代码生成模型评价指标pass@k评估优化
代码生成模型正确性不在于与参考答案的相似度,而在于能否通过预定义测试用例,因此BLEU、ROUGH等指标表现不佳。pass@k是用于程序代码生成任务的评价指标,在自动编程的评估中非常有用。之前探索了直接统计通过测试的问题数的pass@k指标评估方法。然后,存在方差容易较大的问题。OpenAI结合组合数学的抽取小球的方法对评估过程进行优化。这里尝试探索优化过程,并通过程序进行示例。
代码生成模型正确性不在于与参考答案的相似度,而在于能否通过预定义测试用例,因此BLEU、ROUGH等指标表现不佳。
pass@k是用于程序代码生成任务的评价指标,在自动编程的评估中非常有用。
之前探索了直接统计通过测试的问题数的pass@k指标评估方法。
https://blog.csdn.net/liliang199/article/details/155393240?
然后,存在方差容易较大的问题。
OpenAI结合组合数学的抽取小球的方法对评估过程进行优化。
这里尝试探索优化过程,并通过程序进行示例。
1 pass@k探索
1.1 测试问题有限
代码生成评估非常类似于Lean等刷题网站的OJ(Online Judage)模型。
用自然语言描述问题,LLM理解问题并生成问题代码,再由一个验证程序检查代码正确性。
人工构造测试集一般很小,如HumanEval只有167个问题,LLM对于每个问题只生成一种代码,那指标评估结果会具有很大方差,无法体现LLM真实能力。
1.2 pass@k指标
直观方法是让LLM对每个问题都生成n个代码,计算该问题的平均通过率。再对所有问题的通过率求均值得到总体通过率。LLM可以通过调整temperature,top-p等参数生成具有随机性的不同样本,让LLM 对一个问题生成多个代码候选,从而更精准的考查LLM在该问题上的真实通过率。
然而,当两个待评测模型,一个模型倾向于稳定输出而另一个模型的输出变化较大,但是两个模型生成的结果中通过和不通过的比例相当,平均通过率指标并不能反应哪个模型更具有随机性。
一个简单改进评价指标,就是让LLM对于一个问题生成k次,测算其至少能通过一次的概率,称为 pass@k。这样用不同k值进行评测,就可以反应出模型输出的随机性了,还可以根据评价结果来调整temperature等参数,使模型更加适应最终应用场景。
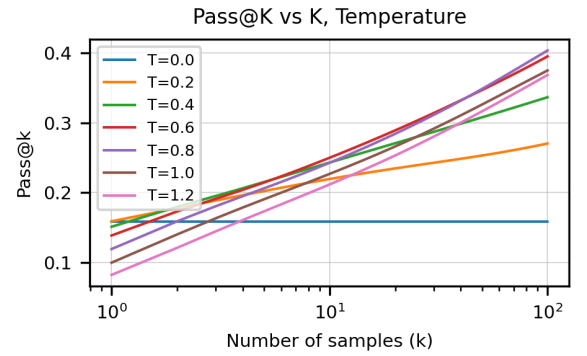
如上图所示: k 值越大,通过率越高; temperature 越高则模型的随机性 (斜率) 越大。
1.3 pass@k问题
然而pass@k计算方法,每一个测试问题重复实验t次,每次生成k个代码,最后计算平均通过率。
假如t=100, k=100,即重复实验100次估计pass@100,需要生成10000个代码,计算量巨大。
然而,t越小,对pass@k的估计有可能不准,因为方差较大。
2 pass@k尝试改进
2.1 无偏版pass@k
OpenAI在HumanEval中,针对每个问题生成n个代码(n>k),然后用下式进行无偏估计。
其中,c是生成n个代码中通过测试的数量。 n越大估计越准确。
由于n << t * k,所以,其计算代价相比pass@k的直接估计要小很多。
假设LLM为问题生成n个代码。
从n个代码中随机选择k个代码的可能情况数目,即为分母
由于c个代码通过测试,所以从剩下未通过的n-c个中选择k个代码的情况数目,即为分子。
所以,上述分数计算未通过测试的概率,被1减后,即为通过测试的概率。
然后对所有问题的通过情况求期望。
2.2 无偏pass@k依据
首先,再次梳理无偏pass@k的基础假设。
针对一个问题,假设LLM只能生成n种不同代码,每一种代码被生成的概率是相等的。
其中,c个代码通过测试。
LLM任意生成的k个代码,全都没有通过测试的概率即为
从n-c个不能通过的代码中采样k个代码的情况数,除以从n个代码中采样k个代码的情况数。
采样过程是均匀采样,可以通过二项分布模拟。
根据大数定理,当样本总量趋近无穷时,样本的平均值无限接近数学期望。
因此只要求出的均值,即得到了对pass@k的无偏估计。
更远一些, 应该是对
的无偏估计。
这里先不考虑这个问题,重点考虑。
对于,其实也是难以直接计算估计的,如果也是MCMC类采样模拟,成本也hold不住。
那如果用生成单个代码的平均通过率估计,是不是也能做到无偏估计。
3 pass@k期望估计
3.1 pass@k期望估计基础
其中p是pass@1指标,即生成单个代码的平均通过率。
这里解释从期望转化为求和式,在期望式子中,n和k都是确定的,只有c是随机变量。
1) 上下边界
求和式子中,上下边界为0和n-k,这里尝试理解其选择依据。
在期望公式中,列举c的所有可选项
c=0,表示n个代码均没通过测试
c=1,表示仅1个代码通过测试
...
c=n-k表示仅n-k个代码通过测试
c=n-k+1,表示仅n-k+1个通过测试,然而此时n-c=n-(n-k+1) = k-1,从k-1个代码选k个没意义。
所以c=n-k+1不存在。
同理,后续的可选项c=n-k+2, c=n-k+3, ..., c = n-1, c=n均没有意义。
所以,求和式子中的上下边界没有问题。
2)二项分布建模
binom(n, p)建模
其中P(c=i)就是做n次试验刚好有c=i个结果通过的概率。
这里,结合组合数学,随机变量c符合二项分布binom(n, p),将一次单独试验通过的概率表示为p。
所以,做n次试验刚好有c=i个结果通过的概率P(c=i)表示如下。
3.2 pass@k期望估计继续
在此基础上,继续对期望公式进行化简
最终,得到pass@k = 1 - (1-p)^k。
k=1时,pass@k = p,用生成单个代码的平均通过率估计,时没有问题的。
但,大部分对LLM生成代码能力的评估,不能做k=1的限制,用生成单个代码的平均通过率估计,是不能做到无偏估计。
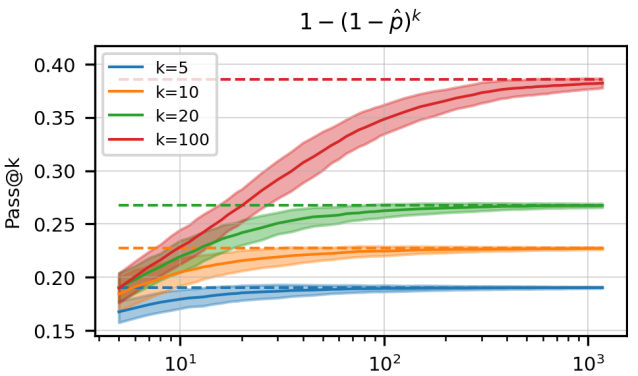
图中横坐标为实验次数n,可见当n比较小的时候,估计值与真实值 (虚线) 存在较大的偏差。
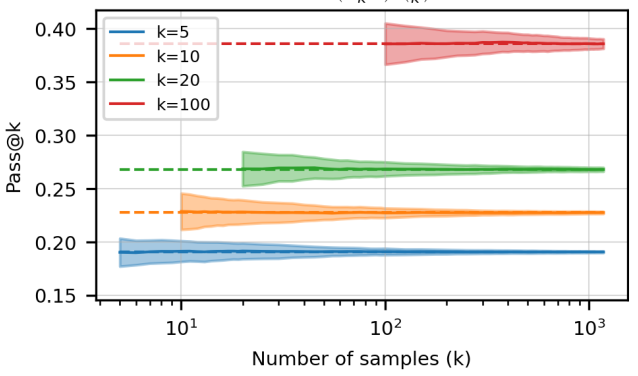
4 pass@k无偏估计
这里,只能k项一项一项的计算,才能得到无偏估计。
为了解决数值问题,作者作了如下的化简:
用代码实现,即为
def pass_at_k(n, c, k):
"""
:param n: total number of samples
:param c: number of correct samples
:param k: k in pass@$k$
"""
if n - c < k:
return 1.0
return 1.0 - np.prod(1.0 - k / np.arange(n - c + 1, n + 1))这样可以求得pass@k的无偏估计了
reference
---
pass@k代码生成模型评估指标的探索学习-基础版
https://blog.csdn.net/liliang199/article/details/155393240?
代码生成模型评价指标 pass@k 的计算
https://zhuanlan.zhihu.com/p/653063532
Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR
https://arxiv.org/abs/2508.14029
大模型代码生成能力Pass@k评估指标详解
https://awesomeml.com/大模型代码生成能力passk评估指标详解/
pass@k 如何计算
https://blog.csdn.net/weixin_47067712/article/details/147821946
Pass@k 评价指标
https://blog.csdn.net/u013172930/article/details/147080171
瞄准靶心:深入理解统计学中的有偏与无偏估计量

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)