神经网络参数计算:小学生都能看懂的AI训练原理
摘要: 神经网络训练的核心原理是通过调整参数(W、B)使预测值接近真实值,使用损失函数(如均方误差)量化误差。简单情况下可直接求解(如线性回归),复杂网络则采用梯度下降法:随机初始化参数后,计算梯度并沿最陡方向逐步调整。神经网络的多层结构通过链式法则计算各层参数的梯度,这一反向传播过程从前向计算输出开始,反向推算各层梯度并更新参数,循环迭代直至损失最小化。整个过程就像从山顶一步步试探着走到最低点。
神经网络参数计算:小学生都能看懂的AI训练原理
写在前面
还记得第一次接触"神经网络训练"这个词的时候吗?那些W、B、梯度下降、反向传播…一堆术语砸过来,感觉像是在听天书。
但其实,训练神经网络的核心逻辑,就藏在我们中学学过的一道数学题里——怎么找到一条最贴合数据点的直线?
今天,我们就用最朴实的语言,把神经网络参数计算这件事儿说透。不用担心看不懂,因为这篇文章的目标就是:让你妈都能看懂AI是怎么学习的。
一切从"找最佳答案"开始
什么叫"训练得好"?
假设你是一个算命先生(别笑,这比喻很贴切),客人报出生辰八字(输入X),你要预测他的运势(输出Y)。一开始你瞎猜,十次能错九次。但慢慢地,你发现了规律,预测越来越准。
神经网络的训练,本质上就是这个过程:
-
一开始:参数W和B都是随机的,就像新手算命先生瞎猜
-
训练目标:调整W和B,让预测值(y hat)无限接近真实值(Y)
-
判断标准:用"损失函数"来量化"猜得准不准"
损失函数:给错误打分
想象你在玩飞镖游戏,每一飞镖偏离靶心的距离,就是你的"误差"。把所有飞镖的误差加起来,就是你的"总得分"——这就是损失函数的作用。
在神经网络里,我们这样计算误差:
-
对每个数据点,画一条竖线连接"预测点"和"真实点"
-
这条线的长度就是单次误差
-
把所有误差平方后求平均,得到均方误差(MSE)
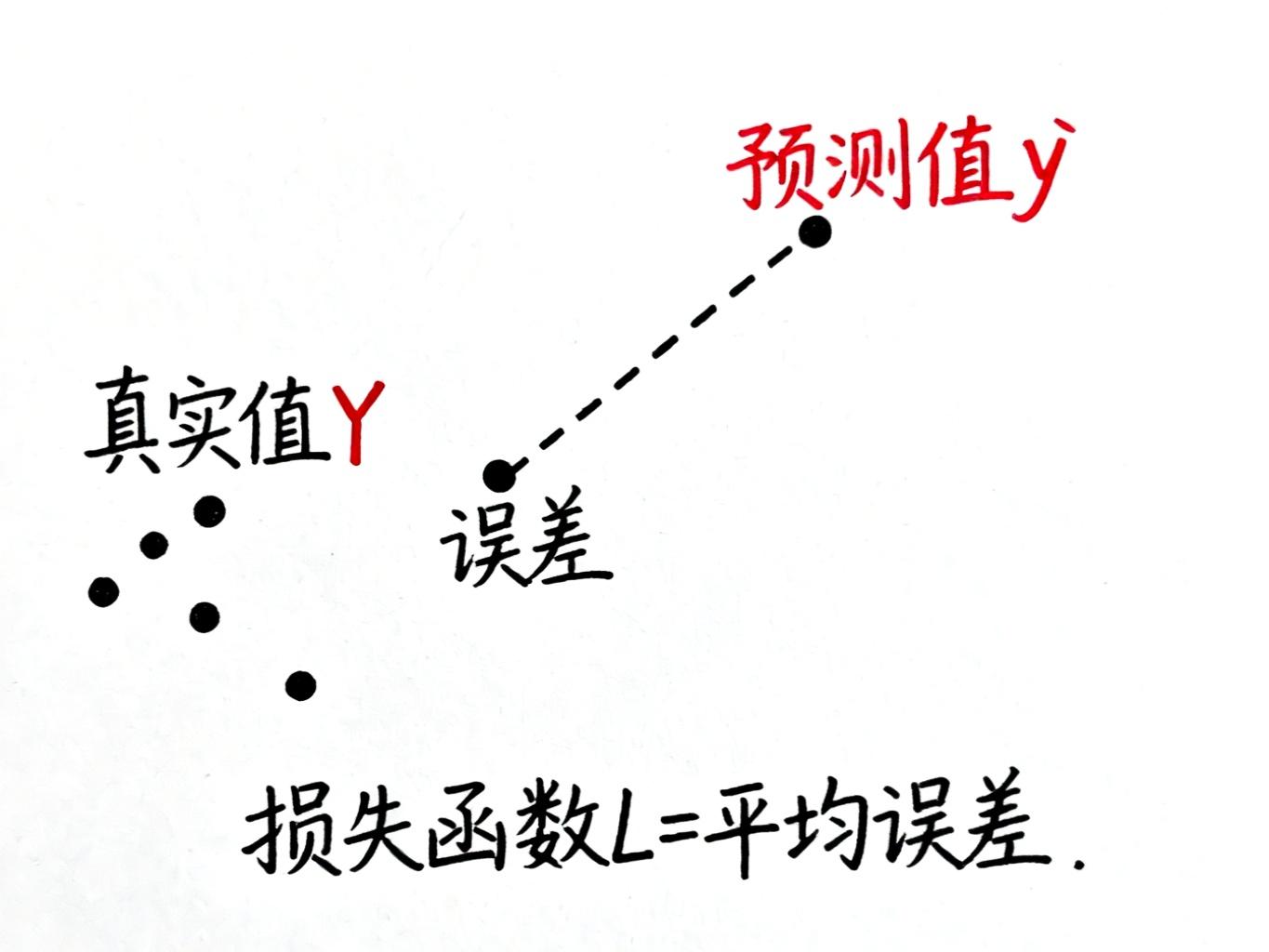
为什么要平方而不是直接用绝对值?因为平方有两个好处:
-
数学上更好算(求导时不用分情况讨论)
-
惩罚大误差(错得越离谱,惩罚越重)
从中学数学到AI黑科技
简单情况:直接求解
还记得中学学过的"求函数最小值"吗?对一个简单的二次函数,我们只需要:
-
对函数求导
-
令导数等于零
-
解方程得到最优解
比如我们有四个数据点(1,1)、(2,2)、(3,3)、(4,4),想找一条过原点的直线Y=WX来拟合它们。按照上面的步骤,很快就能算出W=1,也就是Y=X这条线最合适。
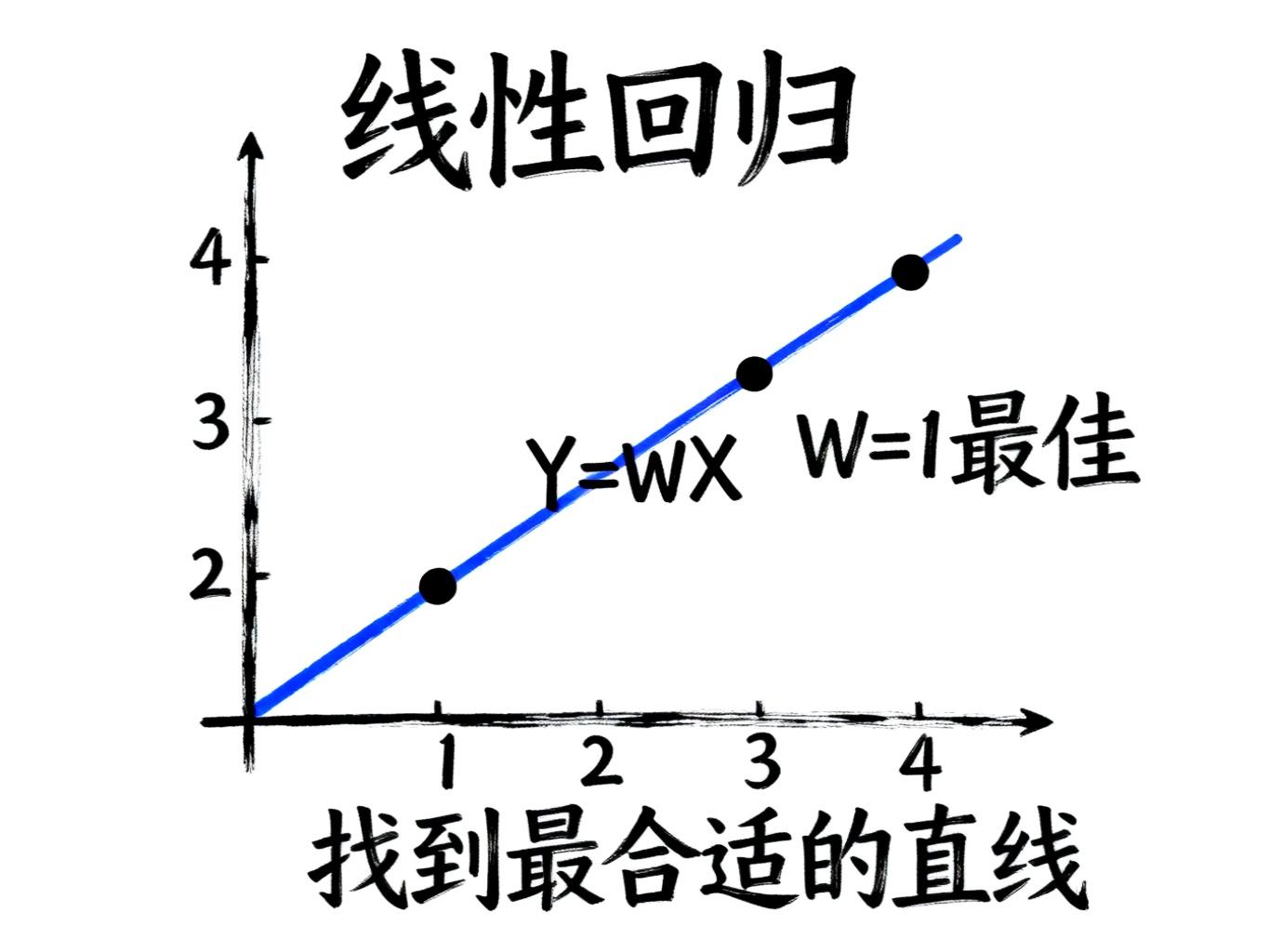
这就是经典的线性回归——机器学习最基础的技术之一。
复杂情况:一步步试探
但神经网络可不是简单的直线,它是由多层神经元组成的复杂函数。这种情况下,我们没法直接"解方程"找到最优解,怎么办?
答案是:像下山一样,一步步试探着走。
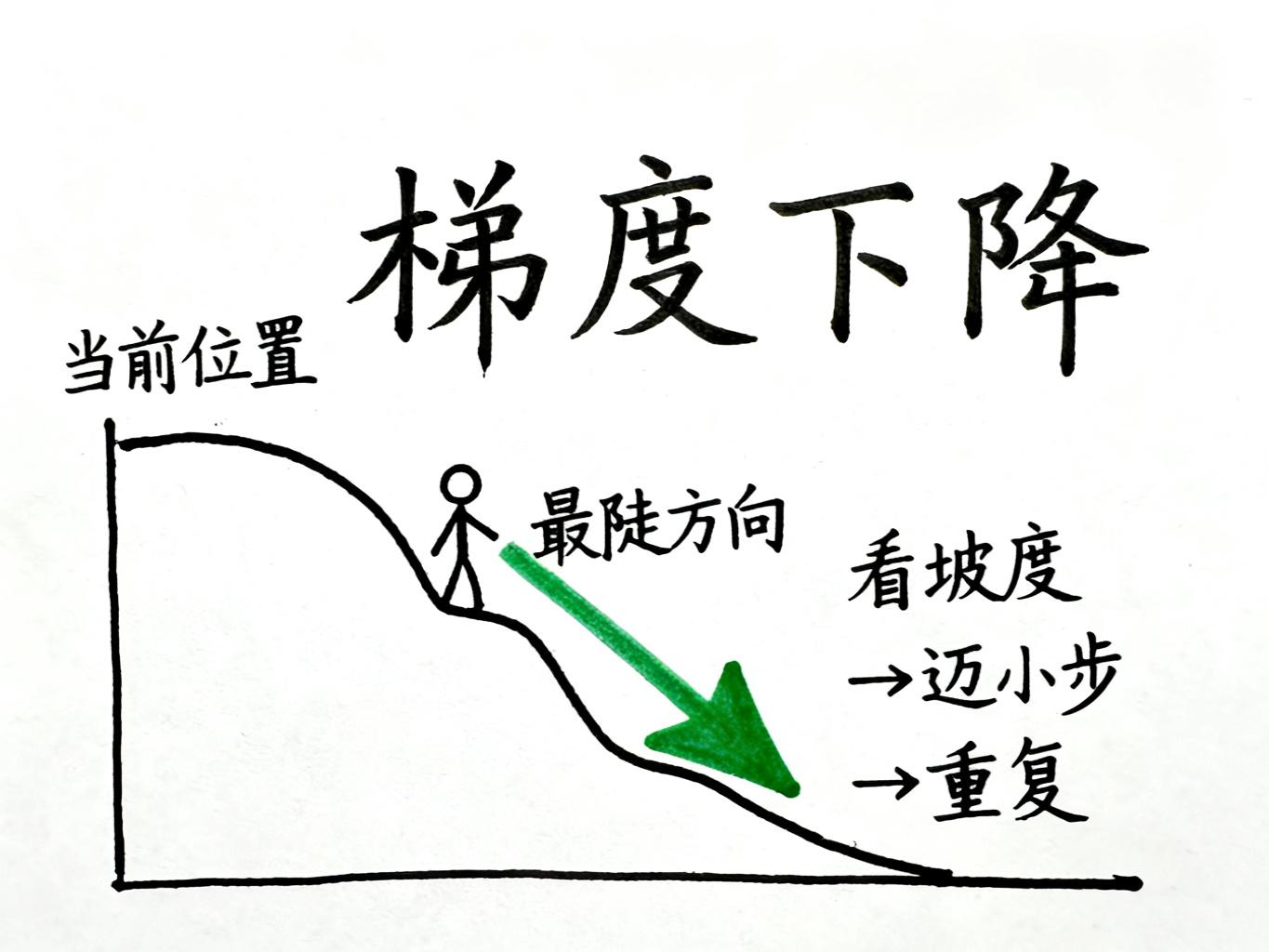
梯度下降的核心思路:
-
先站在山上某个随机位置(随机初始化W和B)
-
看看脚下哪边最陡(计算损失函数对各参数的偏导数)
-
往最陡的方向迈一小步(参数 = 参数 - 学习率 × 梯度)
-
重复2-3步,直到走到山底(损失函数足够小)
这里有个关键参数叫"学习率"——它控制每次迈步的大小。迈太大容易跌倒(震荡不收敛),迈太小又走得慢(训练效率低)。就像下山时,你得根据坡度调整步幅。
神经网络的"连锁反应"
层层嵌套的函数
神经网络的特殊之处在于:它不是一个简单函数,而是多个函数套娃组合。
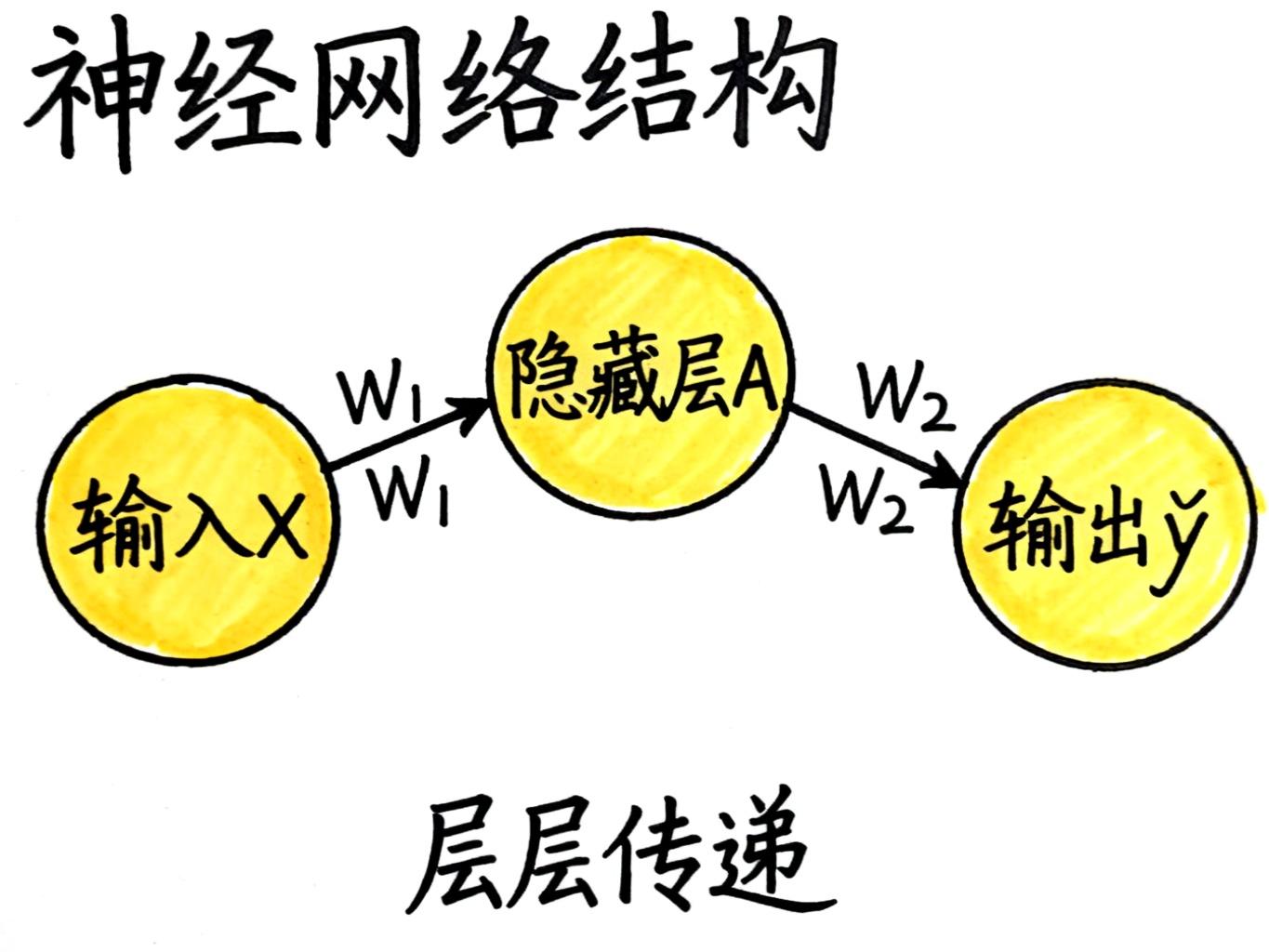
以最简单的三层网络为例:
-
第一步:输入X通过权重W1和激活函数G,得到隐藏层A
-
第二步:隐藏层A通过权重W2和激活函数,得到输出y hat
-
第三步:对比y hat和真实值Y,计算损失L
问题来了:损失函数L是最后一步才算出来的,但第一层的W1该怎么调整呢?
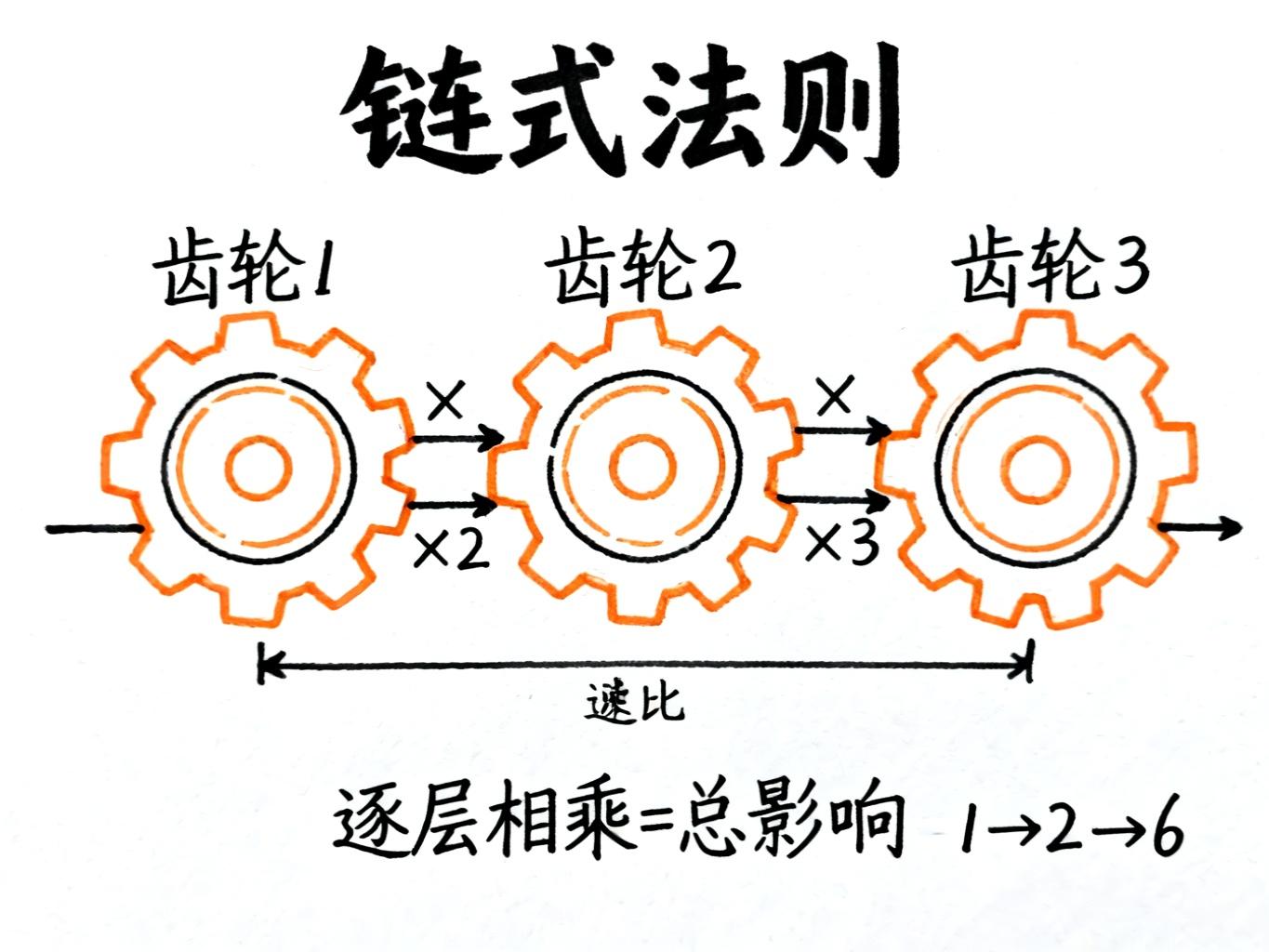
链式法则:齿轮的智慧
想象一个齿轮组:
-
第一个齿轮转1圈,第二个转2圈
-
第二个齿轮转1圈,第三个转3圈
-
问:第一个齿轮转1圈,第三个转几圈?
答案是2×3=6圈。这就是链式法则的核心思想:把每一步的影响相乘,就得到总影响。
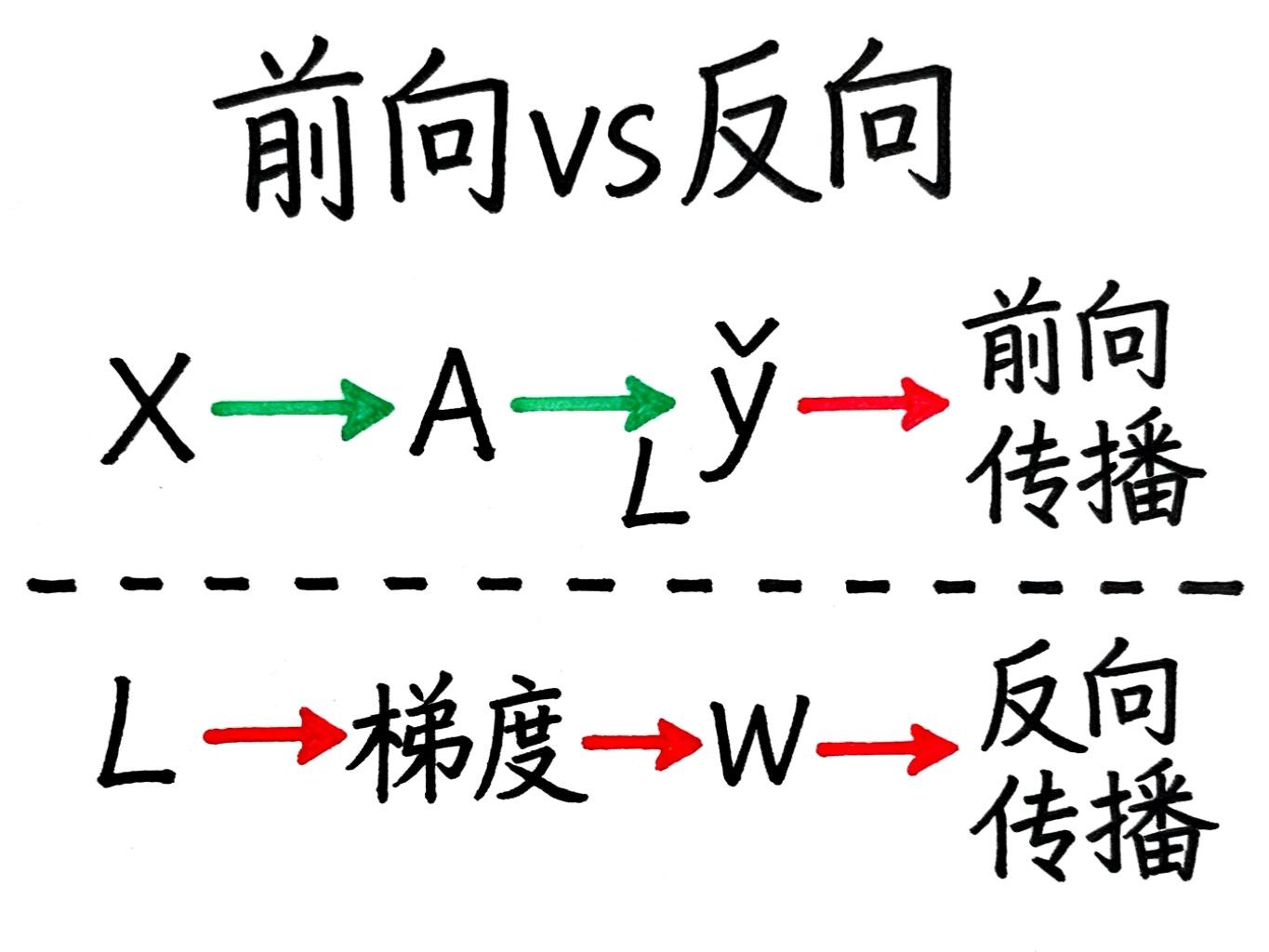
在神经网络里:
-
W1改变1单位 → A改变X单位
-
A改变1单位 → y hat改变Y单位
-
y hat改变1单位 → L改变Z单位
-
所以:W1改变1单位 → L改变X×Y×Z单位
这就是∂L/∂W1的计算方法!
反向传播:从结果倒推原因
因为我们需要从最后的损失L,一层层往前推算每个参数的梯度,所以这个过程叫反向传播(Backpropagation)。
完整的训练流程是:
-
前向传播:根据当前参数,从输入X计算到输出y hat
-
计算损失:对比y hat和真实值Y,得到损失L
-
反向传播:用链式法则计算每个参数的梯度
-
更新参数:所有参数沿梯度反方向微调
-
重复1-4步:直到损失足够小

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献100条内容
已为社区贡献100条内容

所有评论(0)