AAAI25|xPatch:基于指数季节-趋势分解的双流时间序列预测方法
本文提出xPatch模型,通过创新性双流架构提升时间序列预测性能。针对Transformer的时序信息保留不足问题,xPatch采用指数移动平均(EMA)进行季节-趋势分解,避免传统方法引入的边界偏差。模型包含线性MLP流处理趋势分量和CNN流处理季节性分量,结合通道独立和patch技术。实验表明,xPatch在9个真实数据集上超越基线模型,MSE和MAE分别提升2.46%和2.34%,且计算效率

论文标题:xPatch: Dual-Stream Time Series Forecasting with Exponential Seasonal-Trend Decomposition
论文链接:https://arxiv.org/abs/2412.17323
研究背景
Transformer的局限性:在时间序列预测中,Transformer的自注意力机制虽能捕捉长序列依赖,但存在排列不变性问题,难以有效保留时间序列的时序信息,甚至被简单的线性模型(如DLinear)超越。
现有分解方法的不足:Autoformer、FEDformer等模型采用简单移动平均(SMA)进行季节-趋势分解,需对序列两端填充,会引入偏差,且分解出的趋势特征单一、季节性模式复杂。
本文提出一种不依赖Transformer的新型双流架构xPatch,结合指数分解、通道独立和patch技术,提升长期时间序列预测的准确性和鲁棒性。
核心方法
01 指数季节-趋势分解(EMA)
原理:基于指数移动平均,给近期数据赋予更高权重,无需填充,避免边界偏差。趋势分量由EMA生成,季节性分量为原始序列与趋势的差值。
优势:相比SMA,EMA能更灵活地捕捉动态变化趋势,分解后的趋势和季节性分量更具可解释性,且通过ADF检验验证了EMA分解后季节性分量的平稳性。
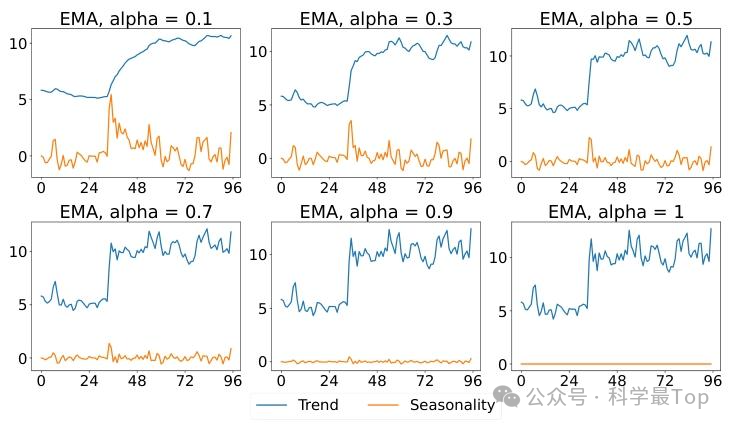
如上图所示:在ETTh1数据集上,作者采用0.1、0.3、0.5、0.7、0.9和1等不同平滑因子,对96长度样本进行指数移动平均分解。
结果显示平滑因子越小,分解出的趋势分量越平滑,对短期波动不敏感,季节性分量包含的高频细节越多;平滑因子越大,趋势分量越贴近原始数据,能更快响应短期变化,季节性分量的波动幅度则相应减小。
02 双流网络架构
-
线性流(MLP):处理趋势分量,包含全连接层、平均池化和层归一化,不使用激活函数,专注于线性特征提取。
-
非线性流(CNN):处理季节性分量,结合patch技术和深度可分离卷积,捕捉非线性模式和patch间的时空相关性。
-
通道独立:将多变量时间序列拆分为单变量处理,每个变量独立通过双流网络,提升模型对各变量特性的适应性。
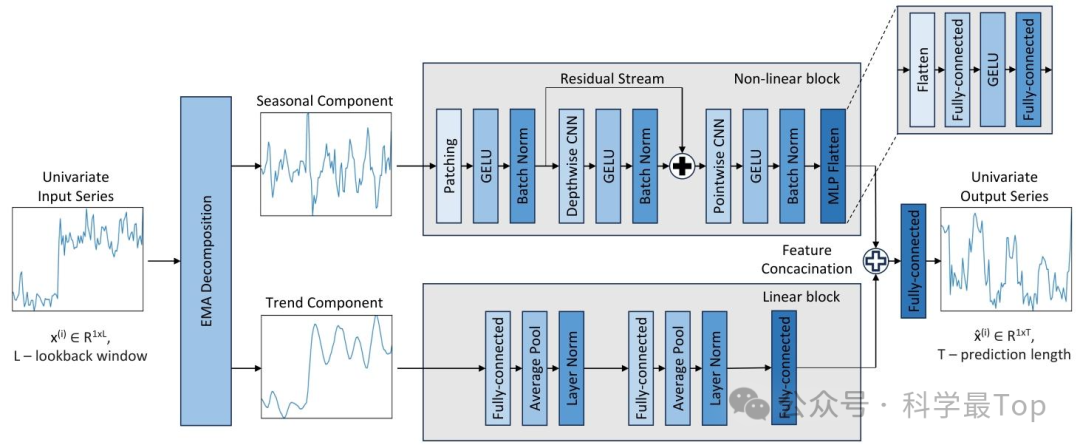
03 损失函数与学习率调整
反正切损失:针对CARD模型中距离衰减系数下降过快的问题,提出反正切损失函数,使远未来预测的损失权重衰减更平缓,提升长期预测稳定性。
Sigmoid学习率调整:引入非线性暖启动和衰减的Sigmoid学习率策略,相比传统的余弦衰减或线性衰减,训练过程更平滑,收敛更优。
实验验证
数据集涵盖9个真实世界数据集,包括电力变压器温度(ETT系列)、天气、交通、电力消耗等,覆盖不同频率和领域。基线模型对比Transformer类模型(如CARD、PatchTST、Autoformer)和非Transformer模型(如DLinear、TimeMixer)。
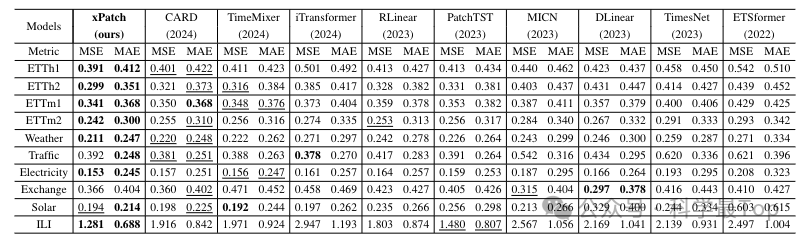
性能优势:在60%(MSE)和70%(MAE)的数据集上取得最优结果,相比CARD,MSE和MAE分别提升2.46%和2.34%;在超参数搜索后,优势扩大至5.29%和3.81%。
计算效率:尽管双流架构比单流模型计算成本略高,但远低于Transformer类模型(如CARD的训练时间是xPatch的4.8倍)。
消融实验:通过消融实验证明EMA分解、双流设计、补丁技术和反正切损失均对性能有显著贡献,其中EMA分解使模型性能提升1.35%-4.96%。
结论与未来方向
核心贡献
提出基于EMA的季节-趋势分解,替代传统SMA,提升分解质量。设计CNN+MLP双流架构,结合通道独立和补丁技术,在非Transformer框架下实现优异性能。引入反正切损失和Sigmoid学习率调整,优化训练过程。
未来方向
-
探索更复杂的分解方法,处理非平稳性更强的时间序列。
-
研究多变量间的交互建模,超越当前的通道独立假设。
大家可以关注我【科学最top】,第一时间follow时序高水平论文解读!!!获取时序论文合集


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)