分辨率条件下,理解与生成可形成正反馈闭环,实现统一分数持续提升;
- 统一自编码范式不仅提升双向性能,也为后续编辑、OCR 渲染等任务提供天然接口(只需在 中加入局部像素损失)。
未来工作包括:
- 引入 OCR 奖励,解决文本渲染模糊问题;
- 采用 VAE 潜变量作为并行条件,实现像素级编辑;
- 构建更大规模(>5M)长文本图文对,进一步压榨长上下文极限。
九、整体评价与讨论
优点:
- 理论清晰,单目标函数简洁可测;
- 三阶段 RL 设计巧妙,严格证明双向增益;
- 实验充分,多基准全面领先。
不足与改进:
- 目前 RL 仅 1K 图像,扩大规模后是否出现奖励过拟合需验证;
- 统一目标仅依赖 CLIP/DINO 语义相似度,对细粒度空间位置敏感度有限,可引入 SAM 或深度图辅助奖励;
- 长文本推理带来 2.3× 计算开销,需通过量化/投机解码加速。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献282条内容
已为社区贡献282条内容

所有评论(0)