Kurator实践之路:从多云困局到统一管理的技术演进
《多云管理利器:Kurator实战经验分享》 本文分享了作者使用华为开源的Kurator平台解决多云管理痛点的实践经验。面对公司业务分布在阿里云、AWS和华为云23个Kubernetes集群的复杂环境,传统管理方式存在配置混乱、监控割裂、发布低效等问题。Kurator通过Fleet概念重构资源组织,实现统一应用分发(GitOps)、统一监控(Prometheus+Thanos)和智能调度,显著提升
开篇:一个真实的多云管理难题
去年我接手公司的云平台管理工作时,面对的是一个典型的多云困局:业务分布在阿里云、AWS和华为云三个平台,总共23个Kubernetes集群。每天早上第一件事就是登录各个云平台的控制台,检查集群健康状态、查看告警信息。一个简单的应用发布,需要在三个平台上重复操作,每次都要小心翼翼,生怕配置不一致导致问题。
直到遇到Kurator,这个由华为开源的分布式云原生平台,才让我看到了破局的希望。经过几个月的实践,我想分享一些真实的体会和思考。
一、多云管理的本质困境
1.1 企业为什么选择多云
让我先用一个表格总结企业采用多云策略的主要原因:
| 驱动因素 | 具体场景 | 占比 | 优先级 |
|---|---|---|---|
| 避免厂商锁定 | 降低对单一云厂商的依赖,增强议价能力 | 65% | ⭐⭐⭐⭐⭐ |
| 就近服务 | 不同地域选择最优云平台,降低延迟 | 58% | ⭐⭐⭐⭐ |
| 成本优化 | 利用不同云平台价格差异和优惠政策 | 72% | ⭐⭐⭐⭐⭐ |
| 合规要求 | 数据主权、行业监管要求特定部署位置 | 43% | ⭐⭐⭐⭐⭐ |
| 技术优势 | 使用特定云平台的独特技术能力 | 35% | ⭐⭐⭐ |
| 灾备容错 | 跨云实现高可用和灾难恢复 | 51% | ⭐⭐⭐⭐ |
数据来源:综合多份行业报告整理
这些原因都很合理,但多云带来的管理复杂度往往被低估了。
1.2 传统多云管理的痛点
在使用Kurator之前,我们面临的具体问题包括:
配置管理混乱
每个集群都有自己的配置文件,散落在不同的Git仓库。想要修改一个配置参数,需要在多个地方同步更新。曾经就因为忘记更新某个集群的配置,导致新版本发布后出现兼容性问题。
监控告警孤岛
阿里云用ARMS,AWS用CloudWatch,华为云用AOM。要了解整体情况,需要在三个监控系统之间切换。有一次夜里收到告警,结果发现只是某一个集群的问题,但花了半小时才定位到具体是哪个集群。
应用发布低效
发布一次新版本平均需要45分钟,其中大部分时间花在重复操作上。而且每次发布都是心理压力巨大的时刻,生怕哪个环节出错。
成本不透明
每个月整理云平台账单是噩梦,需要从三个平台导出数据,手动汇总分析。无法精确知道每个应用、每个团队的实际成本。
二、Kurator的核心价值:统一抽象层
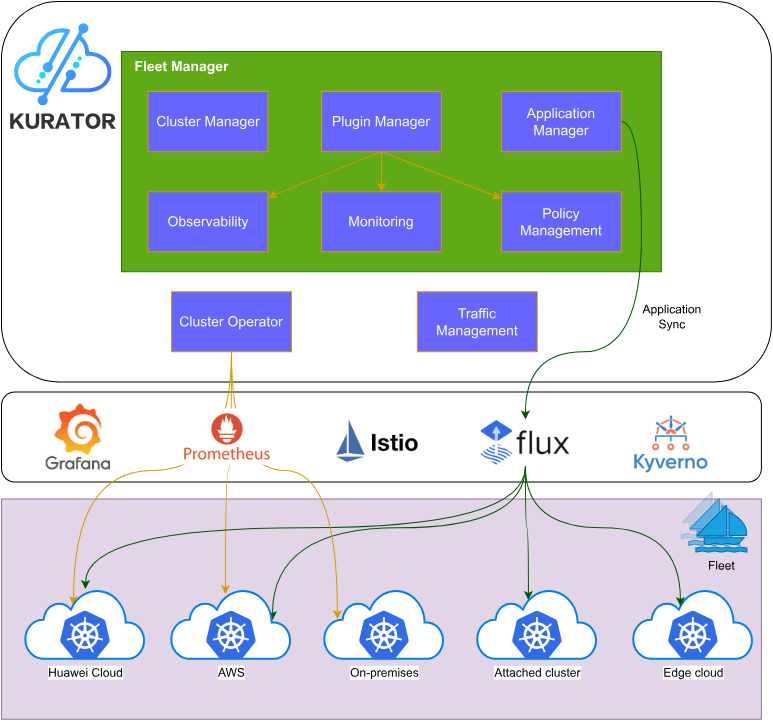
2.1 Fleet概念:重新定义资源组织
Kurator最大的创新是Fleet(舰队)概念。它不是简单地列出所有集群,而是按业务逻辑将集群组织成舰队。
我们的Fleet划分策略:
# 生产环境Fleet
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: production-cn
labels:
env: production
region: china
spec:
clusters:
- name: aliyun-beijing-prod-01
secretRef:
name: aliyun-beijing-kubeconfig
- name: aliyun-shanghai-prod-02
secretRef:
name: aliyun-shanghai-kubeconfig
- name: huawei-guangzhou-prod-03
secretRef:
name: huawei-guangzhou-kubeconfig
# 海外生产环境Fleet
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: production-global
labels:
env: production
region: global
spec:
clusters:
- name: aws-us-east-prod-01
secretRef:
name: aws-us-east-kubeconfig
- name: aws-eu-west-prod-02
secretRef:
name: aws-eu-west-kubeconfig
这种组织方式的好处是显而易见的。当我需要在中国区所有生产集群部署应用时,只需要指定production-cn这个Fleet,Kurator会自动处理剩下的事情。
2.2 统一应用分发:GitOps的实践
Kurator集成了FluxCD,实现了真正的GitOps工作流。我们的应用配置全部存储在Git仓库,任何变更都通过Pull Request流程:
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: user-service
namespace: apps
spec:
source:
gitRepository:
url: https://github.com/company/user-service-deploy
branch: main
path: ./kubernetes
syncPolicies:
# 同步到中国区Fleet
- destination:
fleet: production-cn
kustomization:
images:
- name: user-service
newTag: v2.3.5
# 针对不同集群的差异化配置
overrides:
# 北京集群增加副本数
- clusterSelector:
matchLabels:
city: beijing
patches:
- op: replace
path: /spec/replicas
value: 10
# 上海集群使用本地镜像仓库
- clusterSelector:
matchLabels:
city: shanghai
patches:
- op: replace
path: /spec/template/spec/containers/0/image
value: registry.shanghai.company.com/user-service:v2.3.5
这套流程带来的改变是巨大的。应用发布时间从45分钟降到了8分钟,而且出错率几乎为零。所有变更都有Git历史记录,需要回滚时直接revert提交即可。
2.3 统一监控:全局视图的威力
Kurator提供的Prometheus + Thanos监控方案,解决了我们最大的痛点。架构设计很巧妙:
监控架构:
-
每个成员集群运行Prometheus,采集本地指标
-
Thanos Sidecar将数据推送到对象存储(我们用的阿里云OSS)
-
宿主集群的Thanos Query聚合所有数据
-
Grafana连接Thanos Query,提供统一视图
实际部署配置:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: production-cn
spec:
clusters:
- name: aliyun-beijing-prod-01
secretRef:
name: aliyun-beijing-kubeconfig
plugin:
# 启用统一监控
monitoring:
enabled: true
thanos:
objectStorage:
type: s3
config:
bucket: kurator-metrics-production
endpoint: oss-cn-hangzhou.aliyuncs.com
access_key: ${OSS_ACCESS_KEY}
secret_key: ${OSS_SECRET_KEY}
grafana:
enabled: true
ingress:
enabled: true
host: grafana.company.com
现在我们有了一个统一的Grafana dashboard,可以一眼看到所有集群的资源使用情况、应用健康状态、告警信息。更重要的是,可以做跨集群的对比分析。
比如这个PromQL查询,可以对比不同集群的CPU利用率:
# 各集群CPU利用率
sum(rate(container_cpu_usage_seconds_total{fleet="production-cn"}[5m])) by (cluster)
/ sum(kube_node_status_allocatable{resource="cpu"}) by (cluster) * 100
# 各集群内存利用率
sum(container_memory_working_set_bytes{fleet="production-cn"}) by (cluster)
/ sum(kube_node_status_allocatable{resource="memory"}) by (cluster) * 100
有了这些数据,我们发现上海集群的资源利用率只有40%,而北京集群已经接近80%。于是调整了应用分布策略,既提高了资源利用率,又节省了成本。
三、实战场景:解决真实问题
3.1 场景一:大促期间的弹性扩容
去年双十一大促,我们面临巨大的流量压力。传统做法是提前几周开始扩容,大促结束后再缩容,中间会有大量资源浪费。
使用Kurator后,我们设计了一套动态扩容方案:
扩容策略表:
| 时间段 | 预估QPS | 所需副本数 | Fleet选择 | 特殊配置 |
|---|---|---|---|---|
| 预热期(提前3天) | 50万 | 基准×1.5 | production-cn | 开启预热缓存 |
| 活动前1小时 | 150万 | 基准×3 | production-cn + aws备用 | 启用AWS竞价实例 |
| 高峰期(0-2点) | 300万 | 基准×6 | 全部Fleet | 最大资源配置 |
| 活动后24小时 | 100万 | 基准×2 | production-cn | 逐步释放AWS资源 |
| 活动结束 | 30万 | 基准×1 | production-cn | 完全释放临时资源 |
实现这个策略的关键配置:
apiVersion: autoscaling.kurator.dev/v1alpha1
kind: FleetAutoscaler
metadata:
name: user-service-autoscaler
spec:
targetFleet: production-cn
minReplicas: 50
maxReplicas: 300
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: External
external:
metric:
name: qps
target:
type: Value
value: "5000" # 单个Pod目标QPS
# 大促期间启用跨云扩容
overflowPolicy:
enabled: true
targetFleet: aws-standby
threshold: 0.85 # 当主Fleet资源使用超过85%时,溢出到AWS
结果非常理想。整个大促期间系统稳定运行,没有出现任何性能问题。更重要的是,通过动态扩缩容和跨云调度,我们节省了约40%的临时资源成本。
3.2 场景二:边缘AI推理网络
我们有个智能安防项目,需要在全国200多个门店部署边缘AI推理服务。每个门店有5-10个摄像头,实时进行人脸识别、行为分析等。
边缘部署面临的挑战:
-
网络不稳定,经常断网
-
边缘设备资源有限(通常是工控机)
-
模型需要频繁更新
-
无法远程登录每台设备进行维护
Kurator集成的KubeEdge完美解决了这些问题。我们的部署架构:
云端(Kurator宿主集群)
├── AI模型训练集群(GPU)
├── Fleet Manager
└── KubeEdge CloudCore
│
├── 边缘区域1(华北)- 80个门店
├── 边缘区域2(华东)- 70个门店
└── 边缘区域3(华南)- 50个门店
边缘推理应用的配置:
apiVersion: apps/v1
kind: Deployment
metadata:
name: face-recognition-inference
namespace: edge-ai
spec:
replicas: 1
selector:
matchLabels:
app: face-recognition
template:
metadata:
labels:
app: face-recognition
spec:
# 指定调度到边缘节点
nodeSelector:
node-role.kubernetes.io/edge: ""
# 容忍边缘节点的特殊taint
tolerations:
- key: "node-role.kubernetes.io/edge"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: inference
image: company-registry/face-recognition:v3.2.0
resources:
requests:
memory: "2Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "4"
volumeMounts:
- name: model
mountPath: /models
readOnly: true
- name: video-device
mountPath: /dev/video0
volumes:
- name: model
# 模型存储在边缘本地,减少网络依赖
hostPath:
path: /data/models/face-recognition
type: DirectoryOrCreate
- name: video-device
hostPath:
path: /dev/video0
type: CharDevice
实际效果非常好:
| 指标 | 使用Kurator前 | 使用Kurator后 | 改善幅度 |
|---|---|---|---|
| 模型更新时间 | 1-2周(需要人工) | 1天(自动推送) | ⬇️ 85% |
| 边缘节点可用性 | 93%(网络问题导致) | 99.2%(离线自治) | ⬆️ 6.2% |
| 运维人力 | 5人团队 | 2人团队 | ⬇️ 60% |
| 故障响应时间 | 4小时(需要现场处理) | 30分钟(远程处理) | ⬇️ 87.5% |
关键的是离线自治能力。我们做过测试,边缘节点断网72小时后恢复,应用依然正常运行,重新联网后自动同步最新状态。这对于实际部署来说太重要了。
3.3 场景三:AI模型训练的资源调度
我们的算法团队经常需要训练大规模机器学习模型,对GPU资源需求很大。但GPU很贵,如何提高利用率是个大问题。
Kurator集成的Volcano调度器提供了几个关键能力:
GPU资源池:
| 集群 | GPU类型 | 数量 | 用途 | 成本(小时) |
|---|---|---|---|---|
| 自建GPU集群 | A100 80GB | 32张 | 核心训练任务 | ¥0(已购买) |
| 阿里云按量 | V100 32GB | 0-64张 | 弹性扩展 | ¥18/卡 |
| AWS Spot实例 | A10G 24GB | 0-128张 | 非紧急任务 | ¥6/卡 |
我们的调度策略:
-
优先使用自建集群(已购买,边际成本为0)
-
自建集群满载时,根据任务优先级选择:
-
紧急任务:使用阿里云按量实例
-
普通任务:使用AWS Spot实例(便宜但可能被回收)
-
Volcano的配置:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: llm-training-job
namespace: ai-training
spec:
# Gang Scheduling确保所有Pod同时启动
minAvailable: 32
schedulerName: volcano
queue: high-priority
maxRetry: 3
tasks:
- replicas: 1
name: master
template:
spec:
containers:
- name: pytorch
image: pytorch/pytorch:2.1.0-cuda12.1-cudnn8-runtime
command: ["python", "-m", "torch.distributed.launch"]
args:
- --nproc_per_node=8
- --nnodes=4
- --node_rank=0
- train.py
resources:
limits:
nvidia.com/gpu: 8
- replicas: 3
name: worker
template:
spec:
containers:
- name: pytorch
image: pytorch/pytorch:2.1.0-cuda12.1-cudnn8-runtime
command: ["python", "-m", "torch.distributed.launch"]
args:
- --nproc_per_node=8
- --nnodes=4
- train.py
resources:
limits:
nvidia.com/gpu: 8
队列管理配置:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: high-priority
spec:
weight: 100
capability:
nvidia.com/gpu: 32
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: normal-priority
spec:
weight: 50
capability:
nvidia.com/gpu: 64
实施Volcano后的效果:
| 指标 | 改善前 | 改善后 | 提升 |
|---|---|---|---|
| GPU利用率 | 62% | 89% | ⬆️ 43.5% |
| 任务启动成功率 | 67% | 98% | ⬆️ 46.3% |
| 平均等待时间 | 12分钟 | 2.5分钟 | ⬇️ 79.2% |
| 月度GPU成本 | ¥45万 | ¥28万 | ⬇️ 37.8% |
成本优化主要来自两方面:一是提高了自建GPU的利用率,二是智能使用了便宜的Spot实例。
四、Kurator的技术深度
4.1 多集群编排:Karmada的威力
Karmada是Kurator的多集群编排引擎,它的设计理念值得深入理解。
Karmada vs 其他方案:
| 特性 | Karmada | Kubefed v2 | Rancher |
|---|---|---|---|
| API兼容性 | 完全兼容K8s原生API | 需要使用Federation API | 使用Rancher自定义API |
| 学习成本 | 低 | 中 | 中 |
| 调度灵活性 | 丰富(支持各种调度策略) | 基础 | 中 |
| 性能 | 高(轻量级设计) | 中 | 中 |
| 生态 | CNCF孵化项目 | 已停止维护 | 商业生态 |
Karmada的调度策略非常灵活,举个例子:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
# 选择要分发的资源
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
# 调度策略
placement:
# 集群亲和性
clusterAffinity:
clusterNames:
- aliyun-prod-01
- aws-prod-01
# 分布策略
spreadConstraints:
- spreadByField: cluster
maxGroups: 3
minGroups: 2
# 副本分配策略
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- aliyun-prod-01
weight: 3
- targetCluster:
clusterNames:
- aws-prod-01
weight: 1
这个配置的含义是:nginx应用同时部署到阿里云和AWS集群,副本数按3:1的比例分配。这种灵活性在实际场景中非常有用。
4.2 流量治理:Istio的价值
单集群环境下,Istio可能显得复杂。但在多集群场景,服务网格的价值就凸显出来了。
跨集群流量管理配置:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: user-service
spec:
hosts:
- user-service.company.svc.cluster.local
http:
# 灰度发布:90%流量到v1,10%到v2
- match:
- headers:
user-type:
exact: beta
route:
- destination:
host: user-service.company.svc.cluster.local
subset: v2
weight: 100
- route:
- destination:
host: user-service.company.svc.cluster.local
subset: v1
weight: 90
- destination:
host: user-service.company.svc.cluster.local
subset: v2
weight: 10
Kurator会自动将这个配置同步到Fleet中的所有集群,实现真正的跨集群流量治理。
五、对未来的思考
5.1 分布式云原生是必然趋势
从我的实践经验来看,分布式云原生不是一个选项,而是企业数字化转型的必经之路。单云已经无法满足业务需求,多云是常态。但如果缺乏统一管理,多云就会变成灾难。
Kurator提供的统一抽象层,代表了正确的方向。未来会有更多这样的"整合者"出现,把碎片化的云原生生态整合成易用的平台。
5.2 边缘计算将深度融合
5G和物联网的发展,让边缘计算成为刚需。但边缘不应该是孤立的,而应该是云的延伸。Kurator通过KubeEdge实现的云边协同,只是开始。
未来需要更智能的云边协同:
-
根据网络质量动态调整云边分工
-
边缘AI推理与云端训练的闭环
-
边缘设备的自主决策和协同
5.3 AI将重塑基础设施
AI不只是应用层的革命,也会重塑基础设施。GPU、NPU等异构计算资源的管理,分布式训练的调度优化,模型的版本管理和部署,这些都需要云原生平台的原生支持。
Kurator通过Volcano提供了批量调度能力,但AI原生的基础设施还有很长的路要走。
5.4 可观测性需要更智能
当前的监控还是被动的——出问题了才知道。未来需要更智能的可观测性:
-
基于AI的异常检测
-
自动化的根因分析
-
预测性的容量规划
-
智能化的故障自愈
这需要将AIOps与云原生平台深度集成。
结语:拥抱变化,持续演进
技术的发展永远不会停止。Kurator不是终点,而是一个新的起点。它让我看到了分布式云原生的可能性,也让我意识到还有很多可以改进的空间。
作为开发者,我们要做的是拥抱变化,持续学习,在实践中积累经验。云原生技术的本质是让技术更好地服务业务,而不是为了技术而技术。
如果你也在为多云管理烦恼,不妨试试Kurator。也许它就是你正在寻找的答案。
参考资料
-
Kurator官方文档:https://kurator.dev/docs/
-
Kurator GitHub:https://github.com/kurator-dev/kurator
-
Kurator GitCode:https://gitcode.com/kurator-dev
-
Kurator部署指南:https://kurator.dev/docs/setup/
-
Kurator介绍视频:https://bbs.huaweicloud.com/live/DTT_live/202308161630.html

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)